DagsHubに入門する ~3. DagsHub+DVC+MLflow~
DagsHub+DVC+MLflow
はじめに
- DagsHubって?
- DagsHub+DVC
- DagsHub+DVC+MLflow ←イマココ
前回の記事にてDAGsHubとDVCを用いたコードとデータのバージョン管理を実装した。
今回はそこにMLflowをプラスして、ML実験のトラッキングを実装していく。
成果物のリポジトリはこちら
環境変数の設定
MLflowのトラッキングサーバーに紐づけるために、URLと認証情報が必要になるので、環境変数に設定していく。
プロジェクト毎に変わる環境変数なので、dotenvで設定する。
まずはプロジェクトディレクトリ直下に.envファイルを作成する。
MLFLOW_TRACKING_URI=https://dagshub.com/<username>/<repo_name>.mlflow
MLFLOW_TRACKING_USERNAME=<username>
MLFLOW_TRACKING_PASSWORD=<token>
設定値は例のごとく、DagsHubのUI上から確認できる。(改行用のバックスラッシュやPythonコマンドは除外する)
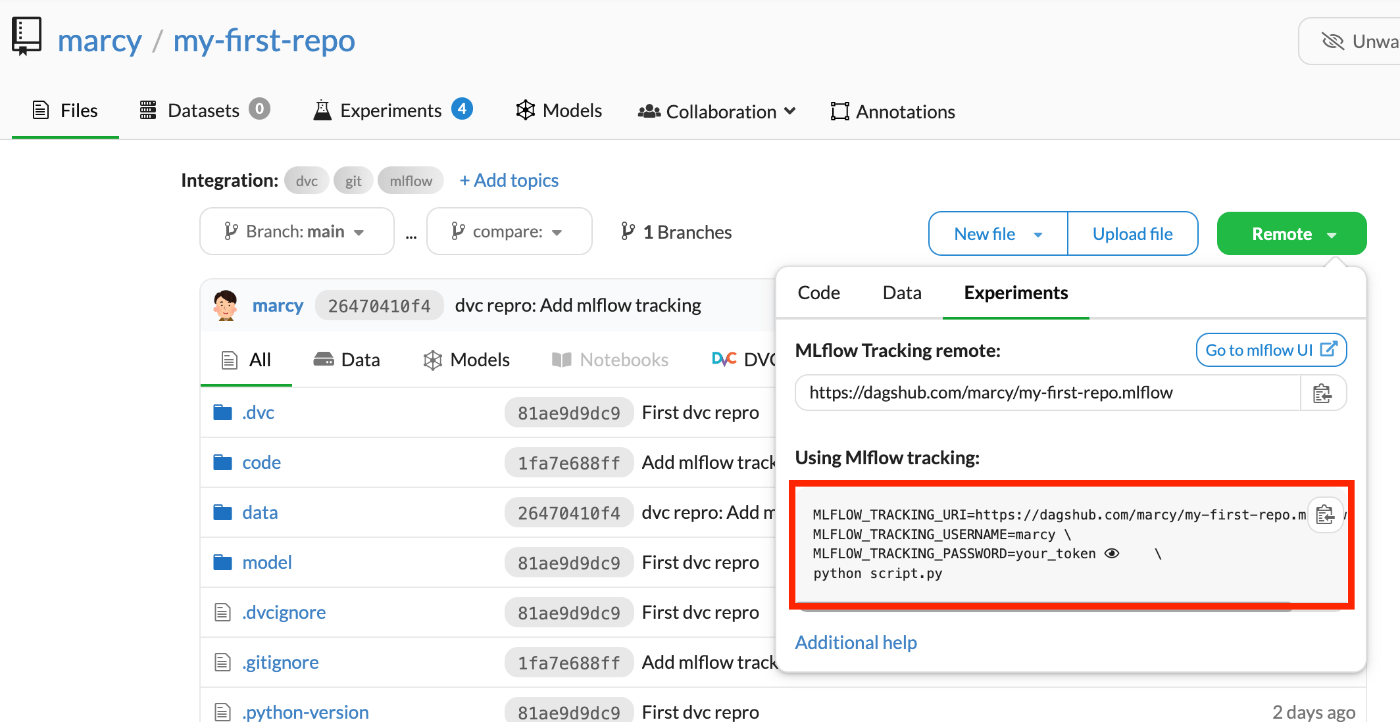
ライブラリのインストール
追加のライブラリをインストールする。
pip install python-dotenv mlflow
Trainスクリプトを更新
前回の記事にて実装したスクリプトを更新していく。
まずは追加のライブラリをインポートする。
import mlflow
from dotenv import load_dotenv
.envを環境変数として読み込む。
load_dotenv()
パラメータとメトリクスの変数を追加する。
params = {
"n_estimators": 100,
"max_depth": 5,
"random_state": 1,
}
model = RandomForestClassifier(**params)
metrics = {
"accuracy": accuracy,
}
MLflowのロギングを追加する。
with mlflow.start_run() as run:
mlflow.log_params(params)
mlflow.sklearn.log_model(model, "model")
mlflow.log_metrics(metrics)
全体
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pickle
import click
import mlflow
from dotenv import load_dotenv
load_dotenv()
@click.command()
@click.argument('input_path')
@click.argument('output_path')
def train(input_path, output_path):
# データの読み込み
df = pd.read_csv(input_path)
X = df.drop('Survived', axis=1)
y = df['Survived']
# 訓練データとテストデータに分割
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42)
params = {
"n_estimators": 100,
"max_depth": 5,
"random_state": 1,
}
# モデルの訓練
model = RandomForestClassifier(**params)
model.fit(X_train, y_train)
# モデルの保存
pickle.dump(model, open(output_path,'wb'))
# モデルの評価
y_pred = model.predict(X_valid)
accuracy = accuracy_score(y_valid, y_pred)
metrics = {
"accuracy": accuracy,
}
# mlflowロギング
with mlflow.start_run() as run:
mlflow.log_params(params)
mlflow.sklearn.log_model(model, "model")
mlflow.log_metrics(metrics)
if __name__ == "__main__":
train()
パイプラインの実行
パイプラインの実行をするということでdvc reproを実行するのだがその前にGitをコミットする。
git add .gitignore .env code/train.py
git commit -m "Add mlflow tracking"
その後パイプラインを実行する。
dvc repro
成功したら、dvcの変更もcommit&pushする。
git add .
git commit -m "DVC REPRO: Add mlflow tracking"
git push
dvc push
MLflow ソースバージョンの更新(スキップ可)
DagsHubのUIから結果を確認、、、の前に、個人的に気になるところを修正したい。
それは、MLflowにロギングされるソースバージョンとGitコミットに差が生じることである。
再現性確保のために、MLflowの実行結果とそのソースとの関連付けは重要である。
しかし、DVCとMLflowを組み合わせて、特にDVCパイプライン中でMLflowのトラッキングを実行すると、DVCパイプライン実行前のコミットをソースとしてロギングしてしまう。
DVCパイプライン実行後にはDVC管理のファイルが更新されるため、MLflowのソースとしてロギングされたコミットとは差が生じてしまう。
そのため、ここではDVCパイプライン実行後、MLflowのソースバージョンを更新する。
まずはスクリプト作成
from dotenv import load_dotenv
import mlflow
from mlflow.tracking import MlflowClient
import click
import git
load_dotenv()
@click.command()
@click.option("--experiment-id", default=0, show_default=True)
@click.option("--run-id", default=None, show_default=True, help="if value is None, use the latest value")
@click.option("--commit-hash", default=None, show_default=True, help="if value is None, use the latest value")
def update_tag(experiment_id, run_id, commit_hash):
if run_id == None:
all_runs = mlflow.search_runs(experiment_ids=[experiment_id])
run_id = all_runs.at[0, "run_id"]
if commit_hash == None:
repo = git.Repo(search_parent_directories=True)
commit_hash = repo.head.object.hexsha
client = MlflowClient()
client.set_tag(run_id, "mlflow.source.git.commit", commit_hash)
if __name__ == "__main__":
update_tag()
その後スクリプト実行
python update_source.py
順番でいうと、git commit実行後にこのスクリプトを実行する。
DagsHubかMLflowのUIから確認すると、sourceが更新されていることが分かる。
MLflow実行結果の確認
まずはDagsHubのUI上から確認する。
上部タブで[Experiments]をクリックすることで確認することができる。
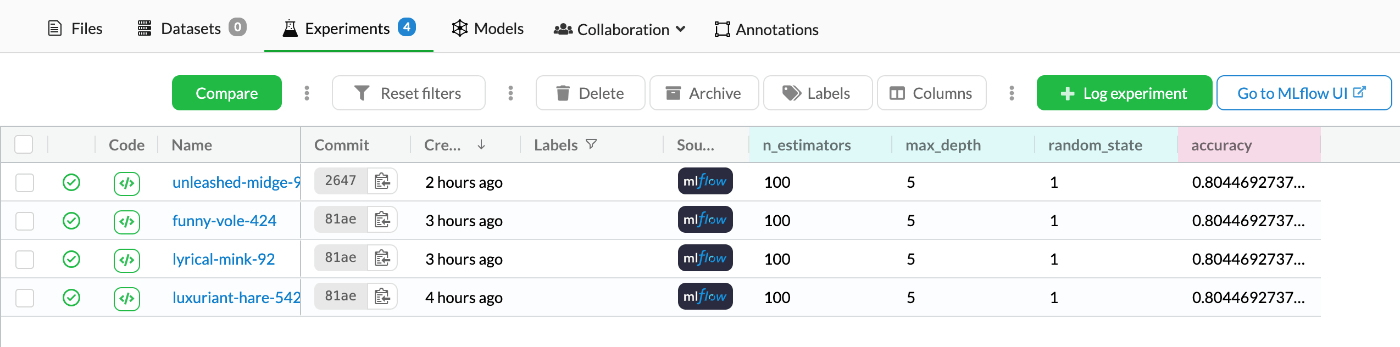
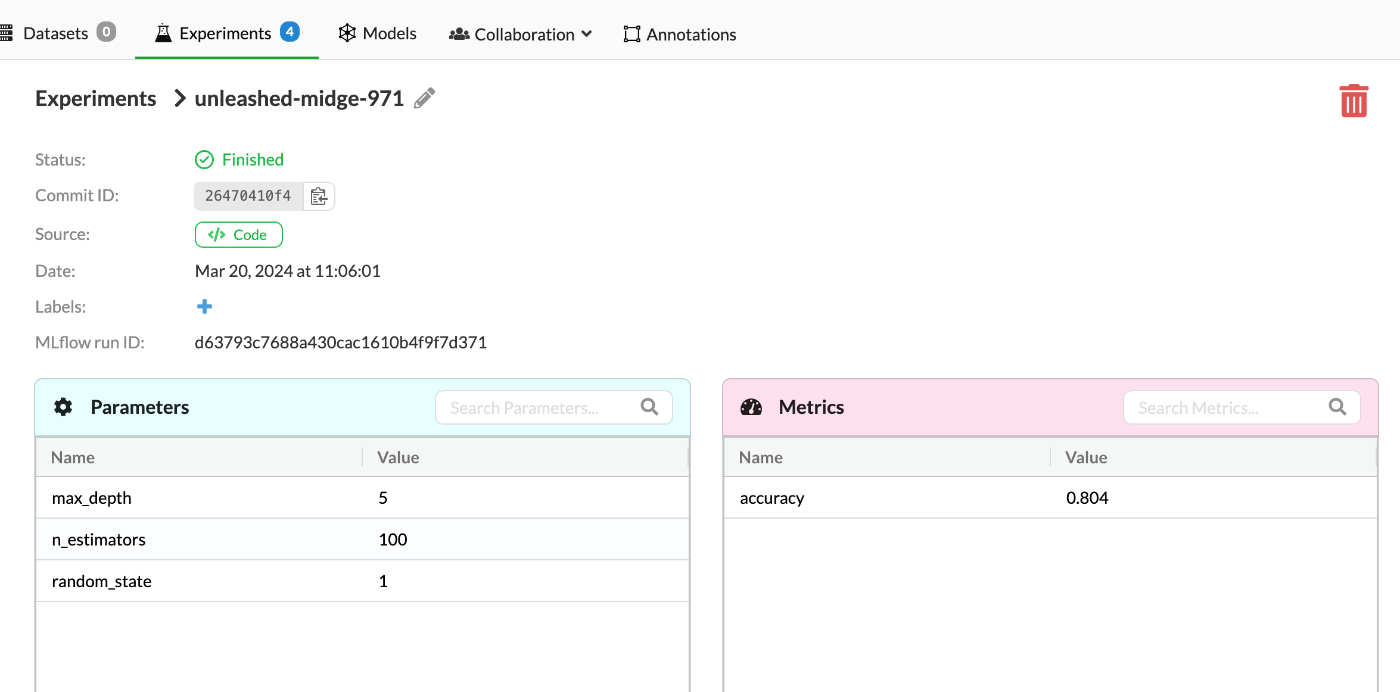
それぞれのNameをクリックすることで詳細を見ることもできる。
次にMLflow UI上から確認する。
先ほどのDagsHub Experiments画面の右上に[Go to MLflow UI]というボタンがあるのでクリックする。
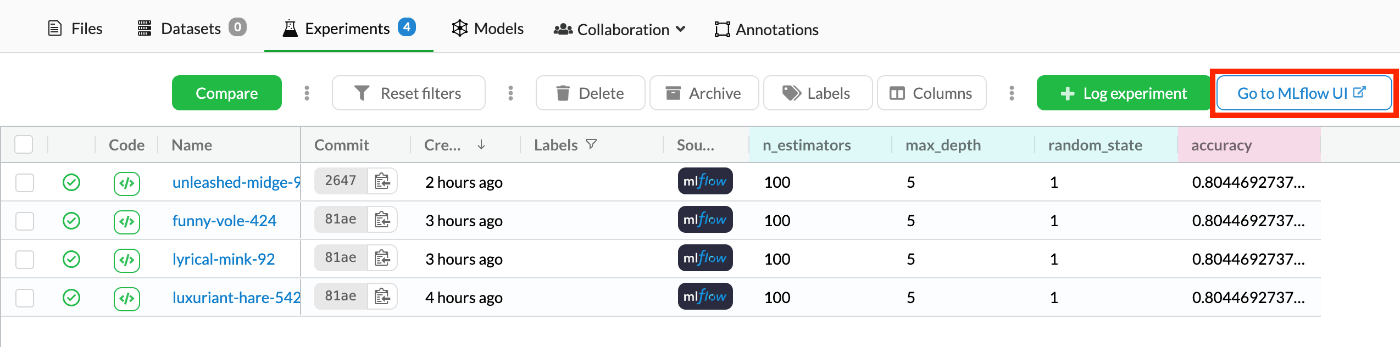
するとMLflow UIに飛ぶことができる。
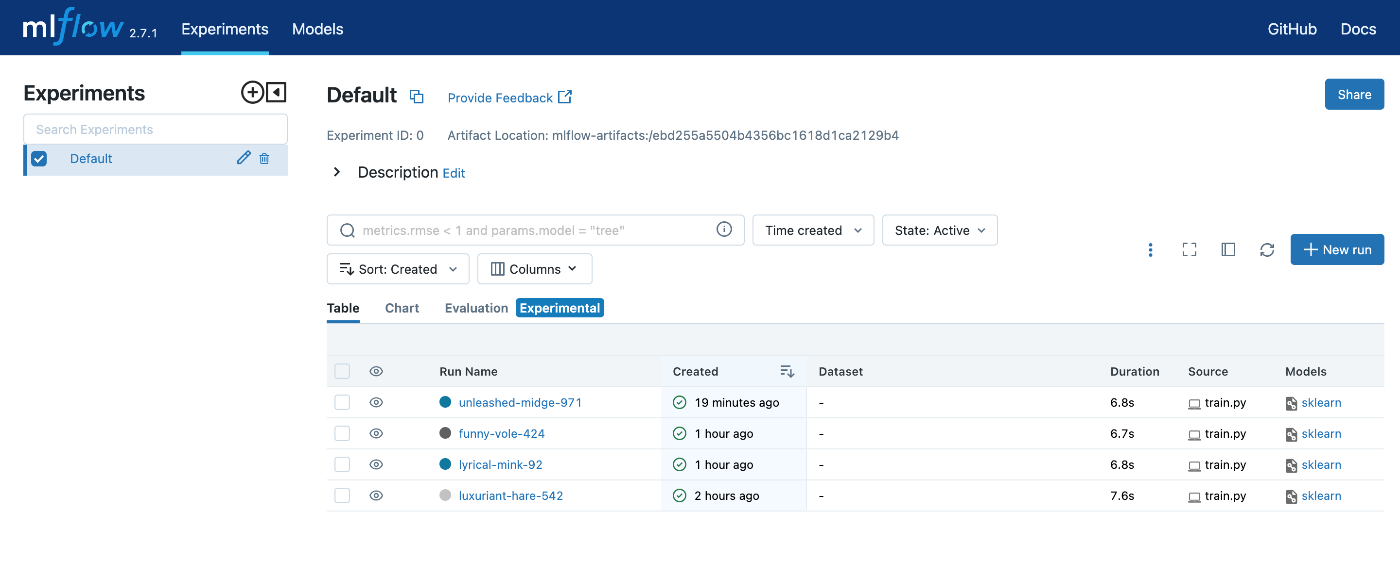
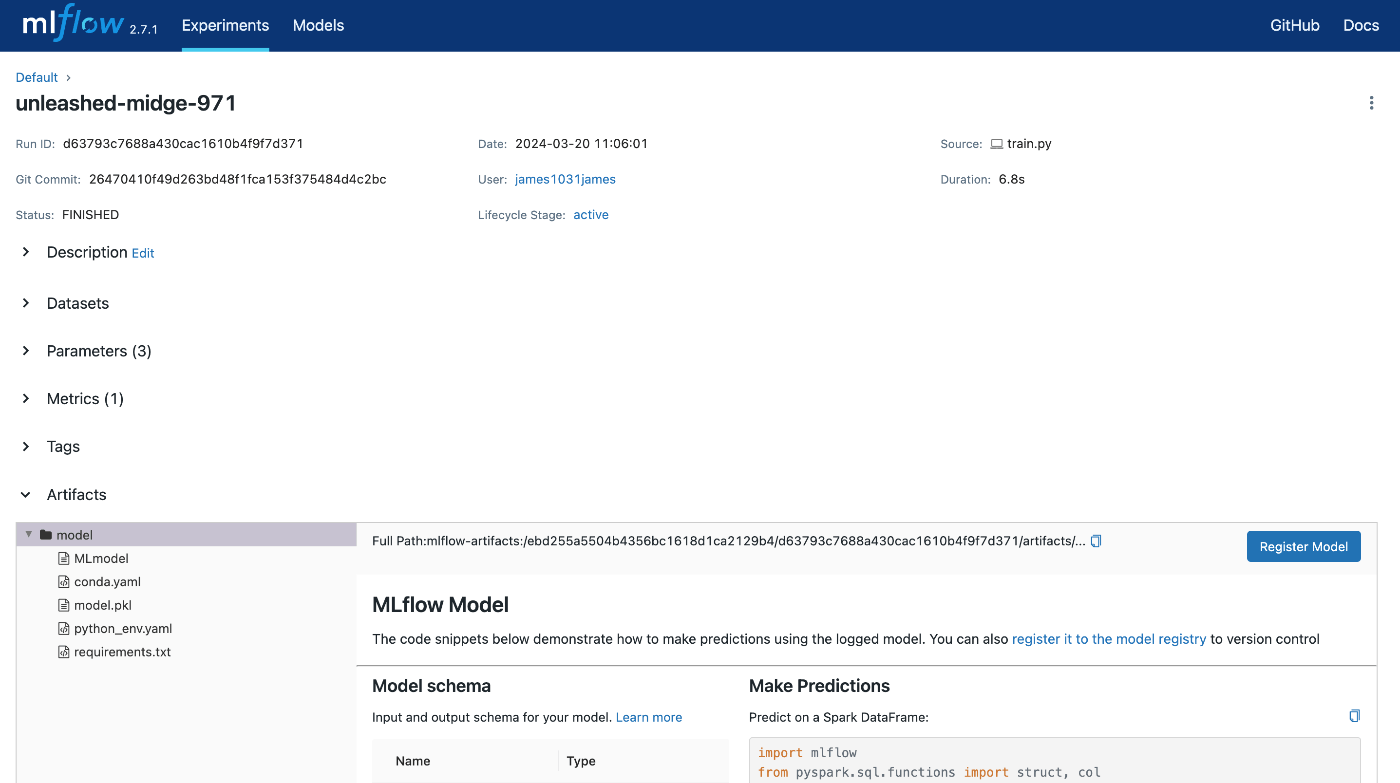
同様にそれぞれのRun Nameをクリックすることで詳細を見ることもできる。
アーティファクトとしてモデルが保存されていることも確認できる。
まとめ
これにてDagsHubにDVCとMLflowを統合して、コード&データのバージョン管理とML実験のトラッキングを実装した。
自分用にMLflowのトラッキングサーバーやアーティファクトサーバー、DVC用のリソースサーバーをDockerで立てたりしていたので、それらの管理をしていたときと比較するとだいぶ楽になった。
個人なら無料でほぼ無制限だし。
DagsHubについては一旦これにて一区切りとする。
それではまた。
Discussion