外部サービスからのデータ取り込み処理は二度走る
この記事は、Magic Moment Advent Calendar 2023 24 日目の記事です。
こんにちは、Magic Moment で Software Engineer をやっている onishi です。
本記事では、実在の問い合わせチケットの調査をもとに問い合わせが来た際のエンジニアの調査の流れをまとめさせていただこうと思います。
MMP というサービスについて
Magic Moment Playbook(以下 MMP と称する)は営業組織の出力を最大化する SaaS です。
営業活動量を圧倒的に増やし、全ての営業活動から優れた顧客体験を生み出すことができます。
弊社のセールスオペレーションクラウドMagic Moment Playbookでは、サービス間で大量の営業データをやりとりする処理を行うシーンがあります。
今回はバッチ処理で大量のデータを取り込む処理の話をします。
エンタープライズ企業のお客様においては日々多くのスタッフの入力により大量のレコードが更新されることも珍しくありません。
当然その更新情報は時間差を置かずに連携先のサービスにも取り込まれる必要があり、それは MMP もまた例外ではありません。
バッチ処理で連携先サービスから更新された情報を取り込む必要があります。
MMP では Cloud Run をベースとした **Event-Driven Architecture (EDA) ** による並列分散処理により大量の取り込みデータ処理を高速に行うことができます。
詳細は先日の AdventCalendar2023 投稿記事Cloud Run × Event-Driven Architecture の並列分散処理によるデータ処理高速化への取り組みをご覧ください。
問い合わせチケットが来た背景
お客様より一部のデータが重複しているという連絡がありました。
データそのものは手動で削除されましたが、同様の問題が再発しないよう原因調査をする必要があります。
お客様から報告を受けた Customer Success から問い合わせチケットが上がり、プロダクトマネージャから高優先度の調査チケットとしてエンジニアチームに引き継がれました。
事象
特定のお客様の環境である種類のレコードが複数件重複していた。
作成時刻はほぼ同時だった。
影響範囲
お客様:1 社
範囲:レコード複数件が重複
時刻:2023-10-05 10:35~10:36 の間にレコードが作成された。
調査の開始
この日出勤していたエンジニアの onishi が 2 次調査からチケットを引き継ぎました。
この手の問い合わせチケットの調査とはシャーロック・ホームズの推理のようなものです。
可能性の中から起こらなかったことを全て取り除いた時、真実だけが残ります。
1 次調査の開始
前日の 1 次調査でいくつかのことが分かりました。
ひとつは重複が発生していた対象は問い合わせのあったお客様のレコードだけです。
今のところ同様の事象は他にありません。
もうひとつは回収されたログから問題が起きた時刻に API 経由でサービス間のリクエストが同じ内容で 2 回叩かれていることが分かりました。
これは手がかりになります。
通常検索クエリはバッチを実行する Job に対して 1 度の実行で 1 度しか叩かれません。
2 度走ったということはその前に何かが起きていたということを表しています。
2 次調査の開始
サービス間リクエストの二重実行の手がかりを中心に調査が進められました。
最初に疑われたのはバッチを実行する Job レコードの二重生成です。
バッチを実行する Job レコードはデータ取り込みが有効な MMP の Object と連携先の Object の連携設定 1 つにつき、バッチ実行ごとに 1 つ作られるジョブです。
今回の場合 10:35 のバッチ実行で作られた「連携先サービスのデータ」と「MMP のエンゲージメント」の連携設定に紐づいたバッチを実行する Job レコードが疑われます。
エンゲージメントは MMP におけるセールスとお客様との関係を表す最も根幹的なデータ概念であり、それをシステム上で実装したレコードを意味します。
もし DB 上で 10:35 ごろ、「連携先サービスのデータ」と「MMP のエンゲージメント」の連携設定の連携設定に対して 1 つではなく 2 つのバッチを実行する Job レコードが作られていたなら該当レコードを作る以前の処理が疑われなければなりません。
調査のため本番 DB に対して SQL を叩き、本番のデータを調査します。
結果、バッチを実行する Job レコードは 1 件だけでした。
つまりバッチを実行する Job レコードを作ってから、データ展開処理が起動して連携先サービスに対して検索クエリを叩くまでの間に問題があることになります。
この図で言う右上のあたりが疑われる箇所です。

次に調査すべきはデータ展開処理です。
データ展開処理はバッチを実行する Job レコード 1 件につき連携先サービスに対して検索クエリを叩き、戻ってきた検索クエリの結果を分割単位件数ごとに処理の実行単位である分散処理 Job レコードに分割する処理です。
本来であればバッチを実行する Job レコード 1 件につき分散処理 Job レコードが生成されるはずです。
その数は今回本来連携先サービスから取り込まれるべきだった件数を分割単位件数(1 回あたりの実行件数)により割った数で推計できます。
調査のため本番 DB に対して SQL を叩きます。
結果、分散処理レコードは本来生成されるべき件数の 2 倍でした。
やはりここで異常が起きていたことが分かります。
二重に分散処理レコードが作られてしまったため、それ以降の処理も二重に走った結果エンゲージメントのレコードが重複して取り込まれてしまったのです。
なぜ二重にエンゲージメントのレコードが重複取り込みされたのかは分かりました。
問題はなぜそれが起きたか、なぜ本来 1 度だけ呼ばれるはずのデータ展開処理が 2 度呼ばれ、重複してエンゲージメントのレコードが取り込まれたのでしょうか?
Pub/Sub 処理(非同期メッセージ送信)を呼び出す関数であるデータ展開処理が 2 度呼ばれた可能性も考えられます。
Pub/Subは Google が作ったサービス間をつなぐ非同期のスケーラブルなメッセージングサービスです。
GCP においてマイクロサービス間の通信に広く使われています。
非同期メッセージ送信を呼び出すデータ展開処理が、呼び出し元のデータ展開起動処理から二重に呼ばれたのでしょうか?
つまり呼び出し元側のコードの書き方や条件判定が悪く、何らかの条件を満たすとループ処理によって先ほどのデータ展開起動処理の呼び出しを 2 回行なってしまったのかもしれません。
Cloud Trace の Trace エクスプローラを使えばデータ展開起動処理が本当に 2 回呼ばれたか分かるはずです。
Cloud Traceは GCP のサービスの 1 つで trace_id によりリクエストがどのようにアプリケーションの中で処理されていったかを追うことができます。
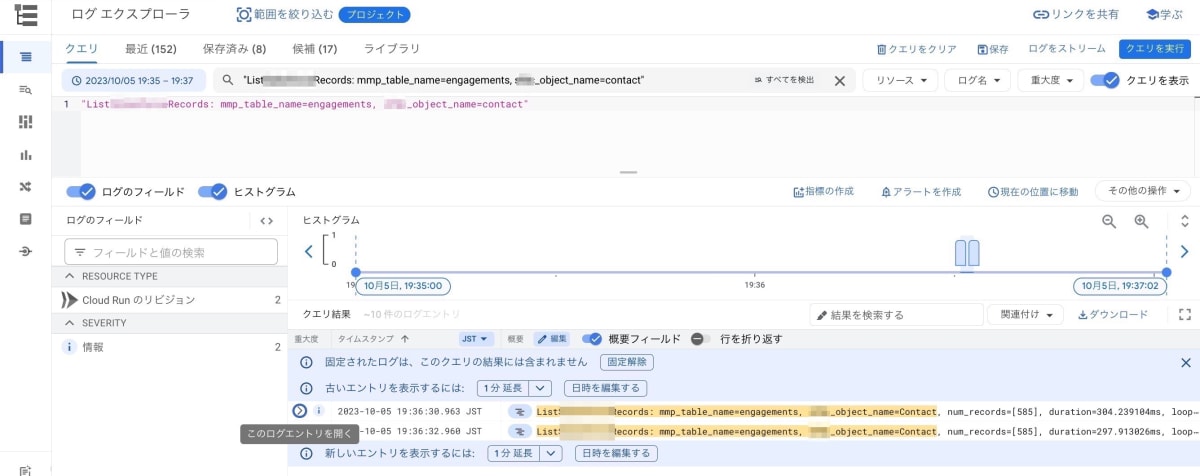
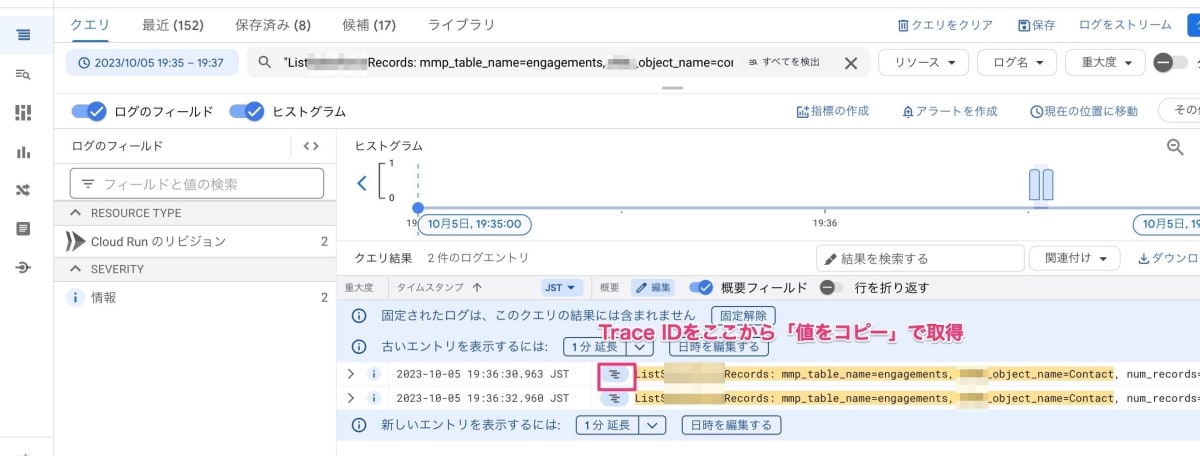
調査のため先ほどの検索クエリを二度叩いたログエクスプローラから trace_id を取得します。
次に Trace エクスプローラから trace_id をもとにデータ展開起動処理が 2 回呼ばれたかを調べてみます。
データ展開起動処理までは 1 度しか呼ばれず、データ展開処理の非同期メッセージ送信がなぜか 2 度呼ばれていることが分かりました。
これで異常が起きた箇所を絞り込むことができました。

ではデータ展開起動処理関数内でデータ展開処理を呼ぶときの非同期メッセージ送信処理の呼び出しロジックが悪いのでしょうか?
コードの書き方や条件判定が悪く、何らかの条件を満たすとループ処理によって非同期メッセージ送信処理の呼び出しを 2 回行なってしまうのかもしれません。
調査のため該当部分のコードを調べてみました。
結果は問題ありませんでした。
クリーンアーキテクチャに基づいて設計された MMP のコードはシンプルかつ堅牢で、意図しない二重実行を引き起こすような作りにはなっていません。
調査のためアプリケーションのコードを調べたところあることが分かります。
MMP の並列分散による高速取込処理、特にデータ展開処理呼び出しの部分の構成は非常にシンプルです。
つまり疑うべき場所は非同期メッセージ送信呼び出し以外にありません。容疑者が絞られたということです。
しかしは非同期メッセージ送信呼び出し処理もまた、ロジックがシンプルで意図しない二重実行を引き起こすような複雑なロジックはありませんでした。
では非同期メッセージ送信(Pub/Sub)の再送処理が問題を起こしたという可能性はどうでしょうか?
非同期メッセージ送信は再送処理が組み込まれています。
デフォルトでは 600 秒の間隔で待機し、受け取りがないと判断すると再度同じ内容を送信します。
600 秒待機して何らかの理由で送信に失敗したと判断した非同期メッセージ送信は実際には受信側で処理が成功したにもかかわらずもう一度送信したのかもしれません。
それは検索クエリの二重実行のログが 600 秒程度の間隔が空いているか調べれば分かるはずです。
しかし二重実行の間隔は 2 秒でした。
この原因も違います。
ではなぜ 2 秒間隔でデータ展開処理は二重に呼び出されたのでしょうか?
調査の行き詰まり
「全く分かりません。何が何だか、コードとデータベースで調べるべきことは全部調べたんですが……」
エンジニアの onishi はなぜ原因を突き止められないのでしょう?
ランチに食べた重いレバノン料理が眠気を誘い集中力を乱したのでしょうか?
「しかしいったい何故なんですか!?」
あるいはコードやデータベース以外に見落としているところがあるのでしょうか?
ここでテックリードの miyake-san がヘルプに入ります。
前述の並列分散処理の深い知見を持つ miyake-san はたちまちのうちにある手がかりを掴みます。
Pub/Sub には再送期限を待たずして再送されることがあります。
2 秒の間隔で二重実行されたログの説明もこれでつきます。
非同期処理である Pub/Sub は基本的に At least Once, つまり最低 1 度は非同期でデータを送ることを保証していますが再送期限より前の段階で 2 回以上送ることもあり得るということです。
ついに原因が判明しました。
原因が分かったあとにするべきことはプロダクトマネージャへの報告と対応策の検討です。
対応策
Pub/Sub ライブラリの中に二重実行を防ぐ仕組みがないかを調べました。
Exactly-once delivery オプションが存在します。
厳密に 1 度だけ実行するようになることで今回のような非同期メッセージ送信の二重実行を防ぐオプションです。
しかしExactly-once delivery オプションは Pull でのみ使えます。今回のような Push では使えません。
そこで並列分散の実行を管理するバッチを実行する Job レコードモデルに「データ展開処理で実際に展開処理が始まったか」というステータスを付与することで二重実行を防止する方針が決まりました。
このステータスが処理開始済みになっているかのチェックを入れれば今回のような二重起動が起きることはなくなるでしょう。
対応チケットを作った上でプロダクトマネージャの判断により優先度がつけられ、バックログに積まれました。
次スプリント以降優先度に応じて対応される予定です。
今日も MMP は大量のレコードを連携先サービスから取り込んでいます。
Discussion