勉強メモ: CMU Database Systems (FALL 2022)
CMU Database systemを勉強した時のメモ
Notesの内容を中心にまとめる。講義動画は補助。
Python や将来的にRustでポーティングしたいお気持ち
Course url: https://15445.courses.cs.cmu.edu/fall2022/
注意点
- 個人の勉強メモのため内容の保証はしません
- SQLの書式は(おおよそ)notes準拠です
- 情報の粒度は僕のその時々の気分で変動してることがあります
目次
Lecture 01: Relational Model & Relational Algebra
1 Databases
- データベース(DB)とは、実世界のある側面をモデル化した相互に関連するデータの組織的な集合体
- ex) クラスの生徒やデジタル音楽ストアなどをモデリングしたもの
- 「DB」と「データベースマネジメントシステム(DBMS)」を混同する人が多いが別物
- DBMS:DBを管理するソフトウェア
2 Flat File Strawman
- DBはDBMSが管理するCSVファイルとして保存される
- 各エンティティはそれ自身のファイルに格納される
- アプリケーションはレコードをreadしたりupdateするごとにファイルを解析する必要がある
- デジタル音楽ストアの例
- 2つのエンティティ:アーティスト、アルバム
- 各エンティティは独自の属性を持っているので、各ファイルでは異なるレコードは改行区切り、同じレコード内の対応する属性はコンマで区切られる。
Wu-Tang Clan, 1992, USA
Notorious BIG, 1992, USA
GZA, 1990, USA
閑話休題
上記のアーティストはいずれもアメリカのHipHopクルー/アーティストであり、HipHopを語る上で外せない存在であるため、ぜひ一度は拝聴してほしい。
また、動画の14:20付近でも「GZAがソロになった年は?」という例題が出ているが、これはGZAがWu-Tang Clan(クルー)のメンバーであるためこの表現が使用されている。あと、noteの「GZE」というのは多分誤字。
Issues with Flat File
- Data Integrity(整合性)
- 各アルバム・エントリについて、アーティストが同じであることを保証するにはどうするか?
- 誰かがアルバムの年を無効な文字列で上書きしたらどうするか
- 1つのアルバムに複数のアーティストがいる場合、どのように扱えばよいか?
- アルバムに含まれるアーティストを削除するとどうなるか?
- Implementation(実装)
- 特定のレコードを見つけるにはどうすればよいのでしょうか?
- 同じデータベースを使う新しいアプリケーションを作りたいとしたらどうか?
- 2つのスレッドが同時に同じファイルに書き込もうとしたら?
- Durability(耐久性)
- プログラムがレコードを更新している最中にマシンがクラッシュしたら?
- 高可用性のために複数のマシンにデータベースを複製したい場合はどうするか?
- 後々ACID特性にも出てくるかな?
3 Database Management System
- 汎用的DBMSは何かしらのデータモデルに従って、DBの定義・作成・問い合わせ・更新・管理を行えるように設計されている。
- データモデル:DB内のデータを記述するための概念の集合体
- ex) リレーショナル、NoSQL(key, value, graph)、配列/マトリックス/ベクトル
- スキーマ:データモデルに基づく特定のデータ集合体の記述
Early DBMSs
- かつてDBアプリケーションは論理層/物理層が密結合しているため、構築/保守が困難だった。
- 論理層:DBがどのようなエンティティや属性を持つかを記述
- 物理層:上記のエンティティや属性がどのように保存されるかを記述
- 初期には物理層はアプリケーションのコードで定義されていた
- そのため、アプリケーションが使用している物理層を変更したい場合、新しい物理層に合わせて全てのコードを変更する必要があった。
4 Relational Model
- 1970年にTed Codd氏がリレーショナルモデルを提唱
- リレーショナルモデル:メンテナンスのオーバーヘッドを避けるために、リレーションに基づいてDBを抽象化することを定義している。
- 3つの特徴
- DBを単純なデータ構造(リレーション)で格納
- 高級言語を使用してデータにアクセスし、DBMSが最適な実行戦略を考案する(?)
- 物理ストレージはDBMSの実装に任せる。
- 3つの概念
- Structure(構造): リレーションおよびその内容の定義。
- リレーションが持つ属性とその属性が保持できる値。
- Integrity(整合性):DBの内容が制約を満たすこと。DBの内容が制約を満たしていることを確認する。
- ex) 日付属性は数字でなければならない
- Manipulation(操作):DBの内容にアクセスし、変更すること
- Structure(構造): リレーションおよびその内容の定義。
- リレーション:エンティティを表す属性のリレーションシップを含む順序なし集合である(?)
- タプル:リレーションにおける属性値(そのドメインともいう)の集合
- もともと値はアトミックかスカラーでなければならなかったが、現在ではリストやネストしたデータ構造でも値になりうる
- すべての属性はNULLという特別な値にすることができ、これは与えられたタプ ルに対してその属性が未定義であることを意味する。
- n個の属性を持つ関係はn-ary関係と呼ばれる。
relationとrelationshipの違い
以下の図と解説が分かりやすかったので引用。
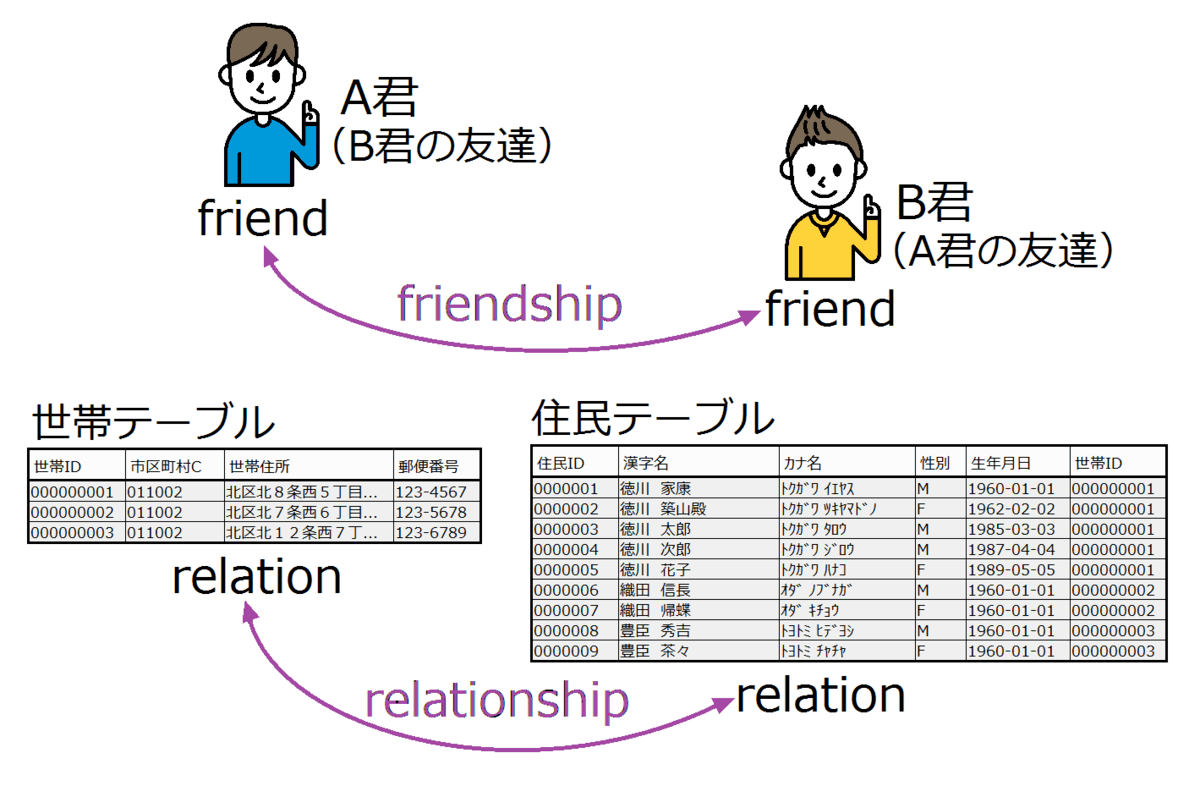
出典:設計者の発言
- relation:あるテーブルのある瞬間における全行のまとまり
- relationship:2つのrelation同士の関連
Keys
- リレーションの主キーは1つのタプルを一意に識別する。
- DBMSによっては、主キーを定義しなくても、自動的に内部主キーを定義していない場合、DBMS は自動的に内部の主キーを作成する。
- 多くの DBMS は自動生成されたキーをサポートしているので、アプリケーションは手動でキーを増やす必要はない場合が多い。
- 外部キーは、ある関係の属性が別の関係のタプルにマップされなければならないことを指定する。
5 Data Manipulation Languages (DMLs)
- DBから情報を保存したり、取り出したりするための方法。そのための2つのクラスの言語がある。
6 Relational Algebra
- 関係代数(Relational Algebra):関係中のタプルを取り出し、操作するための基本的な操作の集合
- select
- Projection:投影は、関係を取り込み、指定された属性のみを含むタプルを持つ関係を出力する。入力関係に含まれる属性の順序を入れ替えたり、値を操作することができる。
- Union:和集合
- SQL:union all
- Intersection:積集合
- Difference:exceptのこと
- Product:Productは2つの関係を取り込み、入力関係からタプルの可能な組み合わせをすべて含む 関係を出力する。
- SQL: (SELECT * FROM R) CROSS JOIN (SELECT * FROM S), or simply SELECT * FROM R, S
- Joinは2つの関係を取り込み、2つの関係が共有する各属性について、両方のタプルのその属性の値が同じである、2つのタプルの組み合わせであるすべてのタプルを含む関係を出力する。
- SQL: SELECT * FROM R JOIN S USING (ATTRIBUTE1, ATTRIBUTE2...)
Lecture 02: Modern SQL
1 Relational Languages
- 関係代数:集合(sets)(順序なし、重複なし)をベースとする
- sets(no duplicates)
- SQLはバッグ(bags)(順番なし、重複あり)をベースとする
- bags(duplicates)
2 SQL History
- 1970年代:IBM System Rプロジェクトの一環として開発。IBMは当初「SEQUEL」(Structured English Query Language)と呼んでいた。
- 1980年代:単に「SQL」(Structured Query Language)と呼ばれるようになりました。
- 直近のスタンダードはSQL:2016
- この言語は、異なるクラスのコマンドで構成されています。
- データ操作言語(DML)。SELECT、INSERT、UPDATE、DELETEステートメント。
- データ定義言語(DDL): テーブル、インデックス、ビュー、その他のオブジェクトのスキーマ定義。
- データ制御言語(DCL)。セキュリティ、アクセス制御
3 Joins
- 1つまたは複数のテーブルのカラムを結合し、新しいテーブルを作成する。
- 複数のテーブルにまたがるデータを扱うクエリを表現するために使用される。

CREATE TABLE student (
sid INT PRIMARY KEY,
name VARCHAR(16),
login VARCHAR(32) UNIQUE,
age SMALLINT,
gpa FLOAT
);
CREATE TABLE course (
cid VARCHAR(32) PRIMARY KEY,
name VARCHAR(32) NOT NULL
);
CREATE TABLE enrolled (
sid INT REFERENCES student (sid),
cid VARCHAR(32) REFERENCES course (cid),
grade CHAR(1)
);
-- 手元で試したい人用
-- studentテーブル
insert into student
values
(53666,'Kanye','kanye@cs',44,4.0),
(53688,'Bieber','jbieber@cs',27,3.9),
(53655,'Tupac','shakur@cs',25,3.5);
-- courseテーブル
insert into course
values
('15-445','Database Systems'),
('15-721','Advanced Database Systems'),
('15-826','Data Mining'),
('15-799','Special Topics in Database');
-- enrolledテーブル
insert into enrolled
values
(53666,'15-445','C'),
(53688,'15-721','A'),
(53688,'15-826','B'),
(53655,'15-445','B'),
(53666,'15-721','C');
余談その1
僕はBigQueryしかまともに触ったこと無いので、VARCHARとかSMALLINTとかは初めて見た。
- VARCHAR: 可変長文字列
- SMALLINT: 2Byte(16bit)の整数を格納できるもの
- TINYINTやBIGINTもあるらしい
余談その2
studentテーブルのHipHopアーティストたち
- Kanye→Kanye West
- Bieber→Justin Bieber
- Tupac→2Pac
あれ?ジャスティン・ビーバーってHipHop関係なくね?って思ったあなた、実は彼は近年HipHop曲を頻繁に出しているのです。常にラップしているわけではないのですが、結構有名所のラッパーたちとコラボし、ほとんどバイラルヒットさせてるので凄い(語彙力)
ちなみに僕のおすすめは以下です。
Justin Bieber - Honest ft. Don Toliver (Directed by Cole Bennett)
例題
Q. どの生徒が15-721でAを取れたか?
SELECT s.name
FROM enrolled AS e, student AS s
WHERE e.grade = 'A' AND e.cid = '15-721' AND e.sid = s.sid;
4 Aggregates
- 集計関数は、タプルのバッグを入力として受け取り、単一のスカラー値を出力として生成します。
- 集約関数は、(ほとんど)SELECT出力リストでのみ使用することができます。
- 集計関数例
- AVG(COL):COLの値の平均値
- MIN(COL):COLの値の最小値
- MAX(COL):COLの最大値
- COUNT(COL):リレーション内のタプルの数
例題4-1
Q. Get # of students with a ‘@cs’ login.(@csでログインしている生徒の数を出力せよ。)
-- 3つの解答例
SELECT COUNT(*) FROM student WHERE login LIKE '%@cs';
-- or
SELECT COUNT(login) FROM student WHERE login LIKE '%@cs';
-- or
SELECT COUNT(1) FROM student WHERE login LIKE '%@cs';
- 1つのSELECT句には複数の集約関数を含めれる
例題4-2
- いくつかの集約関数(COUNT、SUM、AVGなど)は、DISTINCTキーワードをサポートしている
Q. Get # of unique students and their average GPA with a ‘@cs’ login.(@csでログインしている生徒の数と彼らの平均GPAを出力せよ。)
SELECT COUNT(DISTINCT login)
FROM student WHERE login LIKE '%@cs';
例題4-3
- 集計関数外の他のカラムの出力が未定義である(以下、e.cidが未定義である)
Q. Get the average GPA of students in each course.(各コースの生徒の平均GPAを出力せよ。)
SELECT AVG(s.gpa), e.cid
FROM enrolled AS e, student AS s
WHERE e.sid = s.sid;
# エラー文
mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.30 |
+-----------+
ERROR 1140 (42000): In aggregated query without GROUP BY, expression #2 of SELECT list contains nonaggregated column 'database_name.e.cid'; this is incompatible with sql_mode=only_full_group_by
余談
SQLの実行順序(前回説明があったかもしれないし、今後出るかも)
from→where→group by→having→select→union→order by→distinct
例題4-4
- SELECT句の非集約値は、GROUP BY句に表示する必要がある
SELECT AVG(s.gpa), e.cid
FROM enrolled AS e, student AS s
WHERE e.sid = s.sid
GROUP BY e.cid;
例題4-5
- HAVING句は、集計計算に基づいて出力結果をフィルタリングする。
- これは、HAVINGをGROUB BYのWHERE句のように動作させれる。
Q. Get the set of courses in which the average student GPA is greater than 3.9. (学生の平均GPAが3.9より大きい科目の集合を出力せよ。)
- これは、HAVINGをGROUB BYのWHERE句のように動作させれる。
SELECT AVG(s.gpa) AS avg_gpa, e.cid
FROM enrolled AS e, student AS s
WHERE e.sid = s.sid
GROUP BY e.cid
HAVING avg_gpa > 3.9;
- 上記問クエリは多くの主要なデータベースシステムでサポートされているが、標準SQLには準拠していない。
- 標準SQLに準拠するためには、HAVING句の本文でAVG(S.GPA)を繰り返し使用しなければならない。
-- HAVING句のみ変更
HAVING AVG(s.gpa) > 3.9;
5 String Operations
- 標準SQL
- 文字列は大文字と小文字を区別
- シングルクォートのみ使用
- 文字列を操作する関数があり、クエリのどの部分でも使用可能
パターンマッチ:LIKEは、述語の中の文字列マッチングに使われる。- "%": 任意の部分文字列(空も含む)にマッチする。
- "_" : 任意の1文字にマッチする。
- 文字列関数 SQL-92の文字列関数例
- SUBSTRING(S, B, E) や UPPER(S)等
- Concatenation(連結): 2本の縦棒("||")は、2つ以上の文字列を1つの文字列に連結するという意味
- よく使うであろうcatコマンドは“concatenate” の略
6 Date and Time
- DATEとTIMEの属性を操作するためのオペレーション
- 具体的な日付・時刻の操作のための特定の構文は、システムによって大きく異なる
7 Output Redirection
- クエリの結果をクライアント(端末など)に返す代わりに、DBMSに結果を別のテーブルに格納するように指示することができる
- そうすれば、その後のクエリでこのデータにアクセスできる。
- 新しいTable: クエリ出力を新しい(永続的な)テーブルに格納する
SELECT DISTINCT cid INTO CourseIds FROM enrolled;
- 既存Table: クエリの出力を、データベースに既に存在するテーブルに格納する。対象テーブルは、対象テーブルと同じ型を持つ同じ数のカラムを持つ必要があるが、出力クエリのカラムの名前は一致する必要はない
INSERT INTO CourseIds (SELECT DISTINCT cid FROM enrolled);
8 Output Control
- 出力順序を指定したいなら ORDER BYを使え。
- デフォルトのソート順は昇順(ASC)、降順はDESCを明示的に指定する必要あり
- ORDER BY句には任意の式を使うことができる
SELECT sid FROM enrolled WHERE cid = '15-721'
ORDER BY UPPER(grade) DESC, sid + 1 ASC;
- 出力数を絞りたい場合はLIMIT
- 範囲を指定したいときはOFFSETを使う。
- ORDER BY句にLIMITを付けない限り、リレーショナルモデルでは順序が決まっていないため、DBMSはクエリを実行するたびに異なるタプルを結果に生成する可能性がある
9 Nested Queries
- サブクエリのお話
- 外部クエリのスコープは内部クエリに含まれるが (内部クエリは外部クエリの属性にアクセス可能)、その逆はできない。
例題9-1
Q. 例 「15-445」に在籍している学生の名前を取得せよ
SELECT name FROM student
WHERE sid IN (
SELECT sid FROM enrolled
WHERE cid = '15-445'
);
- sidは、クエリ内のどこに出現するかによって、スコープが異なることに注意
10 Window Functions
- ウィンドウ関数は分析関数とも呼ばれ、行のグループに対して値を計算して、各行に対して 1 つの結果を返す
- グループ化
- OVER句は、ウィンドウ関数を計算するときにタプルをグループ化する方法を指定する。
- グループを指定するにはPARTITION BYを使用する。
SELECT cid, sid, ROW_NUMBER() OVER (PARTITION BY cid)
FROM enrolled ORDER BY cid;
- また、OVERの中にORDER BYを入れることで、データベースが内部的に変化しても、順序を指定してくれる
- 重要:DBMSはウィンドウ関数によるソートの後にRANKを計算しますが、ソートの前にROW NUMBERを計算する
11 Common Table Expressions
- WITH句のお話
- 一般的にサブクエリよりWITH句を使うほうがいい
*WITH句かサブクエリか
- 一般的にサブクエリよりWITH句を使うほうがいい
- Common Table Expressions (CTE) は、より複雑なクエリを作成する際に、ウィン関数やネストされたクエリの代わりに使用することができる
- より大きなクエリの中で、ユーザーを補助するステートメントを記述する方法を提供している
- CTE は1 つのクエリにスコープされた一時的なテーブルと考えることができる
WITH cteName AS (
SELECT 1
)
SELECT * FROM cteName;
- ASの前に出力列を名前にバインドすることができる
WITH cteName (col1, col2) AS (
SELECT 1, 2
)
SELECT col1 + col2 FROM cteName;
# 出力結果
+-------------+
| col1 + col2 |
+-------------+
| 3 |
+-------------+
- 1つのクエリに複数のCTE宣言を含めることができる
- WITHの後にRECURSIVEキーワードを追加すると、CTEが自分自身を参照できるようになる
- これにより、SQLクエリに再帰を実装することができる
- 再帰的なCTEを使用することで、SQLはチューリング完全であることが証明され、より汎用的なプログラミング言語と同等の計算表現力を持つことになります(多少面倒)
例題10-1
Q. 1 から 10 までの数字の並びを出力せよ
WITH RECURSIVE cteSource (counter) AS (
( SELECT 1 )
UNION
( SELECT counter + 1 FROM cteSource
WHERE counter < 10 )
)
SELECT * FROM cteSource;
Lecture #03: Database Storage (Part I)
1 Storage
- データベースの主な保存場所が不揮発性ディスクであると仮定した「ディスク指向」DBMSアーキテクチャに焦点を当てる
- ストレージ階層の最上位には、CPUに最も近いデバイスがある。
- これは最速のストレージだが、同時に最小&最も高価。
- CPUから離れるほど、ストレージデバイスは大きくなるが、速度は遅くなる
- これらのデバイスは、GBあたりの単価も安くなる
- Volatile Devices:
- Volatile(揮発性)とはマシンから電源を抜くとデータが失われることを意味する
- 揮発性ストレージは、バイトアドレスで高速ランダムアクセスをサポートしている
- つまり、プログラムは任意のバイト・アドレスにジャンプして、そこにあるデータを取得することができる
- ここでは、このストレージを "メモリ "と呼ぶ
- Non-Bolatile Devices:
- 揮発性の反対
- 不揮発性とは記憶装置が記憶しているビットを保持するために継続的な電力を必要としないことを意味
- 不揮発性ストレージは、伝統的にシーケンシャルアクセス(同時に複数の連続したデータのチャンクを読む)に優れている
- ここでは、これを "ディスク "と呼ぶことにします。
- ソリッドステートストレージ(SSD)と回転式ハードドライブ(HDD)を(大きく)区別することはしない
- 揮発性の反対