※この記事はLuup Advent Calendarの7日目の記事です。
こんにちは、Luupの松本です。
今日は、機械学習のちょっと変わった使い方について、Luupでの実例を用いて簡易に紹介します。機械学習というと、モデリングをして予測結果を出し、それを活用して初めて価値が出ると言われることがあります。基本的に多くのケースでその認識は正しいのですが、機械学習の副産物を活用することにより、予測結果を活用することなくかつ容易にビジネス上の価値を出せることがあります。機械学習の基礎を少し理解していることが前提になりますが、それ以上の深い知識は必要ありません。
機械学習を使ったインサイトの抽出とは?
この度紹介する機械学習を使った方法論は、以下の2つです。機械学習には、複雑な変数が絡み合った現象を容易に扱えるなどの利点があるため、それを活用してインサイトを抽出することにしました。
- 特徴量の重要性
- 特徴量の部分依存
これらは本来的には、機械学習のモデルの精度をあげる方法を模索したり、よくあるトラップに陥っていないかチェックするために使われる方法論です。しかし、これらは両方とも学習済みのモデルがどのように学習したかを可視化する方法であり、上手く活用することでどのような特徴量が予測にどう寄与しているかのインサイトを抽出できます。なお、得られる結果はモデルや特徴量の組み合わせなどにより変わる点に注意ください。また方法論として頑健ではなく、あくまでインサイトが得られる程度のものとご認識ください。
上記の方法論を、Luupが保有するデータおよび公開されているデータを用いて、どのような要素がライド数の増加にどれくらい寄与しているかを検証するプロジェクトを事例として考えます。実際に行ったプロジェクトからは一部改変しておりますが、実際の分析がモデルになっています。
今回は紹介しませんが、近い方法を用いて、どのような要素がポートの価値向上に寄与しているかを調べたこともあり、応用範囲が広いものとなっています。
前準備
上記2つの方法論を利用するためには、モデリングまで終了しておく必要があります。まずターゲットとなるエリアごとのライド数を抽出し、それを予測するための特徴量を選定します。特徴量としては、内部データとしてのポート密度や車両の数、気温などの外部データを抽出して、pandasのDataFrameに格納します。今回の分析の目的は、予測精度を上げることではなくインサイトを得ることなので、特徴量同士で一定程度相関があるものやライド数の変化が結果のみならず原因になるものなどは、できるだけ排除しています。
これらの特徴量を活用してどうモデリングをするかは今回の主眼ではないので、特徴量の正規化やエンジニアリング・アルゴリズムなどの説明は割愛します。モデルに関して、ここでは、scikit-learnのGradientBoostingRegressorを用います。
特徴量の重要性
特徴量の重要性とは、その名の通り、モデリングにあたり、どの特徴量がどれくらい重要であったかを示す指標です。ここで活用したGradientBoostingRegressorは決定木系のモデルであり(*)、その学習過程でどの特徴量で分割するのが最適かを検討しているため、その情報をそのまま利用して、特徴量の重要性を表現できます。
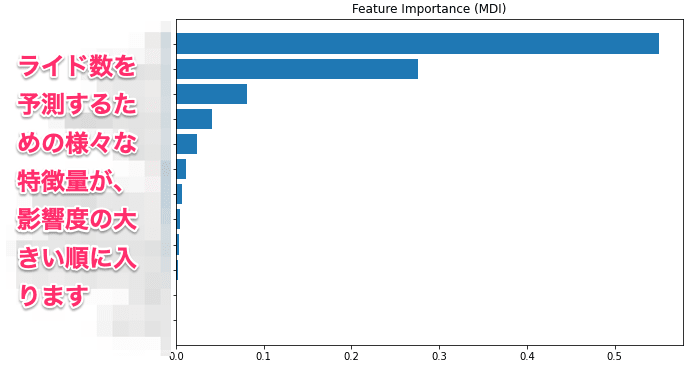
残念ながらここでは具体的な特徴量はお見せできませんが、特徴量が重要な順番で表示されます。
(*)今回はGradientBoostingRegressorを利用して学習していますが、scikit-learnにある決定木系の学習器であれば(例えば、RandomForestRegressorなど)も基本的に利用できます。回帰に限らず、分類でも利用可能です。
この可視化に利用したサンプルコードは以下のとおりです。
import matplotlib.pyplot as plt
# 前提
# regという変数名で、fit済みのscikit-learn学習器が格納されている
# df_dataという変数名で、fitに利用された前処理済みのdataframeが存在する
feature_importance = reg.feature_importances_
sorted_idx = np.argsort(feature_importance)
pos = np.arange(feature_importance.shape[0])
fig = plt.figure(figsize=(20, 6))
plt.subplot(1, 2, 1)
plt.barh(pos, feature_importance[sorted_idx])
plt.yticks(pos, np.array(df_data.columns)[sorted_idx])
plt.title("Feature Importance (MDI)")
なお、本来的にこの方法論の役割としては、データのリークがないかチェックしたり、特徴量を追加・変更してみて学習がどのように変更するか確認したりすることです。
決定木系ではないモデルでは、permutation importanceが利用できます。特定の特徴量をランダムにシャッフルすることで精度がどれくらい落ちるかという観点で特徴量の重要性を計算しており、モデルに依存しないことに加え、計算方法が直感的でわかりやすいというメリットがあります。scikit-learnでも標準実装されておりますので、興味ある方はトライしてみてください。
特徴量の部分依存
特徴量の部分依存とは、学習済みのモデルにおいて、反実仮想的に特定の特徴量だけを色々いじってみた場合に、予測値がどのように変化するかみることです。アルゴリズムに依存せず、理論上どんな場面でも使えるのがこの方法論の強みです。ポート密度に関する指標でみてみましょう。ポート密度だけを仮に変化させてみるとどうなるかみれます。青が個別のデータに関しての部分依存で、それを平均したものが赤い線です。縦軸の絶対的な数字には特に意味はないので、ここではその変化に注目してください。
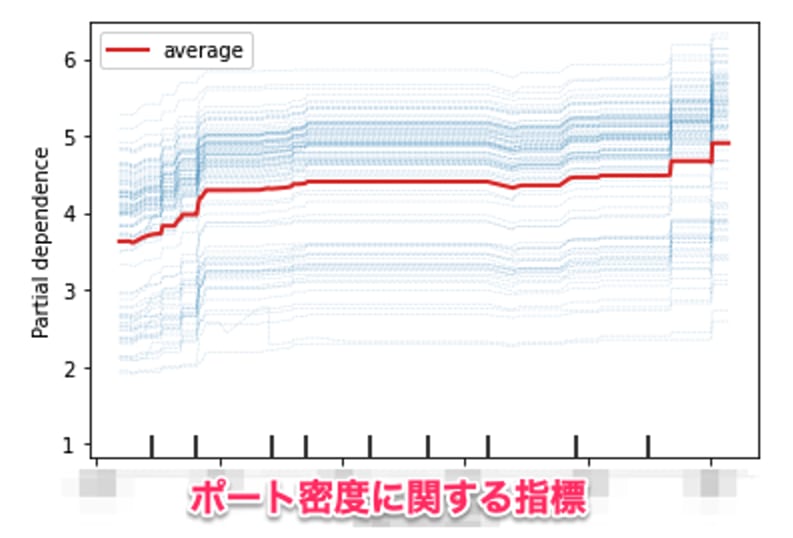
- ポート密度が増えたときに、ライド数がどっと増えている箇所が見受けられると思います。これは別の分析からも確認されているのですが、密度が増えると線形以上にライドが増えることがあり、ポートモデルにおける密度の重要性を物語っています。
- 一方、ポート密度が増えたとき、部分依存が減少しているところが見られます。(ポート同士の共喰いにより車両が分散したことに伴う減少なども考えられますが)ポート密度が増えると通常はライドは増えこそすれ、減らないと考えるのが自然でしょう。その点では、このモデルは一部の箇所で正しく学習できておらず修正が必要かもしれません(部分依存の方法論が、もともとはこのようにモデルの改善に利用されています)。
なお、ポート密度に関する指標を横軸、ライド数を縦軸にしても同じようなデータが得られるから、わざわざ機械学習使わなくてもいいのでは?と考える方もいるでしょう。しかし、その場合ポート密度以外、例えば車両の数なども同時に変動しており、ピュアにポート密度だけの効果をみれていないのです。もちろん、特徴量の部分依存を使っても、様々な理由により、純粋なポート密度だけの効果だけを現実的に抽出できているわけではありませんが、よりそれを実現しようとするアプローチだと理解してもらえると良いかと思います。
こちらが特徴量の部分依存の可視化に利用したサンプルコードです。
from sklearn.inspection import PartialDependenceDisplay
def partial_dependency(feature_list):
output = []
for feature in feature_list:
partial_dependency = PartialDependenceDisplay.from_estimator(
reg,
df_data,
[feature],
kind="both",
subsample=100,
n_jobs=-1,
random_state=0,
ice_lines_kw={"color": "tab:blue", "alpha": 0.2, "linestyle": "--"},
pd_line_kw={"color": "tab:red", "linewidth": 2},
)
output.append(partial_dependency)
return output
partial_dependency(df_data.columns)
ちなみに、ポート密度に関しては、Data Scienceチームが別の記事を出していますのでご参照ください。
最後に
本日は機械学習の副産物を利用した、ちょっと面白いインサイトの抽出方法を紹介しました。簡潔な紹介にとどめたため、ここに書ききれなかった問題点や結果がmisleadingにならないための注意点など、気をつけないといけないものは様々あります。ご興味が湧いた方はぜひ色々調べていただくと、更なる面白い発見があると思います。
また、Luupでは様々な職種で積極的に採用を行なっております。ぜひLuup採用情報を覗いてみてください。

Discussion