2021年末年始からプログラミング言語を開発しているメモ
2021年末の長期休暇のメモ。まず、ずっと気になっていた、Rust のパターンマッチ解析のコードを軽く眺めた(論文読んでもよく分からなかった)。
パターンマッチがない Go 言語でライブラリ実装してみるか(いいものができる気がしなかった)、放置気味の言語開発で試しに実装してみるか、と思ったが、せっかくの長期休暇なので新しいミニ言語で実装してみる。
今までパーサは、手書きの再帰下降パーサで実装していたので、ライブラリを使ってみたい。
- Parsing Expression Grammar (PEG)
- コード生成ではないものがいい
Rust の PEG ライブラリである kevinmehall/rust-peg: Parsing Expression Grammar (PEG) parser generator for Rust を触りはじめた。
proc macro で以下のように文法を書いていくのだが、VSCode だと Spaces: 2 と解釈されてしまう。
peg::parser!{
grammar list_parser() for str {
rule number() -> u32
= n:$(['0'..='9']+) {? n.parse().or(Err("u32")) }
pub rule list() -> Vec<u32>
= "[" l:(number() ** ",") "]" { l }
}
}
これを防ぐには、Settings.json で editor.detectIndentation をオフにしてやる必要があるっぽい。
"[rust]": {
"editor.detectIndentation": false
},
bench ディレクトリに JSON parser の例があるので参考になる。
_ or __ or ___ - Rule (underscore): As a special case, rule names consisting of underscores can be defined and invoked without parentheses. These are conventionally used to match whitespace between tokens.
peg - Rust
LSP を含む IDE サポートを見据えると、Fault torelant で Error Recovery のできる Parser がいいということで、Chumsky を試してみる。
今回、構文にはあまり興味ないので Rubyっぽくする。複文対応も後回し。意味解析やコード生成を先にやる。
- def...end by ishikawa · Pull Request #5 · ishikawa/paty
- Remove semicolon from let by ishikawa · Pull Request #6 · ishikawa/paty
- Add puts function (built-in) by ishikawa · Pull Request #7 · ishikawa/paty
five = 5
def add (x, y)
x + y
end
eight = 3 + five
puts(add(five, eight))
今はチュートリアルのまま構文木をそのまま実行しているので、これをネイティブで実行できるようにしたい。そのために、C のコードに変換するバックエンドを追加する。
-
On the benefits of using C as a language backend · Discussion #7849 · vlang/v
-
意味解析
- トップレベルと関数定義を分ける
- 変数割り当て
-
コード生成
- 関数はそのまま C の関数に
- トップレベルは(とりあえず)
main関数に -
putsはprintfの列にする
雑な C バックエンドを書いたので、簡単にテストも追加しておく。テストの仕方は 低レイヤを知りたい人のためのCコンパイラ作成入門 を参考にした。
C99 以降、C 言語を書かなくなって久しく色々忘れてる。
- Clang - Options to Control Error and Warning Messages
- Diagnostic flags in Clang — Clang 13 documentation-
-
-pedanticオプションは非推奨で、-Wpedanticになったらしい - headers
やっと、元々の目的であるパターンマッチの実装に入れる(いまのところ整数型しかないが)。意味解析を後回しにして、まずは実行可能にする。
以下のようなコードを
# fibonacci number
def fib(n)
case n
when 1
1
when 2
1
else
fib(n - 1) + fib(n - 2)
end
end
f = fib(10)
puts(f)
次のような C 言語に変換する。
#include <stdio.h>
#include <stdint.h>
#include <inttypes.h>
// fibonacci number
int64_t fib(int64_t n)
{
int64_t t0;
if (n == INT64_C(1))
{
t0 = INT64_C(1);
}
else if (n == INT64_C(2))
{
t0 = INT64_C(1);
}
else
{
t0 = fib(n - INT64_C(1)) + fib(n - INT64_C(2));
}
return t0;
}
int main(void)
{
int64_t f = fib(INT64_C(10));
printf("%" PRId64 "\n", f);
return 0;
}
- 今の実装は、適当に
returnしているが、関数の最後の式だけreturnするように変える - 式ではない
ifに変換するので一時変数tNが必要。- ということは、case 式を変換したあとで結果を格納した一時変数を
returnする - 一時変数の名前もユーザーの定義した変数と衝突しないようにしないといけない
- 意味解析時にスコープにある変数を調べて Mangle? 後回し
- コメントを維持するのも意外と難しい
- ということは、case 式を変換したあとで結果を格納した一時変数を
コメントを維持するのも意外と難しい
どこにでもコメントが挿入される可能性がある。
# comment 1
# comment 2
def
# comment 3
add( # comment 4
a, b) # comment 5
end
# comment 6
プログラマは意図を持ってコメントを書いているので、できるだけ位置も保持したいところだが、割と難しい。
-
トークナイズのフェーズで頑張れば、前後のコメントを区別できるが、ひとつ前に読んだトークンを覚えておかないといけない
-
トークン自体にコメントを持たせると、ノードを構築するところで chumsky の combinator を使うのが難しくなってしまう
-
コメントは、次のノードに紐づける。ファイル末尾のコメントは無視、くらいでいいかも
Rust の型変換イディオム - Qiita この記事に何度お世話になったか分からない 🙏
今は構文木を直接 C コードに変換しているため、ナイーブに実装すると大量の一時変数ができてしまう。
# fibonacci number
def fib(n)
case n
when 1
1
when 2
1
else
fib(n - 1) + fib(n - 2)
end
end
f = fib(10)
puts(f)
が、こんな感じ
#include <stdio.h>
#include <stdint.h>
#include <inttypes.h>
// fibonacci number
int64_t fib(int64_t n)
{
int64_t t0;
int64_t t1;
t1 = n;
if (t1 == INT64_C(1))
{
int64_t t2;
t2 = INT64_C(1);
t0 = t2;
}
else if (t1 == INT64_C(2))
{
int64_t t3;
t3 = INT64_C(1);
t0 = t3;
}
else
{
int64_t t4;
int64_t t5;
int64_t t6;
int64_t t7;
t7 = n;
int64_t t8;
t8 = INT64_C(1);
t6 = t7 - t8;
t5 = fib(t6);
int64_t t9;
int64_t t10;
int64_t t11;
t11 = n;
int64_t t12;
t12 = INT64_C(2);
t10 = t11 - t12;
t9 = fib(t10);
t4 = t5 + t9;
t0 = t4;
}
return t0;
}
int main(void)
{
int64_t t0;
int64_t t1;
t1 = INT64_C(10);
t0 = fib(t1);
int64_t f = t0;
int64_t t2;
t2 = f;
printf("%" PRId64 "\n", t2);
return 0;
}
- Span で管理されている
-
Range<T>と(Context, Range<T>)に実装済み - parser では offset や context は関与していない
-
- Span を生成するのは Stream
- Stream は内部で Iterator を保持しており、生成時に与えられたインプット(文字列など)から Iterator を作っている
- 文字列の場合は char の Iterator. Span はインデックスの
i..i + 1
- なので、行番号を追跡するためには、
- 文字列(など)から、char と行番号を管理できる Span を返す Iterator を作る
-
Stream::from_iterで Stream を作るFromtrait 実装 -
parse(...)でいけそう - 注意点
-
Stream::from_iterでは、入力の終端を示す Span を渡す必要がある 文字列から生成するときの例 - この Span はインデックスも管理していて、Eq の判定はインデックスのみを使うようにすれば、あらかじめ終端まで読む必要はなさそう。
-
Arena これまでは arena allocator として bumpalo を使っていたのだが、これはひとつの arena で多様な型のメモリを確保できる代わりに、deallocation が面倒くさい、という難点があった。今回は typed_arena を試してみる。
とりあえず、Rust のパターンマッチ解析のコードをベタに移植した。リテラルとワイルドカードパターンのみ。
まだちゃんとコードを理解していないので、他のパターンも追加していく。
IR
C を直接生成するのは辛いので、とりあえず現時点で必要な抽象化を入れた IR を生成する。
- 一時変数の割り当てと代入
- 不要な一時変数を削除したい
- 最終的な C コードを読みやすくするため
- 使われていない変数がエラーになるので
- 不要な一時変数を削除したい
- 条件分岐は
if,switchまたは?:に変換できるようにする- 元の
case..when..に近いものになりそう - Wasm より C 寄り
- 元の
- AST から簡単に生成できること
- 一度生成したあとで最適化する
main(void): // Function
---
t0 = 5 // TmpVarDef(t0, Int(5))
five = t0 // VarDef(five, f0)
t1 = five // TmpVarDef(t1, Var(five))
printf(t1) // Printf(TmpVar(t1))
ret 0 // Ret(Int(0))
fib(n):
---
t0 = n
t1 = cond {
t0 >= 1 && t0 <= 2 -> // And(Ge(TmpVar(t0), Int(1)), Le(TmpVar(t0), Int(2)))
t2 = 1
ret t2
_ ->
t3 = n
t4 = 1
t5 = t3 - t4
t6 = fib(t5)
t7 = n
t8 = 2
t9 = t6 - t7
t10 = fib(t9)
t11 = t6 + t10
ret t11
}
ret t1
関数引数での Tuple パターンも動くようになった。
def foo((x, y): (int64, int64))
x + y
end
puts(foo((10, 20)))
変換後の C 言語では、仮引数にテンポラリな名前を割り当て、関数先頭に代入文を生成。
int64_t foo(struct _T2i64i64 t0)
{
int64_t x = t0._0;
int64_t y = t0._1;
return (x + y);
}
今のところ、不要な変数代入削除は、一時変数にしか実装していないが、これを普通の変数にも一般化すれば、上記の生成コードはこうなるはず。
int64_t foo(struct _T2i64i64 t0)
{
return (t0._0 + t0._1);
}
もう少しパターンマッチの実装を勉強するために以下の機能を追加したい。
-
文字列定数
- メモリ管理はまだしたくないので定数のみ
- C レベルでは
const uint8_t *
-
真偽値、タプル、シンボルを追加
- メモリ管理はまだしたくない
- タプルは構造体のコピー
- シンボルは整数値?
- とりあえず文字列定数でもいいかな...
- タプルと組み合わせて
(:ok, int64)のような型になる
-
型指定
-
関数の引数には型を指定する
- IDE 支援を考えると、型を指定した方がいい
- 今のところ、型指定を省略した場合は
int64既存テストとかの書き換えが面倒なので- 将来的には
anyとかunknownを導入?
- 引数名の後ろに型を書くスタイル
def foo(n: int64)
-
型
- 組み込み型は小文字
int64booleanstring:symbol(:ok, int64)
-
真偽値を実装した。式の型が分からないとこれ以上進めるのが難しくなってきたので、引数の型指定と型推論を実装したい。型推論といえば Hindley–Milner 型システムの Algorithm W なのだが、型変数もない現状では、ナイーブな実装で十分な気がする。
タプルのシンタックスについて。Elixir/Erlang は
{Term1, ..., TermN}
だが、{...} は構造体やマップに使いたい。また、JavaScript の short hand property name のような構文を入れた場合、
{x, y, z}
のような表記が衝突する。個人的にこの構文は入れたいので、タプルは Python や Rust のように
(Term1, ... TermN)
にする。1 要素のタプルは (Term1,) になって気持ち悪いが、まあ、滅多に使わないので。
シンボルの必要性
Ruby や Lisp などにおけるシンボル (:symbol, 'symbol) は、
- 短い文字列のような値
- 辞書のキーや列挙型のように使える
- 同じ値のシンボルは唯一ひとつしか存在しない (internalized) ので比較が高速
という特徴があり、非常に便利で、実際によく使われている。
しかし、文字列のような値であるのに、文字列として扱うには変換が必要であり、文字列をキーに持つ辞書を変換するときはかなり面倒である。文字列と等価交換できるようにするか、むしろ、文字列をそのまま使えるとなお良い。
- 短い文字列のような値 文字列をそのまま使う。また、文字列は不変であるとする。
-
辞書のキーや列挙型のように使える String 型としても使えるし、TypeScript のように
"ok" | "error"のように直和型でリテラルをそのまま使える -
同じ値のシンボルは唯一ひとつしか存在しない (internalized) ので比較が高速 十分に短い文字列であれば、比較がそんなに遅いだろうか?
- 多くのシンボルは小文字のアルファベットと数種類の記号で構成されているので、64bit 整数にエンコードできる気がする
- 30文字として 5 bits
- 12文字いけそう。0 終端。シンボルとしては十分な長さ
- 残り 4 bits をフラグに使う
- 大文字を含む場合はフラグをセットして、6文字までいける
- メモリでシンボルの辞書を管理するよりも、管理が楽だし、どの環境でも同じ値になる
- 他の文字列と比較するときは、変換する必要がある
- 短いのでスタック上で変換することができる
- ただ、ビット操作なので遅そう
- 変換なしで文字列と比較する関数があった方がいいかも
- 多くのシンボルは小文字のアルファベットと数種類の記号で構成されているので、64bit 整数にエンコードできる気がする
TypeScript で関数の返り値が推論されるとき、以下のように条件分岐で複数の値のいずれかを返せば、リテラル型の Union になる。
// function foo1(n: number): "ok" | "ng"
function foo1(n: number) {
if (n === 1) {
return "ok";
} else {
return "ng";
}
}
しかし、以下の場合はリテラル型にはならない (Widening される)。
// function foo2(): string
function foo2() {
return "ok";
}
So the issue is one of practicality: people rarely intend to return single literal types, but they often do intend to return unions of literal types.
要するに、こういう挙動の方が実用的だから、ということみたいだ。
TypeScript のリテラル型は文字列を列挙型のように扱う目的が大半(だと思う)。これを踏まえて、シンボルは、常にリテラル型として解釈される文字列型ということにすればいいかも?
chumsky で組んだ parser のコンパイル時間が異様に長くなってしまった...。境界にライフタイムを追加するとやばい感じ。
$ time cargo build
cargo build 375.40s user 6.13s system 106% cpu 5:56.81 total
chumsky で組んだ parser のコンパイル時間が異様に長くなってしまった...。
解決できそうにないので、再帰下降パーサーで書き直すことにした。とりあえず、Lexer は chumsky のまま。
再帰下降パーサーで書き直して、無事に(?)コンパイルが通るようになった。
[paty] $ cargo clean
[paty] $ time cargo build
cargo build 23.80s user 3.31s system 239% cpu 11.327 total
完全に忘れていたが C99 から構造体の初期化に Designated initializer が使えるので、Tuple はこんな感じで実装。
#include <stdio.h>
#include <stdint.h>
#include <stdbool.h>
#include <inttypes.h>
#include <string.h>
struct _T3i64i64i64
{
int64_t _0;
int64_t _1;
int64_t _2;
};
int main()
{
struct _T3i64i64i64 date = {._0 = INT64_C(2022), ._1 = INT64_C(1), ._2 = INT64_C(22)};
printf("%" PRId64 " %" PRId64 " %" PRId64 "\n", date._0, date._1, date._2);
return 0;
}
Tuple を表現するための構造体は、とりあえず以下のような可変長フォーマットで名前を生成
Integer types
+-----+-------------------------+
| "i" | digits (number of bits) |
+-----+-------------------------+
Tuple type
+-----+---------------------------+----------+
| "T" | digits (number of fields) | (fields) |
+-----+---------------------------+----------+
Other types
| Type | Format |
|---|---|
boolean |
"b" |
string |
"s" |
int (C type) |
"ni" |
今まで puts(...) から C ライブラリの printf(...) に変換するときは C のコードジェネレータでやっていたが、これだと Tuple の要素を分解するときにコード生成がうまくいかないので、IR の時点で変換 (= マクロの展開と同様の考え) にした。64bit 整数のフォーマットに C マクロを使う必要があるので少々面倒くさいが、以下のような生成コードになった。
#include <stdio.h>
#include <stdint.h>
#include <stdbool.h>
#include <inttypes.h>
#include <string.h>
struct _T3i64i64i64
{
int64_t _0;
int64_t _1;
int64_t _2;
};
int main()
{
struct _T3i64i64i64 t3 = (struct _T3i64i64i64){._0 = INT64_C(1), ._1 = INT64_C(2), ._2 = INT64_C(3)};
printf(u8"(%" PRId64 u8", %" PRId64 u8", %" PRId64 u8")\n", t3._0, t3._1, t3._2);
return 0;
}
64bit 整数のフォーマットに C マクロを使う必要があるので少々面倒くさいが、以下のような生成コードになった。
あとで気づいたが、これだと IR がバックエンドに依存してしまうので、もう少し抽象化する必要がある。
- IR に
printf([ string | expression ])を追加し、format specifier の生成を C バックエンドで処理するようにした。
Tuple 型の実装はできたので、変数パターンの実装をやる。
関数の引数にもパターンを書けるようにしているが、そうすると以下のようなコードを書ける。
def foo(_, _, z)
puts(z)
end
これは次のような C に変換される。
int64_t foo(int64_t _0, int64_t _1, int64_t z)
{
return z;
}
しかし、これは -Wunused-parameter をつけてコンパイルすると警告が出てしまう。
./_tmp/test18.c:7:21: error: unused parameter '_0' [-Werror,-Wunused-parameter]
int64_t foo(int64_t _0, int64_t _1, int64_t z)
^
./_tmp/test18.c:7:33: error: unused parameter '_1' [-Werror,-Wunused-parameter]
int64_t foo(int64_t _0, int64_t _1, int64_t z)
とはいえ、引数を省略することはできないので、このままだと困ってしまう。これは以下のようにすれば回避できるらしい
int64_t foo(int64_t _0, int64_t _1, int64_t z)
{
(void)_0;
(void)_1;
return z;
}
こういうコードをコンパイルできるようにした。
(x, y, z) = (11, 22, 33)
puts(x + y + z)
コンパイル後
struct _T3i64i64i64
{
int64_t _0;
int64_t _1;
int64_t _2;
};
int main()
{
struct _T3i64i64i64 t3 = (struct _T3i64i64i64){._0 = INT64_C(11), ._1 = INT64_C(22), ._2 = INT64_C(33)};
int64_t x = t3._0;
int64_t y = t3._1;
int64_t z = t3._2;
printf("%" PRId64 "\n", ((x + y) + z));
return 0;
}
Tuple で C 構造体が入ってきたので、forward declaration 問題が出てきた。ネストした Tuple による変数代入、例えば、こういうコードは、
((a, b, c), (d, e), (f,)) = ((11, 22, 33), (44, 55), (66,))
puts(a + b + c + d + e + f)
深さ優先でコード生成することで、未定義の C 構造体を参照しないようにした。
struct _T3i64i64i64
{
int64_t _0;
int64_t _1;
int64_t _2;
};
struct _T2i64i64
{
int64_t _0;
int64_t _1;
};
struct _T1i64
{
int64_t _0;
};
struct _T3T3i64i64i64T2i64i64T1i64
{
struct _T3i64i64i64 _0;
struct _T2i64i64 _1;
struct _T1i64 _2;
};
int main()
{
struct _T3T3i64i64i64T2i64i64T1i64 t9 = (struct _T3T3i64i64i64T2i64i64T1i64){._0 = (struct _T3i64i64i64){._0 = INT64_C(11), ._1 = INT64_C(22), ._2 = INT64_C(33)}, ._1 = (struct _T2i64i64){._0 = INT64_C(44), ._1 = INT64_C(55)}, ._2 = (struct _T1i64){._0 = INT64_C(66)}};
int64_t a = t9._0._0;
int64_t b = t9._0._1;
int64_t c = t9._0._2;
int64_t d = t9._1._0;
int64_t e = t9._1._1;
int64_t f = t9._2._0;
printf("%" PRId64 "\n", (((((a + b) + c) + d) + e) + f));
return 0;
}
関数引数での Tuple パターンも動くようになった。
def foo((x, y): (int64, int64))
x + y
end
puts(foo((10, 20)))
変換後の C 言語では、仮引数にテンポラリな名前を割り当て、関数先頭に代入文を生成。
int64_t foo(struct _T2i64i64 t0)
{
int64_t x = t0._0;
int64_t y = t0._1;
return (x + y);
}
今のところ、不要な変数代入削除は、一時変数にしか実装していないが、これを普通の変数にも一般化すれば、上記の生成コードはこうなるはず。
int64_t foo(struct _T2i64i64 t0)
{
return (t0._0 + t0._1);
}
今まではこういうコードをコンパイルすると、
case (10, 20, 30)
when (x, y, z)
puts(x + y + z)
end
ワイルドカードを if (true) として生成していたので、無駄な条件判定が生成されていた。
if (((true && true) && true))
{
int64_t x = t4._0;
int64_t y = t4._1;
int64_t z = t4._2;
printf("%" PRId64 "\n", ((x + y) + z));
}
あまりに不恰好なので、ワイルドカードと変数パターンでの条件判定は除去するようにした。
{
int64_t x = t4._0;
int64_t y = t4._1;
int64_t z = t4._2;
printf("%" PRId64 "\n", ((x + y) + z));
}
もともとパターンマッチの実験的実装として、年末年始の暇つぶしにはじめたプロジェクトだが、それなりに動いてきた
次は構造体を実装したい。構文はちょっと迷うが今はあまりこだわらずに C 風にする。
struct T {
a: int64,
b: boolean,
}
t = T { a: 100, b: true }
C の構造体は最低でもひとつメンバーが必要なのか...。知らなかった。
(C11, 6.7.2.1 Structure and union specifiers p8) "If the struct-declaration-list does not contain any named members, either directly or via an anonymous structure or anonymous union, the behavior is undefined."
構造体で初めて、ユーザー定義型を名前で参照するようになったので、Parse はできたけど、型の解決はまだ、という状態がありえるようになった。
-
Type::Namedを導入。参照している識別子と、未解決の型Cell<Option<Type>>を持つ -
意味解析フェーズで型を決定
-
こういう「コンパイルフェーズやエラーによって未解決の型」がすでにふたつある (型推論できなかった
Type::Undeterminedと今回のType::Named) -
モジュールの仕組みが入ったら、型の定義にもスコープが出てくるので、さらに複雑になるはず
フィールドを持たない構造体 (Zero-sized struct) の puts などを IR で生成するとき、フィールドを持たないので used カウントが増えない。そのため、変数で参照した構造体を puts に渡していると、C レベルで使用していない変数が残ってしまう。
これを防ぐには、
- 一時変数と同じように未使用変数を除去する最適化を実装するか、
- Zero-sized struct では C コードを生成しないようにする
1 もそのうちやりたいが、今回は 2 で対応するのが良さそう。2 をどのフェーズでやるか、だが、Zero-sized struct とそれを利用するコードでどのようなコードを生成するかは、C レベルでやらないと、IR レベルだけでやるのは難しい。ただ、関数引数も考えると面倒くさいことになりそう。
関数の引数とかはまだやってないけど、とりあえず、こういうコードがあると、
struct A {}
struct B { a: int64 }
struct C { b: B, c: (A, B), }
c = C { b: B { a: 50 }, c: (A {}, B { a: 60 })}
puts(c)
構造体 A はフィールドを持たない Zero-sized struct なので、生成後の C コードには現れないように出来た。
struct _SB
{
int64_t a;
};
struct _T2SASB
{
struct _SB _1;
};
struct _SC
{
struct _SB b;
struct _T2SASB c;
};
int main()
{
struct _SC c = (struct _SC){.b = (struct _SB){.a = INT64_C(50)}, .c = (struct _T2SASB){._1 = (struct _SB){.a = INT64_C(60)}}};
struct _SC t7 = c;
struct _T2SASB t10 = t7.c;
printf("%s { %s: %s { %s: %" PRId64 " }, %s: (%s {}, %s { %s: %" PRId64 " }) }\n", u8"C", u8"b", u8"B", u8"a", t7.b.a, u8"c", u8"A", u8"B", u8"a", t10._1.a);
return 0;
}
関数の引数/返り値も実装した。
struct Zst {}
struct WeAreZst {
one: Zst,
two: Zst,
}
def printZst()
puts(WeAreZst { one: Zst {}, two: Zst {} })
end
_ = printZst()
puts((Zst {},))
上記のコードは以下の C コードになる。
int64_t printZst()
{
return printf("%s { %s: %s {}, %s: %s {} }\n", u8"WeAreZst", u8"one", u8"Zst", u8"two", u8"Zst");
}
int main()
{
printZst();
printf("(%s {})\n", u8"Zst");
return 0;
}
構造体のパターンマッチも動きはじめた。あとはこの辺
- フィールドの省略
-
{ foo: foo }を{ foo }と書けるように
struct D { foo: int64, bar: boolean, baz: string }
d = D { bar: true, foo: 2022, baz: "Year" }
D { bar: x, foo: y, baz: z} = d
case D { bar: x, foo: y, baz: z}
when D { bar: false }
puts(false)
when D { foo: foo, baz }
puts(baz, foo)
end
これはこうなる。
struct _SD
{
int64_t foo;
bool bar;
const char *baz;
};
int main()
{
struct _SD d = (struct _SD){.bar = true, .foo = INT64_C(2022), .baz = u8"Year"};
struct _SD t4 = d;
bool x = t4.bar;
int64_t y = t4.foo;
const char *z = t4.baz;
struct _SD t9 = (struct _SD){.bar = x, .foo = y, .baz = z};
if (!t9.bar)
{
printf("%s\n", (false ? "true" : "false"));
}
else
{
int64_t foo = t9.foo;
const char *baz = t9.baz;
printf("%s %" PRId64 "\n", baz, foo);
}
return 0;
}
- 無駄な変数割り当ては、もっとなくせそう
- 変数は原則 immutable なので、別の変数や構造体のフィールドをそのまま代入しているところは削除していい
- 確実に到達しない分岐は削除するか、警告を出す?
- とりあえず、
false ? "false" : "true"による真偽値の文字列変換はなんとかしたい [1]
- とりあえず、
今後の予定
- 関数のオーバーロード
-
無名構造体
- Structual Matching
パターンマッチと組み合わせて、関数引数の型指定を省略できるようにしたい(アイデア)
def foo(r: Rect, options: {name: string})
...
end
- Or-パターン
- Return type annotation
- Union Type
- リテラル型
- Enum
- Union はあるが、やはり Enum もほしい
- 無名関数/クロージャ
- モジュール
- インターフェース/トレイト
- 他の数値型
- 整数、浮動小数点
- Parser improvements
- String view tokenizer with String#char_indices() and slices.
- Incorporate line and column number.
- LSP server + VSCode plugin
- WebAssembly backend
テストも書きづらくなってきたので、複文を書けるようにした。今まで複数の式を書くためには関数や変数の定義の後にしか書けなかったが、複文対応したことで自由に書けるようになった。
def foo()
puts(1)
puts(2)
end
関数のオーバーロードを実装中。とりあえず、オーバーロードされた関数の候補を解決する処理(複数候補があるとエラー)を意味解析に実装したので、
def foo(n: int64)
puts(n)
end
def foo(b: boolean)
puts(b)
end
def foo(s: string)
puts(s)
end
こういうのが、
int64_t foo(int64_t n)
{
return printf("%" PRId64 "\n", n);
}
int64_t foo(bool b)
{
return printf("%s\n", (b ? "true" : "false"));
}
int64_t foo(const char *s)
{
return printf("%s\n", s);
}
こうなるところまでは来た。
やっぱり構造体のパターンマッチでは、Rust と同じように、フィールドを省略していることを明示した方がいいかも。あとでフィールドを追加したときにコンパイルエラーになってほしい。
C++ の mangling を参考に、以下のようにした。C の呼び出し規約になるパターンもあるので、そこも(適当に)対処済み。
int64_t _Z3foo1i64(int64_t n)
{
return printf("%" PRId64 "\n", n);
}
int64_t _Z3foo1b(bool b)
{
return printf("%s\n", (b ? "true" : "false"));
}
int64_t _Z3foo1s(const char *s)
{
return printf("%s\n", s);
}
int main()
{
_Z3foo1i64(INT64_C(30));
_Z3foo1b(true);
_Z3foo1s(u8"hello");
return 0;
}
メモ。真偽値のパターンで変数割り当てをやると、コンパイルできない。
def baz(t: (boolean, string))
case t
when (true, s)
s
when (false, _)
""
end
end
こんな風にコンパイルされて、変数が初期化されない可能性がある、と判定されてしまう。
const char *_Z3baz1T2bs(struct _T2bs t)
{
struct _T2bs t1 = t;
const char *t0;
if (t1._0)
{
const char *s = t1._1;
t0 = s;
}
else if (!t1._0)
{
t0 = u8"";
}
return t0;
}
if...else... としてコンパイルする必要あり。
上に書いた問題はあるものの、こういうプログラムが、
def baz(n: int64, t: (boolean, string))
puts(baz(n), baz(t))
end
def baz(n: int64)
n * 10
end
def baz(t: (boolean, string))
case t
when (_, s)
s
end
end
baz(10, (true, "baz!"))
こうなるようになったので、とりあえず動く。関数宣言が必要だったのも今回足した。
struct _T2bs
{
bool _0;
const char *_1;
};
int64_t _Z3baz2i64T2bs(int64_t n, struct _T2bs t);
int64_t _Z3baz1i64(int64_t n);
const char *_Z3baz1T2bs(struct _T2bs t);
int64_t _Z3baz2i64T2bs(int64_t n, struct _T2bs t)
{
return printf("%" PRId64 " %s\n", _Z3baz1i64(n), _Z3baz1T2bs(t));
}
int64_t _Z3baz1i64(int64_t n)
{
return (n * INT64_C(10));
}
const char *_Z3baz1T2bs(struct _T2bs t)
{
struct _T2bs t1 = t;
const char *t0;
{
const char *s = t1._1;
t0 = s;
}
return t0;
}
int main()
{
_Z3baz2i64T2bs(INT64_C(10), (struct _T2bs){._0 = true, ._1 = u8"baz!"});
return 0;
}
やっぱり構造体のパターンマッチでは、Rust と同じように、フィールドを省略していることを明示した方がいいかも。あとでフィールドを追加したときにコンパイルエラーになってほしい。
JS のスプレッド構文 と無名構造体と組み合わせて、省略したフィールドをまとめてキャプチャできるといいかも。
struct T
bar: string,
baz: int64,
bow: boolean,
end
t = T { bar: "bar", baz: 123, bow: true }
case t
when T { bow: true, ...x }
puts(x) # { baz: 123, bar: "bar" }
else
puts(0)
end
Uniform function call syntax は、単純な syntax suger として Parser で変換するようにした。[1]
def square(n)
n * n
end
def baz(n, message: string)
n.puts(message)
end
10.square().baz("baz!")
このプログラムがこうなる。
int64_t _Z6square1i64(int64_t n)
{
return (n * n);
}
int64_t _Z3baz2i64s(int64_t n, const char *message)
{
return printf("%" PRId64 " %s\n", n, message);
}
int main()
{
_Z3baz2i64s(_Z6square1i64(INT64_C(10)), u8"baz!");
return 0;
}
無名構造体とスプレッド演算子/パターン
{...} は無名の構造体であり、いつでも自由に定義できる。
def foo(options: {repeat: boolean, count: int64})
...
end
名前つき構造体と異なり、Structual matching であり、無名構造体同士のフィールドと型が同じであれば同じ型として扱われる。
foo({ repeat: true, count: 40 }) # ok
foo({ count: 30, repeat: false }) # ok
# 以下のケースは、現時点ではコンパイルエラー。将来的には許可するかもしれない。
# 名前つき構造体と無名構造体に互換性はない
struct T {repeat: boolean, count: int64}
foo(T { count: 30, repeat: false }) # Error
# 無名構造体で必要なフィールドが定義されているが、余計なフィールドが含まれているのでコンパイルエラー。
foo({ repeat: false, count: 10, message: "dummy" }) # Error
パターンとしても使うことができる。
# { a: int64, b: int64, c: int64 } という無名構造体を定義し値を生成
t = { a: 1, b: 2, c: 3 }
case t
when { a, b: value, c }
...
end
また、構造体パターンでは、フィールドを省略ができなくなる。省略したい場合は、新しく導入されたスプレッドパターンで明示的に指定する。
case t
when T { a, b: value, ... } # `a`, `b` 以外のフィールドは無視する
...
end
スプレッドパターンでは変数名を指定することもでき、省略されたフィールドを無名構造体でキャプチャーできる。
case t
when T { a, b: value, ...x } # x.c で `c` を参照できる。x は無名構造体
...
end
スプレッド演算子も導入され、構造体の初期化に、別の構造体を使うことができる。
struct T {
a: int64,
b: int64,
c: int64,
}
t1 = T { a: 1, b: 2, c: 3 }
t2 = T { ...t1, a: 3, b: 10 } # { a: 3, b: 10, c: 3 }
t3 = T { ...t1, ...t2, ...{ a: 50, c: 40 } } # { a: 50, b: 10, c: 40 }
無名構造体とスプレッド演算子を実装した。思ったよりも面倒だった。
Or-pattern におけるパターンマッチの意味解析。Rust を参考にする。
Or-pattern の実行パスの全てで同じ変数が割り当てられていなければならない。
struct T {
a: i64,
b: i64
}
fn main() {
let t = T { a: 123, b: 456 };
match t {
T { a, .. } | T { b: 3, .. } => println!("a = {}", a),
}
}
error[E0408]: variable `a` is not bound in all patterns
--> src/main.rs:10:23
|
10 | T { a, .. } | T { b: 3, .. } => println!("a = {}", a),
| - ^^^^^^^^^^^^^^ pattern doesn't bind `a`
| |
| variable not in all patterns
同じ名前と型の変数があれば良い。どのパターンが実行されても同じなら良い。また、Or-pattern 内でも unreachable pattern が検出される。
struct T {
a: i64,
b: i64
}
fn main() {
let t = T { a: 123, b: 456 };
match t {
T { a, .. } | T { b: a, .. } => println!("a = {}", a),
}
}
warning: unreachable pattern
--> src/main.rs:10:23
|
10 | T { a, .. } | T { b: a, .. } => println!("a = {}", a),
| ^^^^^^^^^^^^^^
|
= note: `#[warn(unreachable_patterns)]` on by default
変数名が同じでも型が不一致だと駄目。
struct T {
a: i64,
b: bool
}
fn main() {
let t = T { a: 123, b: false };
match t {
T { a, .. } | T { b: a, .. } => println!("a = {}", a),
}
}
error[E0308]: mismatched types
--> src/main.rs:10:30
|
9 | match t {
| - this expression has type `T`
10 | T { a, .. } | T { b: a, .. } => println!("a = {}", a),
| - ^ expected `i64`, found `bool`
| |
| first introduced with type `i64` here
Or パターンを実装した。変数パターンと組み合わせた時に、どのパスを通るかで変数の初期化が変わるのをどうやって実装するか悩んだが、一時変数の代入と && のショートサーキットを組み合わせることで無理矢理対応した。
struct T { a: int64, b: int64 }
def foo(t: T)
case t
when T { a: 1, b: a } | T { a, b: _ }
a
end
end
int64_t _Z3foo1ST(struct _ST t)
{
bool _t3 = false;
int64_t _t0 = 0;
if (((t.a == INT64_C(1)) || ((_t3 = true))))
{
int64_t a = ((_t3) ? t.a : t.b);
_t0 = a;
}
return _t0;
}
次の目標として、リテラル型と Union 型を導入したい。このふたつは関連している上に、エッジケースを考えると微妙な問題もいくつかあるが、TypeScript と Elixir で便利だと思ったので入れてみたい、というのが動機。
- TypeScript: Documentation - Everyday Types
- TypeScript: Documentation - Narrowing
- union typeは楽園ではない - ncaq
- Union Types | Scala 3 — Book | Scala Documentation
まずはリテラル型から考えてみる。
string や int64 のように総称的な型に加えて、特定の文字列や数値を型として扱うことができる。これをリテラル型と言う。
x = "hello"
ここで、x は "hello" 型になり、"hello" 以外の値にはならない。しかし、string 型とは互換性がある。これは、より制約の緩い型に変換されるので、型の Widening と言う。
def print_str(v: string)
puts(s)
end
x = "hello"
print_str("hello") # string 型と互換があるため呼び出せる。
リテラル型と Widening 可能な型の両方を取る関数がある場合、リテラル型の方(より制限の強い型)が優先される。
def print_str(hello: "hello")
puts(s, "world!")
end
def print_str(v: string)
puts(s)
end
print_str("hello") # prints "hello world!"
print_str("hi") # prints "hi"
リテラル型の Widening は、関数の返り値の型を推論するときにも発生する。複数のリテラル型を返す可能性がある関数は、より総称的な型に Widening される。
# この関数は string 型の値を返す。
def describe_code(code: int64)
case code
when -1
"failed"
when 0
"success"
else
"invalid"
end
end
パターンマッチによって、マッチした節の内部だけで、より制限の強い型に推論させることができる。型の Narrowing と言う。
def describe_code(_: -1)
"failed"
end
def describe_code(_: 0)
"success"
end
def describe_code(code: int64)
case code
when -1
describe_code(code)
when 0
describe_code(code)
else
"invalid"
end
end
リテラル型を関数オーバーロードが組み合わさると、かなり微妙な感じがしてくる。
Union Type は複数の型を組み合わせて作り、それらの型のうちいずれかの値を表す型になる。それぞれの型を Union Type の Variant と呼ぶ。
def print_id(id: int64 | string)
puts("Your ID is: ", id)
end
# OK
print_id(101)
# OK
print_id("202")
# Error
print_id({ myID: 22342 })
Union Type は無名であり、その同値性は取りうる Variant のみで判断される。Union Type を名前で参照したい場合は、type 宣言によって別名を与えることができる。
type NumberOrStr = int64 | string
def print_id(id: NumberOrStr)
puts("Your ID is: ", id)
end
Union Type の値では、すべての Variant に共通するフィールドのみアクセス可能。また、Union Type もリテラル型と同じように Narrowing が可能。
struct NetworkLoadingState {
state: "success",
}
struct NetworkFailedState {
state: "failed",
code: int64,
}
struct NetworkSuccessState {
state: "success";
response: {
title: string;
duration: number;
summary: string;
},
}
type NetworkState =
NetworkLoadingState |
NetworkFailedState |
NetworkSuccessState
def logger(state: NetworkState)
# Right now the compiler does not know which of the three
# potential types state could be.
# Trying to access a property which isn't shared
# across all types will raise an error
state.code # The field 'code' does not exist on type 'NetworkState'.
# The field 'code' does not exist on type 'NetworkLoadingState'.
# By switching on state, the compiler can narrow the union
# down in code flow analysis
case state.state
when "loading"
puts("Downloading...")
when "failed"
# The type must be NetworkFailedState here,
# so accessing the `code` field is safe
puts("Error", state.code, "downloading")
when "success":
puts("Downloaded", state.response.title, "-", state.response.summary)
end
end
Union Type 導入後は、複数のリテラル型を返す関数は、それぞれのリテラル型の Union Type を返す関数として推論される。
# この関数は "failed" | "success" | "invaild" 型の値を返す。
def describe_code(code: int64)
case code
when -1
"failed"
when 0
"success"
else
"invalid"
end
end
string 型を返す関数として定義したい場合は、Return Type Annotation で明示的に指定する。
# この関数は string 型の値を返す。
def describe_code(code: int64): string
case code
when -1
"failed"
when 0
"success"
else
"invalid"
end
end
C 言語の構造体をゼロクリアする方法
リテラル型の文字列を実装中
- Rust には存在しない型なので、パターンマッチの網羅性チェックのコードを修正する必要があった。
- C 言語の型としては string 型と同様
const char *として扱われるが、関数のオーバーロードでは区別する必要がある - また、別々の型 (string 型と literal string 型) であっても、C 言語では同一の型になるケースが出てきたので、C 言語に出力するときに二重定義にならないようにする必要があった。
- 今までは型チェックは単純に同一かどうかしか見ていなかったが、リテラル型は対応する基本型に代入可能なので、assignable かどうかでチェックするように変更
一応、リテラル型による関数オーバーロードも実装した。
def greeting(lang: "English")
puts("Hello,", lang)
end
def greeting(lang: "日本語")
puts("こんにちは。", lang)
end
def greeting(lang: string)
puts("Sorry, I don’t speak", lang)
end
greeting("English")
greeting("日本語")
greeting("Deutsch")
このプログラムは以下の C 言語に変換される。関数名としてのリテラル文字列は Base58 でエンコードした。
int64_t _Z8greeting1Ls10_3dc8myzv8w(const char *lang)
{
return printf("%s %s\n", u8"Hello,", lang);
}
int64_t _Z8greeting1Ls13_3wEow4hJpzJFP(const char *lang)
{
return printf("%s %s\n", u8"こんにちは。", lang);
}
int64_t _Z8greeting1s(const char *lang)
{
return printf("%s %s\n", u8"Sorry, I don\'t speak", lang);
}
int main()
{
_Z8greeting1Ls10_3dc8myzv8w(u8"English");
_Z8greeting1Ls13_3wEow4hJpzJFP(u8"日本語");
_Z8greeting1s(u8"Deutsch");
return 0;
}
リテラル型への type narrowing も実装した。今までエラーメッセージ用途に使っていた、パターンから型への変換がそのまま使えた。
def foo(t: { values: (string, string) })
case t.values.1
when "A"
t.values.1 # "A" type
else
t.values.1 # string type
end
end
整数の Literal Type を実装しつつ、色々見逃してたところを修正
- ネストした型の widening にも対応した
-
when節、else節に複文が書けなかったのを対応
リテラル型を実装した。そのうち依存型的なこともやりたい。
無事 (?) リテラル型も実装できたので、Union Type を実装していきたい。Union Type は匿名の型なので、無名構造体と同じく構造でマッチする。参照したい場合は type 宣言でエイリアスをつける。
type U = int64 | { flag: boolean }
素直に考えると Tagged union で実現できそうだ。こういう型は
type U = int64 | { flag: boolean }
こういう感じで実装できそう。
struct T {
flag: bool;
};
struct U {
int type;
union {
int64_t _0,
T _1;
} _u;
};
Union Type の値は含む型の値であれば比較可能であり、narrowing できる
def foo(u: U)
case u
when 1
# u の型は `1`
else
...
end
end
foo(1)
比較可能でない場合はエラー
case u
when "string"
# unreachable pattern
else
...
end
また、変数パターンに型注釈をつけられるようにして、Union Type で使うことができる。
case u
when _: int64
# u の型は `int64`
...
when _: { flag: boolean }
# u の型は `{ flag: boolean }`
...
when _
# unreachable pattern
end
C 言語の話に戻すと...
narrowing の場合は構造体フィールドにアクセスするだけで済むが、
// narrowing...
// u の型は `int64`
u._u._0
windening の場合は型変換が必要
// int64 を U に変換する
(struct U){ .type = 0, .u = {._0 = ...}};
Union Type のメンバーがすべて同じ基本型のリテラル型の場合、Tagged Union は不要
# この方の C 言語での表現は int64_t
type K = 1 | 2 | 3;
まずは、型注釈つきパターンと type 宣言から実装するのが良さそうだが、型注釈つきパターンは usefulness check をどう実装するかが悩ましい。
型注釈つきパターンは usefulness check をどう実装するかが悩ましい。
まずは構文、型チェックのみで実装し、usefulness check では通常の変数パターンと同様に扱う。Union Type が存在しないので意味的には変わらない。
usefulness check は Rust コンパイラの実装を基にしているので、Union Type は Rust の enum として扱うのが楽そう。
type U = int64 | { flag: boolean }
は、Rust で以下のような enum として扱うことで usefulness check できるはず。
enum {
VariantA(i64),
VariantB { flag: bool },
}
つまり、パターンマッチの対象が Union type の場合、各パターンを enum パターンに変換してやる必要がある。型注釈つきパターンも同様。
型注釈つきパターンは、そのまま関数の引数として使えることに気づいて、そのように実装している。
型注釈つきパターンは usefulness check をどう実装するかが悩ましい。
まずは構文、型チェックのみで実装し、usefulness check では通常の変数パターンと同様に扱う。Union Type が存在しないので意味的には変わらない。
実装した。unify_xxx(...) を Generics と Trait で汎用的な実装に変えたところ、引数の参照が自動的に外れなくなった。Rust を雰囲気で使っているので、この辺の挙動がよく分からない。
次は、Type Script の Type alias と同様のものを実装する。
Type alias を実装しているが、型の解決が面倒くさくなってきた。
構文解析の時点では、文脈(コンテキスト)に依存した型の解決をしていない。例えば、ソースコード上で以下のような構造体の定義があったとして、
struct T { ... }
そのあと、関数の引数で T 型が使われていたとしても、構文解析の時点では、この T が何の型かは分からない。
def foo(t: T)
なので、構文解析の時点では T は「"T" という名前で参照できる型」という型になっている。
これを意味解析のフェーズで、スコープに応じた型解決をやっていくわけだが、明示的な型指定ができる箇所が
- 構造体定義のフィールド
- 関数引数
- 型注釈つきパターン
- Type alias
と増えてきた。
- コードを走査するパスが一度増えるため、パフォーマンス的に不利
- コードを走査するとき、愚直にパターンマッチで再帰的に処理しているため、コード量も増える
- ただ、この愚直な実装は理解しやすいし、パターンマッチの網羅性チェックも効くので、まだしばらくはこのままにしておきたい。
型解決を遅延させてオンデマンドに実行するのがいいかもしれない。 これはこれで、型解決の実行回数が増えてしまう。-> 結局、愚直に実装した。
週末で、Union type が少しだけ動くようになった。こういうプログラムが、
type ID = string | int64
def printID(id: ID)
puts(id)
end
printID(1234567)
printID("abcdefg")
次のような C コードに変換される。
struct _U2si64
{
int64_t tag;
union
{
const char *_0;
int64_t _1;
} u;
};
int64_t _Z7printID1U2si64(struct _U2si64 id);
int64_t _Z7printID1U2si64(struct _U2si64 id)
{
if (id.tag == INT64_C(0))
{
printf("%s", id.u._0);
}
else if (id.tag == INT64_C(1))
{
printf("%" PRId64 "", id.u._1);
}
return printf("\n");
}
int main()
{
_Z7printID1U2si64((struct _U2si64){.tag = 1, .u = {._1 = INT64_C(1234567)}});
_Z7printID1U2si64((struct _U2si64){.tag = 0, .u = {._0 = u8"abcdefg"}});
return 0;
}
Union type への暗黙の型変換 (type promotion) が、まだ一部のケースしか実装していないのでエッジケースも考えつつ実装していく必要があるし、usefulness check も手付かず。
Union 型の暗黙の型変換 (Type promotion) を実装している。
type Field = (string, int64 | boolean)
def print_field(t: Field)
puts(t.0, "=", t.1)
end
print_field(("a", 102030))
というときに、print_field() を呼び出すときの引数に (string, int64) 型の値を渡しているが、これは仮引数 (string, int64 | boolean) と C 言語レベルでは互換性がない(別の構造体)なので、暗黙の型変換が必要になる。
struct _T2si64 _t2 = (struct _T2si64){._0 = u8"a", ._1 = INT64_C(102030)};
_Z11print_field1T2sU2i64b((struct _T2sU2i64b){._0 = _t2._0, ._1 = (struct _U2i64b){.tag = 0, .u = {._0 = _t2._1}}});
ここまでは実装したのだが、このパターンだと、不要な一時変数が残ってしまう。もう少し単純化した例で示すと、
def foo(t: (int64, int64, int64))
puts(t)
end
foo((1, 2, 3))
こういうコードが、C 言語では以下のようになる。
struct _T3i64i64i64 _t3 = (struct _T3i64i64i64){._0 = INT64_C(1), ._1 = INT64_C(2), ._2 = INT64_C(3)};
_Z3foo1T3i64i64i64((struct _T3i64i64i64){._0 = _t3._0, ._1 = _t3._1, ._2 = _t3._2});
ここで、_t3 を消して、_t3._0 などは即値にしてしまいたい。
今のアルゴリズムは、IR 生成時に一時変数が参照されるたびに参照カウントをインクリメントしていき、最終的に参照カウントが
-
0の場合は削除 -
1の場合は参照元を置き換えて削除
という単純なもの。
上記コードの IR は(最適化なしだと)
foo(t: (int64, int64, int64)):
t0 (used: 3) = t
t1 (used: 0) = @printf("(")
t2 (used: 1) = t0.0
t3 (used: 0) = @printf(t2)
t4 (used: 0) = @printf(", ")
t5 (used: 1) = t0.1
t6 (used: 0) = @printf(t5)
t7 (used: 0) = @printf(", ")
t8 (used: 1) = t0.2
t9 (used: 0) = @printf(t8)
t10 (used: 0) = @printf(")")
t11 (used: 1) = @printf("\n")
return t11
main():
t0 (used: 1) = 1
t1 (used: 1) = 2
t2 (used: 1) = 3
t3 (used: 3) = (t0, t1, t2)
t4 (used: 1) = (t3.0, t3.1, t3.2)
t5 (used: 0) = foo(t4)
return 0
見ての通り、t3 の参照カウントは 3 になっている(次のステートメントから参照されている)。これを無くすのが目標。
最適化パスを抜本的に書き直して、以下のコードが
type Field = (string, int64 | boolean)
def print_field(t: Field)
puts(t.0, "=", t.1)
end
print_field(("a", 102030))
中間コードで main 部分が以下のようになって、
main():
t0 (used: 0) = "a"
t1 (used: 0) = 102030
t2 (used: 0) = (t0, t1)
t3 (used: 0) = (union)t2.1
t4 (used: 0) = (t2.0, t3)
t5 (used: 0) = print_field(t4)
return 0
最適化を通すと、こうなって、
main():
t5 (used: 0) = print_field(("a", (union)102030))
return 0
求めていた C コードになった。
int main()
{
_Z11print_field1T2sU2i64b((struct _T2sU2i64b){._0 = u8"a", ._1 = (struct _U2i64b){.tag = 0, .u = {._0 = INT64_C(102030)}}});
return 0;
}
ただし、定数(っぽいもの)伝播と未到達コードの削除を何度も繰り返すのでパフォーマンスはだいぶ悪くなったはず。
Union 型の実装を進めているのだが、素直に実装すると型定義とチェックがひどいことになる。例えば、こういうコードは
type S = string | boolean
type V1 = { value: int64 }
type V2 = { value: string }
type V3 = { value: S }
type T =
(int64, V1) |
(int64, V1, int64) |
(int64, V2) |
(int64, V3, int64)
def print_2nd(t: T)
puts(t.1.value)
end
print_2nd((10, V1 { value: 20 }))
print_2nd((10, V1 { value: 30 }, 40))
print_2nd((10, V2 { value: "40" }))
print_2nd((10, V3 { value: "50" }, 50))
print_2nd((10, V3 { value: true }, 50))
無名型のための定義が延々と続き...
struct _U2sb
{
int64_t tag;
union
{
const char *_0;
bool _1;
} u;
};
struct _S1n5value
{
int64_t value;
};
struct _S1s5value
{
const char *value;
};
// ...
puts(t.1.value) しているだけの関数 print_2nd() が以下のようになる。
int64_t _Z9print_2nd1U4T2nS1n5valueT3nS1n5valuenT2nS1s5valueT3nS1U2sb5valuen(struct _U4T2nS1n5valueT3nS1n5valuenT2nS1s5valueT3nS1U2sb5valuen t)
{
struct _S1n5value _t1 = (struct _S1n5value){.value = t.u._0._1.value};
struct _S1n5value _t3 = (struct _S1n5value){.value = t.u._1._1.value};
struct _S1s5value _t5 = (struct _S1s5value){.value = t.u._2._1.value};
struct _S1U2sb5value _t7 = (struct _S1U2sb5value){.value = ((t.u._3._1.value.tag == INT64_C(0)) ? (struct _U2sb){.tag = 0, .u = {._0 = t.u._3._1.value.u._0}} : (struct _U2sb){.tag = 1, .u = {._1 = t.u._3._1.value.u._1}})};
if (((((t.tag == INT64_C(0)) ? (struct _U3S1n5valueS1s5valueS1U2sb5value){.tag = 0, .u = {._0 = _t1}} : ((t.tag == INT64_C(1)) ? (struct _U3S1n5valueS1s5valueS1U2sb5value){.tag = 0, .u = {._0 = _t3}} : ((t.tag == INT64_C(2)) ? (struct _U3S1n5valueS1s5valueS1U2sb5value){.tag = 1, .u = {._1 = _t5}} : (struct _U3S1n5valueS1s5valueS1U2sb5value){.tag = 2, .u = {._2 = _t7}}))).tag == INT64_C(0)) ? (struct _U3nsU2sb){.tag = 0, .u = {._0 = ((t.tag == INT64_C(0)) ? (struct _U3S1n5valueS1s5valueS1U2sb5value){.tag = 0, .u = {._0 = (struct _S1n5value){.value = t.u._0._1.value}}} : ((t.tag == INT64_C(1)) ? (struct _U3S1n5valueS1s5valueS1U2sb5value){.tag = 0,
// あまりに長いので省略...
}
int64_t _t18 = printf("\n");
return _t18;
}
最適化でなんとかしたい...。 普通にバグってるっぽいな。
Union 型の実装を進めているのだが、素直に実装すると型定義とチェックがひどいことになる。
いくつか問題があったので修正
- Union/Struct/Tuple で、同じ型への型変換が適用されていた
- 最適化で一時変数を置き換えるときの判定が間違っていた
- 一時変数を割り当てるべきところで割り当てていなかった
上記を修正することで、このコードは
type S = string | boolean
type V1 = { value: int64 }
type V2 = { value: string }
type V3 = { value: S }
type T =
(int64, V1) |
(int64, V1, int64) |
(int64, V2) |
(int64, V3, int64)
def print_2nd(t: T)
puts(t.1.value)
end
こんな感じになる。
int64_t _Z9print_2nd1U4T2nS1n5valueT3nS1n5valuenT2nS1s5valueT3nS1U2sb5valuen(struct _U4T2nS1n5valueT3nS1n5valuenT2nS1s5valueT3nS1U2sb5valuen t)
{
struct _U3S1n5valueS1s5valueS1U2sb5value _t6 = ((t.tag == INT64_C(0)) ? (struct _U3S1n5valueS1s5valueS1U2sb5value){.tag = 0, .u = {._0 = t.u._0._1}} : ((t.tag == INT64_C(1)) ? (struct _U3S1n5valueS1s5valueS1U2sb5value){.tag = 0, .u = {._0 = t.u._1._1}} : ((t.tag == INT64_C(2)) ? (struct _U3S1n5valueS1s5valueS1U2sb5value){.tag = 1, .u = {._1 = t.u._2._1}} : (struct _U3S1n5valueS1s5valueS1U2sb5value){.tag = 2, .u = {._2 = t.u._3._1}})));
struct _U3nsU2sb _t15 = ((_t6.tag == INT64_C(0)) ? (struct _U3nsU2sb){.tag = 0, .u = {._0 = _t6.u._0.value}} : ((_t6.tag == INT64_C(1)) ? (struct _U3nsU2sb){.tag = 1, .u = {._1 = _t6.u._1.value}} : ((_t6.u._2.value.tag == INT64_C(0)) ? (struct _U3nsU2sb){.tag = 1, .u = {._1 = _t6.u._2.value.u._0}} : (struct _U3nsU2sb){.tag = 2, .u = {._2 = (struct _U2sb){.tag = 1, .u = {._1 = _t6.u._2.value.u._1}}}})));
if (_t15.tag == INT64_C(0))
{
printf("%" PRId64 "", _t15.u._0);
}
else if (_t15.tag == INT64_C(1))
{
printf("%s", _t15.u._1);
}
else if (_t15.tag == INT64_C(2))
{
if (_t15.u._2.tag == INT64_C(0))
{
printf("%s", _t15.u._2.u._0);
}
else if (_t15.u._2.tag == INT64_C(1))
{
printf("%s", (_t15.u._2.u._1 ? "true" : "false"));
}
}
int64_t _t29 = printf("\n");
return _t29;
}
意味解析周りでずっと気になっていたところも直した。
関数呼び出し時に、呼び出す関数を決定しても返り値の型が不明なケースがある。
- 関数定義内でその関数自身を再帰呼び出ししている場合
- まだ定義前の関数を呼び出している場合
今までは、関数呼び出しノードに呼び出す関数ノードへの参照を持たせておき、IR 生成時に必要な場合は関数ノードを見るようにしていた。これだと、関数呼び出しノードは型が未決定のケースがありうることになり、対応が面倒なので、
- 関数呼び出しノードに呼び出す関数のシグネチャ(関数名 + 引数の型)を保存
- 意味解析の最後で関数呼び出しノードのシグネチャから関数ノードを探索して、(その時点では決定している)返り値の型を関数呼び出しノードの型として設定
することで、意味解析通過後はすべての型が確定するようにした。
これによって、意味解析通過後は
- すべての型が確定している
- バックエンドのコードを正しく生成できる
ことが保証されており、(コンパイラのデバッグ目的以外では)構文木の情報は不要になる(panic 時のスタックトレース情報は必要?)
今は、
ソースコード -> 構文木 -> (意味解析) -> IR -> (最適化) -> C コード
として変換しているが、これを以下のように変更した方が見通しが良くなりそう。
ソースコード -> 完全構文木 -> (意味解析) -> 抽象構文木 -> IR -> (最適化) -> C コード
- 完全構文木 (Concrete Syntax Tree)
- ソースコードの見た目そのままを保持
-
(expr)の括弧やコメント、空白- 今は
(expr)をexprにしているのと空白は無視
- 今は
-
- リテラル以外の型は未決定
- ソースコードの見た目そのままを保持
- 抽象構文技 (Abstract Syntax Tree)
- コメントや空白は削除
- 構造を変えてもいい
- 型も決定している
- 意味的に同じ、より効率的な型に変換もできる
面倒なので、すぐはやらないけど...
低確率で失敗するテストがあり、エラーに情報追加した。さすがにそろそろ行番号くらいは追加したいが、Parser の実装は面白くないのでモチベーションが...。
C 言語では、64bit 整数の最小値を整数リテラルで書けない。整数のパターンマッチで境界条件をテストしていて気づいた。
マイナスは単項演算子だから...と言うのはなるほど。INT64_MIN マクロが使える。
低確率で失敗するテストがあり、エラーに情報追加した。
型エイリアスで型が未解決の場合の同値判定が間違っているのが原因だった。
TypeScript で以下のコードは、
- T を U に代入することはできるが、
- U を T に代入することはできない
この辺が(直接的ではなさそうだが)関係している?
type T = [number, number] | [string, number];
type U = [number | string, number];
const t1: T = [1, 2];
const t2: U = [1, 2];
const t3: U = t1;
const t4: T = t3; // error
// Type 'U' is not assignable to type 'T'.
// Type '[string | number, number]' is not assignable to type '[number, number]'.
// Type at position 0 in source is not compatible with type at position 0 in target.
// Type 'string | number' is not assignable to type 'number'.
// Type 'string' is not assignable to type 'number'.(2322)
単純に Union 型の比較をやっていくとこの結果になるし、実際、
- Union 型に、含まれるメンバー型を代入できる
- 含まれるメンバー型に Union 型は代入できない
とも整合しているので、これでいい気がしてきた。
型にリテラル型とユニオン型が加わったことで、パターンを型でより正確に表現できるようになった。あとは、
- 範囲パターン
- Rest パターン
のふたつを型で表現できれば、パターンと型を対応づけられる(して嬉しいかどうかは不明)。このうち「範囲パターン」は「順序が定義されているリテラル型から新しい型を作り出す演算子」と考えられる(Or-パターンに対するユニオン型)気がする。
目視デバッグがつらくなってきたので、clang-format と bat を入れてみた(このコードはバグっている)。
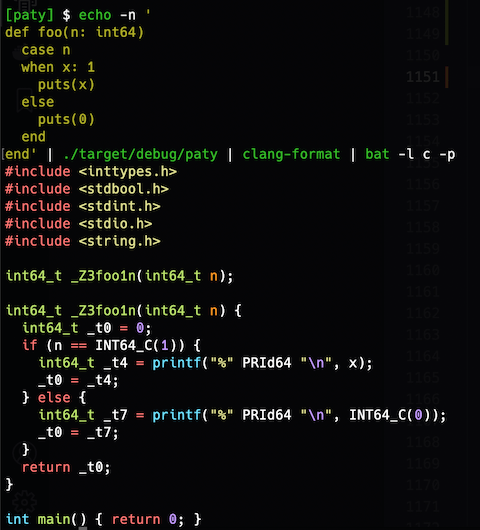
以下のコードが見た目とは異なる解釈をされることに気づかず時間を溶かした。やはり、曖昧な文法はつらい。せめて \n を強制したい。
case value
when _: T { name: "me" }
puts(0)
end
-
fslang-design/FS-1092-anonymous-type-tagged-unions.md at main · fsharp/fslang-design
- F# への匿名ユニオン型提案
- discriminated union と disjoint union
-
Union Types - More Details | Scala 3 Language Reference | Scala Documentation
- Scala のユニオン型
-
SIP-23 - Literal-based singleton types | Scala Documentation
- Scala のリテラル型
ずっとやっていたユニオン型をやっとマージした...。
もともと、このプロジェクトの目的は nico という自作言語で、パターンマッチの網羅性チェックの実装方法が論文を読んでも分からず、Rust の実装を真似て実装してみることだった。その過程で Union 型を実装したりなんだかんだで 4 ヶ月も経ってしまったが、網羅性チェック自体は動くようになったので、そろそろふたつのプロジェクトを統合したい。
コードベースとしては、このプロジェクトのものをベースにしたいので、nico にあってこのプロジェクトに不足しているものを実装して、ある程度動くようになったら統合していくことにする。
- WebAssembly
- LSP
Node.js の WASI に載っている Hello, World プログラムを実行すると、node.js, wasmtime では動くけど、wasm3 ではエラーになる。
$ wat2wasm ./_work/hello.wat
$ wasm-objdump -s ./hello.wasm
hello.wasm: file format wasm 0x1
Contents of section Type:
000000a: 0260 047f 7f7f 7f01 7f60 0000 .`.......`..
Contents of section Import:
0000018: 0116 7761 7369 5f73 6e61 7073 686f 745f ..wasi_snapshot_
0000028: 7072 6576 6965 7731 0866 645f 7772 6974 preview1.fd_writ
0000038: 6500 00 e..
Contents of section Function:
000003d: 0101 ..
Contents of section Memory:
0000041: 0100 01 ...
Contents of section Export:
0000046: 0206 6d65 6d6f 7279 0200 065f 7374 6172 ..memory..._star
0000056: 7400 01 t..
Contents of section Code:
000005b: 011b 0041 0041 0836 0200 4104 410c 3602 ...A.A.6..A.A.6.
000006b: 0041 0141 0041 0141 1410 001a 0b .A.A.A.A.....
Contents of section Data:
000007a: 0100 4108 0b0c 6865 6c6c 6f20 776f 726c ..A...hello worl
000008a: 640a d.
$ node --experimental-wasi-unstable-preview1 ./_work/wasi.mjs ./hello.wasm
(node:43923) ExperimentalWarning: WASI is an experimental feature. This feature could change at any time
(Use `node --trace-warnings ...` to show where the warning was created)
hello world
$ wasmtime run ./hello.wasm
hello world
$ wasm3 ./hello.wasm
Error: [trap] out of bounds memory access
WebAssembly 関連
- WebAssembly Spec
- WASI
-
WASI Document Guide
- NuxiNL/cloudlibc: CloudABI's standard C library - WASI の capability-based security model に影響を与えている
- Spec - snapshot preview1
-
WASI Document Guide
- WebAssembly向けのデバッガを開発しました - kateinoigakukunのブログ
WAT を作るための構造体とかを地道に書いて、とりあえず Hello, World! できるところまでは来た。
$ echo -n 'puts("Hello, World!\n")' | ./_work/run_wasm.sh
--- (optimized IR)
main():
t2 (used: 0) = @printf("Hello, World!\n", "\n")
return 0
───────┬──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
│ File: ./_tmp/tmp2.wat
│ Size: 690 B
───────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
1 │ (module $demo.wat
2 │ (import "wasi_snapshot_preview1" "fd_write" (func $fd_write (param i32 i32 i32 i32) (result i32)))
3 │ (export "memory" (memory 0))
4 │ (export "_start" (func $_Z4main0))
5 │ (memory (;0;) 1)
6 │ (data (;0;) (i32.const 0) "\08\00\00\00\0e\00\00\00Hello, World!\0a")
7 │ (data (;1;) (i32.const 22) "\1e\00\00\00\01\00\00\00\0a")
8 │ (func $_Z4main0
9 │ (drop
10 │ (call $fd_write
11 │ (i32.const 1)
12 │ (i32.const 0)
13 │ (i32.const 1)
14 │ (i32.const 1024)))
15 │ (drop
16 │ (call $fd_write
17 │ (i32.const 1)
18 │ (i32.const 22)
19 │ (i32.const 1)
20 │ (i32.const 1024))))
21 │ (type (;0;) (func (param i32 i32 i32 i32) (result i32)))
22 │ (type (;1;) (func)))
───────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
tmp1.wasm: file format wasm 0x1
wasmtime で実行。
$ wasmtime run ./_tmp/tmp1.wasm
Hello, World!
ただ、wasmtime だと、fd_write に渡した引数が一度に書き込まれるわけではないみたいだ (Node.js だといける) 。nwritten をチェックして、何度も呼ばないといけない?
- alignment の問題だった。
fd_writereturns the amount of bytes written. You have to call it in a loop until all bytes are written. This matches the posixwritesyscall. From the man page of thewritesyscall:The number of bytes written may be less than count if, for example, there is insufficient space on the underlying physical medium, or the RLIMIT_FSIZE resource limit is encountered (see setrlimit(2)), or the call was interrupted by a signal handler after having written less than count bytes. (See also pipe(7).)
Higher level api's generally do this loop for you.