LoRAの論文を読む
LoRAとはfinetuningを効率的に低コストでできる手法。詳しくは他にわかりやすい解説をしている記事がたくさんあるのでそちらを参考にしてください。
今回は自分の知らなかった細かなところのみを書きます。
(分からなかった点のメモも残っているので注意)
論文
実装はこのあたり
表記はtransfomerのattentionのquery/key/value/outputが
手法
学習済重み
ただし、
新たに学習させたweightを含めたすべてのweightは次の様に表せる
ただし、
Aに対してはa random Gaussian initialization、Bに対してはzeroで初期化する。
したがって、学習の最初はΔW = BAはゼロとなる。
入力xに対する出力は以下のように表せる。
最適化手法としてAdamを使った場合、スケールを適切に行なった場合αはおおよそlearning rateと同じになる。
(このあたりの説明が不明。実装だと毎回スケールしてそう?)
実装はこのあたり
この論文ではtransfomerのattentionにのみ適応する。
MLPレイヤーやLayerNormレイヤー、biasesへの適応は今後の課題。
7章 UNDERSTANDING THE LOW-RANK UPDATES
5章の実験結果と6章はスキップ
7章ではいくつかの疑問に答えるために、実験を行う
- transformerのどのweightを学習すれば、性能を最大化できるか
- ΔWはrankdeficientなのか?
(rankdeficientってなに?) - ΔWとWの相関関係、ΔWとWのサイズ比較
parameter budgetの場合、transformerのどのweightを学習すれば性能を最大化できるか
GPT-3 175Bで18Mのparameter budgetとする。データセットは以下を使う。
- WikiSQL: sql queryと自然言語のセット
- MultiNLI: 文同士の関係
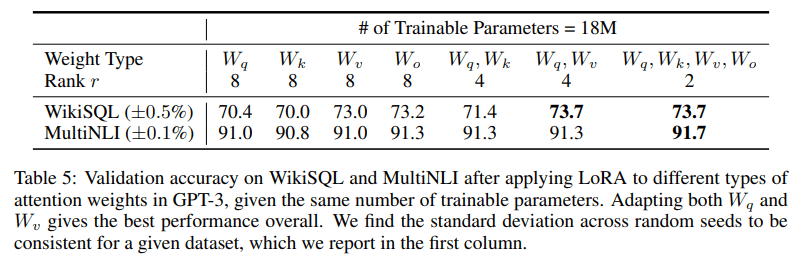
qとvの2つのattention weight typeに適応することで、r=8よりも小さいr=4で十分ってことかな?
ただ、r=8でW_oの場合と、r=4でW_q, W_vの場合が近いスコアなのが気になる
論文中であまり言及されてないが、r=2で4種類のweight typeに適応させたのが一番スコア高い
以上より、大きなrで1種類の重みを適応させるより、多くの重み行列適応させる方が望ましい。
LoRAにおけるrは何か?
rank rの影響を調べる

weight typeが
- WikiSQLでは、r=1, r=2を比べるとr=1の方がスコアが高い
- MultiNLIでは、r=1, r=2を比べるとr=2の方がスコアが高い
次の文は上記の結果を見て言ってる? To our surprise, a rank as small as one suffices for adapting both Wq and Wv on these datasets while training Wq alone needs a larger r.
だとしたら、W_q, W_vのr=2よりr=4の方がスコア高くなってるけどなぁ...
確かに、WikiSQLでW_q, W_v, W_k, W_oのときは、r=1の場合が一番スコア高い
r=64まで上げる必要はないけど、r=1だと小さすぎで、r=4がちょうど良さそう
W_oを含めるとスコアが高くなるのは、行列サイズが大きいのでΔWへの影響が大きいから?
小さなrの場合でも、よりcompetitivelyなパフォーマンスになっている。(ここは何が言いたい?)
複数種類のweight typeに適応させると、rは小さくても十分。
ΔWとWの相関関係、ΔWとWのサイズ比較
ΔWの特異値分解する。左特異ベクトル、右特異ベクトルがそれぞれU,V
UとVのtop rの

ランダム行列と比べΔWはWと相関がある。これはΔWがすでにあるWに対する増幅を示唆する。
Wの最大特異値に対応する特異ベクトルを繰り返す代わりに、Wの強調されてない方向を強調する。 (∆W only amplifies directions that are not emphasized in W. )
r=4では6.91/0.32≒21.5、r=64では3.57/1.90≒1.88。r=4の方がより効率的にタスクに対して適応できている。
以上より、事前学習で学ぶ一般的な知識に対し、低ランク適応では特定のタスクの重要な特徴を強調するのではないか?
結論
今後の研究の方向性はたくさんある。
- LoRAは他の効率的な適応手法と組み合わせることができ、直交的な改善を提供できる可能性がある。
- ファインチューニングやLoRAの背後にあるメカニズムは明確ではない。我々は、LoRAが完全なファインチューニングよりも答えやすいと信じている。
3)LoRAを適用する重み行列の選択は、ほとんどヒューリスティックに頼っている。もっと原理的な方法はありますか? - 最後に、∆W のランク不足は、W もランク不足である可能性を示唆している。
ここはそのまま翻訳
所感
個人的に発見だったのは、rとattention weightの種類の選び方について。
実装だとr=8、
r=8で
実験では175Bモデルで学習可能パラメタが18Mに制限された状態だった。llama2 13Bでは、学習可能パラメタは6.5Mなので、タスクにも依るがr=2とかで十分そう?
rankdeficientの話どこにあった?
結局スケールがわらなかった。実装的にはlayerのforwardが呼び出されるところで毎回スケールされてる気がする。ただし、デフォルト値はr=8でrola_alpha=8なので、defaultではscalingはされない。
実装ではdropoutあるけどこれの影響は?
zeroの行列から始まるからdropoutしなくても割とzeroの箇所が多そうだけど、どのくらい効果あるんだろう
わからないところ結構あったので分かる人いればtwitterとかで教えてください
Discussion