こんにちは。Data Engineeringチームの河野(@matako1124) です!
今年のData Engineering業務としてデータマネジメントからデータ活用促進の仕組み化まで幅広く活動してきましたが、その中でも特に事業にインパクトの大きい変革のお話をしていこうと思います。
結論から言うと、Supersetの新規導入とRedashからの乗り換えを試みています。
注意
- 執筆に当たり細心の注意を払っておりますが、不十分な説明や誤りがある可能性もございます。
- 記事内で紹介しているコードは部分的なものです。参考程度にご参照ください。
目次
- 2024年時点でのLuupのデータ基盤のご紹介
- 現状の課題
- Superset導入の目的と理由
- 構築事例
- Superset推し機能
- Superset改善したい機能
- まとめ、今後の施策
- 終わりに
2024年時点でのLuupのデータ基盤のご紹介
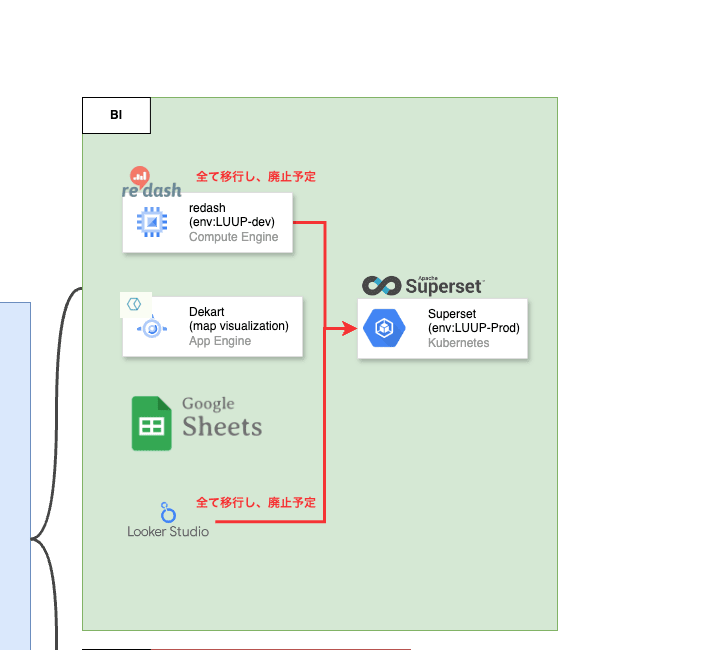
本編に入る前に、現時点でのLuupのデータ基盤について簡単にご紹介します。
図にすると、以下のようなイメージです。
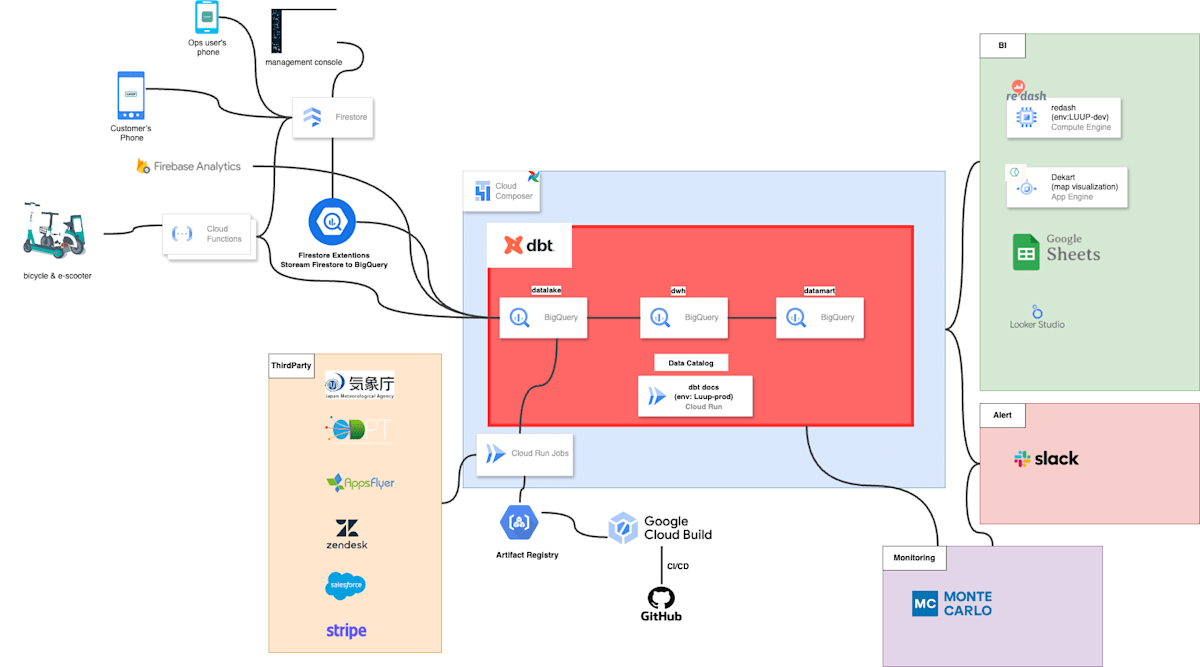
直近で大きく変更を加えた箇所はなく、ポイントとしては以下になります。
- 各種アプリデータはFirestoreからBigQueryへ
- 車両データはFunctionsからPubSubを経由して、BigQueryへ
- 各種ThirdPartyデータの取得はCloud run jobsでmodule化し、Cloud Composer(Airflow)からキックする
- オーケストレーションツールはCloud Composer(Airflow)を使用し、dbtでモデルの作成と管理を担う
- データ監視にはMonteCarloを使用し、BigQuery上におかしなデータがないか監視させる
- データの可視化にはRedashを中心としつつ、Spreadsheet、MapVisualizationツール Dekart、一部 Looker Studioを使用
今回はデータ基盤のお話ではないので、細かい設計・実装話は割愛させていただきますが、現状上記のデータ基盤を使い、データ活用を促進していくためには、活用面で大きな課題があります。
現状の課題
上記でお話させていただいたとおり、現状のデータ基盤は、Airflow、dbt、MonteCarlo等をうまく組み合わせることで、ある程度信頼性の担保されたデータを少ない運用工数で活用者に提供することができるようになっています。ただ、活用面を見ると大きな課題を残しています。
それは、データ抽出にSQLが必須であることです。Redashは基本、SQLを書いてデータを抽出し、Dashboardを作っていくツールであるため、SQLを書けないメンバーはデータチームもしくはSQLをかけるメンバーに依頼しないといけません。
これまではデータチームが依頼ベースで対応することでなんとかなっていましたが、人が増えてくるとそうはいきません。
データチームの工数の多くをデータ抽出にかけてしまうと、データアナリストが本質的に取り組むべき分析やビジネス支援、データエンジニアが本質的に取り組むべきデータパイプライン、データマネジメント、データプロダクト開発等に時間を割けなくなってしまいます。
また、他にもRedashには、以下のような課題が発生しています。
- BigQueryの全てのデータセットにアクセスできてしまい、Rawデータから参照しているクエリも多数存在しており、野良クエリも多く、どのQuery、Dashboardが正しいものなのかわからない
- Semantic Layer Toolとの互換性がない
- インフラ管理ができておらず、OOMが頻発している
- 位置情報データの可視化ができない
社内でSQLをかける人を増やして、定義を決めて、このクエリで出すようにしましょうと啓蒙することもできますが、全員がSQLをかけるようになれるわけでもなく、他部署の方はやるべきタスクが多い状況の中で、SQLの勉強をして自分で抽出するというのは中々厳しいものだと思います。(もちろんある程度の啓蒙活動は仕組み化を進めていった後も必要ですが)
そこで登場するのがSupersetです。
Superset導入の目的と理由
Superset導入の目的は、データ活用の促進であり、SQLに依存したデータ抽出、BIツールでの正しいデータがどれかわからない、位置情報データの可視化ができない等、活用側の課題を全て仕組み化で解消することです。
ただ、上記課題は他のBIツールでも解決できるのではないかと思われる方もいらっしゃるかと思います。
例えば、SQLに依存せず、データの整合性を担保した上で可視化したいのであれば、LightdashやSteepが検討枠に入ります。またお金がある程度あるならtableauでもいいでしょう。
なぜ、Supersetの導入に決めたのかというと、コストをかけず上記課題の全てを解決できることにプラスして、位置情報データを一緒にダッシュボード化できること が決断の決め手です。
Luupでは位置情報データの分析を行う機会が多く、今ではDekartでアドホック的に行うことがほとんどですが、DekartにはDashboardの機能が存在しません。
従って、数値データと一つの画面でMapVisualizationを表現するといったことができないので、別の画面のRedashと行き来して分析せざるを得ない状況になっています。
Supersetでは、以下のサンプルダッシュボードのようにMapVisualizationと一緒にテーブルやグラフを一つの画面で見ることができ、自動更新もできるようになります。
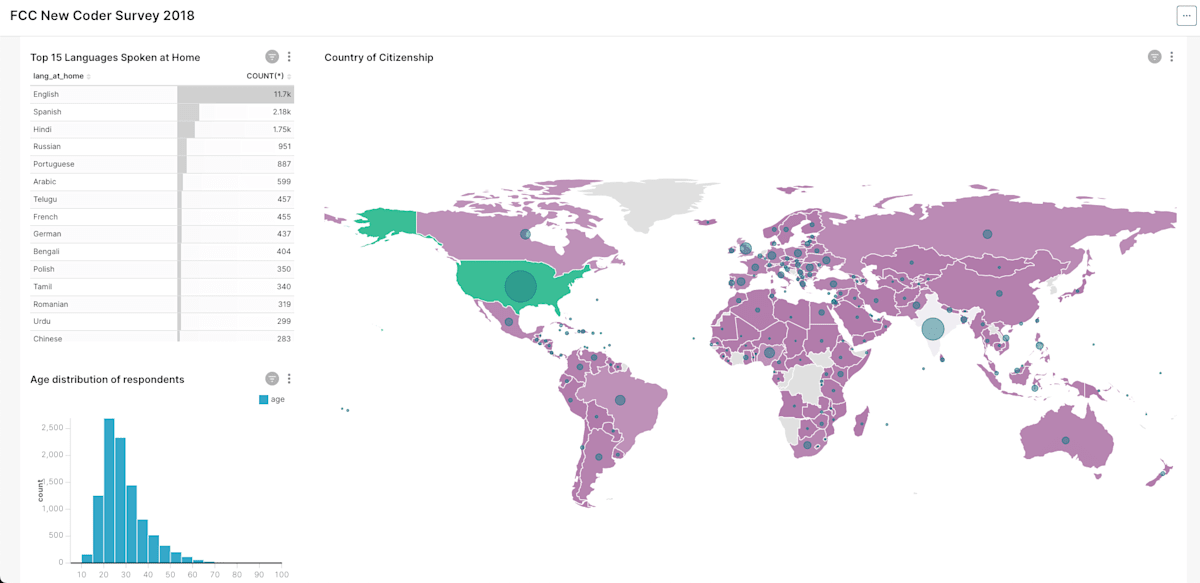
なお、以下リンクから公式でサンプルを提供してくれています(Versionは古いです)。可視化表現が豊富なので、いろいろ触ってみると面白いかと思います。
エンジニアリング観点のポイントとしても、cube.jsなどのSemantic Layer Toolとの互換性がある点もポイントが高く、今後Semantic Layerを導入することでデータの質向上も図れます。
上記の点を総合的に判断して、Supersetが最適であると判断しました。
構築事例
インフラ周り
実際のインフラ構築事例をご紹介します。
Luupでは、Redash や Dekart などさまざまなOSSツールを導入しており、当時はあまり考えず、GCE上に用意したり、GAEで作ったりとツールによってさまざまな対応方法で作られていました。Redashもその影響で、現在インフラ周りが管理できておらず、活用者も増え、移行するにも影響が大きく、腰が重いといった状況になってしまっています。
さらに今後はSupersetに加え、OpenMetadataやcube.jsなど多くのOSSツールの導入を検討しています。この状況でOSSのインフラ構築を今までのように属人化対応してしまうと後々面倒なことになるのは明白です。したがって、今後はきちんとコードで管理しつつ、作る場所は統一して、属人化しないような仕組みにしようと考え、場所はGKE、リソースの管理はTerraform、k8sのmanifestはhelmでそれぞれ管理するようにしました。
以下のようなイメージです。
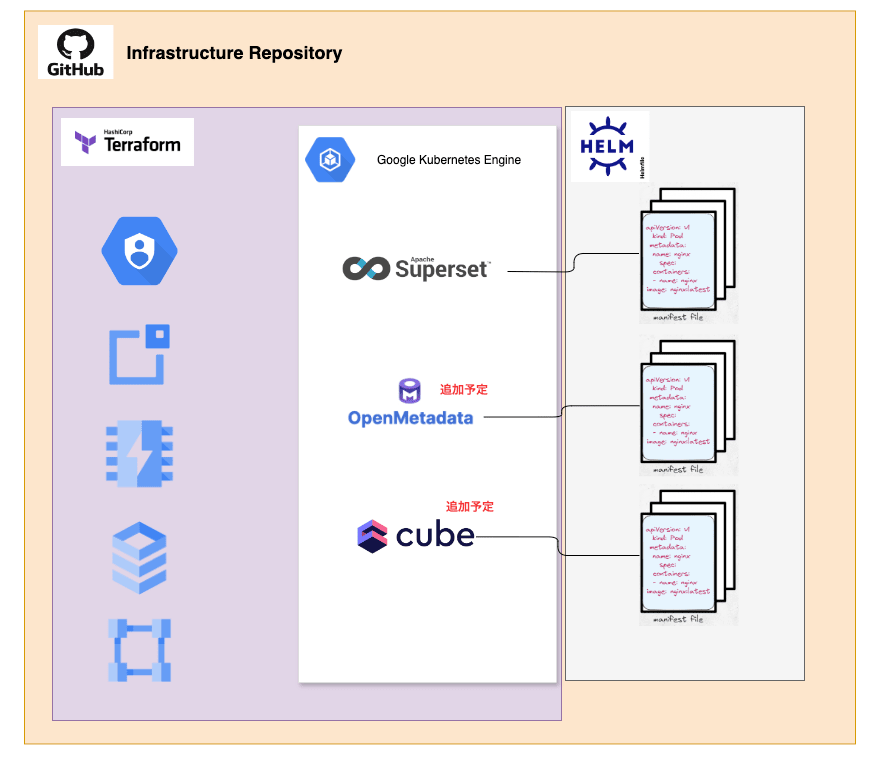
Luupでのインフラの管理はsreチームが作成・管理してくれているRepositoryがあるので、Data Engineeringチームもここに乗っからせてもらっています。
実際の構築は、公式ドキュメントがあるのでそれに沿って進めつつ、公式ドキュメントはあくまでPocまでの設定しか記載してくれていない(例えばredisやpostgresqlがpod内に作られてしまうので別だしする必要がある)ので、それぞれ本番環境で動かせるように作っていきます。
また、helmで作るのであれば公式Chartがあるので、このChartをTemplateにしてカスタムするだけで済みます。
以下に例としてコードを記載します。
- Terraform
locals {
region = "us-central1"
}
resource "google_compute_network" "data_oss_cluster_network" {
name = "data-oss-cluster-network"
...
}
resource "google_compute_subnetwork" "data_oss_cluster_subnetwork" {
name = "data-oss-cluster-subnetwork"
...
}
resource "google_compute_router" "data_oss_cluster_nat_router" {
name = "data-oss-cluster-nat-router"
region = local.region
...
}
resource "google_compute_router_nat" "data_oss_cluster_nat" {
name = "data-oss-cluster-nat"
region = local.region
...
}
resource "google_compute_global_address" "external_cloud_sql_vpc_peering_ip_alloc" {
project = var.project_id
name = "external-cloud-sql-vpc-peering-ip-alloc"
...
}
resource "google_service_networking_connection" "external_cloud_sql_private_vpc_connection" {
network = google_compute_network.data_oss_cluster_network.id
...
}
resource "google_container_cluster" "data_oss" {
name = "${var.project_id}-data-oss"
location = local.region
...
}
resource "google_redis_instance" "superset" {
name = "superset-redis"
memory_size_gb = 1
location_id = local.zone
...
}
resource "google_compute_global_address" "superset_ip" {
name = "superset-ip"
...
}
resource "google_sql_database_instance" "superset_postgres" {
region = local.region
name = "superset-postgres"
...
}
resource "google_sql_database" "superset" {
name = "superset"
...
}
- helm
helmfile.yaml
---
repositories:
- name: superset
url: http://apache.github.io/superset/
releases:
- name: superset
namespace: superset
chart: superset/superset
version: 0.12.11
values:
- values-superset.yaml.gotmpl
- name: superset-extra-manifests
namespace: superset
chart: ./superset-extra-manifests
values:
- values-superset.yaml.gotmpl
values.yaml
---
projectId: project_id
clusterName: cluster_name
clusterLocation: us-central1
superset:
...
initImage:
...
init:
createAdmin: true
...
service:
...
ingress:
enabled: true
...
serviceAccount:
...
backendConfig:
...
oauthClientCredentials:
...
mapBox:
...
slack:
...
supersetNode:
replicas:
...
autoscaling:
...
externalDatabase:
...
externalCache:
...
startupProbe:
...
livenessProbe:
...
readinessProbe:
...
resources:
...
supersetWorker:
replicas:
...
autoscaling:
...
livenessProbe:
...
resources:
...
values-superset.yaml.gotmpl
...
configOverrides:
my_override: |
FEATURE_FLAGS = {
"DASHBOARD_NATIVE_FILTERS": True,
"DASHBOARD_CROSS_FILTERS": True,
...
}
ENABLE_PROXY_FIX = True
BABEL_DEFAULT_LOCALE = "ja"
LANGUAGES = {
"ja": {"flag": "jp", "name": "Japanese"},
"en": {"flag": "us", "name": "English"}
}
enable_oauth: |
from flask_appbuilder.security.manager import (AUTH_DB, AUTH_OAUTH)
AUTH_TYPE = AUTH_OAUTH
OAUTH_PROVIDERS = [
{
"name": "google",
"icon": "fa-google",
...
}
}
]
AUTH_USER_REGISTRATION = True
AUTH_USER_REGISTRATION_ROLE = "Viewer"
...
細かい説明は長くなってしまうので、割愛させていただきますが、1点ポイントとして、Supersetの各種Option設定はconfigOverridesから行います。
ここで言語設定(英語や日本語など)やログイン認証設定(Luupではgoogle oauth認証を採用)などを行います。
権限設定
前提として、Supersetのアクセス制御はIAPを採用しており、luupドメインメンバーのみアクセス可能にしています。
このパートでは、Superset内の権限をどう定義し、メンバーにアタッチしているか説明します。
権限設定する前に、メンバーに何を付与するのかポリシーを決める必要があります。
LuupではDocumentツールにNotionを採用しているので、以下のようにNotionにポリシーを定め、社内に展開しています。
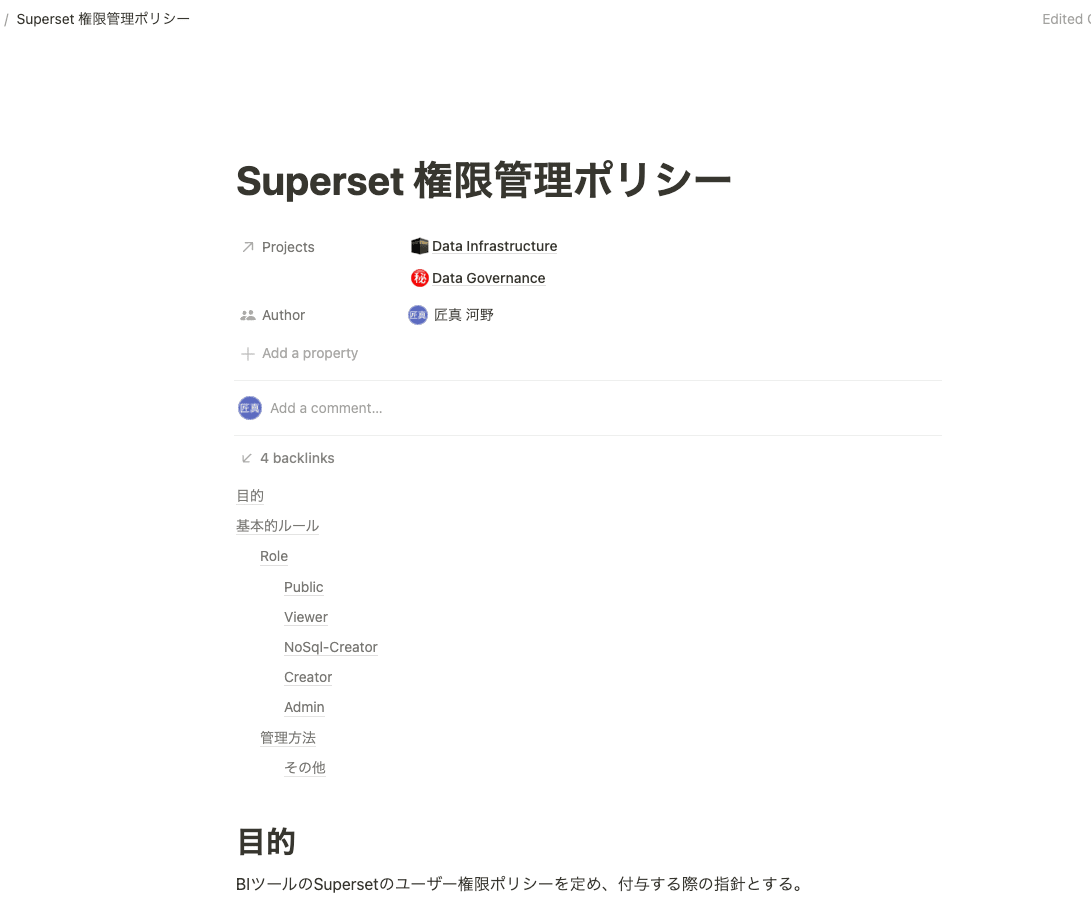
具体的なRoleですが、SupersetにはDefaultでAdmin, Alpha, Gamma, SQL_LABの4つのRoleが用意されており、カスタムロールを作ることもできるので、柔軟な権限設定が可能です。
DefaultのRoleだと、閲覧だけできるRoleやSQLはかけないが、dashboardやchartは自由に作りたいRoleなどに対応できないため、Luupでは以下の4つのカスタムロールを作成し、これにプラスDefaultのAdminを加えた5つのRoleで管理していくことにしました。
- Public: 外部公開用、社内メンバーには付与しない
- Viewer: Defaultでつく権限、閲覧者用
- NoSql-Creator: SQLは書けないが、GUIのぽちぽち操作で自分でdashboardやchartを作成する人用
- Creator: SQL書けて、自由にdataset、dashboard、chartを作成する人用
Permissionリストは以下になります。
また、上記インフラ周りのところでも触れた通り、ログインはgoogle oauth認証にしており、DefaultではViewer権限が紐付くようにしているため、新しいメンバーが入ってきた時に都度作業する必要がないようにしています。
Superset推し機能
Supersetの好きな機能を少しだけご紹介します。
GUIでのデータ抽出
SupersetはGUI操作でデータを抽出し、表現することができます。SQLに依存することなくデータ抽出ができるので、データ活用の促進を図れつつ、データチームへの抽出依頼工数削減にもつながります。
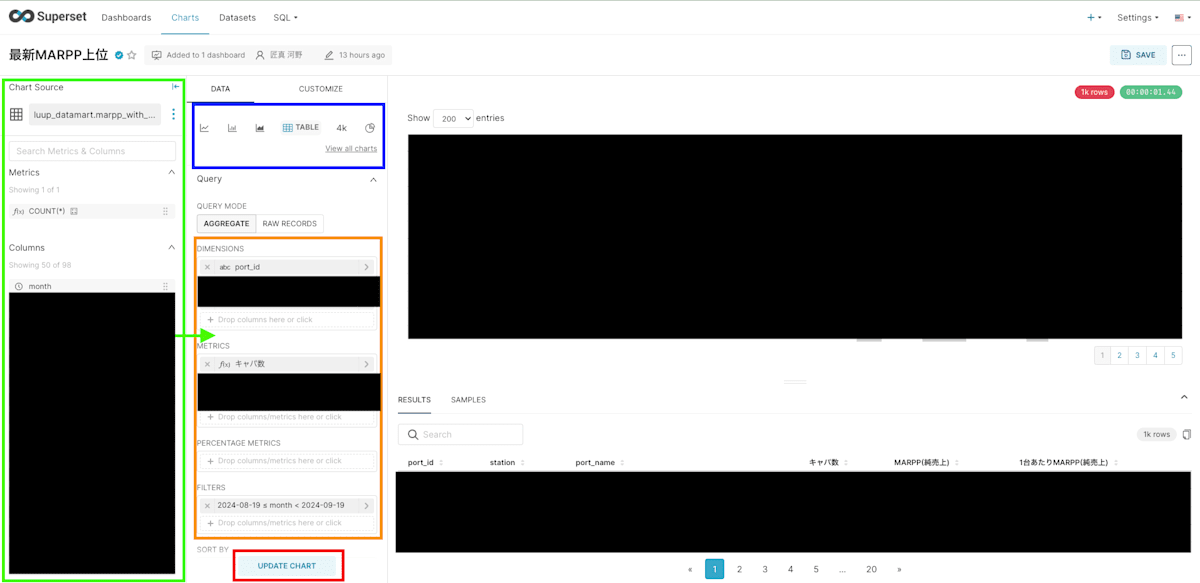
やり方は簡単で、緑枠にあるカラムを各種Dimensions・Metricsに移動させ、青枠で表現したい可視化方法を選択し、赤枠のupdate chartをクリックするだけです。
可視化表現の豊富さ
2024/10時点で可視化表現パターンは60パターン存在し、グラフ表現に加え、Box PlotやBubble Chart、MapVisualizationなど幅広い表現が可能です。
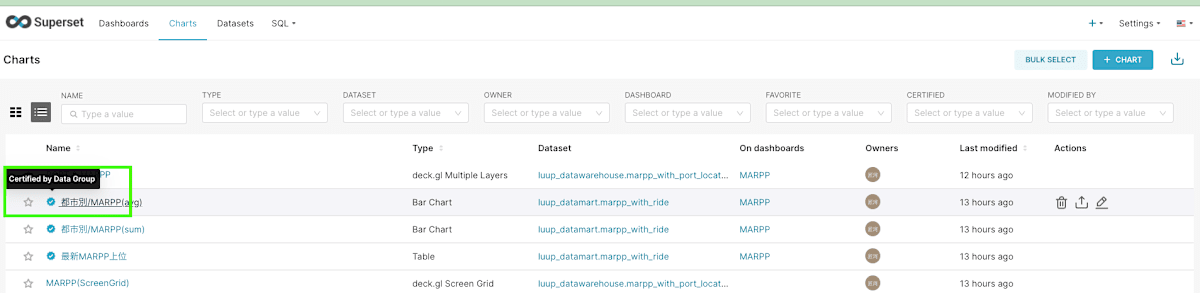
Certifiedマーク
DashboardやChart、Datasetに対して、Certifiedマークという印をつけることができます。この機能により、活用者はどれを見れば正しいデータなのか把握することができます。
LuupではデータチームのReviewが通ったデータの信頼性が一定担保されているものについては、Certifiedマークをつけて展開するような方針にしています。
Superset改善したい機能
Supersetの現状発生している不具合や改善したい機能についても少しだけ触れておきます。
MapVisualizationのdeck.gl Multiple Layersのfilterが機能しない
以下画像のようにいくつかのMapVisualizationを重ねて表示させたい時に、Multiple Layersという表現方法を使うのですが、この表現方法で可視化した場合、filterがうまく動きません。
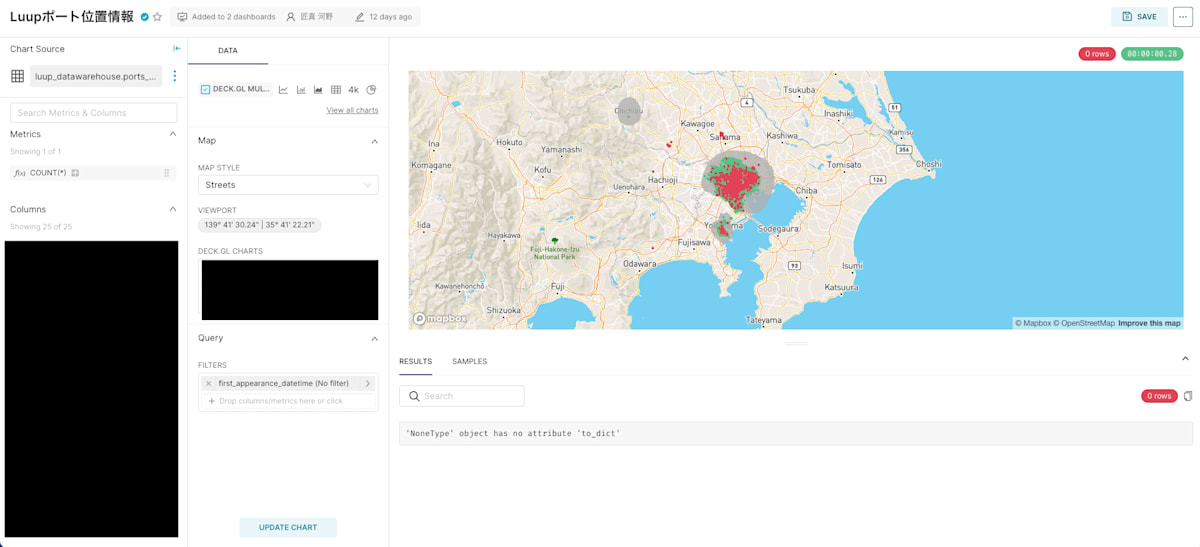
Issueは上がっているのですが、対応はまだされていないようです。
MapVisualizationでH3表現ができない
H3とは、Uber社が開発しているグリッドシステムで位置情報に基づいた集計を高速に行う際に便利な表現方法です。
わかりやすい例で言うと、ライドのルート情報において、どのルートを多く活用しているかの集計に使ったりしています。
DekartではH3の機能がついているのですが、SupersetではH3の機能がついていません。
こちらもIssueは上がっていますが、対応はまだされていないようです。
大元のDeck.glではサポートしているようなので、自分で取り込むことによって表現自体はできそうです。
なお、H3の詳細については、以下の記事などが参考になるかと思います。
日本語の表現が微妙
上記のインフラ周りで記載した通り、言語設定に日本語を選択できるのですが、全て綺麗に日本語になるわけではなく、一部は英語のままだったりします。
まとめ、今後の施策
Supersetを導入して終わりではなく、導入してからがスタートです。Supersetのメリットを最大にするために、以下のような施策を進めています。
- 現状のRedashやLooker Portalからの切り替えとSupersetの社内浸透活動
- データ基盤側のlayer層の改善、Semantic Layerの導入
- Dimensional Modelingの採用
- Supersetの不具合解消や新規機能開発のCommit
- Supersetのdatasetやchart、dashboard、Certifiedマーク等管理のIac化
Redash完全切り替えとSupersetの社内浸透活動は時間かかると思いますが、地道に進めていこうと思っています。
終わりに
Luupのデータエンジニアリングチームは圧倒的にメンバーが足りません。今回ご紹介したようなBIツールの導入におけるインフラ周りの構築からデータ基盤、データマネジメントに活用までデータに関わることは基本全て担います。やることは多いですが、様々な領域を幅広く経験することができる環境だと思っています。
Luupでのデータ基盤構築、データ活用に少しでもご興味がある方、ぜひ情報交換という形でもお話しできたら嬉しいです。

Discussion