AIエージェントで障害対応とかにおける調査を少しでも楽にしたい
はじめに
こんにちは。間瀬です。
今回は「AIエージェントを使って障害対応とかにおける調査を少しでも楽にしたい」というテーマで記事をお届けしたいと思います。
システム運用における障害対応と個人的な課題感
既にシステムを運用されている方であればご存知だと思いますが、障害対応って大変ですよね。
サービス提供に影響ないことが分かっていたり、調査や復旧の必要がないことがすぐに分かれば早期に解決することができますが、そうでない場合は原因調査や復旧作業が必要になることがあります。
これらの作業が遅れてしまうとサービスを復旧するまでに時間がかかり、それが顧客の不満に繋がり最悪の場合、サービスの収益にも影響を与えかねません。
個人的な課題感
- 「有識者」じゃないと調査が難しいまたは時間がかかりがち
多くのシステム運用では障害発生時に備えて張り付きやオンコールでの監視体制を敷くことになりますが、特に自社で開発しているアプリケーションの原因調査や復旧作業は高いノウハウが求められることが多く、現場では知らない人がいないような「スーパーエンジニア」や「システム開発者本人」といった「有識者」による対応が必要になることが多々あると思います。
しかし、これら要員を常に監視体制としてアサインすることは現実的ではなく、特に深夜や休日といった連絡の取りづらいタイミングに障害が発生すると復旧までに時間がかかってしまうことになります。
また、サービスの市場競争力を高めるための新規機能追加といった別のプロジェクトにアサインされていることも多く、それらデリバリとの両立が難しくなることも多々あると思います。
AIエージェントによる調査
今回は上記のような課題によるチームや担当者の負担を減らし、これまで有識者による調査が必要になっていた作業をLLMをベースとしたAIエージェントによる調査で効率的に行うことができないか検証してみたのでその内容を紹介します。

尚、今回は「自前で開発している外部に公開されていないアプリケーションの問題」を調査する前提としています。
調査に使用するコンテキスト
AIエージェントを実装する前に調査に使用するコンテキストを整理しておきます。
実際に私自身が障害等で調査を行う際にインプットとしたい情報を参考に定義しています。
| コンテキスト | 説明 |
|---|---|
| ログ | アプリケーションが出力する構造化ログ。処理内容を知らせるものや、エラー発生時に出力される情報。 |
| トレース | OpenTelemetryによって出力されるアプリケーションの処理の流れや処理にかかった時間を記録できるもので、処理に関わる一連のアプリケーションを特定するための情報でもある。 |
| ソースコード | 実際に本番稼働するアプリケーションのソースコード |
ポイントとして、これらコンテキストをAIエージェントが関連付けて抽出&分析できるように、OpenTelemetryのトレース情報やアプリケーション名称、関数名等によってある程度、相互にリンクできるようにしていきます。

構造化ログ
アプリケーションが出力するログにはメッセージやタイムスタンプ以外にも以下のような情報を付与します。今回の検証と関連性が薄い情報は割愛しています。
| 情報 | 説明 |
|---|---|
| TraceID | OpenTelemetryによって採番されるTraceID |
| SpanID | OpenTelemetryによって採番されるSpanID |
| サービス名 | アプリケーションのサービス名 |
| リポジトリ名 | アプリケーションのソースコードを管理するリポジトリ名 |
| 関数名 | ログを出力したアプリケーションの関数名 |
| ファイル名 | ログを出力時の関数が含まれるソースコードファイル名 |
トレース
OpenTelemetryによって出力されるトレース情報の属性として、構造化ログと対応付けられる「サービス名」を設定します。その他の情報も色々と付与されていますが、今回の検証と関連性が薄いのでこちらも割愛します。
なお、関連する各種アプリケーションではトレース情報を伝搬させるようにしています。
ソースコード
実際に本番稼働するアプリケーションのソースコードと関連するコンフィグや、デプロイするためのファイル等含めて全てベクトル化してデータベースに登録します。
検証環境の構成
以下の構成で Google Cloud 上で検証環境を構築していきます。
また、AIエージェントは Google ADK (Agent Development Kit) を使用して実装していきます。
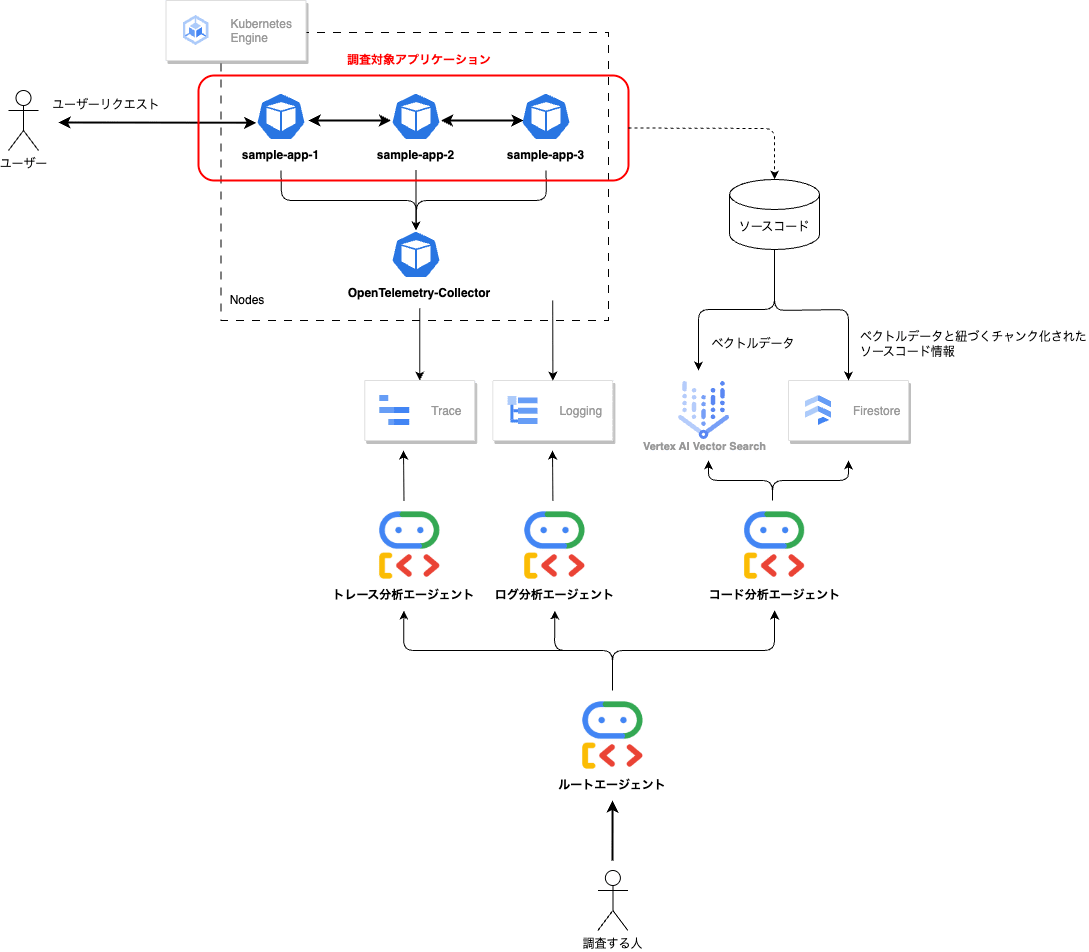
sample-app(調査対象となるアプリケーション)
- 今回の検証では同じコードのアプリケーションを3つ用意して、それぞれのアプリケーションにて異なるサービス名を設定している。
- アプリケーションの処理ではランダムに数秒のスリープやエラーが発生するように実装している。
- トレースやログについては前述した通りに出力して Cloud Trace や Cloud Logging へ連携するようにしている。
- 今回の検証では重要ではないが、トレースはOpenTelemetry-Collectorを経由して出力している。
VertexAI Vector Search
- sample-appのソースコードをベクトル化してVertexAI Vector Searchに登録している。
- 検索精度の向上のため、セマンティック検索とキーワード検索を組み合わせたハイブリッド検索を行えるようにしている。
- FirestoreにはベクトルデータのIDに対して極力コードを関数単位に分割したコンテンツ情報を登録しており、ハイブリッド検索によって抽出されたベクトルデータのIDからFirestoreに登録されているコンテンツ情報を取得することができるようにしている。
AIエージェント
- ルートエージェントに対するサブエージェントとして、それぞれ Cloud Trace、Cloud Logging、Vertex AI Vector Searchに対して照会と調査を行うエージェントを実装している。
- サブエージェントが各種APIを利用できるように FunctionTool を利用してツールを実装している。
- ルートエージェントは各サブエージェントへのタスクの委譲や各エージェントの調査結果を集約した上で分析するようにしている。
- 今回の検証ではADKに最初から用意されている WebUI を利用してエージェントを実行している。
トレース分析サブエージェントのプロンプト概要
- トレース情報からサービスの全体像を理解するように指示している。
- トレースIDがなければサービス名でフィルタして照会、トレースIDがあればこれを使用して照会するように指示している。
あなたはCloud Traceを調査する専門家です。以下のタスクを実行してください:
1. Cloud Trace APIからトレース情報を取得します。traceが分かる場合はget_cloud_trace_by_trace_idを利用してトレースを取得します。traceが分からない場合はlist_cloud_tracesを利用して、service_nameを指定してトレースをリストとして取得します。service_nameはアプリケーションのサービス名を指定します。指定がなければ最大5件まで取得します。
2. トレース毎に関連するアプリケーションサービスの全体像を把握します。
3. トレース毎にスパン情報を分析して処理時間の長いスパンを特定する。それぞれのスパンのstartTimeとendTimeを使って処理時間を計算すること。処理時間が最も長いスパンをボトルネックとして特定しますが、スパンに親子関係がある場合は親スパンと子スパンのstartTimeに注目してボトルネックを特定すること。
4. ボトルネックとなっている関数やサービスを識別
5. 以下の情報を抽出する:
- トレースに関連するサービスの全体像
- スパンの処理時間
- 関数呼び出しの階層構造
- 並列/直列実行の状況
- 外部API呼び出しによる遅延がないか
分析結果は構造化された形式で返してください。特にパフォーマンスのボトルネックとなっているスパンを明確に指摘してください。
ログ分析サブエージェントのプロンプト概要
- トレースIDがあればトレースIDによるフィルタを、サービス名が分かる場合にはサービス名でフィルタするように指示している。
あなたはCloud Loggingを調査する専門家です。以下のタスクを実行してください:
1. ユーザーから指定された条件でCloud Loggingからログを取得します。traceが分かる場合はフィルタにてtraceを指定します。サービス名が分かる場合はフィルタにてservice_nameを指定します。特に指定がなければ最大10件まで取得します。
2. エラーがあればエラーログを特定し、エラーの内容を分析します。
3. 処理時間の長いことが分かるログがあれば識別します。
4. sourceLocationからログがアプリケーションのどの関数またはメソッドから出力されているか識別します。
5. 以下の情報を抽出する:
- エラーメッセージ
- サービス名
- 関数名やメソッド名
- スタックトレース
- 実行時間(あれば)
- リポジトリ名称
分析結果は構造化された形式で返してください。特にボトルネックとなっている関数やエラーが発生している箇所を明確に指摘してください。
コード分析エージェントのプロンプト概要
- トレースやログから得られた情報で検索処理を行うように指示している。
あなたはソースコードを分析する専門家です。以下のタスクを実行してください:
1. ログやトレースから得られた関数名、クラス名、エラーメッセージを使ってVertex AI Vector Searchでソースコードを検索します。
2. 検索結果のIDと距離から、関連するソースコードを特定します。
3. 検索されたソースコードの内容を分析し、パフォーマンスのボトルネックやエラーの原因を分析します。
検索されたソースコードは内容を勝手に予測するのではなく、Vertex AI Vector Searchで検索されたソースコードをそのまま分析すること。
ルートエージェントのプロンプト概要
ちょっと長すぎるので割愛しますが、以下のような点を指示として与えています。
- 各サブエージェントの役割説明
- 調査ステップの説明
- 調査結果の分析方法の説明
実践してみる
すごく見辛いかもしれませんが、参考までに全てのアプリケーションで正常に処理が行われた際のトレースは以下の通りです。スリープ処理がランダムに入ってくるので全体の処理時間はばらつきます。

ユーザーによる調査依頼
アプリケーションに対して更に数件リクエストを送信した上で、WebUIからAIエージェントに調査を依頼してみます。
ちなみに本例では、「サービスのレイテンシが長いような気がするので調査してください」という問題が発生したとします。

トレース分析エージェントによる回答
- サービスの全体像を把握した上で、処理に時間がかかったトレースを抽出し、どこがボトルネックになっているか回答してくれている。

ログ分析エージェントによる回答
- 上記エージェントから連携されたトレースIDによるフィルタを行い、ログを特定してくれている。
- 今回はログからエラーが見られたので、エラー原因の分析をしてくれている。
- ログ自体には処理時間の情報をもたないが、関連するアプリケーションが出力するログ間の情報からボトルネックとなっている処理を予測してくれている。

- 改善点として、ターゲットとしたトレース情報が1件だけになってしまっているので、ここはルートエージェントか本エージェントのプロンプトを改善し、繰り返し調査を行うようにする必要がありそう。
コード分析エージェントによる回答
- トレースとログ調査エージェントから連携された情報を基にソースコードを検索し、ボトルネック及び、エラー原因を分析し改善策を提示してくれている。
- 記事内で記載はしていないが、提示されているソースコードは実際のソースコードの実装内容と完全に一致している。

実践結果まとめ
-
ログとトレースに加えてソースコードと突き合わせさせることで、精度の高い回答を得ることができた。
※上記の実践に至るまでにトレースとログ情報だけで調査を依頼してみたところ、当たり前ではあるがボトルネックとなっている処理やエラーが発生している箇所までは特定できるものの、原因や改善策の回答まではできませんでした。 -
ログを切り口とした調査も同等の精度で回答可能であった
※上記例はトレースから処理時間が長い処理を抽出した上で調査を行なっていますが、例えば「XXXサービスでエラーが発生しているからログから調査してください」と指示した場合、ログの分析から始まりトレースの分析、ソースコード分析といったステップで調査を行い、上記例と同様に具体的な回答を得ることができました。
本番導入に向けた検討事項
今後の自分への備忘も含めて、今回はスコープから外したが、仮に本番導入を進める際に検討しなければいけないポイントを記載しておきます。「セキュリティちゃんとせい」とか当たり前なものは割愛しています。
トレースはサンプリングされることを考慮すべき
- 規模が大きなシステムでは、全ての処理に対してトレースを取得することはコスト面から現実的ではなく、サンプリングされることが一般的なので「ログはあるがトレース情報はない」というケースを想定すること。
VertexAI Vector Searchのインデックスは複数のアプリケーションリポジトリのソースコードを保存することを考慮して実装すること
- VertexAI Vector Searchを使用する場合、インデックス単位にソースコードやアクセスするためのエンドポイントを用意することになる。
- 一つのインデックスに全てのアプリケーションソースコードを含めることはインデックス更新処理の長期化や検索精度の劣化が懸念される。
- 一案としてアプリケーションリポジトリ毎にインデックスを作成する等を検討すること、この場合、エージェントではインデックスへのアクセスに必要な情報をツールを使って動的に取得できるようにすること。
- アプリケーションリポジトリは随時更新されることを前提として、インデックスのメンテナンスフローを実装すること。
AIエージェントと各種システム&担当者とのインタフェース
- 調査を行うトリガー(XXXアラート、週次でのチェック等)を定義してAIエージェントに依頼できるように検討すること。
- 担当者が利用するコミュニケーションツールとの連携やWebUIを用意してインタラクティブに追加での調査や質問、指摘が依頼できるように検討すること。
その他
今回の検証を通じて気になった点や今後似たようなことを実践するときに参考になりそうな情報を最後に記載しておきます。
なぜ VertexAI Search ではなく VertexAI Vector Search を使用したのか
- VertexAI Search は非構造化データに対する検索機能はあるものの、現時点ではテキスト(.txt)や画像ファイルの検索にしか対応していない。詳細は公式ドキュメントを参照してください
- 試しにソースコードや関連ファイルを全てテキストファイルとして取り込んでみたが、期待するような検索精度が得られなかった。
- VertexAI Vector Search はベクトル化や上述したようなインデックスのメンテナンスが面倒だが、ベクトルデータの分割単位をコントロールできるといった点で柔軟性が高く比較的精度が高かった。
コンテキストとしてプロファイルも使いたかったが見送りに
- AIエージェントに渡すコンテキストを定義する際にプロファイルを対象することを最初から検討していましたが、Google Cloud の Cloud Profiler はAPIによるプロファイルの閲覧ができなかったため対象外としました。
ADKのトレース
- ADK自体にCloud Traceと連携できる機能が用意されていて、ユースケースによりますが有効化するだけでトレース情報の取得が可能です。
以下は FastAPIを利用するときの設定例。詳細は公式ドキュメントを参照してください
# エージェントディレクトリのパス
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
# FastAPIアプリケーションを作成
app: FastAPI = get_fast_api_app(
agents_dir=AGENT_DIR,
session_service_uri="sqlite:///./sessions.db",
allow_origins=["http://localhost", "http://localhost:8080", "*"],
web=True,
trace_to_cloud=True, ←ここ
)
注意点
- ADKのソースを調査したわけではないので定かではないが、上記を有効化するとADKの起動中にCloud TraceのAPIを何度もコールするのか、照会系のクォータを常にギリギリまで食い潰していたので注意してください。
さいごに
今回はAIエージェントを使って「障害対応とかにおける調査を少しでも楽にしたい」というモチベーションのもとに検証を行いました。
アプリケーションの規模が小さい、原因の作り込みが簡単過ぎたということもあるかもしれませんが、個人的には想定していたよりも高い精度で回答できていたので、今後はより複雑なケースを検証して実用に向けて動いていきたいと思います。
記事を閲覧いただきありがとうございました。
Discussion