C# 最適化/パフォーマンス/Peanut Butter
やり方の基本
- できるならビルド時最適化を試してみる
- アプリ全体でプロファイルする
- プロファイルでネックが見つかったら細かく比較計測
- Peanut Butterよりアルゴリズム見直し・並列処理化・非同期化・遅延実行
注意点
- ネック箇所の比較計測には BenchmarkDotNet を使う
- 事実上標準
-
System.Diagnostics.Stopwatchは辞める- 理由
- めちゃくちゃ時間かかる処理とかはあり
-
StopWatch.GetElapsedTime()(.NET7+
-
- ランタイム/コンパイラの違いを意識する
- 新しい.NETほど同じソースでも高速
- たとえば、一部の
foreachがforに事前展開されたりしている
- たとえば、一部の
- SharpLab や Compiler Explorer で 展開後のコードやILの違いを確認できる
- Unityのランタイムは標準と違うので注意
- ちょっと古い手法が有効
- 新しい.NETほど同じソースでも高速
-
.NET 8.0以降は計測時に Dynamic PGO のON/OFFに注意
- 良くないコードも Dynamic PGOが効くと最適化されて速くなるから
- 新しい情報収集を忘れずに
- 昔はよかったものももっといい手法・アルゴリズム・ライブラリが出てきたりする
- 内部実装が変わって速くなることがある
- 例
どのやり方をつかう?
重い処理が…
どんな時も
- アルゴリズムの見直し
- 1000倍早くなることもよくある
ネットやファイル読み込みが重い
- 非同期処理 (
async/await) - アルゴリズムの見直し
- 一度に全部呼び出さない・読み込まない
CPUが重い
- 一瞬だけ重い
- 遅延実行( LINQ /
Lazy<T>) - キャッシュ機構
- 遅延実行( LINQ /
- いつでも重い
-
並列処理
- TPL :
ParallelForとか - PLINQ :
AsParallel()で使える並列LINQ - Concurrent Collection : 並列処理用コレクション
- Synchronization Primitives(同期プリミティブ):
semaphoreSlimとかSpinLockとか - パーティショナー:TPL/PLINQ用にデータを分割
- System.Threading.Channels : プロデューサー・コンシューマーパターン
- TPL :
- SIMD命令
- GPUに任せる
- ComputeSharp
- Silk.NET (OpenCV)
- ML.NET
- OpenTK
-
並列処理
調べ方:用語
- 最適化
- 高速化
- optimize / optimization
- performance
- peanut butter
p95 / p99 / p50
-
pは "percentile"(パーセンタイル) の略 - p95は 95th percentile
- 「全リクエストのうち、95% がこの値以下の時間で完了している」という意味
| 指標 | 意味 | 使われる目的 |
|---|---|---|
| p50 | 50パーセンタイル(中央値) | 典型的な(平均的な)性能 |
| p90 | 上位10%が超える遅さ | 遅いリクエストの傾向 |
| p95 | 上位5%が超える遅さ | よく使われる「ほぼ全体の性能」指標 |
| p99 | 上位1%が超える遅さ | 「最悪に近い」パフォーマンス評価 |
| p999 | 上位0.1%が超える遅さ | 超高負荷・リアルタイム用途で注目 |
情報源
記事
- パフォーマンス向上で知っておくべきコンピューターサイエンスの基礎知識とその実践
- 50 C# Optimization Performance Tips - ByteHide Blog
- 7 Simple (Optimization) Tips in C# - DEV Community
- C# の高速化・最適化関連 #C# - Qiita
- C# Code Optimization: Techniques for Faster Software | by Alexandra Grosu | Medium
- C# Performance tips and tricks · Raygun Blog
- 【C#】ループの最適化手法 ③Span<T>編 ~配列をSpan<T>にするだけで早い~ #C# - Qiita
- .NETのパフォーマンス計測ツール「dotnet-trace」の使い方
- C# パフォーマンス改善に使える新しめの機能たち 7.0〜 #C# - Qiita
- Fast File IO with .NET 6
- チュートリアル: ref safety を使用してメモリ割り当てを削減する
- 【C#】分岐最適化時代の Compare の書き方 - てくメモ
- CEDEC 2023 モダンハイパフォーマンスC# 2023 Edition
- 静的クラスは遅いことがあるよ - Speaker Deck
- 今日からできる!簡単 .NET 高速化 Tips -2024 edition-
- neue cc - R3のコードから見るC#パフォーマンス最適化技法実例とTimeProviderについて
- C# + LINQ の速度比較(.NET Framework 4.7 ~ .NET 8)
- .NET Memory Performance Analysis
- C# Optimizations That Boosted Our Application’s Performance
- リストを並列処理で追加するときのパフォーマンス比較 #C# - Qiita
- 【C#】文字列の最適化手法について - Annulus Games
- C#でGPGPU!? CUDAなんかいらなかった with ComputeSharp #ComputeShader - Qiita
- Object Pools in C#: Examples, Internals and Performance Benchmarks | alexeyfv
- Using vectorization in C# to boost performance - RandomDev
- .NET を自在に操る: C# で参照型をスタック割り当てする方法 - DEV Community
- Modern C# Techniques, Part 3: Generic Code Generation
- .NET 9 のパフォーマンス改善
- Unsafe code best practices
- Stop Wasting Memory: 5 Advanced .NET Tricks Nobody Teaches You
- C# パフォーマンス最適化完全ガイド: 少ないリソースでより多くの成果を得る
- Hidden Costs of Boxing in C#: How to Detect and Avoid Them
- What .NET 10 GC Changes Mean for Developers - Roxeem
- How I Reduced API Response Time by 70% in a Large .NET Project
- Parallel Processing in .NET Core: Choosing Between Parallel.ForEach, Task.Run, and Task.WhenAll
- 5 .NET Concurrency Patterns That Actually Scale in Production
- 5 .NET Patterns That'll Save Memory, CPU, and Your Sanity
- Stop Treating Memory Like It's Free: 5 .NET Fixes You Should've Known Years Ago
- DotNet: 9 Versions of .NET Performance Enhancements
- 5 Stream Mistakes Every .NET Dev Makes (And How to Fix Them)
公式MSLearn
公式DevBlog
ビルド時最適化
- そもそもコード中で頑張らなくてもビルド設定でも最適化できる
- まず最初に見直す
-
中間コードJITコンパイルのメリットを捨てて最適化する方法、だったり
- メリットとデメリットの比較が大事!
- .NETなのでC#以外でも有効
【前提】最新の.NETむけに最新の.NETでビルドする
- 新しい.NET SDKでコンパイルするとより最適化されたコードが出力される
- 新しい.NET ランタイムで実行するとより高速な処理になる(SIMD/Dynamic PGOとか)
R2R (Ready To Run)
- 事前コンパイルで起動が早くなる
- この意味ではC#は正確にはJITではなかった
- 結構前から使える
- 最新の技術じゃないので使えることが多い
- ファイルサイズがデカくなる
- …けど今なら別にいいんじゃないかなぁ
- 事前コンパイルなのでプラットホーム依存
<PropertyGroup>
<PublishReadyToRun>true</PublishReadyToRun>
</PropertyGroup>
NativeAOT
- ネイティブバイナリへの事前コンパイル
- PublishTrimがデフォでされるらしく容量も小さめになる
- .NET 7.0以降が公式サポート
-
制限がそこそこある
- リフレクションとかと相性悪い
- そりゃそう
- .NET7だとGUIに対応してない[ウソ]
- これはMAUIとかの話。Avaloniaでいいじゃん。
- モバイル系は.NET 8でも実験的サポート
- リフレクションとかと相性悪い
- 事前コンパイルなのでプラットホーム依存
-
クロスコンパイルできない
- まあそりゃそう
- 中間コードのメリットを捨てて最適化する方法だしね
- x64 - arm64はできることもあるっぽい
- まあそりゃそう
OptimizationPreference
- サイズと速度どちら優先かを選べる
<OptimizationPreference>Size</OptimizationPreference>
<OptimizationPreference>Speed</OptimizationPreference>
IlcInstructionSet / IlcMaxVectorTBitWidth
- 追加のCPU限定命令を有効に出来るオプションがある
<PropertyGroup>
<IlcInstructionSet>native</IlcInstructionSet>
<IlcMaxVectorTBitWidth>512</IlcMaxVectorTBitWidth>
</PropertyGroup>
Dynamic PGO
- .NET 8.0以降 そのままで有効
- .NET 7.0
<PropertyGroup>
<TieredPGO>true</TieredPGO>
</PropertyGroup>
変化の大きいC#の文字列の最適化手法
前提:C#の文字列stringはネックになりがち
- C#の
stringはimmutable - 書き換えは新しい文字列が作られる
- 新しく作られる→ヒープメモリ確保→メモリアロケーション→GCが走りやすくなる
- …でネックになりやすいらしい
文字列最適化手法の変化
古い情報だと「とりあえずStringBuilder」というものが多いけど、最近は色々最適化されるようになってきていて昔の方法が通じないかんじ。
- 昔:
- 「文字列結合は
+を使わずStringBuilderで!」
- 「文字列結合は
-
.NET 8+時代 :
- ある程度固定されてる文字列なら文字列補完を使う
$"abc{val}" -
StringBuilderより文字列補完の中で使われてるDefaultInterpolatedStringHandlerの方が速くなる - 文字列がUTF-8なら(C#内部はUTF-16)、UTF8文字列リテラル(
"あいう"u8)で扱う-
ReadOnlySpan<byte>として扱われる
-
-
String.Create()もある
- ある程度固定されてる文字列なら文字列補完を使う
.NET8+時代の考え方
var yatta = "やったぜ!";
var str = $"""
改行OK! ({yatta})
文字列エスケープ不要! ({yatta})
インデントしてもOK! ({yatta})
""";
-
なるべく
stringのままで扱わない- 最初と最後だけにする
-
ToString()しない - 可能ならそれすらも避ける
-
- (型のサイズ的な意味で)1文字なら
char - もっと最適化するなら
byte/Span<byte>で扱う-
ReadOnlySpan<byte>で文字列 - UTF-8文字列リテラル →参考 「C#12.0 .NET8.0における、Utf8文字列の作り方とパフォーマンス – 技探」
-
- 最初と最後だけにする
String.Intern はそのままだと自作キャッシュに負けるがNativeAOTで逆転
.NET 8.0+ の高速化用新機能・ライブラリ
.NET 8.0
-
System.Collections.Frozen- 「コレクションの作成後にキーと値を変更することができません。 この要件により、読み取り操作を高速化できます」
- nugetで導入できる
-
System.Buffers.SearchValues【C#】SearchValues<char> を測ったら桁違いに速かった - てくメモ- Boosting string search performance in .NET 8.0 with SearchValues
- .NET 9+ではより文字列に対して使いやすくなった
- 前のバージョン向けには公開されてない…
-
System.Text.CompositeFormat- 「コンパイル時に不明な書式指定文字列を最適化する場合に便利」
- 前のバージョン向けには公開されてない…
-
System.IO.Hashing.XxHash3/System.IO.Hashing.XxHash128- 高速ハッシュ生成
- nugetで導入化
-
System.Runtime.Intrinsics.Vector512<T>- AVX-512(SIMD)
- 前のバージョン向けには公開されてない…
-
Parallel.ForAsync-
Parallel.Forの 非同期版 - ForEachAsyncは前からあった
- 前のバージョン向けに公開されてないっぽい
-
.NET 9.0
-
allows ref struct(C#13.0)- 要は ジェネリクスで
Span<T>が使える!-
Memory<T>とかにいちいち変換しなくていい
-
- allows ref struct ライブラリで使用される
- C# 13 allows ref struct - rksoftware
- 言語機能なので少なくともSDKは.NET9+
- 要は ジェネリクスで
- params ReadOnlySpan<T>
- params引数にSpan<T>/ReadonlySpan<T>が使えるように
- 言語機能なので少なくともSDKは.NET9+
-
Lock(System.Threading.Lock)-
lock(){}で使える汎用的な高速ロッククラス - 前のバージョン向けには公開されてないがpolyfilライブラリはある
-
-
OrderedDictionary<TKey, TValue> -
ReadOnlySet<T> -
Regex.EnumerateSplits()- 「ReadOnlySpan<char>を受け取り、結果を表すRangeオブジェクトの列挙可能な値を返します。」
- Regex.EnumerateSplits メソッド
.NET 10.0
-
System.Linq.AsyncEnumerable- 非同期LINQが公式組み込み
- 破壊的変更 - .NET 10 の System.Linq.AsyncEnumerable - .NET | Microsoft Learn
- nugetのSystem.Linq.Asyncを置き換えなので旧バージョンはこちらを使う
決して最速じゃない配列T[]
- C#の配列
T[]は利便性ならList<T>, パフォーマンスならSpan<T>に負ける(ことがある)- .NET 8.0時代だと、なんでもかんでも配列化、はNG
- C#の配列はプリミティブなものだから速い、というわけでもない
- 要素の追加削除で再割り当て
- コピーが発生(メモリアロケーション)
- .NETの内部では
T[]->Span<T>への置き換えが進んでいて高速化が図られている
- バッファで使うなら
new byte[]じゃなくて- サイズが小さいなら
stackalloc byte[]でSpan<T>/ReadOnlySpan<T>で扱う - 大きいorわからないなら
ArrayPool<T>.Shared.Rent()
- サイズが小さいなら
- イディオムまとめました: バッファには
stackalloc+ArrayPool<T>.Shared.Rent()
byte[]? rented = null;
var isSmallBuffer = buffLength <= 256;
Span<byte> buffer = isSmallBuffer
? stackalloc byte[buffLength]
: (rented = ArrayPool<byte>.Shared.Rent(buffLength));
try
{
//ここでバッファをつかう処理をする
DoSomething(buffer);
}
finally
{
if (rented is not null) //ここはisSmallBufferの判定でもOK
ArrayPool<byte>.Shared.Return(rented);
}
- .NET 10+では最適化が掛かって小さい配列は
Span<T>/ReadOnlySpan<T>をstackallocで確保するようになるそう
TaskとValueTask, TupleとValueTuple
- Valueがついてる方が構造体
- パフォーマンスを意識した実装
TaskとValueTask
-
Task<T>の方が古い- クラスなのでムダが…
- awaitしないで抜ける時とか割とよくある
-
ValueTask<T>- 理由がなければこれで
TupleとValueTuple
-
ValueTupleは直接使うことない- タプル記法の中身がこれ
-
Tuple型はクラスでメモリアロケーション- まあつかわないかな(匿名型も)
インライン化阻害防止
反復・例外処理をprivate/local関数化
C# コンパイル結果の IL 命令が32バイトを超える場合、インライン化しない
反復処理を含む場合、インライン化しない
例外処理を含む場合、インライン化しない
ので
反復(forとか)や例外のところだけstaticな(privateやローカル)関数で外に出すとインライン化されやすくなる。
インライン化属性
[MethodImpl(MethodImplOptions.AggressiveInlining)]を付与すると、サイズが小さければインライン化してくれる(こともある)。
インライン化防止属性([MethodImpl(MethodImplOptions.NoInlining)])はベンチマーク取る時に大事。
インライン化すれば必ず早くなるわけじゃないのに注意。
DynamicPGOはその辺動的に判断するらしい。
例外処理用属性
DoesNotReturn
DoesNotReturnIf
PolySharpで古い環境にも入れられる
ThrowHelper/ スローヘルパー 系
System.ThrowHelper
- dotnet内部で使われてる
-
internal:cry: - コードサイズ削減が目的
ThrowIf~系
.NET には、特定の条件 (ArgumentNullException.ThrowIfNull と ArgumentException.ThrowIfNullOrEmpty) で例外をスローするヘルパー メソッドも用意されています。
一部はExceptionクラスのメソッドとして利用できる
- .NET Standard 1.0
- .NET 7.0
- .NET 8.0
- ArgumentException.ThrowIfNullOrEmpty
- ArgumentException.ThrowIfNullOrWhiteSpace
-
ArgumentOutOfRangeException
- ThrowIfEqual
- ThrowIfGreaterThan
- ThrowIfGreaterThanOrEqual
- ThrowIfLessThan
- ThrowIfLessThanOrEqual
- ThrowIfNegative
- ThrowIfNegativeOrZero
- ThrowIfNotEqual
- ThrowIfZero
Microsoft.Toolkit.Diagnostics.ThrowHelper
-
.NET Community Toolkit に例外を外部関数化した
ThrowHelperがライブラリ化されている. - コードサイズも小さくなる。
- Guard APIも
Guard / ガード 系
いわゆる「ガード句」用のライブラリも同じ用途で使える。
CommunityToolkit.Diagnostics.Guard
public static void SampleMethod(int[] array, int index, Span<int> span, string text)
{
Guard.IsNotNull(array);
Guard.HasSizeGreaterThanOrEqualTo(array, 10);
Guard.IsInRangeFor(index, array);
Guard.HasSizeLessThanOrEqualTo(array, span);
Guard.IsNotNullOrEmpty(text);
}
LINQは遅い?
「決して最速じゃない配列T[]」で書いたようにfor文でT[]を色々するよりLINQが早い場合もある。
新しい.NETを使う
- SIMD化などで高速化するものがある
- .NET 7.0
- int/longの
Min()/Max()
- int/longの
-
.NET 8.0
- int/long以外の
Min()/Max() Sum()-
Order()/OrderDescending() - keyが値型の時の
OrderBy()/OrderByDescending() new Dictionary<K, V>(List<KeyValuePair<K, V>>)
- int/long以外の
- .NET 7.0
PLINQで並列処理する
- データ量がある程度多いならforで回すよりPLINQで並列化のほうが効果的
-
Parallel.Forとかでもいいけど…
-
LINQ高速化ライブラリを使う
-
SimdLinq
- SimdLinq - LINQをそのままSIMD対応して超高速化するライブラリ
- .NET 7.0~
- BurstLinq
-
NetFabric.Hyperlinq
- support for
Span<T>,ReadOnlySpan<T>,Memory<T>andReadOnlyMemory<T>
- support for
-
ZLinq
- .NETStandard2.0でもつかえるとか、Linq to tree/Linq to spanができることがメリット
間違った使い方をしない
-
Enumerableで長さを確認するのにAny()を使わない-
Length/Count/IsEmptyプロパティを使う - いつも
Any()つかうな、ではないのに注意。Count()の代わりに推奨されるときも。 - CA1860: 'Enumerable.Any()' 拡張メソッドを使用しない
- アナライザーが教えてくれる
-
-
Count()するまえにEnumerable.TryGetNonEnumeratedCount<TSource>(.NET6+)- 可能なら、列挙しないで長さを取得できる
- 長さを得るためにToList()やToArray()しなくていい
- Enumerable.TryGetNonEnumeratedCount<TSource> Method (System.Linq) | Microsoft Learn
- How does TryGetNonEnumeratedCount work?
- 可能なら、列挙しないで長さを取得できる
LINQ 高速化ライブラリ比較
- .NET8.0ではちょくちょく素のLINQが最速というパターンがある
- 単純なfor/foreachより早いケースも
プロファイル
ベンチマーク
BenchmarkDotNet
-
- 事実上の標準
-
BenchmarkDotNet templates
-
dotnet new benchmarkでテンプレ導入できる
-
-
benchly
-
VBench
-
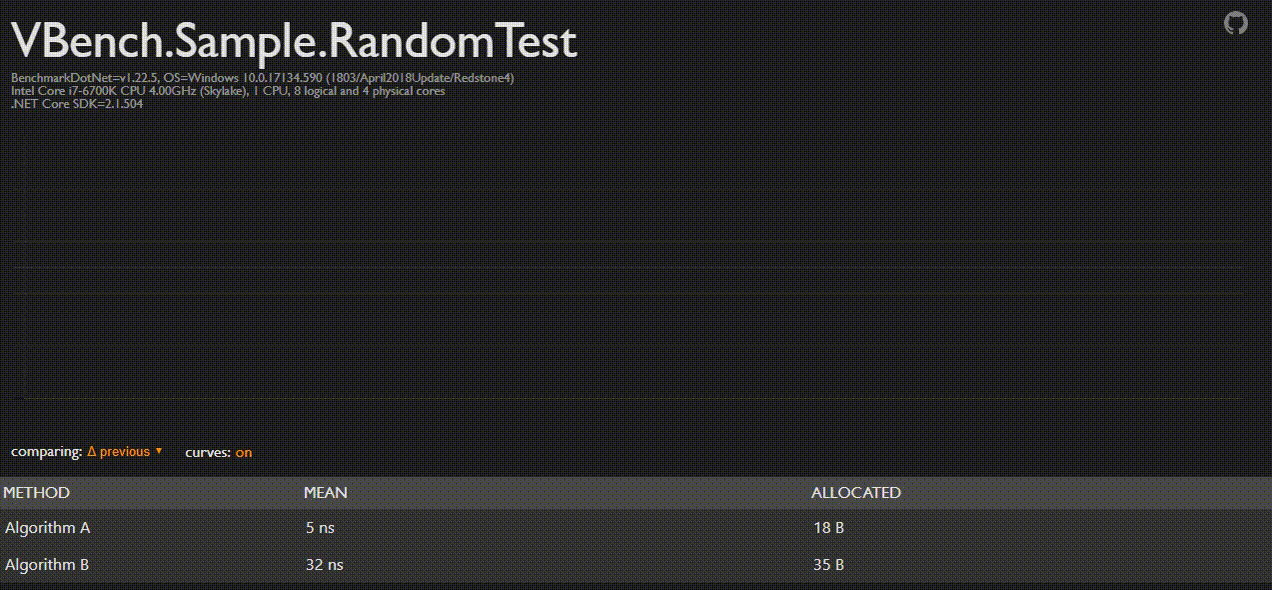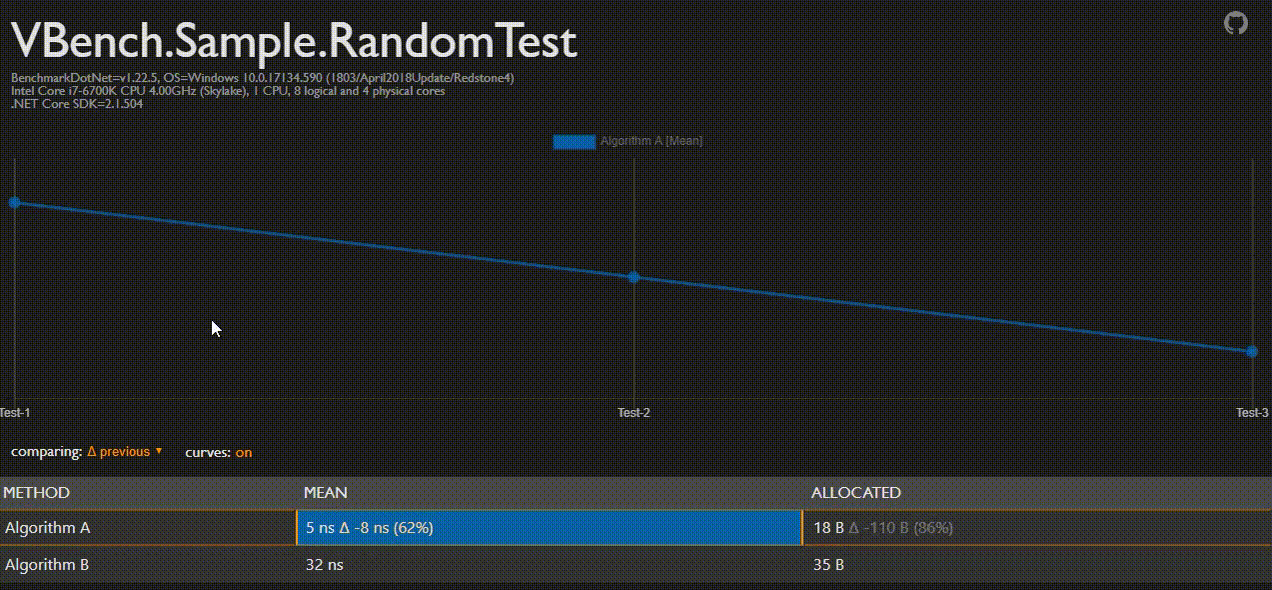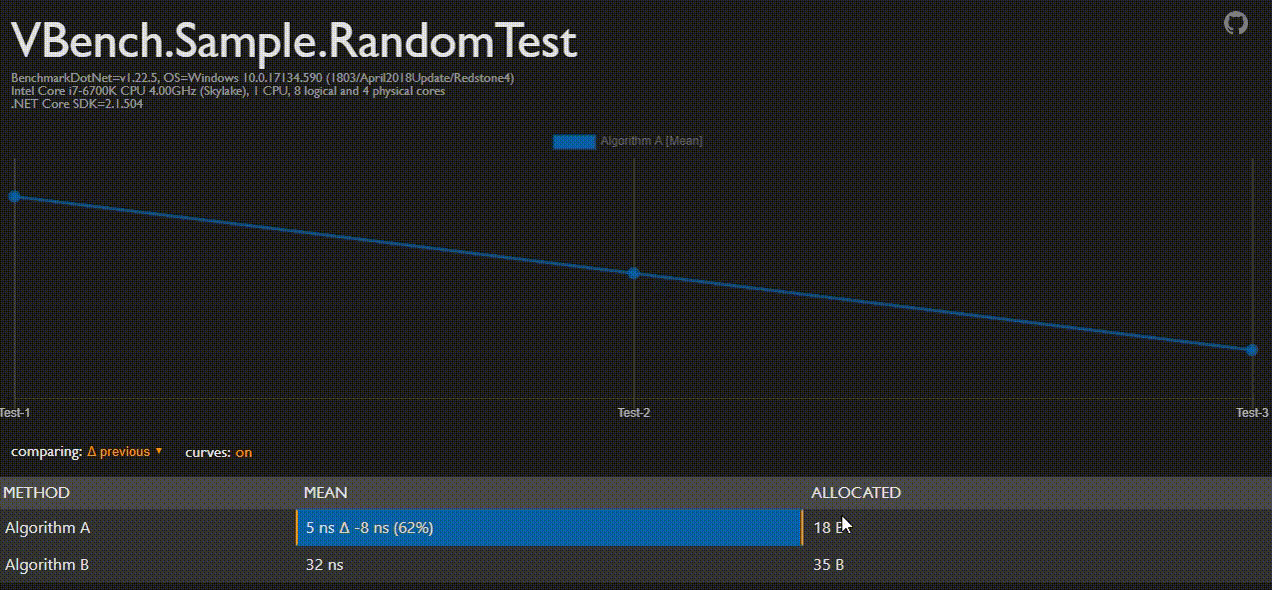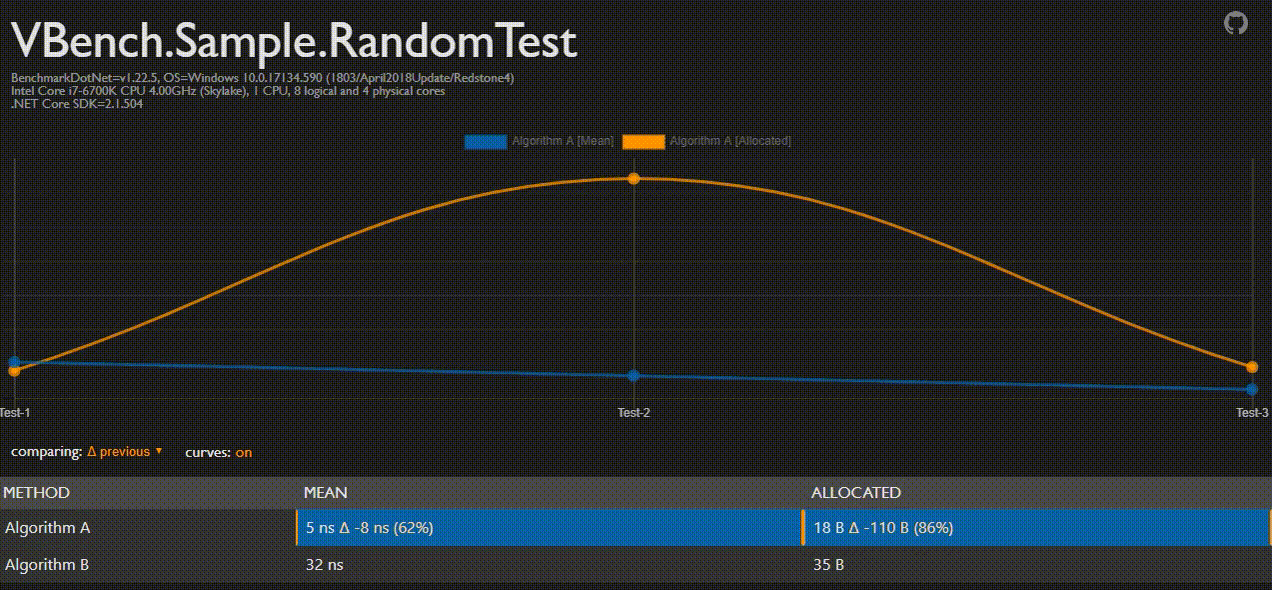
BenchmarkDotNet Analyser (BDNA)
benchmark.net使用時注意
- 複数ランタイムで比較する
- .NET Frameworkと.NETの最新LTS、最新とか
- 内部処理が違うので同じコードでも差がでる
- 可能ならR2R・NativeAOTも比較
- 最新版だけでいいかも
- インライン化を抑制する
- 純粋な処理の差を見るため
[MethodImpl(MethodImplOptions.NoInlining)]
- Dynamic PGOを抑制する
- 純粋な処理の差を見るため
- .NET 8.0~
アプリprofiler
- dotnet-counters
- dotnet-trace
- 公式無料
- dotnet-countersより詳細
- Chromeのプロファイラやspeedscopeで可視化できる
- .NETのパフォーマンス計測ツール「dotnet-trace」の使い方 | Technology | KLablog | KLab株式会社
- dotnet-trace 診断ツール - .NET CLI - .NET | Microsoft Learn
- 公式無料
- Intel VTune
- AMD uProf
- AMD CPUのみ
- AMD μProf | AMD
- PerfCollect
- dotTrace
- 有料
- JetBrains
-
Ultra is an advanced profiler for .NET Applications available on Windows.
- 作者は元Unity社のxoofxさん
ローカルstaticフィールドはReadOnlySpan<T>でできる
void DoSomething(){
//できない
//static int[] arr = {1,2,3};
//staticと同じ扱い
ReadOnlySpan<int> arr = [1,2,3];
}
-
ローカルな
ReadOnlySpan<T>変数をコレクション式で宣言するとstaticと同等になる- コレクション式じゃなくてもOK
-
Tはプリミティブ型に限る
-
読み取りが高速化
- メモリは減らない
-
sharplabで調べたら本当だった
- 現時点だと
__StaticArrayInitTypeSize=12_Align=4っていう自動生成されたクラス内のstaticな構造体になってる
- 現時点だと
[Peanut Butter]Span<T>のコピーで長さの判定を入れると速くなる(.NET8)
if(spanA.Length == 10){
spanA.CopyTo(spanB);
}else{
spanA.CopyTo(spanB);
}
PRが通ってるので.NET 9.0では自動で内部的にこれになりそう。
newしない初期値・リセット
- 初期化・リセットのたびに
newすると遅い - 代わりに空を示すプロパティ・メソッドが用意されてる
- わかりやすくなるメリットも
文字列 string.Empty
-
""の代わり - 現状だとパフォーマンス面であんまり差はないかも?
- わかりやすさは上
配列 Array.Empty<T>()
- メモリアロケーション防止
コレクション Enumerable.Empty<T>()
- メモリアロケーション防止
- .NET8時点では
EmptyPartition<T>.Instanceっていうキャッシュされたゼロenumberableが返ってくるっぽい
リスト ImmutableArray<T>.Empty
-
List<T>.Emptyはない - けど、
ImmutableArray<T>.Emptyならある
-
ReadOnlyCollectionにもある- .NET8以降
- FrozenSet / FrozenDictionaryにもある
Span<T> Span<T>.Empty
- Span<T>, ReadOnlySpan<T>, Memory<T>, ReadOnlyMemory<T>にある
コレクション式で初期化 []
.NET8.0時点では、ケースバイケース。
-
T[]-
Array.Empty<T>()が呼ばれる 👍
-
-
List<T>-
new List<T>()と同じ
-
-
ImmutableArray<T>-
ImmutableCollectionsMarshal.AsImmutableArray(Array.Empty<T>())が呼ばれる
-
-
Span<T>-
default(Span<T>)と同じ
-
-
string- 使用不可
- UTF-8 string
-
default(ReadOnlySpan<byte>)と同じ
-
-
FrozenSet<T>-
FrozenSet.Create(default(ReadOnlySpan<T>));と同じ
-
-
FrozenDictionary<T>- 使用不可
int[] array = []; //Array.Empty<int>();
List<int> list = []; //new List<int>();
ImmutableArray<int> im = []; //ImmutableCollectionsMarshal.AsImmutableArray(Array.Empty<int>());
Span<int> span = []; //default(Span<int>);
//string str = []; //error!
ReadOnlySpan<byte> u8str = []; //default(ReadOnlySpan<byte>);
FrozenSet<int> fset1 = []; //FrozenSet.Create(default(ReadOnlySpan<int>));
半公式の高速化ライブラリ
.NET Community Toolkit
- コミュニティベースのライブラリだが、MSが開発していてMS Learnにリファレンスがある
- 以下がパフォーマンスに影響
- CommunityToolkit.Diagnostics
ThrowHelper-
GuardAPI - →インライン化阻害防止
- CommunityToolkit.HighPerformance
-
Span2D<T>/Memory2D<T> -
MemoryOwner<T>/SpanOwner<T> StringPoolParallelHelper
-
- CommunityToolkit.Diagnostics
.NEXT
.NEXT (dotNext) is the family of powerful libraries aimed to improve development productivity and extend the .NET API with unique features. The project is supported by the .NET Foundation.
- dotnet公式リポジトリで管理されている
Microsoft.IO.RecyclableMemoryStream
System.IO.MemoryStreamに特化したプーリングライブラリ
実行時最適化
Tiered Compilation
P18
- 速度優先(QuickJIT, Tier 0)と最適化優先(Tier 1)に"実行時に"処理が分かれる
- .NET Core 3.0以降
- csproj or runtimeconfig.json or 環境変数で設定変更可能
- R2RでビルドするとTier1に
<TieredCompilation>false</TieredCompilation>
<TieredCompilationQuickJit>false</TieredCompilationQuickJit>
<TieredCompilationQuickJitForLoops>true</TieredCompilationQuickJitForLoops>
On-Stack Replacement
情報
.NET 8 で既定で有効になった Dynamic PGO について - Speaker Deck
.NET の最適化の罠? (インライン展開がされなかった理由) #C# - Qiita
正規表現 GeneratedRegex
-
ソースジェネレータを使う
GeneratedRegexが.NET7以降に追加 -
RegexOptions.Compiledと同じ用途なら置き換え推奨 -
NativeAOT Readyになる
-
起動が早くなる
-
処理も高速に
-
Trimが効くのでサイズが小さくなる
- ただし、ソース生成なので複雑な正規表現は逆に大きくなる
3rd party performance / optimization libs
Algorythm
- LibOptimization : LibOptimization is numerical optimization algorithm library for .NET Framework. / .NET用の数値計算、最適化ライブラリ
Cache
- LazyCache : An easy to use thread safe in-memory caching service with a simple developer friendly API for c#
GPGPU / Compute shader
- ComputeSharp : A .NET library to run C# code in parallel on the GPU through DX12, D2D1, and dynamically generated HLSL compute and pixel shaders, with the goal of making GPU computing easy to use for all .NET developers! 🚀
SIMD
- HPCsharp : High performance algorithms in C#: SIMD/SSE, multi-core and faster
IL
- DistIL : Post-build IL optimizer and intermediate representation for .NET programs
コレクション(配列・List<T>・Span<T>・etc...)の標準最適化用API
プーリング / pooling
※コレクションでなければObjectPoolがある
-
ObjectPool<T>MSLearn LeakTrackingObjectPool<T>
キャッシュ / cache
- Microsoft.Extensions.Caching.Memory.MemoryCache
-
ConditionalWeakTable<TKey, TValue>
- メモリに残り続ける問題を弱参照で解決する
- コレクションでないなら
WeakReference<T>
パイプライン / pipeline
- Pipe / PipeReader / PipeWriter
- 高速なバイトストリームI/OをGC負荷少なく扱う用
-
StreamPipeReader- 巨大ファイルI/Oやネットワークストリーム用
バッファ / buffer
- ReadOnlySequence<T>
- SequenceReader<T>
Span<T>/Memory<T>もバッファ用途に使える
- Span<T> / ReadOnlySpan<T>
- Memory<T> / ReadOnlyMemory<T>
前述のArrayPool<T>もバッファ用途で使われる → 「決して最速じゃない配列」
文字列・ファイル
-
SearchValues<T>- 複数の候補文字を高速検索するための構造体
-
Utf8Formatter/Utf8Parser- 数値・日付などの型をUTF-8エンコードのバイト列で直接フォーマット/パース
-
Utf8JsonReader/Utf8JsonWriter- JSONをUTF-8バイト列として直接読み書き
-
MemoryMappedFile- 巨大ファイルをメモリ空間に直接マップして扱う
チャネル / channel
- Channel<T>
- プロデューサー/コンシューマーパターン
- 高性能スレッドセーフなキュー
- ChannelReader<T> / ChannelWriter<T>
コンカレント / concurrent
Concurrent collection (System.Collections.Concurrent)を使う。
- ConcurrentDictionary<TKey, TValue>
- ConcurrentQueue<T>
- ConcurrentBag<T>
- BlockingCollection<T>
Immutable collection系、Fronzen collection系もスレッドセーフ用途で利用できる。
- ImmutableArray<T>
- ImmutableDictionary<TKey,TValue>
- FrozenSet<T>
- FrozenDictionary<TKey,TValue>
パラレル / parallel
- Dataflow
- Partitioner<T>
- OrderablePartitioner<T>