00052. Portkey-AI, Initial Investigation
- AI Gateway
- Architecture
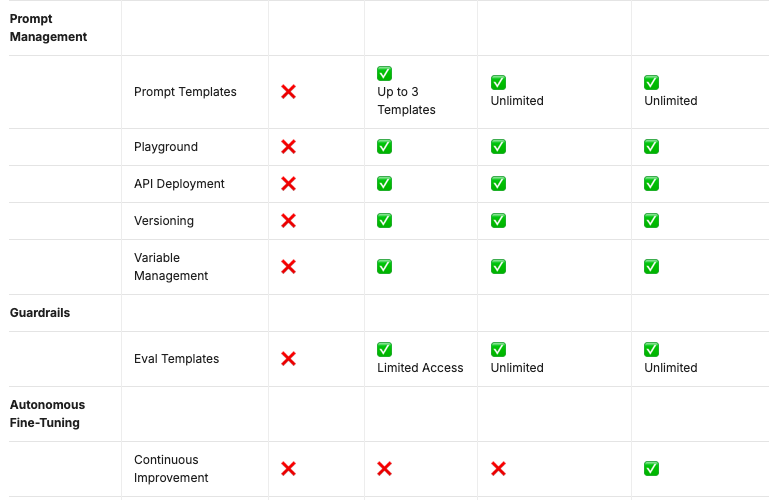
- Prompt Management
- Guardrails
- Autonomous Fine-Tuning
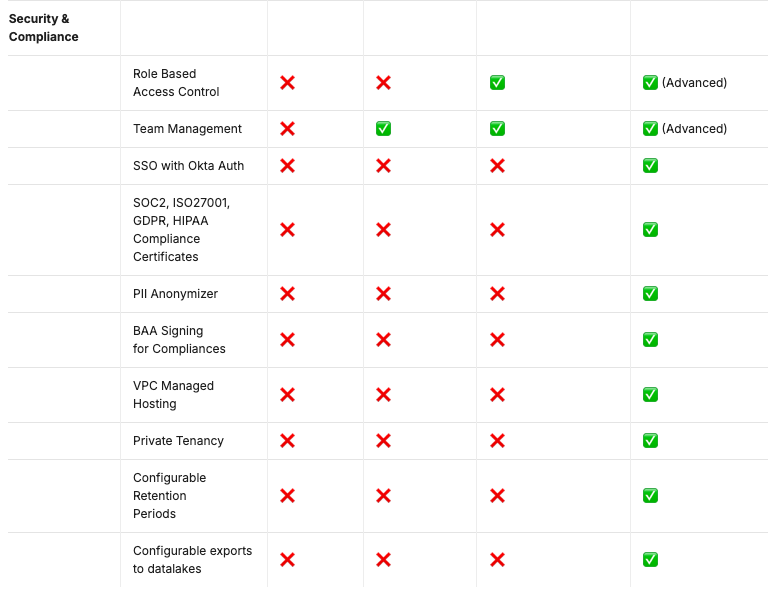
- Security & Compliance
Tiering
Observablity は OSS だとサポートなしなので自分で何とかする。(どう何とかできるか調べる)
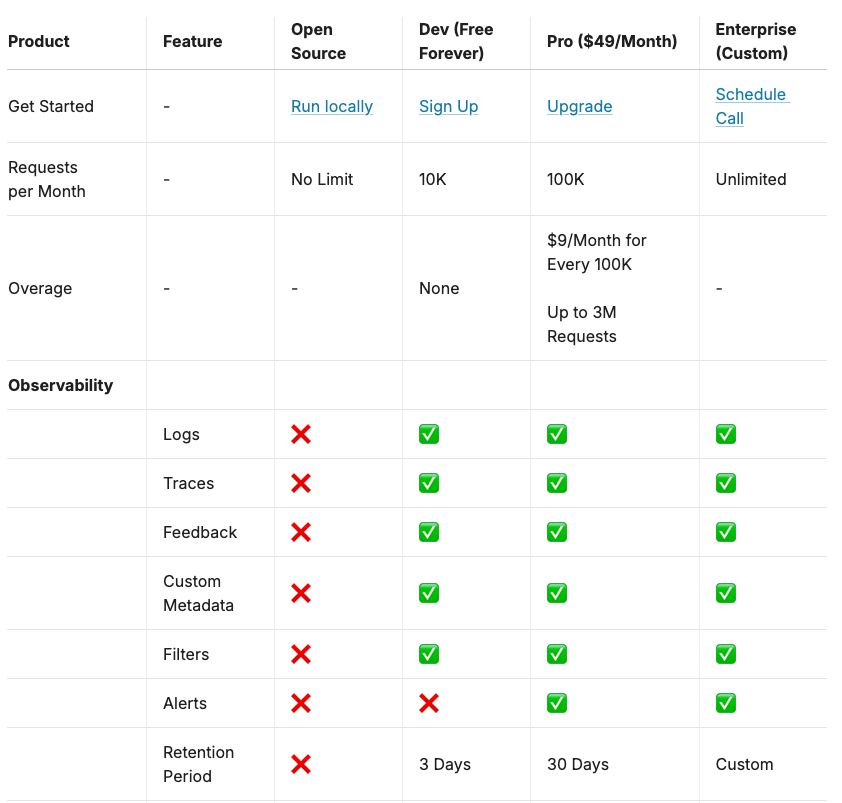
Caching がない感じ
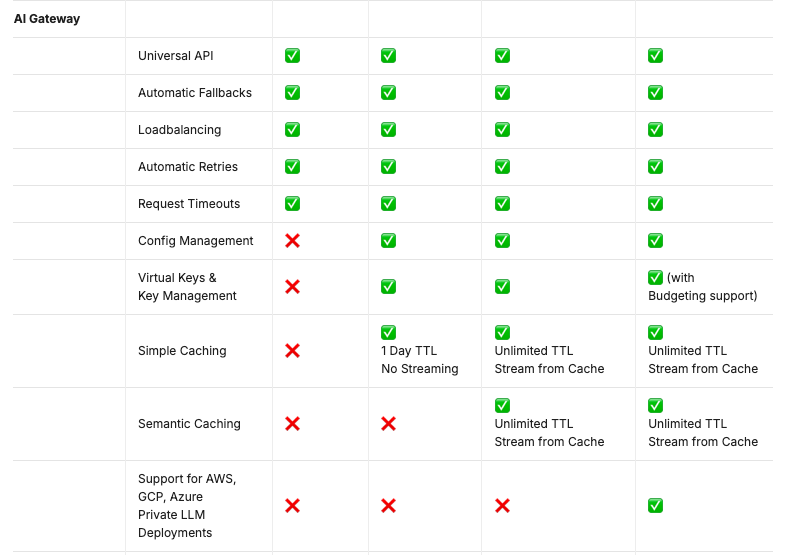
AI Gateway -Universal API
Portkey AIのUniversal API機能に関する情報を以下にまとめます。
機能サマリー
PortkeyのUniversal APIは、テキスト、視覚、音声などのさまざまなモダリティと、100以上のモデル(OpenAI、Anthropic、Metaなど)を統合するための一貫したインターフェースを提供します。このAPIを使用することで、異なるマルチモーダルLLMに対して別々の統合を維持する必要がなくなり、すべてのリクエストがOpenAIの仕様に変換されて応答が返されます。
主な機能
-
統一されたインターフェース: さまざまなAIプロバイダーやモデルを統一されたAPIで利用可能。
-
ローカルモデルの統合: プライベートまたはローカルにホストされたモデルへのルーティングも可能。
-
簡単なプロバイダー切り替え: プロバイダーを簡単に切り替えることができ、柔軟に対応。
-
多様なリクエスト形式: REST APIを通じて、さまざまなリクエストをサポート。
ドキュメントURL
詳細な情報は以下のURLから確認できます: Universal API - Portkey Docs [3]。
Citations:
[1] https://docs.portkey.ai/docs
[2] https://docs.portkey.ai/docs/api-reference/introduction
[3] https://docs.portkey.ai/docs/product/ai-gateway/universal-api
[4] https://docs.portkey.ai/docs/integrations/llms/openai
[5] https://docs.portkey.ai/docs/introduction/make-your-first-request
[6] https://docs.portkey.ai/docs/api-reference/authentication
[7] https://docs.portkey.ai/docs/product/ai-gateway/configs
[8] https://docs.portkey.ai/docs/introduction/feature-overview
Universal APIの使い方
Portkeyの Universal APIを使用する際の具体的な手順は以下の通りです。
1. APIキーの取得
Portkeyのダッシュボードから、APIキーを取得します。このキーは、すべてのAPIリクエストに含める必要があります。
2. リクエストの送信
Universal APIのエンドポイントにHTTPリクエストを送信します。リクエストには以下の情報を含める必要があります:
- APIキー (ヘッダーまたはクエリパラメータで指定)
- モデルのプロバイダー (例: openai, anthropic, etc)
- モデルのID (例: text-davinci-003, claude-v1, etc)
- リクエストのタイプ (例: completion, embedding, image, etc)
- リクエストのパラメータ (例: prompt, max_tokens, temperature, etc)
以下は、Python製のrequestsライブラリを使ったサンプルコードです:
import requests
url = "https://api.portkey.ai/v1/universal"
headers = {
"Authorization": "Bearer YOUR_API_KEY"
}
data = {
"provider": "openai",
"model": "text-davinci-003",
"type": "completion",
"parameters": {
"prompt": "Hello, how are you?",
"max_tokens": 50,
"temperature": 0.7
}
}
response = requests.post(url, headers=headers, json=data)
result = response.json()
3. レスポンスの処理
APIからのレスポンスには、リクエストの結果が含まれています。レスポンスのステータスコードが200の場合は成功を意味し、ボディにはモデルの出力が含まれています。
エラーが発生した場合は、ステータスコードが400以上になり、ボディにはエラーメッセージが含まれています。
以下は、レスポンスの例です:
{
"id": "cmpl-7Abcdefghijk",
"object": "text_completion",
"created": 1677811200,
"model": "text-davinci-003",
"choices": [
{
"text": " I'm doing well, thank you for asking.",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 6,
"completion_tokens": 10,
"total_tokens": 16
}
}
以上が、Universal APIを使用する際の基本的な流れです。詳細については、Portkeyのドキュメントを参照してください。
Citations:
[1] https://innova-jp.com/media/cms-api
[2] https://www.salesforce.com/jp/blog/universal-api-management/?bc=HA
[3] https://www.strategit.jp/column/041202/
[4] https://www.creativehope.co.jp/media/ua-backup.html
[5] https://projectofnapskint.com/luna-api-vision-console-pro-bundle/
[6] https://docs.portkey.ai/docs/product/ai-gateway/universal-api
[7] https://ayudante.jp/column/2022-06-22/11-00/
[8] https://docs.portkey.ai/docs/integrations/llms/openai
AI Gateway - Automatic Fallbacks
Portkey AIのAutomatic Fallbacks機能は、複数の言語モデル(LLM)を利用する際に、主要なモデルが応答しない場合やエラーが発生した場合に自動的に次のモデルに切り替えることができる機能です。この機能により、アプリケーションの堅牢性と信頼性が向上します。
機能の概要
-
フォールバックの設定: ユーザーは、優先順位のリストに基づいて複数のモデルを指定できます。主要なLLMが失敗した場合、Portkeyは自動的に次のLLMにフォールバックします。
-
設定方法: フォールバックを有効にするには、設定オブジェクトに
fallbackモードを追加します。例えば、OpenAIのgpt-4oが失敗した場合にAnthropicのclaude-3.5-sonnetにフォールバックする設定は以下のようになります。{ "strategy": { "mode": "fallback" }, "targets": [ { "virtual_key": "openai-virtual-key", "override_params": { "model": "gpt-4o" } }, { "virtual_key": "anthropic-virtual-key", "override_params": { "model": "claude-3.5-sonnet-20240620" } } ] }
特定のエラーコードでのフォールバック
デフォルトでは、フォールバックは非2xxステータスコードのリクエストでトリガーされますが、特定のエラーコードに対してのみフォールバックをトリガーするように設定することも可能です。例えば、OpenAIからのリクエストがレート制限エラー(429)を返した場合にのみAzure OpenAIにフォールバックする設定は以下のようになります。
{
"strategy": {
"mode": "fallback",
"on_status_codes": [429]
},
"targets": [
{
"virtual_key": "openai-virtual-key"
},
{
"virtual_key": "azure-openai-virtual-key"
}
]
}
フォールバックリクエストのトレース
Portkeyは、フォールバック設定の一部として送信されたすべてのリクエストをログに記録します。これにより、どのターゲットが失敗し、どれが成功したかを簡単に追跡できます。ログページで特定のConfig IDでフィルタリングし、個別のリクエストをトレースすることができます。
注意点
- フォールバックリストに含まれるLLMが使用ケースに適していることを確認する必要があります。
- 各LLMの使用状況に注意を払い、単一のリクエストが複数のLLM呼び出しを引き起こす可能性があることを理解する必要があります。
- 各LLMには独自のレイテンシと価格があるため、別のLLMにフォールバックすることはコストや応答時間に影響を与える可能性があります。
このように、Portkey AIのAutomatic Fallbacks機能は、アプリケーションの信頼性を向上させるための強力な手段です。
Citations:
[1] https://docs.portkey.ai/docs/product/ai-gateway/fallbacks
AI Gateway - Load Balancing
Portkey AIのLoad Balancing機能は、複数の大規模言語モデル(LLM)に対してネットワークトラフィックを効率的に分散させることで、高可用性と最適なパフォーマンスを実現します。この機能を使用することで、特定のLLMがパフォーマンスのボトルネックになることを防ぎ、生成AIアプリケーションの効率を向上させます。
Load Balancingの有効化
Load Balancingを有効にするには、configオブジェクトを修正し、strategyにloadbalanceモードを設定します。以下は、OpenAIとAzure OpenAIアカウント間で75-25の負荷分散を行うための例です。
"strategy": {
"mode": "loadbalance"
},
"targets": [
{
"virtual_key": "openai-virtual-key",
"weight": 0.75
},
{
"virtual_key": "azure-virtual-key",
"weight": 0.25
}
]
Load Balancingの仕組み
-
負荷分散ターゲットとその重みの定義: 利用するLLMの
virtual keys(またはprovider+api_keyのペア)をリストとして提供し、各ターゲットに重みを割り当てます。重みは、各ターゲットにどれだけのリクエストをルーティングするかを示します。 -
重みの正規化: Portkeyは、提供された全ての重みを合計し、各ターゲットの重みをその合計で割って正規化された重みを計算します。これにより、重みの合計が1(または100%)となり、トラフィックが比例的に分配されます。
例: 重みが5、3、1の3つのターゲットがある場合、合計は9です。正規化された重みは次のようになります。
- ターゲット1: 5 / 9 = 0.55 (55%のトラフィック)
- ターゲット2: 3 / 9 = 0.33 (33%のトラフィック)
- ターゲット3: 1 / 9 = 0.11 (11%のトラフィック)
-
リクエストの分配: リクエストが来ると、Portkeyは正規化された重みに基づいてターゲットLLMにルーティングします。これにより、指定された重みに従ってトラフィックが分散されます。
注意点
-
利用するLLMが使用ケースに適していることを確認する必要があります。すべてのLLMが同じ能力を持っているわけではなく、応答形式も異なります。
-
各LLMの使用状況に注意が必要です。重みの分配によって、各LLMへの使用量が大きく異なる可能性があります。
-
各LLMには独自のレイテンシーと価格があるため、トラフィックを多様化することはコストや応答時間に影響を与える可能性があります。
このように、Portkey AIのLoad Balancing機能を活用することで、複数のLLMを効果的に管理し、アプリケーションのパフォーマンスを最適化することが可能です[1]。
Citations:
[1] https://docs.portkey.ai/docs/product/ai-gateway/load-balancing
Load Balancing の仕組みは Cloud の LB との違い、A/B テスト、LLM Routing を組み合わせるときにどう考慮すべきかは検討の余地がある。
AI Gateway - Automatic Retries
Portkey AIのAutomatic Retries機能は、APIリクエストの失敗を軽減するための便利なツールです。この機能は、すべてのPortkeyプランで利用可能で、特にLLM(大規模言語モデル)APIの不明な失敗に対処するために設計されています。
機能の概要
-
自動再試行の回数: 最大5回まで再試行が可能です。
-
特定のエラーコードに基づく再試行: デフォルトでは、再試行は以下のエラーコードに対してトリガーされます。
- 429(Too Many Requests)
- 500(Internal Server Error)
- 502(Bad Gateway)
- 503(Service Unavailable)
- 504(Gateway Timeout)
-
指数バックオフ戦略: 再試行は、ネットワークの過負荷を防ぐために、指数的な待機時間を設けて行われます。具体的には、最初の呼び出しの後、再試行の間隔は次のようになります。
- 1回目の再試行: 1秒
- 2回目の再試行: 2秒
- 3回目の再試行: 4秒
- 4回目の再試行: 8秒
- 5回目の再試行: 16秒
具体的な使い方
再試行を有効にする
再試行を有効にするには、設定オブジェクトにretryパラメータを追加します。以下は、5回の再試行を設定する例です。
"retry": {
"attempts": 5
},
"virtual_key": "virtual-key-xxx"
特定のエラーコードに対する再試行
特定のエラーコードに対してのみ再試行を行いたい場合、on_status_codesパラメータを設定します。以下は、408、429、401のエラーコードに対して3回の再試行を設定する例です。
"retry": {
"attempts": 3,
"on_status_codes": [408, 429, 401]
},
"virtual_key": "virtual-key-xxx"
この設定を行うことで、指定したエラーコードに対してのみ再試行がトリガーされ、Portkeyのデフォルトのエラーコードに対しては再試行が行われなくなります。
このAutomatic Retries機能を活用することで、APIリクエストの信頼性を向上させ、エラー発生時の影響を最小限に抑えることができます。
Citations:
[1] https://docs.portkey.ai/docs/product/ai-gateway/automatic-retries
AI Gateway - Request Timeouts
Portkey AIの Request Timeouts機能
Portkey AIのRequest Timeouts機能は、LLMのレイテンシを効果的に管理するために使用されます。この機能により、指定された時間を超えるリクエストを自動的に終了させることができ、エラーを優雅に処理したり、より高速なリクエストを行ったりすることができます。[1]
Request Timeoutsの有効化
Request Timeoutsは、リクエストを行う際に有効にするか、Configsで設定することができます。リクエストタイムアウトはミリ秒単位で指定します。[1]
リクエスト時の設定
Portkeyクライアントをインスタンス化する際にリクエストタイムアウトを設定するか、REST APIを使用している場合は、x-portkey-request-timeoutヘッダーを送信します。[1]
以下は、Python とcurlでの具体的な設定例です。
from portkey_ai import Portkey
portkey = Portkey(
api_key="PORTKEY_API_KEY",
virtual_key="VIRTUAL_KEY",
request_timeout=3000
)
completion = portkey.chat.completions.create(
messages=[{"role": 'user', "content": 'Say this is a test'}],
model='gpt-4o-mini'
)
curl "https://api.portkey.ai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "x-portkey-api-key: $PORTKEY_API_KEY" \
-H "x-portkey-virtual-key: openai-virtual-key" \
-H "x-portkey-request-timeout:5000" \
-d '{
"model": "gpt-4o-mini",
"messages": [{"role": "user", "content": "Hello!"}]
}'
Configsでの設定
Configsでは、リクエストタイムアウトを(1)戦略レベルか(2)ターゲットレベルで設定できます。10秒のタイムアウトの場合は、"request_timeout": 10000のように設定します。[1]
戦略レベルでタイムアウトを設定する例:
"strategy": { "mode": "fallback" },
"request_timeout": 10000,
"targets": [
{ "virtual_key": "open-ai-xxx" },
{ "virtual_key": "azure-open-ai-xxx" }
]
ここでは、10秒のリクエストタイムアウトがこのConfig内のすべてのターゲットに適用されます。[1]
ターゲットレベルでタイムアウトを設定する例:
"strategy": { "mode": "fallback" },
"targets": [
{ "virtual_key": "open-ai-xxx", "request_timeout": 10000 },
{ "virtual_key": "azure-open-ai-xxx", "request_timeout": 2000}
]
ここでは、1つ目のターゲットには10秒のタイムアウトが、2つ目のターゲットには2秒のタイムアウトが設定されます。[1]
ネストされたターゲットオブジェクトは上位レベルのタイムアウトを継承し、カスタマイズされた制御のために任意のレベルでオーバーライドできます。[1]
リクエストタイムアウトの処理
タイムアウトしたリクエストに対しては、Portkeyは標準の408エラーを発行します。on_status_codesパラメータを使用して、フォールバックや再試行の戦略を設定することで、これらのシナリオを堅牢に処理することができます。[1]
フォールバックのトリガーとしてリクエストタイムアウトを使用する例:
"strategy": {
"mode": "fallback",
"on_status_codes": [408]
},
"targets": [
{ "virtual_key": "open-ai-xxx", "request_timeout": 2000 },
{ "virtual_key": "azure-open-ai-xxx"}
]
ここでは、最初のリクエストが2秒後にタイムアウトした場合にのみ、OpenAIからAzure OpenAIへのフォールバックがトリガーされます。そうでない場合は、408エラーコードでリクエストが失敗します。[1]
再試行のトリガーとしてリクエストタイムアウトを使用する例:
"request_timeout": 1000,
"retry": { "attempts": 3, "on_status_codes": [ 408 ] },
"virtual_key": "open-ai-xxx"
ここでは、リクエストが1秒以内に応答を返さない場合、最大3回まで再試行がトリガーされます。3回の再試行が失敗した後は、408コードでエラーになります。[1]
注意点と考慮事項
リクエストタイムアウトは、制御不能なモデルとそのレイテンシを優雅に処理するための強力な機能ですが、いくつか考慮すべき点があります。[1]
- 合理的なタイムアウトを設定していることを確認してください。例えば、
gpt-4のようなモデルは、10秒未満の応答時間を持つことが多いです。 - リクエストがタイムアウトした場合に408エラーを適切に処理することを確認してください。ユーザーにクエリを再実行するように伝え、アプリ上でスムーズなインタラクションを設定することができます。
- ストリーミングリクエストの場合、指定された期間内に少なくとも1つのチャンクが受信されると、タイムアウトはトリガーされません。
Citations:
[1] https://docs.portkey.ai/docs/product/ai-gateway/request-timeouts
AI Gateway - Config Management
Portkey AIのConfig Management機能は、Gatewayの管理を効率化し、プログラム的に様々な要素(フォールバック、ロードバランシング、リトライ、キャッシュなど)を制御することを可能にします。この機能は、すべてのPortkeyプランで利用可能です。
機能の概要
-
構成(Config): JSONオブジェクトとして定義され、Gatewayへのリクエストのルーティングルールを設定できます。複数の構成を作成し、リクエストで使用することができます。
-
作成方法: Portkeyアプリの「Configs」ページに移動し、「Create」をクリックして新しい構成を作成します。
具体的な使い方
-
SDKを通じての使用:
- Portkey SDKクライアントのconfigパラメータを使用します。
- 例:
const portkey = new Portkey({ apiKey: "PORTKEY_API_KEY", config: "pc-***" // 構成IDまたは構成オブジェクトを指定 });
-
OpenAI SDKでの使用:
- OpenAI SDKのデフォルトヘッダーに構成を追加します。
- 例:
const openai = new OpenAI({ apiKey: 'OPENAI_API_KEY', baseURL: PORTKEY_GATEWAY_URL, defaultHeaders: createHeaders({ provider: "openai", apiKey: "PORTKEY_API_KEY", config: "CONFIG_ID" // UIから取得した構成ID }) });
-
REST APIでの使用:
- リクエストヘッダーに
x-portkey-configを追加します。 - 例:
curl https://api.portkey.ai/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "x-portkey-api-key: $PORTKEY_API_KEY" \ -H "x-portkey-provider: openai" \ -H "x-portkey-config: $CONFIG_ID" \ -d '{ "model": "gpt-3.5-turbo", "messages": [{ "role": "user", "content": "Hello!" }] }'
- リクエストヘッダーに
-
特定リクエストへの構成の適用:
- デフォルト構成が設定されている場合でも、特定のリクエストで構成を指定すると、そのリクエストに対して優先されます。
- 例:
portkey.chat.completions.create({ messages: [{role: "user", content: "Say this is a test"}], model: "gpt-3.5-turbo" }, {config: "pc-***"});
ログでの構成の確認
Portkeyは、ログページで構成の使用状況を表示し、各リクエストのGatewayの活動を確認できます。リクエストに使用された特定の構成IDも表示され、ログ詳細ページから直接編集することも可能です。
このように、Portkey AIのConfig Management機能は、開発者がGatewayの動作を柔軟に制御できる強力なツールです。
Citations:
[1] https://docs.portkey.ai/docs/product/ai-gateway/configs
AI Gateway - Virtual Keys & Key Management
Portkey AIのVirtual KeysおよびKey Management機能は、APIキーの安全な管理と使用を可能にするシステムです。この機能は、すべてのPortkeyプランで利用可能です。
機能の概要
セキュリティと管理
-
APIキーの安全な保存: LLM APIキーは暗号化され、安全なボールトに保存されます。これにより、リクエスト時のみアクセスが可能で、データのセキュリティが確保されます。
-
バーチャルキーの生成: 単一のAPIキーに対して複数のバーチャルキーを生成でき、これによりキーのローテーションが容易になります。
-
制限の設定: コスト、リクエスト量、ユーザーアクセスに基づいて制限を設けることができます。
具体的な使い方
バーチャルキーの作成
- 「Virtual Keys」ページに移動し、右上の「Add Key」ボタンをクリックします。
- AIプロバイダーを選択し、キーにユニークな名前を付けます。
Portkey SDKの使用
バーチャルキーを使用するには、以下のようにPortkey SDKにキーを追加します。
import Portkey from 'portkey-ai'
const portkey = new Portkey({
apiKey: "PORTKEY_API_KEY", // 環境変数からデフォルト取得
virtualKey: "VIRTUAL_KEY" // LLMキーのためのボールトをサポート
})
バーチャルキーをオーバーライドして使用する場合は、以下のようにします。
const chatCompletion = await portkey.chat.completions.create({
messages: [{ role: 'user', content: 'Say this is a test' }],
model: 'gpt-3.5-turbo',
}, {virtualKey: "OVERRIDING_VIRTUAL_KEY"});
予算制限の設定
Portkeyでは、バーチャルキーごとに予算制限を設定でき、AIプロバイダーやLLMに対する支出を管理するのに役立ちます。
プロンプトテンプレートの選択
Portkeyのプロンプトテンプレート内でバーチャルキーを選択すると、自動的に取得され、すぐに使用できる状態になります。
Langchain / LlamaIndexとの統合
PortkeyのカスタムLLMを使用する際は、以下のようにバーチャルキーを設定します。
llm = PortkeyLLM(api_key="PORTKEY_API_KEY", virtual_key="VIRTUAL_KEY")
このように、PortkeyのVirtual Keys機能は、APIキーの管理を効率化し、セキュリティを強化するための強力なツールです。
Citations:
[1] https://docs.portkey.ai/docs/product/ai-gateway/virtual-keys
AI Gateway - Caching
Portkey AIのSimple Caching機能は、過去のレスポンスをキャッシュに保存することで、LLMリクエストの速度を向上させ、コストを削減するための機能です。この機能は、すべてのプランで利用可能です。
機能概要
キャッシュモード
-
Simple Cache: リクエストをそのまま一致させる機能で、完全に同じプロンプトが再度送信された場合にキャッシュからレスポンスを直接取得します。すべてのモデル(画像生成モデルを含む)で動作します。
-
Semantic Cache: 意味的に類似したリクエストをマッチさせる機能で、前置詞や代名詞が異なる場合でも、コンテキストの類似性を考慮します。このキャッシュは、
/chat/completionsエンドポイントで利用可能です。
キャッシュの設定
キャッシュを有効にするには、設定オブジェクトに次のように追加します。
"cache": { "mode": "simple" }
使用例
以下に、Simple Cacheを使用するための具体的なコード例を示します。
Pythonでの使用例
from portkey_ai import Portkey
portkey = Portkey(
api_key="PORTKEY_API_KEY",
virtual_key="open-ai-xxx",
config="pp-cache-xxx"
)
response = portkey.chat.completions.create(
messages=[{"role": 'user', "content": 'Hello!'}],
model='gpt-4',
cache={"mode": "simple"}
)
JavaScriptでの使用例
import Portkey from 'portkey-ai';
const portkey = new Portkey({
apiKey: "PORTKEY_API_KEY",
config: "pc-cache-xxx",
virtualKey: "open-ai-xxx"
});
async function main() {
const response = await portkey.chat.completions.create({
messages: [{ role: 'user', content: 'Hello!' }],
model: 'gpt-4',
}, {
cache: { mode: "simple" }
});
}
main();
キャッシュの有効期限と強制更新
-
キャッシュの有効期限:
max_ageを設定することで、キャッシュの有効期限を秒単位で指定できます。最小60秒、最大90日まで設定可能です。 -
キャッシュの強制更新: リクエスト時に新しいレスポンスを取得し、既存のキャッシュレスポンスを上書きするためには、以下のヘッダーを使用します。
"x-portkey-cache-force-refresh": "True"
これにより、キャッシュの内容を強制的に更新することができます。
まとめ
Portkey AIのSimple Caching機能は、リクエストの応答時間を大幅に短縮し、コストを削減するための強力なツールです。シンプルなキャッシュモードを利用することで、同一のリクエストに対して迅速に応答することが可能になります。
Citations:
[1] https://docs.portkey.ai/docs/product/ai-gateway/cache-simple-and-semantic
Architecture
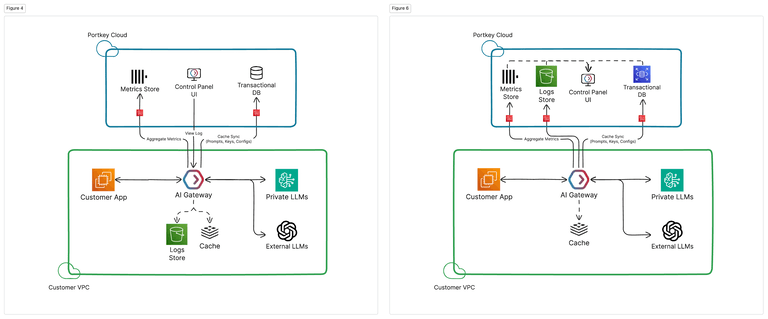
Portkeyのエンタープライズ向けアーキテクチャ
Portkeyのエンタープライズ向け製品は、顧客のVPCにホストされたAIゲートウェイが全てのトラフィックを管理する、ハイブリッドクラウドアーキテクチャで展開されることが望ましいです[1]。キー、アクセス制御、ルーティングルール、ガードレールなどのトラフィック管理はすべて、付属のキャッシュによって管理されます[1]。
Portkeyのコントロールプレーンは、ユーザー、プロンプトテンプレート、仮想キー、アクセス管理、設定を制御しながら、ログやアナリティクスなどの重要な可視化情報を提供するコントロールパネルUIをホストしています[1]。
データプレーンの役割
データプレーンは、付属のキャッシュと必要に応じてログストアをホストしたAIゲートウェイで構成されています[1]。顧客のクラウド内にプライベートにデプロイされたAIゲートウェイは、コントロールプレーンから情報を暗号化して復号化し、すべてのデータとトラフィックが顧客のクラウド内に留まるようにします[1]。
コントロールプレーンの役割
コントロールプレーンは、プロンプト管理、バージョン管理、デプロイメント、メトリクスの集計、高度なフィルタ、メタデータ、フィードバックを備えたログとアナリティクスの表示UI、組織とチームの管理、ゲートウェイの設定管理とバージョン管理などの面倒を見ることで、顧客が自社でこれらのシステムを管理する必要がなくなります[1]。
新機能とパッチ管理
ほとんどの機能については、Portkeyは顧客のデプロイメントに新しい機能を自動的にリリースできます。AIゲートウェイ上の変更を伴うものについては、新しいリリースとパッチがコンテナレジストリから提供されます[1]。
具体的な使い方
- 顧客のVPCにAIゲートウェイをプライベートにデプロイし、Portkeyのコントロールプレーンと連携させる
- コントロールプレーンのUIから、プロンプト、ユーザー、アクセス制御などを管理する
- AIゲートウェイのキャッシュを使用して、LLMの呼び出しを高速化する
- 新しい機能やパッチをコンテナレジストリからAIゲートウェイにデプロイする
Citations:
[1] https://docs.portkey.ai/docs/product/enterprise-offering/private-cloud-deployments/architecture
Prompt Management - Prompt Templates
Portkey AIのPrompt Templatesは、ユーザーが大規模言語モデル(LLM)用のプロンプトを簡単に作成・管理できる機能です。この機能はすべてのプランで利用可能で、プロンプトの変更を自動的に追跡し、バージョン管理を行います。これにより、開発者やプロンプトエンジニアは、プロダクション環境を壊すことなく迅速な実験が可能になります。
具体的な使い方
-
プロンプトの作成:
- Portkeyアプリで「Prompts」ボタンをクリックし、「Create」を選択すると、新しい空のプレイグラウンドが開きます。
- ユーザー/アシスタントメッセージを記入し、
top_pやmax_tokens、logit_biasなどのモデルパラメータを設定できます。
-
テンプレートエンジンの使用:
- Mustacheというロジックレスのテンプレートエンジンを使用して、変数を定義し、プロンプトを拡張できます。例えば、
{{customer_data}}や{{chat_query}}といった変数を使用し、実行時に値を渡すことができます。
- Mustacheというロジックレスのテンプレートエンジンを使用して、変数を定義し、プロンプトを拡張できます。例えば、
-
バージョン管理:
- プロンプトに変更を加えると、ブラウザ内で変更が保存されますが、Portkeyには自動的には反映されません。右上のボタンをクリックして最新バージョンを保存できます。
- 以前のバージョンは右側のカラムで確認でき、復元することも可能です。
-
プロンプトの公開:
- プロンプトを更新しても、プロダクション環境のプロンプトは自動的には更新されません。更新時に「Publish prompt changes」を選択することで、最新バージョンをデプロイできます。
-
異なるプロンプトバージョンの使用:
-
PROMPT_IDを使用して、特定のバージョンのプロンプトを指定することができます。デフォルトでは、公開されたバージョンが使用されますが、特定のバージョンを指定することで、実験や特定のユースケースに応じたプロンプトを利用できます。
-
このように、Portkey AIのPrompt Templatesは、プロンプトの作成から管理、バージョン管理までを一元的に行える強力なツールです。
Citations:
[1] https://docs.portkey.ai/docs/product/prompt-library/prompt-templates
Prompt Management - Prompt Partials
Prompt Partials とは
Prompt Partials は、Portkey AI で提供されている機能で、プロンプトテンプレートの中で頻繁に使用される部分(命令セット、データ構造の説明、例など)を別途保存し、必要に応じてフレキシブルに組み込むことができます。[1]
Partials は、グローバル変数ストアとしても機能します。複数のプロンプトテンプレートで共通して使用される変数を定義し、簡単に参照または更新することができます。[1]
Partials の作成
Partials は、プロンプトページから直接アクセスできます。[1]
新しい Partial を作成し、任意のプロンプトテンプレートで使用することができます。例えば、命令を別途保存するプロンプトパーシャルは次のようになります:
保存時に、各 Partial には一意の ID が生成され、プロンプトテンプレート内で使用することができます。[1]
テンプレートエンジン
Partials は Mustache テンプレートエンジンに従い、実行時にタグを使用してデータ入力を簡単に処理することができます。[1]
Portkey は以下のタグをサポートしています:
{{variable}}{{#block}} <string> {{/block}}{{^block}}
タグの使用方法については、こちらの包括的なガイドをご覧ください。[1]
バージョン管理
Portkey は、プロンプトテンプレートと同様の更新とパブリッシュのフローに従います。Partial を継続的に更新し、新しいバージョンを保存することができ、パブリッシュ機能を使用して任意のバージョンをプロダクションに送信することができます。[1]
任意の Partial の履歴はすべて右列に表示され、以前のバージョンを最新版またはプロダクション用に公開済みとして簡単に復元することができます。[1]
Partials の使用
プロンプトテンプレートの中で、{{> と入力するだけで、利用可能なプロンプトパーシャルの名前をリストから選択することができます。[1]
テンプレートにパーシャルが組み込まれると、定義されているすべての変数/ブロックがPrompt変数セクションにレンダリングされます。[1]
新しい Partial バージョンがパブリッシュされると、任意のプロンプトテンプレートで使用されているパーシャルも自動的に更新されます。[1]
プロンプト完了リクエストの作成
パーシャル内で定義されたすべての変数/タグは、prompts.completion リクエストを行う際に直接呼び出すことができます。[1]
const response = portkey.prompts.completions.create({
promptID: "pp-system-pro-34a60b",
variables: {
"user_query":"",
"company":"",
"product":"",
"benefits":"",
"phone number":"",
"name":"",
"device":"",
"query":""
}
})
Citations:
[1] https://docs.portkey.ai/docs/product/prompt-library/prompt-partials
Prompt Management - Retrieve Prompts
Retrieve Prompts機能は、Portkey AIのプロダクトにおいて、保存されたプロンプトを取得し、さまざまなAPIリクエストで使用できるようにするためのものです。この機能はすべてのPortkeyプランで利用可能です。
機能概要
Retrieve Promptsを使用することで、特定のプロンプトIDを指定して、プロンプトの内容や保存されたパラメータをJSON形式で取得できます。これにより、プロバイダーのSDKを使用する場合でも、Portkey SDKを使わずにプロンプトを利用できます。
具体的な使い方
1. プロンプトの取得
プロンプトを取得するには、以下のエンドポイントにPOSTリクエストを送信します。
POST https://api.portkey.ai/v1/prompts/$PROMPT_ID/render
リクエストには、PortkeyのAPIキーをヘッダーに含め、必要な変数をペイロードで送信します。
例:
curl -X POST "https://api.portkey.ai/v1/prompts/$PROMPT_ID/render" \
-H "Content-Type: application/json" \
-H "x-portkey-api-key: $PORTKEY_API_KEY" \
-d '{
"variables": {"movie":"Dune 2"}
}'
このリクエストにより、指定した映画「Dune 2」に関するプロンプトが取得されます。
2. プロンプトパラメータの更新
取得したプロンプトのモデルパラメータ(例:temperatureやmessages body)を変更したい場合は、リクエストのペイロードにオーバーライドするパラメータを追加します。
例:
curl -X POST "https://api.portkey.ai/v1/prompts/$PROMPT_ID/render" \
-H "Content-Type: application/json" \
-H "x-portkey-api-key: $PORTKEY_API_KEY" \
-d '{
"variables": {"movie":"Dune 2"},
"model": "gpt-3.5-turbo",
"temperature": 2
}'
このリクエストでは、モデルをgpt-3.5-turboに変更し、温度を2に設定しています。
3. レンダー出力を新しいリクエストに使用
取得したプロンプトを他のAPIリクエストに利用することも可能です。例えば、OpenAIのSDKを使用してプロンプトを送信することができます。
例:
import Portkey from 'portkey-ai';
import OpenAI from 'openai';
const portkey = new Portkey({ apiKey: "PORTKEY_API_KEY" });
async function getPromptTemplate() {
const render_response = await portkey.prompts.render({
promptID: "PROMPT_ID",
variables: { "movie": "Dune 2" }
});
return render_response.data;
}
const openai = new OpenAI({
apiKey: 'OPENAI_API_KEY',
baseURL: 'https://api.portkey.ai/v1',
defaultHeaders: {
'x-portkey-provider': 'openai',
'x-portkey-api-key': 'PORTKEY_API_KEY',
'Content-Type': 'application/json',
}
});
async function main() {
const PROMPT_TEMPLATE = await getPromptTemplate();
const chatCompletion = await openai.chat.completions.create(PROMPT_TEMPLATE);
console.log(chatCompletion.choices[0]);
}
main();
このように、Retrieve Prompts機能を利用することで、保存したプロンプトを柔軟に取得し、さまざまな用途に応じて活用することができます。
Citations:
[1] https://docs.portkey.ai/docs/product/prompt-library/retrieve-prompt-templates
Guardrails
Portkey AIのGuardrailsは、AIモデルの入力と出力が特定の基準を満たすことを保証するための機能であり、リアルタイムでの行動を監視します。以下に、Guardrailsの概要と具体的な使い方を説明します。
Guardrailsの概要
Guardrailsは、AIモデルが適切に動作することを保証するための保護バリアを提供します。これにより、リクエストやレスポンスが事前に設定された条件に従っているかを確認できます。具体的には、以下のようなチェックが可能です:
- 正規表現マッチ: リクエストやレスポンスのテキストが特定のパターンに一致するかを確認します。
- JSONスキーマ: レスポンスのJSONが指定されたスキーマに合致しているかを検証します。
- コードの検出: SQLやPythonなどのコードが含まれているかをチェックします。
- カスタムガードレール: 既存のカスタムガードレールをPortkeyに統合することも可能です。
これらのガードレールは、AIの責任ある利用を促進し、リスクを軽減するために設計されています[1]。
Guardrailsの具体的な使い方
Guardrailsを使用するには、以下の4つのステップを踏む必要があります。
1. ガードレールチェックの作成
- Portkeyの「Guardrails」ページで、右側のサイドバーから希望するガードレールチェックを追加します。
- 各チェックは、入力または出力のいずれかを検証するために設定されます。
2. ガードレールアクションの追加
- ガードレールに対する基本的なオーケストレーションロジックを定義します。
- 6種類のアクションがあり、各アクションはチェック結果に基づいて異なる動作を実行します。
3. 設定を通じてガードレールを有効化
- 作成したガードレールをリクエストに添付するために、設定を使用します。
- 設定には、リクエストの前後でガードレールを実行するためのフックを追加できます。
4. 設定をリクエストに添付
- Portkeyクライアントを初期化する際に、設定IDを渡します。
const portkey = new Portkey({
apiKey: "PORTKEY_API_KEY",
config: "CONFIG_ID" // 設定IDを指定
});
このようにして、Guardrailsを利用することで、AIアプリケーションの整合性と信頼性を確保し、安全でコンプライアンスに適合したリクエストのみを処理することができます[1]。
Citations:
[1] https://docs.portkey.ai/docs/product/guardrails
Portkey AI のパートナー Guardrails
Portkey AIは、Patronus AI、Aporia、Pillarなどの有名なAIガードレールカンパニーとパートナーシップを結び、それらのガードレールフレームワークをPortkey Gatewayに導入し、Portkeyの世界中のユーザーが利用できるようにしています。[1]
パートナー Guardrailsの具体的な使い方
パートナー Guardrailsを使用するには、Portkey Gatewayでそれらを有効化する必要があります。ガードレールを有効にすると、AIリクエストの送信前に自動的にチェックが実行されます。
例えば、Patronus AIのガードレールを使用して、AIレスポンスに不適切なコンテンツが含まれていないかチェックできます。Patronus AIガードレールを有効にし、チェックするカテゴリ(暴力、性的コンテンツなど)を指定します。AIリクエストを送信すると、Patronus AIによってレスポンスがスキャンされ、問題があれば警告が表示されます。[1]
他のパートナー Guardrailsも同様の方法で使用できます。Aporiaのガードレールを使えば、AIレスポンスのバイアスをチェックしたり、Pillarのガードレールを使えば、機密情報の漏洩をチェックしたりできます。[1]
カスタム Guardrailの作成
Portkeyでは、カスタムwebhookを使ってオリジナルのガードレールを作成することもできます。これにより、特定のユースケースに合わせてガードレールをカスタマイズできます。[1]
Citations:
[1] https://docs.portkey.ai/docs/product/guardrails/list-of-guardrail-checks
Autonomous Fine-tuning
Portkey AIの「Autonomous Fine-tuning」機能に関する情報は、提供されたURLに記載されています。この機能は現在プライベートベータ版であり、利用に関心がある場合は、指定のメールアドレスまたはDiscordで連絡するように案内されています。
機能の概要
「Autonomous Fine-tuning」は、AIモデルのパフォーマンスを向上させるための自動調整機能です。この機能は、特定のデータセットに基づいてモデルを微調整し、より高い精度を実現することを目的としています。
具体的な使い方
-
データの準備: 微調整に使用するデータセットを準備します。このデータセットは、特定のタスクやドメインに関連するものである必要があります。
-
設定の確認: Portkeyのプラットフォームにアクセスし、Autonomous Fine-tuning機能の設定を確認します。
-
モデルの選択: 微調整したいAIモデルを選択します。
-
微調整の実行: 準備したデータセットと選択したモデルを使って、Autonomous Fine-tuningを実行します。このプロセスは自動的に行われ、モデルのパフォーマンスが最適化されます。
-
結果の評価: 微調整後のモデルのパフォーマンスを評価し、必要に応じて再調整を行います。
この機能は、AIモデルの特定の用途に対して、より適切な応答や予測を提供するために設計されています。詳細な情報や最新のアップデートについては、公式ドキュメントを参照してください。
Citations:
[1] https://docs.portkey.ai/docs/product/autonomous-fine-tuning
Security & Compliance - ACM
Portkey AIの企業向けアクセス制御管理機能
Portkey AIの企業向けプランには、強力で柔軟なアクセス制御管理システムが用意されています。これにより、機密情報を確実に保護しながら、チームの効果的なコラボレーションを可能にします。
1. 分離・カスタマイズ可能な組織
Portkey AIでは、チームやプロジェクト用の複数の安全で分離された環境である「組織」を作成できます。このマルチテナント アーキテクチャにより、データ、ログ、分析、プロンプト、仮想キー、設定、ガードレール、APIキーが各組織内で厳密に制限され、無許可のアクセスが防止され、データの機密性が維持されます。
複数の組織を作成・管理する機能により、組織の構造とプロジェクトの要件に合わせてアクセス制御をカスタマイズできます。ユーザーを特定の組織に割り当て、Portkey AIの使いやすいユーザーインターフェイスを使って、組織間を簡単に切り替えることができます。[1]
2. 細かいユーザーロールと権限
Portkey AIには、ユーザーロールに細かい権限を割り当てることができる包括的なロールベースアクセス制御(RBAC)システムが用意されています。
デフォルトでは、
Owner、
Admin、
Memberの3つのロールが用意されており、各ロールにはプラットフォームの様々な機能に対する予め定義された権限セットが割り当てられています。
Ownerは組織全体の管理、課金、プラットフォームのすべての機能に対する完全な制御権を持ちます。
Adminは、ユーザー管理、プロンプト、設定、ガードレール、仮想キー、APIキーの管理などの特権を持ちます。
Memberは、ログ、分析、プロンプト、設定、仮想キーなどの基本的な機能にアクセスでき、限定的な権限が与えられます。[1]
3. 安全でカスタマイズ可能なAPIキー管理
Portkey AIでは、細かい権限を持つ複数のAPIキーを作成・管理できる安全で柔軟なAPIキー管理システムを提供しています。各APIキーには、メトリクス、コンプリーション、プロンプト、設定、ガードレール、仮想キー、チーム管理、APIキー管理などの機能に対する特定のアクセスレベルを付与することができます。
デフォルトでは、新しい組織には全ての権限が有効になったマスターAPIキーが用意されています。オーナーとアドミンは、これらのキーを編集・管理し、必要な権限に合わせてカスタマイズされた新しいAPIキーを作成することができます。この細かい制御により、各APIキーが必要最小限のリソースにのみアクセスできるようにし、最小特権の原則を実施することができます。[1]
具体的な使い方
- 複数の組織を作成し、チームやプロジェクトごとに分離された環境を設定する
- ユーザーを組織に割り当て、ロール(オーナー、アドミン、メンバー)に応じて権限を設定する
- 特定の機能(プロンプト、設定、APIキーなど)に対する権限を持つAPIキーを作成する
- 組織内の管理アクティビティを監査するためのログを確認する(近日公開予定)
Citations:
[1] https://docs.portkey.ai/docs/product/enterprise-offering/access-control-management