Cloud Run × Event-Driven Architecture の並列分散処理によるデータ処理高速化への取り組み
この記事は、Magic Moment Advent Calendar 2023 5日目の記事です。
こんにちは!
Magic Moment で Tech Lead をやっている Miyake です。
弊社のセールスオペレーションクラウド「Magic Moment Playbook」では、大量の営業データに対してバッチ処理を行うシーンがあります。
今回はバッチ処理の高速化について、Cloud Run と Event-Driven Architecture を活用したアーキテクチャで取り組んだときのお話をしたいと思います。
実装した背景
リアーキテクト以前では、課題が大きく2つありました。
- 処理速度が単純に遅い
- リソースの枯渇によるパフォーマンスの低下
「1. 処理速度が単純に遅い」に関しては、システムの製品価値として解決が必要なものでした。旧アーキテクチャでは対象のデータに対して1レコードずつ直列にループを回して処理をしていたこともあり、速度パフォーマンスという点では課題がありました。
「2. リソースの枯渇によるパフォーマンスの低下」については、扱うデータ量に対して CPU やメモリといったリソースが足らず、処理パフォーマンスが低下してしまうという、よくあるシステム課題です。
弊社プロダクトは GKE を中心にサービスを提供しており、バッチ処理もクラスタ内のコンテナサービスの1つとしてデプロイされていることも多く、本テーマの処理系も例外ではありませんでした。
GKE 上のコンテナプロセスですとバッチ処理のようなプロセスのリソース最適化が難しく、同じノード内の他のマイクロサービスにも影響が出てしまう危険性があるため、解決したいと考えていました。
特にメモリに関しては OOM によるプロセスの停止なども発生するので注意が必要でした。
アーキテクチャ
先に上げた課題を解決すべく、新アーキテクチャではシステムを構成するインフラからすべて見直し、Cloud Run をベースとした Event-Driven Architecture (EDA) で構成することに決めました。
アーキテクチャ図は以下となります。
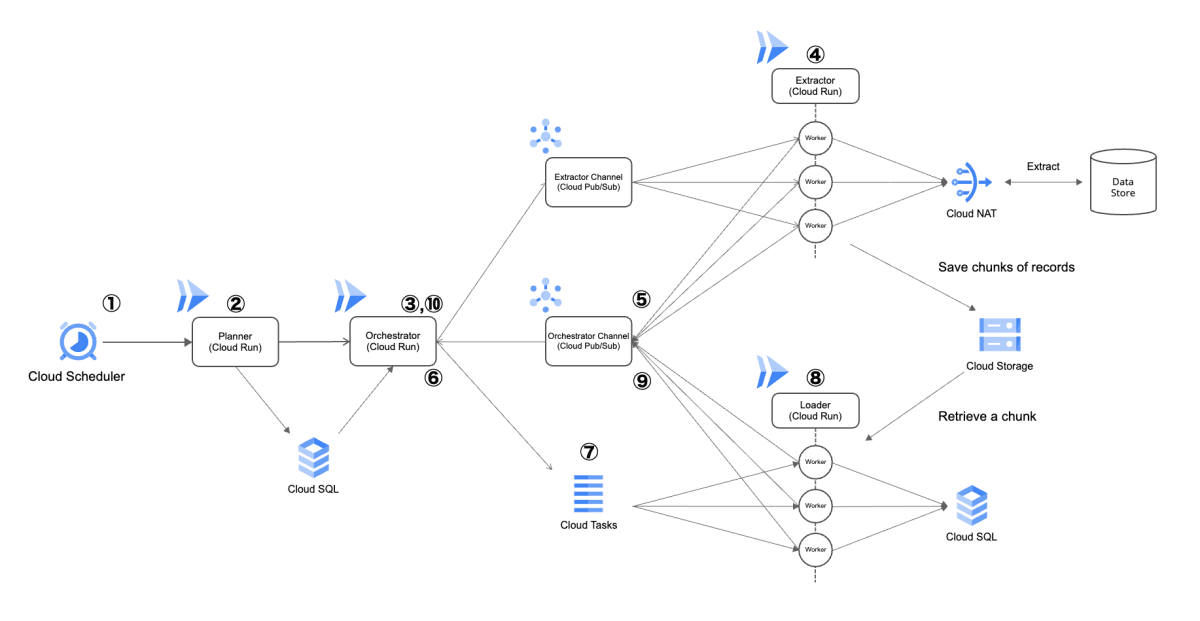
課題に対するアプローチとして、Cloud Run を活用することにより、データサイズに応じた必要なコンピューティングリソースをオンデマンドで確保。そしてデータソースから取得したデータを分割し、EDA でコントロールした複数プロセスで並列に処理することで速度パフォーマンスを向上させる。
このような分散処理システムを、弊社の内部バッチ処理における「並列分散処理」と呼んでいます。
工夫した点など、いくつかのポイントをピックアップして話したいと思います。
- プロセス分割により資源効率性と保守性が向上
- オブザーバビリティを意識して Cloud Trace を Open Telemetry で導入
- Cloud Tasks を活用した負荷対策
1. プロセス分割により資源効率性とコードの保守性が向上
旧アーキテクチャでは1プロセスで行っていたバッチ処理処理でしたが、それを各処理フェーズで分割し別々の Cloud Run サービスにしました。
各処理フェーズでは扱うデータサイズや処理内容が全く異なります。処理を分割することでリソース配分やそのスケール設定などの最適化をでき、オンデマンドでサーバレスに水平スケールをしてくれる Cloud Run のメリットを活用できました
また処理ロジックやアクセスするインフラリソースなども異なる点から、サービス分割することでコードの保守性が向上し、インフラの構成設定も各サービスごとに必要なものだけのシンプルな形にできました。
具体的には、データソースからデータを取得する処理フェーズを独立したサービスとすることで、データソースへのアクセス系の処理コードや Cloud NAT への接続設定をそのサービスでの管理に限定できる、といった具合です。
以上のような、システムの凝集性や資源効率性といった観点を考えた際に、オンデマンドでスケールする Cloud Run と EDA の構成は相性が良く、オンライン処理ではない今回のようなケースにフィットするなと感じました。
2. オブザーバビリティを意識して Cloud Trace を Open Telemetry で導入
分散システムにリアーキテクトする上で、エラー時のデバッグ容易性は設計時から考えていました。
そのためオブザーバビリティツールの導入を実施し、具体的には Cloud Trace を Open Telemetry で実装しました。
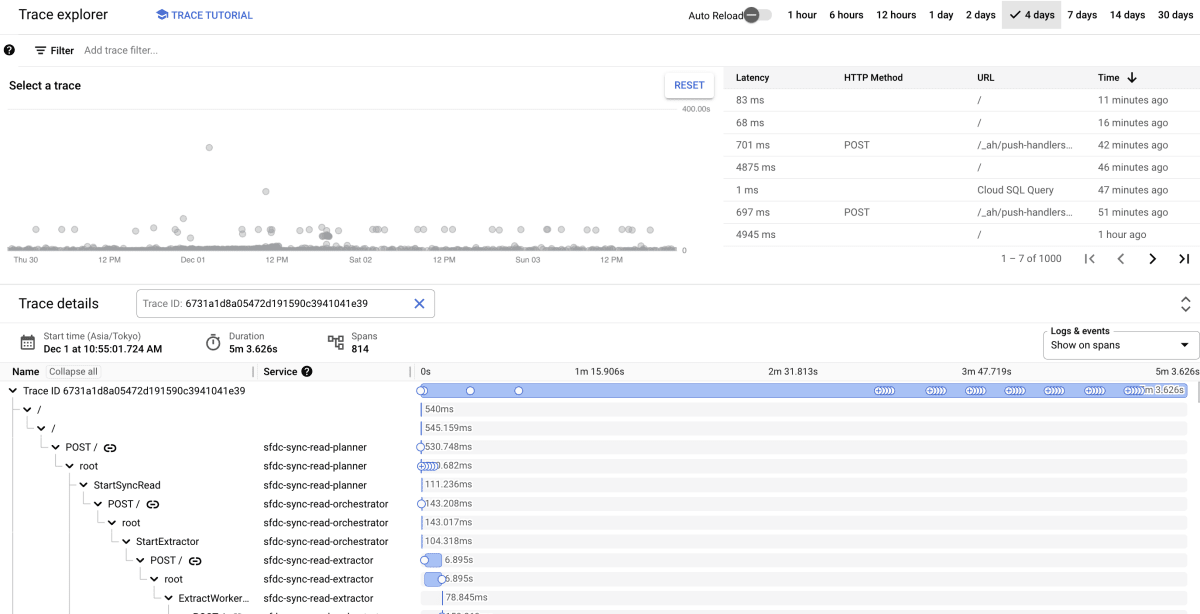
ただ Cloud Trace を導入するだけでなく、トレースデータを一連の処理内で伝搬させログに出すようにもしており、異常時のデバッガビリティはかなり意識しました。
Cloud Trace を採用した理由としては、単純に Google Cloud 内で完結しているシステムにはおいては導入が簡単だったからです。当時ちょうどオブザーバビリティツールの導入を検討している時期でしたがリリースには間に合いそうもなかったので、Open Telemetry で実装することにより、将来的な移行性を担保しようという考えでした。
※現在では Datadog をシステム全体で導入しているので、そちらへの移行を計画しています。
3. Cloud Tasks を活用した負荷対策
並列分散処理により速度パフォーマンスの改善は実現できましたが、無制限に水平スケールしてしまうと保存先のデータベース負荷が限界に達してしまいます。
そのため処理系の中に Cloud Tasks を導入し、流入制限を実装しました。
Cloud Tasks の流入制限により、予期せぬ大量データのバッチ処理が発生した場合でも、安全水準なシステム負荷を維持できています。
苦労した点
並列分散処理を実装〜リリースするにあたり、大変だったことをお話します。
既存のマイクロサービスとの通信
弊社プロダクトのシステムはマイクロサービスアーキテクチャで構成されており、今回の並列分散処理系からもメインシステム側の一部サービスへ通信する必要がありました。
その際に Cloud Run から GKE のサービスへ gRPC で通信をしなければならないのですが、GKE側の gRPC サービスは外部に公開されていないため、通信可能な構成にする必要がありました。
セキュリティの観点から Google Cloud Internal な通信を実現したかったので、調査を経て、内部ロードバランサーとサーバーレスVPCアクセスコネクタを用いて実装することにしました。
しかし gRPC での通信については情報が少なく、この点に苦労しました。結果的には GKE Internal Ingress と Nginx のリバースプロキシの組み合わせで実現できましたが、実装の過程で証明書の適用だったり Nginx の設定など、細かい仕様調査やネットワーク層のエラーにぶつかり、色々と大変でした。
ネットワーク層の調査は難しいなと思うと同時に、Cloud Run や GKE の仕様を勉強する良い機会となりました。
非機能要件の検証
今回のリーアキテクトプロジェクトでは、パフォーマンス改善がゴールだったので、その点の検証はかなり時間を取って行いました。一口にパフォーマンスといっても、速度だけでなくリソースの効率性も含まれます。また大量データを処理する上で外せなかったのがストレステストなどです。
具体的な観点としては以下のようなものです。
- 速度性能
- e.g. 20万件のデータ処理が1時間以内に完了するか
- 資源効率性
- Cloud Run の適切なリソース設定を見るために実施
- 可用性・負荷耐性
- GKE の Pod や Node のスケールが適切に作動するか
- データベース負荷が安全水準を保てるか
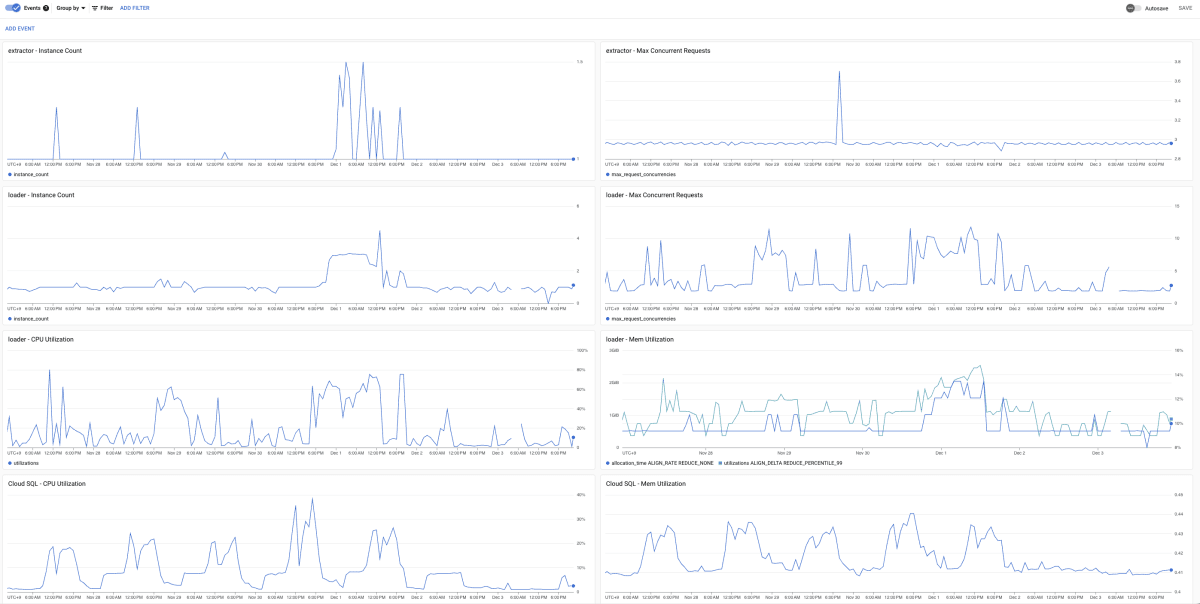
実施の際には、GKE 側のサービスの HPA や resource の設定を変化させたり、Cloud Profiler[1] を導入したりして、細かいパフォーマンスや挙動の検証などを行ったりしました。
計測については関連するメトリクスを Cloud Monitoring で1つのダッシュボードにまとめ、数値の推移や変化の相関などが分析しやすいように工夫しました。
リアーキテクトの効果
並列分散処理の実装により、データ処理速度に関して劇的な改善を実現できました。
具体的には、以下のような成果です。
- 2時間以上かかっていた3万件の処理処理が、10分以内に完了
- 24時間以上かかる見込みだった数十万件の夜間バッチ処理が、1時間以内に完了
営業データのメンテナンスは弊社プロダクトにおいて重要なポイントですので、それに貢献できて良かったです。
最後に
今回のリアーキテクトプロジェクトを通じて、アーキテクトの仕事の楽しさを知りました。
難しい顧客要求の実現と高いプロダクト品質を両立させるためには、高いビジネス理解、幅広い技術知識や経験、高い発想力などが求められます。アーキテクトはまさにその役割を根幹を担う職種であり、それに対して自分はまだまだ至らない点が多々ありますが、その一歩目を経験できたという意味で自身にとっても重要なプロジェクトでした。
プロダクト全体において課題は尽きないので、お客様により良い価値を届けるためにどうすればよいかを常に考え続け、ドメイン理解・技術理解を常に深めていきたいと思います。
明日のアドベントカレンダーは 清家 さんの「スクラムマスターのいないスクラムチームへの挑戦」です。
-
Cloud Profiler については私が書いた「Cloud Profilerを導入してパフォーマンス改善をした話」という記事があるので、よろしければご参照ください。 ↩︎
Discussion