こちらの記事は、LUUP のTVCM放映に合わせた一足早い「Luup Developers Advent Calendar 2024」の15日目の記事です。
はじめに
こんにちは。Data Groupの小林(@mizkino) です。
Luupにおけるデータ活用とそれを支えるデータ基盤についてお話しします。
近年、多くの企業でデータの信頼性をいかに担保するかが大きなトピックとなっています。
データの収集から加工、分析、そして意思決定への活用まで、各フェーズでの品質管理の重要性が認識され、様々な取り組みが行われています。
Luupも例外ではなく、データパイプラインにおける品質管理の仕組みを整備してきました。
特にデータの収集から加工までの品質担保については、データチームの河野の発表「Data Reliabilityを最小工数で実現するためのデータ基盤」でご紹介したものなどがあります。
また、現在のデータ基盤のアーキテクチャに関しては、4日目の記事の中で河野が触れていますので、合わせてご覧ください。
新BIツール「Superset」を導入した話
このように、データ基盤の信頼性の担保について様々な場で語られるようになりましたが、もちろんデータ活用フェーズにおける品質管理も重要です。
本記事では、Luupがデータ活用フェーズの品質管理のために取り組んできた施策についてご紹介します。具体的には、タスク管理の統合、コードレビュープロセスの確立、データ利用ガイドラインの整備など、実践的な取り組みとその効果についてお話しさせていただきます。
現状どのようなデータ基盤を持っているのか、どのような課題があるのか、それを解決するためにどのような施策を進めているのか、をご紹介します。
抱えていた課題感
私がLuupに入社したのは1年ほど前ですが、その時のデータ組織において以下のような課題があることに気づきました。
- サイエンスや分析系依頼の管理がSlackをベースに行われており、ストックされていない
- データサイエンスチームとエンジニアリングチームでタスク管理が別々になっている
- 依頼対応のSQLやスクリプトが点在しており、管理が煩雑
- データ利用や提供のルールが明文化されていない
といった課題がありました。
元々が少数精鋭でやってきた組織であったため、それぞれの能力の高さでカバーしてきた部分もあり、それまではさほど問題になっていなかったと思いますが、今後のスケールアップに向けては、これらの課題を解決していく必要があると感じました。
ここから、それぞれの課題に対してどのような施策を進めてきたのか、その効果についてご紹介します。
取り組み
タスク管理の改善
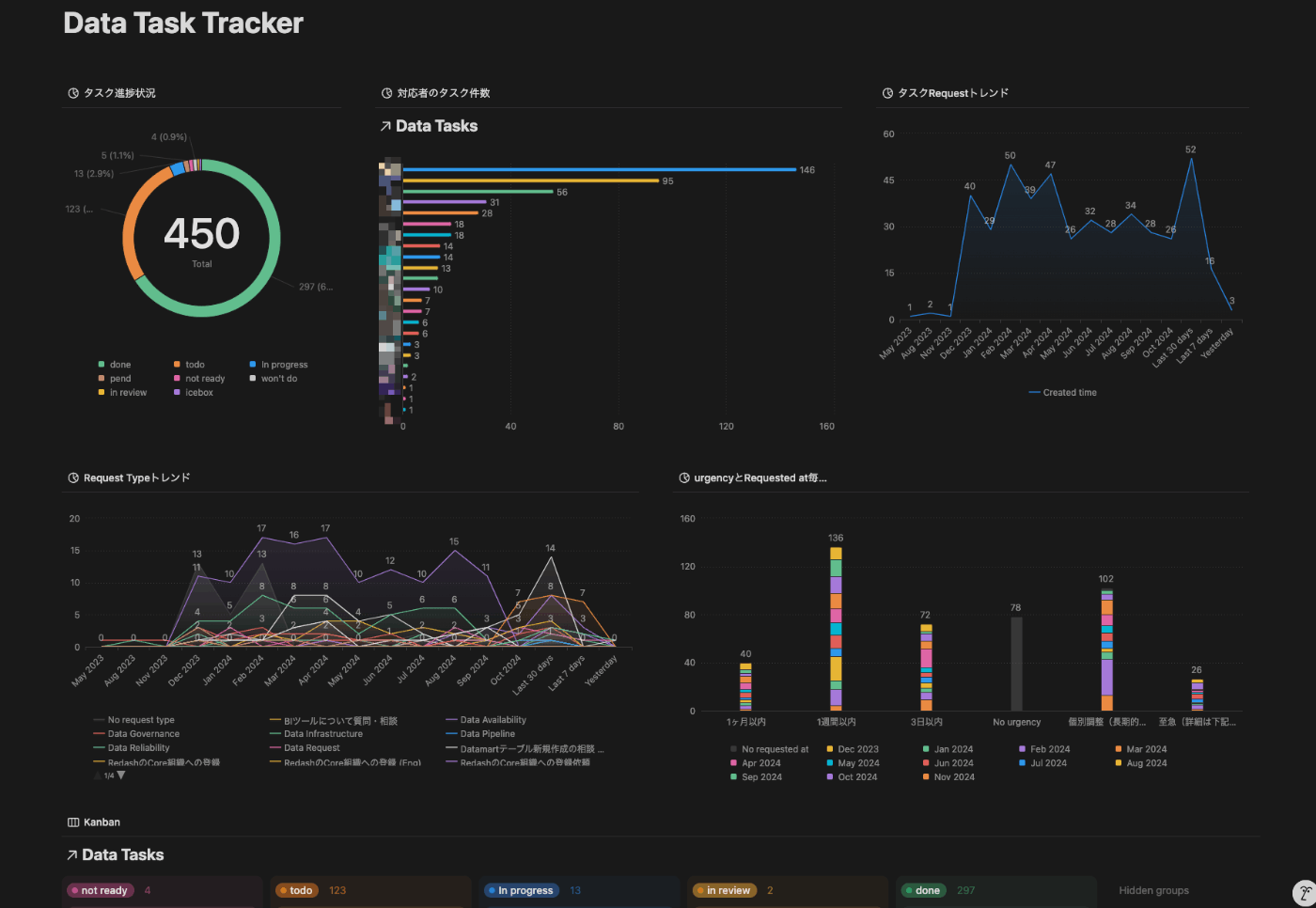
まず、サイエンスや分析系依頼の管理をストックして管理するために、Slackをベースに行われていたタスク管理をNotionに移行しました。
Notionの利用により、タスクのストックと過去の分析や課題の解決策の参照が容易になりました。
SlackからNotionのdbへの直接的なアイテム作成ができなかったため、一度SlackからSpreadsheetを経由して移行する方法を取りました。
Notionでは、タスクの状況や担当者、期限などを管理し、進捗状況の可視化を実現しました。
また、データエンジニアリングチームでは元々Notionでタスク管理をしていましたが、サイエンス側で利用したい粒度や項目とは異なっていたため、それらを統合するための取り組みを進めています。(統合中)
GitHub管理の導入
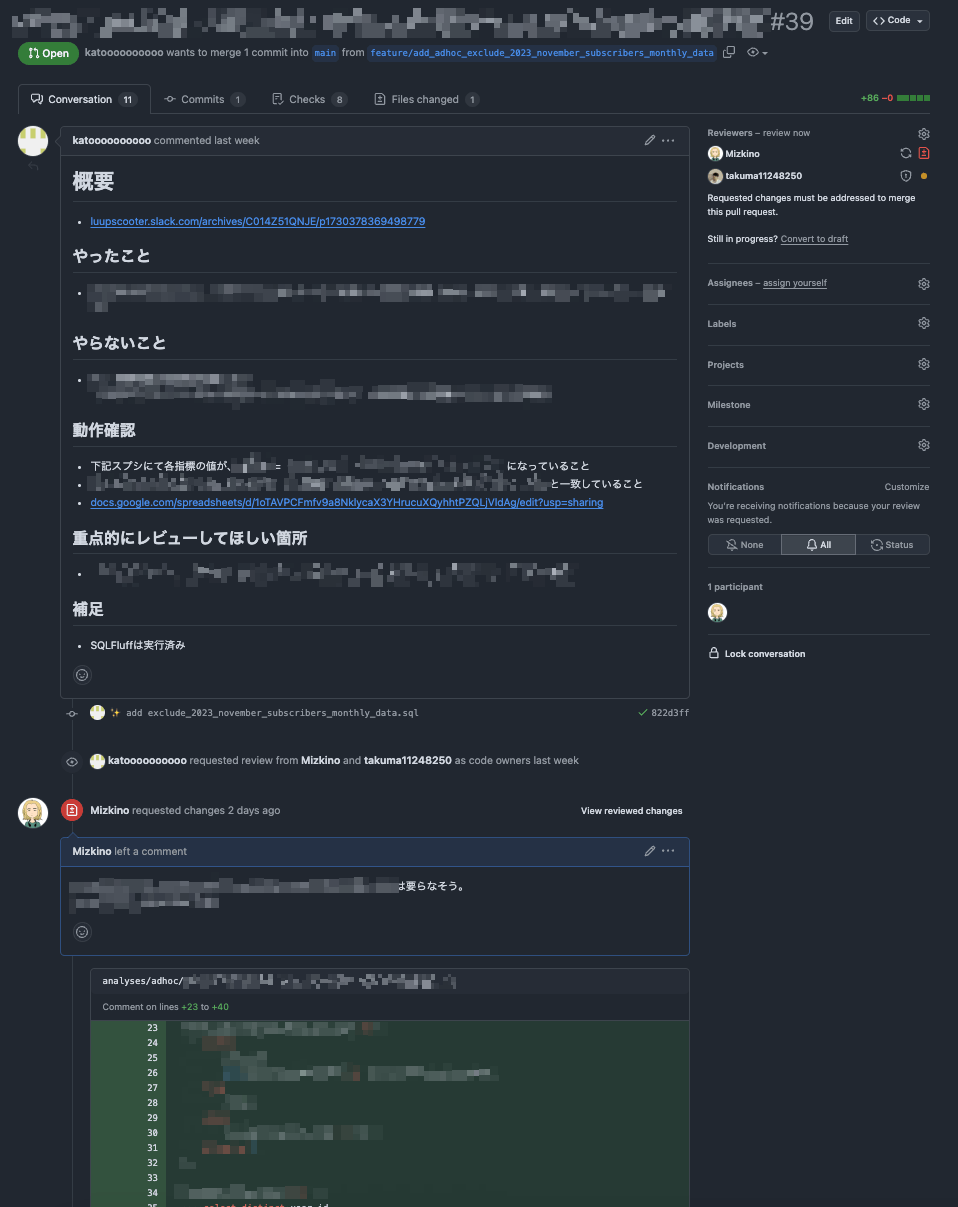
次に、依頼対応のSQLやスクリプトの管理をGitHubに移行しました。
これまでは、個々のメンバーがそれぞれのGoogleDriveやNotionのページにスクリプトを保存し、依頼対応のSQLはRedashのクエリとして保存していました。
これらをGitHubに統合することで一元管理を実現し、過去のスクリプトやSQLの参照が容易になりました。さらに、コードのレビュープロセスも確立しました。
Apps Scriptの管理
また、Apps Scriptを利用していた部分は、claspを利用してGitHubに移行しました。
claspは、Apps Scriptをローカルで開発するためのツールです。
claspの導入により、ローカルでの開発が可能になり、開発環境の構築やテストも容易になりました。
現在の標準の構成は以下のようになっています。
.
├── src # スクリプトのソースコード
│ ├── appsscript.json # GASの設定ファイル
│ └── some_code.js # GASのスクリプト
├── README.md
├── clasp.json # claspの設定ファイル(symlink)
├── clasp.prod.json # prod環境の設定ファイル
├── clasp.dev.json # dev環境の設定ファイル
└── Makefile # makeコマンドを使ってスクリプトを管理するためのファイル
claspだけで記事が一本書けそうなのですが、今回は本題ではないので詳細は割愛します。
SQLの管理
依頼対応のSQLについても、GitHubに移行しました。
元々は単発の簡易な依頼対応は、Redashで素早く作成して共有する形で行われていました。しかし、似た条件の依頼を別の作業者が担当した場合、少しずつ定義の異なるRedashが増えていました。また、複雑な依頼や追加対応で複数人での作業が必要な場合には、編集履歴が見られず、変更点の把握やバグの原因特定が困難でした。
これを解決するために、依頼対応のSQLもGitHubで管理し、レビューを通すフローを設けました。
データ活用促進のために、コアとなる部分を作成するものと、活用に着目したテーブル群を作成するものの2つにdbtのプロジェクトを分けていて、後者はアナリストが使いやすいように様々な仕組みの構築を進めています。
すでにアナリスト用のdbt環境を導入しているため、依頼対応のSQLもdbt上のanalysesで管理することにしました。
dbtのanalysesを利用することで、実テーブルを作成せずmodel側の環境を保護しつつ、jinjaテンプレートやdbtのmacroなどの便利機能を活用しながらSQLを記述できます。
データ利用ガイドラインの整備
最後に、データ利用ガイドラインの整備についてです。
実はこれはまだ途中ですが、データ利用者やデータ提供者が従うべきルールを明文化したものを作成しています。

具体的には、データ利用者や提供先ごとにどこまで匿名化するか(k - 匿名性や i - 多様性の基準など)を定義しました。これにより相手の種別に応じた適切な匿名化手法を選択でき、判断の属人性を排除しています。
また、数値の定義や単位、データ提供時のフォーマットに関してもガイドラインを整備しています。これによりデータ作成時の無駄な判断やブレを防ぎ、品質の向上を図っています。
さらに、データへのアクセス権限についても明確なルールを設定し、セキュリティとプライバシーの観点からも適切なデータ利用を促進しています。これにより、必要な人が必要なデータにアクセスできる環境を維持しながら、データの安全性も確保しています。
まとめ
これらの取り組みにより、一定のデータ活用における品質の担保は達成できましたが、まだまだ改善の余地があると感じています。
今回ご紹介した施策を基盤としつつ、より良いデータ活用の実現に向けて改善を重ねていきたいと考えています。
今後は、ガイドラインの継続的な改善や、データ分析や効果測定のフォーマット化などを進めながら、組織全体のデータ活用能力の向上を目指していきます。
おわりに
Luupのデータ組織で一緒に働くメンバーを募集しています。
機械学習や最適化、データ基盤構築、データ活用に興味がある方、ぜひ一度お話ししましょう。
よろしくお願いします。

Discussion