はじめに
以前の記事では、画像から文字を読み取る OCR 処理についてまとめました。
今回は音声から文字データを起こす方法として、OpenAI の Whisper を使った音声認識(ASR: Automatic Speech Recognition)に挑戦してみました。
Whisper を使った記事は他にもたくさんありますが、この記事では以下のポイントにフォーカスしています:
作ったもの
Docker Compose を使って、以下の 2 つのコンテナで構成されるシステムを構築しました。
| コンテナ | 役割 | 技術スタック |
|---|---|---|
asr |
Whisper 音声認識 API | FastAPI + OpenAI Whisper |
frontend |
ファイルアップロード UI | Streamlit |
┌─────────────────────────────────────────────────┐
│ Docker Network │
│ │
│ ┌──────────────┐ ┌──────────────────┐ │
│ │ frontend │──────▶│ asr │ │
│ │ (Streamlit) │ :8000 │ (Whisper) │ │
│ │ :8501 │ │ │ │
│ └──────────────┘ └──────────────────┘ │
│ │ │
└─────────│────────────────────────────────────────┘
│
▼ :8501
ブラウザ
環境構築
ディレクトリ構成
whisper-de-asr/
├── compose.yml
├── asr/
│ ├── Dockerfile
│ ├── app.py
│ ├── download_models.py
│ └── requirements.txt
└── frontend/
├── Dockerfile
├── app.py
└── requirements.txt
compose.yml
services:
asr:
build: ./asr
container_name: whisper-asr
environment:
- WHISPER_MODEL=base
volumes:
- whisper-cache:/root/.cache/whisper
restart: unless-stopped
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 60s
frontend:
build: ./frontend
container_name: whisper-frontend
ports:
- "8501:8501"
environment:
- ASR_URL=http://asr:8000
depends_on:
- asr
restart: unless-stopped
volumes:
whisper-cache:
ASR コンテナ
asr/Dockerfile
# syntax=docker/dockerfile:1
FROM python:3.11-slim
WORKDIR /app
# ffmpegとcurlをインストール(Whisperに必要)
RUN apt-get update && apt-get install -y --no-install-recommends \
ffmpeg \
curl \
&& rm -rf /var/lib/apt/lists/*
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# モデルのキャッシュディレクトリを設定
ENV XDG_CACHE_HOME=/app/cache
# モデルを事前ダウンロード(BuildKitキャッシュを利用)
COPY download_models.py .
RUN \
mkdir -p /app/cache/whisper && \
cp -n /tmp/whisper-cache/* /app/cache/whisper/ 2>/dev/null || true && \
python download_models.py && \
cp /app/cache/whisper/* /tmp/whisper-cache/ 2>/dev/null || true
COPY app.py .
EXPOSE 8000
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
asr/requirements.txt
fastapi
uvicorn[standard]
python-multipart
openai-whisper
asr/download_models.py
ビルド時に全モデルをダウンロードしておくスクリプトです。
"""起動時に全モデルをダウンロードするスクリプト(ロードはしない)"""
import os
from whisper import _download, _MODELS
MODELS = ["tiny", "base", "small", "medium", "large"]
cache_home = os.getenv("XDG_CACHE_HOME", os.path.join(os.path.expanduser("~"), ".cache"))
DOWNLOAD_ROOT = os.path.join(cache_home, "whisper")
if __name__ == "__main__":
os.makedirs(DOWNLOAD_ROOT, exist_ok=True)
print(f"Download directory: {DOWNLOAD_ROOT}")
for model_name in MODELS:
print(f"Downloading model: {model_name}...")
_download(_MODELS[model_name], DOWNLOAD_ROOT, in_memory=False)
print(f"✓ {model_name} downloaded")
print("All models downloaded successfully!")
asr/app.py
FastAPI で Whisper API を提供します。モデルのキャッシュ機能付きです。
import os
import time
import tempfile
from fastapi import FastAPI, UploadFile, File, HTTPException
from fastapi.middleware.cors import CORSMiddleware
import whisper
app = FastAPI(title="Whisper ASR API")
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 利用可能なモデル一覧
AVAILABLE_MODELS = ["tiny", "base", "small", "medium", "large"]
# モデルキャッシュ
model_cache = {}
def get_model(model_name: str):
"""モデルを取得(キャッシュがあればそれを使用)"""
if model_name not in AVAILABLE_MODELS:
raise HTTPException(status_code=400, detail=f"Invalid model: {model_name}")
if model_name not in model_cache:
print(f"Loading Whisper model: {model_name}")
model_cache[model_name] = whisper.load_model(model_name, device="cpu")
print(f"Model {model_name} loaded successfully")
return model_cache[model_name]
@app.get("/health")
async def health_check():
return {
"status": "healthy",
"default_model": os.getenv("WHISPER_MODEL", "base"),
"loaded_models": list(model_cache.keys()),
"available_models": AVAILABLE_MODELS
}
@app.get("/models")
async def list_models():
"""利用可能なモデル一覧を返す"""
return {
"available_models": AVAILABLE_MODELS,
"loaded_models": list(model_cache.keys()),
"default_model": os.getenv("WHISPER_MODEL", "base")
}
@app.post("/preload/{model_name}")
async def preload_model(model_name: str):
"""モデルを事前にロードする"""
try:
get_model(model_name)
return {
"status": "success",
"model": model_name,
"loaded_models": list(model_cache.keys())
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/transcribe")
async def transcribe(
file: UploadFile = File(...),
model_name: str = None,
language: str = None,
beam_size: int = 5,
initial_prompt: str = None,
temperature: float = 0.0,
):
"""音声ファイルを文字起こし"""
selected_model = model_name or os.getenv("WHISPER_MODEL", "base")
# 一時ファイルに保存
with tempfile.NamedTemporaryFile(delete=False, suffix=os.path.splitext(file.filename)[1]) as tmp:
content = await file.read()
tmp.write(content)
tmp_path = tmp.name
try:
model = get_model(selected_model)
options = {
"fp16": False,
"beam_size": beam_size,
"temperature": temperature,
}
if language:
options["language"] = language
if initial_prompt:
options["initial_prompt"] = initial_prompt
# 処理時間を計測
start_time = time.time()
result = model.transcribe(tmp_path, **options)
elapsed_time = time.time() - start_time
return {
"filename": file.filename,
"model": selected_model,
"text": result["text"],
"language": result.get("language", "unknown"),
"elapsed_seconds": round(elapsed_time, 2),
"segments": [
{
"start": seg["start"],
"end": seg["end"],
"text": seg["text"]
}
for seg in result.get("segments", [])
]
}
finally:
os.unlink(tmp_path)
フロントエンドコンテナ
frontend/Dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app.py .
EXPOSE 8501
CMD ["streamlit", "run", "app.py", "--server.address", "0.0.0.0"]
frontend/requirements.txt
streamlit
requests
frontend/app.py
import streamlit as st
import requests
import os
ASR_URL = os.getenv("ASR_URL", "http://localhost:8000")
st.set_page_config(page_title="Whisper ASR", page_icon="🎙️", layout="wide")
st.title("🎙️ Whisper 音声文字起こし")
# セッション状態の初期化
if "loaded_models" not in st.session_state:
st.session_state.loaded_models = []
if "preload_status" not in st.session_state:
st.session_state.preload_status = None
def preload_model(model_name: str):
"""モデルをプリロード"""
try:
resp = requests.post(f"{ASR_URL}/preload/{model_name}", timeout=600)
if resp.status_code == 200:
data = resp.json()
st.session_state.loaded_models = data.get("loaded_models", [])
st.session_state.preload_status = f"✅ {model_name} ロード完了"
else:
st.session_state.preload_status = f"❌ ロード失敗: {resp.text}"
except requests.exceptions.RequestException as e:
st.session_state.preload_status = f"❌ エラー: {str(e)}"
def check_health():
"""ヘルスチェック"""
try:
resp = requests.get(f"{ASR_URL}/health", timeout=10)
if resp.status_code == 200:
data = resp.json()
st.session_state.loaded_models = data.get("loaded_models", [])
return data
return None
except:
return None
# サイドバー:設定
with st.sidebar:
st.header("⚙️ 設定")
# ヘルスチェック
health = check_health()
if health:
st.success("✅ ASR接続OK")
else:
st.error("❌ ASR接続失敗")
st.divider()
# モデル選択とプリロード
st.subheader("🤖 モデル選択")
available_models = ["tiny", "base", "small", "medium", "large"]
model_name = st.selectbox(
"モデル",
available_models,
index=1,
help="大きいモデルほど精度が高いが処理時間が長い"
)
col1, col2 = st.columns([3, 1])
with col1:
if st.button("🔄 モデルをロード", use_container_width=True):
with st.spinner(f"{model_name} をロード中..."):
preload_model(model_name)
with col2:
if st.session_state.loaded_models:
if model_name in st.session_state.loaded_models:
st.markdown("✅")
else:
st.markdown("⬜")
if st.session_state.preload_status:
st.info(st.session_state.preload_status)
st.divider()
# 言語設定
st.subheader("🌐 言語")
language = st.selectbox(
"言語",
["auto", "ja", "en", "zh", "ko", "fr", "de", "es"],
index=0,
format_func=lambda x: {
"auto": "自動検出",
"ja": "日本語",
"en": "英語",
"zh": "中国語",
"ko": "韓国語",
"fr": "フランス語",
"de": "ドイツ語",
"es": "スペイン語"
}.get(x, x)
)
if language == "auto":
language = None
st.divider()
# 詳細設定
st.subheader("🎛️ 詳細設定")
beam_size = st.slider("Beam Size", 1, 10, 5, help="大きいほど精度が上がるが処理時間が長くなる")
initial_prompt = st.text_input("初期プロンプト", placeholder="例: これは日本語の会議の音声です。")
# メインエリア
st.header("📁 ファイルアップロード")
uploaded_file = st.file_uploader(
"音声ファイルを選択",
type=["mp3", "wav", "m4a", "flac", "ogg", "webm"],
help="対応形式: MP3, WAV, M4A, FLAC, OGG, WebM"
)
if uploaded_file is not None:
st.audio(uploaded_file, format=f"audio/{uploaded_file.type.split('/')[-1]}")
if st.button("🎯 文字起こし開始", type="primary", use_container_width=True):
with st.spinner("処理中...(モデルの初回ロードには時間がかかります)"):
try:
files = {"file": (uploaded_file.name, uploaded_file.getvalue())}
params = {
"model_name": model_name,
"beam_size": beam_size,
}
if language:
params["language"] = language
if initial_prompt:
params["initial_prompt"] = initial_prompt
response = requests.post(
f"{ASR_URL}/transcribe",
files=files,
params=params,
timeout=600
)
if response.status_code == 200:
result = response.json()
st.success("✅ 文字起こし完了!")
elapsed = result.get('elapsed_seconds', 0)
st.info(f"モデル: {result.get('model', 'unknown')} / 言語: {result.get('language', 'unknown')} / 処理時間: {elapsed}秒")
st.subheader("📝 文字起こし結果")
st.text_area(
"全文",
result.get("text", ""),
height=200,
label_visibility="collapsed"
)
# セグメント表示
with st.expander("📋 タイムスタンプ付きセグメント"):
for seg in result.get("segments", []):
start = seg["start"]
end = seg["end"]
text = seg["text"]
st.markdown(f"**[{start:.1f}s - {end:.1f}s]** {text}")
else:
st.error(f"❌ エラー: {response.text}")
except requests.exceptions.RequestException as e:
st.error(f"❌ エラー: {str(e)}")
起動方法
# ビルドと起動
docker compose up -d --build
# ログ確認
docker compose logs -f
起動後、ブラウザで http://localhost:8501 にアクセスします。
使い方
- モデルを選択:サイドバーから使用するモデルを選択
- モデルをロード:「モデルをロード」ボタンでモデルを事前読み込み(任意)
- 音声ファイルをアップロード:対応形式(MP3, WAV, M4A, FLAC, OGG, WebM)
- 文字起こし開始:ボタンをクリックして処理開始

モデル比較
Whisper には複数のモデルサイズがあり、精度と処理速度のトレードオフがあります。
| モデル | パラメータ数 | 必要 VRAM |
|---|---|---|
| tiny | 39M | ~1GB |
| base | 74M | ~1GB |
| small | 244M | ~2GB |
| medium | 769M | ~5GB |
| large | 1550M | ~10GB |
実際の比較結果
音声ファイルはこちらの G-01 の CM 原稿(せっけん)を使用させていただきました!
tiny

処理時間: 11.55 秒
結果:
ムテンカの社本名ませっけんだら、もう安心。天年の保室成分が含まれるため、肌にうるうよあたえ、少いやかにたもちます。お肌のことでお悩みの方は、ぜひ一度、ムテンカ社本名ませっけんをお試しください。お求めは、ゼロ一にいゼロゼロゴーゴー、休号まで。
base
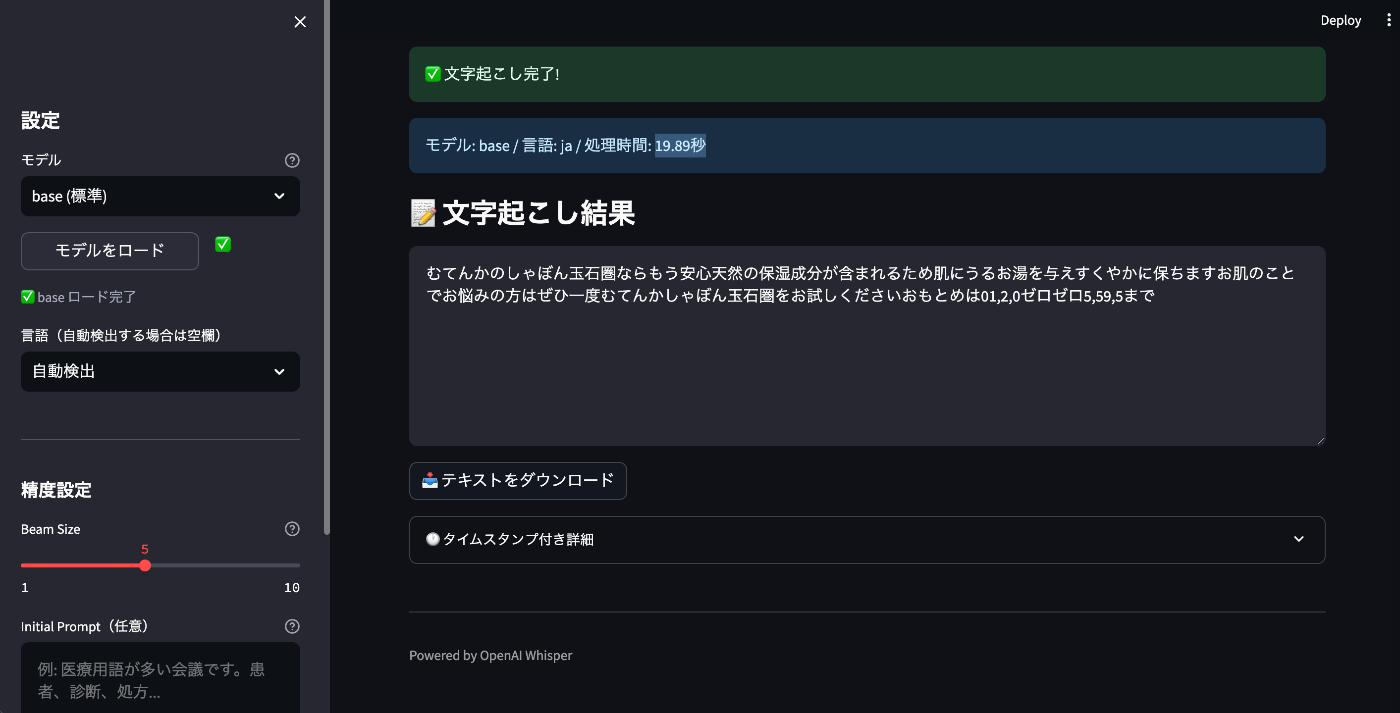
処理時間: 19.89 秒
結果:
むてんかのしゃぼん玉石圏ならもう安心天然の保湿成分が含まれるため肌にうるお湯を与えすくやかに保ちますお肌のことでお悩みの方はぜひ一度むてんかしゃぼん玉石圏をお試しくださいおもとめは01,2,0ゼロゼロ5,59,5まで
small
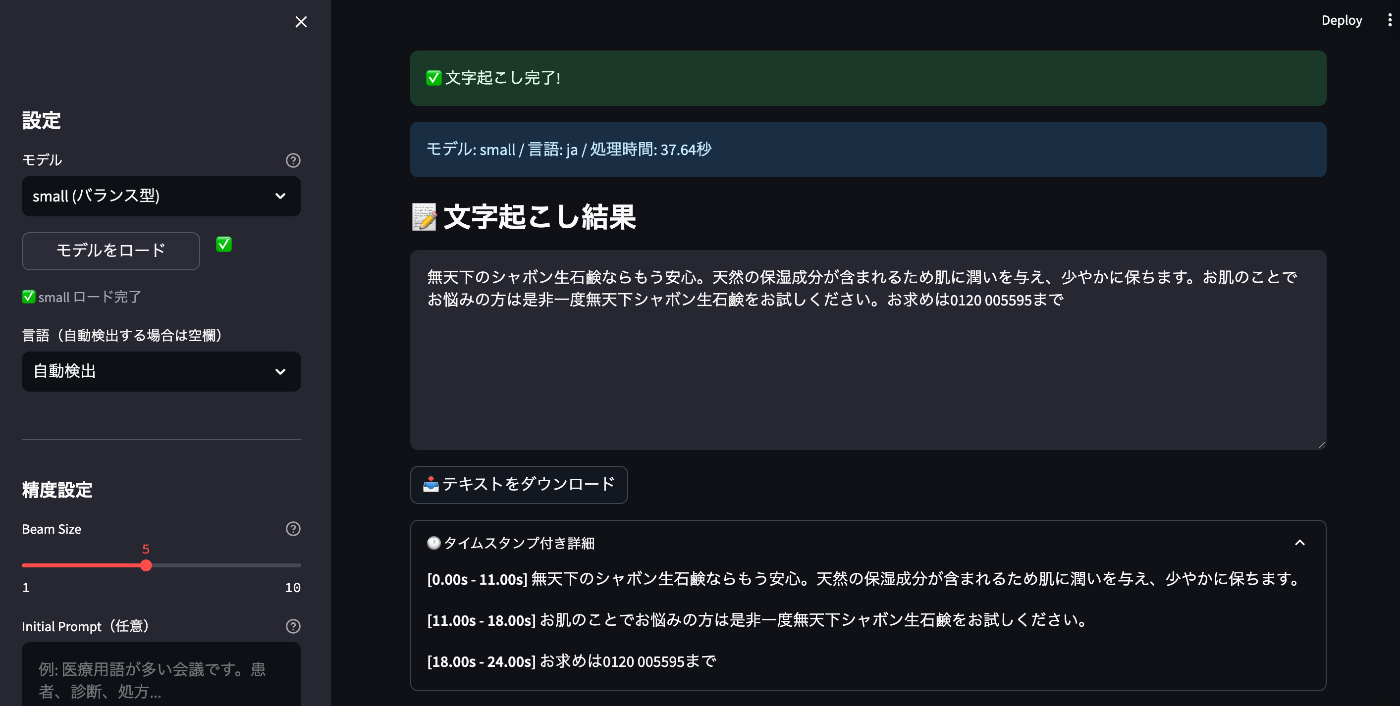
処理時間: 37.64 秒
結果:
無天下のシャボン生石鹸ならもう安心。天然の保湿成分が含まれるため肌に潤いを与え、少やかに保ちます。お肌のことでお悩みの方は是非一度無天下シャボン生石鹸をお試しください。お求めは0120 005595まで
medium
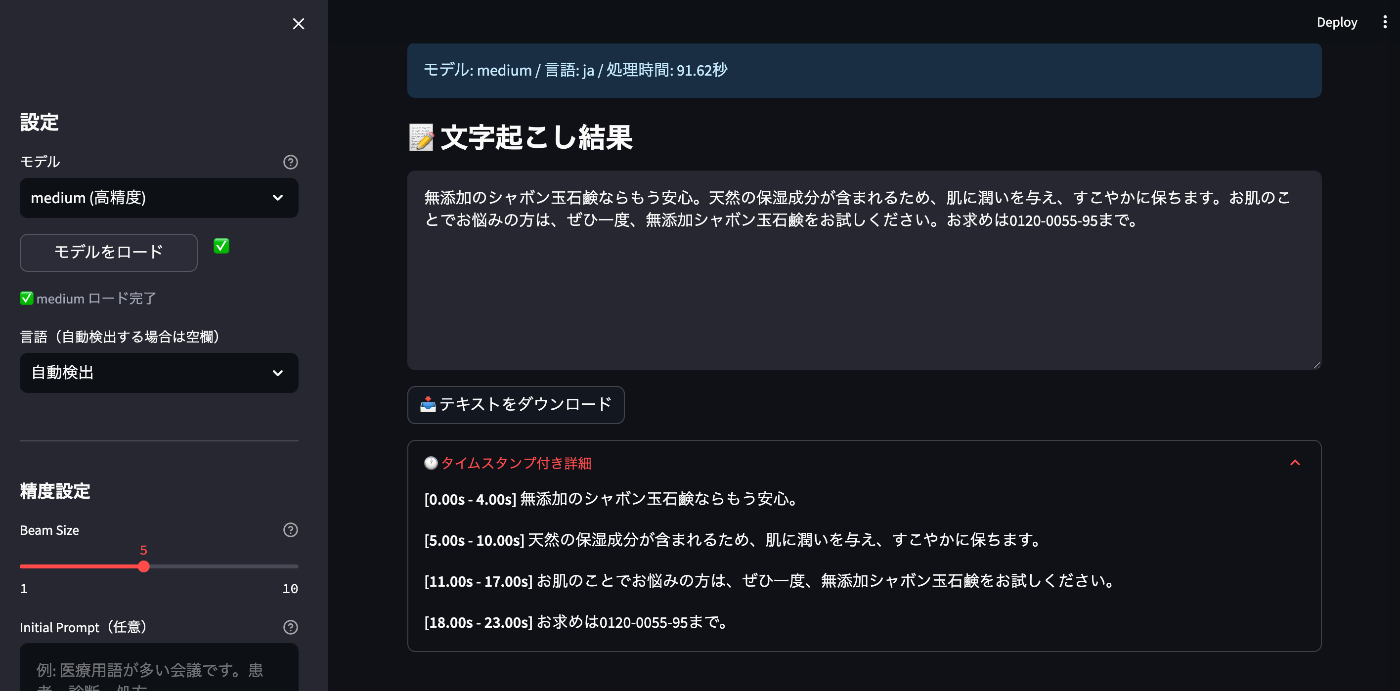
処理時間: 91.62 秒
結果:
無添加のシャボン玉石鹸ならもう安心。天然の保湿成分が含まれるため、肌に潤いを与え、すこやかに保ちます。お肌のことでお悩みの方は、ぜひ一度、無添加シャボン玉石鹸をお試しください。お求めは0120-0055-95まで。
large
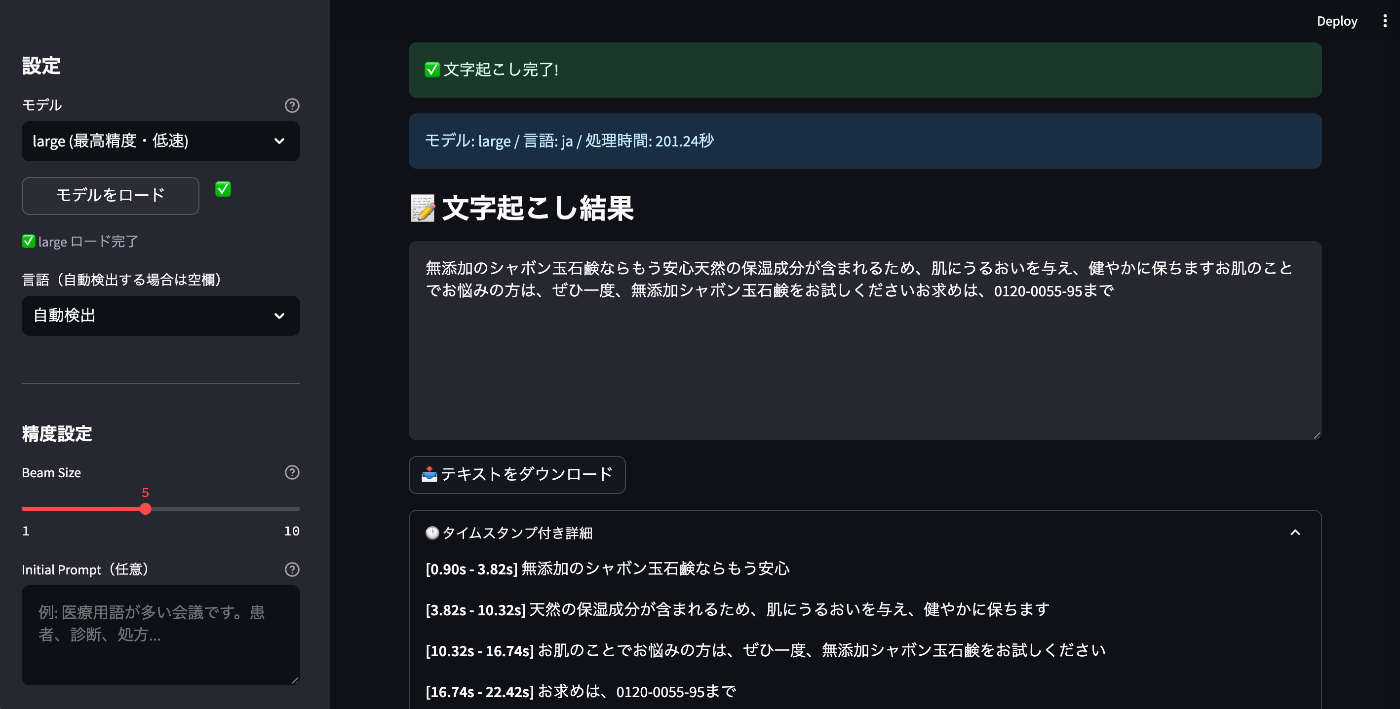
処理時間: 201.24秒
結果:
無添加のシャボン玉石鹸ならもう安心天然の保湿成分が含まれるため、肌にうるおいを与え、健やかに保ちますお肌のことでお悩みの方は、ぜひ一度、無添加シャボン玉石鹸をお試しくださいお求めは、0120-0055-95まで
比較まとめ
| モデル | 処理時間 | 精度の所感 |
|---|---|---|
| tiny | 11.55秒 | 誤認識が多く実用は厳しい(「社本名ませっけん」など) |
| base | 19.89秒 | 改善されるが固有名詞や数字に誤りあり |
| small | 37.64秒 | かなり正確。電話番号も認識できている |
| medium | 91.62秒 | ほぼ完璧。句読点や表記も自然 |
| large | 201.24秒 | mediumと同等の精度。句読点がやや少ない |
総評
精度重視なら medium 以上がおすすめです。今回のテストでは、medium モデルが「無添加のシャボン玉石鹸」「0120-0055-95」と正確に認識し、句読点の位置も自然でした。
一方、tiny や base は処理速度は速いものの、固有名詞や数字の誤認識が目立ちます。特に tiny は「ムテンカの社本名ませっけん」のように意味が通らない出力になることも。
用途別おすすめモデル:
- 📝 議事録・正確性重視 →
mediumまたはlarge - ⚡ リアルタイム・速度重視 →
small - 🧪 動作確認・テスト用 →
tinyまたはbase
CPU のみの環境では medium でも約 1.5 分かかりますが、medium の精度はかなり実用的なレベルです。リアルタイム処理には向かないものの、バッチ処理や非同期処理であれば十分に検討できる選択肢だと思います。長時間の音声を大量に処理する場合は GPU 環境の検討もおすすめします。
Tips
Beam Size について
Beam Size は、音声認識の探索幅を制御するパラメータです。
- 小さい値(1-3): 高速だが精度が下がる可能性
- 大きい値(5-10): 精度が上がるが処理時間が増加
デフォルトの 5 は、精度と速度のバランスが取れた値です。
初期プロンプトの活用
初期プロンプトを設定することで、認識精度を向上させることができます。
例: これは日本語の技術会議の音声です。Docker、Kubernetes、APIなどの用語が含まれます。
リポジトリ
今回作成したコードは GitHub で公開しています。
git clone https://github.com/tamoco-mocomoco/whisper-de-asr.git
cd whisper-de-asr
docker compose up -d --build
おわりに
今回は OpenAI Whisper を使って、ローカルで動作する音声文字起こしシステムを構築しました。
クラウド API を使わずに完全ローカルで動作するため、機密性の高い音声データも安心して処理できます。また、複数のモデルを切り替えながら比較できるので、用途に応じた最適なモデルを見つけることができます。
OCR で画像からテキストを抽出し、Whisper で音声からテキストを抽出する。これらを組み合わせることで、様々なメディアからテキストデータを取得できるようになりました。

Discussion