ログラスの龍島(@hryushm)です。最近は秋に備えて干し芋を作る練習をする日々を過ごしています。
ログラスではオニオンアーキテクチャを採用してしてDDDを実践しています。直近プロダクトのスケールによってデータのレポーティング、集計処理のパフォーマンス劣化の問題が顕在化、早急な対応を迫られる事態となっていました。その対応としてRDBMS(PostgreSQL)からDWH(BigQuery)へ一部のクエリを移行しました。オニオンアーキテクチャの恩恵で移行が比較的容易であり、実装自体は1ヶ月というスピードで終えることで顧客に素早く価値提供できたため、実例として記事にしたいと思います。
オニオンアーキテクチャと利点
オニオンアーキテクチャ自体の説明は多数の記事があるため省きますが、弊社松岡の記事が理解しやすいと思います。
記事中にあるレイヤードアーキテクチャと比較した時に肝となる、依存性逆転の原則を適用しドメイン層をインフラ層に依存させないということは、ドメイン層、インフラ層それぞれに下記のようなメリットがあると言えます。
- ドメイン層は依存するものがなくなるため、変更を柔軟に行うことができる
- インフラ層はドメイン層から依存されないため、変更の際にドメイン層に影響を与えない
対象とするドメイン(経営管理)の複雑さから、これまでのログラスでアプリケーション開発を行う際には前者のメリットを感じることが多かったです。しかし前述のように、プロダクトのスケールによってインフラ層の責務である領域に課題が発生すると、インフラ層のみで身動きが取れる後者のメリットも大きいと感じました。
「実際インフラ層の変更頻度って高くないので、その観点での分離する価値は大きくないのでは?」という声も聞くことはありますし、自分自身もそう思うこともあったのですが、今回のインフラ移行は考えを改める良い機会となりました。
実例
早速実例がどのようだったか見ていきます。
アプリケーションとインフラ構成Before, After
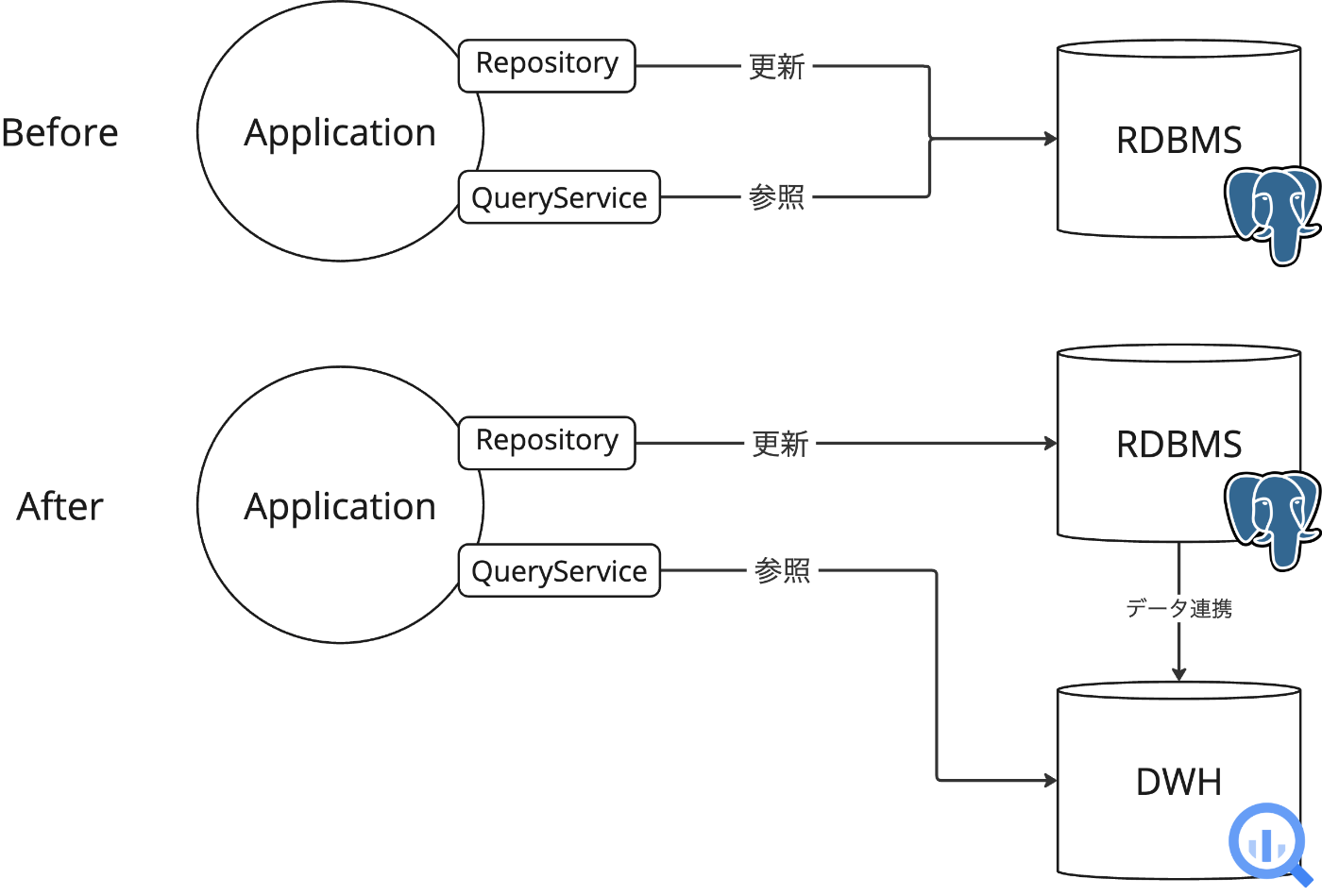
インフラ構成 Before, After
構成変更前はアプリケーションがPostgresに直接接続するシンプルな構成でした。アプリケーション側はCQRSの構成になっており、QueryServiceとして集計処理が実装されていますが、クエリするデータソースとしてはPostgresです。
前述の通りPostgresでは集計クエリに対して期待されるパフォーマンスを出すことができない状態となってしまったので、参照用のデータソースとしてBigQueryを導入しました。
変更後は更新処理をPostgres、重たい集計クエリはデータ同期されているBigQueryに投げる構成にとしています。アプリケーション側の改修はBigQuery用のQueryService(IFはPostgresのものと同じ)を実装したのみです。
QueryServiceの実装を低コストにした要素
該当の集計処理をするQueryServiceはアプリケーションの中でも1,2を争う複雑なモジュールでしたが、2つの要素によって比較的低コストに実装することができました。
オニオンアーキテクチャによりインフラ層に閉じた変更となること
前述のオニオンアーキテクチャの利点の通り、既存のPostgreSQLへ向けたQueryServiceと同じIFを実装するBigQuery向けのQueryServiceを実装し置き換えることで、ドメイン層への影響なしで実装が可能でした。
移行プロジェクト中、別のチームが機能開発のためにドメイン層やアプリケーションサービス層に変更を加えていましたが、干渉すること無く進められたため、新機能の開発を止める必要がなかったことはビジネス的にも大きな価値でした。
QueryServiceに対して充実した自動テストがあったこと
既存のPostgreSQLのQueryServiceにはDBの処理を含めた自動テストが作成されていました。プロダクトの性質上数値計算の誤りはプロダクトの価値毀損に直結することもあり、通常のテストに加えてパターンを網羅したスナップショットによるリグレッションテストも整備されていました。BigQuery向けQueryServiceの実装にあたってはこれらのテストを通せれば大丈夫という安心感があり、高速に実装を進めることができました。
スナップショットテストについては下記の記事でも紹介しています。
実装コストの低さから本質的に解決したい課題に集中
実際上記の移行を検証をしていると、PostgreSQLで実行していたクエリをそのままBigQueryで実行するだけでは改善はするものの、期待するほどの改善が見込めないことがわかりました。
本質的に解決したいのはパフォーマンスの問題だったところが、そもそも解決しきれない危機です。
しかし、前述の通りQueryServiceの実装コストが低かったため、この問題に正面から時間をかけて向き合うことができました。
試行錯誤の結果BigQueryで参照するマスタデータのデータ構造を列志向DBの特性に合わせたものに変更すると性能改善することがわかったため、BigQueryでは参照用に別のデータ構造を持つようにしました。
具体的な内容については下記の記事で紹介しています。
参照するデータ構造から変えることは、実装やテストを考えると高コストに思えますが、限られた時間の中でも対応する余力を作れたことでやりきることができました。
まとめ
オニオンアーキテクチャを採用しドメイン層をインフラ層に依存させなかったこと、またインフラ層のQueryServiceに対する責務を検証するテストを整備できていたことから、本質的に解決したかった課題の解決に集中できた例を紹介しました。
DDDやオニオンアーキテクチャは、本質的に向き合いたい課題に集中し、他の偶有的な複雑性を減らす設計手法なのだと改めて感じるいい機会となりました。

Discussion