kube-controller-manager
Index
コードリーディング用ブランチ/タグ
TODO
controller-manager
- controller-manger
メインとなるコントローラー
アカウント/権限関連
Namespace関連
Endpoints関連
- endpoints-controller
- endpointslice-controller TODO ちゃんとは読んでない
- endpointslice-mirroring-controller TODO さっとみただけ
Pod関連
- replicationcontroller-controller TODO replicaset-controllerとの違いが不明
- daemonset-controller
- job-controller
- deployment-controller
- replicaset-controller
- horizontal-pod-autoscaler-controller
- disruption-controller
- statefulset-controller
- cronjob-controller
- pod-garbage-collector-controller
- ttl-after-finished-controller
証明書関連
- certificatesigningrequest-signing-controller
- certificatesigningrequest-approving-controller
- certificatesigningrequest-cleaner-controller
- root-ca-certificate-publisher-controller
Node関連
ボリューム関連
- persistentvolume-binder-controller
- persistentvolume-attach-detach-controller
- persistentvolume-expander-controller
- persistentvolumeclaim-protection-controller
- persistentvolume-protection-controller
- ephemeral-volume-controller
その他
余力があったらやるコントローラー
- storageversion-garbage-collector-controller
- resourceclaim-controller
- validatingadmissionpolicy-status-controller
参考資料
エントリーポイント
内容について
プログラムの起動~controller群の起動まで
コマンド初期化
- option初期化: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L107-L111
- 各種flagsetを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L158-L165
- help時の出力関数を設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L167-L168
- バージョン出力時の処理: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L131
- klogの設定をバリデーション: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L133-L137
- コマンドラインフラグを出力: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L138
- configを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L140-L143
- バリデーション: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/options/options.go#L428-L430
- 必要に応じて自己証明書を発行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/options/options.go#L432-L434
- 設定からkubeconfigを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/options/options.go#L436-L444
- clientsetを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/options/options.go#L446-L449
- eventrecorderを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/options/options.go#L451-L452
- optionを生成してoptionが受け取った各種設定をconfigに流し込む: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/options/options.go#L454-L462
- 有効にするmetricsの設定など: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/options/options.go#L463
- feature gateで有効化されたmetrics情報を追加? TODO: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L144-L145
- Runの実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L146
Run
- eventbroadcastの出力にklogのstructured loggingを追加: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L193-L196
- configz(
/configzエンドポイントでconfig情報を公開するやつ)に起動するkube-controller-managerのconig情報を設定 - 下記のエンドポイントを持ったHTTP Serverを起動: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L204-L226
-
/healthz: ヘルスチェック用エンドポイント -
/debug: デバッグ用のエンドポイント -
/configz: config情報取得用エンドポイント -
/metrics: メトリクス情報取得エンドポイント - 関連コード
- leader election関連チェックを設定したhealth checkerを設定したhealthcheckエンドポイントを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L204-L211
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/controller-manager/pkg/healthz/handler.go#L49-L68
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/server/healthz/healthz.go#L129-L135
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/server/healthz/healthz.go#L159-L166
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/server/healthz/healthz.go#L168-L193
- healthcheckを含めた各種エンドポイントを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L217-L220
- HTTP Serverに認証/認可などを追加: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L221
- leader election関連チェックを設定したhealth checkerを設定したhealthcheckエンドポイントを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L204-L211
-
- client builder(clientsetやclient configを返してくれるやつ)を生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L228
- leader electionを使わない場合は
runを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L251-L255 - leader migratorが有効な場合にleader migratorを使用する設定を差し込む: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L265-L284
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/controller-manager/pkg/leadermigration/migrator.go#L41-L61
- ざっと見た感じ下記のような感じ
- controller managerでは
serviceaccount-token-controllerの初期実行を待機してから実行するcontrollerとそうでないcontrollerがある - leader migratorを使用することで、
serviceaccount-token-controllerの初期実行を待機してから実行するcontroller群とそうでないcontroller群を分割して、controllerの開始タイミングを分けることができる
- controller managerでは
- leader electionを挟んで
runを実行する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L286-L305- leader electionが有効な場合は、
serviceaccount-token-controllerの初期実行を待機する必要のないcontroller群だけ実行するようにする -
leaderElectAndRun: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L740-L769
- leader electionが有効な場合は、
- leader electionが有効な場合は、
serviceaccount-token-controllerの初期実行を待機する必要のあるcontroller群を実行するようにする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L307-L330 - stopされた場合の終了処理: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L332-L333
run
-
ControllerContextを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L233-L237- clientとinformerを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L527-L531
- api serverの起動確認まで待機: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L533-L537
- discovery clientの生成と定期的なrefresh処理を開始: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L539-L545
- 使用可能なリソース(GVR)一覧を取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L547-L550
- cloud controller群向けcloud providerを生成(組み込みcloud providerを使用する場合): https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L552-L556
-
ControllerContextを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L558-L570 -
running_managed_controllersという起動しているcontroller数のメトリクスを登録 : https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L571
- 起動するcontroller一覧を取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L238
- controller群を起動: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L239-L242
-
serviceaccount-token-controllerがあれば実行してserviceaccount-token-controllerを起動 : https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L580-L586 - cloud controller群向け初期化処理(組み込みcloud providerを使用する場合): https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L588-L592
- controller群を起動: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L594-L645
- disableなcontrollerの起動をskipする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L606-L609
- 設定したinterval分次のcontrollerの起動を待機する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L611
- controllerを起動: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L613-L622
- controllerのdebug用ハンドラーを追加(debugは有効な場合): https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L624-L633
- controller独自のhealth checkerがある場合は独自checkerに差し替え: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L634-L639
- 各controllerのhealth check handlerを追加: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L640-L645
-
- informerを起動: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L244-L245
- 終了待機: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L248C15-L248C15
デフォルトで起動されるcontroller一覧
デフォルトでdisable
- bootstrap-signer-controller
- token-cleaner-controller
cloud controllerが実行される設定だった場合
- service-lb-controller
- node-route-controller
- cloud-node-lifecycle-controller
feature gateの設定によって起動するか否かが変わるcontroller
- storageversion-garbage-collector-controller: APIServerIdentity(デフォルト無効)とStorageVersionAPI(デフォルト無効)が両方有効な場合
- resourceclaim-controller: LegacyServiceAccountTokenCleanUp(デフォルト無効)が有効な場合
- validatingadmissionpolicy-status-controller: ValidatingAdmissionPolicy(デフォルト無効)が有効な場合
デフォルト値はv1.28.2時点のもの
一部controller群起動の前に起動されるcontroller
- serviceaccount-token-controller
その他デフォルト有効なcontroller
- endpoints-controller
- endpointslice-controller
- endpointslice-mirroring-controller
- replicationcontroller-controller
- pod-garbage-collector-controller
- resourcequota-controller
- namespace-controller
- serviceaccount-controller
- garbage-collector-controller
- daemonset-controller
- job-controller
- deployment-controller
- replicaset-controller
- horizontal-pod-autoscaler-controller
- disruption-controller
- statefulset-controller
- cronjob-controller
- certificatesigningrequest-signing-controller
- certificatesigningrequest-approving-controller
- certificatesigningrequest-cleaner-controller
- ttl-controller
- node-ipam-controller
- node-lifecycle-controller
- persistentvolume-binder-controller
- persistentvolume-attach-detach-controller
- persistentvolume-expander-controller
- clusterrole-aggregation-controller
- persistentvolumeclaim-protection-controller
- persistentvolume-protection-controller
- ttl-after-finished-controller
- root-ca-certificate-publisher-controller
- ephemeral-volume-controller
serviceaccount-token-controller
内容について
serviceaccount-token-controllerは下記のような処理を行う
- service accountに紐づくtoken(secret)の管理を行う
- tokenに紐づくservice accountがなければtokenの削除を行い
- service accountに紐づくtokenを必要に応じて生成して更新する
このcontrollerで更新されるリソース
- secrets(
Typeが "kubernetes.io/service-account-token" のもの): tokenが更新される - service account:
.Sercret(ObjectReference) が更新される
このcontrollerに関連するリソース
- secrets(
Typeが "kubernetes.io/service-account-token" のもの) - service account
起動処理
startServiceAccountTokenController
serviceaccount-token-controllerは他のcontrollerより先に起動されるため startServiceAccountTokenController によって起動される
- disableだったらskipする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L659-L662
- 秘密鍵がない場合は起動しない: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L664-L667
- 秘密鍵を取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L668-L671
- 既存のroot CAファイルを読み込むか、client config情報から生成する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L673-L680
- controllerの生成と起動を実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L682-L698
- informerFactoryを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L700-L701
Run
- informer cacheの同期完了まで待機: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L165-L167
-
syncServiceAccountの定期実行を開始(interval無し→終了したらすぐ次を実行) -
syncSecretの定期実行を開始(interval無し→終了したらすぐ次を実行)
syncServiceAccount
- service accountの取得処理: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L221-L239
- もしtokenに紐づくservice accountがすでに存在しない場合はtokenを削除する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L244-L252
syncServiceAccountはServiceAccountsリソースを変換したデータを元に呼び出される
event handler周りの設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L89-L98
- queueへの追加処理:
https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L179-L183 - リソース変換処理: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L574-L580
- 変換されるstruct: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L565-L572
syncSecret
- secretの取得処理: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L256-L279
- secretが存在しない場合
- 紐づくservice accountが存在する場合は、service accountに紐づけたsercret情報を削除する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L280-L289
- secretが存在する場合
- 紐づくservice accountを取得を試みる: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L291-L296
- 紐づくservice accountが存在しない場合、secret(token)の削除を行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L297-L303
- 紐づくservice accountが存在する場合、必要に応じてtokenを生成してsecretをアップデートする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L304-L310
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L361-L428
- token generatorの生成処理はこちら: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/serviceaccount/jwt.go#L58-L87
- token自体の生成処理はこちら: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/serviceaccount/jwt.go#L213-L222
syncSecretはSecretsリソースを変換したデータを元に呼び出される
- event handler周りの設定(
Typeが "kubernetes.io/service-account-token" のものにfilterされる): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L100-L121 - queueへの追加処理: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L208-L218
- リソース変換処理: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L602-L610
- 変換されるstruct:
https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/tokens_controller.go#L590-L600
serviceaccount-controller
内容について
serviceaccount-controllerは下記のような処理を行う
- 作成されたNamespaceに"default" ServiceAccountを作成する
- "default" ServiceAccountが削除された場合に再作成を行う
このcontrollerで更新されるリソース
- ServiceAccount
このcontrollerに関連するリソース
- ServiceAccount
- Namespace
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L467-L479
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L64-L87
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L106-L123
startServiceAccountController
- NewServiceAccountsControllerでcontrollerを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L468C39-L476
- Runを実行 https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L477
NewServiceAccountsController
- ServiceAccountsControllerを生成 : https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L65-L69
- ServiceAccount削除をフックするハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L71C2-L75
- Namespaceのハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L77-L84
ServiceAccount削除をフックするハンドラー(serviceAccountDeleted)
cache.DeletedFinalStateUnknown関連がよくわからないけど受け取ったObjectがServiceAccount相当のObjectであればQueueに対象ServiceAccountのNamespaceを追加するという処理のよう
Namespaceのハンドラー
namespaceAdded
追加されたNamespaceをQueueに加える
namespaceUpdated
更新されたNamespaceをQueueに加える
Run
- wait.UntilWithContextでworkerを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L118-L120
runWorker ~ processNextWorkItem ~ syncHandler(syncNamespace)
- processNextWorkItemを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L155-L158
- c.queueに対してc.syncHandler(syncNamespace)を実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L160-L178
syncNamespace
- syncNamespaceの処理対象リソースはNamespace: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L185
- NamespaceがActiveでなければ処理はしない: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L192-L195
- 対象Namespace内に
c.serviceAccountsToEnsureのリストのServiceAccountの内、存在しないServiceAccountが存在すれば作成を行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L197-L216
serviceAccountsToEnsure
c.serviceAccountsToEnsureは常に"default"のみとなる
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L67
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L472
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/serviceaccount/serviceaccounts_controller.go#L54-L61
clusterrole-aggregation-controller
内容について
clusterrole-aggregation-controllerは下記のような処理を行う
名前の通りClusterRoleにはClusterRole.AggregationRuleという他のClusterRoleのRuleを自身に取り組む設定があるらしい。
具体的には ClusterRole.AggregationRule.ClusterRoleSelectors のラベルルールにマッチするClusterRoleの各種Ruleを取り込むように対象ClusterRoleのRuleの更新を行う。
ClusterRole.AggregationRuleに関するドキュメントが一切見つからないんだけどなんで?
このcontrollerで更新されるリソース
- ClusterRole
このcontrollerに関連するリソース
- ClusterRole
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/rbac.go#L27-L36
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/clusterroleaggregation/clusterroleaggregation_controller.go#L54-L77
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/clusterroleaggregation/clusterroleaggregation_controller.go#L183-L201
startClusterRoleAggregrationController
- clusterrolesが利用できないクラスターであればコントローラーは起動しない: https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/rbac.go#L28-L30
- NewClusterRoleAggregation ~ Runでコントローラーを起動する https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/rbac.go#L31-L34
controllerContext.AvailableResources
AvailableResourcesはdiscovery APIから利用可能なリソース種別を取得して生成される
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L547
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/controllermanager.go#L494-L521
NewClusterRoleAggregation
- ClusterRoleAggregationControllerを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/clusterroleaggregation/clusterroleaggregation_controller.go#L56-L62
- ハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/clusterroleaggregation/clusterroleaggregation_controller.go#L65-L75
enqueue(ハンドラーで呼び出されるやつ)
clusterRole.AggregationRule != nil なすべてClusterRoleがqueueに入れられる
Run
- wait.UntilWithContextでrunWorkerを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/clusterroleaggregation/clusterroleaggregation_controller.go#L197
runWorker ~ processNextWorkItem ~ syncHandler
- runWorkerでprocessNextWorkItemを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/clusterroleaggregation/clusterroleaggregation_controller.go#L203C44-L206
- processNextWorkItemでsyncHandlerを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/clusterroleaggregation/clusterroleaggregation_controller.go#L208C44-L225
syncHandler(syncClusterRole)
ClusterRole.AggregationRule.ClusterRoleSelectorsのラベルセレクタールールにマッチするClusterRole一覧を取得して、それらのClusterRoleのRule(権限設定)を取り込んだRuleを対象ClusterRoleに設定する
applyClusterRoles
ClusterRoleのserver side applyの実行
updateClusterRoles
ClusterRoleのupdateの実行(server side apply)が有効でない場合
namespace-controller
内容について
namespace-controllerは下記のような処理を行う
- 対象Namespaceの
Namespace.Spec.Finalizersが空では無く、またnamespace.DeletionTimestampが空のときに限定して処理が実行される - Namespaceの削除時に対象NamespaceのNamespacedなリソースのすべてを削除する(ただしDelete APIのあるものに限定)
- 削除を試みた結果finalizerやその他の影響で削除できないリソースがあった場合はrequeueされ、再度削除が試みられる
- 全リソース削除ができなかったリソースにPodが含まれる場合、Podのgraceful shutdownの設定に応じてrequeueの時間が調整されるよう(estimate)
- 対象Namespaceの
Namespace.Spec.Finalizersからnamespace-controllerのfinalizerを取り除く
上記のようにNamespaceに紐づくリソースが(ほぼ)完全に削除されるまで処理を繰り返すコントローラーとなっているよう
TODO
このコントローラーの外側でNamespace.Spec.Finalizersがどのように設定されるのかがわからないとこのコントローラーの全体像を理解するのが難しそう
このcontrollerで更新されるリソース
NamespaceとすべてのNamespacedリソース
このcontrollerに関連するリソース
NamespaceとすべてのNamespacedリソース
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L433-L442
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L444C6-L465
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/namespace_controller.go#L65C1-L99
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/namespace_controller.go#L192-L209
startNamespaceController
startModifiedNamespaceControllerに渡すパラメータ調整などを行いつつstartModifiedNamespaceControllerを実行
startModifiedNamespaceController
NewNamespaceControllerでcontrollerを生成~Runで起動
NewNamespaceController
NamespaceControllerを生成してイベントハンドラーを設定
イベントハンドラーはAdd/Updateイベントに対してNamespaceをenqueueしてるだけ
Run
wait.UntilWithContext(ctx, nm.worker, time.Second)を実行してる
worker
queueがあれば、syncNamespaceFromKeyを調整ループとして実行
ResourcesRemainingErrorが発生した場合はestimate時間に応じたrequeueを行う
syncNamespaceFromKey
対象Namespaceが存在していればnm.namespacedResourcesDeleter.Deleteを実行する
namespacedResourcesDeleter.Delete
namespacedResourcesDeleterの設定
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/namespace_controller.go#L78
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L45C1-L62
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L156-L192
namespacedResourcesDeleter.Delete
- 対象Namespaceがnamespace.DeletionTimestamp != nilだった場合に実行する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L97-L111
- 再度対象Namespaceがnamespace.DeletionTimestamp != nilであることを確認: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L123-L126
- finalizerが0個であれば何もしない(namespace_controller自身のfinalizerなどが設定されているはずだから、そのfinalizerが無いということはすでに削除処理を実行済みだから何もしない、ということだと思われる): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L128-L131
- deleteAllContentを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L133-L137
- エラー処理: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L135-L137
- 削除できなかったコンテンツがあればその旨を推定削除時間とともに報告: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L138-L140
- NamespaceのFinalizerからnamespacedResourcesDeleterのfinalizerを取り除いてアップデートする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L142-L152
updateNamespaceStatusFunc
- NamespaceのステータスがTerminatingの場合ならreturnする(この関数の実行前にnamespace.DeletionTimestamp != nilであることが保証されているため): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L268-L270
- ステータスがTerminatingでなければTerminatingにアップデートする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L271-L273
deleteAllContent
- resources種別の一覧を取得 https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L511-L516
- resource一覧からdelete可能なリソースのみをフィルタリング: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L517-L524
- 対象種別のリソースの削除処理を実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L526-L551
- deleteAllContentForGroupVersionResourceを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L531
- エラーが発生したらその旨をレポート: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L532-L537
- 必要に応じてestimateとnumRemainingTotalsの情報を更新: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L538-L549
- 結果を報告: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L551
- 削除処理の結果Namespaceのステータスに変更があった場合は更新を行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L553-L560
- エラーとestimateをreturn: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L562-L565
deleteAllContentForGroupVersionResource
- DeleteCollectionを使用して対象Namespace内の対象リソース一覧を削除する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L427-L431
- DeleteCollectionがサポートされていない場合は1件ずつ削除する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L433-L439
- 全件削除されたのを確認したら正常に完了したとしてreturn: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L441-L456
- 削除できなかったアイテムのfinalizerの数を数える: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L458-L464
- 削除完了の見積もりが残っていればその旨をreturnする TODO estimateについて: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L466-L473
- 削除できなかったアイテムの一覧をreturnする: TODO finalizersToNumRemainingの利用について: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L475-L483
- 予期せぬエラーの報告を行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/namespace/deletion/namespaced_resources_deleter.go#L485-L490
resourcequota-controller
内容について
resourcequota-controllerは下記のような処理を行う
仕組みとしては複雑なんだけど、やってることとしてはResourceQuotaで設定されたQuotaの設定項目と、その対象となるリソースの使用量をResourceQuota.Statusに保存して、現在のリソース使用量を保存する、ということをやっている
これを実現するためにおおまかに言うと下記のようなことをやっている
- 現在の各種ResourceQuotaの設定を取得
- 各種ResourceQuotaの設定に基づき、QuotaMonitorというQuotaを監視するモニターを管理するマネージャーがMonitorと呼ばれる対象リソースを監視するcontrollerのようなものを起動(リソース別にgo routineを実行している感じ)
- 各Monitorを通してリソースの変更が行われたものを取得して、対象リソース(+Namespace)に関連するResourceQuotaをqueueに追加
- resourcequota-controller側の調整ループにより、ResourceQuotaで設定されたQuotaの設定項目と、その対象となるリソースの使用量をResourceQuota.Statusに保存して、現在のリソース使用量を保存する
その他ResourceQuotaを定期的に全件requeueしたりなどもしているが最終的にはこんな感じのことをやっている
TODO: これだけだとResourceQuotaのStatusを更新しているだけなので、おそらくkube-api-server側の組み込みAdmission ControllerでResourceQuotaの仕様状況によるValidationを行うものが入るのではないか?
↓
多分このQuotaAdmissionがやってる
このcontrollerで更新されるリソース
- ResourceQuota
このcontrollerに関連するリソース
- ResourceQuota
- ResourceQuotaで設定された監視対象となるリソース
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L402-L431
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L105-L186
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L287-L318
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L433-L495
startResourceQuotaController
ResourceQuotaControllerの生成とRun/Syncの実行を行う
NewController
- ResourceQuotaに紐づくハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L122-L151
- quotaMonitorを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L154-L165
- Quotableなリソース("create", "list", "watch", "delete"のAPIが全てあるリソース)種別の一覧を取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L167-L173
- SyncMonitorsを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L175-L177
Run
- quotaMonitor.Runを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L298-L300
- rq.worker(rq.queue)とrq.worker(rq.missingUsageQueue)を実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L306-L310
- rq.enqueueAllを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L311-L316
quotaMonitor.Run
- runningステータスを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L294-L298
- StartMonitorsを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L300-L302
- QuotaMonitorの終了処理をdeferで設定?: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L304-L311
- wait.UntilWithContextで qm.runProcessResourceChangesを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L312
- 終了処理(の一部を実行): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L314-L325
runProcessResourceChanges ~ processResourceChanges
- processResourceChangesを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L328-L331
- qm.resourceChangesというqueueからアイテムを取り出しqm.replenishmentFuncを実行する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L333-L360
qm.replenishmentFunc
- replenishmentFuncを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L160
- 引数のgroupResourceに対応するevaluator(TODO これ何?)を取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L400-L404
- 対象のNamespaceに設定されたResourceQuotasを全件取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L406-L418
- 各ResourceQuotasの中でevaluatorにマッチするリソース設定を含むResourceQuotasをcontrollerのqueueに追加: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L422-L430
worker
要約すると、渡されたworkqueueを使ってrq.syncHandlerを実行している
rq.syncHandler ~ syncResourceQuota
- rq.syncHandlerを設定してる: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L117-L118
- syncResourceQuotaを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L320-L345
- 対象となるResourceQuotaに設定された各種使用量を計算 ~ ResourceQuotaのStatusに設定する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L347-L396
enqueueAll
- ResourceQuota全件をqueueに入れる: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L188-L205
Sync
- wait.UntilWithContextを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L437
- resource quotaに関連する差分チェック: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L438-L460
- resyncMonitorsを実行してキャッシュの同期を待機: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L462-L493
resyncMonitors
- rq.quotaMonitor.SyncMonitorsを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L534-L536
- rq.quotaMonitor.StartMonitors(ctx)を実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L537
StartMonitors
- 実行中なら何もしない: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L239-L241
- informer開始まで待機: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L243-L245
- 各リソースのハンドラーを設定した低レベルcontrollerを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L247-L256
SyncMonitors
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_controller.go#L154-L165
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L167-L228
以下処理の流れ
- 引数で渡した各リソース種別に対して処理を実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L187
- 除外リソースであればスキップ: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L188-L196
- 対象リソースのイベントハンドラーを設定(qm.controllerFor): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L197-L201
- QuotaMonitorのregistryに登録: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L203-L211
- リソース向けハンドラーを設定した際の取得したcontroller(TODO これ何?)を保存: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L213-L215
- 終了するモニターの終了処理: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourcequota/resource_quota_monitor.go#L219-L223
QuotaMonitorのregistry
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L418
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/quota/v1/generic/registry.go#L34-L38
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/quota/v1/generic/registry.go#L65-L72
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/quota/v1/install/registry.go#L36-L39
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/quota/v1/evaluator/core/registry.go#L36-L49
controllerFor
対象リソースのハンドラーを設定して、ハンドラー内でqm.resourceChanges というworkqueueにaddする
endpoints-controller
内容について
endpoints-controllerは下記のような処理を行う
Serviceと紐づくPodに基づいてEndpointsリソースを生成する
また、ExternalName以外のServiceについてはSelectorが有る限りはEndpointsが作成されるようだった(多分)
このcontrollerで更新されるリソース
- Endpoints
このcontrollerに関連するリソース
- Endpoints
- Service
- Pod
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L369-L378
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L72C1-L115
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L161-L191
startEndpointController
New ~ Run実行
NewEndpointController
- Serviceのイベントハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L84-L92
- Podのイベントハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L94-L100
- Endpointsのイベントハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L102-L106
onServiceUpdate
queueにServiceを追加
onServiceDelete
queueにServiceを追加
addPod
Podに紐づくService一覧をqueueに追加
endpointsliceutil.GetPodServiceMemberships
Podに紐づくService一覧を取得
updatePod
Podに変更によって影響を受ける可能性のあるService一覧をqueueに追加
endpointsliceutil.GetServicesToUpdateOnPodChange
Podに変更によって影響を受ける可能性のあるService一覧を取得
deletePod
Podに紐づくService一覧をqueueに追加
endpointsliceutil.GetPodFromDeleteAction
Pod情報が取得できれば取得したものを返す
onEndpointsDelete
queueにEndpointsを追加
Run
- go wait.UntilWithContext(ctx, e.worker, e.workerLoopPeriod)を実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L181-L183
- e.checkLeftoverEndpoints()を実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L185-L188
worker ~ processNextWorkItem ~ syncService
- processNextWorkItemを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L310-L317
- syncServiceを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L327
- Serviceを取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L366
- Serviceが見つからない場合は、紐づくEndpointsを削除 https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L367-L383
- ExternalNameの場合は何もしない: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L385-L389
- Selectorが設定されてなければ何もしない: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L391-L395
- Pod一覧を取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L398-L403
- Pod一覧とServiceを元にEndpoints.Subnetsを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L411-L457
- Endpointsが不要なPodであれば生成をスキップ: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L416-L419
- PodとServiceを元にEndpointAddressを生成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L421-L432
- subsets(Endpoints.Subnetsの元データ)にHeadless Service向けのデータを追加: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L434-L439
- 非Headless Service向けのデータはService.Spec.Ports別にデータを追加: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L441-L454
- subsetsを元にEndpoints.Subnetsを生成 : https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L457
- 既存のEndpointsとの比較を行い、差分がなければスキップする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L459-L492
- AnnotationとLabelを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L493-L521
- Endpointsの作成 or 更新を行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpoint/endpoints_controller.go#L523-L553
checkLeftoverEndpoints
Endpointsに対応するサービスの削除を行うため、control planeのEndpointsを除く?Endpoints一覧をqueueに入れる
endpointslice-controller
内容について
endpointslice-controllerは下記のような処理を行う
TODO 全部読んでないので間違いがあるかも
Endpointsと大体同じでExternalName以外のServiceに紐づくEndpointSliceを生成するっぽい
ただNodeのTopologyAwareHintsの利用は明確に新機能っぽい
このcontrollerで更新されるリソース
TODO 全部読んでないので他にもあるかも
- EndpointSlice
このcontrollerに関連するリソース
- EndpointSlice
- Service
- Pod
- Node
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/discovery.go#L30-L42
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L80-L181
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L252-L277
startEndpointSliceController
controllerの起動してるだけ
NewController
- Serviceのイベントハンドラー設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L111-L119
- Podのイベントハンドラー設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L121-L127
- EndpointSliceのイベントハンドラー設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L133-L139
- TopologyAwareHints featuregateが有効であればNodeのイベントハンドラー設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L154-L168
- Reconcilerを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L170-L178
イベントハンドラーはNodeの以外はだいたいEndpointsControllerと同じような感じだったのでスキップ
addNode
- checkNodeTopologyDistributionを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L528-L530
updateNode
- 必要に応じてcheckNodeTopologyDistributionを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L532-L542
deleteNode
- checkNodeTopologyDistributionを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L544-L546
checkNodeTopologyDistribution
TODO reconcile読まないとわからない
Run
worker ~ processNextWorkItem ~ syncService
- processNextWorkItemの実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L279-L286
- syncServiceの実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L288-L299
- serviceを取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L331
- serviceが存在しない場合はキャッシュデータの調整?を実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L332-L342
- 紐づくpod一覧を取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L358-L366
- 紐づくEndpointSlices一覧を取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L368-L380
- 削除中のEndpointSlicesを除外する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L382-L383
- EndpointSliceのキャッシュが古い場合はエラーを返す: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslice/endpointslice_controller.go#L385-L387
TODO なんやかんやあってReconcileのfinalizerでEndpointSliceを生成してるんだけど、ちょっと工程がめんどくさすぎるので後回し
endpointslice-mirroring-controller
内容について
endpointslice-mirroring-controllerは下記のような処理を行う
TODO ちゃんと読んでない
このcontrollerで更新されるリソース
- EndpointSlice
このcontrollerに関連するリソース
- EndpointSlice
- Endpoints
- Service
- Pod
- Node
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/discovery.go#L44-L55
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslicemirroring/endpointslicemirroring_controller.go#L71-L150
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslicemirroring/endpointslicemirroring_controller.go#L211-L236
startEndpointSliceMirroringController
controller起動してるだけ
NewController
- Endpointsのイベントハンドラー設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslicemirroring/endpointslicemirroring_controller.go#L100-L112
- EndpointSliceのイベントハンドラー設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslicemirroring/endpointslicemirroring_controller.go#L114-L124
- Serviceのイベントハンドラー設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/endpointslicemirroring/endpointslicemirroring_controller.go#L126-L132
Run
worker ~ processNextWorkItem ~ syncEndpoints
最終的にendpointslice-controllerと同じreconcilerのメソッド呼び出してEndpointSlices作ってるだけっぽいのでスキップ
deployment-controller
内容について
deployment-controllerは下記のような処理を行う
Deploymentに応じたReplicaSetの作成と更新を行う。
また、ReplicaSetの状況をDeploymentのステータスなどに反映を行う。
DeploymentのRollingUpdateによる徐々に新しいPodの台数を増やす形でデプロイするといった機能もこのDeploymentコントローラーで実現している。
このcontrollerで更新されるリソース
- Deployment
- ReplicaSet
このcontrollerに関連するリソース
- Deployment
- ReplicaSet
- Pod
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/apps.go#L76-L89
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L101-L154
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L156-L180
startDeploymentController
controllerを実行
NewDeploymentController
- Deploymentリソースのイベントハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L115-L126
- ReplicaSetリソースのイベントハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L127-L137
- Podリソースのイベントハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L138-L142
addDeployment
Deploymentをenqueue
updateDeployment
Deploymentをenqueue
deleteDeployment
Deploymentをenqueue
addReplicaSet
ReplicaSetからDeploymentを取得してenqueue
updateReplicaSet
ReplicaSetからDeploymentを取得してenqueue
deleteReplicaSet
ReplicaSetからDeploymentを取得してenqueue
deletePod
PodからReplicaSet ~ Deploymentを取得してenqueue
enqueue(enqueueDeployment)
enqueueする
Run
workerを実行
worker ~ processNextWorkItem ~ syncHandler(syncDeployment)
- processNextWorkItemを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L471-L476
- syncHandlerを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L478-L489
- DeploymentのSelectorをバリデーション: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L608-L616
- 紐づくReplicaSetとPodを取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L618-L632
- Deploymentが削除中ならDeployment(+ReplicaSet)のステータスのみをアップデート: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L634-L636
- DeploymentのStatus.Conditions[x].Type == "Progressing"をチェックして、Spec.Paused: trueなのにPause ConditionでなければPause Conditionに変更して、 Spec.Paused: falseなのにPause ConditionだったらPause Conditionを変更する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L638-L643
- Spec.Paused: trueならsyncを実行する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L645-L647
- "deprecated.deployment.rollback.to" Annotationでロールバック情報が設定されていた場合はrollbackを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L649-L654
- 紐づくReplicaSetがあった場合、そのReplicaSetの"deployment.kubernetes.io/desired-replicas" AnnotationがDeploymentのSpec.Replicaと一致しない場合はsyncを実行する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L656-L662
- Spec.Strategy.Type == "Recreate"ならrolloutRecreateを実行する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L665-L666
- Spec.Strategy.Type == "RollingUpdate"ならrolloutRollingを実行する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/deployment_controller.go#L667-L668
rolloutRolling
- 必要に応じたReplicaSet/Deploymentの作成や更新を行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L33-L37
- scale up/outの必要性を判断して、RollingUpの状況を加味しつつ必要に応じてReplicaSetに新たなreplica数を設定する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L39-L43
- RollingUpdateの状況を含め、現在の状況をDeploymentにフィードバックする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L44-L47
- 古いReplicaSetのscale downを実施: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L49-L53
- 現在の状況をDeploymentにフィードバックする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L54-L57
- DeploymentのRollingUpdateなどが完了していたら、DeploymentのSpec.RevisionHistoryLimitを超える処理が完了した古いReplicaSetを削除する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L59-L63
- 現在の状況をDeploymentにフィードバックする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L65-L66
reconcileNewReplicaSet
- replica数が同じなら何もしない: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L70-L73
- scale downの場合はDeploymentのReplica数をReplicaSetに反映する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L74-L78
- scale upの場合、RollingUpdateの場合は古いReplicaSetの台数に応じて台数を最新のReplicaSetに反映していく: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L79-L84
NewRSNewReplicas
- RollingUpdateの場合は古いReplicaSetの台数に応じて台数を返す(RollingUpdate用の数字): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/util/deployment_util.go#L786-L803
- Recreateの場合はそのまんまDeploymentのReplica数を返す: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/util/deployment_util.go#L804-L805
reconcileOldReplicaSets
- ReplicaSet一覧でReplicaSetのSpec.ReplicasとStatus.AvailableReplicasが一致していないもの(unhealthy)をscale downする(ReplicaSetのreplica数を調整する): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L135-L140
- 古いReplicaSetをscale downする(ReplicaSetのreplica数を調整する): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/rolling.go#L143-L148
rolloutRecreate
- 古いReplicaSetのreplica数を0にアップデートして、差分があったらDeploymentに反映して終了: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/recreate.go#L38-L46
- 古いPodが稼働中であればDeploymentに状態を反映して終了: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/recreate.go#L48-L51
- 必要に応じて新しいReplicaSetを作成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/recreate.go#L53-L65
- Deployが完了してたらクリーンアップをしてDeploymentに状態を反映して終了: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/recreate.go#L67-L74
sync
Deploymentに紐づく各ReplicaSetの調整を行う
getAllReplicaSetsAndSyncRevision
- ReplicaSet一覧から最新のReplicaSetを除いた一覧を取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L117
- 必要に応じてReplicaSet/Deploymentの更新や新規ReplicaSetの作成などを行ってくれる: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/util/deployment_util.go#L628-L645
必要に応じたReplicaSet/Deploymentの作成や更新を行う
getNewReplicaSet
- DeploymentのSpec.Templateと一致する最新のReplicaSetを取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L140
- 最新以外のReplicaSet一覧から、最新のrevisionを取得(revisionはReplicaSetの"deployment.kubernetes.io/revision" Annotationから取得する) https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L142-L143
- 上記で取得した最新revision+1のrevisionを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L144-L145
- DeploymentのSpec.Templateと一致する最新のReplicaSetが存在する場合必要に応じてDeploymentやReplicaSetを更新して終了する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L147-L182
- DeploymentとReplicaSetを比較してAnnotation(ReplicaSet用に自動設定されるものを含む)かSpec.MinReadySecondsに変更があれば変更内容を保存して終了: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L154-L160
- Deploymentの"deployment.kubernetes.io/revision" AnnotationとReplicaSetのrevisionを比較して、差分があれば上書きする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L162-L163
- Spec.ProgressDeadlineSecondsが設定されていた場合、まだ "Progressing" conditionが設定されていなければ設定する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L162-L173
- 必要があればReplicaSetを更新して返す: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L175-L181
- createIfNotExistedがfalseなら新しいReplicaSetの作成は行わずに終了: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L184-L186
- 色々やってるように見えるけど、自動設定されるフィールドデータを計算などしつつReplicaSetを新たに作ってるだけ: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L188-L279
- ReplicaSet作成後、Deploymentの更新を行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/deployment/sync.go#L281-L291
replicaset-controller
内容について
replicaset-controllerは下記のような処理を行う
ReplicaSetの状態に応じたPodの作成/削除を行う。
このcontrollerで更新されるリソース
- ReplicaSet
- Pod
このcontrollerに関連するリソース
- ReplicaSet
- Pod
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/apps.go#L65-L74
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L119-L134
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L136-L199
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L201-L226
startReplicaSetController
コントローラーを起動
NewReplicaSetController
NewBaseControllerでReplicaSetControllerを生成
NewBaseController
- ReplicaSetのイベントハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L151-L177
- Podのイベントハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L179-L194
Run
- workerを起動: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L222
worker ~ processNextWorkItem ~ syncHandler(syncReplicaSet)
- processNextWorkItemを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L540C10-L540C29
- syncHandlerを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L551
- controller内のキャッシュに基づいてReplicaSetとPodの更新の必要性を判断(キャッシュはPodの更新のタイミングで更新される): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L693
- activeなPodの内、SelectorからReplicaSetに紐づくPodをフィルタリング(同時に紐づくか紐づかないかでPodのOwnerReferenceを更新): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L700-L715
- 更新内容の応じてReplicaSetのステータスを更新: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L721-L730
manageReplicas
- replica数に対してPod数が不足している場合、一定のサイズ毎に並列でPodの作成を行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L575-L616
- replica数に対してPod数が多い場合、起動中のPodを優先して並列削除を行い台数調整を行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/replicaset/replica_set.go#L618-L664
replicationcontroller-controller
内容について
replicationcontroller-controllerは下記のような処理を行う
TODO ReplicationManagerはReplicaSet Controllerを利用して処理を実行しているようなので、処理内容の差がよくわからない
このcontrollerで更新されるリソース
- ReplicaSet
- Pod
このcontrollerに関連するリソース
- ReplicaSet
- Pod
起動処理
pod-garbage-collector-controller
内容について
pod-garbage-collector-controllerは下記のような処理を行う
一定間隔で実行されて、すでに終了してるけど何らかの理由で削除されずに残っているPodを削除する
このcontrollerで更新されるリソース
- Pod
このcontrollerに関連するリソース
- Pod
- Node
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L391-L400
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podgc/gc_controller.go#L73-L76
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podgc/gc_controller.go#L78-L96
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podgc/gc_controller.go#L98-L114
startPodGCController
controllerを起動
NewPodGC
NewPodGCInternalを実行
NewPodGCInternal
PodGCControllerを生成
Run
go wait.UntilWithContext(ctx, gcc.gc, gcc.gcCheckPeriod)を実行
gc
- gcTerminated
- gcTerminating
- gcOrphaned
- gcUnscheduledTerminating
の4つの処理を全てのpodとnodeを使って実行
gcTerminated
terminatedなステータスのPodに対して、必要ならPodステータスをfailedの設定してPodを削除する
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podgc/gc_controller.go#L192-L225
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podgc/gc_controller.go#L340-L373
gcTerminating
terminatedなステータスのPodに対して、実行していたnodeを取得してnodeがnot readyかout of service状態であればPodを削除する
gcOrphaned
存在しないNodeに割り当てられているPodの"DisruptionTarget" ConditionをTrueに設定してPodを削除する
gcUnscheduledTerminating
nodeにスケジュールされてないけどDeletionTimestampが設定されている削除予定Podを削除する
daemonset-controller
内容について
daemonset-controllerは下記のような処理を行う
DaemonSetに応じて対象となる各Nodeに配置するPodを作成、管理する。
その際ControllerRevisionというリソースを使用して状態の管理を行いつつPodの作成などを行う。
このcontrollerで更新されるリソース
- DaemonSet
- ControllerRevision
- Pod
このcontrollerに関連するリソース
- DaemonSet
- ControllerRevision
- Pod
- Node
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/apps.go#L36-L51
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/daemon/daemon_controller.go#L134-L223
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/daemon/daemon_controller.go#L280-L310
startDaemonSetController
controllerを起動
NewDaemonSetsController
controllerを生成
Run
runWorker & dsc.failedPodsBackoff.GCを起動
runWorker ~ processNextWorkItem ~ syncHandler(syncDaemonSet)
- DaemonSetに紐づくControllerRevisionを取得~重複削除などを行う(存在しなければ作成する): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/daemon/daemon_controller.go#L299-L1278
- 必要に応じてDaemonSetのStatusを更新: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/daemon/daemon_controller.go#L1280-L1283
- DaemonSetのPodのデプロイなどを実行 ~ 完了したらControllerRevisionから不要なものをクリーンアップ: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/daemon/daemon_controller.go#L1285
- 再度DaemonSetのStatusを更新: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/daemon/daemon_controller.go#L1286-L1297
dsc.failedPodsBackoff.GC
DaemonSetのPodのBackOff処理に利用されるdsc.failedPodsBackoffの内、不要になったデータの削除を行う
persistentvolume-binder-controller
内容について
persistentvolume-binder-controllerは下記のような処理を行う
主にPVCとPVの紐づけ処理を行う。
場合によってはPVのプロビジョニングも行う。
このcontrollerで更新されるリソース
- PVC
- PV
このcontrollerに関連するリソース
- PVC
- PV
- StorageClass
- Pod
- Node
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L251-L277
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L79-L150
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L306-L335
ProbeControllerVolumePlugins
Probe用にVolumePlugin(普通にkubeletでVolumeの操作をするプラグイン)
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L253-L256
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/plugins.go#L87-L132
startPersistentVolumeBinderController
volume pluginを生成してcontrollerを起動
NewController
- VolumePluginを初期化: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L106-L109
- PVのイベントハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L111-L119
- PVCのイベントハンドラーを設定: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L121-L129
Run
- VolumePlugin向けのindexerにデータをキャッシュ: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L326
- resyncを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L328
- volumeWorkerを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L329
- claimWorkerを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L330
resync
volumeWorkerとclaimWorker向けのデータをenqueueする
volumeWorker
- updateVolumeを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L518
- PVが見つからない場合はキャッシュから削除 https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L526-L546
updateVolume
- cacheを更新して変更がなければ終了: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L211-L217
- syncVolumeを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L219-L228
syncVolume
- PVのAnnotationとFinalizerを設定してPVを更新する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L561-L567
- Spec.ClaimRef == nil なら VolumeのPhaseを"Available"に設定する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L569-L578
- PVCによって作成されたPVで、まだ特定のPVCに紐付けられていないもののPhaseを"Available"に設定する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L580-L591
- volumeManager内部のキャッシュストアに紐づくPVCが見つからなかった場合はcontrollerのindexerやAPI Serverから取得を行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L593-L635
- PVCが古い可能性がある場合はAPI Serverから取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L636-L655
- PVCが見つからない場合、PVが紐づくPVCが削除されたということで、Reclaim Policyに基づく削除などを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L657-L683
- PVCのSpec.VolumeNameが無い場合、PVとPVCのボリュームモードをチェックして、異なっていたら何も処理せず終了する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L684-L694
- PVがboundで、PVCがpendingのケースであればsyncClaimを実行してステップを進めるためにenqeueuして終了します: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L696-L711
- PVとPVCの紐づけが一致していればPVを"Bound"ステータスに変更して終了: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L712-L720
- それ以外の場合: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L721-L768
- PVがDynamic VolumeでReclaim Policyが"Delete"ならPhaseを"Released"に変更してReclaimを実行してボリュームを削除する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L722-L743
- そうでない場合PVをunboundする(PVのAnnotationsやSpec.ClaimRefをリセットしてPhaseを"Available"にする): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L745-L766
claimWorker
- updateClaimを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L577
- PVCがなければキャッシュから削除: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L585-L603
updateClaim
- キャッシュを更新: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L261
- syncClaimを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller_base.go#L268-L277
syncClaimを実行
- PVCのAnnotationを更新: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L254-L262
- PVCの "pv.kubernetes.io/bind-completed" Annotationの有無に合わせた処理を実行:
https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L264-L268
syncUnboundClaim
- PVCに紐づくPVがない場合、PVCの条件にマッチするPVも見つからない場合、PVCのvolume binding modeに基づいてボリュームの作成などを行う(volumeBindingMode: WaitForFirstConsumerであれば特に何もしない、CSI DriverなどexternalであればVolume作成はCSI Driverなどに任せるなど): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L334-L383
- PVCにマッチするPVが見つかる場合、PVCとPVの紐づけを行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L385-L403
- PVCに紐づくPVがキャッシュに無い場合は"Pending"ステータスに更新する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L417
- PVCに紐づくPVがキャッシュにあったけどPV側がPVCを紐づけてない場合は紐づけを行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L427-L446
- PVCとPVがすでに紐づいている場合も一応?紐づけを行う: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L448-L457
- PVCに紐づいたPVが別のPVCに紐付けられていた場合、controllerで自動で紐付けられた場合はPVCを"Pending"ステータスに変更する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/persistentvolume/pv_controller.go#L459-L478
syncBoundClaim
"pv.kubernetes.io/bind-completed" Annotationがある場合にはこちらが実行されるが、このAnnotationは1度はbind処理が実行されている場合に設定されるようなので、1度はsyncUnboundClaimがすでに実行されている状態となるよう。
なのでPVの作成依頼などはすでに行われており、PVのbindが完全に完了していないケースなどで呼び出されて"Bound"になったりしたかをチェックするためにある感じ?
persistentvolume-attach-detach-controller
内容について
persistentvolume-attach-detach-controllerは下記のような処理を行う
PVCやPV、Podなどの状態を元にPodのスケジュール対象NodeにPVのアタッチ/デタッチを行う。
アタッチ/デタッチの具体的な処理方法はVolume Pluginの実装に依存しており、例えばCSI DriverであればVolumeAttachmentの作成/削除を行い、実際のアタッチ/デタッチはCSI Driver側で行うなどをする
参考資料
このcontrollerで更新されるリソース
- AttachDetachVolume
- Node
このcontrollerに関連するリソース
- AttachDetachVolume
- Node
- PVC
- PV
- Pod
- CSINode
- CSIDriver
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L279-L313
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/attach_detach_controller.go#L107-L235
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/attach_detach_controller.go#L327-L376
startAttachDetachController
controllerを起動
NewAttachDetachController
controllerを生成
Run
- adc.reconciler.Runを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/attach_detach_controller.go#L363
- adc.desiredStateOfWorldPopulator.Runを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/attach_detach_controller.go#L364
- adc.pvcWorkerを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/attach_detach_controller.go#L365
adc.reconciler.Run(reconciliationLoopFunc)
- reconcileを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/reconciler/reconciler.go#L107-L109
- 設定に応じてsyncを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/reconciler/reconciler.go#L125
reconcile
-
actual stateとdesired stateを比較して、すでに不要なvolumeのattachがあればdetachを実行する
- detachの内容は使用されているボリューム種別に紐づくVolume Pluginに依存しており、例えばCSI DriverであればVolumeAttachmentを削除するなどを行う
- その上でactual stateとdesired stateの更新を行う
-
https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/reconciler/reconciler.go#L168-L296 -
actual stateとdesired stateを比較して、不要になったvolumeのattachを実行する
- attachの内容は使用されているボリューム種別に紐づくVolume Pluginに依存しており、例えばCSI DriverであればVolumeAttachmentを作成するなどを行う
- その上でactual stateとdesired stateの更新を行う
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/reconciler/reconciler.go#L298
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/reconciler/reconciler.go#L307-L360
- 更新内容に応じてNodeの Status.VolumesAttached の更新を行う
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/reconciler/reconciler.go#L300-L304
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/statusupdater/node_status_updater.go#L61-L76
sync
adc.desiredStateOfWorldPopulator.Run(populatorLoopFunc)
desiredStateOfWorldPopulator内のキャッシュデータの更新を行っている感じ
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/populator/desired_state_of_world_populator.go#L95
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/populator/desired_state_of_world_populator.go#L98-L115
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/populator/desired_state_of_world_populator.go#L117-L177
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/populator/desired_state_of_world_populator.go#L179-L195
最終的にはProcessPodVolumesという関数でdesiredStateOfWorldPopulatorのキャッシュに追加/削除するを判断してる
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/populator/desired_state_of_world_populator.go#L179-L195
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/populator/desired_state_of_world_populator.go#L117-L177
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/attachdetach/util/util.go#L186-L246
adc.pvcWorker(syncPVCByKey)
desiredStateOfWorldPopulator内のキャッシュデータの更新を行っている感じ
persistentvolume-expander-controller
内容について
persistentvolume-expander-controllerは下記のような処理を行う
PVCのボリュームサイズ拡張に応じてVolume Pluginを用いて実ボリュームのリサイズを行い、その結果をPVのサイズに反映する。
なおCSI DriverについてはVolume Pluginが対応していなかったので、CSI Driverとsidecar側で勝手にやるんだと思われる。
このcontrollerで更新されるリソース
- PV
このcontrollerに関連するリソース
- PVC
- PV
起動処理
startVolumeExpandController
controllerを起動
NewExpandController
Run
runWorker(syncHandler)
- runWorker実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/expand/expand_controller.go#L336
- processNextWorkItem実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/expand/expand_controller.go#L343
- syncHandler実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/expand/expand_controller.go#L188
- volume紐づけチェック: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/expand/expand_controller.go#L223-L227
- volume拡張が必要かをチェック https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/expand/expand_controller.go#L232-L237
- in-treeの場合の処理: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/expand/expand_controller.go#L245-L269
- expandを実行 https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/expand/expand_controller.go#L286
expand
VolumePluginを用いてボリューム拡張を行い、その結果をPVに反映する
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/expand/expand_controller.go#L295-L318
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/volume/util/operationexecutor/operation_generator.go#L1652-L1659
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/volume/util/operationexecutor/operation_generator.go#L1663-L1671
persistentvolumeclaim-protection-controller
内容について
persistentvolumeclaim-protection-controllerは下記のような処理を行う
PVCに "kubernetes.io/pvc-protection" finalizerをつけて削除保護を行い、PVC削除時にPVCに紐付けられたPVを使用しているPodがあるかどうかを持ってfinalizerのON/OFFを行いPVCの削除タイミングをコントロールする。
このcontrollerで更新されるリソース
- PVC
このcontrollerに関連するリソース
- PVC
- Pod
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L534-L546
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvcprotection/pvc_protection_controller.go#L57C1-L94
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvcprotection/pvc_protection_controller.go#L96-L114
startPVCProtectionController
controllerを起動
NewPVCProtectionController
controllerを生成
Run
processPVCを実行
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvcprotection/pvc_protection_controller.go#L110
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvcprotection/pvc_protection_controller.go#L117
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvcprotection/pvc_protection_controller.go#L135
processPVC
- "kubernetes.io/pvc-protection" finalizerがある削除中PVCで、このPVCを使用しているPodがなければこのfinalizerを削除する:
https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvcprotection/pvc_protection_controller.go#L164-L175 - "kubernetes.io/pvc-protection" finalizerがない削除中ではないPVCにfinalizerを付与する: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvcprotection/pvc_protection_controller.go#L177-L183
persistentvolume-protection-controller
内容について
persistentvolume-protection-controllerは下記のような処理を行う
persistentvolumeclaim-protection-controllerのPV版
PVが"Bound"ステータスか否かに応じて"kubernetes.io/pv-protection"Annotationのつけ外しを行いPVの削除保護を行う
このcontrollerで更新されるリソース
- PV
このcontrollerに関連するリソース
- PV
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L548-L555
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvprotection/pv_protection_controller.go#L52-L70
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvprotection/pv_protection_controller.go#L72-L90
startPVProtectionController
controllerを起動
NewPVProtectionController
controllerを生成
Run
中身はpersistentvolumeclaim-protection-controllerと大体一緒
使用中の判断をPVの場合は"Bound"ステータスかどうかで判断してる
また、finalizerのキー名は"kubernetes.io/pv-protection"
- runWorker: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvprotection/pv_protection_controller.go#L86
- processNextWorkItem: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvprotection/pv_protection_controller.go#L93C8-L93C27
- processPV: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvprotection/pv_protection_controller.go#L107
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/pvprotection/pv_protection_controller.go#L119-L154
ephemeral-volume-controller
内容について
ephemeral-volume-controllerは下記のような処理を行う
Podにephemeral volumeが設定されていた場合、ephemeral volume用のPVCを作成する。
ephemeral volumeはPVCにPodのowner referenceが設定されるようなので、Pod owner referenceの有無を持ってephemeralかどうかを判断してるのかも。
このcontrollerで更新されるリソース
- PVC
このcontrollerに関連するリソース
- Pod
- PVC
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L340-L350
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/ephemeral/controller.go#L78-L116
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/ephemeral/controller.go#L165-L181
startEphemeralVolumeController
controllerを起動
Run
- runWorker: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/ephemeral/controller.go#L177
- processNextWorkItem: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/ephemeral/controller.go#L184
- syncHandler: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/ephemeral/controller.go#L195
- handleVolume: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/ephemeral/controller.go#L232
- epemeral volumeが作成済みなら何もしない(volumeが対象podのものでなければエラー報告): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/ephemeral/controller.go#L254-L261
- ephemeral volumeを作成: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/volume/ephemeral/controller.go#L263-L288
node-ipam-controller
内容について
node-ipam-controllerは下記のような処理を行う
TODO 主にCloud Controller Managerから起動されるcontrollerのようなので一旦スキップ
このcontrollerで更新されるリソース
TODO
このcontrollerに関連するリソース
TODO
前提
このコントローラーはデフォルトでは起動されない
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/cloud-provider/options/kubecloudshared.go#L65
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L104-L107
また、externalなCloud Controller Managerを利用している場合はCloud Controller Managerから起動される
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L109-L112
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/cloud-controller-manager/main.go#L62-L75
起動処理
startNodeIpamController
controllerを起動
node-lifecycle-controller
内容について
node-lifecycle-controllerは下記のような処理を行う
- Nodeのコンディション状態などが正しくkubeletによって更新されているかを確認して、更新されていなかったら更新する(kubeletが停止したりしたケースを想定してる?)
- Nodeのコンディションなどが変更された場合のPodの際スケジュールのためのPodのステータス更新や削除
といったことを行っている。
なので"NoExecute"なTaintが出た際にPodを再スケジュールさせるのはこのコントローラーのおかげのよう。
このcontrollerで更新されるリソース
- Node
- Pod
このcontrollerに関連するリソース
- Node
- Pod
前提
依然は同名のコントローラーだったものが"cloud-node-lifecycle-controller"と名前を変えたっぽい感じ?なので下記とは別物となる
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L177-L199
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/node_lifecycle_controller.go#L294-L456
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/node_lifecycle_controller.go#L458-L510
startNodeLifecycleController
controllerを起動
NewNodeLifecycleController
controllerを生成
Run
- nc.taintManager.Run https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/node_lifecycle_controller.go#L483
- nc.doNodeProcessingPassWorker: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/node_lifecycle_controller.go#L491
- nc.doPodProcessingWorker: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/node_lifecycle_controller.go#L495
- nc.doNoExecuteTaintingPass: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/node_lifecycle_controller.go#L500
- nc.monitorNodeHealth: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/node_lifecycle_controller.go#L502-L507
nc.taintManager.Run
channelという概念を使用しているが、複数のworkerを同時に実行管理するためのものだと思われる。
要約するとNodeとPodのイベントをハンドリングしており、ハンドリングするとNode内で実行しているPodがNode/Podの変更に伴い、対象PodのTolerationが対象Nodeの"NoExecute"なTaintの条件を満たしているのかの検証を行い、満たしていなければPodのステータスに"DisruptionTarget"コンディションを設定して、Podの削除を行う。
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/scheduler/taint_manager.go#L227-L245
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/scheduler/taint_manager.go#L247-L267
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/scheduler/taint_manager.go#L272
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/nodelifecycle/scheduler/taint_manager.go#L277-L308
nc.doNodeProcessingPassWorker
nc.doNodeProcessingPassWorker は2つの処理を行う
- 各Nodeの現在のコンディションやSpec.Unschedulableに応じたTaintの設定を行う
- 具体的には下記のTaintについてのつけ外しを行う
- "node.kubernetes.io/not-ready"
- "node.kubernetes.io/memory-pressure"
- "node.kubernetes.io/disk-pressure"
- "node.kubernetes.io/network-unavailable"
- "node.kubernetes.io/pid-pressure"
- "node.kubernetes.io/unschedulable"
- "kubernetes.io/os"と"kubernetes.io/arch"ラベルの設定を行う(それぞれ"beta.kubernetes.io/os"と"beta.kubernetes.io/arch"という古いラベルの値を新しいラベルにマイグレーションしてる)
nc.doPodProcessingWorker
nc.nodeHealthMapというNodeの状態キャッシュ内にあるNode.Status.Conditionsが全て"Ready"コンディションが"True"であるかを確認して、"Ready"じゃなかったりしたものがあればPodの"Ready"コンディションを"False"にする
nc.doNoExecuteTaintingPass
状況に応じて"node.kubernetes.io/not-ready"や"node.kubernetes.io/unreachable"TaintをNodeに設定するよう
nc.monitorNodeHealth
- nc.nodeHealthMapというNodeの状態キャッシュの更新
- NodeのTaintの(一部?)更新
などを行っているようだった
他のworkerでもNodeのTaintなどの制御をしてるのになんでここでもわざわざやってるのかよくわからんかった
コメントによると下記とのこと
(各コンディションはkubelet側でもチェックされるはずと思ってたのでそれは正しそうだった)
monitorNodeHealthは、ノードのヘルスがkubeletによって常に更新されていることを確認し、更新されていない場合は "NodeReady==ConditionUnknown "をポストします。
ttl-controller
内容について
ttl-controllerは下記のような処理を行う
"node.alpha.kubernetes.io/ttl" AnnotationというConfigMapやSecretの更新を行うタイミングをNodeに提案するための時間情報をNodeに設定するコントローラーのよう
なぜ"node.alpha.kubernetes.io/ttl" Annotationが必要なのかは不明
このcontrollerで更新されるリソース
- Node
このcontrollerに関連するリソース
- Node
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L481-L488
- https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/ttl/ttl_controller.go#L80-L101
- https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/ttl/ttl_controller.go#L119-L136
startTTLController
controllerを起動
NewTTLController
controllerを生成
Run
"node.alpha.kubernetes.io/ttl" AnnotationというConfigMapやSecretの更新を行うタイミングをNodeに提案するための時間情報をNodeに設定する
ttl-after-finished-controller
内容について
ttl-after-finished-controllerは下記のような処理を行う
Jobが実行が完了してからSpec.TTLSecondsAfterFinished分の時間を過ぎたJobを削除するcontroller
このcontrollerで更新されるリソース
- Job
このcontrollerに関連するリソース
- Job
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L557-L564
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/ttlafterfinished/ttlafterfinished_controller.go#L71-L101
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/ttlafterfinished/ttlafterfinished_controller.go#L103-L121
startTTLAfterFinishedController
controllerを起動
New
controllerを生成
Run
実行が完了してから一定期間を過ぎたJobを削除してる
- worker: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/ttlafterfinished/ttlafterfinished_controller.go#L117
- processNextWorkItem: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/ttlafterfinished/ttlafterfinished_controller.go#L164
- processJob: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/ttlafterfinished/ttlafterfinished_controller.go#L175
root-ca-certificate-publisher-controller
内容について
root-ca-certificate-publisher-controllerは下記のような処理を行う
各Namespaceに"kube-root-ca.crt"というConfigMapを作成して、"ca.crt"というキー名にrootCAデータを設定するcontroller
このcontrollerで更新されるリソース
- ConfigMap
このcontrollerに関連するリソース
- ConfigMap
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/certificates.go#L171-L195
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/rootcacertpublisher/publisher.go#L51-L78
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/rootcacertpublisher/publisher.go#L96-L114
startRootCACertPublisher
controllerを起動
NewPublisher
controllerを生成
Run
各Namespaceに"kube-root-ca.crt"というConfigMapを作成して、"ca.crt"というキー名にrootCAデータを設定する
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/rootcacertpublisher/publisher.go#L110
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/rootcacertpublisher/publisher.go#L154
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/rootcacertpublisher/publisher.go#L167
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/rootcacertpublisher/publisher.go#L74
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/rootcacertpublisher/publisher.go#L177-L224
certificatesigningrequest-signing-controller
内容について
certificatesigningrequest-signing-controllerは下記のような処理を行う
CertificateSigningRequestリソースが作られたら、Status.Certificateに生成した証明書データを設定する。
このcontrollerで更新されるリソース
- CertificateSigningRequest
このcontrollerに関連するリソース
- CertificateSigningRequest
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/certificates.go#L35-L91
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/signer/signer.go#L66-L74
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/signer/signer.go#L86-L110
startCSRSigningController
起動時オプションなどを確認して、必要に応じてcontrollerを起動
NewKubeAPIServerClientCSRSigningController
controllerを生成
NewCSRSigningController
Run
c.dynamicCertReloader.Runとc.certificateController.Runを実行
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/signer/signer.go#L114
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/signer/signer.go#L116
c.dynamicCertReloader.Run
ローカルの証明書ファイルとプライベートキーを監視して、変更があればそれを読み込んでCertificateSigningRequestに設定する証明書データ作成の元データを更新する。
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/signer/signer.go#L95
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/signer/signer.go#L136
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/signer/ca_provider.go#L31-L45
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/server/dynamiccertificates/dynamic_serving_content.go#L127-L146
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/server/dynamiccertificates/dynamic_serving_content.go#L200-L203
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/server/dynamiccertificates/dynamic_serving_content.go#L205-L222
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/server/dynamiccertificates/dynamic_serving_content.go#L81-L120
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/server/dynamiccertificates/dynamic_serving_content.go#L140
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/server/dynamiccertificates/dynamic_serving_content.go#L148-L179
c.certificateController.Run
CertificateSigningRequestリソースが作られたら、Status.Certificateに生成した証明書データを設定する。
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/signer/signer.go#L151-L193
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/certificate_controller.go#L109-L127
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/certificate_controller.go#L129-L133
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/certificate_controller.go#L135-L156
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/certificate_controller.go#L167-L190
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/certificate_controller.go#L71
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/signer/signer.go#L151-L193
certificatesigningrequest-approving-controller
内容について
certificatesigningrequest-approving-controllerは下記のような処理を行う
CertificateSigningRequestをチェックして、問題なければSubjectAccessReviewsを作成してCertificateSigningRequestのStatusに成功結果のコンディションを設定するcontroller
approve/denied自体はkubectlで下記のように行う
$ kubectl certificate (approve|denied) <certificate-signing-request-name>
このcontrollerで更新されるリソース
- CertificateSigningRequest
- SubjectAccessReviews
このcontrollerに関連するリソース
- CertificateSigningRequest
- SubjectAccessReviews
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/certificates.go#L151-L160
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/approver/sarapprove.go#L47-L60
startCSRApprovingController
controllerを起動
NewCSRApprovingController
controllerを生成
ベースとなるcontrollerはcertificatesigningrequest-signing-controllerと同じ
handle
handleを呼ぶ部分まではcertificatesigningrequest-signing-controllerと同じなのでスキップ
CertificateSigningRequestをチェックして、問題なければSubjectAccessReviewsを作成してCertificateSigningRequestのStatusに成功結果のコンディションを設定
certificatesigningrequest-cleaner-controller
内容について
certificatesigningrequest-cleaner-controllerは下記のような処理を行う
下記のCertificateSigningRequestを削除するcontroller
- 承認済み or 拒否済み or 証明書の発行に失敗した or 承認も拒否もされなかったもので古くなったもの
- 承認済みだけど証明書が失効したもの
このcontrollerで更新されるリソース
- CertificateSigningRequest
このcontrollerに関連するリソース
- CertificateSigningRequest
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/certificates.go#L162-L169
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/cleaner/cleaner.go#L67-L76
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/certificates/cleaner/cleaner.go#L78-L91
startCSRCleanerController
controllerを起動
NewCSRCleanerController
controllerを生成
Run
下記のCertificateSigningRequestを削除する
-
承認済み or 拒否済み or 証明書の発行に失敗した or 承認も拒否もされなかったもので古くなったもの
-
承認済みだけど証明書が失効したもの
storageversion-garbage-collector-controller
内容について
storageversion-garbage-collector-controllerは下記のような処理を行う
controller名にgarbage collectorと入っているが
- 各StorageVersionsリソースのStatus.StorageVersionsから自身のものがあれば除外する。
- 各StorageVersionsリソースのStatus.StorageVersionsから無効なものがあれば除外する。
- Status.StorageVersionsが存在しなければ、そのStorageVersionsは削除する。
といった処理を行うようなので、どちらかというと異常値なデータを除去するといった感じの処理を行うcontrollerな印象
TODO そもそもStorageVersionsリソースがどのように作られるのか?そもそもStorageVersionsリソースとは何かということを知らないとわからない部分がある
このcontrollerで更新されるリソース
- StorageVersion
このcontrollerに関連するリソース
- StorageVersion
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L701-L709
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/storageversiongc/gc_controller.go#L57-L84
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/storageversiongc/gc_controller.go#L86-L110
startStorageVersionGCController
controllerを起動
NewStorageVersionGC
Run
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/storageversiongc/gc_controller.go#L106
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/storageversiongc/gc_controller.go#L107
runLeaseWorker
各StorageVersionsリソースのStatus.StorageVersionsから自身のものがあれば除外する。
その結果Status.StorageVersionsが存在しなければ、そのStorageVersionsは削除する。
TODO そもそもStatus.StorageVersionsはどこで設定されるのかがわからない
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/storageversiongc/gc_controller.go#L117-L133
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/storageversiongc/gc_controller.go#L158-L193
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/storageversiongc/gc_controller.go#L276-L286
runStorageVersionWorker
各StorageVersionsリソースのStatus.StorageVersionsから無効なものがあれば除外する。
ここでいう無効なものというのは、各Status.StorageVersionsのAPIServerIDに一致するLeaseリソースを取得して、そのLeaseリソースの"apiserver.kubernetes.io/identity"ラベルの値が"kube-apiserver"ではなかったものを無効とみなすよう。
TODO StorageVersionsはkube-apiserverのみによって作成されるから、それ以外は無効ということ?
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/storageversiongc/gc_controller.go#L135-L138
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/storageversiongc/gc_controller.go#L140-L156
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/storageversiongc/gc_controller.go#L195-L223
resourceclaim-controller
内容について
resourceclaim-controllerは下記のような処理を行う
ResourceClaimsに関するKEP
要はCPUとメモリ(+Storageも?)以外の専用ハードウェアなど様々なリソースに対するコントローラーを行うための共通インターフェイスとしてのリソースという感じかな?
図があった
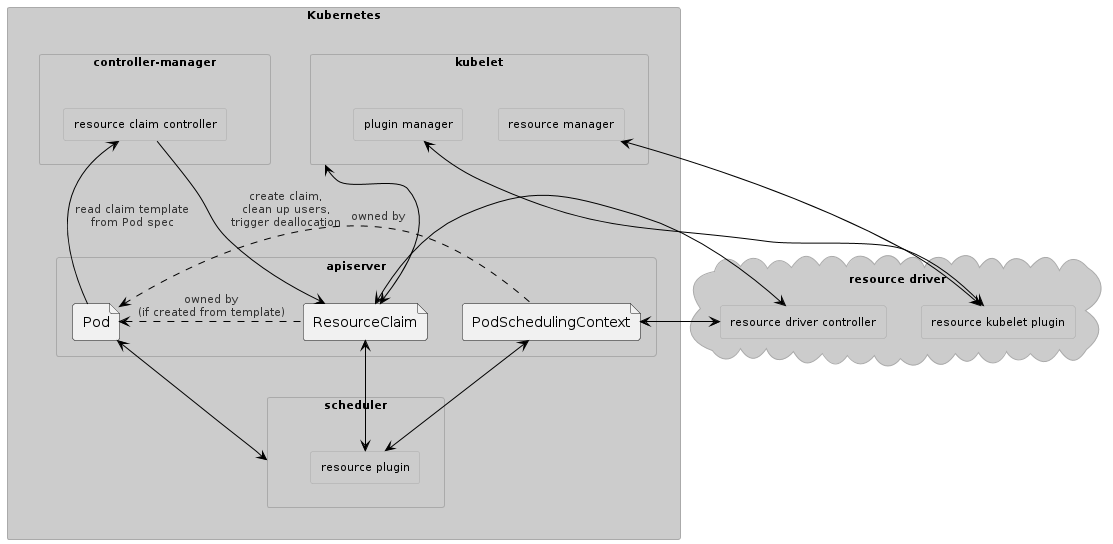
ざっくりこんな感じ?
- ResourceClaimsは紐づくdriverによって管理するリソースの要求・管理を行うリソース
- ResourceClaims.Status.ReservedFor は複数Podを紐付けられるので、driverの設定次第でこのリソースを複数Podでシェアすることが可能
- PodSchedulingContextsは(ResourceClaimsを使用する)Podが使用するNodeを紐付ける(なんでPodのnodeNameじゃない?)
- PodからResourceClaimsが作られて、driverによってResourceClaimsの実体が設定されて、schedulerでNodeが設定されたらPodSchedulingContextsが作られて、ResourceClaims.Status.ReservedForによってPodと紐付けられて、ResourceClaimsを要求するPodが無くなったらResourceClaimsを削除する、みたいな感じ?
おおまかにいうと初めっからCSI Driver方式で実装されたvolume pluginみたいなもんかな?
これ以上詳細についてはscheduler pluginとdriverのインターフェイスや実装例をみないとなんとも言えない感じかな
このcontrollerで更新されるリソース
- ResourceClaims
- PodSchedulingContexts
このcontrollerに関連するリソース
- ResourceClaims
- PodSchedulingContexts
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L354-L367
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourceclaim/controller.go#L124-L206
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourceclaim/controller.go#L389-L412
startResourceClaimController
NewController
Run
データに合わせてsyncPodかsyncClaimを実行する
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourceclaim/controller.go#L408
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourceclaim/controller.go#L414-L417
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourceclaim/controller.go#L419-L436
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/resourceclaim/controller.go#L438-L460
syncPod
主にPodのSpec.ResourceClaimsからResourceClaimを作成したり、PodSchedulingContextsを設定したりといった感じ
syncClaim
主に不要になったResourceClaimを削除したりといった感じ
validatingadmissionpolicy-status-controller
内容について
validatingadmissionpolicy-status-controllerは下記のような処理を行う
validatingadmissionはPolicyが下記のCommon Expression Language(CEL)でルールを記述することが可能になった。
このcontrollerでは、このCELの文法が正しいかをチェックするcontrollerとなっている。
バリデーションエラーになったポリシーをValidatingAdmissionPolicyのStatus.TypeChecking.ExpressionWarningsに設定するという処理を行う。
このcontrollerで更新されるリソース
- ValidatingAdmissionPolicy
このcontrollerに関連するリソース
- ValidatingAdmissionPolicy
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/validatingadmissionpolicystatus.go#L33-L51
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/validatingadmissionpolicystatus/controller.go#L69-L89
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/validatingadmissionpolicystatus/controller.go#L54-L67
startValidatingAdmissionPolicyStatusController
NewController
Run
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/validatingadmissionpolicystatus/controller.go#L63
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/validatingadmissionpolicystatus/controller.go#L102-L105
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/validatingadmissionpolicystatus/controller.go#L107-L139
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/validatingadmissionpolicystatus/controller.go#L141-L162
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/admission/plugin/validatingadmissionpolicy/typechecking.go#L101-L135
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/admission/plugin/validatingadmissionpolicy/typechecking.go#L174-L189
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/staging/src/k8s.io/apiserver/pkg/admission/plugin/validatingadmissionpolicy/typechecking.go#L217-L232
horizontal-pod-autoscaler-controller
内容について
horizontal-pod-autoscaler-controllerは下記のような処理を行う
HPAの設定に基づいて /scale サブリソースを提供しているリソースのスケールを行う。
replica数の調整方法も/scale サブリソースのエンドポイントを使用しているので、自動で色々計算して kubectl scaleを実行してる感じ。
replica数の計算方法はHPAの Spec.Metricsに設定したメトリクスデータを元に行う。
このcontrollerで更新されるリソース
このcontrollerに関連するリソース
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/autoscaling.go#L39-L45
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/autoscaling.go#L47-L66
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/autoscaling.go#L68-L97
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L127-L192
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L194-L212
startHPAController
startHPAControllerWithRESTClient
startHPAControllerWithMetricsClient
NewHorizontalController
Run
reconcileAutoscalerを実行する
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L208
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L258-L263
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L265-L290
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L502-L533
reconcileAutoscaler
- 対象GVを取得: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L763-L771
- 対象のmappingを取得(対象GVの各バージョンをまとめたやつ): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L773-L786
- HPAの対象となるリソースの
/scaleサブリソースエンドポイントからScaleリソースを取得~取得できた段階でスケール可能であるとみなす: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L788-L799 - HPAの各Spec.Metricsから最適化replica数を算出し、算出したものの中で最大のreplica数となる値を取得(めっちゃざっくり説明だけどメインはこんな感じ): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L822-L874
- 必要があれば
/scaleサブリソースエンドを使用してリソースをスケール(kubectl scaleコマンドみたいなもの): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L876-L908 - HPAのステータスを更新: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/podautoscaler/horizontal.go#L910-L916
job-controller
内容について
job-controllerは下記のような処理を行う
Jobリソースに基づいてPodを作成して、実行管理を行う
このcontrollerで更新されるリソース
- Job
- Pod
このcontrollerに関連するリソース
- Job
- Pod
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/batch.go#L31-L39
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L150-L154
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L156-L211
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L213-L240
startJobController
NewController
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L150-L154
newControllerWithClock
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L156-L211
Run
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L234
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L237
jm.worker
なんやかんやでJobリソースからPodを作成して実行管理する
TODO 長すぎるので詳細は省略
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L575-L580
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L582-L599
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L206
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L710-L935
jm.orphanWorker
"batch.kubernetes.io/job-tracking" finalizerを持つPodの内、Jobとのowner referenceが正しく設定されていないPodから"batch.kubernetes.io/job-tracking" finalizerを取り除く
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L601-L604
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L606-L621
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/job/job_controller.go#L623-L658
disruption-controller
内容について
disruption-controllerは下記のような処理を行う
PodDisruptionBudget(PDB)に紐づくPodの内
- ReplicationController
- Deployment
- ReplicaSet
- StatefulSet
- その他
/scaleサブリソースを持つリソース
上記のいずれかによって管理されているPodの件数とPDBの設定を比較して、起動する必要のあるPod情報などを計算してPDBのステータスに保存するcontroller
その際、上記によって管理されていないPodについては除外して計算される
TODO 周辺の"DisruptionTarget"コンディションの扱いについて知らないと適切な理解ができなさそう
このcontrollerで更新されるリソース
- PodDisruptionBudget
- Pod
このcontrollerに関連するリソース
- PodDisruptionBudget
- Pod
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/policy.go#L31-L54
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L136-L163
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L165-L242
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L431-L460
startDisruptionController
NewDisruptionController
NewDisruptionControllerInternal
Run
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L455
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L456
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L457
worker
PodDisruptionBudget(PDB)に紐づくPodの内
- ReplicationController
- Deployment
- ReplicaSet
- StatefulSet
- その他
/scaleサブリソースを持つリソース
上記のいずれかによって管理されているPodの件数とPDBの設定を比較して、起動する必要のあるPod情報などを計算してPDBのステータスに保存する
その際、上記によって管理されていないPodについては除外して計算される
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L612-L615
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L617-L634
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L672-L704
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L706-L743
recheckWorker
worker用のqueueをenqueueするだけ
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L636-L639
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L641-L649
stalePodDisruptionWorker
"DisruptionTarget"コンディションが"True"に設定されたPodの内、一定時間以上を経過したPodの"DisruptionTarget"コンディションを"False"に設定する、という感じ?
つまりPDBを待たずに終了する対象にする的な感じ?
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L651-L654
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L656-L670
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/disruption/disruption.go#L745-L787
cronjob-controller
内容について
cronjob-controllerは下記のような処理を行う
CronJobリソース設定に基づくJobリソースの作成とcron式から次回の実行時間を計算してenqueするcontroller
なのでcron式に対応した定期処理の実行はworkqueueのenqueueによって実現されていたことになる
このcontrollerで更新されるリソース
- CronJob
- Job
このcontrollerに関連するリソース
- CronJob
- Job
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/batch.go#L41-L52
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/cronjob/cronjob_controllerv2.go#L82-L125
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/cronjob/cronjob_controllerv2.go#L127-L151
startCronJobController
NewControllerV2
Run
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/cronjob/cronjob_controllerv2.go#L147
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/cronjob/cronjob_controllerv2.go#L153-L156
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/cronjob/cronjob_controllerv2.go#L165
- cronjobに紐づくjobを抽出: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/cronjob/cronjob_controllerv2.go#L194-L197
- 成功したJobと失敗したJobを削除: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/cronjob/cronjob_controllerv2.go#L203
- Jobリソースの作成とcron式から次回の実行時間を計算してenqueueする: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/cronjob/cronjob_controllerv2.go#L205
garbage-collector-controller
内容について
garbage-collector-controllerは下記のような処理を行う
TODO ぶっちゃけよくわからん
このcontrollerで更新されるリソース
- "delete", "list", "watch" 全てのAPIを持つリソース全部?
このcontrollerに関連するリソース
- "delete", "list", "watch" 全てのAPIを持つリソース全部?
前提
デフォルトでは起動しなさそう
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L491-L493
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/options/garbagecollectorcontroller.go#L37
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/core.go#L490-L532
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L86-L130
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L142-L175
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L177-L276
startGarbageCollectorController
NewGarbageCollector
Run
gc.dependencyGraphBuilder.Run
runProcessGraphChanges ~ processGraphChanges
これぶっちゃけよくわからんかった
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/graph_builder.go#L306
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/graph_builder.go#L603-L606
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/graph_builder.go#L620-L842
gc.runAttemptToDeleteWorker ~ processAttemptToDeleteWorker
これぶっちゃけよくわからんかった
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L313-L316
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L322-L340
gc.runAttemptToOrphanWorker ~ processAttemptToOrphanWorker
自信ないんだけど、やってることとしてはownerのdependenciesからownerのowner referenceを取り除くということをやってるっぽい
このownerもdependenciesにも"node"というstructが使われてるんだけど、もしかしてこれってNodeリソースのことでは無くて単純なリソースの親子関係を示すものでしかない感じ?
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L738-L741
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L743-L766
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L768-L794
Sync
"delete", "list", "watch" 全てのAPIを持つリソースを削除可能対象のリソースとしてmonitorによる監視を開始する
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L177-L276
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L190
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L246
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/garbagecollector.go#L132-L140
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/graph_builder.go#L184-L236
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/garbagecollector/graph_builder.go#L238-L266
statefulset-controller
内容について
statefulset-controllerは下記のような処理を行う
StatefulSetリソースの設定に基づくPodやPVCを作成~管理する。
このcontrollerで更新されるリソース
- StatefulSet
- ControllerRevisions
- PVC
- Pod
このcontrollerに関連するリソース
- StatefulSet
- ControllerRevisions
- PVC
- Pod
起動処理
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/cmd/kube-controller-manager/app/apps.go#L53-L63
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/statefulset/stateful_set.go#L79-L147
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/statefulset/stateful_set.go#L149-L173
startStatefulSetController
NewStatefulSetController
Run
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/statefulset/stateful_set.go#L169-L169
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/statefulset/stateful_set.go#L438-L442
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/statefulset/stateful_set.go#L421-L436
- https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/statefulset/stateful_set.go#L444-L483
- StatefulSetのセレクタにマッチするけど、ownerReferenceで紐づいていないControllerRevisionsがあればそれを紐付ける: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/statefulset/stateful_set.go#L473-L475
- StatefulSetにマッチするセレクタのPodを取得する(ownerReferenceが適切に紐づいていなければ紐付ける): https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/statefulset/stateful_set.go#L477-L480
- syncStatefulSetを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/statefulset/stateful_set.go#L482-L482
- ssc.control.UpdateStatefulSetを実行: https://github.com/kubernetes/kubernetes/blob/v1.28.2/pkg/controller/statefulset/stateful_set.go#L491-L491
- performUpdateを実行: https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/statefulset/stateful_set_control.go#L93-L100
- updateStatefulSetを実行: https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/statefulset/stateful_set_control.go#L117
- StatefulSetに対するPodやPVCの作成・管理などをよしなに実行: https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/statefulset/stateful_set_control.go#L519-L712
- StatefulSetのステータスを更新: https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/statefulset/stateful_set_control.go#L122-L130
- 古いControllerRevisionを削除: https://github.com/kubernetes/kubernetes/blob/master/pkg/controller/statefulset/stateful_set_control.go#L102-L103