今日は機械学習ってやつを勉強していくぜぇ〜〜!!
モチベ
mjx(bertのコード)が全然分からずに萎えたため
あまりにも初心すぎて激萎えしており、python3エンジニア試験とかいう胡散臭い試験のデータ分析の更にその初級ぐらいが勉強にちょうどいいことに気づいてしまった(激萎え)
機械学習における微分は、最小値を求める際に利用します。scikit-learnを使えば微分を知らなくても学習モデルを作れますが、微分が分かると仕組みが理解できます。
scikit-learnのmodel学習には微分を使う
微分基礎の基礎から学び直してる
ベクトルは使う機会も多く、皆さん馴染みがあるかと思います。
ないが・・・
連立方程式は行列で表せる
平均変化率=xの値がa->bまで変化する時のyの値のX(a)->X(b)の変化率
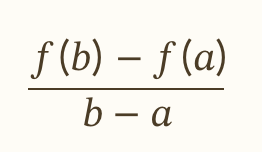
動的計算グラフと静的計算グラフについて
Rustとpython的な
torch動的でtfは静的
torch.tensor.backwardについて
backward()を使うにはtensor(, require_grad=true)が必要
あとtensorの第一引数がfloatである必要がある
kerasという文字列が見えたらtf
統計学
- 共分散
- 相関係数
共分散と相関係数はデータセット内の変数間の関係を整理するのに役立つ
共分散はDS内の変数がどの程度一緒か(-1から1の値をとる)
相関係数は共分散を変数の標準偏差で割ったもの。
見せかけの回帰(suprious regression)と擬似相関(suprious correlation)は別物
そもそも回帰とは
回帰は変数間の関係をモデル化するために用いられる
目的変数==応答変数であり説明変数==特徴量である
回帰
回帰の種類には多重回帰、ロジスティック回帰や線形回帰、リッジ回帰などがある
回帰、分類は全部教師あり学習
線形回帰、漸化式っぽい。
分類はn個のデータがあってそれをクラスタリングする感じ。線形回帰はn個のデータをプロットして線を引く
推測統計学と記述統計学
事象もベン図で表せる

確率分布とXがFに従うという用語について
確率変数ー>目的変数的な感じ。サイコロ投げだったらサイコロの目が確率変数になる。サイコロなら確率変数Saikoroが6面全て1/6で確率分布になる。
連続的確率変数と離散的確率変数
連続的確率変数が気温で離散的確率変数がサイコロの目
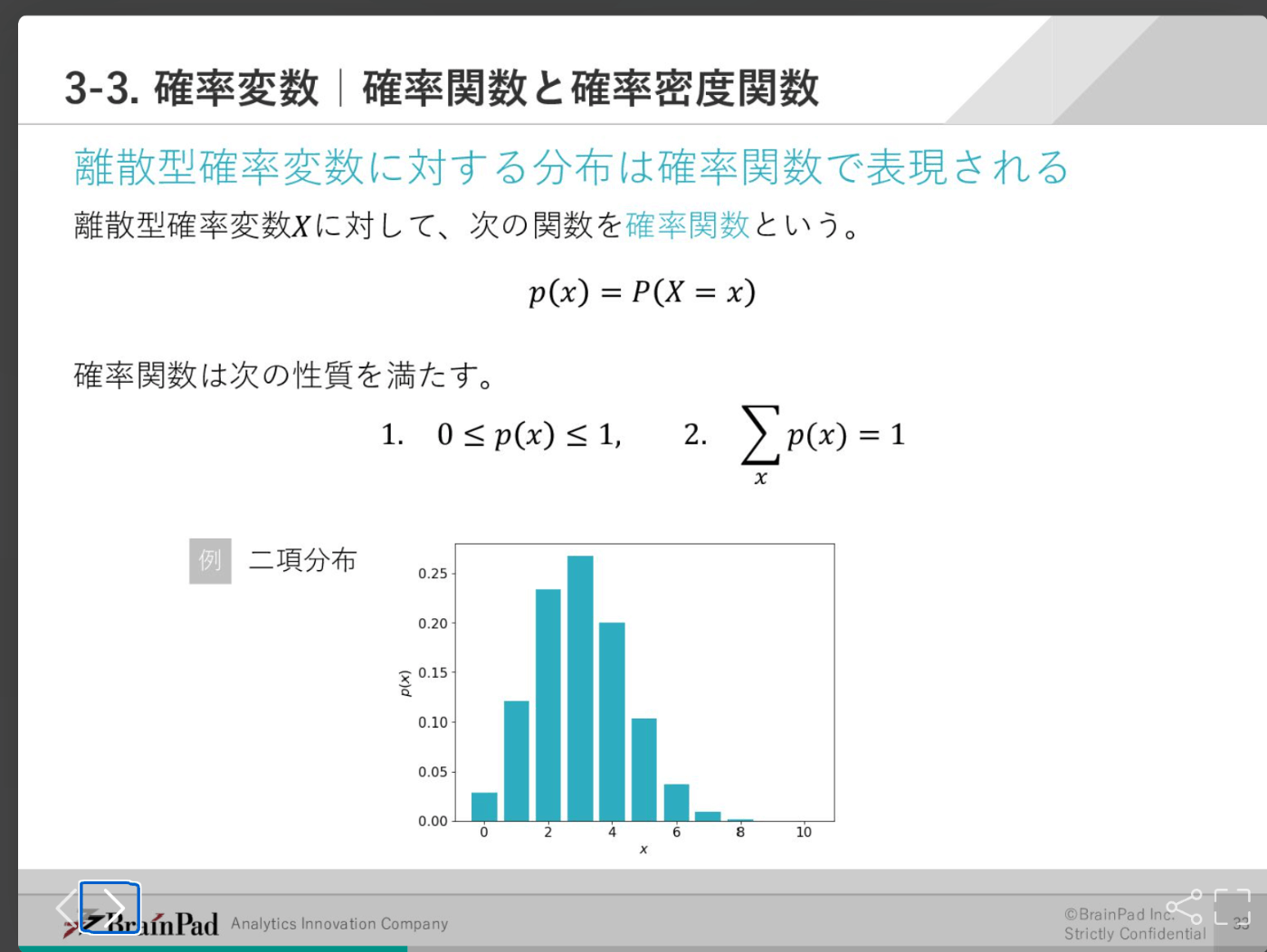
確率関数と確率密度関数
確率関数は離散的確率変数の確立を求める
確率密度関数は連続的確率変数の確立を求める
回帰の評価指標・・・モデルのパフォーマンス計測で使われる。openevalとか?過学習の検知とかでも回帰の評価指標が使われる。
平均二乗誤差
平均絶対誤差
R二乗
例えば過学習の検知にはMSEが使われる。
セガが公開している基礎線形代数講座
線形代数を一言でいうと線形な(連続した)性質を持つ対象を代数の力で読み解く
自然数N
有理数Q(分数で表すことができる数)
1~2の間は無限に広がっていてこのような性質を稠密という
可算集合
自然数Nと濃度が等しい集合
集合Aのそれぞれの要素に対して集合Bの要素をひとつづつ定める規則のことをAからBへの写像という
集合Aを始集合(initial set)と呼び、集合Bを終集合(final set)と呼ぶ
写像の像・・・A{a}に対するB{b}
関数(集合)は始集合と終集合がともにRもしくはその部分集合からなる集合。Rはすべての実数の集合
実数には有理数と無理数が含まれるのでQとRとNはすべて別物。
写像の例: 1つのPCと1つのOSの組み合わせなど

この辺になってくるとついていけないですね・・・諦め
多価関数(Multivalued Function)と1価関数(Single-valued Function)
多価関数は1対nの関数ということですか?->はいらしいです、gpt-3.5くんによると。
恒等写像・・・A->Aの写像
単射(injection)
シグモイド活性化関数
ReLuの仲間。
活性化関数の一つ。0~1の間の数を返す。出力層では一般的だが、隠れ層ではあまり使われない。
活性化関数
activation functionはnnの各ニューロンの出力を決定する関数。

フィードフォワードnnはmlpともいう(バナナ)。
maxpoolについて
この記事かなり分かりやすい
この画像もいい
教師あり学習には回帰と分類がある
DQNの実装サンプルより。
torch.nn.functional(通常 F としてインポートされる)は、PyTorchのニューラルネットワーク(NN)モジュールの一部で、さまざまな低レベルの関数を提供します。これらの関数は、ニューラルネットワークを構築する際に、レイヤーやアクティベーション関数、損失関数などの実装に使用されます。
nn.functional as Fのサンプル
- 活性化関数・・・F.reluなど
f.reluだったらnn.relu()でいいじゃんって思ったけどnn.ReLu()の中でnn.functional.ReLuを使ってるわ。
class nn.ReLu(nn.module):
のfoward()関数の中身がnn.functional.ReLu
-
損失関数・・・損失関数はnnで重要な役割を果たしますが、これはnn内部ではなく、trainで使われる。
nn.functional.mse_lossやtorch.nn.functional.cross_entropyなど。 -
畳み込み層

nn.Linearの理解としてとても良い
教師あり学習は回帰と分類の2種類に分かれます。
回帰と分類の違いは目的変数にあります。回帰の目的変数は連続値で、分類の目的変数は離散値です。
損失関数の勾配降下法について
損失関数は数学的にはラージLで表す。
予測値Tpと実測値Tt、Σ1~M(T1p-T1t)+(T2p-T2t)+(TMp-TMt)/Mが損失関数L(ω1, ω2)
損失関数がどれだけ進んで誤差を小さくするかを学習率ε
torchのoptim.adamについて完全に理解してしまった人になった
optim.adamは基本勾配降下法なんですがadaとmoment法で改善した勾配降下法のアルゴリズムがoptim.adam
学習率はtorchだとlr(learning rate)になる
シグモイド関数についてわかりやすくてよかった。
- LeRu関数が優れている点として、勾配消失問題が起きにくい。
- 勾配消失問題・・・微分を重ねすぎて勾配がどんどん小さくなり、消失してしまう(層の重みが0に近づいてしまう。
- シグモイド関数は0~1の間を取る関数だが、勾配消失問題が起こりやすい。
- シグモイド関数は微分値の最大値が0.25になる
- シグモイド関数は入力が負の値であれば0~0.25になり、入力が大きい場合1に近づく、負になるにしたがって0に近づくし、でかくなるにしたがって1に近づく。
パーセプトロンの基礎
パーセプトロンでは出力を流すか流さないかを0or1で表す
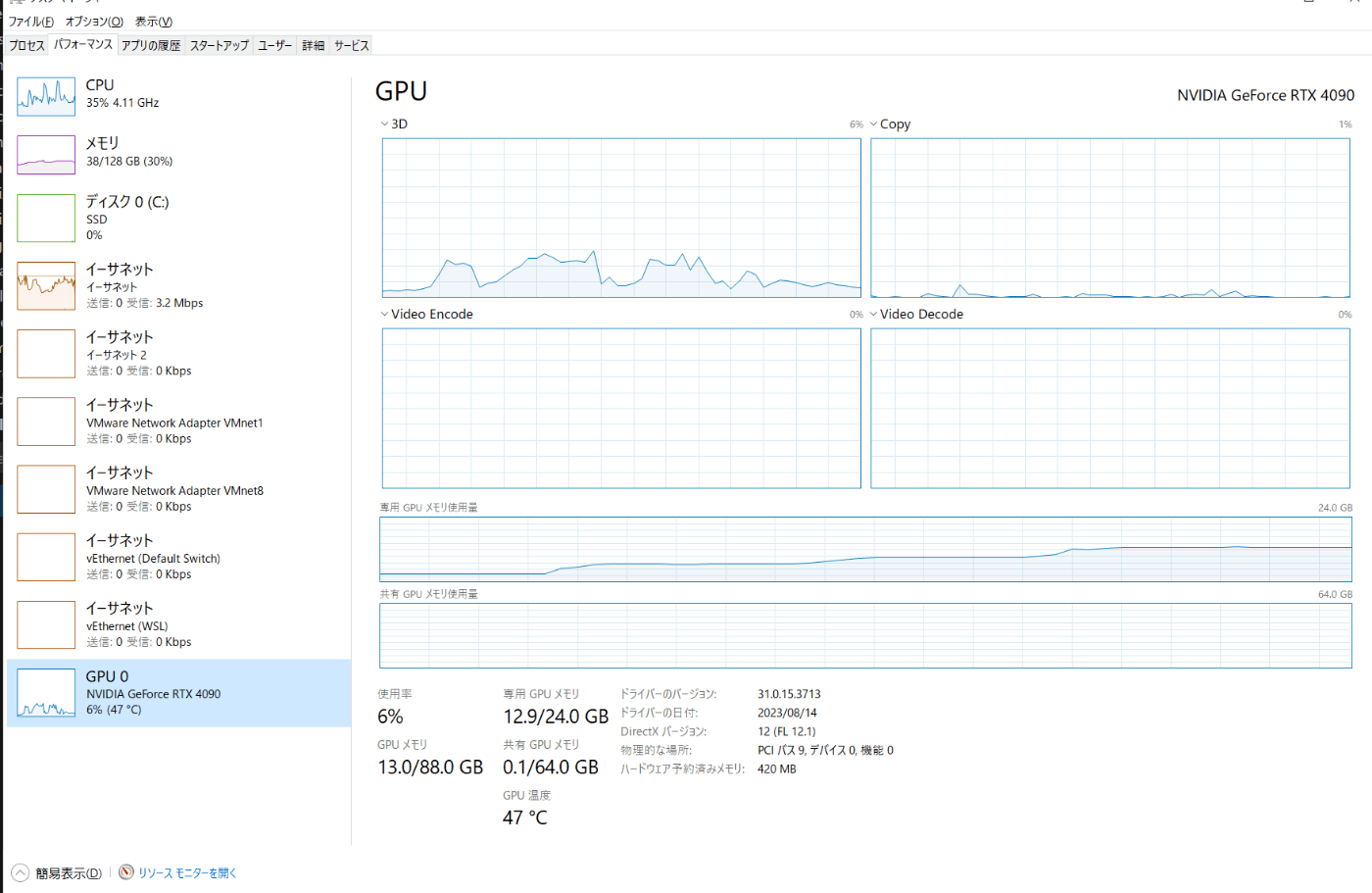
LLMのサイズ数
モデルのパラメータ数*バイト数
例えばOpenCaLMだと68億なので68億(10*9)(7B)*float32(4Byte)=28GB
FTしようとなったら追加でさらにGPUmemが必要。FTでは誤差伝播法で勾配を計算する。そのために大体LLMと同じぐらいのメモリが追加で必要なのでopencalmのfull-fine tuningをするには50GB必要
CNNの劣化問題
cnnの劣化問題を解決するためにresnetが生まれた。
cnnの20層より56層のほうが学習データでもテストデータでも精度が悪くなっている。
resnetは恒等写像をしやすくするテクニック
今日の日記:
transformerモデルやSoftwareDesignのsd最終回の記事のu-netのモデルとかでResNetを無限回見た。
残差接続(residual connection)=スキップ接続とかもっとちゃんと理解が必要そう
プーリング層は過学習を抑えるために使われる
SHAP
shapにはシャープレイ値がある。限界貢献度
SHAPは特徴量の貢献度を計算する手法
StreamDiffusionのpaper読んでたらそもそもdiffusion model(拡散モデル)の理解を求められた
- DL、deep leaning==深層学習
- 拡散モデル==diffusion model
- 拡散モデルの基礎は画像にガウシアンノイズを載せて完全なランダムノイズにしてからそれを戻す
unetはu字になってるからu-net
in0~in11で畳み込みを行う、畳み込みを行うときに4チャンネル存在する(rgb+stable diffusion特有の)
このチャンネルを全部足す。そうすると最初の入力への類似度的なのが一つになって出てくる。
in0ブロックは320個の特徴発見機を持っている。
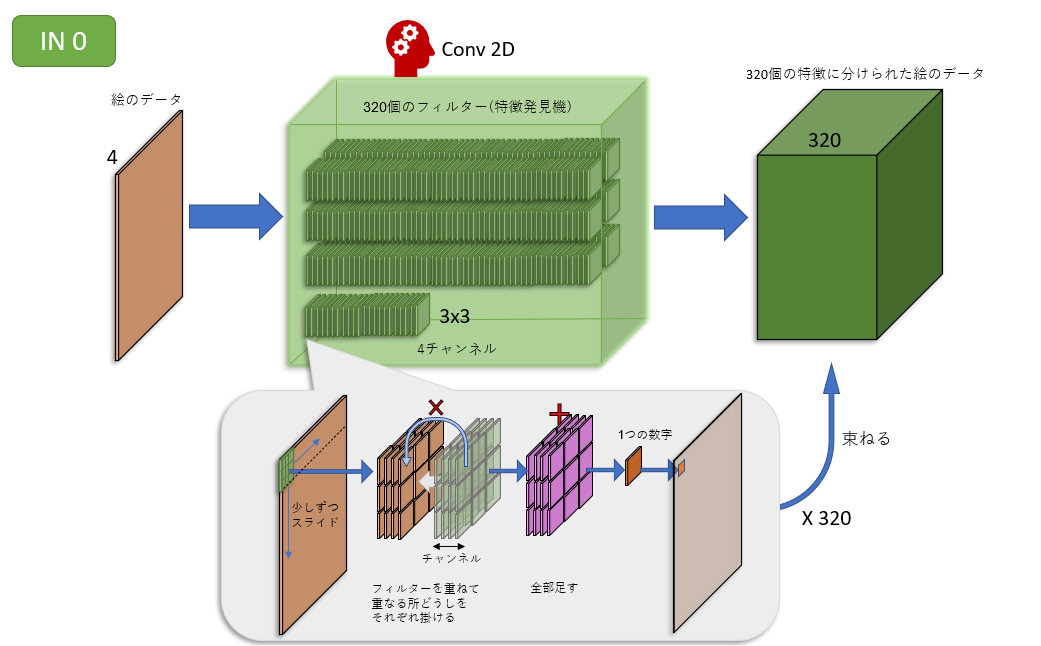
実際のStable DiffusionはLatent Spaceという画像圧縮を使うので、厳密には画像データではありませんが。
GANは敵対性生成ネットワークの生成側、generatorに着目し、入力データをイメージに変換するプロセスを解明した。
ganはgeneratorが生成した画像をdescriminatorが真偽を判定して制度を上げる
入力データデータはランダムなベクトルで構成され、latent spaceと呼ばれる
健在空間、latent space
健在空間は通常、高次元なデータ(音声や画像)を低次元で表現するために使用されます。オートエンコーダのようなモデルは入力をlatent spaceにエンコードして潜在空間からdecodeする
潜在空間はvaeにおいても重要です。
lcmはlatent consistency modelの略。潜在一貫性モデル。画質を多少犠牲にすることで信じられないほど高速化する仕組み
stable diffusionはldmという仕組みをベースにしている。sampling step数でランダムなノイズを入れてそれを除去するやつ
webuiで見てみるとわかるが、sampling step数はデフォルトの20ぐらいが最適。9ぐらいからノイズが消えて「絵」になる。30ぐらいだと絵柄が変わってしまう。
lcmはstep数が8ぐらいで安定している。
sdxl-tarboはaddという技術を使っている。adversaral diffution distillation、敵対的拡散蒸留
tensorrtはtensor run time。nvidiaが開発したstable diffusionのmodelをRTX gpu上で最高のパフォーマンスで利用するためのもの。
pytorchなどのdlフレームワークで訓練されたモデルを取り込みそれを最適化して推論を効果的に行うことが出来るもの。
日記:
今日はgguf量子化を試しました。
ggufにするにはllama2のconvert-hf-to-gguf.pyを使うみたいです。
hfからmodelを持ってきた後ggufに変換して、そのあと量子化する。つまりgguf化と量子化はまた別。
python ../convert-hf-to-gguf.py phi-2/
../quantize phi-2/ggml-model-f16.gguf phi-2/ggml-model-q4_0.gguf q4_0
../main phi-2/ggml-model-q4_0.gguf -p "what about 1+1"
nekomata14bは
error loading model: create_tensor: tensor 'token_embd.weight' not found
llama_load_model_from_file: failed to load model
llama_init_from_gpt_params: error: failed to load model 'models/nekomata-14b-q4_0.gguf'
と言われた。
special_tokens_map.jsonの意味について
add_token()
tokenizer_config.json
Custom Tokenizerをautotokenizerから呼び出せるようにする
今日はvllmを動かした
macでもwindowsでもpoetryやryeを使うと何故か動かなかった。諦めて生pip installをするとうまく動いた
windowsもだめ、こける
Administrator in ~ via v21.4.0
❯ pip install vllm
Collecting vllm
Using cached vllm-0.2.6.tar.gz (167 kB)
Installing build dependencies ... done
Getting requirements to build wheel ... error
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [22 lines of output]
C:\Users\Owner\AppData\Local\Temp\pip-build-env-h1dt3he5\overlay\Lib\site-packages\torch\nn\modules\transformer.py:20: UserWarning: Failed to initialize NumPy: No module named 'numpy' (Triggered internally at ..\torch\csrc\utils\tensor_numpy.cpp:84.)
device: torch.device = torch.device(torch._C._get_default_device()), # torch.device('cpu'),
No CUDA runtime is found, using CUDA_HOME='C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2'
Traceback (most recent call last):
File "C:\ProgramData\anaconda3\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 353, in <module>
main()
File "C:\ProgramData\anaconda3\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 335, in main
json_out['return_val'] = hook(**hook_input['kwargs'])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\ProgramData\anaconda3\Lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 118, in get_requires_for_build_wheel
return hook(config_settings)
^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\Owner\AppData\Local\Temp\pip-build-env-h1dt3he5\overlay\Lib\site-packages\setuptools\build_meta.py", line 325, in get_requires_for_build_wheel
return self._get_build_requires(config_settings, requirements=['wheel'])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\Owner\AppData\Local\Temp\pip-build-env-h1dt3he5\overlay\Lib\site-packages\setuptools\build_meta.py", line 295, in _get_build_requires
self.run_setup()
File "C:\Users\Owner\AppData\Local\Temp\pip-build-env-h1dt3he5\overlay\Lib\site-packages\setuptools\build_meta.py", line 311, in run_setup
exec(code, locals())
File "<string>", line 298, in <module>
File "<string>", line 268, in get_vllm_version
NameError: name 'nvcc_cuda_version' is not defined. Did you mean: 'cuda_version'?
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates
swallow-7bの実行
llm-jp-evalのためにswallow-7bをlocalに持ってきた。
sentencepieceが無い状態で推論すると下記のエラーが出た。下記のコマンドを打つとうまく動いた。
pip install sentencepiece accelerate protobuf
root@DESKTOP-2TQ96U5:/mnt/c/Users/Owner/work/private/ai/LLM/llm-jp-eval2# python swallow-sample.py
Traceback (most recent call last):
File "/mnt/c/Users/Owner/work/private/ai/LLM/llm-jp-eval2/swallow-sample.py", line 6, in <module>
tokenizer = AutoTokenizer.from_pretrained("./Swallow-7b-instruct-hf")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/.anyenv/envs/pyenv/versions/3.11.4/lib/python3.11/site-packages/transformers/models/auto/tokenization_auto.py", line 787, in from_pretrained
return tokenizer_class.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/.anyenv/envs/pyenv/versions/3.11.4/lib/python3.11/site-packages/transformers/tokenization_utils_base.py", line 2028, in from_pretrained
return cls._from_pretrained(
^^^^^^^^^^^^^^^^^^^^^
File "/root/.anyenv/envs/pyenv/versions/3.11.4/lib/python3.11/site-packages/transformers/tokenization_utils_base.py", line 2260, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/.anyenv/envs/pyenv/versions/3.11.4/lib/python3.11/site-packages/transformers/models/llama/tokenization_llama_fast.py", line 124, in __init__
super().__init__(
File "/root/.anyenv/envs/pyenv/versions/3.11.4/lib/python3.11/site-packages/transformers/tokenization_utils_fast.py", line 120, in __init__
raise ValueError(
ValueError: Couldn't instantiate the backend tokenizer from one of:
(1) a `tokenizers` library serialization file,
(2) a slow tokenizer instance to convert or
(3) an equivalent slow tokenizer class to instantiate and convert.
You need to have sentencepiece installed to convert a slow tokenizer to a fast one.
vmには100GBぐらいほしい
llm-jp-eval
root@DESKTOP-2TQ96U5:/mnt/c/Users/Owner/work/private/ai/LLM/llm-jp-eval2# CUDA_VISIBLE_DEVICES=0 python scripts/evaluate_llm.py -cn config.yaml model.pretrained_model_name_or_path=Swallow-7b-instruct-hf tokenizer.pretrained_model_name_or_path=Swallow-7b-instruct-hf dataset_dir=sample/1.1.0/evaluation/test/
git clone git@hf.co:tokyotech-llm/Swallow-7b-instruct-hf
python swallow-sample.py
python scripts/preprocess_dataset.py --dataset-name all --output-dir sample
root@DESKTOP-2TQ96U5:/mnt/c/Users/Owner/work/private/ai/LLM/llm-jp-eval2# CUDA_VISIBLE_DEVICES=0 python scripts/evaluate_llm.py -cn config.yaml model.pretrained_model_name_or_path=Swallow-7b-instruct-hf tokenizer.pretrained_model_name_or_path=Swallow-7b-instruct-hf dataset_dir=sample/1.1.0/evaluation/test/
[2023-12-30 07:34:52,696][accelerate.utils.modeling][INFO] - We will use 90% of the memory on device 0 for storing the model, and 10% for the buffer to avoid OOM. You can set `max_memory` in to a higher value to use more memory (at your own risk).
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [04:32<00:00, 90.99s/it]
jamp: 0%| | 0/100 [00:00<?, ?it/s]wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice: 3
wandb: You chose "Don't visualize my results"
wandb: W&B syncing is set to `offline` in this directory.
wandb: Run `wandb online` or set WANDB_MODE=online to enable cloud syncing.
wandb: Streaming LangChain activity to W&B at
wandb: `WandbTracer` is currently in beta.
wandb: Please report any issues to https://github.com/wandb/wandb/issues with the tag `langchain`.
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
jamp: 1%|██▎ | 1/100 [00:18<30:46, 18.65s/it]Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
jamp: 2%|████▌
humaneval・・・昔試してるっぽい,conda環境があった
eryza tasks 100
bigcode
llmの性能評価
- llm-open-eval
- JP Language Model Evaluation Harness(commit #9b42d41)
- ELYZA-tasks-100
- Japanese MT-bench
LLM-as-a-judge
マイナー
-
MLflow
-
OpenAIのEvals
-
oasst-model-eval
-
JGLUE
-
Japanese Vicuna QA Benchmark
- MT-Bench の前身である vicuna-blog-eval の日本語版。一般、知識、ロールプレイ、常識、フェルミ推定、反実仮想、コーディング、数学、ライティングに関する 80 問の質問を収録している。
-
https://huggingface.co/datasets/yuzuai/rakuda-questions?row=3
-
GLUE(General Language Understanding Evaluation)
- 自然言語処理(NLP)モデルの性能を評価するための標準ベンチマークです(英語のみ)。
- 日本語向けとしてJGLUEがあります(日本語NLP評価用にGLUEを参考に一から作り直したもの)。
ref
trlのSFTTrainer
今日はpeftとloraをやってます
はい
今後はtokenizer.encode_plusを使うのが良さそう
sdについて
普通はノイズを入れてから除去するというのを一ピクセルごとにやるので256¥*256=65535回計算が必要なんですが、ガチャガチャして潜在空間にしてから潜在変数にだけ計算を行う、その後少し小さい潜在空間に戻す、これを何回もやるのがu-net
今日はloraを使ったチューニングの実装をやっていたがtarget_module周りで何もわからなくなってtransformerについて調べてそこからattensionなどについて調べ始めてしまった、数学も
あとはひたすらtransformerやpeftなどを実装して表面だけ撫でています
世界一分かりやすいnp.meshgridの使い方 (メッシュグリッド) https://disassemble-channel.com/np-meshgrid/
何もわからんまぁいいや
qloraとloraの違い: 量子化(クオンタイズ)するかしないかだけ

マジ?loraに対して楽すぎる
BitsAndBytesConfigなどの理解は必要だけどね
SFTやったのに基本的なところ理解してなかったかもしれん
nekomata-14b only cuda

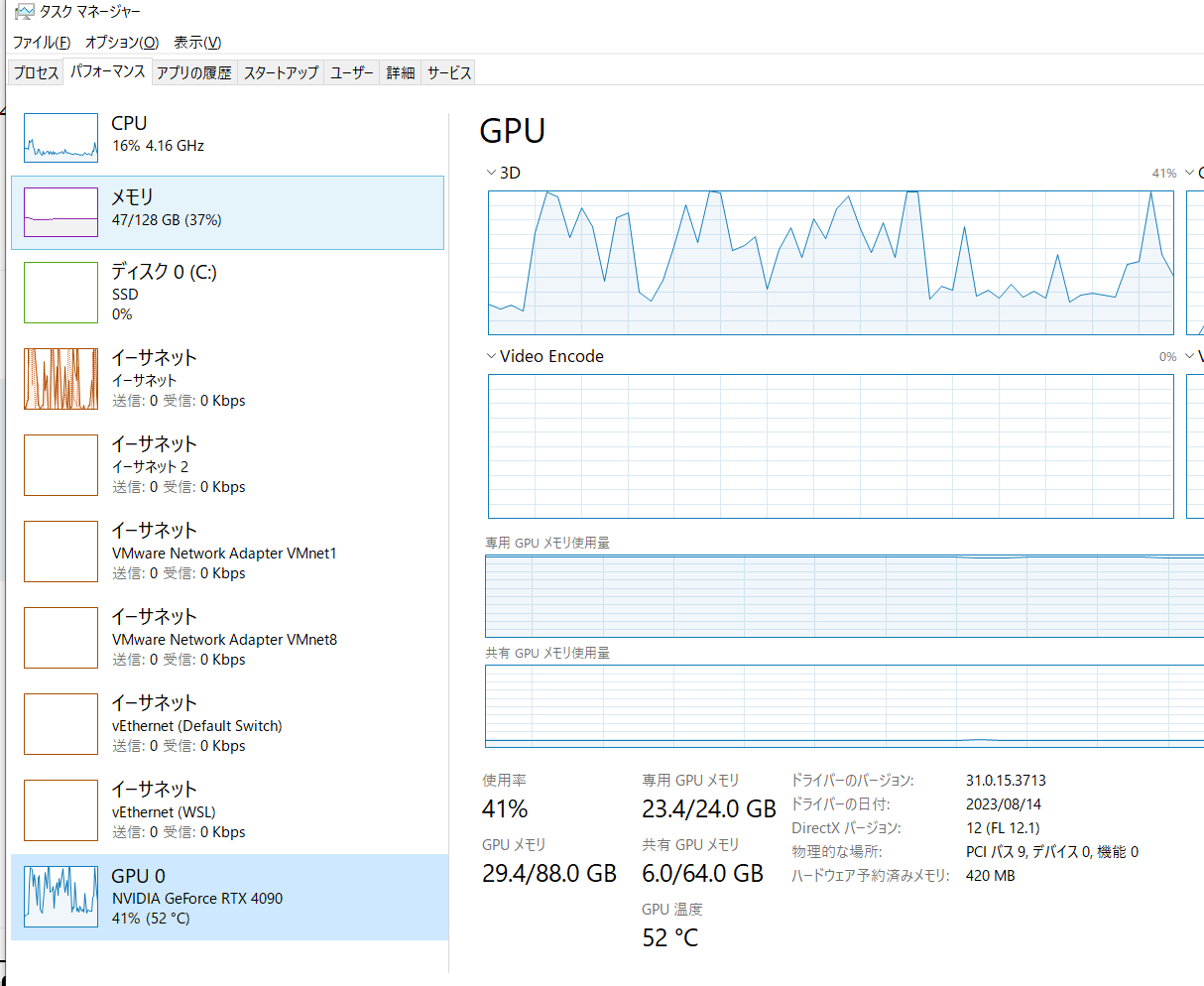
nekomata-14bのtransformerの量子化読み込みに苦労している
## 出てきた謎のエラーたち
* FP4 quantization state not initialized. Please call .cuda() or .to(device) on the LinearFP4 layer first.
* The model is automatically converting to bf16 for faster inference. If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to "AutoModelForCausalLM.from_pretrained".
* ValueError: `.to` is not supported for `4-bit` or `8-bit` bitsandbytes models. Please use the model as it is, since the model has already been set to the correct devices and casted to the correct `dtype`.
* You shouldn't move a model when it is dispatched on multiple devices.
* The model is automatically converting to bf16 for faster inference. If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to "AutoModelForCausalLM.from_pretrained".
* FP4 quantization state not initialized. Please call .cuda() or .to(device) on the LinearFP4 layer first.
GGUF量子化とcuda
早いしメモリ使用率も減った
real 1m7.199s
user 1m3.490s
sys 0m25.383s
オタクは2回見る
ガウス分布=正規分布
diffusionモデルでは入力画像をx0と書いてxtはノイズ状態
foword process
x^0が予測画像(出力画像)
イラストを生成するとき:ノイズから画像を作るわけだが
Xt-1=√αt Xt+√βt εt(ノイズ)
stable diffusion本家は1000ステップぐらいで学習してる
diffusionmodelのデノイジングを理解するにはODEの理解が必要
ODEは常微分方程式のこと。常微分方程式は未知の関数Xとそれの微分が与えられた方程式。
微分の全てを忘れたためまた導関数からやり直したほうがいい説が高い
t_index_listはゆらゆらしてて次元数はステップ数なんですね
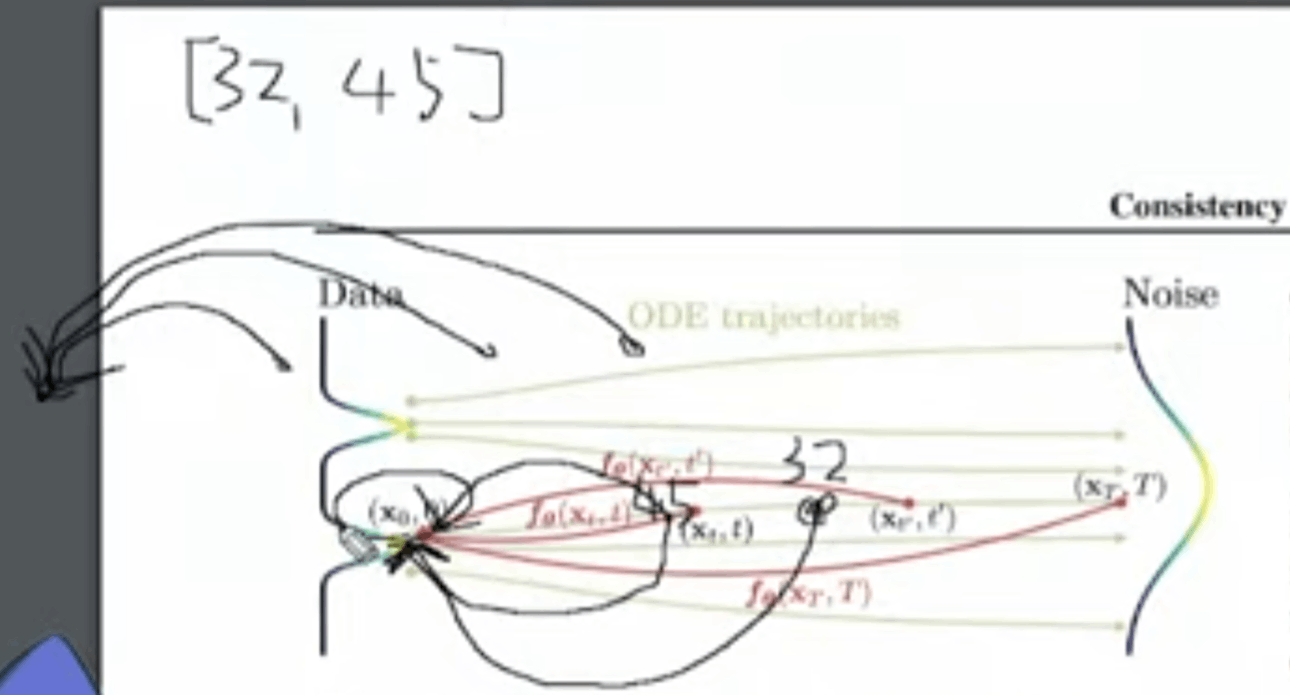
そのうちやりたい→t_index_listの1つめのステップ数の最初の推論した画像を抜いてくることもできる
22分20s
f0==u-netを指している
sdのデフォルトは512512なので6464に落としている(再度)
latent diffusion model=元画像をlatent 空間に落としてノイズを加えて戻す
Latent Consistency Model=
tensorRT
ordinary differentail equation以外にもSDEもある。
この辺はautomaticのサンプラーの種類とかにかかわってくる。DDIMとかEulerとか。
Eulerが最も基本的な常微分方程式。Eulerはオイラー
勉強したい: DarkBERTやFraudGPT
今日はdiffusersに入門してますわ
kanachanだけに構っててはいけませんのでね。
- stablediffusionpipelineを使って動かす
- load_lora_wheightとfuse_loraを使って適用
- 速度調査など