単体テストの考え方/使い方
第1部 単体テストとは
単体テストの現状を知ることが目標
第1章 なぜ単体テストを行うのか
単体テストをすることでソフトウェア開発プロジェクトの成長を「持続可能」なものにすることを成し遂げたい。
開発スピードが急に遅くなる事象はソフトウェア・エントロピー(無秩序の量)の増加によって起こる。
テストを用意しておくことで、コードに変更を加えたとしても、コードの変更によって生じる多くの退行(リグレッション)を検出するセーフティネットが備わっている。
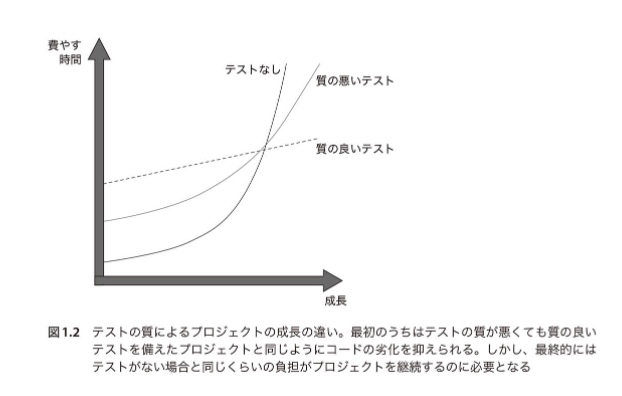
すべてのテストケースは平等に作られているわけではない。ソフトウェア全体の品質を向上させる価値あるテストケースもあればそうでないものもある。
単にテストケースを増やしただけでは単体テストの目標を実現できない。
単体テストの目標を実現するには、作成する単体テストの価値とその維持にかかるコストの両方を考慮する必要がある。
網羅率をもってテストスイートの質を評価することはできない。
コード網羅率は高くなってもテストスイートの価値があがったり、コードベースの保守がしやすくなったりするわけではない。
分岐網羅率はコード網羅率よりも正確な網羅率の計測ができる。
網羅率の問題:以下の理由によりテストスイートの質を評価できない。
- 網羅率からは実際にプロダクションコードが検証されたかを保証できない。
- プロダクションコードによって生み出される全ての結果(結果が1つとは限らない)が想定結果と一致することを検証しなければいけない。
- 確認不在のテストは価値が全くない。
- 網羅率の算出時、使用するライブラリ内のコードは計測対象外になる。
網羅率を最大限に活用するには、テストが十分に行われていないことを示すものとして見る必要がある。(網羅率の数値を目標にしてしまうと確認すべきテストに意識が向かず、目標数値に到達するために行動するなど、単体テストの目標から遠ざかる可能性がある)
テストスイートの評価に関して最も信頼できる方法は各テストケースを1つずつ評価することしかない。(自動的に評価する方法はない)
優れたテストスイートの特徴は以下の3つ
- テストすることが開発サイクルに組み込まれている。
- 理想的なのは変更が加わるたび(些細な変更であっても)テストが実施されるようにする。
- CIのパイプラインでテストされてるがそれで十分か?☆
- コードベースの特に重要な部分のみテスト対象となっている。
- ドメインモデルに対するテストが費用対効果が最も高い。(ビジネスロジックが含まれている)
- ドメインモデルを他の関心事から隔離しておく必要がある(クリーンアーキテクチャ)
- 最小限のコストで最大限の価値を生み出せるようになっている。
- テストスイートの質を十分に高めるにはテストをビルドシステムに組み込んだり、ドメインモデルに対するテストカバレッジを高く維持するだけでは不十分。
- テストスイートに含めるテストケースを保守コストより高い価値をもたらすものだけにすることが重要で、それを実現するためには以下の能力が必要になる。
- 価値のあるテストケースを認識できること。(価値の低いテストケースを認識できること)
- 認識できるようになるには、テストケースの価値を評価するための基準となる枠組みを知っている必要がある。☆本書で学ぶ
- 価値のあるテストケースを作成できること。
- 上述の能力に加えて設計のテクニックも理解しておく必要がある。
- 価値のあるテストケースを認識できること。(価値の低いテストケースを認識できること)
第2章 単体テストとは何か
- 古典学派(デトロイト学派)
- ロンドン学派
モックの利用とテストの壊れやすさとの関係を見るときに重要な要素となる2つの学派
単体テストの定義
以下の3つの性質を全て備わっているものが単体テストとなる。
- 単体(Unit)と呼ばれる少量のコードを検証する(「 少量のコード」が意味するところは学派によって異なる)
- ロンドン学派では「隔離」の解釈上、単一のクラスを意味する。
- 古典学派では必ずしも1つのクラスに限定されず共有依存が含まれない限り複数のクラスを単体テストで検証しても良い。
- 実行時間が短い
- 隔離された状態で実行される(学派によって「隔離」の解釈が異なる)
- ロンドン学派: テスト対象クラスが他のクラスに依存している場合はすべてテストダブルに置き換えなければいけない。
- ただし依存が不変であればテストダブルに置き換えない場合もある。
- 古典学派: テストケースを互いに影響を与えず個別に実行可能でなければならない。
- テストケースの順序に依存性なく効果的な実行方法を選択可能になる。
- データベースやファイルシステムなどがテストケース間で状態が共有されてしまうことをプロセス外依存と呼ぶ。
- 注意:プロセス外依存 ≠ 共有依存
https://zenn.dev/link/comments/d9bb137b76ab8f
- 注意:プロセス外依存 ≠ 共有依存
- 古典学派でもテストダブルを使用することはあるが、プロセス外依存に対してのみ使用する考え方。
- ロンドン学派: テスト対象クラスが他のクラスに依存している場合はすべてテストダブルに置き換えなければいけない。

テストダブルの利点
- 問題が起こった箇所の明確化。
- ロンドン学派ではテスト対象クラス以外はテストダブルに置換されているため
- オブジェクトグラフを分離できること。
- オブジェクトグラフ: 同じ問題を解決するために結びついたオブジェクトの集まりのこと。
古典学派による単体テストの例
import static org.junit.jupiter.api.Assertions.*;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
class StoreTest {
private Store store;
private Customer customer;
@BeforeEach
void setUp() {
store = new Store();
customer = new Customer();
}
// 在庫が十分にある場合、購入は成功する
@Test
void purchaseSucceedsWhenEnoughInventory() {
// 準備 (Arrange)
store.addInventory(Product.SHAMPOO, 10);
// 実行 (Act)
boolean success = customer.purchase(store, Product.SHAMPOO, 5);
// 確認 (Assert)
assertTrue(success);
assertEquals(5, store.getInventory(Product.SHAMPOO)); // 店にある商品数が「5」に減っていること
}
// 在庫が足りない場合、購入は失敗する
@Test
void purchaseFailsWhenNotEnoughInventory() {
// 準備 (Arrange)
store.addInventory(Product.SHAMPOO, 10);
// 実行 (Act)
boolean success = customer.purchase(store, Product.SHAMPOO, 15);
// 確認 (Assert)
assertFalse(success);
assertEquals(10, store.getInventory(Product.SHAMPOO)); // 店の商品数が変わっていないこと
}
}
// 商品の種類
enum Product {
SHAMPOO,
BOOK
}
// シンプルな Store クラス(在庫管理)
class Store {
private final java.util.Map<Product, Integer> inventory = new java.util.HashMap<>();
public void addInventory(Product product, int quantity) {
inventory.put(product, inventory.getOrDefault(product, 0) + quantity);
}
public int getInventory(Product product) {
return inventory.getOrDefault(product, 0);
}
public boolean purchase(Product product, int quantity) {
int stock = getInventory(product);
if (stock >= quantity) {
inventory.put(product, stock - quantity);
return true;
}
return false;
}
}
// シンプルな Customer クラス
class Customer {
public boolean purchase(Store store, Product product, int quantity) {
return store.purchase(product, quantity);
}
}
上述の例では、準備フェーズにて、テスト対象システムと協力者オブジェクト(Store)の2つのオブジェクトを用意することになる。
協力者オブジェクトをテストダブルに置き換えないので一緒に検証することになる。
テスト対象システムは正常に動作していても協力者オブジェクトでバグがある場合、単体テストが失敗する。
つまりこの2つのオブジェクトは「隔離」されていない。
ロンドン学派による単体テストに置き換え
import static org.junit.jupiter.api.Assertions.*;
import static org.mockito.Mockito.*;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.mockito.Mockito;
class StoreTest {
private IStore storeMock;
private Customer customer;
@BeforeEach
void setUp() {
storeMock = mock(IStore.class);
customer = new Customer();
}
// 在庫が十分にある場合、購入は成功する
@Test
void purchaseSucceedsWhenEnoughInventory() {
// 準備 (Arrange)
when(storeMock.hasEnoughInventory(Product.SHAMPOO, 5)).thenReturn(true);
// 実行 (Act)
boolean success = customer.purchase(storeMock, Product.SHAMPOO, 5);
// 確認 (Assert)
assertTrue(success);
verify(storeMock, times(1)).removeInventory(Product.SHAMPOO, 5); // removeInventoryが一度呼ばれる
}
// 在庫が足りない場合、購入は失敗する
@Test
void purchaseFailsWhenNotEnoughInventory() {
// 準備 (Arrange)
when(storeMock.hasEnoughInventory(Product.SHAMPOO, 5)).thenReturn(false);
// 実行 (Act)
boolean success = customer.purchase(storeMock, Product.SHAMPOO, 5);
// 確認 (Assert)
assertFalse(success);
verify(storeMock, never()).removeInventory(Product.SHAMPOO, 5); // removeInventoryは呼ばれない
}
}
// 商品の種類
enum Product {
SHAMPOO,
BOOK
}
// Store インターフェース(モック対象)
interface IStore {
boolean hasEnoughInventory(Product product, int quantity);
void removeInventory(Product product, int quantity);
}
// Customer クラス(テスト対象)
class Customer {
public boolean purchase(IStore store, Product product, int quantity) {
if (store.hasEnoughInventory(product, quantity)) {
store.removeInventory(product, quantity);
return true;
}
return false;
}
}
-
Product.SHAMPOOをモックに置き換えずにそのままオブジェクトを利用している。- Product.SHAMPOOは列挙型(enum)で不変(値オブジェクト)のため置き換えずにOK
値オブジェクトについて(Value Object)
ロンドン学派では協力者オブジェクトが具象クラスの代わりにインターフェースが導入されそのインターフェースに対してモックを作成している。
☆テスト対象システムから協力者オブジェクトを隔離するにはインターフェースが必要であることが重要
具象クラスをモック化するのはアンチパターンである。

- 依存は共有依存もしくはプライベート依存のどちらかになる
- プライベート依存は可変依存か不変依存(値オブジェクト)のどちらかになる

実際のプロジェクトにおいて、
- 「共有依存だがプロセス外依存でないもの」を扱うことは滅多にない。
- 「共有されないプロセス外依存のもの」を扱うことは滅多にない。
- ほとんどのプロセス外依存は可変
そのため本書では「共有依存」と「プロセス外依存」は交換可能なものとして扱っている。
作者は古典学派のスタイルを好んでいる。理由としては、単体テストの目標である「プロジェクトの持続的な成長を促す」ことの達成に向いているため。またロンドン学派の単体テストは壊れやすくなるため。
ロンドン学派の単体テストの長所
- より細やかな粒度で検証ができる
- 1つのテストケースで1つのクラスしか検証しないため
- 依存関係が複雑になっても簡単にテスト可能
- 全ての協力者オブジェクトをテストダブルに置き換えるためそれらの依存のことを深く考えずに済む
- テスト失敗時にどの機能に問題があったかを正確に見つけられる
- 全ての協力者オブジェクトをテストダブルに置き換えるためテスト対象システムだけを見れば良くなる
上述のロンドン学派の長所に対して、作者はそれぞれ以下のように評価している。
より細やかな粒度で検証ができる
- コードの粒度を細かくしようとすることは単体テストにおいて有用ではない。
- 単体テストでは「1単位のコード」を検証するのではなく「1単位の振る舞い」を検証するものである。「1単位の振る舞い」を実現するためには複数のクラスにまたがることもある。(必ずしも1つのクラスに収まるとは限らない)
- 「1単位の振る舞い」が検証されていれば良い単体テストだが、コードの粒度を細かくした結果「1単位の振る舞い」が検証されていなければ、質の悪い単体テストになる。
- ☆ 単体テストにおいて各テストケースがすべきことはそのテストに関わる人たちにテスト対象のコードが解決しようとしている物語を伝えること であり、その物語を伝えるためには凝集度を高め、非開発者でも理解できるようにする ことが必要
依存関係が複雑になっても簡単にテスト可能
- 本来考えるべきことは複雑な依存関係を構築しなくても済むようにするための方法である。(複雑な依存関係を持つクラスを検証するための方法を見出すことではない)
- ☆ 複雑な依存関係になってしまったのは間違った設定が行われたことが原因である。
- 準備フェーズがあまりにも大きくなるようであれば何らかの設計の問題がある可能性が高い。
テスト失敗時にどの機能に問題があったかを正確に見つけられる
- 古典学派の単体テストコードでも、頻繁に実施していれば、最後に修正をした箇所にテストを失敗させた原因があることが明白なため。
- 依存先コードの不具合が原因で失敗がテストスイートのいたるところに広がったとしても得られるメリットもある。1つの問題が1つのテストケースだけでなく多くのテストケースに影響を与えるのであればその問題のあったコードは多くのクラスに依存された重要な価値があることの証明になる。このことは設計や変更でコードを扱う際に把握していると有用な情報になる。
古典学派とロンドン学派の違い(その他)
- TDD(テスト駆動開発)を用いたシステム設計
- ロンドン学派:単体テストのスタイルは外側から内側に向かうTDD
- システム全体がどのように機能するかを考えた広い視野でのテストケースを作成することから始める開発
- 古典学派:内側から外側に向かうTDD
- ドメインモデルから実装とテストを始め、その外側の層の実装とテストの追加を繰り返していくスタイル
- ロンドン学派:単体テストのスタイルは外側から内側に向かうTDD
- テストコードが把握することになるプロダクションコードの詳細
- 単体テストはプロダクションコードのことをどれくらい把握する必要があるか(言い換えると単体テストはテスト対象の内部的なコードとどれくらい結びつくかということ)
-
一般的にロンドン学派のほうが実装の詳細に深く結びつく傾向がある。
- 作者がロンドン学派に賛同できない最大の理由
古典学派とロンドン学派における統合テストの違い
- ロンドン学派:協力者オブジェクトを使うテストのこと
- 古典学派:単体テストの再定義(以下参照)の性質を1つでも損なっているテストのこと
以下の3つの性質を全て備わっているものが単体テストとなる。
- 単体(Unit)と呼ばれる少量のコードを検証する
- 実行時間が短い
- 隔離された状態で実行される
これを古典学派の観点で再定義すると以下のようになる。
- 1単位の振る舞いを検証すること
- 実行時間が短いこと
- 他のテストケースから隔離された状態で実行されること
統合テストとE2Eテストの違い

第3章 単体テストの構造的解析
単体テストの構造
AAAパターンを利用することでテストスイートに含まれたすべてのテストケースに対して簡潔で統一された構造を持たせられるようになる。それは可読性につながり、メンテナンスコストの低下にもつながる。
- Arange(準備)
- Act(実行)
- Assert(確認)
単体テストにおいて回避すべきことは同じフェーズを複数回用意すること。
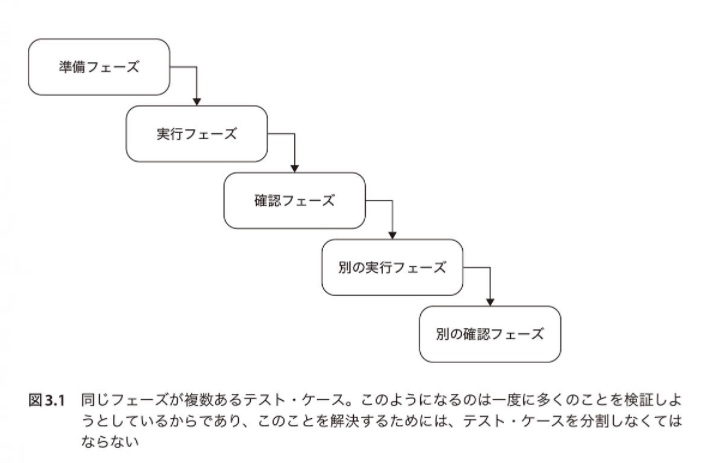
上記のような状態になるということは、1つのテストケースで複数の振る舞いをテストしていることになる。そして、それは「統合テスト」に該当するものである。
テストケースを分割して1つの実行フェーズと1つの確認フェーズを持つテストケースを複数作成する。
単体テストにおいて回避すべきことはif文を使用すること。
テストケースに含まれるif文も1つのテストケースで多くのことを検証していることの示唆である。
AAAパターンの各フェーズのサイズはどれくらいが適切か。
-
準備フェーズが最も大きくなる
- あまりに大きくなる場合は一部を同テストクラスのプライベートメソッドに切り出したり、その部分を作成する別のファクトリクラスを作るのが良い。
- 「オブジェクトマザー」パターンと「テストデータビルダー」パターンが有用。
-
実行フェーズが1行を超す場合は注意が必要
- 実行フェーズは1行で足りるはず。
- 複数行になるならテスト対象外クラスで公開されているAPIが適切に設計されていないことを示唆している。
-
確認フェーズで確認する項目はどれくらいあれば良いか
- 1単位の振る舞いによって複数の結果が生じることはあり得る。それら全てを検証する。
- ただし確認フェーズが大きくなりすぎる場合はプロダクションコードでの抽象化がうまくいっていない可能性がある。
データの整合性が損なわれることは"不変条件の侵害"と呼ばれ、その危険性からコードを守る行為がカプセル化である。
テスト対象システムとその依存との違いが明確に分かることが重要。テスト対象システムをsutと名付ける。
テストケース間で共有するテストフィクスチャ
テストフィクスチャとは?
テストを実施する際に使われるオブジェクトのことを指す。(sutに渡される引数やデータベースのデータやハードディスク上のファイルの場合もある)
このようなオブジェクトは各テストケースが実行されるまえに 決められた(fixed) 状態になっている必要がある。このことからフィクスチャ(fixture)と呼ばれる。
⚠️テストフィクスチャの準備の注意点
- コンストラクタを使うのは可読性の低下とテストケース間の結び付きを強めてしまうため避けるべき。
- 全てのテストケースで同じテストフィクスチャを利用する場合は例外的にコンストラクタを使っても良い。
- テストケースにプライベートなファクトリメソッドを導入するのが良い。
単体テストでのテストメソッドに名前を付けるときの指針
- 厳格な命名規則に縛られないようにする
- 問題領域のことに精通している非開発者に対してどのような検証をするのかが伝わる名前を付ける
- アンダースコアを使って単語を区切る
☆ テスト対象メソッド名をテストメソッド名に含めるべきではない。(ついやってしまう)
単体テストはコードをテストしているのではなく振る舞いをテストしているため。テスト対象メソッド名を含めてしまうと、メソッド名が変更されたときにテストメソッド名まで変更する必要が出てくる。これはコードがテストと結びついていることになる。例外としてユーティリティのコードをテストするときはメソッド名を含めていい。
パラメータ化テスト
- パラメータ化テストはコード量と読みやすさのトレードオフ
- 正常系と異常系を1つのパラメータ化テストにしないようが良い。(何を検証しているか明確なときのみ1つにする)
- テスト対象の振る舞いが複雑すぎる場合はパラメータ化テストは行わず異常系や正常系の検証をそれぞれ個別のテストケースとして実装する。
確認フェーズの読みやすさの改善
import org.junit.jupiter.api.Test;
import static org.assertj.core.api.Assertions.assertThat;
class Calculator {
public double sum(double a, double b) {
return a + b;
}
}
class CalculatorTest {
@Test
void sum_of_two_numbers() {
Calculator calculator = new Calculator();
double result = calculator.sum(10, 20);
assertThat(result).isEqualTo(30);
}
}
AssertJを利用することで、確認に関する記述を英語として読みやすく実装可能である。
第2部 単体テストとその価値
何をもって価値のある単体テストとなるのかという核心を見ていく。どうすれば既存の単体テストをより価値のあるものにリファクタリングできるかを学んでいく。
第4章 良い単体テストを構成する4本の柱
どうすれば価値のあるテストケースを認識できるようになるかを考えていく。
テストケースを分析するのに使う基準となる枠組みについて見ていく。
この基準となる枠組みを用いてソフトウェアテストにおけるよく知られた概念を分析する。
☆ 良い単体テストを構成する4つの柱
- 退行(リグレッション)に対する保護
- リファクタリングへの耐性
- 迅速なフィードバック
- 保守のしやすさ
退行(リグレッション)に対する保護:
テストすることで退行の存在をいかに検出できるかを示す性質
退行(リグレッション)に対する保護がどれくらい備わっているかを把握するには以下のことに目を向ける。
- テスト時に実行されるプロダクションコードの量
- 実行されるプロダクションコードが多ければ退行が見つかる可能性が高くなる。(実行結果の適切な検証が行われていることが前提)
- そのコードの複雑度
- そのコードが扱っているドメインの重要度
- バグがあると影響が大きい
取るに足らないコードに関してはテストをする価値はほとんどない。
リファクタリングへの耐性
プロダクションコードをリファクタリングした際に、テスト対象コードが実際には意図通りの振る舞いをしているにも関わらず、テストコード側の問題によってテストが失敗することを「偽陽性」と呼ぶ。
リファクタリングをしても偽陽性が起こりにくい性質のことを「リファクタリングへの耐性」と呼んでいる。
つまり、偽陽性の発生が少ないほどリファクタリングへの耐性がよく備わっていることになる。
偽陽性によってテストを実施すること自体の意味が損なわれてしまうため、注意を払う必要がある。
偽陽性を生み出す可能性を減らす唯一の方法は、テストコードをテスト対象の内部的なコードから切り離すこと。実行された最終的な結果に対して検証する。(その結果を得るための細かい手順である実装の詳細には目を向けない)
ブラックボックステストが望ましいことと関係ある?→関係あり。
"退行に対する保護"と"リファクタリングへの耐性"との関係
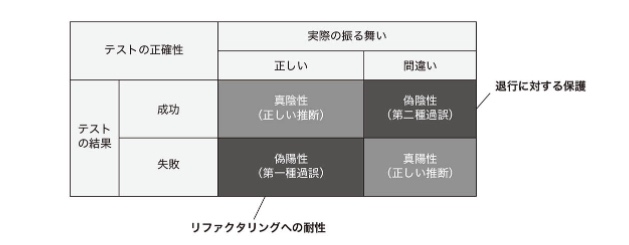
- テストをすることでどれだけバグを検出できるか?偽陰性(見つけられないバグ)の発生を抑制することに関係し、"退行に対する保護"が該当する。
- テストをすることでバグがないことをどれだけ示せるか?偽陽性(嘘の警告)の発生を抑制することに関係し、"リファクタリングへの耐性"が該当する。
偽陽性と偽陰性の重要度の違い
- 偽陽性(嘘の警告)はプロジェクトの初期はそれほど大きな弊害にならないがプロジェクトが成長するにつれてテストスイートに大きな影響を与えるようになる。
- プロジェクトの初期はリファクタリングの必要性がないため。
- プロジェクトが成長するとリファクタリングの必要性が増す。それにつれて"リファクタリングへの耐性"も重要度を増していく。(テストが嘘の警告を出すとテスト結果を信頼できるフィードバックとして見れなくなる)

"迅速なフィードバック"と"保守のしやすさ"
-
"迅速なフィードバック"
- テストが速やかに行えるとフィードバックから改善までの時間が劇的に短くなる。
-
"保守のしやすさ"がどれくらい備わっているかは以下の2点から把握できる。
- テストケースを理解することがどれくらい難しいか?
- テストケースのサイズが影響する。
- テストを行うことがどれくらい難しいか?
- 特にプロセス外依存があると準備フェーズの実装が多くなったり、多くの時間を費やすことになる。
- テストケースを理解することがどれくらい難しいか?
理想的なテストとは?
- 退行(リグレッション)に対する保護
- リファクタリングへの耐性
- 迅速なフィードバック
- 保守のしやすさ
- 「良い単体テストを構成する4つの柱」を掛け算することでテストケースの価値で評価できる。
テストケースの価値=[0...1] * [0...1] * [0...1] * [0...1]- どれか1つでも備わっていないと価値は0になる。
- どの解析ツールでも正確には評価できないが4本の柱の観点において立ち位置を正確に評価可能。
- 理想的なテストは「良い単体テストを構成する4つの柱」を全て完全に備えたテストケースだが、そのようなテストケースは作成不可能である。
- "退行(リグレッション)に対する保護"と"リファクタリングへの耐性"と"迅速なフィードバック"の3本は互いに排反する性質であるため。3本全てを最大限に備えることはできず、どれかを犠牲にしないと他の2本の柱を最大限に備えることはできない。
- 「良い単体テストを構成する4つの柱」のバランスについても考慮が必要。どの柱も欠落させてはならず、全ての柱を可能な限り備えるように努める。
極端な例 #1: E2Eテスト
- 多くのプロダクションコードが実行されるため"退行に対する保護"を十分に備えているテストである。
- 偽陽性(嘘の警告)も持ち込まれにくいため"リファクタリングへの耐性"がもっとも備わったテストである。
- ユーザから見た振る舞いのみ検証しているため実装の詳細から可能な限り切り離されたテストである。
- テスト実行完了までの時間がかかりすぎてしまう。

極端な例 #2: 取るに足りないテスト
- 実行時間がかなり短い。
- 偽陽性(嘘の警告)も持ち込まれにくいため"リファクタリングへの耐性"がもっとも備わったテストである。
- テスト対象コードに間違いが存在する可能性がほとんどないため退行が検出されることがない。
- プロダクションコードと同じことを別の書き方で表現しているだけで何も検証していないのと同じ。

極端な例 #3: 壊れやすいテスト
- 実行時間は短い。
- "退行に対する保護"を十分に備えているテストである。
- "リファクタリングの耐性"はまったく備わっていないテストである。
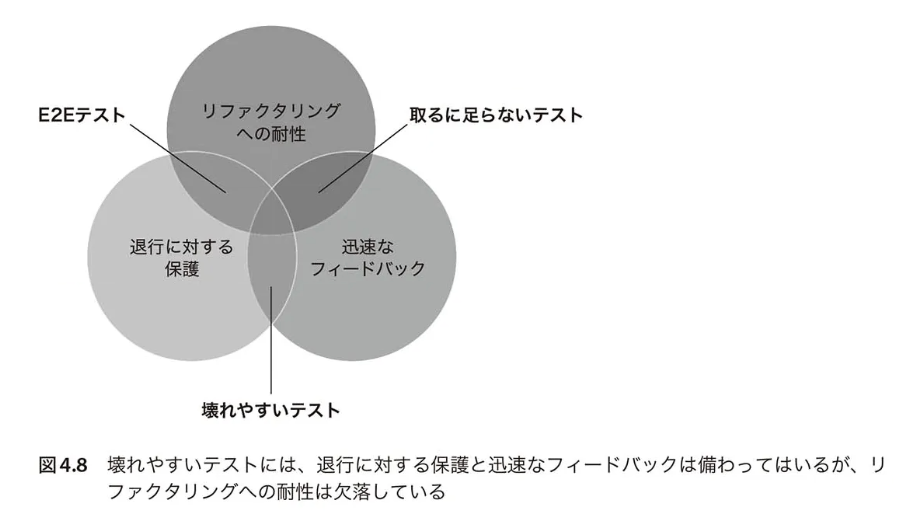
改めて、壊れやすいテストができるのは、テストケースの「何(What)」ではなく「どのように(How)」に目を向けてしまっていることで、テストとテスト対象の内部的なコードが結びついてしまっているため。
単体テストを作成する際に、どの柱を優先し、どの柱を犠牲にするかを決断しなくてはいけない。さらに、4本の柱のどれかが完全に欠如したテストケースを決して作らないように注意しなくてはいけない。
つまり、柱間のトレードオフは部分的、かつ戦略的に行う必要がある。
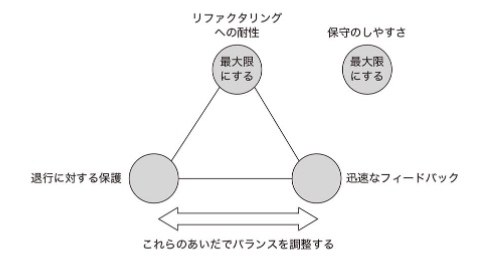
最善の単体テストは"保守のしやすさ"と"リファクタリングへの耐性"を最大限備えたもの。"退行に対する保護"と"迅速なフィードバック"の2本の柱のどちらを優先するかというバランスを調整することになる。
テストピラミッド
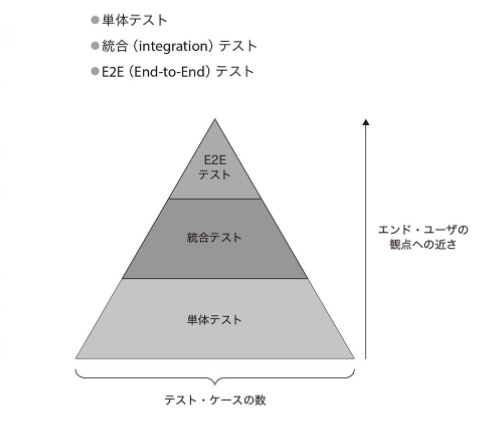
テストピラミッドの層が異なれば"退行に対する保護"と"迅速なフィードバック"とのバランスにおいてどうするのが最善かが変わる。
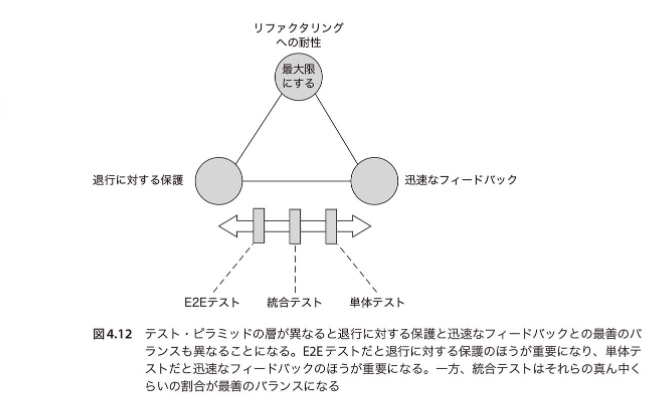
どの層も"リファクタリングへの耐性"を必ず備えるようにする。(つまり偽陽性を可能な限り排除するように努めなければならない)
テストピラミッドにも例外がある。
- テスト対象のアプリケーションが基本的なCRUD操作しか行わず、ビジネスルールや他の複雑なことを扱わない場合は、テストピラミッドは四角に近い形になる。
- 1つのプロセス外依存しか扱わないAPIをテストする場合はE2Eテストをより多く用意するほうがより効果が出る。
- ブラックボックステスト
- システムの機能を内部構造を知ることなしに検証するテスト手法
- ホワイトボックステスト
- システムの機能の内部構造を検証するテスト手法

"リファクタリングへの耐性"を最大限備えることを考えるなら、テストケースを作成するときは ホワイトボックステストよりブラックボックステストをまずは選択しなければならない。
ただし、ホワイトボックステストを使ってはいけない訳ではない。テストを分析する際はホワイトボックステストも用いることができる。カバレッジされていないコードを見つけ出し、その経路を検証するテストケースを作成する。といった様にブラックボックステストとホワイトボックステストを組み合わせることでテストスイートの質をより高めることができる。
第5章 モックの利用とテストの壊れやすさ
テストケースや単体テストの手法を分析するのに使える基準となる枠組みが実際にどのように使われるのかを見ていく。モックを用いたテストを分析していく。
モックを用いることでどの様にテストが壊れやすくなるのか(リファクタリングへの耐性を失うのか)を見ていき、モックを使ってもテストケースが壊れにくいケース、さらにはモックを使った方がテストケースの質が良くなるケースを見ていく。
モックとスタブの違い
テストダブルの種類には大きく分けて2種類(細かく分けると5種類)ある。
- モック
- モック
- スパイ
- スタブ
- ダミー
- スタブ
- フェイク
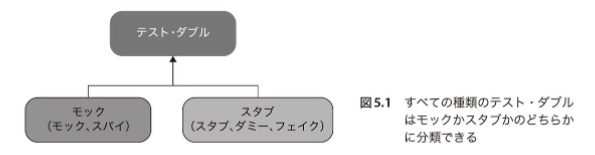
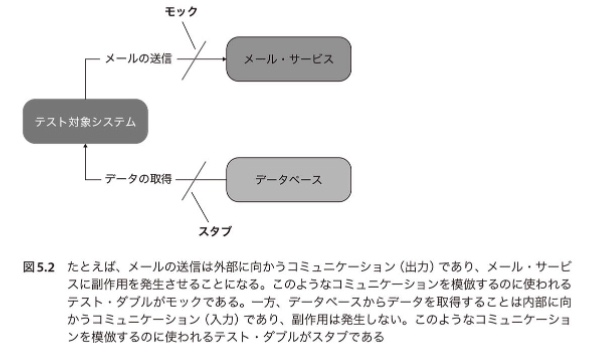
- モックはテスト対象システムからその依存に向かって行われる外部に向かうコミュニケーションを模倣し、検証に使われる。
- スタブは依存からテスト対象システムに向かって行われる内部に向かうコミュニケーションを模倣するのに使われる。
☆ スタブは模倣のみだが、モックは模倣に加えて検証まで行う。
- モックはフレームワークの助けを借りて生成される。
- スパイはモックと同じ役割を果たすが開発者自身の手で実装されるため「手書きのモック」と言われる。
- ダミーはnull値や一時しのぎの文字列など、最低限の値を返すだけのオブジェクト。主にメソッドの引数として使用されるが、最終的な結果を生成することには参加しない。
- スタブは設定によって返す結果を異なるシナリオごとに変えられる完全に自立した依存として振る舞うもの。
- フェイクはまだ存在しない依存を置き換えるために作成するもの。
☆ 道具としてのモックとテストダブルとしてのモックを混同しないようにする。(道具としてのモックからスタブを作成することも可能なため)
☆ スタブとのやり取りを決して検証してはいけない。
スタブはテスト対象クラスが最終的な結果を生成するために必要なデータを提供するだけ。
スタブとのコミュニケーションを検証することはテストを壊れやすくするアンチパターン。
最終的な結果の一部とならないものを検証を検証することを過剰検証という。(スタブとのコミュニケーションを検証することはこれに該当)
モックとスタブの両方の性質を持ったテストダブル
☆ 実業務でこのパターンはある。
import static org.mockito.Mockito.*;
import static org.junit.jupiter.api.Assertions.*;
import org.junit.jupiter.api.Test;
import org.mockito.Mockito;
class StoreTest {
@Test
void purchaseFailsWhenNotEnoughInventory() {
// モックの作成
Store storeMock = mock(Store.class);
// モックの動作設定
when(storeMock.hasEnoughInventory(Product.SHAMPOO, 5)).thenReturn(false);
Customer sut = new Customer();
// メソッドの実行
boolean success = sut.purchase(storeMock, Product.SHAMPOO, 5);
// 検証
assertFalse(success);
verify(storeMock, never()).removeInventory(Product.SHAMPOO, 5);
}
}
模倣と検証を異なるメソッドに対して行っているため、ルールに違反していない。
テストダブルがモックとスタブの両方の性質を備える場合は「スタブ」と呼ばれず「モック」と呼ばれることが一般的。(モックであることのほうが重要なため)
モックとスタブの考え方はコマンド・クエリ分離の原則との関連性がある。
- コマンド:戻り値がなく副作用(オブジェクトの状態を変更したりファイルシステムのファイルを変更すること)を起こすメソッドを指す。→ モックを利用
- クエリ:いかなる副作用も起こさず何らかの値を返すメソッドを指す。→ スタブを利用
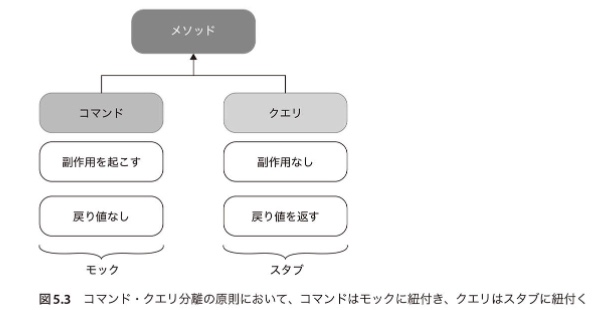
☆ 反証可能なコードを実装する能力のためには意識すべきことだと感じた。
実装の詳細とは何なのか、観測可能な振る舞いとどのように違うのかを見ていく。
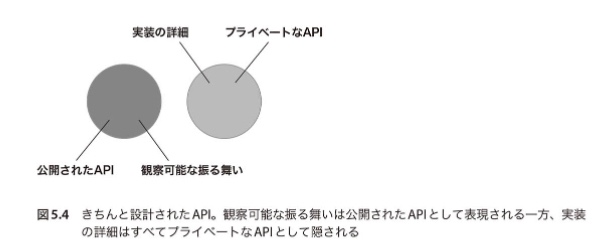
すべてのプロダクションコードは2つの観点で分類できる。
- 公開APIなのかプライベートなAPIなのか
- 観測可能な振る舞いなのか、実装の詳細なのか
観測可能な振る舞いの一部になるにはコードが次のどちらかでなければいけない。
- クライアントが目標を達成するために公開された操作(計算したり副作用を起こしたりするメソッドのこと)
- クライアントが目標を達成するために公開された状態(システムの現時点でのコンディションのこと)
上記2つに該当しないコードが 実装の詳細 となる。
=== 以下があまり分からん ==
コードが観測可能な振る舞いか否かの判断はクライアントが何なのか、そしてそのクライアントが目標としていることは何なのか、ということによって変わる。
「クライアント」とはそのコードがどこにあるかによって変わり、テスト対象のコードを呼び出す同じコードベース上にあるコード、外部アプリケーション、ユーザーインターフェースなどがある。
理想の形
よくありがちな形
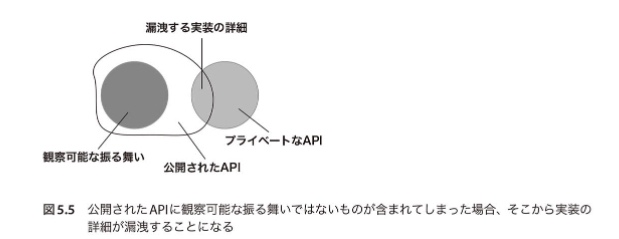
5.2.2 公開APIから漏洩する実装の詳細
クラスが実装の詳細を漏洩しているのかどうかを判断する際に有益な方法がある。
☆ クライアントが1つの目標を達成するためにテスト対象のコードを何度呼び出しをしているかを確認すること。(複数呼び出しをしている場合は実装の詳細を漏洩していると考えられる)
理想とすべきAPIの設計は、いかなる目標であれ、1つの操作で目標を達成できるようにすること。
☆ 実装の詳細が漏洩することで不変条件の侵害が起こることがよくある。そうした不変条件の侵害からコードを守るための手段がカプセル化。カプセル化は間違ったことをする選択肢をコードベースに提供させなくする。カプセル化が目指しているのは単体テストと同じでソフトウェアの持続可能な成長。
「尋ねるな、命じよ」という原則がある。カプセル化を実践していれば自然とたどり着く結論である。
- 実装の詳細を隠すこと
- データの操作をメソッドを経由させること
5.3 モックの利用とテストの壊れやすさの関係
- システム内コミュニケーション: 実装の詳細に該当するため、ここの検証にモックを利用するとテストが実装の詳細と結び付くことになりリファクタリングへの耐性が失われる。
- システム間コミュニケーション: テスト対象のアプリケーションがどのように外部とのコミュニケーションを取るのかは、そのシステムの観測可能な振る舞い全体を形成するもののため実装の詳細に該当しない。ここの検証にはモックの利用が有効的。
第6章 単体テストの3つの手法
単体テストには以下の3つの手法がある。(質の高いテストケースを作成できる順番で記述)
- 出力値ベーステスト(戻り値を確認)
- 状態ベーステスト(状態を確認)
- コミュニケーションベーステスト(オブジェクト間のやり取りを確認する)
出力値ベーステストが用いられてなくても出力値ベーステストに変換できるテクニックがある。そのためには関数型プログラミングの原則に従ってリファクタリングをする。
出力値ベーステスト(戻り値を確認)は関数型による単体テストの手法としても知られており、「関数型」という呼び方は副作用のないコードを書くことが求められる関数型プログラミングから来ている。
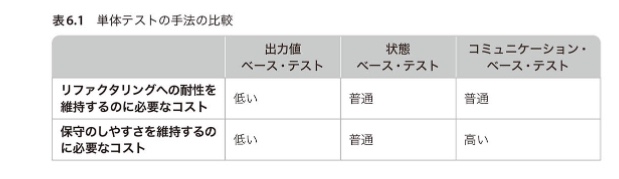
良い単体テストを構成する4つの柱の観点から見る、単体テスト手法の比較
- 退行に対する保護の観点での比較
- 単体テストの手法による影響はほとんどない。
- プロダクションコードの3要素によって決まるため。
- 再掲: https://zenn.dev/link/comments/6c11403c761ada
- 単体テストの手法による影響はほとんどない。
- 迅速なフィードバックの観点での比較
- 単体テストの手法による影響はほとんどない。コミュニケーションベーステストはモックの負荷が加わるため少しだけ遅くなる可能性がある。
- リファクタリングへの耐性の観点での比較
- 偽陽性の発生を最も抑えられるのは出力値ベーステスト(実装の詳細と結び付くのはテスト対象メソッドが実装の詳細である場合のみのため)
- 状態ベーステストは出力値ベーステストに比べて偽陽性が発生しやすくなる。(状態の検証のためにAPIと結び付くことになり実装の詳細を漏洩するコードとも結び付くため)
- コミュニケーションベーステストは偽陽性に対して最も脆弱である。
- 保守のしやすさの観点での比較
- 再掲: https://zenn.dev/link/comments/ed9d0076cc05a3
- 出力値ベーステストを用いたテストケースが最も保守しやすい。
- 状態ベーステストは確認フェーズのコード量が多くなる傾向にあるため出力値ベーステストより保守が難しくなる。
- ヘルパーメソッドを利用したり確認対象をValueObjectにすることでコード量は減らせる。ただしそれらは条件が揃ったときにしか利用できないテクニック。
- コミュニケーションベーステストは最も保守性が低い。
関数型プログラミングは数学的関数を用いたプログラミングで、隠れた入力や出力がない関数のこと。つまり、数学的関数のすべての入力と出力はメソッドシグネチャ(メソッド名、引数、戻り値の型で構成)に明示されることになる。
数学的関数は、検証するテストケースも簡潔で短いものにするだけでなく、理解しやすく、保守しやすいものになる。
隠れた入力や出力の種類は以下のようなものがある。
- 副作用
- 隠れた出力がある。
- 例外
- 隠れた出力がある。
- 内部もしくは外部の状態への参照
- 情報の取得や参照は全てメソッドシグネチャに定義されていない隠れた入力が存在する。
数学的関数かどうかを判断する方法の1つに、参照透過性があるかを確認する。
参照透過性はプログラムの振る舞いが変えずにメソッドを呼び出している部分を実際の値に置き換えられる能力のこと。
関数型プログラミングの目標は、ビジネスロジックを扱うコードと副作用を起こすコードを分離することにある。(副作用を完全に取り除くことではない)
関数型アーキテクチャでは、副作用をビジネスオペレーションの最初や最後に持っていくことで、ビジネスロジックと副作用を分離しやすくなっている。
どうやって、ビジネスロジックと副作用を分離するのか。以下の2種類のコードに分類することで行われる。
- 決定を下すコード(関数的核/不変核)
- 決定に基づくアクションを実行するコード(可変殻)
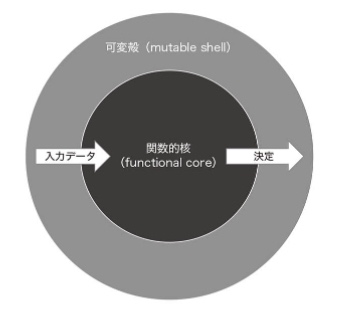
関数的核と可変殻の適切な分離を維持するためには、関数的核の戻り値の型に、可変殻が処理を行うのに必要な情報を全て含めること。言い換えると可変殻は可能な限り指示されたことのみ行うような作りにする。こうすることで、単体テストは出力値ベーステストを用いて関数的核だけを検証できるようになる。可変殻のテストは統合テストに任せる。
カプセル化と不変性
オブジェクト指向プログラミングは可変の部分をカプセル化することによってコードを理解しやすくしている一方、関数型プログラミングは可変の部分を最小限にすることでコードを理解しやすくしている。
関数型アーキテクチャとヘキサゴナルアーキテクチャの比較
【類似点】
- 関心の分離
- 依存の流れが一方向になっている
【違い】
- 副作用の扱い
- 関数型アーキテクチャ:全ての副作用を関数的核の外に出し、ビジネスオペレーションの最初や最後に持ち込む。副作用に関する処理は可変殻で行う。
- ヘキサゴナルアーキテクチャ:ドメイン層での全ての副作用はドメイン層内に収まっていなくてはならず、ドメイン層の境界を超えてはいけない。
☆ 関数型アーキテクチャおよび出力値ベーステストへの移行
以下2つの以降を順を踏んで行うことで実施される。
- プロセス外依存の利用からモックの利用への移行
- モックの利用から関数型アーキテクチャの利用への移行
サンプルコード(訪問者記録システム)
import java.io.IOException;
import java.nio.file.*;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.stream.Collectors;
public class AuditManager {
private final int maxEntriesPerFile;
private final String directoryName;
public AuditManager(int maxEntriesPerFile, String directoryName) {
this.maxEntriesPerFile = maxEntriesPerFile;
this.directoryName = directoryName;
}
public void addRecord(String visitorName, String timeOfVisit) throws IOException {
// 訪問者記録ファイルのディレクトリから全てのファイルパスを取得
// ファイル名に含まれるインデックスで並び替え
List<Path> filePaths = Files.list(Paths.get(directoryName))
.filter(Files::isRegularFile)
.sorted((p1, p2) -> {
String name1 = p1.getFileName().toString();
String name2 = p2.getFileName().toString();
return name1.compareTo(name2);
})
.collect(Collectors.toList());
String newRecord = visitorName + ", " + timeOfVisit;
// 訪問者記録ファイルが未作成なら新規ファイルを作成して記録する
if (filePaths.isEmpty()) {
String newFile = Paths.get(directoryName, "audit_1.txt").toString();
Files.writeString(Paths.get(newFile), newRecord, StandardCharsets.UTF_8);
return;
}
Path currentFilePath = filePaths.get(filePaths.size() - 1);
List<String> lines = Files.readAllLines(currentFilePath, StandardCharsets.UTF_8);
// 記録可能な訪問者の上限数に達しているかを確認
if (lines.size() < maxEntriesPerFile) {
// 上限未達の場合は新たな訪問者の記録を追加
lines.add(newRecord);
Files.write(currentFilePath, lines, StandardCharsets.UTF_8);
} else {
// 新規ファイルを作成して記録を追加
int newIndex = filePaths.size() + 1;
String newName = "audit_" + newIndex + ".txt";
String newFile = Paths.get(directoryName, newName).toString();
Files.writeString(Paths.get(newFile), newRecord, StandardCharsets.UTF_8);
}
}
}
- 退行に対する保護:良い
- リファクタリングへの耐性:良い
- 迅速なフィードバック:悪い
- 保守のしやすさ:悪い
import java.io.IOException;
import java.nio.file.*;
import java.util.List;
import java.util.stream.Collectors;
public interface IFileSystem {
List<String> getFiles(String directoryName) throws IOException;
void writeAllText(String filePath, String content) throws IOException;
List<String> readAllLines(String filePath) throws IOException;
}
class DefaultFileSystem implements IFileSystem {
@Override
public List<String> getFiles(String directoryName) throws IOException {
try (var stream = Files.list(Paths.get(directoryName))) {
return stream.map(Path::toString).collect(Collectors.toList());
}
}
@Override
public void writeAllText(String filePath, String content) throws IOException {
Files.writeString(Paths.get(filePath), content);
}
@Override
public List<String> readAllLines(String filePath) throws IOException {
return Files.readAllLines(Paths.get(filePath));
}
}
import java.io.IOException;
import java.nio.file.Path;
import java.util.*;
public class AuditManager {
private final int maxEntriesPerFile;
private final String directoryName;
private final IFileSystem fileSystem;
public AuditManager(int maxEntriesPerFile, String directoryName, IFileSystem fileSystem) {
this.maxEntriesPerFile = maxEntriesPerFile;
this.directoryName = directoryName;
this.fileSystem = fileSystem;
}
public void addRecord(String visitorName, String timeOfVisit) throws IOException {
List<String> filePaths = fileSystem.getFiles(directoryName);
List<String> sorted = filePaths.stream().sorted().toList();
String newRecord = visitorName + ";" + timeOfVisit;
if (sorted.isEmpty()) {
String newFile = Path.of(directoryName, "audit_1.txt").toString();
fileSystem.writeAllText(newFile, newRecord);
return;
}
String currentFilePath = sorted.get(sorted.size() - 1);
List<String> lines = fileSystem.readAllLines(currentFilePath);
if (lines.size() < maxEntriesPerFile) {
lines.add(newRecord);
String newContent = String.join("\n", lines);
fileSystem.writeAllText(currentFilePath, newContent);
} else {
int newIndex = sorted.size() + 1;
String newFile = Path.of(directoryName, "audit_" + newIndex + ".txt").toString();
fileSystem.writeAllText(newFile, newRecord);
}
}
}

import static org.mockito.Mockito.*;
import static org.junit.jupiter.api.Assertions.*;
import org.junit.jupiter.api.Test;
import org.mockito.Mockito;
import java.io.IOException;
import java.util.List;
class AuditManagerTest {
@Test
void testNewFileIsCreatedWhenCurrentFileOverflows() throws IOException {
IFileSystem fileSystemMock = mock(IFileSystem.class);
when(fileSystemMock.getFiles("audits"))
.thenReturn(List.of("audits/audit_1.txt", "audits/audit_2.txt"));
when(fileSystemMock.readAllLines("audits/audit_2.txt"))
.thenReturn(List.of(
"Peter;2019-04-06T16:30:00",
"Jane;2019-04-06T16:40:00",
"Jack;2019-04-06T17:00:00"
));
AuditManager sut = new AuditManager(3, "audits", fileSystemMock);
sut.addRecord("Alice", "2019-04-06T18:00:00");
verify(fileSystemMock).writeAllText(
"audits/audit_3.txt",
"Alice;2019-04-06T18:00:00"
);
}
}
- 退行に対する保護:良い
- リファクタリングへの耐性:良い
- 迅速なフィードバック:良い(ファイルシステムにアクセスをしなくなったため)
- 保守のしやすさ:普通(ファイルシステムに関する後始末などが不要になったため。ただし準備フェーズの実装は改善の余地がある)
【関数型アーキテクチャへのリファクタリング】


import java.nio.file.*;
import java.time.LocalDateTime;
import java.util.*;
import java.util.stream.*;
public class AuditManager {
private final int maxEntriesPerFile;
public AuditManager(int maxEntriesPerFile) {
this.maxEntriesPerFile = maxEntriesPerFile;
}
public FileUpdate addRecord(FileContent[] files, String visitorName, LocalDateTime timeOfVisit) {
List<Map.Entry<Integer, FileContent>> sorted = sortByIndex(files);
String newRecord = visitorName + ";" + timeOfVisit;
if (sorted.isEmpty()) {
return new FileUpdate("audit_1.txt", newRecord);
}
Map.Entry<Integer, FileContent> current = sorted.get(sorted.size() - 1);
List<String> lines = new ArrayList<>(List.of(current.getValue().getLines()));
if (lines.size() < maxEntriesPerFile) {
lines.add(newRecord);
String newContent = String.join("\r\n", lines);
return new FileUpdate(current.getValue().getFileName(), newContent);
} else {
int newIndex = current.getKey() + 1;
String newName = "audit_" + newIndex + ".txt";
return new FileUpdate(newName, newRecord);
}
}
private List<Map.Entry<Integer, FileContent>> sortByIndex(FileContent[] files) {
return IntStream.range(0, files.length)
.mapToObj(i -> Map.entry(i, files[i]))
.sorted(Comparator.comparingInt(Map.Entry::getKey))
.collect(Collectors.toList());
}
}
class FileContent {
private final String fileName;
private final String[] lines;
public FileContent(String fileName, String[] lines) {
this.fileName = fileName;
this.lines = lines;
}
public String getFileName() {
return fileName;
}
public String[] getLines() {
return lines;
}
}
class FileUpdate {
private final String fileName;
private final String newContent;
public FileUpdate(String fileName, String newContent) {
this.fileName = fileName;
this.newContent = newContent;
}
public String getFileName() {
return fileName;
}
public String getNewContent() {
return newContent;
}
}
class Persister {
public FileContent[] readDirectory(String directoryName) throws IOException {
return Files.list(Paths.get(directoryName))
.map(path -> {
try {
return new FileContent(path.getFileName().toString(), Files.readAllLines(path).toArray(new String[0]));
} catch (IOException e) {
throw new UncheckedIOException(e);
}
})
.toArray(FileContent[]::new);
}
public void applyUpdate(String directoryName, FileUpdate update) throws IOException {
Path filePath = Paths.get(directoryName, update.getFileName());
Files.write(filePath, update.getNewContent().getBytes());
}
}
class ApplicationService {
private final String directoryName;
private final AuditManager auditManager;
private final Persister persister;
public ApplicationService(String directoryName, int maxEntriesPerFile) {
this.directoryName = directoryName;
this.auditManager = new AuditManager(maxEntriesPerFile);
this.persister = new Persister();
}
public void addRecord(String visitorName, LocalDateTime timeOfVisit) throws IOException {
FileContent[] files = persister.readDirectory(directoryName);
FileUpdate update = auditManager.addRecord(files, visitorName, timeOfVisit);
persister.applyUpdate(directoryName, update);
}
}
import org.junit.jupiter.api.Test;
import java.time.LocalDateTime;
import static org.junit.jupiter.api.Assertions.assertEquals;
public class AuditManagerTest {
@Test
public void aNewFileIsCreatedWhenTheCurrentFileOverflows() {
AuditManager sut = new AuditManager(3);
FileContent[] files = new FileContent[] {
new FileContent("audit_1.txt", new String[0]),
new FileContent("audit_2.txt", new String[] {
"Peter;2019-04-06T16:30:00",
"Jane;2019-04-06T16:40:00",
"Jack;2019-04-06T17:00:00"
})
};
FileUpdate update = sut.addRecord(
files, "Alice", LocalDateTime.parse("2019-04-06T18:00:00"));
assertEquals("audit_3.txt", update.getFileName());
assertEquals("Alice;2019-04-06T18:00:00", update.getNewContent());
}
}
- 退行に対する保護:良い
- リファクタリングへの耐性:良い
- 迅速なフィードバック:良い
- 保守のしやすさ:良い
第7章 単体テストの価値を高めるリファクタリング
この章では、出力値ベーステストを行えるようにするアプローチを幅広い範囲のアプリケーション(第6章まで見てきた関数型アーキテクチャへのリファクタリングができないアプリケーションを含む)に浸透させるにはどうするのかを見ていく。
そしてどのすれば価値のあるテストをほぼ全てのソフトウェアプロジェクトで作成できるようになるのかという実践的な指針についても学んでいく。
☆【リファクタリングが必要なコードの識別】
全てのプロダクションコードは次の2つの視点で分類できる。
- コードの複雑さ、もしくはドメインにおける重要性
- 協力者オブジェクトの数
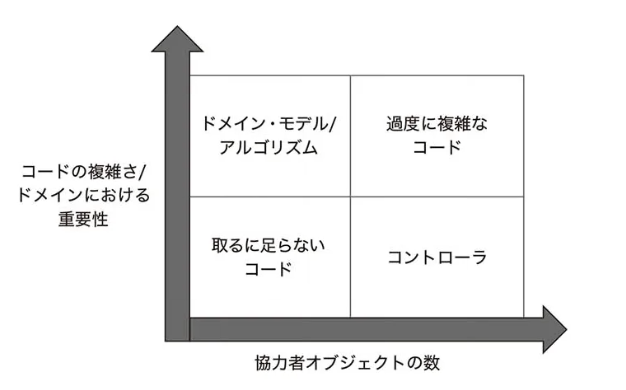
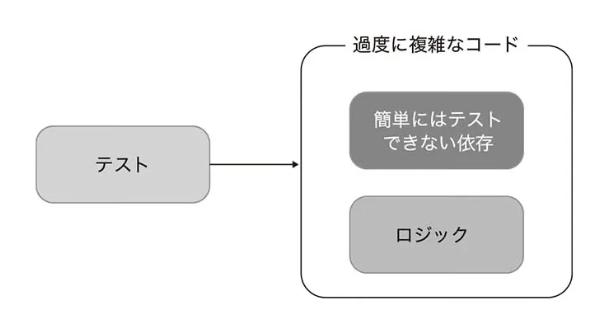
過度に複雑なコードはテストをすることが非常に難しいにも関わらず、テスト無しにしておくには危険なコード達のこと。(実業務で沢山存在する⋯)この章でどのようにこのジレンマを回避するのかということを考えていく。よく行われることとしては、過度に複雑なコードをアルゴリズムとコントローラーに分割することだが、現実的に難しい場合も多々存在する。
過度に複雑なコードを取り除き、単体テストで検証するコードをドメインモデルやアルゴリズムにお属するコードだけにすることは、テストスイートの価値を高くし、保守を行いやすくすることに繋がる。過度に複雑なコードを取り除くことを行いやすくするためのテクニックは存在するため、その根底にある理論を学び、どのようにテクニックを使うのかを見ていく。
【質素なオブジェクト(Humble Object)を用いた過度に複雑なコードの分割】
過度に複雑なコードを分割する場合、質素なオブジェクト(Humble Object)と呼ばれる設計パターンを導入することが考えられる。
テストをすることが難しくなるのはテスト対象のコードがフレームワークとなる依存に直接結びつく場合が多い。(非同期や複数スレッドでの実行、ユーザインターフェース、プロセス外依存とのコミュニケーションなど)
そのような依存と結びついてしまったロジックをテストするには、過度に複雑なコードから、テストをしやすい部分を抽出する必要がある。
その抽出された部分を包み込む質素(Humble)なクラスを作成し、そのクラスに対して、テストが難しい依存を結びつけるようにする。その質素(Humble)なクラスにはロジックをほぼ含ませないようにすることで、テストをする必要がないようにする。

上記のパターンは、ヘキサゴナルアーキテクチャと関数型アーキテクチャもこのパターンを適用している。
関数的核と可変殻(https://zenn.dev/link/comments/52fa0a77e67177)を4種のプロダクトコードの分類にプロットした場合

☆ ビジネスロジックに関するコードと連携の指揮に関するコードを分離することは非常に重要。(現在広く知られている原則や設計パターンは質素なオブジェクトの一種として見ることができる)
【単体テストに価値を持たせるためのリファクタリング】
サンプルプロジェクト(ユーザ管理システム)
- もしユーザのメールアドレスに自社のドメイン名が含まれている場合、そのユーザの種類(type)を「従業員(employee)」として登録して、そうでない場合は「顧客(customer)」として登録する。
- 登録されたユーザの中から従業員となるユーザの数(従業員数)を管理し、ユーザの種類が従業員から顧客に変わるのであれば、従業員数を減らし、その逆に、顧客から従業員に変わるのであれば、従業員を増やすようにする。
- メールアドレスの変更ができたらメッセージバスにメッセージを送り、メールアドレスが変更されたことを外部のシステムに通知する。
public class User {
private int userId;
private String email;
private UserType type;
public int getUserId() {
return userId;
}
public String getEmail() {
return email;
}
public UserType getType() {
return type;
}
public void changeEmail(int userId, String newEmail) {
Object[] data = Database.getUserById(userId); // 指定したユーザのメールアドレスと種類をデータベースから取得する
this.userId = userId;
this.email = (String) data[1];
this.type = (UserType) data[2];
if (email.equals(newEmail)) {
return;
}
Object[] companyData = Database.getCompany(); // 会社のドメイン名と従業員数を取得する
String companyDomainName = (String) companyData[0];
int numberOfEmployees = (int) companyData[1];
String emailDomain = newEmail.split("@")[1];
boolean isEmailCorporate = emailDomain.equals(companyDomainName);
UserType newType = isEmailCorporate ? UserType.Employee : UserType.Customer; // メールアドレスに含まれるドメイン名をもとにユーザの種類を決める
if (type != newType) {
int delta = newType == UserType.Employee ? 1 : -1;
int newNumber = numberOfEmployees + delta;
Database.saveCompany(newNumber); // 必要に応じて従業員数を更新する
}
this.email = newEmail;
this.type = newType;
Database.saveUser(this); // ユーザの情報をデータベースに保存する
MessageBus.sendEmailChangedMessage(userId, newEmail); // メッセージバスにメッセージを送る
}
}
enum UserType {
Customer(1),
Employee(2);
private final int value;
UserType(int value) {
this.value = value;
}
public int getValue() {
return value;
}
}
class Database {
public static Object[] getUserById(int userId) {
// Implement database retrieval logic
return new Object[]{};
}
public static Object[] getCompany() {
// Implement database retrieval logic
return new Object[]{};
}
public static void saveCompany(int newNumber) {
// Implement database save logic
}
public static void saveUser(User user) {
// Implement database save logic
}
}
class MessageBus {
public static void sendEmailChangedMessage(int userId, String newEmail) {
// Implement message sending logic
}
}
-
ChangeEmailメソッドのなかで明示的な決定を下す箇所が以下2箇所しかないためコードは複雑なものはない。しかし、システムにとっては重要な部分のビジネスロジックの一部なのでドメインにおける重要性が高い。- ユーザが従業員なのか顧客なのかの判断
- 従業員数を更新するのか否かの判断
- Userクラスは2つの明示的な依存と2つの暗黙的な依存の合計4つの依存を持つ。
- 2つの明示的な依存:
ChangeEmailメソッドの引数であるuserIdとnewEmail→ これらは値として見ることができるため協力者オブジェクトにならない。 - 2つの暗黙的な依存:
DatabaseクラスとMessageBusクラス → これらはプロセス外依存のため協力者オブジェクトになる。
- 2つの明示的な依存:
- ドメインにおける重要度が高いコードに協力者オブジェクトを含めてはいけないが、
Userクラスは協力者オブジェクトを2つも含んでいるため、過度に複雑なコードに分類されることになる。- ドメインクラスがデータベースから自身のデータを取得したり保存したりする設計パターンをActive Recordパターンと呼ぶ。
- このようになってしまうのは2つの責務(ビジネスロジックとプロセス外依存とのコミュニケーション)を分離できていないことが原因。

1回目のリファクタリング
アプリケーションサービス層を導入することで、Userクラスからプロセス外依存を扱う負担を取り除く。
public class UserController {
private final Database database = new Database();
private final MessageBus messageBus = new MessageBus();
public void changeEmail(int userId, String newEmail) {
Object[] data = database.getUserById(userId);
String email = (String) data[1];
UserType type = (UserType) data[2];
User user = new User(userId, email, type);
Object[] companyData = database.getCompany();
String companyDomainName = (String) companyData[0];
int numberOfEmployees = (int) companyData[1];
int newNumberOfEmployees = user.changeEmail(
newEmail, companyDomainName, numberOfEmployees);
database.saveCompany(newNumberOfEmployees);
database.saveUser(user);
messageBus.sendEmailChangedMessage(userId, newEmail);
}
}
class User {
private int userId;
private String email;
private UserType type;
public User(int userId, String email, UserType type) {
this.userId = userId;
this.email = email;
this.type = type;
}
public int changeEmail(String newEmail, String companyDomainName, int numberOfEmployees) {
if (email.equals(newEmail)) {
return numberOfEmployees;
}
String emailDomain = newEmail.split("@")[1];
boolean isEmailCorporate = emailDomain.equals(companyDomainName);
UserType newType = isEmailCorporate ? UserType.Employee : UserType.Customer;
if (type != newType) {
int delta = newType == UserType.Employee ? 1 : -1;
numberOfEmployees += delta;
}
email = newEmail;
type = newType;
return numberOfEmployees;
}
}
enum UserType {
Customer(1),
Employee(2);
private final int value;
UserType(int value) {
this.value = value;
}
public int getValue() {
return value;
}
}
class Database {
public Object[] getUserById(int userId) {
// Implement database retrieval logic
return new Object[]{};
}
public Object[] getCompany() {
// Implement database retrieval logic
return new Object[]{};
}
public void saveCompany(int newNumber) {
// Implement database save logic
}
public void saveUser(User user) {
// Implement database save logic
}
}
class MessageBus {
public void sendEmailChangedMessage(int userId, String newEmail) {
// Implement message sending logic
}
}
このリファクタリングを行っても以下のような課題が残る。
- プロセス外依存は直接インスタンス化されており注入されていない。
- データベースから取得したデータをそのまま使って
Userクラスのインスタンスを生成している。(この変換は複雑なロジックに該当するものでありアプリケーションサービスで行うべきではない)同じことが会社のデータについても言える。 -
Userクラスのオブジェクトがメールアドレスを変更したあとに従業員数を返却するようになっている。従業員数は特定のユーザが扱う責務ではないため、別のクラスに持たせる必要がある。 - 更新されたデータを保存後に無条件でメッセージバスにメッセージを送るようになっている。

2回目のリファクタリング
アプリケーションサービスから複雑さを取り除くために、データベースから取得したデータをそのまま使ってUserクラスのインスタンスを生成しているロジックをUserControllerから取り除く。O/Rマッパーを利用しているのであればそこに変換ロジックをもたせるのが良いが、利用しない場合は、変換ロジックをドメインモデルに持たせるようにする。
public class UserFactory {
public static User create(Object[] data) {
if (data.length < 3) {
throw new IllegalArgumentException("Data array must have at least 3 elements");
}
int id = (int) data[0];
String email = (String) data[1];
UserType type = (UserType) data[2];
return new User(id, email, type);
}
}
- 協力者オブジェクトを1つも持たないためテスト容易性が高い。
- このメソッドには送られてくるデータのセーフティーネットが設けられている。
- 変換ロジックは複雑さは持っていてもドメインにおける重要性はないためユーティリティコードとして扱われることになる。
3回目のリファクタリング
従業員数を返却する責務を持たせる新たなCompanyクラスをドメイン層に作成する。
public class Company {
private final String domainName;
private int numberOfEmployees;
public Company(String domainName, int numberOfEmployees) {
this.domainName = domainName;
this.numberOfEmployees = numberOfEmployees;
}
public String getDomainName() {
return domainName;
}
public int getNumberOfEmployees() {
return numberOfEmployees;
}
// 従業員数を変更する
public void changeNumberOfEmployees(int delta) {
if (numberOfEmployees + delta < 0) {
throw new IllegalArgumentException("Number of employees cannot be negative");
}
numberOfEmployees += delta;
}
// 会社に属するメールアドレスか
public boolean isEmailCorporate(String email) {
String emailDomain = email.split("@")[1];
return emailDomain.equals(domainName);
}
}
class CompanyFactory {
public static Company create(Object[] data) {
if (data.length < 2) {
throw new IllegalArgumentException("Data array must have at least 2 elements");
}
String domainName = (String) data[0];
int numberOfEmployees = (int) data[1];
return new Company(domainName, numberOfEmployees);
}
}
上記のメソッドは「尋ねるな、命じよ」という原則(データとそのデータに関連する操作をまとめておき、その操作を使ってデータを処理させる原則)をメソッドの呼び出し元に遵守させる作りになっている。
public class UserController {
private final Database database = new Database();
private final MessageBus messageBus = new MessageBus();
public void changeEmail(int userId, String newEmail) {
Object[] userData = database.getUserById(userId);
User user = UserFactory.create(userData);
Object[] companyData = database.getCompany();
Company company = CompanyFactory.create(companyData);
user.changeEmail(newEmail, company);
database.saveCompany(company);
database.saveUser(user);
messageBus.sendEmailChangedMessage(userId, newEmail);
}
}
class User {
private int userId;
private String email;
private UserType type;
public User(int userId, String email, UserType type) {
this.userId = userId;
this.email = email;
this.type = type;
}
public void changeEmail(String newEmail, Company company) {
if (email.equals(newEmail)) {
return;
}
UserType newType = company.isEmailCorporate(newEmail)
? UserType.Employee
: UserType.Customer;
if (type != newType) {
int delta = newType == UserType.Employee ? 1 : -1;
company.changeNumberOfEmployees(delta);
}
email = newEmail;
type = newType;
}
}
-
Userクラスから担うべきでない責務(会社のデータに関する処理)を取り除いたことでUserクラスのコードが簡潔で理解しやすいものになった。

プロダクションコードの種類に基づく効果的な単体テストの作成

単体テストの費用対効果の観点では、最も効果を得られるのは左上のメソッド。(コードの複雑度やドメインにおける重要度が高いほど退行に対する保護を強く保証できる、かつ協力者オブジェクトの数が少ないほど保守コストを減らせる)
事前条件(以下の例で言うと、 if (numberOfEmployees + delta < 0)の部分)をテストすべきか?
public class Company {
private final String domainName;
private int numberOfEmployees;
// 従業員数を変更する
public void changeNumberOfEmployees(int delta) {
if (numberOfEmployees + delta < 0) {
throw new IllegalArgumentException("Number of employees cannot be negative");
}
numberOfEmployees += delta;
}
確固たるルールは存在しないが、事前条件がドメインにとって重要であればテストすべきである。
例えば以下の事前条件の例は、ドメインにとって重要ではないため、テストする価値はあまりない。
public class UserFactory {
public static User create(Object[] data) {
if (data.length < 3) {
throw new IllegalArgumentException("Data array must have at least 3 elements");
}
…
}
}
7.4 コントローラーにおける条件付きロジックの扱い
ビジネスロジックのコードと連携を指揮するコードの分離を最も行いやすくするのは1つのビジネスオペレーションが次の3段階になっている場合。
- ストレージからのデータ取得
- ビジネスロジックの実行
- 変更されたデータの保存
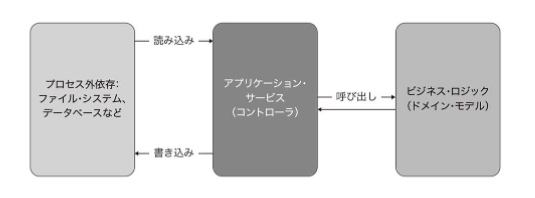
このケースにできない場合も数多くある。(例えば次のようなケース)
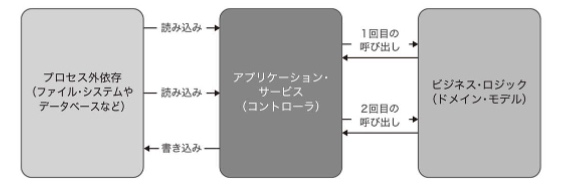
上記の課題を解決するための選択肢は3つ存在する。
①外部の依存に対するすべての読み込みと書き込みをビジネスオペレーションの始めと終わりに持っていく(後述の性質AとBを備える)
②ドメインモデルにプロセス外依存を注入する(後述の性質BとCを備える)
③決定を下す過程をさらに細かく分割する(後述の性質AとCを備える)
上記の選択肢を選ぶ際に重要なのは次に挙げる3つの性質がうまくバランスが取れていること。(ただし3つの性質を全て備えることはできず2つまでしか備えることができない)
A.ドメインモデルのテストのしやすさ
B.コントローラーの簡潔さ
C.パフォーマンスの高さ
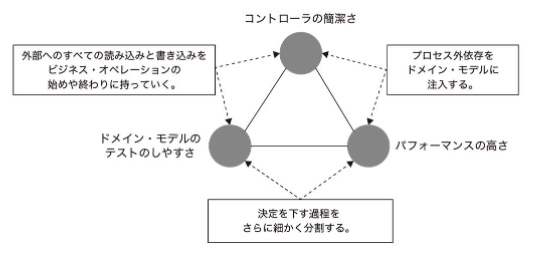
AとCは超重要な性質なため、Bの性質を犠牲にする選択肢③が現実的な選択である。ただし、コントローラーの簡潔さを損ねても、複雑になりすぎない管理可能なレベルにまで抑えることはできる。
7.4.2 ドメインモデルの状態を追跡するドメインイベントの利用
ドメインイベントが表現していることは既に起こったことであるためドメインイベントの名前は常に過去形で付けるようにする。
例えば、メールアドレスが変更されたことを伝えるドメインイベントを格納するコレクションをUserクラスに持たせ、メールアドレスが変更されたときに値を追加するようにする。
第3部 統合テスト
第8章 なぜ統合テストを行うのか
統合テストは、プロセス外依存と直接的にやり取りを行うことがあるため、テストを実行してから終わるまでに時間がかかる。
さらに、保守コストは単体テストより高くなる。(プロセス外依存を利用可能な状態に維持する必要がある。協力者オブジェクトの数が増えるにつれて、テストケースのコード量が増える。)
一方で、単体テストより多くのコードを実行させることになるため退行に対する保護は優れている。さらに、プロダクションコードとの結びつきが直接的ではないため、リファクタリングへの耐性も優れている。
単体テストと統合テストの適切なテストケースの割合は、一般的に単体テストはビジネスシナリオにおける異常系ケースをできるだけ多く検証するのに対して、統合テストは1件のハッピーパス+単体テストで検証不可能な全てのケースを検証することが適切とされている。
検証する内容のほとんどを単体テストに持たせることでテストスイート全体の保守コストを少なくする。加えて、ビジネスシナリオごとに1〜2件の包括的な統合テストを行うことで、システム全体が正しく機能することに自信が持てるようになる。
8.4 インターフェースを使った依存の抽象化
8.4.1 インターフェースと疎結合の関係
インターフェースの利用に関して誤解している開発者が多く、インターフェースを過度に使われてしまっている。
インターフェースが利用される理由でよく挙げられるものは以下2つがあるが、いずれも誤った認識である。
- プロセス外依存を抽象化できるようになり疎結合を実現できるようになる。
- 大前提として、インターフェースの実装クラスが1つしかなければ、そのインターフェースは抽象ではなく、具象クラスをそのまま使う場合と比べて疎結合になるわけではない。つまり、インターフェースが本当の抽象になるためには2つ以上の実装クラスが存在していなければいけない。
- 既存のコードを変更することなく新しい機能を追加できるようになり、開放/閉鎖原則を遵守しやすくなる。
- 設計のより根本的な原則であるYAGNI原則から外れている。現時点で必要とされていない機能に時間を費やすことが無駄であったり、念の為に導入するのはコード量を不必要に増やすことになることため望ましいことではない。
8.4.2 なぜプロセス外依存にインターフェースを使うか?
インターフェースを実装するクラスが1つしかないにもかかわらずプロセス外依存にインターフェースを利用するのはモックを作成できるようにするためという実践的かつ現実的な理由のため。
つまりは、管理下にない依存(例えば他のアプリケーションからもアクセスされるプロセス外依存)に対してのみインターフェースを用意するという結論に至る。
8.5 統合テストのベストプラクティス
◉ ドメインモデルの境界を明確にする
◉ アプリケーションを構成する層を減らす
◉ 循環依存を取り除く
◉ ドメインモデルの境界を明確にする
ドメインクラスとコントローラーの境界が明確になっていれば単体テストと統合テストの区別をしやすくなる。(ドメインクラスは単体テスト、コントローラーは統合テストでテストする)
◉ アプリケーションを構成する層を減らす
間接参照の層が多くなるとコードが何をしているか理解しずらくなり、開発者の認知的負荷となり開発全体の進行を妨げるものになる。
バックエンドシステムであれば、ほとんどの場合、ドメイン層・アプリケーションサービス層・インフラ層の3層で十分。
◉ 循環依存を取り除く
循環依存とは適切に機能させるために2つ以上のクラスが直接的もしくは間接的にお互いに依存する状態を指す。(よくある循環依存の例にコールバックがある)
循環依存はテストにも悪影響を及ぼす。テストするためにインターフェースとモックを使ってクラス感の依存関係を分解し、1単位の振る舞いとなるように隔離されることがあるが、循環依存の問題を隠しているだけに過ぎない。(再掲:ドメインモデルのテストにおいてモックを使ったテストはやってはいけない)
8.6 ログ出力に対するテスト
第9章 モックのベストプラクティス
モックの導入に関して「管理下にない依存(外部アプリケーションから観察可能な依存だけ)をモックに置き換える。」という指針に従っていても成功までの道のりの約2/3までしか到達できていないため、成功までの残りの道のりを見ていく。
◉ モックの利用は統合テストに限定する(単体テストでは利用しない)
◉ モックに対して行われた呼び出しの回数を常に確認する
- 想定する呼び出しが行われていること
- 想定しない呼び出しは行われていないこと
◉ モックの対象になる型は自身のプロジェクトが所有する型のみにする
- サードパーティ製のライブラリが提供するものを直接モックに置き換えるのではなく、そのライブラリに対する独自のアダプタを作成して、アダプタに対してモックを作成する。
- サードパーティ製のライブラリが持つ複雑さを抽象化できるようになる。
- サードパーティ製のライブラリが提供する機能のなかで必要な機能のみ公開できるようになる。
- 自身のプロジェクトで使っているドメインの用語を使えるようになる。
検証の際はプロダクションコードを信用しない。テストではプロダクションカードに定義されたリテラルや定数は使わないようにする。(テストではプロダクションコードから影響を受けない検証を行える場所を提供しなければいけない)
第10章 データベースに対するテスト
可能な限り、単位作業(unit of work)パターンを採用するようにする。単位作業パターンは仕様するデータベースのトランザクションに依存するもので、全ての更新をビジネスオペレーションの最後まで行わないように後ろ回しにするようになっており、このことはパフォーマンスの向上につながる。
テストの際にSQLiteなどのインメモリデータベースを使わないようにする。テストの際にベンダーのデータベースを使ってもアプリケーションへの適切な保護を得ることはできない。そのため統合テストでも本番環境と同じ種類のデータベースを使うようにする。
第4部 単体テストのアンチパターン
第11章 単体テストのアンチパターン
11.1 プライベートなメソッドに対する単体テスト
基本的にはプライベートなメソッドに対するテストは一切すべきではないが、例外的なケースも存在する。
大前提として、プライベートなメソッドをテストすること自体は悪いことではない。プライベートなメソッドをテストすべきでない理由は、プライベートなメソッドは実装の詳細に繋がるものであるため、実装の詳細がテストされるとテストが壊れやすいものになってしまうから。
しかし、極めて稀に、プライベートでありながらも観測可能なふるまいの一部となるメソッドが存在することがある。
import java.time.LocalDateTime;
import java.util.Optional;
public class Inquiry {
private boolean isApproved;
private LocalDateTime timeApproved;
public boolean isApproved() {
return isApproved;
}
public Optional<LocalDateTime> getTimeApproved() {
return Optional.ofNullable(timeApproved);
}
// O/Rマッパーがデータベースからデータ取得し、そのデータを使ってこのクラスのインスタンスを生成するときに呼び出されることが意図されており、呼び出しをO/Rマッパーだけに制限したかったためプライベートにしている
private Inquiry(boolean isApproved, LocalDateTime timeApproved) {
if (isApproved && timeApproved == null) {
throw new IllegalArgumentException();
}
this.isApproved = isApproved;
this.timeApproved = timeApproved;
}
public void approve(LocalDateTime now) {
if (isApproved) {
return;
}
isApproved = true;
timeApproved = now;
}
}
このクラスに定義されている承認(approve)のロジックは明らかに重要なロジックであるため単体テストで検証したいが、コンストラクタがプライベートである。テストのためにコンストラクタを公開してはならないという指針があるため公開できない⋯
今回のケースは、Inquiryクラスのコンストラクタを公開してもテストが壊れやすくなることはないため公開しても良い。また別の選択肢として、リフレクションを用いてInquiryクラスのインスタンスを生成する方法もある。
11.3 テストへのドメイン知識の漏洩
プロダクションコードのアルゴリズムをテストコードに持ち込むことは問題であり、アンチパターンである。(ブラックボックステストの観点でプロダクションコードをテストする必要がある)
そのようなテストは実装の詳細と結びついた別の形の例に過ぎない。そのため、リファクタリングへの耐性はほぼ持っておらず、テストとしての価値がない。
ロジックやアルゴリズムをテストコードに書くのでなく、期待値に値を直接書き込むようにする(実践すべきプラクティスである)
11.4 プロダクションコードへの汚染
テストに関するコードをプロダクションコードに含ませないようにしなければいけない。
プライベートなメソッドを検証するのに公開されたAPIの振る舞いの一部としてテストすることがあまりにも難しいのであればテスト対象のコードにて抽象化の欠落が起こっている可能性が高い。
テスト対象コードに対して適切な抽象化を行い、その抽象化したものを別のクラスとして抽出し、その抽出したクラスに対して検証を行う。