Day 3:メモリオーダリング ~並行処理の基礎~
メモリオーダリングとは
昨日はアトミック操作について説明した。今日は、メモリオーダリングについて学習する。
「メモリオーダリング(Memory Ordering)」とは、コンピュータシステムやプログラミングにおいて、メモリ操作(読み込みや書き込み)がどのような順序で実行されるかを定義する概念である。
プロセッサは性能向上のため、プログラムの命令順に処理を実行せずに、順序を入れ替えて実行することがある。性能が向上することに越したことがないのだが、マルチスレッド環境でメモリ操作の実行の順序が適切でないと、データの不整合が発生するなどの問題が生じる。なので、アトミック操作のメモリオーダリングを適切に制御して、プログラムの正確な動作とパフォーマンスを両立させる必要がある。
Rustのメモリオーダリング
Rustでアトミック操作のメモリオーダリングの指定はOrdering型を用いて行う。
以下のようなメモリオーダリングが指定できる
| Ordering | 説明 |
|---|---|
| Ordering::Relaxed | 順序保証なし。単一の原子操作のみが保証される。 |
| Ordering::Acquire | 読み込みをする操作に使用される。以降の読み書き操作がAcquire操作より後に実行されることを保証。 |
| Ordering::Release | 書き込みをする操作に使用される。以前の読み書き操作がRelease操作より前に実行されることを保証。 |
| Ordering::AcqRel | 読み書きの両方を伴う操作に対してAcquireとReleaseを適用。 |
| Ordering::SeqCst | 最も強力なオーダリングで、全てのメモリ操作が全スレッドで一貫した順序で見えることを保証。 |
メモリオーダリングの違いを観測する
実際にRustでアトミック操作をするコードを実行して、メモリオーダリングの指定の仕方でどのように挙動が変わるかを観測する。
わざとアウトオブオーダーで実行する
プログラムの命令順に処理を実行せずに、順序を入れ替えて実行することを「アウトオブオーダー」と呼ぶ。
スピンロックでクリティカルセクションを保護するコードで再現してみる。
use std::sync::atomic::{AtomicBool, Ordering};
use std::thread;
static LOCK: AtomicBool = AtomicBool::new(false);
static mut COUNTER: usize = 0;
fn lock() {
while LOCK
.compare_exchange(false, true, Ordering::Relaxed, Ordering::Relaxed)
.is_err()
{}
}
fn unlock() {
LOCK.store(false, Ordering::Relaxed);
}
fn main() {
let mut handles = Vec::new();
for _ in 0..10 {
let handle = thread::spawn(|| {
for _ in 0..100_000 {
lock();
unsafe {
COUNTER += 1;
}
unlock();
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Final counter value: {}", unsafe { COUNTER });
}
実行してみる。
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.07s
Running `target/debug/hoge`
Final counter value: 999691
このコードでは10個のスレッドを生成し、それぞれがCOUNTERを10万回インクリメントしているが、結果は期待通りのものにならなかった。
これはロック、ロックの解放にOrdering::Relaxedを使用しているのが原因である。
ロックの取得とロックの解放とデータの更新の順序が保証されずに以下のような不正な挙動をしてしまった:
- データの更新をしてからロックの取得
- ロックの解放をしてからデータの更新
図にするとこうなる。
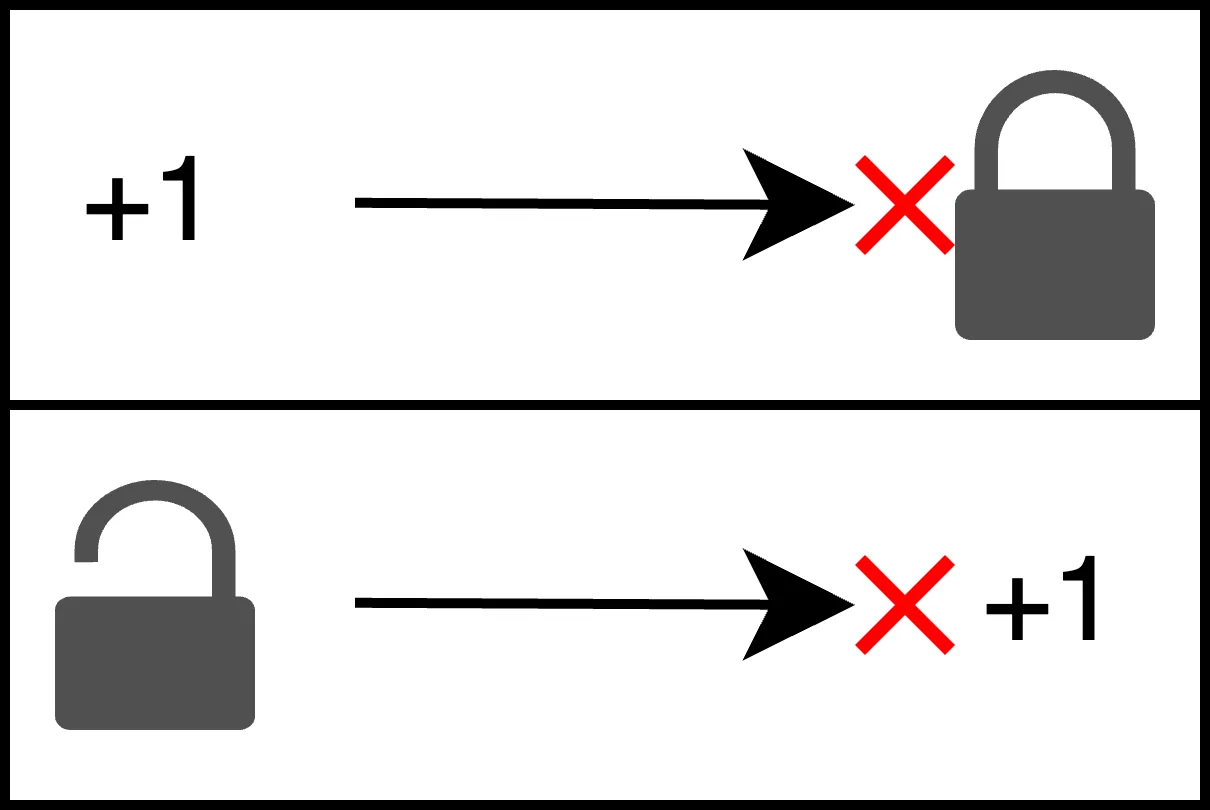
このケースではRelaxedは不適切ということがわかった。
適切にメモリオーダリングを使用する
意図しないアウトオブオーダー実行を防ぐためには、lock関数とunlock関数で使われているアトミック操作のメモリオーダリングをそれぞれ適切に指定しなければならない。
ここでAcquireとReleaseの説明を振り返ってみる。
| Ordering | 説明 |
|---|---|
| Ordering::Acquire | 読み込みをする操作に使用される。以降の読み書き操作がAcquire操作より後に実行されることを保証。 |
| Ordering::Release | 書き込みをする操作に使用される。以前の読み書き操作がRelease操作より前に実行されることを保証。 |
ロックの後に読み書きが実行されるべきなので、ロックの解放の前に読み書きが実行されるべきなので以下のようなメモリオーダリングを指定する:
- ロック取得時 (
lock関数):Ordering::Acquire - ロック解放時 (
unlock関数):Ordering::Release
以下のようなコードになる。
use std::sync::atomic::{AtomicBool, Ordering};
use std::thread;
static LOCK: AtomicBool = AtomicBool::new(false);
static mut COUNTER: usize = 0;
fn lock() {
while LOCK
.compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed)
.is_err()
{}
}
fn unlock() {
LOCK.store(false, Ordering::Release);
}
fn main() {
let mut handles = Vec::new();
for _ in 0..10 {
let handle = thread::spawn(|| {
for _ in 0..100_000 {
lock();
unsafe {
COUNTER += 1;
}
unlock();
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Final counter value: {}", unsafe { COUNTER });
}
実行する。
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/hoge`
Final counter value: 1000000
これでロック、データ更新、ロック解放の命令がアウトオブオーダー実行されないようになった。
今日は、ここで終了。ちょっと足りない気がするので気が向いたら追記する。
明日はプロセッサ命令を勉強する。Rustが提供するインターフェースだけを知っていれば基本的に問題ない。つまり、明日の記事は読まなくてもいいかもしれないが、プロセッサ命令レベルまで掘り下げたらより理解の助けになる。
ここまで読んでくださってありがとうございます!
Discussion