株式会社ログラスの龍島(りゅうしま)です。最近はもっぱら新生姜をガリにしてクラフトビールのつまみにする毎日を送っています。今日はデータベースとデータ構造の話です。
この記事でやること
データ集計の高速化のため、多くの場合、列指向データベースが選ばれます。列指向が大量のデータ操作を効率的に処理できるためです。行指向のデータベースを利用している状況で、データ集計のパフォーマンス向上のため列指向データベースへの移行をすることはよくある例です。しかし、行指向データベースで有効なデータ構造やクエリが列指向で同様に優れているとは限りません。この記事では、行指向のPostgreSQLと列指向のBigQueryを使って、それぞれに適したデータ構造とクエリのパフォーマンスを実験から探ります。
具体的には、木構造を用いた集計クエリを例に取り、DBとして行指向のPostgreSQLと列指向のBigQuery、データ構造として経路列挙モデル、閉包テーブルモデルを用いてそれぞれの組み合わせでの性能を比較します。
列指向データベースでは「多くの列を扱わない方がよい」と言われ、行指向データベースでは「joinなどで行数をむやみに増やさないほうがよい」と言われます。それが本当なのかを確かめていきいます。
列指向、行指向データベース
世に多くの解説記事はあるため深堀りせず、簡単に列指向、行指向データベースの特徴をまとめます。
列指向データベース(例:BigQuery)
列指向データベースは、データを列単位で格納します。この方式は、特定の列だけを対象とする集計や分析クエリが非常に高速になるため、ビッグデータの分析やレポート作成に適しています。列ごとにデータ型や圧縮方式を最適化できるため、ストレージ効率も良くなります。
行指向データベース(例:PostgreSQL)
行指向データベースでは、データは行単位で保存されます。これにより、一つの行にある複数の列を効率的に処理することができ、トランザクション処理や更新処理が頻繁なアプリケーションに適しています。そのため、日常の業務アプリケーションや、リアルタイム処理を要するシステムでよく利用されます。
階層データモデル
今回は階層構造を表現するデータモデルとして、閉包テーブルモデルと経路列挙モデルを用います。それぞれ簡単に紹介します。
閉包テーブルモデル
閉包テーブルモデルでは、ノード間のすべての祖先と子孫の関係を表すために、祖先と子孫のペアとその間の距離を保存します。特定のノードについて、ancestorで絞り込めば子孫の集合、descendantで絞り込めば祖先の集合を簡単に取得することができます。
例えばエリアを例とすると下記のようなイメージです
| ancestor | descendant | depth |
|---|---|---|
| 日本 | 日本 | 0 |
| 日本 | 関東地方 | 1 |
| 関東地方 | 関東地方 | 0 |
| 日本 | 東京都 | 2 |
| 関東地方 | 東京都 | 1 |
| 東京都 | 東京都 | 0 |
| 日本 | 神奈川県 | 2 |
| 関東地方 | 神奈川県 | 1 |
| 神奈川県 | 神奈川県 | 0 |
| 日本 | 千葉県 | 2 |
| 関東地方 | 千葉県 | 1 |
| 千葉県 | 千葉県 | 0 |
| 日本 | 関西地方 | 1 |
| 関西地方 | 関西地方 | 0 |
| 日本 | 大阪府 | 2 |
| 関西地方 | 大阪府 | 1 |
| 大阪府 | 大阪府 | 0 |
| 日本 | 京都府 | 2 |
| 関西地方 | 京都府 | 1 |
| 京都府 | 京都府 | 0 |
経路列挙モデル
経路列挙モデルでは、ノードの全ての祖先を列に記録します。閉包テーブルモデルをいわゆる横持ちにしたような形です。
閉包テーブルモデルの例と同様なデータ構造を表現すると下記のようなイメージです
| level_1 | level_2 | level_3 |
|---|---|---|
| 日本 | ||
| 日本 | 関東地方 | |
| 日本 | 関東地方 | 東京都 |
| 日本 | 関東地方 | 神奈川県 |
| 日本 | 関東地方 | 千葉県 |
| 日本 | 関西地方 | |
| 日本 | 関西地方 | 大阪府 |
| 日本 | 関西地方 | 京都府 |
一般に経路列挙モデルというと一つのカラム(例えばpath)で 日本/関東地方/東京都 という文字列で構造を表現することもありますが、今回の実験では集計のしやすさのため階層ごとにカラムを分けた構造を前提に進めます。
実験
対象処理
下記のような都道府県の売上データをすべての階層別に集計したいとします。
サンプルデータ
| item_id | area | value |
|---|---|---|
| 001 | 東京都 | 500 |
| 002 | 東京都 | 300 |
| 003 | 神奈川県 | 200 |
| 004 | 神奈川県 | 150 |
| 005 | 千葉県 | 250 |
| 006 | 大阪府 | 400 |
| 007 | 京都府 | 180 |
| 008 | 京都府 | 220 |
欲しい結果
| area | total_sales |
|---|---|
| 日本 | 2200 |
| 関東地方 | 1400 |
| 東京都 | 800 |
| 神奈川県 | 350 |
| 千葉県 | 250 |
| 関西地方 | 800 |
| 大阪府 | 400 |
| 京都府 | 400 |
この処理のパフォーマンスがデータベースの種類、データ構造の組み合わせでどのように変わるか見ていきます。
PostgreSQLでのDDL、テストデータ生成SQLは下記のようにしてみました。
詳細な部分は本旨にあまり関係ないため、結果と考察に飛んでいただいて問題ないです。
テーブル、テストデータ用意
create table areas
(
area_id text primary key,
parent_area_id text
references areas (area_id),
name text
);
create table area_path_enumeration
(
area_id text primary key references areas (area_id),
leve_1_id text references areas (area_id),
leve_2_id text references areas (area_id),
leve_3_id text references areas (area_id),
leve_4_id text references areas (area_id),
leve_5_id text references areas (area_id)
);
create table area_closure
(
ancestor_id text references areas (area_id),
descendant_id text references areas (area_id),
depth integer,
primary key (ancestor_id, descendant_id)
);
create table items
(
item_id text primary key,
area_id text references areas (area_id),
value bigint
);
-- areasテーブルへのデータ挿入
-- 階層構造を反映するためにparent_area_idを設定
WITH RECURSIVE area_hierarchy AS (SELECT 1 AS level,
CAST('area1' AS TEXT) AS area_id,
CAST(NULL AS TEXT) AS parent_area_id,
CAST('Area 1' AS TEXT) AS name
UNION ALL
SELECT ah.level + 1,
ah.area_id || CAST(child.suffix AS TEXT),
ah.area_id,
'Area ' || ah.area_id || CAST(child.suffix AS TEXT)
FROM area_hierarchy ah,
generate_series(1, 6) AS child(suffix)
WHERE ah.level < 5)
INSERT
INTO areas (area_id, parent_area_id, name)
SELECT area_id, parent_area_id, name
FROM area_hierarchy;
-- area_closureテーブルのデータ生成
WITH RECURSIVE closure AS (SELECT a.area_id AS ancestor_id, a.area_id AS descendant_id, 0 AS depth
FROM areas a
UNION ALL
SELECT c.ancestor_id, a.area_id, c.depth + 1
FROM areas a
JOIN areas ap ON a.parent_area_id = ap.area_id
JOIN closure c ON ap.area_id = c.descendant_id)
INSERT
INTO area_closure (ancestor_id, descendant_id, depth)
SELECT *
FROM closure;
INSERT INTO area_path_enumeration (area_id, leve_1_id, leve_2_id, leve_3_id, leve_4_id, leve_5_id)
WITH agg AS (SELECT ac.descendant_id AS area_id,
array_agg(ac.ancestor_id order by ac.depth desc) AS ancestors
FROM area_closure ac
group by ac.descendant_id)
SELECT area_id,
ancestors[1],
ancestors[2],
ancestors[3],
ancestors[4],
ancestors[5]
FROM agg;
-- itemsテーブルへのデータ挿入(エリアごとにランダムな値)
INSERT INTO items (item_id, area_id, value)
SELECT 'item_' || a.area_id || '_' || CAST(gs.idx AS TEXT),
a.area_id,
(RANDOM() * 1000)::INT
FROM areas a
CROSS JOIN generate_series(1, 10000) AS gs(idx)
;
集計クエリは下記です
閉包テーブル利用
select ac.ancestor_id, sum(i.value)
from items i
inner join area_closure ac on ac.descendant_id = i.area_id
group by ac.ancestor_id;
経路列挙モデル利用
select coalesce(ape.leve_5_id, leve_4_id, leve_3_id, leve_2_id, leve_1_id) as area_id,
sum(i.value)
from items i
inner join area_path_enumeration ape on i.area_id = ape.area_id
group by grouping sets ( (ape.leve_1_id),
(ape.leve_2_id),
(ape.leve_3_id),
(ape.leve_4_id),
(ape.leve_5_id)
)
having coalesce(ape.leve_5_id, leve_4_id, leve_3_id, leve_2_id, leve_1_id) is not null;
grouping setsは複数のgroup byを一度にできるもので、下記の記事でも解説しています。
結果
| PostgreSQL | BigQuery | |
|---|---|---|
| 閉包テーブルモデル | 19,241ms | 602ms |
| 経路列挙モデル | 8,113ms | 2,048ms |
PostgreSQLにおいては経路列挙モデルが閉包テーブルモデルと比較して137%高速で、BigQueryでは逆に閉包テーブルモデルが経路列挙モデルと比較して240%高速となりました。
考察
PostgreSQLとBigQueryで処理の早いデータモデル、クエリが異なるという結果になりました。なぜこうなるのか考えてみます。
実験で作成したテーブルは下記のようなイメージです。
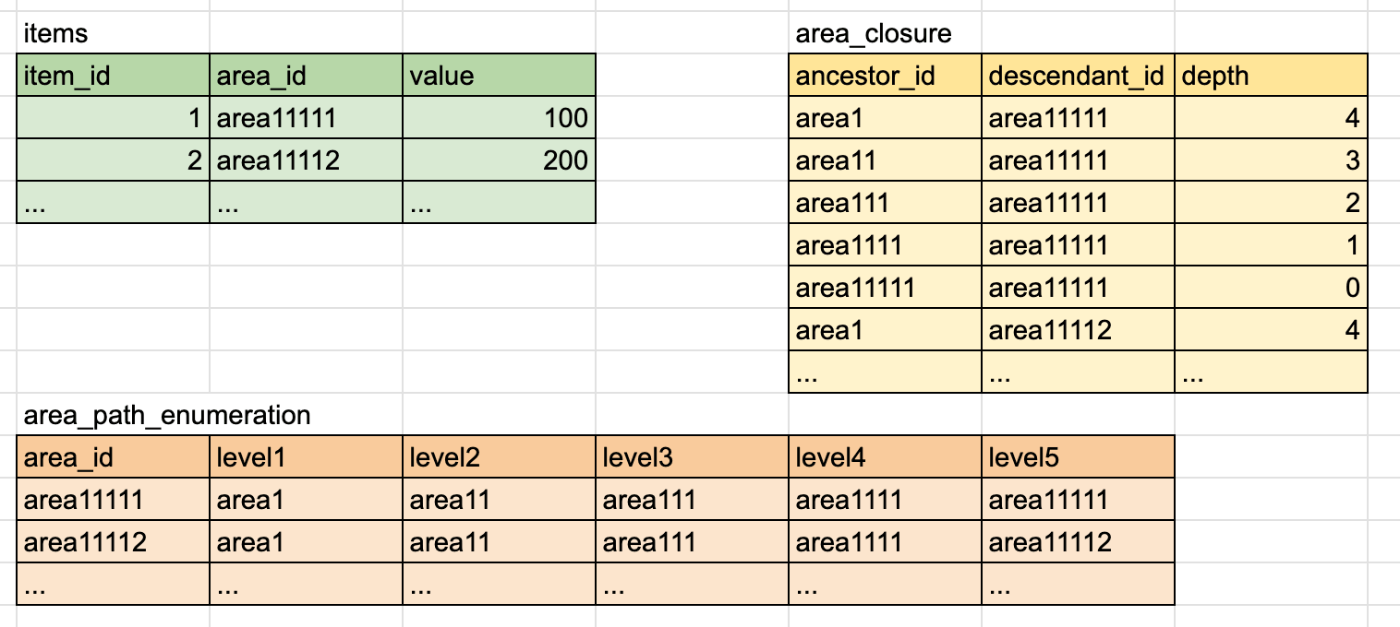
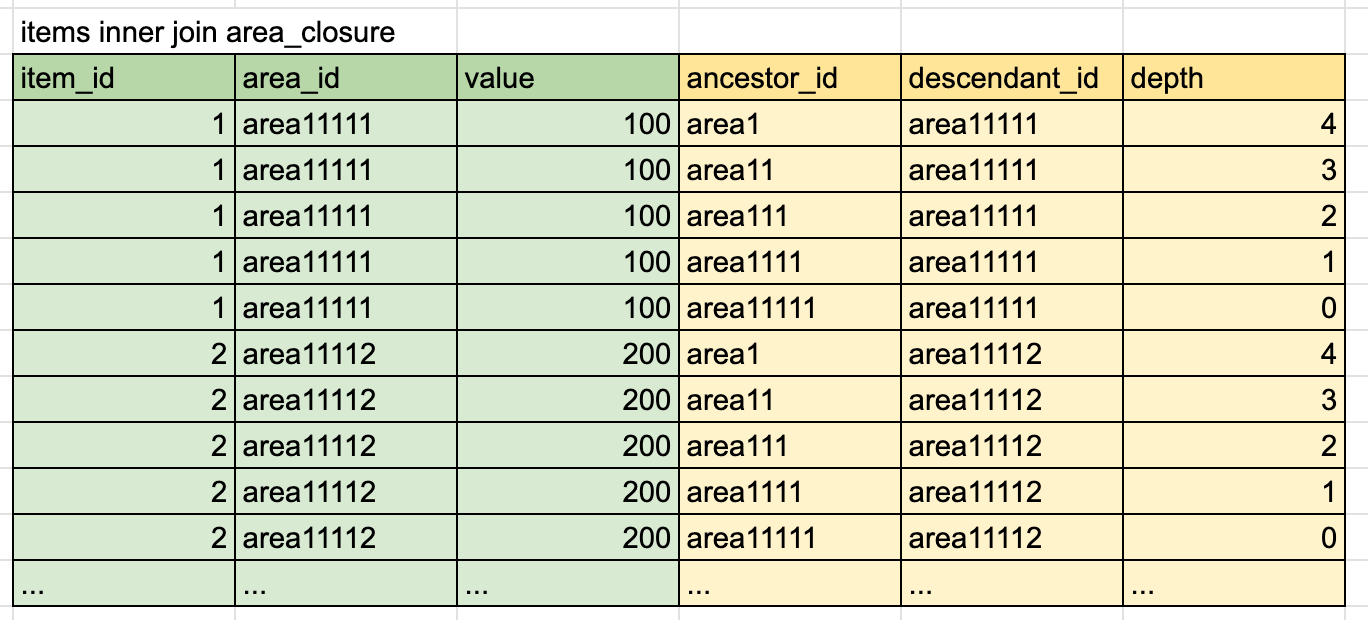
それぞれのクエリでitemsにarea_closure, area_path_enumerationをjoinすると下記のようになります。
account_closure(閉包テーブルモデル)
account_path_enumeration(経路列挙モデル)

行数に着目すると、閉包テーブルモデルは行数が増え、経路列挙モデルはitemsから行数は増えていません。列数に着目すると閉包テーブルモデルは比較的少ない列数、経路列挙モデルは比較的多い列数となっています。
行指向データベースは行単位でデータを扱う特性から、列が多くなっても性能劣化しにくく、列指向データベースは列単位でデータを扱う特性から列が多くなることで性能劣化するのだと考えられます。
このようにデータベースの特性によって適したデータ構造を持つことで、大きくクエリの性能を向上させることができる可能性があります。
一方データ構造によっては更新のコストが高いこともありえるため、ユースケースによって求められる性能要件に応じて適切な選定をしていく必要があります。
自身の経験として行指向データベースの経験が長かったため、常に「計算する行を増やさないにはどうしたらよいか」を考える癖がついてしまっており、特性を意識して考え方を切り替えることの重要性を感じました。

Discussion
閉包テーブルモデルについて、depthが1以外のデータは必要なのでしょうか?
日本は日本ですし、
日本の中にある関東地方の中にある東京都なので、日本の中に東京都があるのは明らかです。
閉包テーブルモデルにおけるdepth=1に絞ったものは、隣接リストモデルと呼ばれるデータ構造になります。
閉包テーブル自体は木構造をデータベースに保存する目的に絞ると冗長なデータ構造であり、隣接リストモデルは必要最低限でシンプルなデータ構造です。
しかし、隣接リストモデルで今回のような集計クエリを作成することを考えてみていただけると理解しやすいかと思うのですが、隣接リストは祖先や子孫の取得、それを用いた集計などが非常にやりにくく、結局クエリの途中で閉包テーブルモデルや経路列挙モデルのようなデータ構造を作ることになります。
閉包テーブルモデルや経路列挙モデルは参照時にクエリがし易いよう保存時にあらかじめ持ち方を工夫していると考えていただけると良いと思います。
このあたりの話はSQLアンチパターンにもわかりやすく書かれているため参照いただけると良いかもしれません。