『Go言語による並行処理』をやっていく会
README
ゴルーチンとか並行処理とかそのへん理解したい〜 くらいのテンション。別に並行処理で困っていることがあるわけではない。
一緒に本を読みながらあーだこーだしたい人も募集中です!
「一緒に本を進めようぜ!」的な気持ちが湧いたら、https://twitter.com/mohirara まで連絡もらえると嬉しいです(DMでもメンションでもなんでも!)
Scrap内リンク
- 第1章 並行処理入門
- 第2章 並行性をどうモデル化するか: CSP とは何か
- 第3章 Go における並行処理の構成要素 3.1 ゴルーチン(goroutine)
- 第3章 3.2 3.2.1
sync.WaitGroup3.2.2sync.Mutex - 第3章 3.2.3
sync.Cond - 第3章 3.2.4
sync.Once - 第3章 3.3 チャネル(channel)
- 第3章 3.4 select文
- 第4章 4.1 拘束(Confinement)
- 第4章 4.2 for-selectループ
- 第4章 4.3 ゴルーチンリークを避ける
- 第4章 4.4 orチャネル
- 第4章 4.5 エラーハンドリング
- 第4章 4.6 パイプライン
- 第4章 4.6.1 パイプライン構築のためのベストプラクティス
- 第4章 4.6.2 便利なジェネレーターをいくつか
- 第4章 4.7 ファンアウト、ファンイン
- 第4章 4.8 or-doneチャネル
- 第4章 4.9 teeチャネル
- 第4章 4.10 bridgeチャネル
- 第4章 4.11 キュー
- 第4章 4.12 contextパッケージ
- 第5章 大規模開発での並行処理 5.1 エラー伝播
- 第5章 5.2 タイムアウトとキャンセル処理
- 第5章 5.3 ハートビート
- 第5章 5.4 複製されたリクエスト
- 第5章 5.5 流量制限
- 第5章 5.6 不健全なゴルーチンを直す
- 第6章 ゴルーチンとGoランタイム
- 第6章 6.1 ワークスティーリング
- 第6章 6.1.1 タスクと継続どちらを盗むのか
- 第6章 6.2 すべての開発者にこの言葉を贈ります
第1章 並行処理入門
紙書籍に書き込んでいた。Zennにまとめるかはまた今度決める。
1.2がめっちゃ面白い。
第2章 並行性をどうモデル化するか: CSP とは何か
紙書籍に書き込んでいた。Zennにまとめるかはまた今度決める。
- 並行性と並列性の議論は激アツ
- ゴルーチンが並行処理をデザインするための道具であるという位置づけの話が嬉しい
- ゴルーチンは並行処理モデリングのための有用な道具って感じ
- ゴルーチンは湯水のごと使え!
第3章 Go における並行処理の構成要素 3.1 ゴルーチン(goroutine)
- ゴルーチンってなに?
- ゴルーチンを理解するための周辺概念4つを区別するべし
- ゴルーチン(Goroutine)
- コルーチン(Coroutine) ← 名前もスペルも似ているのでややこしいね!
- OSスレッド
- グリーンスレッド(言語のランタイムにより管理されるスレッド)
- 重要っぽい概念
- プリエンプティブ と ノンプリエンプティブ
- スケジューリング
ゴルーチン使ってないと思った? 残念! 絶対に最低1つのゴルーチンがあるんやで!
- メインゴルーチンだよ
-
goというキーワードがないコードも、実はゴルーチンがあったわけよ - ガベージコレクションやソフトウェア割り込みのためのゴルーチンも自動で起動しているらしい
ゴルーチンは並行性の話で、必ずしも並列とは限らんぞ!
ゴルーチンは他のコードに対し並行に実行している関数のことです。
p.23の言葉を思い出してほしいぞ!
並行性は、コードの性質
並列性は、動作しているプログラムの性質
雑な感じで、「ゴルーチンは並行だか並列に処理するよ〜」みたいな言い回しはマジで危険やな!
ゴルーチンは、コルーチンの1種。ゴルーチンはOSスレッドではない。ゴルーチンはグリーンスレッドでもない。
この3つは、ゴルーチンを理解する上で重要な区別だと思う。
- ゴルーチンは、コルーチンの1種である
- ゴルーチンは、OSスレッドではない
- ゴルーチンは、グリーンスレッドではない
OSスレッド
たぶん、OSが管理している(?)スレッドのこと。OSのプロセスの中に存在するやつ。意外と説明ができない
グリーンスレッド
グリーンスレッドは、言語のランタイムにより管理されるスレッド(p.38)
ほう。要は、OSスレッドではないという話。
グリーンスレッド(英: green threads)とは、コンピュータプログラミングにおいて、オペレーティングシステムではなく仮想マシン (VM) によってスケジュールされるスレッドである。(Wikipedia)
コルーチン(Coroutine)
コルーチンは、プリエンプティブでない並行処理のサブルーチン
Goでは関数、クロージャ、メソッドに相応です
つまり、割り込みをされることがないということです。
プリエンプティブ?
プリエンプティブとノンプリエンプティブは、共にマルチタスクOS上で実行されているプログラムを切り替えるときの方式です。
https://www.ap-siken.com/kakomon/26_haru/q16.html
プリエンプティブ
OSがCPUやシステム資源を管理し、CPU使用時間や優先度などによりタスクを実行状態や実行可能状態に切り替える方式。
OSがうまいことスケジューリングしたり、なんかいろいろやることを切り替えてくれるやつ?
ノンプリエンプティブ(==プリエンプティブでない)
実行プロセスの切替をプログラム自身に任せる方式で、プログラムが自発的にCPUを開放した時間でほかタスクを実行する。OSがCPUを管理しないので、1つのプログラムを実行中は、ほかのプログラムの実行は制限される。
コルーチンはこっち。
ゴルーチンの独特ポイント: ゴルーチンとGoのランタイムが密結合している
(「独特」というキーワードは学習するときにありがたいけど、比較の土台ができてないからちょっとアレ)
ゴルーチンは一時停止や再エントリーのポイントを定義していない。
ランタイムがうまいこと、一時停止や再エントリーをやってくれるらしい。
というか、Goプログラマがそれを直接いじれないような設計になっている(==エントリーポイントが提供されてない)。
ありがたや。
「密結合」っていうと、ネガティブニュアンスで捉えようとしちゃうけど、ゴルーチンとGoランタイムの関係でいえば、"ありがたい"密結合だと思うな〜。
コルーチン(Coroutine)については、Pythonで遊ぶといいかもしれん
(コルーチン) コルーチンはサブルーチンのより一般的な形式です。
コルーチンのほうが抽象度が高いってこと。
サブルーチンには決められた地点から入り、別の決められた地点から出ます。
これ(=サブルーチン)はいつものやつって感じ。これが基準。まあ、関数とか普通に書くとただのサブルーチンって感じ。
で、考えてみれば、どの地点から始めたっていいわけだよね。あるいは、途中で出ていったっていいよね。ただの関数とかのサブルーチンから学ぶから、途中の出入りがおかしく感じられるけど、別にその制限をなくしたっていいわけじゃんね。
コルーチンには多くの様々な地点から入る、出る、再開することができます。 コルーチンは async def 文で実装できます。 PEP 492 を参照してください。
ここが、「一時停止や再エントリー」とかって言われているところかな。
コルーチン使っているけど、別に並行"ではない"やつ
import asyncio
import time
async def say_after(delay: int, what: str) -> None:
await asyncio.sleep(delay)
print(what)
async def main():
# 合計で約4秒かかる
# sleep(2) → hello出力 → sleep(2) → world出力
print(f"started at {time.strftime('%X')}")
await say_after(2, 'hello')
await say_after(2, 'world')
print(f"finished at {time.strftime('%X')}")
if __name__ == '__main__':
asyncio.run(main())
コルーチンを並行にスケジュールしたやつ
import asyncio
import time
async def say_after(delay: int, what: str) -> None:
await asyncio.sleep(delay)
print(what)
async def main():
# 約2秒ちょっとで動く(早くなった!)
# asyncio.create_task() で「コルーチン」を並行にスケジュールしているから
task1 = asyncio.create_task(say_after(2, 'hello'))
task2 = asyncio.create_task(say_after(2, 'world'))
print(f"started at {time.strftime('%X')}")
await task1
await task2
print(f"finished at {time.strftime('%X')}")
if __name__ == '__main__':
asyncio.run(main())
並行性はコルーチンの性質ではない話
コルーチン、また結果としてゴルーチンは、暗黙的には並行処理の構成要素ですが、並行性というのはコルーチンの性質ではありません。(p.39)
コルーチンの性質は、あくまで、自由な出入りってことかな? あるいは、中断と再開(書籍の言葉で言えば、一時停止と再エントリー)
次のページの説明が最強かもしれん。
コルーチン
一般に、ジェネレータ (generator) は呼び出されるたびに新しい値を生成して返す関数のことをいいます。このような処理をさらに一般化して、**複数のプログラム間で実行の中断や再開を相互に行わせることができます。このようなプログラムのことを「コルーチン (co-routine)」**といいます。
ほうほう。
サブルーチン (sub-routine) は call してから return するまで途中で処理を中断することはできませんが、コルーチンは途中で処理を中断し、そこから実行を再開することができます。
サブルーチンを一般化すると、コルーチンになる感じ。わかってきた。
また、コルーチンを使うと複数のプログラムを (擬似的に) 並行に動作させることができます。この動作は「スレッド (thread)」とよく似ています。
そう、この時点だと、コルーチンとスレッドが区別できない。はてさて、どうやって峻別する?
通常、スレッドは一定時間毎に実行するスレッドを強制的に切り替えます。このとき、スレッドのスケジューリングは処理系が行います。これを「プリエンプティブ (preemptive)」といいます。
OSがうまいこと管理してくれる系の話だと思う。「処理系」って書いてあるけど、多分OSとかも含めてよさそう(このへん曖昧)。
コルーチンの場合、プログラムの実行は一定時間ごとに切り替わるものではなく、プログラム自身が実行を中断しないといけません。これを「ノンプリエンプティブ (nonpreemptive)」といいます。
ここが、コルーチンとスレッドを区別するポイント! 要は、実行とか中断とか再開をプログラムしないといけないってことだと思う。
Pythonの例を見るとわかりやすい。つまり、コルーチンを使っている(=asyncとか使っている)けど、別に並行じゃないプログラムもかけるわけだよね。
コルーチンで複数のプログラムを並行に動作させるには、あるプログラムだけを優先的に実行するのではなく、他のプログラムが実行できるよう自主的に処理を中断する、といった協調的な動作を行わせる必要があります。
コルーチンはNonプリエンプティブだから、並行処理をやるにはうまいこと管理しないといけないのが負担ポイント。
そのかわり、スレッドと違って排他制御といった面倒な処理を考える必要がなく、スレッドのような切り替え時のオーバーヘッドも少ないことから、スレッドよりも動作が軽くて扱いやすいといわれています。
こっちはコルーチンの嬉しいポイント(スレッドと比べて)
並行性はコルーチンの性質ではない話を再び考える
コルーチンとか、ノンプリエンティブとかの話がわかったところで、戻りましょう。
コルーチン、また結果としてゴルーチンは、暗黙的には並行処理の構成要素ですが、並行性というのはコルーチンの性質ではありません。(p.39)
これは、「コルーチン」を使ったからと言って、必ずしも並行性を獲得できない(=並行なプログラムにはならない)ってことだと思っている。
くどいけど、Pythonのコードの1つ目の例がまさにそう。
コルーチンは、中断とか再開できる能力を持ったサブルーチンってだけ。並行とかそんなんじゃない。中断とか再開できる性質が並行処理に貢献するってだけ。
並行である場合には、何かが複数のコルーチンを同時管理して、それぞれに実行の機会を与えなければなりません。―さもなければ、ゴルーチンが並行になることはありません!
コルーチンは、ノンプリエンプティブだからね。つまり、勝手にうまいことスケジューリングしてくれて、各コルーチンを実行したり中断したり再開してくれる誰かが存在しない。
fork-joinモデル
forkはシステムコールのfork()って感じ。
合流ポイントがない例
- ゴルーチン2(子)はGoランタイムにスケジュールされるけど、mainゴルーチンが終了するまでに、実行する機会が得られない(=
fmt.Println("ゴルーチン2")が実行されない)ままプログラム全体が終了する
package main
import "fmt"
func main() {
fmt.Println("mainゴルーチンはじまるよ〜")
go sayHello()
fmt.Println("mainゴルーチンおわるよ〜")
}
func sayHello() {
fmt.Println("ゴルーチン2")
}
合流ポイントがないからってtime.Sleepで解決しようとするな!
time.Sleepによって実現されるのは、ゴルーチン2が実行される確率を高めるだけ。確率を高めるだけで根本的な解決じゃない。ゴルーチン2の実行は保証されない。競合状態は解決していない。
p.4辺読んでね。
合流ポイントを作って、競合状態を正しく解決する
- 非決定的だったものが、決定的になった!
- これはすごいことですぞ!
package main
import (
"fmt"
"sync"
)
// p.40 2つのゴルーチンの間に合流ポイントを作った例
func main() {
fmt.Println("mainゴルーチンすたーと")
var wg sync.WaitGroup
wg.Add(1)
sayHello := func() {
fmt.Println("hello")
wg.Done()
}
go sayHello()
wg.Wait()
fmt.Println("mainゴルーチンおわり〜")
}
ゴルーチンはそれが作られたアドレス空間と同じ空間で実行される
ん?
おもしろいこと! とは感じられなかった。アドレス空間が同じってことはすごいことなのか? わからん。
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
salutation := "hello" // salutationは「あいさつ」とか「敬礼」とかって意味らしい
wg.Add(1)
go func() {
defer wg.Done()
salutation = "welcome"
fmt.Println(salutation, &salutation)
}()
wg.Wait()
fmt.Println(salutation, &salutation)
}
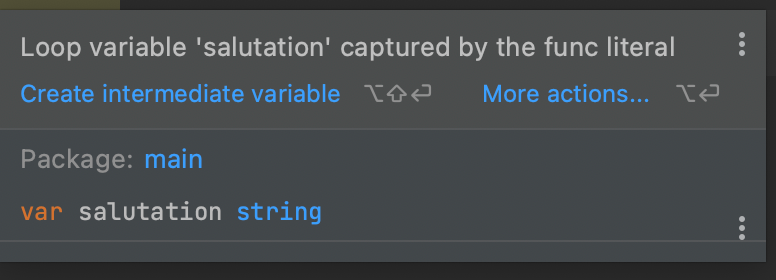
厄介な例
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
for _, salutation := range []string{"hello", "greetings", "good day"} {
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println(salutation)
}()
}
wg.Wait()
}
$ go run ch3/3.1/4/main.go
good day
good day
good day
こうはならない
# 順不同に hello greetings good day が出力されそうな気がするが、こうはならない
$ go run ch3/3.1/4/main.go
greetings
hello
good day
仕組み: ゴルーチンが実行されるタイミングより早くforループが終了するから!
forループが終了する、つまり、salutationが指す値はgood day(文字列スライスの末尾の要素)になるわけ。
で、forループ内の3つのゴルーチンは全員salutationが見えている。
で、ある時刻で、3つのゴルーチンそれぞれが実行されるけど、そのときはすでに、salutaionはgood dayになっているので、good dayが3回出力されるオチ。
GoLandでも警告がでるね
クロージャーをでうまいこと解決した例
なんかわかってきた感じある。アドレス空間的な話が。
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
for _, salutation := range []string{"hello", "greeting", "good day"} {
wg.Add(1)
go func(salutation string){
fmt.Println(salutation)
wg.Done()
}(salutation)
}
wg.Wait()
}
でもやっぱり謎なフレーズもある
ゴルーチンはお互いにアドレス空間を操作していて、単純に関数をホストしているため、ゴルーチンを使うことは並行でないコードを書くことの自然な延長になっています。
うーん、
「並行でないコードを書くかのように、わりと素直に書ける」っていうことかな? 言わんとしていることは。
Goのコンパイラがうまいことやってくれる
Goのコンパイラはうまい具合に変数をメモリに割り当ててくれて、ゴルーチンが開放されたメモリに間違ってアクセスしてしまわないようにします。
ありがたや〜。よくわからんけど、高性能なんだろうな。そこを知りたい的なところもあるけど、それはまあいつかですな。
これによって開発者がメモリ管理でなく問題空間に集中できます。
やっぱ大変なんだろうな。メモリがどうこうなっているとか、うまいことやるのは。
ゴルーチンはスレッドと比べてハチャメチャに軽量。湯水の如く使うのだ!
スレッドはメガバイト、ゴルーチンはキロバイト
OSTスレッドのデフォルトスタックサイズに関してはOSTによって変化しますが、例えば翻訳時現在、Windowsは1MB、POSIXスレッドはLinuxでは2MBなどと、メガバイト単位にされているのに対し、Goでは通常ゴルーチンは最小で2KBに設定されています(†4より)
並行処理を実現することを考えたときに、スレッドと比べてめっちゃお得やん! すごいやん
ガベージコレクタは「ブロックされた状態」のゴルーチンを回収しない。なーんもしない。
package main
func main() {
ch := make(chan int)
// ずーっと受信を待つゴルーチン
go func() {
<-ch
}()
}
このコードがあっても別に何もしない。
このゴルーチンはプロセスが終了するまで存在するだけ。
プロセスが終了したら、ゴルーチンもバイバイ。
コンテキストスイッチの速度を調べる
結果だけを比較する
- OSのコンテキストスイッチ: 1.916551マイクロ秒(==3.833102マイクロ秒/2)
- ゴルーチンのコンテキストスイッチ 120n秒 = 0.120マイクロ秒
めっちゃはやいぞゴルーチン!
[root@a16aa2563528 /]# taskset -c 0 perf bench sched pipe -T
# Running 'sched/pipe' benchmark:
# Executed 1000000 pipe operations between two threads
Total time: 3.833 [sec]
3.833102 usecs/op
260885 ops/sec
$ go test -bench=. -cpu=1 ch3/3.1/8/context_switch_test.go
goos: darwin
goarch: amd64
cpu: VirtualApple @ 2.50GHz
BenchmarkContextSwitch 9939310 120.1 ns/op
PASS
ok command-line-arguments 1.771s
p.46 perfコマンドのインストールと実行(Docker)
docker run --rm -it centos:centos7 bash
yum update -y
yum install -y perf
Go
package main
import (
"sync"
"testing"
)
func BenchmarkContextSwitch(b *testing.B) {
var wg sync.WaitGroup
begin := make(chan struct{})
c := make(chan struct{})
var token struct{}
sender := func() {
defer wg.Done()
<-begin
for i := 0; i < b.N; i++ {
c <- token
}
}
receiver := func() {
defer wg.Done()
<-begin
for i := 0; i < b.N; i++ {
<-c
}
}
wg.Add(2)
go sender()
go receiver()
b.StartTimer()
close(begin)
wg.Wait()
}
第3章 3.2 3.2.1 sync.WaitGroup 3.2.2 sync.Mutex
sync.WaitGroup
WaitGroupはひとまとまりの並行処理があったとき、その結果を気にしない、もしくは他に結果を収 集する手段がある場合に、それらの処理の完了を待つ手段として非常に有効です
sync.WaitGroupは意外とちっちゃいぞ!
$ go doc sync.WaitGroup
package sync // import "sync"
type WaitGroup struct {
// Has unexported fields.
}
A WaitGroup waits for a collection of goroutines to finish. The main
goroutine calls Add to set the number of goroutines to wait for. Then each
of the goroutines runs and calls Done when finished. At the same time, Wait
can be used to block until all goroutines have finished.
A WaitGroup must not be copied after first use.
func (wg *WaitGroup) Add(delta int)
func (wg *WaitGroup) Done()
func (wg *WaitGroup) Wait()
A WaitGroup waits for a collection of goroutines to finish.
WaitGroupは、ゴルーチンのコレクションが完了するのを待機する。そのままやな。
The main goroutine calls Add to set the number of goroutines to wait for.
メインゴルーチンがWaitGroup.Add()を読んで、何個のゴルーチンを待つかを決めますよ〜。
Then each of the goroutines runs and calls Done when finished.
それぞれのゴルーチンが動いて、WaitGroup.Done()を呼ぶわけ。で、そのWaitGroup.Done()はゴルーチンが終わったときに呼ぶようにする。
At the same time, Wait can be used to block until all goroutines have finished.
と、同時に、WaitGroup.Wait()は、すべてのゴルーチン(要は、何個待つか決めた数ね)が終了するまで、処理をブロックしまっせ。
A WaitGroup must not be copied after first use.
コピーしたらあかんやつ!
あとで追記
コピーしたらイケナイ系のやつ
go vet の話とかも書く
sync.WaitGroupの単純な例
- 「並行処理で安全なカウンター」と考えることもできる
-
Add()でカウントアップして、Done()でカウントダウンって感じ
-
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("1st goroutine sleeping...")
time.Sleep(1 * time.Second)
}()
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("2nd goroutine sleeping...")
time.Sleep(2*time.Second)
}()
wg.Wait()
fmt.Println("All goroutine complete")
}
wg.Add()は、監視対象のゴルーチンの外でやらないと「競合状態」になるぞ!
おさらい: 競合状態ってなんだっけ?
競合状態は、2つ以上の操作が正しい順番で実行されなければいけないところで、プログラムが順序を保証するように書かれていなかったときに発生します。
競合状態をわざと起こしたコード
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
go func() {
wg.Add(1) // Addの呼び出しをゴルーチン内部でやってしまっている! → 競合状態!
defer wg.Done()
fmt.Println("1st goroutine sleeping...")
time.Sleep(1 * time.Second)
}()
go func() {
wg.Add(1) // Addの呼び出しをゴルーチン内部でやってしまっている! → 競合状態!
defer wg.Done()
fmt.Println("2nd goroutine sleeping...")
time.Sleep(2*time.Second)
}()
wg.Wait()
fmt.Println("All goroutine complete")
}
# 1st と 2ndの出力がないまま終了してしまっている!
# Add(1) される前に、Wait()呼ばれた場合こうなる
# なんにもAddしてないなら、Wait()は素通りだよね
$ go run main.go
All goroutine complete
つまり、これと同じことになるかもしれない
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Wait()
fmt.Println("All goroutine complete")
}
Mutex は Mutual Exclution、つまり「相互排他」の略
- mutualは mjúːtʃuəl(米国英語) と発音する
- この略は慣れだなw
おさらい: クリティカルセクションってなんだっけ?
p.8
プログラム内で共有リソースに対する排他的なアクセスが必要な場所には名前があります。
それはクリティカルセクションと呼ばれています
トランザクションのスコープって感じだよね。
いろんな人(プログラム)が同時にアクセスするとやべーことになるところ。
p.49
クリティカルセクションは、プログラムが共有リソースに排他的アクセスを必要とする場所のことでした。
他の人の定義
クリティカルセクションとは、複数のプログラムが並行して実行されているとき、共有資源に同時にアクセスすることで不具合が生じる危険があるプログラム上の箇所のこと。また、そのような箇所を指定して同時に実行しないようにする制御を指すこともある。
チャネルは「通信」でメモリ共有、ミューテックスは「慣習」でメモリ共有
こういう比較もできるのか! なるほど。
慣習というか性善説はなかなか大変だね。
だからといってミューテックスがチャネルより劣るとかそういう話でもねーからな!
sync.Mutexも小さい構造体
$ go doc sync.Mutex
package sync // import "sync"
type Mutex struct {
// Has unexported fields.
}
A Mutex is a mutual exclusion lock.
The zero value for a Mutex is an unlocked mutex.
A Mutex must not be copied after first use.
func (m *Mutex) Lock()
func (m *Mutex) Unlock()
sync.Lockerインタフェース
$ go doc sync.Locker
package sync // import "sync"
type Locker interface {
Lock()
Unlock()
}
A Locker represents an object that can be locked and unlocked.
めも: MutexとRWMutexは、もっと小さい例も含めてゆっくりやったほうがいいね
「ロックをとる」という表現になれよう
sync.Mutexはコピーしちゃだめだよ
- コンパイルは通るが、警告がでる
- ちなみにPlayGroundでの実行は
go vetしてくれている
package main
import (
"sync"
)
// sync.Mutex をコピーする
// コンパイルは通るが、警告がでる
func main() {
var m1 sync.Mutex
var m2 sync.Mutex
m2 = m1 // assignment copies lock value to m2: sync.Mutex
_ = m2 // assignment copies lock value to _: sync.Mutex
}
$ go build main.go # Buildはできる
# go vet で検査すると...
$ go vet main.go
# command-line-arguments
3.2.4/5/main.go:11:7: assignment copies lock value to m2: sync.Mutex
3.2.4/5/main.go:12:6: assignment copies lock value to _: sync.Mutex
copylockってやつがうまいことチェックしてくれている
strings.Builderもコピー撮っちゃだめ! そして、コピーガードが入っている!
-
strings.Builderがコピーされては行けない理由は、内部にスライス(配列へのポインタ)をもっているから
$ go doc strings.Builder
package strings // import "strings"
type Builder struct {
// Has unexported fields.
}
A Builder is used to efficiently build a string using Write methods. It
minimizes memory copying. The zero value is ready to use. Do not copy a
non-zero Builder.
Q. strings.Builer.copyCheck()でpanicになるケースを再現したいけど、どうやってやればいいんだ?
並行処理と並列処理をPythonの実装で見比べると理解深まりそう
並行処理を考えるときに重要っぽい単語 CPUバウンド / IOバウンド
よくでてくる
第3章 3.2.3 sync.Cond
第3章 3.2.4 sync.Once
sync.Once: 関数を、確実に、一度だけ、呼び出すことができる機能
sync.Onceは内部的にsyncの何らかのプリミティブを使って、Do()に渡された関数が―たとえ異なるゴルーチンで呼ばれたとしても―一度しか実行されないようにする型です。(p.58)
$ go doc sync.Once
package sync // import "sync"
type Once struct {
// Has unexported fields.
}
Once is an object that will perform exactly one action.
A Once must not be copied after first use.
func (o *Once) Do(f func())
Once is an object that will perform exactly one action.
sync.Onceは、確実に1つのアクションだけを実行するオブジェクトですよ。
A Once must not be copied after first use.
一回使ったら、コピーしたらあかんぜよ
sync.Onceの実装例その2
- https://pkg.go.dev/sync#Once の example
package main
import (
"fmt"
"sync"
)
// https://pkg.go.dev/sync#Once
func main() {
var once sync.Once
onceBody := func() {
fmt.Println("Only once")
}
// 単一チャネルで管理
// 『Go言語による並行処理』では sync.WaitGroup 使ってた
done := make(chan bool)
for i := 0; i < 10; i++ {
go func() {
once.Do(onceBody)
done <- true
}()
}
for i := 0; i < 10; i++ {
<-done
}
}
「sync.Once.Do()で確実に一度だけ実行」と言われて「はい、そーですか」とはいかないぜよ! 中身を見ましょう(Go1.12)
実装が単純だった Go1.12 のコードをみてみる
(Go1.16だと最適化とか入っているらしく、ちょっとややこしいので見ない)
sync.Onceの内部構造
-
sync.Mutexとdoneだけ -
sync.Mutexがあるのは、「一度だけ実行する」ときにロックを勝ち取る必要があるからだと思う
// Once is an object that will perform exactly one action.
type Once struct {
m Mutex
done uint32
}
sync.Once.Do() の実装
基本的にsync/atomicを使っている! そりゃそうだ。
func (o *Once) Do(f func()) {
// 1. `Once.done`が1なら、即returnで関数fは呼ばれない
// o.done == 1 をアトミックにしただけ
if atomic.LoadUint32(&o.done) == 1 {
return
}
// Slow-path.
// 2. ロックをとる
o.m.Lock()
// 3. 終わったらロックを解除
defer o.m.Unlock()
// 4. ここで、doneかどうかを確認する
// この時点でロックをとっている == 1つのゴルーチンしかこないので、
// `o.done==0`は、`sync/atomic`を使わない比較でOKっぽい
if o.done == 0 {
// 5. deferにしているので、panicしたとしても実行したことになる
// もし関数をfを実行したときにpanicが起きても、doneの値は1に設定される
// つまり、このOnceインスタンスは、もう関数は実行しない
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
Mutexは何を守っているか?
Mutexがいない世界を考える(==ロックをとらなかったらどうなる?)
- 「誰か」がDoをした
- まだ、
o.doneのフラグたってない(例えば、f()が処理時間かかるとかね) -
f()の処理中に、「別の誰か」がDoをした! - 「別の誰か」は
o.done==0の条件を通過するので、Doできちゃう! - 悲しさがあふれる
というわけで、ロックをかけていない場合、f()が複数回実行されちゃうわけ
Mutexが守ってくれる世界
- 「誰か」がDoをした
- その「誰か」がロックをとった(ガチャり)
- まだ、
o.doneのフラグたってない(例えば、f()が処理時間かかるとかね) -
f()の処理中に、「別の誰か」がDoをした! - しかし、ロックがかかっているので、「別の誰か」は待機しないといけない
- 「誰か」がやっていた
f()の処理が終わる -
o.doneのフラグが立てられる - ロックが解除される
- ロックが解除されたので、「別の誰か」がロックをとれる(ヒャッホーイ!)
- しかし、すでに
o.doneは1なので、「別の誰か」は関数fを呼び出せませんでした - めでたしめでたし
sync.Once.DoのDocを読もう
Do calls the function f if and only if Do is being called for the first time for this instance of Once.
sync.Once.Do() は、関数fを呼び出すよ。
ただし、呼び出すのは、このsync.Onceインスタンスで初めてsync.Once.Do()が呼び出されるときだけですよ。
(sycn.Once.Doは、このOnceインスタンスで初めてDoが呼び出される場合にのみ、関数fを呼び出します。)
In other words, given var once Once if once.
言い換えると、1つのOnce変数につき、一回だけってこと。
Do(f) is called multiple times, only the first call will invoke f, even if f has a different value in each invocation.
もし、sync.Once.Do(f)が複数回実行されたらどうなるでしょうか?
その場合は、1発目の呼び出しだけが、関数fが実行されます。
もし、呼び出しごとに関数fが異なっていたとしても、最初の呼び出しだけが優先されるってわけ。
(Do(f)は複数回呼び出され、呼び出しごとにfの値が異なっていても、最初の呼び出しのみがfを呼び出します。)
A new instance of Once is required for each function to execute.
呼び出したい関数ごとに、sync.Onceの新規インスタンスが必要ですよ。
関数fを1回しか実行しないから、その都度Onceが必要だよねって話だな。
Do is intended for initialization that must be run exactly once.
Since f is niladic, it may be necessary to use a function literal to capture the arguments to a function to be invoked by Do:
config.once.Do(func() { config.init(filename) })
Because no call to Do returns until the one call to f returns, if f causes Do to be called, it will deadlock.
If f panics, Do considers it to have returned; future calls of Do return without calling f.
sync.Onceは標準でも結構使われている話
$ go env GOVERSION
go1.16
$ grep -ir sync.Once $(go env GOROOT)/src | wc -l
128
何が出力されるでしょう?
package main
import (
"fmt"
"sync"
)
func main() {
var count int
increment := func() { count++ }
decrement := func() { count-- }
var once sync.Once
once.Do(increment)
once.Do(decrement)
fmt.Println(count)
}
sync.OnceはDoが呼び出された回数しか見てない!
どの関数を呼んだとかは気にしていないわけよ。
ここをみて → https://zenn.dev/mohira/scraps/95427e91e27c93#comment-e5ce1ac47e9d19
sync/atomicの実際の実装
- アセンブリで書いてある
-
runtime/internal/atomic/*.sという感じ -
.sはアセンブリの拡張子 - アーキテクチャごとにファイルが分かれている
-
arm64: M1mac -
amd64: intel
-
// uint32 Xadd(uint32 volatile *val, int32 delta)
// Atomically:
// *val += delta;
// return *val;
TEXT runtime∕internal∕atomic·Xadd(SB), NOSPLIT, $0-20
MOVQ ptr+0(FP), BX
MOVL delta+8(FP), AX
MOVL AX, CX
LOCK
XADDL AX, 0(BX)
ADDL CX, AX
MOVL AX, ret+16(FP)
RET
よくわかんないけど、LOCKをとっている感じが溢れている。
sync/atomicを体感するコード
- このコードを実行して、F5連打してみましょう。だんだんズレていくぞ〜
- どのコンテキストにおいてアトミックなのかを考えるべし
package main
import (
"fmt"
"net/http"
"sync/atomic"
"time"
)
func main() {
var (
count1 int
count2 int32
)
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
x := count1 + 1
time.Sleep(30 * time.Millisecond)
count1 = x
count2 = atomic.AddInt32(&count2, 1)
fmt.Fprintln(w, count1, count2)
})
http.ListenAndServe(":8080", nil)
}
第3章 3.2.5 sync.Pool
- いつかやろう。あとまわし
第3章 3.3 チャネル(channel)
-
「待機するのはゴルーチン」って捉え方をすると開けた感じがある!
- 「チャネルはブロックする」って言葉がイメージできてなかったということでもある!
-
ゴルーチンのやりとりを擬人化して可視化するとイメージつかめる
- ゴルーチンの発言を可視化(Print)したり。
- Sleepを仕込んで、コミュニケーションを表現したり。
- 呼び出したゴルーチン内でSleepしたり一気に結果が出力されてしまうので、分かりにくいと思うわけ
-
チャネルはブロックします」を全然理解できてなかったわけですが、「そのチャネルを操作しようとしているゴルーチンが待機する」って捉えたらスッキリ。
- 「チャネルがブロックする」ってのはあくまでチャネルの性質であって、その性質によって待機するのはチャネルの利用者(=ゴルーチン)。
-
この辺のクエスチョンに答えられると良さそう
- チャネルがブロックするって、一体何を?
- チャネルがブロックするのはどんなとき?
- チャネルのブロックによって待機するのは誰?
-
チャネルの所有権、チャネルの所有者の責任、チャネルの消費者、それぞれを考えると動きが推測しやすいコードになる話
p.65 チャネルはGo並行処理における基本部品だよ
チャネルはHoareのCSPに由来する、Goにおける同期処理のプリミティブの1つです。
「チャネルはチャネル」から卒業だわ!
メモリに対するアクセスを同期するのに使える一方で、ゴルーチン間の通信に使うのが最適です
具体例を積み上げていきましょう
具体例その1
- もっとも基本的なやつ
package main
import "fmt"
func main() {
stringStream := make(chan string)
go func() {
stringStream <- "Hello channels!"
}()
fmt.Println(<-stringStream)
}
Q. ゴルーチンにしないとDeadlockになるのなんでなん?
- 「ゴルーチンを使わないのに、チャネルを使う」状況が実際的に意味がないってのはさておき、mainゴルーチン内だけでチャネルを使うとデッドロック
- なんで?
- バッファサイズが関係しているっぽい?
package main
import "fmt"
func main() {
stringStream := make(chan string)
// fatal error: all goroutines are asleep - deadlock!
stringStream <- "Hello channels!"
fmt.Println(<-stringStream)
}
片方向のチャネル: 送信専用と受信専用
package main
func main() {
sendOnlyChannel := make(chan<- int)
receiveOnlyChanel := make(<-chan int)
// invalid operation: <-sendOnlyChannel (receive from send-only type chan<- int)
<-sendOnlyChannel // 受信しようとしてみる
// invalid operation: receiveOnlyChanel <- 1 (send to receive-only type <-chan int)
receiveOnlyChanel <- 1 // 送信しようとしてみる
}
主語を捉えろっ! チャネルを扱っている張本人はゴルーチンだ!
「チャネルはブロックする」だと、なんというか、「チャネル」主語のように思える。けど、それはあくまでチャネルの性質って感じ。
実際に待機しているのはゴルーチン。
あるゴルーチンが、チャネルを読み込もうとする。しかし、そのチャネルは空だった。だから、チャネルはブロックする(読み込めない)。その結果、そのゴルーチンが待機する。
あるゴルーチンが、チャネルに書き込もうとする。しかし、そのチャネルはキャパシティいっぱいだった。だから、チャネルはブロックする(書き込めない)。その結果、そのゴルーチンが待機する。
こんな解釈がいい気がする。
チャネルは使われる側であって、使う側ではない感じ。
あるいは、「チャネルが待機する」とは言わないよねって話。
改めて、コードをみてみるといいぞ。
package main
import "fmt"
func main() {
ch := make(chan string)
go func() {
// 無名ゴルーチンは、キャパシティが空くまで待機する
// キャパシティがあれば、チャネルに書き込む
ch <- "Hello channels!"
}()
// メインゴルーチンは、読み込みをする
// もし、チャネルが空だったら、メインゴルーチンは待機する
// つまり、チャネルにデータが書き込まれるまで、メインゴルーチンは待機する
// だから、プログラムは終了しないし、実行結果が「決定的」になる
fmt.Println(<-ch)
}
ゴルーチン間のコミュニケーション感を演出してみると、わかりやすいのでは!?
- チャネルの読み書きと、forが組み合わされる、行ったりきたりするのでややこしいわけよ
- 目があっちこっちいく感じね
- なので、喋らせるとわかりやすいと思うわけ
$ go run main.go
無名ゴルーチン(っ'-')╮ =͟͟͞(1) : データ書き込んだよ!
Mainゴルーチン ∠( ゚д゚)/: (1) を受け取ったぞ
Mainゴルーチン ∠( ゚д゚)/: 次、送って良いぞ〜
------------------------------
無名ゴルーチン(っ'-')╮ =͟͟͞(2) : データ書き込んだよ!
Mainゴルーチン ∠( ゚д゚)/: (2) を受け取ったぞ
Mainゴルーチン ∠( ゚д゚)/: 次、送って良いぞ〜
------------------------------
無名ゴルーチン(っ'-')╮ =͟͟͞(3) : データ書き込んだよ!
Mainゴルーチン ∠( ゚д゚)/: (3) を受け取ったぞ
Mainゴルーチン ∠( ゚д゚)/: 次、送って良いぞ〜
------------------------------
無名ゴルーチン(っ'-')╮ =͟͟͞(4) : データ書き込んだよ!
Mainゴルーチン ∠( ゚д゚)/: (4) を受け取ったぞ
Mainゴルーチン ∠( ゚д゚)/: 次、送って良いぞ〜
------------------------------
無名ゴルーチン(っ'-')╮ =͟͟͞(5) : データ書き込んだよ!
Mainゴルーチン ∠( ゚д゚)/: (5) を受け取ったぞ
Mainゴルーチン ∠( ゚д゚)/: 次、送って良いぞ〜
------------------------------
おしまい
実装はこんな感じ。
-
for v range := chの頻出パターンっぽいね - これくらいがサラッと読み書きできるといい感じっぽい
package main
import (
"fmt"
"strings"
"time"
)
// ゴルーチン間のコミュニケーション感を演出してみる
// Mainゴルーチン と 無名ゴルーチン にアイコンを付ける → ∠( ゚д゚)/ っ'-')╮
// 発言させてみる。sleepをつけると会話っぽくなる
func main() {
ch := make(chan int)
go func() {
defer close(ch) // 無名ゴルーチンでforループの処理が終わったら、チャネルを閉じる
for i := 1; i <= 5; i++ {
ch <- i
fmt.Printf("無名ゴルーチン(っ'-')╮ =͟͟͞(%d) : データ書き込んだよ!\n", i)
}
}()
for integer := range ch {
time.Sleep(1 * time.Second)
fmt.Printf("Mainゴルーチン ∠( ゚д゚)/: (%d) を受け取ったぞ\n", integer)
time.Sleep(1 * time.Second)
fmt.Printf("Mainゴルーチン ∠( ゚д゚)/: 次、送って良いぞ〜\n")
time.Sleep(1 * time.Second)
fmt.Println(strings.Repeat("-", 30))
}
fmt.Println("おしまい")
}
close()と rangeの基本コンビネーション
- チャネルの
for-rangeっていうよりも「終了条件のない繰り返し」って捉えるほうがよさそう
package main
import "fmt"
func main() {
ch := make(chan int)
go func() {
defer close(ch)
for i := 0; i < 10; i++ {
ch <- i
}
}()
// for-rangeっていうよりも「終了条件のない」繰り返し
// 終了の判定は close(ch) をきっかけにforが勝手にやってくれる感じ
for v := range ch {
fmt.Println(v)
}
}
close忘れるとデッドロックになるからな!
- 上のパターンは、
closeを活用していることをお忘れなく - 「終了条件のない繰り返し」を終了できるのは
closeしているから!
package main
import "fmt"
func main() {
ch := make(chan int)
go func() {
for i := 0; i <= 5; i++ {
ch <- i
}
}()
for v := range ch {
fmt.Println(v)
}
}
こうなる
$ go run main.go
0
1
2
3
4
5
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive]:
なんでデッドロック?
まず、「0から5までの送信受信コミュニケーション」はできている(みのがしちゃいけない点だとおもう)。
しかし、終了条件を書いていないから、Mainゴルーチンはずーっと待機することになる。
で、どこかのタイミングで、Goが「Mainゴルーチン以外のゴルーチンが寝ていること」を検知する。
ってなわけで、デッドロック!
closeは狼煙
- チャネルの
closeは、複数のゴルーチンに同時にシグナルを送る方法でもある! - いわば、狼煙!
- もちろん、あくまで狼煙を上げるだけであって、「狼煙を見たらやること」は事前に決めとかないとね
実装はこんな感じ
package main
import (
"fmt"
"sync"
"time"
)
func main() {
begin := make(chan int)
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
wg.Add(1)
go func(n int) {
defer wg.Done()
fmt.Printf("\t(っ'-')╮ =͞ ゴルーチン%d号 待機...\n", n)
// 狼煙がくるまで、各ゴルーチンは待機
// beginチャネルがcloseされるまで(受信可能になるまで)待機
// close(begin)されたあとなら、無限に受信ができる(そして、ゼロ値を返す)
<-begin
fmt.Printf("\t(っ'-')╮ =͞ ゴルーチン%d号 出動!\n", n)
}(i)
}
// ゴルーチン間のコミュニケーションをイメージしやすくするための仕込み
fmt.Println("∠( ゚д゚)/: 狼煙の準備なう...")
time.Sleep(1 * time.Second)
fmt.Println("∠( ゚д゚)/: 狼煙だ〜〜〜")
time.Sleep(1 * time.Second)
close(begin) // 終了の狼煙を上げる
wg.Wait() // 無名ゴルーチンたちが終了するまで、Mainゴルーチンは待機
fmt.Println("∠( ゚д゚)/: おしまい")
}
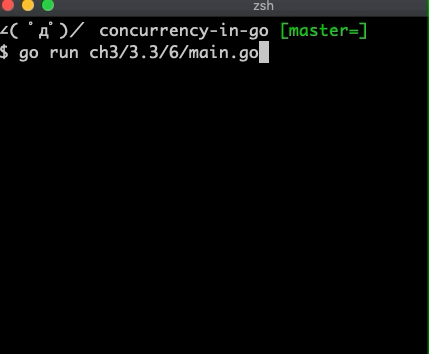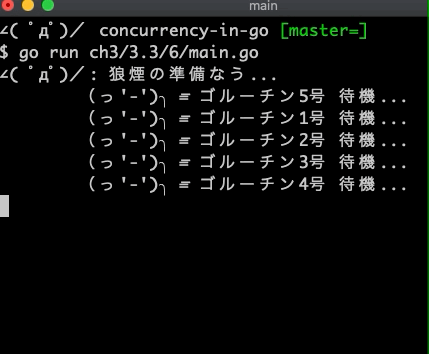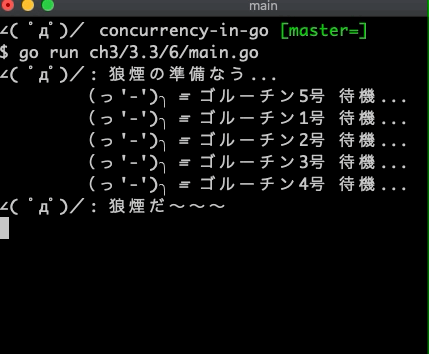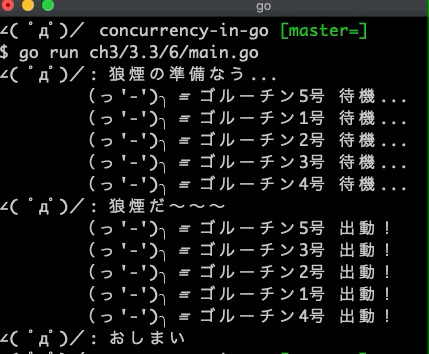
結果はこうなる
$ go run main.go
∠( ゚д゚)/: 狼煙の準備なう...
(っ'-')╮ =͞ ゴルーチン5号 待機...
(っ'-')╮ =͞ ゴルーチン1号 待機...
(っ'-')╮ =͞ ゴルーチン2号 待機...
(っ'-')╮ =͞ ゴルーチン3号 待機...
(っ'-')╮ =͞ ゴルーチン4号 待機...
∠( ゚д゚)/: 狼煙だ〜〜〜
(っ'-')╮ =͞ ゴルーチン3号 出動!
(っ'-')╮ =͞ ゴルーチン4号 出動!
(っ'-')╮ =͞ ゴルーチン1号 出動!
(っ'-')╮ =͞ ゴルーチン2号 出動!
(っ'-')╮ =͞ ゴルーチン5号 出動!
∠( ゚д゚)/: おしまい
gifにするとさらにわかりやすい
Q. バッファありなしで、挙動が違うんだけど、ちゃんと説明できぬぞ?
package main
func main() {
ch := make(chan rune)
ch<-'A' // fatal error: all goroutines are asleep - deadlock!
}
package main
func main() {
ch := make(chan rune, 0) // 明示的に第2引数に0を渡す
ch <- 'A' // fatal error: all goroutines are asleep - deadlock!
}
package main
import "fmt"
func main() {
ch := make(chan rune, 1) // バッファサイズが1
ch <- 'A'
fmt.Println(<-ch) // 65
}
// これはわかりやすい
func main() {
ch := make(chan rune, 1)
fmt.Println(<-ch) // fatal error: all goroutines are asleep - deadlock!
}
Q. 何言っているかわからん
また、バッファ付きチャネルが空で、かつそれに対する受信先がある場合、バッファはバイパスされ、 値は送信元から受信先へと直接渡されます。実際のところ、これは透過的に行われますが、バッファ 付きチャネルの性能に関する性質として知っておいて損はないでしょう。
p.73
チャネルへの書き込み回数が事前にわかっているなら、バッファつきチャネルをいい感じ使うこともある
これは正しい条件の元で役立つ最適化の例です。チャネルに書き込みをおこなうゴルーチンが書き込む回数を事前に知っていたら、バッファ付きチャネルをこれから書き込む回数分のキャパシティだけ用意して、できる限り早く書き込みを行います。もちろん、注意すべきこともありますが、それは次の章で紹介します。
p.75
package main
import (
"bytes"
"fmt"
"os"
)
func main() {
var stdoutBuff bytes.Buffer
defer stdoutBuff.WriteTo(os.Stdout)
ch := make(chan int, 4) // バッファサイズ: 4
go func() {
defer close(ch)
defer fmt.Fprintln(&stdoutBuff, "Producer Done.")
// バッファサイズ分だけ整数を送信する(事前にわかっている)
for i := 0; i < 5; i++ {
fmt.Fprintf(&stdoutBuff, "っ'-')╮ =͞ Sending: %d\n", i)
ch <- i
}
}()
for integer := range ch {
fmt.Fprintf(&stdoutBuff, "∠( ゚д゚)/ Received %v.\n", integer)
}
}
$ go run main.go
っ'-')╮ =͞ Sending: 0
っ'-')╮ =͞ Sending: 1
っ'-')╮ =͞ Sending: 2
っ'-')╮ =͞ Sending: 3
っ'-')╮ =͞ Sending: 4
Producer Done.
∠( ゚д゚)/ Received 0.
∠( ゚д゚)/ Received 1.
∠( ゚д゚)/ Received 2.
∠( ゚д゚)/ Received 3.
∠( ゚д゚)/ Received 4.
「チャネルの所有者」と「チャネルの非所有者」という概念を導入する作戦
次の3つの操作を行うゴルーチンを、チャネルの所有権を持つ人(所有者)って考える。権利はゴルーチンに紐づく感じ。
- チャネルを初期化する
- チャネルに書き込む
- チャネルを閉じる
定義の文には書いてないけど「チャネルの所有権を渡す」ってのも入ってそう。
チャネルの非所有者(「消費者」のほうがイメージつかみやすい)
- チャネルから読み込む
だけのゴルーチン! 他の権限は一切ない!
チャネルの所有者であることを表現するのにクロージャーが便利な話
チャネルの所有権を意識して、コードを眺めてごらん?
package main
import "fmt"
func main() {
// chanOwner は intChチャネル の所有権を持っている
// で、「非所有者」が使えるように、「読み込み専用チャネル」を返している
chanOwner := func() <-chan int {
// チャネルの所有者なので、チャネルを初期化している(定義1)
intCh := make(chan int, 5)
go func() {
// チャネルの所有者なので、チャネルを閉じている(定義3)
defer close(intCh)
for i := 0; i <= 5; i++ {
// チャネルの所有者なので、チャネルに書き込んでいる(定義2)
intCh <- i
}
}()
return intCh
}
// チャネルの所有者が、消費者にむけて「読み込んでよいぞチャネル」を作ってあげた感じ
// このへん擬人法の怪しさがあふれる
ch := chanOwner()
// Mainゴルーチンは、チャネルの非所有者(チャネルを読み込むだけの人)
for result:= range ch {
fmt.Printf("Received: %d\n", result)
}
fmt.Printf("Done receiving!")
}
p.76の表3-2はわかんなくなったら振り返ろう
チャネルの状態に対する、チャネルへの操作結果をまとめた表。
たぶん役立つ。
送信専用チャネル、受信専用チャネルは、所有権管理に使うイメージ
一方向チャネルを初期化するところはあまり見かけないでしょうが、関数の引数や戻り値として使われるのをよく目にすることでしょう。これから見ていきますが、これはすごく便利です。
Goが双方向チャネルを必要に応じて暗黙的に一方向チャネルに変換してくれるので、こうしたことが可能になって います。
(p.66)
package main
func receiveOnlyChannel() <-chan int {
c := make(chan int) // この時点では読み書きできるチャネル
return c
}
func main() {
// 返り値の型のおかげで受信専用のチャネルになっている
// 呼び出し側が書き込むことを制限できている感じ
ch := receiveOnlyChannel()
// 許されていない行為(書き込み)をしようとしてもできなくなっている(嬉しい)
ch <- 1 // invalid operation: c <- 1 (send to receive-only type <-chan int)
}
双方向=>一方向 の変換はしてくれるけど、一方向=>双方向の変換はだめだよ
package main
// 双方向 => 受信専用 は OK
func to1(c chan int) <-chan int {
return c
}
// 双方向 => 送信専用 は OK
func to2(c chan int) chan<- int {
return c
}
// 一方向 => 双方向 は無理
// cannot use c (type <-chan int) as type chan int in return argument
func to3(c <-chan int) chan int {
return c
}
// 一方向 => 双方向 は無理
// cannot use c (type chan<- int) as type chan int in return argument
func to4(c chan<- int) chan int {
return c
}
所有権(ownership)という考え方は公式の記述見るといい感じ
Channels allow you to pass references to data structures between goroutines. If you consider this as passing around ownership of the data (the ability to read and write it), they become a powerful and expressive synchronization mechanism.
ゴルーチン間で「データをやり取りする」ではなく、「データの所有権を受け渡しする」とみなしているって感じ。そしてそのほうが表現力が高いね。
第3章 3.4 select文
Select文は順番に関係なくチャネルを同時に扱うすごいやつ
反射的にSwitch文のようにみてしまうのは危険だ。冷静に。
Switch文と同一視すると詰む! Select文は、Switch文と見た目が似ているが、似ているのは見た目だけ。全然別物! まじで罠!
switchブロックと違い、selectブロックのcase文は上から順番に評価されません。
第1の罠。
また、1つも条件に該当しない場合には自動的に実行されません。
第2の罠。
select文はチャネルを「同時に」扱う
かわりに、読み込みや書き込みのチャネルはすべて同時に取り扱われ、どれが用意できたかを確認します。
順番に見てないよ(2回目)。
裏ですごいことをやってくれてそうだ。
- case句でチャネルの読み込みをしているなら
- そのチャネルの書き込みや、チャネルのcloseを見張っている
- case句でチャネルの書き込みしているなら、
- そのチャネルのキャパシティを見張っていているわけ。や、チャネルのcloseを見張っている
チャネルが準備OKか(==case句での読み書き操作ができるか)を見張っていることを体感する例
package main
import (
"fmt"
"time"
)
func main() {
start := time.Now()
c := make(chan interface{})
go func() {
fmt.Printf("(っ'-')╮ =͞ 5秒寝まーす\n")
time.Sleep(5 * time.Second)
fmt.Printf("(っ'-')╮ =͞ close!!!\n")
close(c)
}()
fmt.Println("∠( ゚д゚)/ 読み込みを待機...")
// ホントは <-c だけで十分(selectなくてもいける)けど、記述を拡張していくためにわざと書いている
select {
// チャネルに読み込み可能になる(書き込まれるか、closeされるか)まで、チャネルはブロックする
// つまり、Mainゴルーチンが待機するってこと
case <-c:
fmt.Printf("∠( ゚д゚)/ %v経ちましたとさ\n", time.Since(start))
}
}
select文に関するいろんな疑問のコーナー
- 複数のチャネルが準備OKな場合はどうなるの?
- どのチャネルも準備OKな状態にならなかったらどうなるの?
- どのチャネルも準備完了していないときに何かしたい場合はどうするの?
Q. 複数のチャネルが準備OKな場合はどうなるの?
selectはチャネル同時に扱うわけですが、同時ってどうなのよ? って話。これは面白い。
package main
import "fmt"
// 疑問1: 複数のチャネルが準備OKな場合、selectはどうなるのか?
func main() {
c1 := make(chan interface{})
c2 := make(chan interface{})
// 速攻で、closeしている! == チャネルが読み込める状態 == 準備OK状態
close(c1)
close(c2)
var count1, count2 int
for i := 1000; i > 0; i-- {
select {
case <-c1:
count1++
case <-c2:
count2++
}
}
// Q. 何が出力されるでしょう?
fmt.Printf("count1: %d\ncount2: %d\n", count1, count2)
}
実行結果
実際にやってみてね
2つのチャネルが準備OKなときのselectの動き
- 観察
- 毎回結果が変わる!
- おおよそ半々くらいになっている
$ go run 3/main.go
count1: 517
count2: 483
$ go run 3/main.go
count1: 496
count2: 504
$ go run 3/main.go
count1: 507
count2: 493
これは偶然!
もうちょっとちゃんというと、こんな感じ
Goのランタイムはcase文全体に対して疑似乱数による一様選択をしています† 17。
つまり、case文全体では、それぞれの条件が等しく選択される可能性があるわけです
なんでそんな設計になっているの?
Goのランタイムはあなたが書いた select 文の意図を何一つ知りえません。
そりゃそうだ。
つまり、Goのランタイムはあなたの問題空間やあなたが select文でチャネルをまとめた理由を推測できません。
つまり、プログラマーの気持ちを読み取って、"よしなに"やることはできない。
とはいえ、何か方策を決めておかないと困りそうではあるよね。適当にするっていっても、その適当って何よ? って話。
こうした理由から、Go のランタイムが実現したいと思っている最善の状態は、それぞれの条件をならして実行することです。
それを実現する良い方法として、平均的に実行するために乱数を導入することです――この場合、どのチャネルから読み込むかの選択です。
各チャネルが使われれる確率を等しくすることで、select文を使うすべてのGoプログラムは各条件をならして実行します。
決められないなら一様選択って発想はとても妥当性があると思う。逆に、もし偏りがあったとすると、つらそう。
Q. どのチャネルも準備OKな状態にならなかったらどうなるの?
nilチャネルを使って実験。
time.Afterも一緒に実験。
package main
import (
"fmt"
"time"
)
func main() {
var c chan int
select {
case <-c: // nilチャネルなので永遠にブロック
case <-time.After(5 * time.Second): // time.Afterは読み込み専用チャネルを返している
fmt.Println("Timed out")
}
}
Q. チャネルが1つも読み込めず、その間に何かする必要がある場合にはどうしたらいいの?
まさにdefaultな感じ!
package main
import (
"fmt"
"time"
)
// 疑問: チャネルが1つも読み込めず、その間に何かする必要がある場合にはどうしたらいいの?
func main() {
start := time.Now()
var c1, c2 <-chan int // どちらもnilチャネルなので永遠ブロック
select {
case <-c1:
case <-c2:
default:
fmt.Printf("In default after%v\n\n", time.Since(start))
}
}
for-selectパターン: ゴルーチンの結果報告を待つ間に、他のゴルーチンで仕事を進める
いい感じのパターンだ! これまでのテクニックが詰まっているし、実用感がすごい。
package main
import (
"fmt"
"time"
)
// defaultをfor-selectループで使う
// ゴルーチンの結果報告を待つ間に、他のゴルーチンで仕事を進められる!
func main() {
done := make(chan interface{})
go func() {
fmt.Printf("(っ'-')╮ =͞ 仕事するぞ!\n")
time.Sleep(5 * time.Second)
fmt.Printf("(っ'-')╮ =͞ 仕事おわり!\n")
close(done)
}()
fmt.Printf("∠( ゚д゚)/ 他のゴルーチン(っ'-')╮ の仕事が終わるまで数を数えまくるぞい\n")
var counter int
loop:
for {
select {
case <-done:
break loop
default:
// <-doneができない == doneチャネルが読み込めない(closeされていない)なら何もしない
// つまり、Mainゴルーチンはcounterをインクリメントする仕事をする
// 1つ仕事(インクリメント)しては、チェックする感じになる
}
counter++
time.Sleep(100 * time.Millisecond)
}
fmt.Printf("∠( ゚д゚)/ %d回数えたで!\n", counter)
}
$ go run main.go
∠( ゚д゚)/ 他のゴルーチン(っ'-')╮ の仕事が終わるまで数を数えまくるぞい
(っ'-')╮ =͞ 仕事するぞ!
(っ'-')╮ =͞ 仕事おわり!
∠( ゚д゚)/ 48回数えたで!
select{}のみで永遠のブロック
package main
func main() {
// fatal error: all goroutines are asleep - deadlock!
//
// goroutine 1 [select (no cases)]:
select {}
}
time.Afterとのコンボを書くといいかもしれない
第3章 3.5 GOMAXPROCSレバー
- 「レバー」ってのは自分で調節できるぜって表現した感じっぽい
- 『Goならわかるシステムプログラミング』もあわせてよみたいところ
- 使いどころがわからない。というより、基本的にいじらなくてよさそう
第4章 4.1 拘束
- 「拘束」は原著だと Confinement【kənfáinmənt】
- Confinementは「監禁」「束縛」「幽閉」「閉じ込め」みたいな意味。
- solitary confinement は 「独房監禁」という意味
- チャネルのブロックの話と同じで、対象や視点を見極めるのが大事
- 誰を拘束するの?
- 誰が拘束するの?
- 所有者はだれ?
- 公開される権限は何?
- 3.3の所有権の話を読み直すといい感じ
並行なコードで安全に操作するための考え方
今まで見てきたやつは2つ。
- メモリを共有するための同期のプリミティブ(ex:
sync.Mutex) - 通信による同期(ex: チャネル)
ところで、イミュータブルもあるよね
- イミュータブルなデータ
それはそうだね。
たぶん、Elixirとかがそうだと思う(詳しくはしらんけど)
変更はできず、新しい値が欲しかったら、新しい値をつくる(コピーしてから変更)ってことね。
4つ目の考え方が「拘束」(Confinement)
拘束は、情報をたった1つの並行プロセスからのみ得られることを確実にしてくれる単純ですが強力 な考え方です。(p.88)
まさに、閉じ込め、監禁という感じ。
独房(Solitary Confinement)に閉じ込めてしまえば、だれもその囚人にアクセスできないよね的な感じ。
これが確実に行われたときには、並行プログラムは暗黙的に安全で、また同期がまったく必要なくなります。(p.88)
そもそも、いろんな人が、同じデータを転がそうとするから衝突したりする。競合する。だから、わざわざ同期なんてことをしないといけなかったり、通信したりしないといけない。めんどくさい。
でも、完全に身柄を拘束してしまえば、同期という概念自体が不要になるよね。それはそうだ。
何を囚人、何を独房と捉えるかが大事っぽい気がした
アドホック拘束 - 規約で乗り切ろう精神
- あるデータ(囚人)は、ある関数やゴルーチン(独房)の中だけで操作するようにしようね作戦
- 性善説スタイル
- 余裕で破られると思う
- もしくは、超リッチな静的解析ツールが自動で楽に動けばなんとかなりそうなくらいのレベル
package main
import "fmt"
func main() {
data := make([]int, 4) // こいつが拘束対象の囚人か?
// やろうと思えば、独房の外で囚人を操作できてしまう!
// 規約違反!
// data[3] = 333
// data[4] = 444
loopData := func(handleData chan<- int) {
// loopData という独房
// ここにdataという囚人を拘束する規約になっている ← アドホック!
defer close(handleData)
// 独房内で囚人を操作できる(これは独房内だから規約に準じている)
for i := range data {
handleData <- data[i]
}
}
handleData := make(chan int)
go loopData(handleData)
for num := range handleData {
fmt.Println(num)
}
}
レキシカル拘束 - 違法をコンパイルエラー検出するぞ
- レキシカルスコープを活用した拘束
- レキシカルスコープ内で、チャネルの所有者だけが、書き込みやcloseができる
- 公開するときは読み込み専用チャネル(
<-chan T)だけ返せばいい
package main
import "fmt"
func main() {
// 読み込み専用チャネルを返す時点で、所有者は「他の連中(ゴルーチン)には読み込みしか許可しないぞ!」って意思表示してる感じ
chanOwner := func() <-chan int {
// resultsをこの関数のレキシカルスコープ内で初期化している
// → 操作できるのはこの関数(独房)の中だけ
// → 書き込み権限の「拘束」ってわけ
results := make(chan int, 5) // 今回の囚人
go func() {
// 所定の書き込みが終わったらclose(他の人は書き込めない)
// まさに、チャネルの所有者の行いですな
defer close(results)
for i := 0; i <= 5; i++ {
results <- i
}
}()
return results
}
// 拘束を突破しようとしても....
// 独房の外からは、囚人に書き込みができない!(嬉しい)
// results <- 999 // コンパイルエラー!
consumer := func(results <-chan int) {
// resultsの読み込み権限"だけ"のコピーを受け取っている
// 拘束を突破しようとしても....
// results <- 999 // コンパイルエラー!(嬉しい)
// 約束通りの読み込み作業
for result := range results {
fmt.Printf("Received %d\n", result)
}
fmt.Println("Done receiving!")
}
results := chanOwner()
consumer(results)
}
並行安全ではないデータ構造(bytes.Buffer)を使った拘束の例
package main
import (
"bytes"
"fmt"
"sync"
)
func main() {
printData := func(wg *sync.WaitGroup, data []byte) {
// printData宣言以前にdataが宣言されてないので
// コピーを受け取るしかない
// printDataを起動するゴルーチンがどう渡すかに制限されるわけ
defer wg.Done()
var buf bytes.Buffer
for _, b:= range data {
fmt.Fprintf(&buf, "%c", b)
}
fmt.Println(buf.String())
}
var wg sync.WaitGroup
wg.Add(2)
data := []byte("golang")
// printDataが使えるdataを一部の範囲に絞っている == 拘束
go printData(&wg, data[:3]) // 先頭3バイトだけ操作できる拘束
go printData(&wg, data[3:]) // 後半3バイトだけ操作できる拘束
wg.Wait()
}
わざとやりたい放題にしてみる
package main
import (
"bytes"
"fmt"
"sync"
)
func main() {
// printData以前に宣言するとやりたい放題で大変!
data := []byte("golang")
var buf bytes.Buffer
printData := func(wg *sync.WaitGroup, data []byte) {
defer wg.Done()
for _, b := range data {
fmt.Fprintf(&buf, "%c", b)
}
fmt.Println(buf.String())
}
var wg sync.WaitGroup
wg.Add(2)
go printData(&wg, data[:3])
go printData(&wg, data[3:])
wg.Wait()
}
ところで、なんで拘束とかいうテクニックを使うの? 同期を使えばよくない?
パフォーマンスの向上と、開発者に対する可読性の向上がその理由です。
同期はコストが高くなり、使用を避けることができればクリティカルセクションを持たずに済みます。
またそれゆえに、同期のコストをかける必要がなくなります。
また同期をおこなうことで発生しうる問題すべてを回避できます。
つまり開発者は単純にこういった類の問題をまったく気にする必要がなくなります。
同期はどうしてもパフォーマンスの話が絡んでくるよな。それはそうだけども。
さらにレキシカル拘束を利用する並行処理のコードは、そうでないコードに比較して一般的には理解しやすいものになるという利点があります。
その理由は、レキシカルスコープのコンテキストの中では同期なコードが書けるからです。
これはでかいよな〜。やっぱ同期的なコードのほうが単純に書けると思う。
まー、全てを拘束にするのは無理なこともあるよな話
とはいえ、拘束をきちんと作るのは難しいこともあります。そして、ときには素晴らしいGoの並行処理のプリミティブを利用しなければならなくなります。
第4章 4.2 for-selectループ
あとで
第4章 4.3 ゴルーチンリークを避ける
あとで
ゴルーチンリークをわざと起こす(読み込み編)
package main
import (
"fmt"
)
// p.93 簡単なゴルーチンリークの例
func main() {
doWork := func(strings chan string) <-chan interface{} {
completed := make(chan interface{})
// ゴルーチン1号: (っ'-')╮
go func() {
// ゴルーチン1号が終了したのなら、このdeferが実行されるはず
defer fmt.Println("(っ'-')╮ =͟͟͞(終了) ブォン")
defer close(completed)
for s := range strings {
fmt.Println(s)
}
}()
return completed
}
// Mainゴルーチンでは、nilチャネル を渡しているので、stringsには絶対書き込みは起きない
// => ゴルーチン1号はメモリ内の残り続ける(このプロセスが生きている限り)
doWork(nil)
fmt.Println("Mainゴルーチン おわり.")
}
# ゴルーチン1号は終了していない!(deferで設定した終了メッセージがでてないから)
$ go run 1/main.go
Mainゴルーチン おわり.
ゴルーチンリークを起こさないようにする(読み込み編)
package main
import (
"fmt"
"runtime"
"time"
)
// p.93 ゴルーチンの親子間で親から子にキャンセルの信号を送れるようにする
// 親ゴルーチンがキャンセルしたいときに、キャンセルする
func main() {
doWork := func(done <-chan interface{}, strings <-chan string) <-chan interface{} {
terminated := make(chan interface{})
// ゴルーチン1号
go func() {
// ゴルーチン1号が終了したのなら、このdeferが実行されるはず
defer fmt.Println("(っ'-')╮ =͟͟͞(終了) ブォン")
defer close(terminated)
for {
select {
case s := <-strings:
fmt.Println(s)
case <-done: // 親からキャンセルが来た場合は、returnする
return
}
}
}()
return terminated
}
done := make(chan interface{})
// nilチャネルを渡しているけど、ちゃんとゴルーチンは終了する!
terminated := doWork(done, nil)
// ゴルーチン2号
go func() {
// 1秒後に操作をキャンセルする
time.Sleep(1 * time.Second)
fmt.Println("∠( ゚д゚)/: Canceling doWork(ゴルーチン1号)")
close(done)
}()
fmt.Printf("ゴルーチンの数: %d\n", runtime.NumGoroutine()) // 3
<-terminated // ゴルーチン1号が終了されるまでブロック
fmt.Printf("ゴルーチンの数: %d\n", runtime.NumGoroutine()) // 1
fmt.Println("Mainゴルーチン おわり.")
}
こうなる
$ go run main.go
∠( ゚д゚)/: Canceling doWork(ゴルーチン1号)
(っ'-')╮ =͟͟͞(終了) ブォン
ゴルーチンの数: 1
Mainゴルーチン おわり.
ゴルーチンリークの例(書き込み編)
package main
import (
"fmt"
"math/rand"
)
// p.94 ゴルーチンリーク
// ゴルーチンがチャネルに対して書き込みを行おうとしてブロックしている状況
func main() {
newRanStream := func() <-chan int {
randStream := make(chan int)
go func() {
defer fmt.Println("newRandomStream closure exited.")
defer close(randStream)
for {
// 終了条件がないので、ずーっと書き込みを頑張り続ける
randStream <- rand.Int()
}
}()
return randStream
}
randStream := newRanStream()
fmt.Println("3 random ints:")
for i := 1; i <= 3; i++ {
fmt.Printf("%d: %d\n", i, <-randStream)
}
}
こうなる
- 一見正しく動いてそうだが、ゴルーチンは終了していない!
- ゴルーチン終了しているなら、
fmt.Println("newRandomStream closure exited.")が実行されているはずだからね。 - ゴルーチンに対して「終わって良いぞ〜」を伝えてないから、それはそう
$ go run main.go
3 random ints:
1: 5577006791947779410
2: 8674665223082153551
3: 6129484611666145821
ゴルーチンリークを起こさないようにする(書き込み編)
- ところで、所有者の話を思い出すといいよ!
-
closeするのは、所有者の責任 - そして、読み込み権限だけ解放しているのも所有者の責任(
newRandStreamの返り値の型は<-chan int(読み込み専用!)
-
package main
import (
"fmt"
"math/rand"
"runtime"
"time"
)
func main() {
newRandStream := func(done <-chan interface{}) <-chan int {
randStream := make(chan int)
go func() {
defer fmt.Println("newRandStream closure exited.")
defer close(randStream) // ところで、closeするのは所有者の責任だよね
for {
select {
case randStream <- rand.Int():
case <-done:
return
}
}
}()
return randStream
}
done := make(chan interface{})
randStream := newRandStream(done)
fmt.Println("3 random ints:")
for i := 1; i <= 3; i++ {
fmt.Printf("%d: %d\n", i, <-randStream)
}
fmt.Printf("ゴルーチンの数: %d\n", runtime.NumGoroutine())
// doneチャネルの所有者はMainゴルーチン
// なので、責任を持ってcloseする
close(done)
// ゴルーチンのdeferの処理を待つためのSleep
time.Sleep(1 * time.Second)
fmt.Printf("ゴルーチンの数: %d\n", runtime.NumGoroutine())
}
こうなる
$ go run main.go
3 random ints:
1: 5577006791947779410
2: 8674665223082153551
3: 6129484611666145821
ゴルーチンの数: 2
newRandStream closure exited.
ゴルーチンの数: 1
HTTPサーバーでお手軽ゴルーチンリーク
package main
import (
"fmt"
"net/http"
"runtime"
)
// $ for i in {1..10}; do curl "localhost:8080"; done
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
ch := make(chan int)
go func() {
ch <- 456
}()
go func() {
ch <- 123
}()
<-ch
fmt.Fprintf(w, "NumGoroutine: %d\n", runtime.NumGoroutine())
})
http.ListenAndServe(":8080", nil)
}
こうなる
- 2つのゴルーチンのうち、必ず片方しか終了にならないから
-
<-chをもう1つ増やせば、ちゃんと終了するようになる
-
$ go run main.go
$ for i in {1..10}; do curl "localhost:8080"; done
NumGoroutine: 4
NumGoroutine: 5
NumGoroutine: 6
NumGoroutine: 7
NumGoroutine: 8
NumGoroutine: 9
NumGoroutine: 10
NumGoroutine: 11
NumGoroutine: 12
NumGoroutine: 13
selectを使ってゴルーチンリークを回避してみるものの、結局処理が止まってしまう例
- 秘孔を突くと、すぐ止まる
package main
import (
"fmt"
"net/http"
"runtime"
"time"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
ch := make(chan int)
// selectを使っているので、ゴルーチンはちゃんと終了する
go func() {
select {
case ch <- 123:
default:
}
}()
go func() {
select {
case ch <- 123:
default:
}
}()
// 少しsleepして、2つのゴルーチンがdefaultで終わるようにする
time.Sleep(100 * time.Millisecond)
<-ch
fmt.Fprintf(w, "NumGoroutine: %d\n", runtime.NumGoroutine())
})
http.ListenAndServe(":8080", nil)
}
こうなる
$ go run 6/main.go
$ curl localhost:8080
# ずーっと終わらない
ゴルーチンリークだし、Mainゴルーチンも永久待機してしまう例
- URLの数だけゴルーチンをつくる
- チャネルの
for-range使うとこういうことになりがちかもしれない。初心者のうちは。 - 『Go言語による並行処理』では、1つの仕事(ここではHTTPリクエスト)に対して1つのゴルーチンにしているから、こういう例はあんまりないかも?
package main
import (
"fmt"
"log"
"net/http"
)
type Result struct {
Err error
Response *http.Response
Url string
}
func (r *Result) String() string {
return fmt.Sprintf("%s: %s", r.Url, r.Response.Status)
}
func main() {
urls := []string{
"https://example.com",
"https://python.org",
"https://google.com",
"https://badhost",
}
newResults := func(urls []string) <-chan Result {
results := make(chan Result)
for _, url := range urls {
go func(url string) {
resp, err := http.Get(url)
result := Result{
Err: err,
Response: resp,
Url: url,
}
// 素直に送信しているが...
results <- result
}(url)
}
return results
}
results := newResults(urls)
// 本当に終了条件のないfor文になってしまっている
for result := range results {
if result.Err != nil {
log.Println(result.Err)
continue
}
fmt.Println(result.String())
}
}
$ go run ch4/4.3/7/main.go
2021/07/23 13:13:40 Get "https://badhost": dial tcp: lookup badhost: no such host
https://google.com: 200 OK
https://example.com: 200 OK
https://python.org: 200 OK
# このままずーっと終わらない
doneチャネル導入と、rangeをやめる、で解決する
package main
import (
"fmt"
"log"
"net/http"
"runtime"
)
type Result struct {
Err error
Response *http.Response
Url string
}
func (r *Result) String() string {
return fmt.Sprintf("%s: %s", r.Url, r.Response.Status)
}
func main() {
urls := []string{
"https://example.com",
"https://python.org",
"https://google.com",
"https://badhost",
}
done := make(chan interface{})
defer close(done)
defer fmt.Printf("ゴルーチン数: %d\n",runtime.NumGoroutine())
newResponses := func(done <-chan interface{}, urls []string) <-chan Result {
results := make(chan Result)
for _, url := range urls {
go func(url string) {
resp, err := http.Get(url)
result := Result{
Err: err,
Response: resp,
Url: url,
}
select {
// selectを仕込んでちゃんとゴルーチンを終了できるようにしておく
case <-done:
return
case results <- result:
}
}(url)
}
return results
}
results := newResponses(done, urls)
for i := 0; i < len(urls); i++ {
result := <-results
if result.Err != nil {
log.Println(result.Err)
continue
}
fmt.Println(result.String())
}
fmt.Printf("ゴルーチン数: %d\n",runtime.NumGoroutine())
}
$ go run main.go
2021/07/23 13:12:11 Get "https://badhost": dial tcp: lookup badhost: no such host
https://google.com: 200 OK
https://example.com: 200 OK
https://python.org: 200 OK
ゴルーチン数: 6
ゴルーチン数: 1
第4章 4.4 orチャネル
あとで
第4章 4.5 エラーハンドリング
- 激烈に重要な章だと思う。
- 並行処理に関係なく、重要
- エラーは値だよ! 値なんだ!
エラーハンドリングで最も考えるべきこと: 誰が捌くか?
エラーハンドリングについて考えるときに最も根本的な疑問は、**「誰がそのエラーを処理する責任を持つべきか」**です。
プログラムはそのエラーの伝搬をコールスタックの途中のどこかで止めて、実際に そのエラーを受けて何かを行う必要があります。こうした作業には何が責任を果たすべきなのでしょうか。
これは並行処理とか関係なく重要な話。
そして、並行処理だとさらに複雑な話になる
だから、俺が裁く! ピシュゥ!!
並行処理プロセスにおいて、起きたエラーをに対して誰が何を行うか問題の例
-
checkStatus内のゴルーチンは、エラーを出力するのが精一杯 - エラーメッセージを出力することはエラーハンドリングじゃないぞ!
- 「たのむぅ〜、だれがエラーをさばいてくれ〜」
package main
import (
"fmt"
"net/http"
)
func main() {
checkStatus := func(
done <-chan interface{},
urls ...string,
) <-chan *http.Response {
responses := make(chan *http.Response)
go func() {
defer close(responses)
for _, url := range urls {
resp, err := http.Get(url)
if err != nil {
// ① このゴルーチンができるのはエラーを出力するところまで!
// 「親Goroutineに、エラーを返して、親が処理する」みたいなことができない!
// エラーを返せないので、**誰かが処理してくれることを願うことしかできない**
fmt.Println(err)
continue
}
select {
case <-done:
return
case responses <- resp:
}
}
}()
return responses
}
done := make(chan interface{})
defer close(done)
urls := []string{
"https://www.google.com",
"xxx",
"https://badhost",
"yyy",
"https://example.com",
}
for response := range checkStatus(done, urls...) {
fmt.Printf("Response: %v\n", response.Status)
}
}
こうなる
$ go run 1/main.go
Response: 200 OK
Get "xxx": unsupported protocol scheme ""
Get "https://badhost": dial tcp: lookup badhost: no such host
Get "yyy": unsupported protocol scheme ""
Response: 200 OK
エラーハンドリングという関心事を、広いコンテキストを持っているヤツに任せる(関心事の分離)
-
checkStatusの内側という小さなコンテキストではなく、もっと広いコンテキストでエラーハンドリングを行う - ∠( ゚д゚)/ Mainゴルーチン「だから、俺が裁く! 」ピシュゥ!!
- 逆にいえば、内側のゴルーチンはエラーは処理しない
-
Result型に、すべての情報(エラー情報とうまくいった場合のレスポンス)を詰め込んでいるだけ
-
package main
import (
"fmt"
"net/http"
)
type Result struct {
Error error
Response *http.Response
}
func main() {
checkStatus := func(
done <-chan interface{},
urls ...string,
) <-chan Result {
results := make(chan Result)
go func() {
defer close(results)
for _, url := range urls {
resp, err := http.Get(url)
// if err != nil のチェックは、ゴルーチン内でやらない!
result := Result{
Error: err,
Response: resp,
}
select {
case <-done:
return
case results <- result:
}
}
}()
return results
}
done := make(chan interface{})
defer close(done)
urls := []string{
"https://www.google.com",
"xxx",
"https://badhost",
"yyy",
"https://example.com",
}
for result := range checkStatus(done, urls...) {
// ゴルーチンの中(相対的に"小さな"コンテキスト)で起きたエラーを
// "大きな"コンテキストで扱えている!
if result.Error != nil {
fmt.Printf("Error: %v\n", result.Error)
continue
}
fmt.Printf("Response: %v\n", result.Response.Status)
}
}
こうなる
$ go run 2/main.go
Response: 200 OK
Error: Get "xxx": unsupported protocol scheme ""
Error: Get "https://badhost": dial tcp: lookup badhost: no such host
Error: Get "yyy": unsupported protocol scheme ""
Response: 200 OK
3回エラーが起きたら処理を停止するように改造
- 要は、広いコンテキストで「エラーを扱える」ようになったら、こういう改造もできるんだと思う
package main
import (
"fmt"
"net/http"
)
type Result struct {
Err error
Response *http.Response
}
// p.101 3つ以上のエラーが発生したら処理を停止する
func main() {
checkStatus := func(done chan interface{}, urls ...string) <-chan Result {
results := make(chan Result)
go func() {
defer close(results)
for _, url := range urls {
resp, err := http.Get(url)
result := Result{
Err: err,
Response: resp,
}
select {
case <-done:
return
case results <- result:
}
}
}()
return results
}
done := make(chan interface{})
defer close(done)
urls := []string{
"https://www.google.com",
"xxx",
"https://badhost",
"yyy",
"https://example.com",
}
errCount := 0
for result := range checkStatus(done, urls...) {
if result.Err != nil {
errCount++
fmt.Printf("Err: %v\n", result.Err)
if errCount >= 3 {
fmt.Println("Too many errors, breaking!")
break
}
continue
}
fmt.Printf("Response: %v\n", result.Response.Status)
}
}
こうなる
$ go run 3/main.go
Response: 200 OK
Err: Get "xxx": unsupported protocol scheme ""
Err: Get "https://badhost": dial tcp: lookup badhost: no such host
Err: Get "yyy": unsupported protocol scheme ""
Too many errors, breaking!
if err != nil を単なるお決まりイディオムだと思い込んでしまう「不幸」
これは不幸なことですし、語弊があり、そして容易に訂正が可能なことです。おそらく、そのように信じてしまっているような状況になったのは、信じているプログラマがGoを使い始めてまだ日が浅く、「エラーをどう処理したらよいか」という問いに対して、このパターンを覚えて、そこで止まってしまっているのだと思います。
思考停止 if err != nil はエラーハンドリングしている風というかそういう感じだな。
エラーハンドリングのことを考えていないことの現れかもしれない。
エラーは値、値なんだから、検証以外にもいろいろできる
もちろん、エラー値がnilかどうかを検証する文はよくありますが、エラー値でできることは他にもたくさんあります。
そしてそれらをあなたのプログラムに適用することで、プログラムが改善され、丸暗記で使っているおきまりの形のif文を 排除することができます。
第4章 4.6 パイプライン
あとで
第4章 4.6.1 パイプライン構築のためのベストプラクティス
あとで
第4章 4.6.2 便利なジェネレーターをいくつか
あとで
第4章 4.7 ファンアウト、ファンイン
あとで
第4章 4.8 or-doneチャネル
あとで
第4章 4.9 teeチャネル
あとで
第4章 4.10 bridgeチャネル
あとで
第4章 4.11 キュー
あとで
第4章 4.12 contextパッケージ
あとで
コンテキストの親子関係とキャンセル伝播の実験
-
子どもコンテキストがキャンセルされても、親コンテキストはキャンセルされない
-
親コンテキストのキャンセルは、子どもコンテキストにも伝搬する
-
ctx.Err()には何が理由でキャンセルされたか情報が格納される - 下記の例で言えば、
context canceledが入るわけよ(親コン的
-
-
以降のコードでは、
<-ctx.Done()のブロックがいつ解除されるかに着目すればいい感じ!
1. 親コンテキストが先にキャンセルされる場合
package main
import (
"context"
"fmt"
"time"
)
func main() {
ctxParent, cancelParent := context.WithCancel(context.Background())
timeLimit := 1 * time.Second
ctxChild, cancelChild := context.WithTimeout(ctxParent, timeLimit)
defer cancelChild()
go func() {
// cancelParent() を timeLimit より先に実行されるようにする
time.Sleep(500 * time.Millisecond)
cancelParent()
fmt.Println("親コンテキストでキャンセル!")
}()
// ctxChild.Done() がブロック解除されるパターンは2つ
// 1. cancelParent() が Timeoutの timeLimit が「来る前」に実行された場合
// 2. cancelParent() が Timeoutの timeLimit が「来た後」に実行された場合
<-ctxChild.Done()
// どちらも同じ値になる!
// 親コンテキスト(WithCancel)がキャンセルされたので、
// 子コンテキスト(WithTimeout)もキャンセルされる
fmt.Printf("ctxParent.Err() = %v\n", ctxParent.Err()) // context canceled
fmt.Printf("ctxChild.Err() = %v\n", ctxChild.Err()) // context canceled
fmt.Println("----- main() done ------")
}
2. 子コンテキストが先にキャンセルされる場合
package main
import (
"context"
"fmt"
"time"
)
func main() {
ctxParent, cancelParent := context.WithCancel(context.Background())
timeLimit := 1 * time.Second
ctxChild, cancelChild := context.WithTimeout(ctxParent, timeLimit)
defer cancelChild()
go func() {
// cancelParent() を timeLimit より後に実行されるようにする
time.Sleep(3 * time.Second)
cancelParent()
fmt.Println("親コンテキストでキャンセル!")
}()
// ctxChild.Done() がブロック解除されるパターンは2つ
// 1. cancelParent() が Timeoutの timeLimit が「来る前」に実行された場合
// 2. cancelParent() が Timeoutの timeLimit が「来た後」に実行された場合
<-ctxChild.Done()
fmt.Printf("ctxParent.Err() = %v\n", ctxParent.Err()) // <nil>
fmt.Printf("ctxChild.Err() = %v\n", ctxChild.Err()) // context deadline exceeded
fmt.Println("----- main() done ------")
}