Google Agent Development Kit (ADK)
概要
Google製のエージェントフレームワーク。
競合はLangChainのLangGraph、MicrosoftのAutoGenあたり。
フロントエンド要素の競合/組み合わせ先としてはChainlit。
ADKの良いところは
- 簡単に書けること: LangGraphよりもはるかに書きやすい
- ウェブアプリケーションとしてデプロイできること: adk webコマンドでlocalhostにウェブアプリケーションが立ち上がる
が、当然ながら凝ったことをしようと思うと色々調べなくてはならない。ここではそのメモを残す。
コンセプト - Agent
ADKにはBeseAgentを継承する3つのAgentタイプがある。
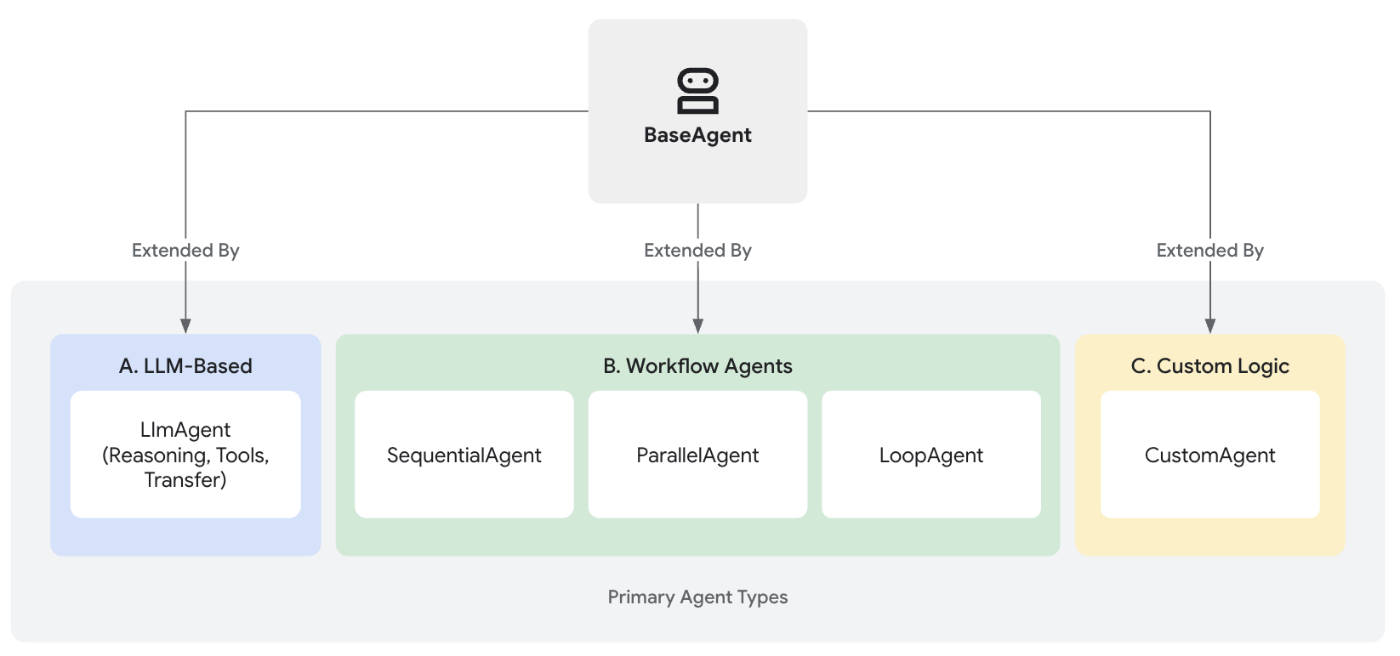
- LLM Agents: LLMを利用したもので非決定論的な出力をする。推論が必要なところで用いる。
- Workflow Agents: 予め定義された処理に従う決定論的な出力をする。
- Custom Agents: カスタム
コンセプト - LlmAgent
Agentというエイリアスで呼ぶこともできる。
基本的なの引数
- name, description, model: 基本。何のためのエージェントかを定義。
- instruction: 最もAgentの振る舞いに影響する。ツールをいつどのように使うかも定義する(意外。ツールの説明はツール側に任せていいと思っていた)。
- tools: 肝。関数、BaseToolを継承したクラスのインスタンス、他のエージェントをリストで与える。
ポイント
発展的な引数
- generate_content_config: temperatureなどを定義
- input_schema, output_schema, output_key: 入出力のデータ構造を定義
- include_contents: コンテキストを受け取るかどうか
- planner: 実行の前に計画を立てさせるために指定する。現在は以下の2つのクラスのインスタンスを指定可能。
- BuiltInPlanner: モデルに組み込まれたプランニング機能を使う。Geminiならデフォルトである程度ついてそう?
- PlanReActPlanner: ReActの実装。以下のような出力になる。
[user]: ai news [google_search_agent]: /*PLANNING*/ 1. Perform a Google search for "latest AI news" to get current updates and headlines related to artificial intelligence. 2. Synthesize the information from the search results to provide a summary of recent AI news. /*ACTION*/ /*REASONING*/ The search results provide a comprehensive overview of recent AI news, covering various aspects like company developments, research breakthroughs, and applications. I have enough information to answer the user's request. /*FINAL_ANSWER*/ Here's a summary of recent AI news: ....
- code_executor: BaseCodeExecutorインスタンスを渡すだけで、コードブロックを実行可能になる
ポイント
code executorを試してみたい。ドキュメントのサンプルにcode_executorの使い方が書いてない。
こっちに書いてた。
code_executorなし
プロンプトでコード実行するようリクエストしてみる
from google.adk.agents import Agent
root_agent = Agent(
name="code-executor",
model="gemini-2.0-flash",
description=(
"コードを実行するエージェント"
),
instruction="""You are a helpful agent that cariculates math problems.
The user will provide a question.
1. Plan the solution.
2. Write the code.
3. Execute the code.
4. Respond to the user with the result.
""",
tools=[],
)
adk webでチェック。
「1から100までの素数を教えて」と入力
コードを出力するだけで実行はしない。

code_executorあり
from google.adk.agents import Agent
+from google.adk.code_executors import BuiltInCodeExecutor
root_agent = Agent(
name="code_executor",
model="gemini-2.0-flash",
description=(
"コードを実行するエージェント"
),
instruction="""You are a helpful agent that cariculates math problems.
The user will provide a question.
1. Plan the solution.
2. Write the code.
3. Execute the code.
4. Respond to the user with the result.
""",
+ code_executor=BuiltInCodeExecutor(),
)
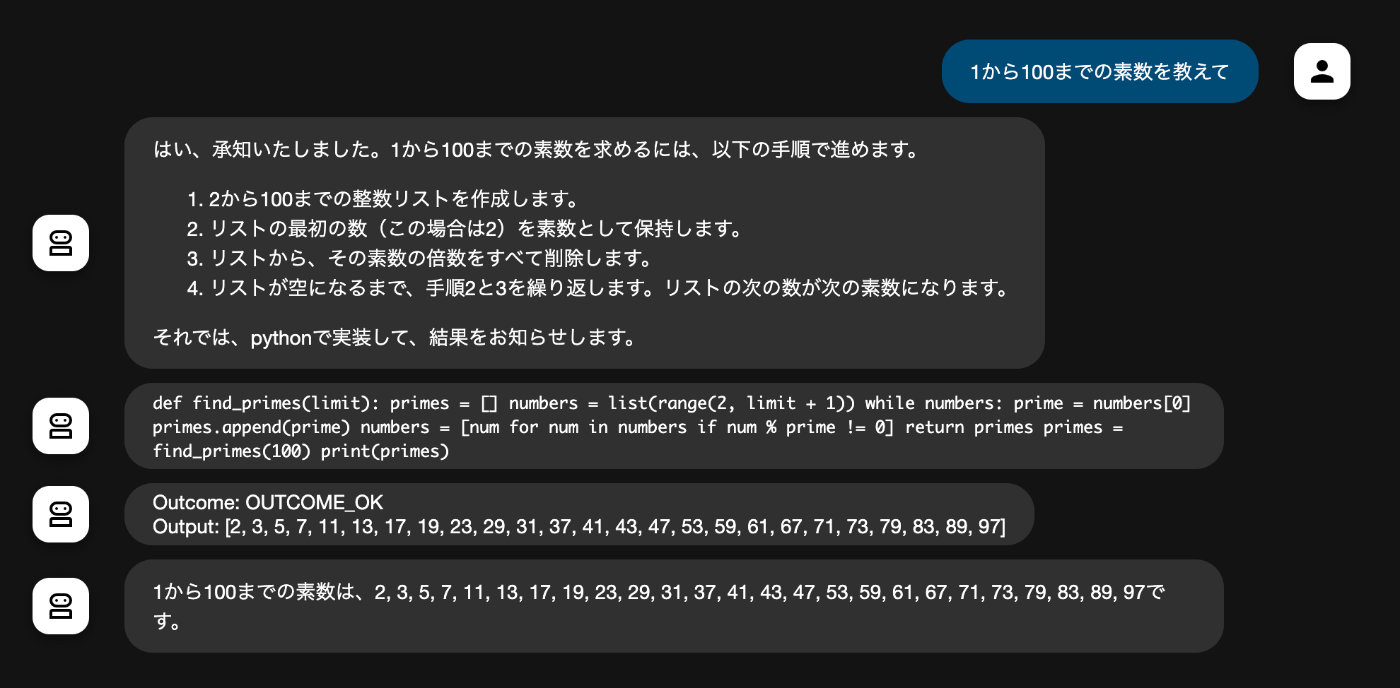
お〜。コード実行している。パースしてevalに渡したり、自分で考えなくていいのは楽。
チャット履歴の有効化
ADKでのエージェントとの会話はセッション単位で管理される。
デフォルトではサーバーを再起動するとセッションログが全て消える。
Notably, in-memory implementations are provided for both services; these are designed specifically for local testing and fast development. It's important to remember that all data stored using these in-memory options (sessions, state, or long-term knowledge) is lost when your application restarts. For persistence and scalability beyond local testing, ADK also offers cloud-based and database service options.
特筆すべきは、両サービスともインメモリ実装が用意されていることです。これらはローカルでのテストや高速な開発に特化しており、アプリを再起動すると保存されたデータ(セッション、ステート、長期知識)はすべて失われます。ローカルテスト以上の永続性やスケーラビリティが必要な場合は、クラウドベースやデータベースサービスのオプションを利用する必要があります。
Agent Development Kit
外部のブログに参考になりそうなものがある。
Session, State, Memory 概要
ADKではエージェントにコンテキストを理解させるためにSession, State, Memoryがある。
これらの概念を整理する。
- セッション:現在の会話スレッド
ユーザーとエージェントシステムとの単一の継続的なやり取りを表します。
特定のやり取りにおけるメッセージや、エージェントが行った行動(イベントと呼ばれる)の時系列の記録を含みます。
また、セッションにはこの会話中だけ有効な一時的データ(State)を保持できます。- ステート(session.state):現在の会話内のデータ
特定のセッション内に保存されるデータです。
この会話スレッドにのみ関連する情報を管理するために使用されます(例:このチャット中のショッピングカートの中身や、このセッション中に言及されたユーザー設定など)。- メモリ:検索可能なセッション横断型の情報
複数の過去セッションにまたがる情報や、外部データソースを含む可能性のある情報の保存領域を表します。
これは、直近の会話を超えて情報やコンテキストを検索し、呼び出すための知識ベースとして機能します。
Agent Development Kit
SessionService, MemoryService概要
ADKではコンテキストを管理するために2種類のサービスを提供する。
- SessionService: 異なる会話スレッドを管理
- セッションのライフサイクルを管理。作成、取得、削除はもちろん、更新ではEventsの追加やSessionの更新を行う
- MemoryService: 長期的な知識を管理
- 情報のlong-term storeへの取り込みを行う(大体は完了したSessionから取り込む)
- 保存領域への検索を行う
いずれのサービスもIn-memoryな実装が可能。ローカルでのテストやクイックな開発には十分だが、再起動時に全て消えてしまう。
永続化にはADKが提供するcloud-base, databaseオプションを利用する(これが知りたかった)。
次はさらにSessionを深掘りして、SessionServiceで外部DBでの永続化を調べよう。
Session 詳細
ユーザーがエージェントとやり取りを開始するとSessionServiceがSessionオブジェクトを作成する。
Sessionには以下のプロパティがある。
- 識別情報 (id, app_name, user_id): 以下の3つで会話スレッドを識別する
- id: 会話スレッドのID
- app_name: アプリケーション名
- user_id: ユーザーID
- 履歴 (events): このスレッド内で発生したすべてのやり取り(ユーザーのメッセージ、エージェントの応答、ツールのアクションなどの Event オブジェクト)の時系列記録。
- セッションステート (state): この進行中の会話にのみ関連する一時的なデータを保存する場所。やり取り中のエージェントの「メモ帳」として機能。
- アクティビティ追跡 (last_update_time): この進行中の会話にのみ関連する一時的なデータを保存する場所。やり取り中のエージェントの「メモ帳」として機能。
コードは以下。実にシンプルな実装。
SessionService 詳細
通常はユーザーがSessionを直接操作することはない。SessionServiceを介する。
主な役割は以下の通りです:
- 新しい会話の開始
ユーザーがやり取りを始めた際に、新しい Session オブジェクトを作成します。- 既存会話の再開
特定の Session(ID を使用して)を取得し、エージェントが中断した場所から会話を続行できるようにします。- 進行状況の保存
セッションの履歴に新しいやり取り(Event オブジェクト)を追加します。
この処理によって、セッションステート(state)も更新されます(詳細は State の章で説明)。- 会話スレッドの一覧取得
特定のユーザーとアプリケーションに関連するアクティブなセッションスレッドを検索します。- クリーンアップ
会話が終了した、または不要になった Session オブジェクトと関連データを削除します。
SessionServiceにはBaseSessionServiceを継承した
- InMemorySessionService
- VertexAiSessionService
- DatabaseSessionService
が存在し、用途に応じて使い分ける。
InMemorySessionService
- Session情報をアプリケーションのメモリに保存
- アプリケーションの再起動でデータが消える(永続化なし)
- 特に準備は必要ないのでクイックな開発、ローカルテストなど長期記憶が必要ないシーンで使う
VertexAiSessionService
- Google CloudのVertex AIインフラをAPI経由で操作
- Vertex AI Agent Engineでデータは永続化される
- GCPのプロジェクト、ストレージバケット、Reasoning Engineなどの設定が必要
- スケーラブルなプロダクション環境、他のVertexAIとの統合に最適
DatabaseSessionService
- relational databaseに接続してセッションデータを保存
- データベースで永続化される
- データベースが必要
- 自分でデータベースを管理したい時に最適
その前に、実際のエージェントでチャット履歴を永続化する方法を確認しておこう。
これまでAgentオブジェクトしか使っておらず、その裏でのSessionServiceがどう利用されているか意識していなかった。
root_agent = Agent(
name="weather_time_agent",
model="gemini-2.0-flash",
description=(
"Agent to answer questions about the time and weather in a city."
),
instruction=(
"You are a helpful agent who can answer user questions about the time and weather in a city."
),
tools=[get_weather, get_current_time],
)
上記のようなどシンプルな実装では裏のSessionServiceの取り扱いが隠されているので紐解く必要あり。
State 詳細
この説明が一番わかりやすい
session.events が会話の完全な履歴を保持するのに対し、session.state は会話中に必要な動的な情報を保存・更新する場所です。
具体的な使い道は
- パーソナライズ
ユーザーの好みを記憶(例: 'user_preference_theme': 'dark')- タスク進行状況の追跡
複数ターンのプロセス進捗を管理(例: 'booking_step': 'confirm_payment')- 情報の蓄積
リストや要約を構築(例: 'shopping_cart_items': ['book', 'pen'])- 意思決定のための記録
次の応答に影響するフラグや値(例: 'user_is_authenticated': True)
Sessionのプロパティなので、SessionSeriveceでSessionが永続化されていれば合わせて残される。InMemorySessionServiceだと消える。
構造はシンプルな辞書形式。
class State:
"""A state dict that maintain the current value and the pending-commit delta."""
APP_PREFIX = "app:"
USER_PREFIX = "user:"
TEMP_PREFIX = "temp:"
def __init__(self, value: dict[str, Any], delta: dict[str, Any]):
"""
Args:
value: The current value of the state dict.
delta: The delta change to the current value that hasn't been committed.
"""
self._value = value
self._delta = delta
def __getitem__(self, key: str) -> Any:
"""Returns the value of the state dict for the given key."""
if key in self._delta:
return self._delta[key]
return self._value[key]
def __setitem__(self, key: str, value: Any):
"""Sets the value of the state dict for the given key."""
# TODO: make new change only store in delta, so that self._value is only
# updated at the storage commit time.
self._value[key] = value
self._delta[key] = value
def __contains__(self, key: str) -> bool:
"""Whether the state dict contains the given key."""
return key in self._value or key in self._delta
def has_delta(self) -> bool:
"""Whether the state has pending delta."""
return bool(self._delta)
def get(self, key: str, default: Any = None) -> Any:
"""Returns the value of the state dict for the given key."""
if key not in self:
return default
return self[key]
def update(self, delta: dict[str, Any]):
"""Updates the state dict with the given delta."""
self._value.update(delta)
self._delta.update(delta)
def to_dict(self) -> dict[str, Any]:
"""Returns the state dict."""
result = {}
result.update(self._value)
result.update(self._delta)
return result
会話の進行に合わせて値が可変するのが特徴。
prefixをつけることでユーザー単位、アプリ単位で共有することが可能。
- プレフィックスなし(セッションスコープ)
- 現在のセッションだけで有効
- 例: session.state['current_intent'] = 'book_flight'
- user:(ユーザースコープ)
- 同一ユーザーの全セッションで共有
- 例: session.state['user:preferred_language'] = 'fr'
- app:(アプリケーションスコープ)
- 同一アプリの全ユーザー・全セッションで共有
- 例: session.state['app:global_discount_code'] = 'SAVE10'
- temp:(一時スコープ)
- 現在の処理ターンのみ有効、永続化されない
- 例: session.state['temp:raw_api_response'] = {...}
アプリケーションスコープの取り扱いは注意が必要
State 詳細2
エージェントへの指示でSessionの値を埋め込むことが可能。
from google.adk.agents import LlmAgent
story_generator = LlmAgent(
name="StoryGenerator",
model="gemini-2.0-flash",
instruction="""Write a short story about a cat, focusing on the theme: {topic}."""
)
インストラクション内で波括弧でsession.stateを呼び出すことができる。
{topic}にはsession.state["topic"]が埋め込まれる。
インストラクションにテンプレート言語などを埋め込みたい時(文字として二重波括弧を使いたい時)がある。
そのような場合にはInstructionProviderを使う。
以下のように、instructionに関数をセットすることでstate injection回避できる。
from google.adk.agents import LlmAgent
from google.adk.agents.readonly_context import ReadonlyContext
# This is an InstructionProvider
def my_instruction_provider(context: ReadonlyContext) -> str:
# You can optionally use the context to build the instruction
# For this example, we'll return a static string with literal braces.
return "This is an instruction with {{literal_braces}} that will not be replaced."
agent = LlmAgent(
model="gemini-2.0-flash",
name="template_helper_agent",
instruction=my_instruction_provider
)
そしてInstructionProviderとstate injectionを両方使いたい時は、inject_session_stateを使う。
from google.adk.agents import LlmAgent
from google.adk.agents.readonly_context import ReadonlyContext
from google.adk.utils import instructions_utils
async def my_dynamic_instruction_provider(context: ReadonlyContext) -> str:
template = "This is a {adjective} instruction with {{literal_braces}}."
# This will inject the 'adjective' state variable but leave the literal braces.
return await instructions_utils.inject_session_state(template, context)
agent = LlmAgent(
model="gemini-2.0-flash",
name="dynamic_template_helper_agent",
instruction=my_dynamic_instruction_provider
)
inject_session_stateではインストラクション内の波括弧で括られた部分を正規表現で取得し、その値がstateに存在すれば置換、存在しなければそのまま通すようにしている。
State 詳細3
Stateの更新は、関数に渡される Context オブジェクト上の state を直接変更すること。
callback_context.state['my_key'] = 'new_value'
Sessionのstateを直接編集すると、ADKのイベント追跡機構をバイパスしてしまい、情報が残らない可能性があるので注意。
my_session.state['my_key'] = 'new_value'
State は必ず、session_service.append_event() を使って、セッション履歴に Event を追加する過程で更新してください。
これにより:
- 変更が正しく追跡される
- 永続化が正しく機能する
- スレッドセーフに更新される
State 設計のベストプラクティスまとめ
- 最小化(Minimalism)
必要不可欠かつ動的なデータだけを保存する。- シリアライズ可能性(Serialization)
基本的でシリアライズ可能な型を使用する。- わかりやすいキー名とプレフィックス(Descriptive Keys & Prefixes)
明確な名前と適切なプレフィックス(user:、app:、temp:、またはなし)を使う。- 浅い構造(Shallow Structures)
可能な限り深いネスト構造を避ける。- 標準的な更新フロー(Standard Update Flow)
append_eventを介して更新する。
振り返り
セッションを永続化させる方法はわかった。VertexAISessionSerive, DatabaseSessionServiceを使ってセッションを管理すればいい。しかしJupyter Notebookで逐次的に処理するような実装しか例がない。
これまでAgentオブジェクトをインスタンス化し、adk webでウェブUIを立ち上げて動作確認をしていた。adk webが裏でSessionServiceをどのように利用しているかを覆い隠している。
新しい概念(SessionService)とチュートリアルのadk webが繋がっていないのでどう実装するかわからない。adk webを改造するのは絶対に避けたい(経験上ろくなことにならない)。
adk webは便利だが、履歴の永続かなどできないのなら自前でUIを実装する必要があるか?
Agent Engineへのデプロイで自動的に永続化される
朗報!
When an AdkApp is deployed to Agent Engine, it automatically uses VertexAiSessionService for persistent, managed session state. This provides multi-turn conversational memory without any additional configuration.
AdkApp を Agent Engine にデプロイすると、自動的に VertexAiSessionService が使用され、永続的かつ管理されたセッションステートが提供されます。
これにより、追加の設定を行わなくても複数ターンにわたる会話メモリが利用可能になります。
Agent Development Kit
ここまでCloud Runへのデプロイをしていたが、そういうことならAgent Engineにデプロイしたい。
コストは気になるが、PoCなので一旦度外視。
が、どうもコマンド経由でしか操作していなさそうだった。
以下のブログ記事を見るに、GUIは存在しない様子...。
困った。
ADKは基本的にバックエンド利用がメインなのかなぁ。
adk deployコマンドでは裏側でコンテナを作っているので中身は不明だった。
が、以下のgcloud CLI経由でデプロイするコードを見ると、get_fast_api_appでウェブUIを作っていることがわかる。
get_fast_api_app()はsession_service_uriを指定できる。ここをうまく使えば外部DBに連携できる?
get_fast_api_app() を利用してCloud SQLにチャット履歴を残す
ここまでの情報まとめ
- adk deployで簡単にデプロイできるデプロイ先はCloud Run, Agent Engine, GKE
-
adk deploy cloud_runコマンドでデプロイする場合、簡単にデプロイできるが細かい設定ができニア -
adk deploy cloud_runコマンドの裏では、DockerfileとFastAPIの実行ファイル(main.py)を取得し、gcloud CLIコマンドでCloud Runにデプロイしている - FastAPIのmain.pyではget_fast_api_app() 関数でFastAPI Appインスタンスを取得している
- get_fast_api_app() 関数はsession_service_uriを引数に指定でき、DatabaseSessionServiceを利用することができる
以上より、adk deploy cloud_runを使わず、Dockerfileとmain.pyを用意して直接gcloud CLIでCloud Runにデプロイすればチャット履歴についてはカスタマイズ可能、と仮説を立てた。
実際に試してみる。
Cloud SQLの立ち上げ
今回、チャット履歴の保存先としてCloud SQLを選択した。
main.pyの作成
公式の実装を参考にする。
import os
import uvicorn
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
SESSION_SERVICE_URI = f"{db_url}?host=/cloudsql/{connection_name}"
ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"]
SERVE_WEB_INTERFACE = True
app = get_fast_api_app(
agents_dir=AGENT_DIR,
session_service_uri=SESSION_SERVICE_URI,
allow_origins=ALLOWED_ORIGINS,
web=SERVE_WEB_INTERFACE,
)
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080))
Dockerfileは
FROM python:3.13-slim
WORKDIR /app
# Install system dependencies for PostgreSQL
RUN apt-get update && apt-get install -y \
gcc \
postgresql-client \
&& rm -rf /var/lib/apt/lists/*
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
RUN adduser --disabled-password --gecos "" myuser && \
chown -R myuser:myuser /app
COPY . .
USER myuser
ENV PATH="/home/myuser/.local/bin:$PATH"
CMD ["sh", "-c", "uvicorn main:app --host 0.0.0.0 --port $PORT"]
ローカルでPostgreSQLをDockerで立ち上げよしなに繋げればチャット履歴の永続化ができた!
次はCloud RunでCloud SQLにチャット履歴を保存させるようにしてみる。
Claude Codeでサクッとできた。
万歳。
と思ったが、ユーザー間でセッション履歴が共通されてしまった。
どうやらすべてのセッションでuser_idが"user"として保存されている。
ログインしているユーザー固有の値を取得していない。
どこで定義されているか探す。
Cloud Run - デプロイ
Cloud Runへのデプロイは非常に簡単。
adk deployコマンドを使うとDockerfileなど意識しなくても良い。
adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--service_name=$SERVICE_NAME \
--app_name=$APP_NAME \
--with_ui \
$AGENT_PATH
requirements.txtを置くのを忘れないように。
Cloud Run - 認証
Cloud RunでIAP (Identity-Aware Proxy) を有効にすることでデプロイしたアプリケーションを限られたユーザーにのみ公開することができる。
IAPを有効にする方法には
- Cloud Run で IAP を直接有効にする
- Cloud Run サービスの前に配置するバックエンド サービスで有効にする
の2つの選択肢がある。
公式では前者をお勧めしているが制限があるので注意が必要。
Cloud Run サービスで IAP を有効にする方法は 2 つあります。Cloud Run サービスで直接有効にするか、Cloud Run サービスの前に配置するバックエンド サービスで有効にします。
Cloud Run で IAP を直接有効にすることをおすすめします。これにより、run.app エンドポイントと、ロードバランサを構成した場合はロードバランサ エンドポイントも保護されます。
IAP for Cloud Run の有効化 | Identity-Aware Proxy | Google Cloud
1. Cloud Run で IAP を直接有効にする
Cloud Runにはプレビュー版の機能だがIAP for Cloud Runが存在する。
Cloud Run 用に Identity-Aware Proxy を構成する | Cloud Run Documentation | Google Cloud
Cloud Runのセキュリティから有効化できる。
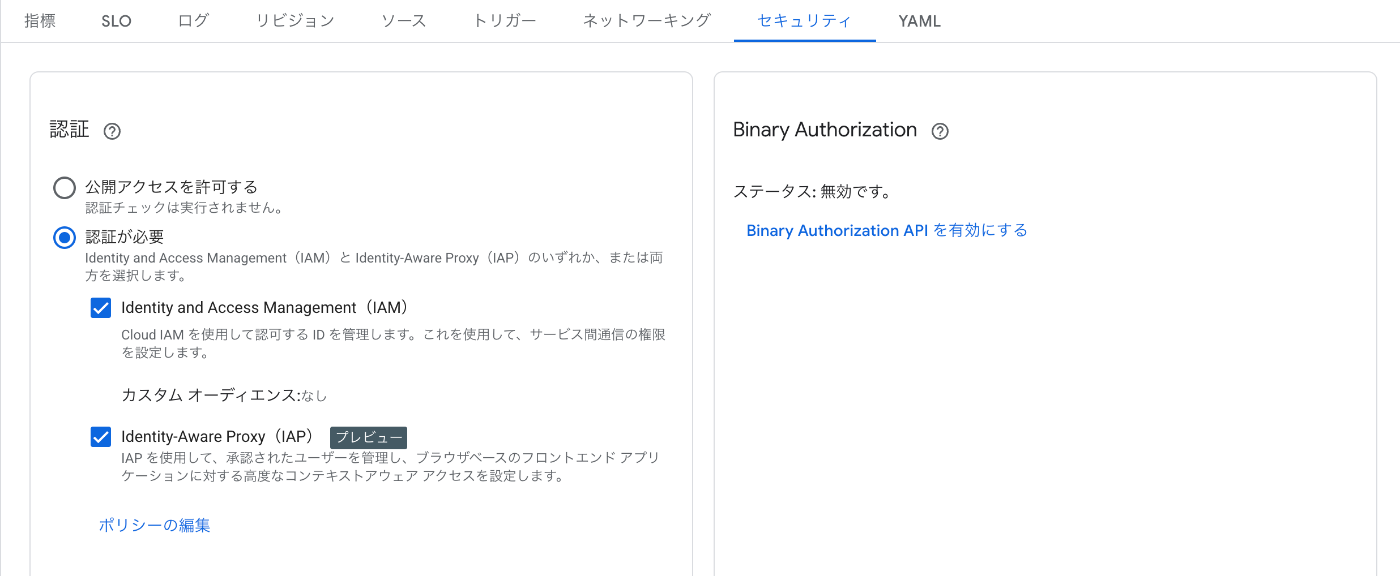
あるいはcli経由でも簡単に有効化できる。
gcloud beta run services update SERVICE_NAME \
--region=REGION \
--iap
2. Cloud Run サービスの前に配置するバックエンド サービスで有効にする
ドキュメントとTerraformのサンプルが用意されている。ありがたい。
サンプル
prompt.pyにプロンプトを書き、

以下のようにインポートするのが主流っぽい。
from . import prompt
MODEL = "gemini-2.5-pro"
academic_newresearch_agent = Agent(
model=MODEL,
name="academic_newresearch_agent",
instruction=prompt.ACADEMIC_NEWRESEARCH_PROMPT,
)
コアコンセプト
順番前後するが、本腰入れて理解するために基礎から理解。
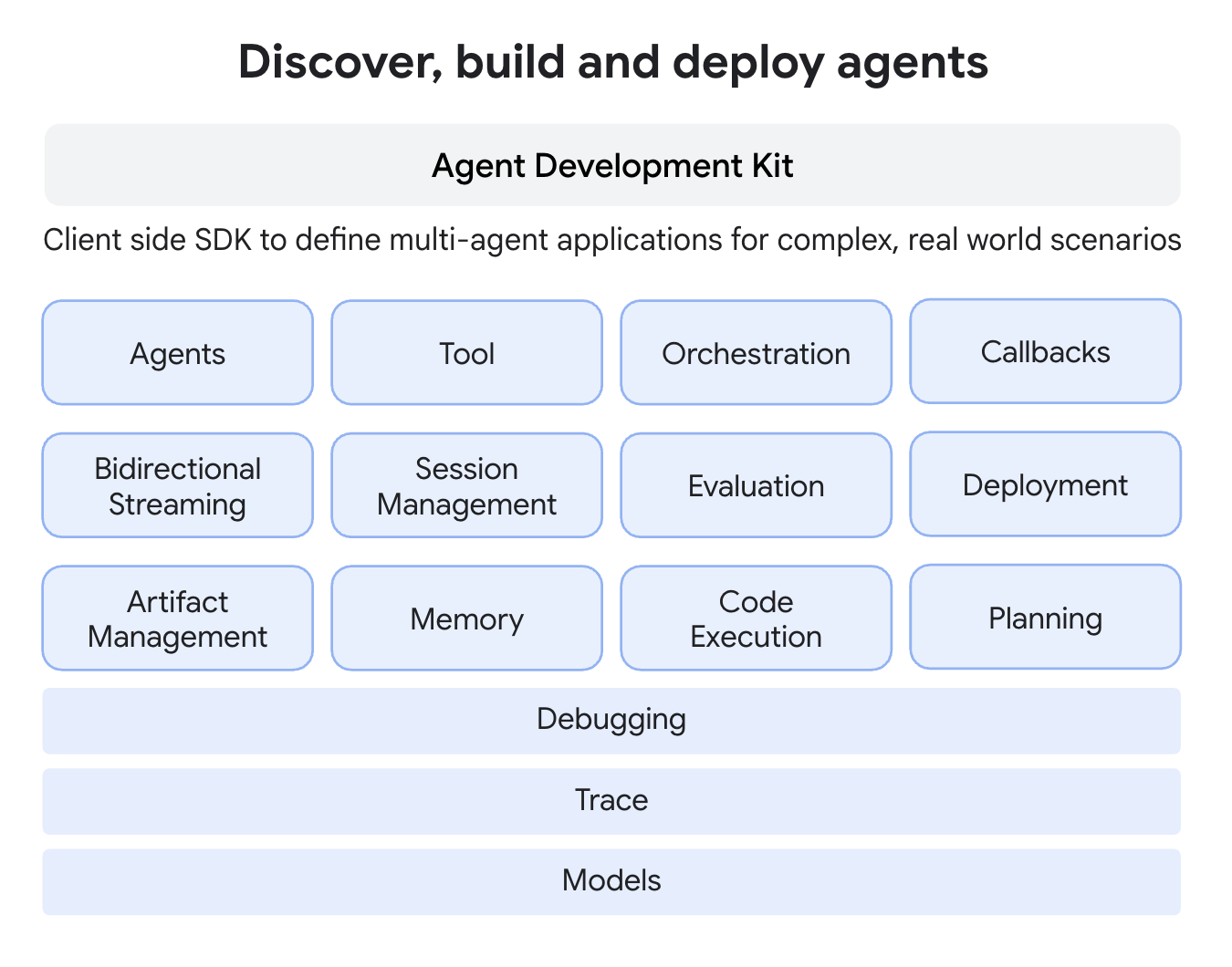
以下がADKのプリミティブ
- エージェント(Agent): 特定のタスク用に設計された基本的な作業単位。エージェントは複雑な推論のために言語モデル(LlmAgent)を使用できるほか、「ワークフローエージェント」(SequentialAgent、ParallelAgent、LoopAgent)と呼ばれる実行の決定論的コントローラーとして動作することもできます。
- ツール(Tool): エージェントに会話以上の能力を与え、外部API、情報検索、コード実行、または他のサービスの呼び出しとのやり取りを可能にします。
- コールバック(Callbacks): エージェントのプロセスの特定のポイントで実行するために提供するカスタムコードスニペットで、チェック、ログ記録、または動作の変更を可能にします。
- セッション管理(Session & State): 単一の会話のコンテキスト(Session)を処理し、その履歴(Events)とその会話に対するエージェントの作業メモリ(State)を含みます。
- メモリ(Memory): エージェントが複数のセッションにわたってユーザーに関する情報を記憶できるようにし、長期的なコンテキストを提供します(短期的なセッションStateとは別物)。
- アーティファクト管理(Artifact): エージェントがセッションまたはユーザーに関連付けられたファイルやバイナリデータ(画像、PDFなど)を保存、読み込み、管理できるようにします。
- コード実行(Code Execution): エージェント(通常はツール経由)が複雑な計算やアクションを実行するためにコードを生成し実行する能力。
- プランニング(Planning): エージェントが複雑な目標をより小さなステップに分解し、ReActプランナーのようにそれらを達成する方法を計画できる高度な機能。
- モデル(Models): LlmAgentを動かす基盤となるLLMで、推論と言語理解能力を実現します。
- イベント(Event): セッション中に発生する事柄(ユーザーメッセージ、エージェントの返信、ツールの使用)を表す基本的な通信単位で、会話履歴を形成します。
- ランナー(Runner): 実行フローを管理し、イベントに基づいてエージェントの相互作用を調整し、バックエンドサービスと連携するエンジン。
チュートリアル
ざっとどんなことができるか見てみる。
Learn to build an intelligent multi-agent weather bot and master key ADK features: defining Tools, using multiple LLMs (Gemini, GPT, Claude) with LiteLLM, orchestrating agent delegation, adding memory with session state, and ensuring safety via callbacks.
インテリジェントなマルチエージェント天気ボットの構築方法を学び、主要なADK機能をマスターしましょう:ツールの定義、LiteLLMを使用した複数のLLM(Gemini、GPT、Claude)の活用、エージェント委譲のオーケストレーション、セッション状態によるメモリの追加、コールバックによる安全性の確保。再試行Claudeは間違えることがあります。回答内容を必ずご確認ください。
Agent Development Kit
チュートリアルではシンプルな実装から始めて以下の実装方法を学ぶ
- 異なるAIモデル(Gemini、GPT、Claude)を活用する。
- 挨拶や別れの言葉など、特定のタスクのために専門的なサブエージェントを設計する。
- エージェント間で知的な委任を可能にする。
- 永続的なセッション状態を使用してエージェントに記憶を与える。
- コールバックを使用して重要な安全対策を実装する。
特に永続的なセッションによるチャット履歴の保存が気になる。
Tools
ツールとは AI エージェントに特定の能力を与えるものであり、テキスト生成や推論といった中核的な能力を超えて行動したり外部とやり取りしたりすることを可能にします。
高度なエージェントと単純な言語モデルを区別する要因は、多くの場合、このツールの効果的な活用にあります。
Agent Development Kit
特徴
- Action-Oriented: データベース問い合わせやウェブ検索などのアクションを実行
- Extends Agent capabilities: リアルタイム情報へのアクセス、外部システムへの働きかけなど
- Execute predefined logic: ツール自体はエージェントの中核である大規模言語モデル(LLM)のような独立した推論能力を持他ない。LLM は「どのツールを、いつ、どの入力で使うか」を判断するが、ツール自体は与えられた機能だけを実行する。
エージェントがツールを使う方法
- 推論(Reasoning)
エージェントのLLMが、システム指示、会話履歴、ユーザーからのリクエストを分析します。- 選択(Selection)
分析結果に基づき、エージェントが利用可能なツールと、そのツールを説明するdocstring(ドキュメンテーション文字列)を参考に、実行するツールを決定します(必要ない場合は使わない)。- 呼び出し(Invocation)
選択したツールに必要な引数(入力値)をLLMが生成し、ツールを実行します。- 観測(Observation)
ツールから返された出力(結果)を受け取ります。- 最終化(Finalization)
ツールの出力を、エージェントの継続的な推論プロセスに組み込み、次の応答を作成したり、次に取るべき行動を決定したり、目標達成を判断します。
ADKのツールタイプ
- Function Tools: 自分で作成し、特定のアプリケーションのニーズに合わせたツール。
- Functions/Methods: コード内で定義した標準的な同期関数やメソッド(例: Python の def)。
- Agents-as-Tools: 別の(場合によっては特化型の)エージェントを、親エージェントのツールとして利用する方法。
- Long Running Function Tools: 非同期処理や、完了までに時間がかかる処理を行うツール。- Built-in Tools: フレームワークが標準で提供する、すぐに使えるツール。例: Google検索、コード実行、RAG(情報検索+生成)。
- Third-Party Tools: 外部の人気ライブラリからシームレスに統合できるツール。例: LangChain Tools、CrewAI Tools。
Built-in Tools
コード実行やGoogle検索などのビルトインのツールが用意されている。
ただし、制限がある。
- 現在、各ルートエージェントまたは単一エージェントにつき、利用できる組み込みツールは1つだけ。同じエージェント内で、他種類を含む他のツールは一切使用できない。
以下のようにBuiltInCodeExecutorを他のツールと併用はできない。
root_agent = Agent(
name="RootAgent",
model="gemini-2.0-flash",
description="Root Agent",
tools=[custom_function, BuiltInCodeExecutor], # <-- BuiltInCodeExecutor not supported when used with tools
)
- 組み込みツールはサブエージェント内では使用できない
以下のようにビルトインツールをサブエージェントとして使うことはできない。
search_agent = Agent(
model='gemini-2.0-flash',
name='SearchAgent',
instruction="""
You're a specialist in Google Search
""",
tools=[google_search],
)
coding_agent = Agent(
model='gemini-2.0-flash',
name='CodeAgent',
instruction="""
You're a specialist in Code Execution
""",
tools=[BuiltInCodeExecutor],
)
root_agent = Agent(
name="RootAgent",
model="gemini-2.0-flash",
description="Root Agent",
sub_agents=[
search_agent,
coding_agent
],
)
上記制限、
- 組み込みツールは他のツールと併用できない
- 組み込みツールはサブエージェントで使えない
を踏まえて「ルートエージェントに組み込みツールを1つだけ配置し、他のツールはサブエージェントとして使わせる」方針を試してみる。
制限に該当しないよう、ルートで組み込みツールを使い、他のツールはサブエージェントとして渡したがダメだった。
database_agent = Agent(
model='gemini-2.0-flash',
name='DatabaseAgent',
instruction=DATABASE_AGENT_INSTRUCTION,
tools=[pubmed_tool],
)
root_agent = Agent(
name="root_agent",
model="gemini-2.0-flash",
instruction=ROOT_AGENT_INSTRUCTION,
code_executor=BuiltInCodeExecutor(), # ルートでコード実行
sub_agents=[database_agent], # サブエージェントで外部ツール
)
以下のエラー。
{"error": "400 INVALID_ARGUMENT. {'error': {'code': 400, 'message': 'Tool use with function calling is unsupported', 'status': 'INVALID_ARGUMENT'}}"}
BuiltInCodeExecutorの中身をさらに追ってみると、最終的にはGoogle Gen AIのToolCodeExecution()を使っていることがわかる。
ToolCodeExecutionは以下のように使うもの。Gen AI SDKは触ったことがないので想像になるが、ToolCodeExecutionをツール化して渡すと、入力クエリをコードに変換、コードを実行して結果を返す、ということができているっぽい。
from google import genai
from google.genai.types import (
HttpOptions,
Tool,
ToolCodeExecution,
GenerateContentConfig,
)
client = genai.Client(http_options=HttpOptions(api_version="v1"))
model_id = "gemini-2.5-flash"
code_execution_tool = Tool(code_execution=ToolCodeExecution())
response = client.models.generate_content(
model=model_id,
contents="Calculate 20th fibonacci number. Then find the nearest palindrome to it.",
config=GenerateContentConfig(
tools=[code_execution_tool],
temperature=0,
),
)
print("# Code:")
print(response.executable_code)
print("# Outcome:")
print(response.code_execution_result)
# Example response:
# # Code:
# def fibonacci(n):
# if n <= 0:
# return 0
# elif n == 1:
# return 1
# else:
# a, b = 0, 1
# for _ in range(2, n + 1):
# a, b = b, a + b
# return b
#
# fib_20 = fibonacci(20)
# print(f'{fib_20=}')
#
# # Outcome:
# fib_20=6765
なお、以下の通りかなり限定されたことしかできない。これはADK上でも同じだろう。
コード実行環境には、次のライブラリが含まれています。独自のライブラリをインストールすることはできません。
Altair
Chess
Cv2
Matplotlib
Mpmath
NumPy
Pandas
Pdfminer
Reportlab
Seaborn
Sklearn
Statsmodels
Striprtf
SymPy
Tabulate
Gen AIのToolCodeExecutionをさらに深ぼってみる。
クラス自体には実装がない。
class ToolCodeExecution(_common.BaseModel):
"""Tool that executes code generated by the model, and automatically returns the result to the model.
See also [ExecutableCode]and [CodeExecutionResult] which are input and output
to this tool.
"""
pass
このクラスの入出力をチェック。
入力はExecutableCode。codeとlanguageが指定される。
class ExecutableCode(_common.BaseModel):
"""Code generated by the model that is meant to be executed, and the result returned to the model.
Generated when using the [CodeExecution] tool, in which the code will be
automatically executed, and a corresponding [CodeExecutionResult] will also be
generated.
"""
code: Optional[str] = Field(
default=None, description="""Required. The code to be executed."""
)
language: Optional[Language] = Field(
default=None,
description="""Required. Programming language of the `code`.""",
)
出力はCodeExecutionResult。outcome (コードの結果) とoutput (標準出力) で構成される。
class CodeExecutionResult(_common.BaseModel):
"""Result of executing the [ExecutableCode].
Only generated when using the [CodeExecution] tool, and always follows a
`part` containing the [ExecutableCode].
"""
outcome: Optional[Outcome] = Field(
default=None, description="""Required. Outcome of the code execution."""
)
output: Optional[str] = Field(
default=None,
description="""Optional. Contains stdout when code execution is successful, stderr or other description otherwise.""",
)
セッション履歴が共有される問題
ADKではセッションはcreate_session()でid (session id), app_name, user_idを指定することで一意に定めることができる。ADKをバックエンドとして使う場合は上記関数を使えば問題ない。
しかし、Web UIとしてデプロイすると話が変わってくる。
例えばCloud Runへのデプロイ方法はチュートリアルがある。
adk deployコマンドを利用すると内部の処理が見えないが、gcloud CLIでデプロイする方法の説明を見ると実態がよくわかる。
エージェントを実装するコードの他に、DockerfileとFastAPI製のmain.py、そしてrequirements.txtを追加しこれらからコンテナイメージをビルドしてCloud Runにデプロイしていることがわかる。
your-project-directory/
├── capital_agent/
│ ├── __init__.py
│ └── agent.py # Your agent code (see "Agent sample" tab)
├── main.py # FastAPI application entry point
├── requirements.txt # Python dependencies
└── Dockerfile # Container build instructions
Web UIの詳細はさらにmain.pyを深掘りすると明らかになる(見やすさのためコメントを除去)。
import os
import uvicorn
from google.adk.cli.fast_api import get_fast_api_app
AGENT_DIR = os.path.dirname(os.path.abspath(__file__))
SESSION_SERVICE_URI = "sqlite:///./sessions.db"
ALLOWED_ORIGINS = ["http://localhost", "http://localhost:8080", "*"]
SERVE_WEB_INTERFACE = True
app = get_fast_api_app(
agent_dir=AGENT_DIR,
session_db_url=SESSION_SERVICE_URI,
allow_origins=ALLOWED_ORIGINS,
web=SERVE_WEB_INTERFACE,
)
if __name__ == "__main__":
# Use the PORT environment variable provided by Cloud Run, defaulting to 8080
uvicorn.run(app, host="0.0.0.0", port=int(os.environ.get("PORT", 8080)))
get_fast_api_appを呼び出しているとわかる。
get_fast_api_appをさらに遡ってみよう。
def get_fast_api_app(
*,
agents_dir: str,
session_service_uri: Optional[str] = None,
session_db_kwargs: Optional[Mapping[str, Any]] = None,
artifact_service_uri: Optional[str] = None,
memory_service_uri: Optional[str] = None,
eval_storage_uri: Optional[str] = None,
allow_origins: Optional[list[str]] = None,
web: bool,
a2a: bool = False,
host: str = "127.0.0.1",
port: int = 8000,
trace_to_cloud: bool = False,
reload_agents: bool = False,
lifespan: Optional[Lifespan[FastAPI]] = None,
) -> FastAPI:
...
if web:
BASE_DIR = Path(__file__).parent.resolve()
ANGULAR_DIST_PATH = BASE_DIR / "browser"
extra_fast_api_args.update(
web_assets_dir=ANGULAR_DIST_PATH,
)
...
上記の、if webの分岐のすすみ、Angular製のコードをweb_assets_dirとして渡していることがわかる。該当箇所は以下。
src/google/adk/cli/browser/ にはビルド済みのファイルがある。get_fast_api_app() これを呼び出している。
browser
├── adk_favicon.svg
├── assets
│ ├── ADK-512-color.svg
│ ├── audio-processor.js
│ └── config
│ └── runtime-config.json
├── chunk-EQDQRRRY.js
├── chunk-TXJFAAIW.js
├── index.html
├── main-W7QZBYAR.js
├── polyfills-B6TNHZQ6.js
└── styles-4VDSPQ37.css
minify、難読化されており、人間が読むことは難しい。
この中でバックエンドのAPIを呼び出すときにuserIdにuserをハードコーディングしているとのこと。
Claude Code曰く
はい、元のソースコードはなく、ビルド済みのバンドルのみです。
- ファイル名にハッシュ付き(例:main-W7QZBYAR.js)
- 極端に長い行(最大32,167文字)でminify済み
- モジュールバンドラー(おそらくWebpack/Vite)でビルド
- Google ADKパッケージの一部として配布
これはPythonパッケージに含まれるプリビルド済みのWeb UIで、開発時のソースコードは含まれていません。
⏺ 申し訳ございませんが、minify済みのJavaScriptコードから、userIdに"user"という文字列を設定している具体的な箇所を特定することは困難です。
コードは高度に圧縮・難読化されており:
- 変数名が短縮(例:userId → o)
- 改行が削除され1行に結合
- 空白が最小化
- 関数名も短縮
adk-webに元のソースコードがある?
google/adk/cli/browser/ は上記をコンパイルしたもの?
こっちをうまいこと持ってきた方が助かるか?
どこが対応しているのかいまいちよくわからない。