Day 2: アトミック操作 ~並行処理の基礎~
アトミック操作とは
昨日は、RCUとは何か簡単な説明をした。
今日からは、RCUなどの並行プリミティブを作るのに必要な並行処理の基礎を学習していく。
まずは、アトミック操作から。
アトミック操作でできること
「アトミック」とは哲学でこれ以上分解することができないものを表す言葉である。
「アトミック操作」も同様に、これ以上小さい操作に分解することや、他のスレッドから途中の状態を観測することができない操作を意味する。仮に途中で失敗しても元の状態に戻る。他のスレッドから観測できるのは、操作前か操作に成功した後の状態のみである。
unsafeな並行カウンタを実装する
まだ概念的な話ばかりなので意味がよくわからない点が多いと思うが、とりあえずアトミック操作の有り難みを実践するべく、unsafeな並行カウンタを実装してみる。
use std::thread;
fn main() {
static mut COUNTER: usize = 0;
let mut handles = vec![];
for _ in 0..5 {
let handle = thread::spawn(|| {
for _ in 0..1000 {
unsafe {
let current = COUNTER;
COUNTER = current + 1;
}
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
unsafe {
println!("Final count: {}", COUNTER);
}
}
5のスレッドが各々「共有するカウンタ(初期値: 0)を1000回インクリメントする処理」を実行するコードである。
実行して結果を見る。
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/unsafe-counter`
Final count: 3297
5000という数字になるはずだが、そうはなっていない。
クリティカルセクション[1]内で操作が重複したため、カウンタが正しく行われずにレースコンディション[2]が発生した。
以下は二つのスレッドがレースコンディションを発生させる例である:
- let current = COUNTER でカウンタを読み取る
- 他のスレッドが同じ値を読み取る
- 両方のスレッドが同じ値に1を加えて書き戻す
- 結果として、2回のインクリメントが1回分しか反映されない
上記の例を図に表すとこうなる。
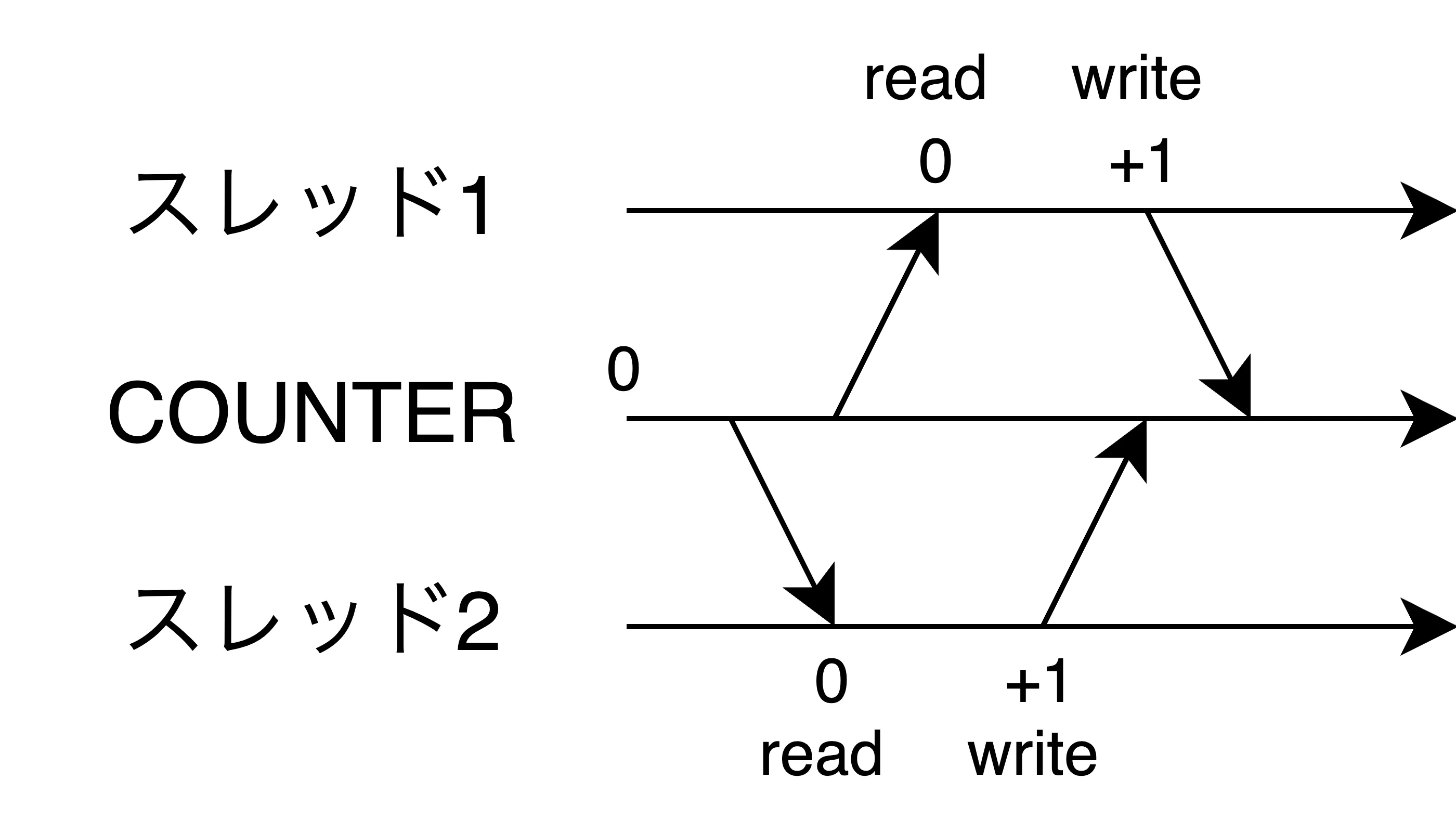
アトミック操作で安全な並行カウンタを実装する
先ほどのコードのデータの不整合は、クリティカルセクションを最小化するか、Mutexなどのロックでクリティカルセクションを保護するかのどちらかで解決できる。そして本題のアトミック操作は、前者のアプローチとなる。
実際にアトミック操作を用いて並行カウンタを再実装してみる。
use std::sync::atomic::{AtomicUsize, Ordering};
use std::thread;
fn main() {
static COUNTER: AtomicUsize = AtomicUsize::new(0);
let mut handles = vec![];
for _ in 0..5 {
let handle = thread::spawn(|| {
for _ in 0..1000 {
COUNTER.fetch_add(1, Ordering::SeqCst);
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Final count: {}", COUNTER.load(Ordering::SeqCst));
}
実行して結果を見る。
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.07s
Running `target/debug/safe-counter`
Final count: 5000
見事に5000回のインクリメントに成功していることが確認できる。
このコードのfetch_addは読み取りとインクリメントをアトミック(不可分)に実行する。そのため、他のスレッドが途中の状態を観測できなくなり、クリティカルセクションがなくなる。
図にするとこういう感じ。読み書きの間に他のスレッドが干渉することができない様子が伝わると嬉しい。
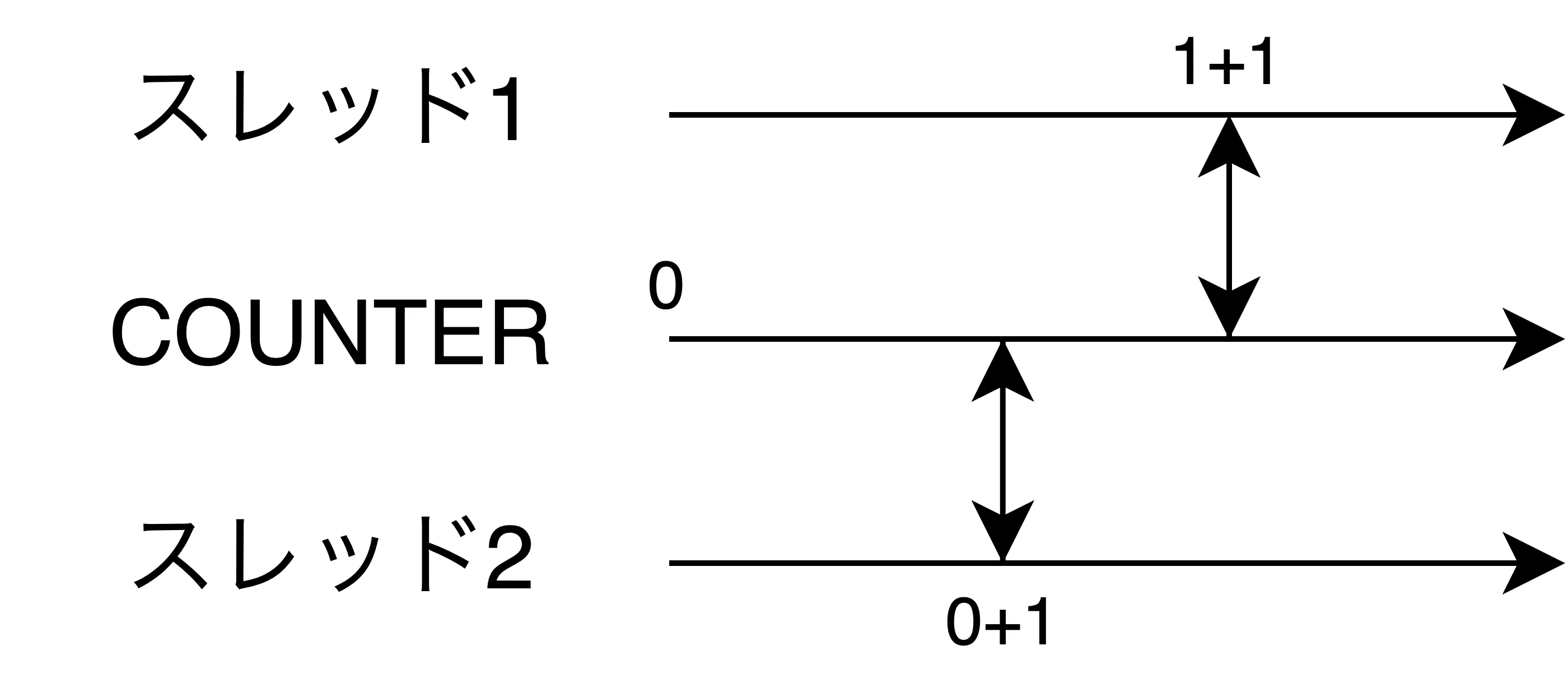
スピンロックを実装する
アトミック操作でクリティカルセクションを最小化する他にも、クリティカルセクションをMutexなどのロックで保護するという方法がある。
ではロックの実装例を書こう!と意気込んでもMutexを使って並行カウンタを実装するのもなんだか味気ない。
なので応用として、先ほど知ったアトミック操作を使ってロックを実装する。
use std::sync::atomic::{AtomicBool, Ordering};
use std::thread;
fn main() {
static LOCK: AtomicBool = AtomicBool::new(false);
let mut handles = vec![];
static mut COUNTER: usize = 0;
for _ in 0..5 {
let handle = thread::spawn(|| {
for _ in 0..1000 {
loop {
let is_locked = LOCK.load(Ordering::SeqCst);
if !is_locked {
if LOCK
.compare_exchange(false, true, Ordering::SeqCst, Ordering::SeqCst)
.is_ok()
{
break;
}
}
}
unsafe {
let current = COUNTER;
COUNTER = current + 1;
}
LOCK.store(false, Ordering::SeqCst);
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
unsafe {
println!("Final count: {}", COUNTER);
}
}
以下のようなアトミック操作の使い方をした:
-
load- 使ったアトミック命令はロックを表すBool値がtrue(ロックあり)か読んで確かめる
-
compare_exchange- false(ロックなし)の場合にtrue(ロックあり)に更新する
この実装で書き込みのためのロック取得に成功できるスレッドが1つしかなくなったので、クリティカルセクションの保護が可能になった。実行する。
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.07s
Running `target/debug/safe-counter-with-lock`
Final count: 5000
unsafeで囲われたインクリメントの処理がうまくいった。先ほどの実装は以下の図のような挙動をする。
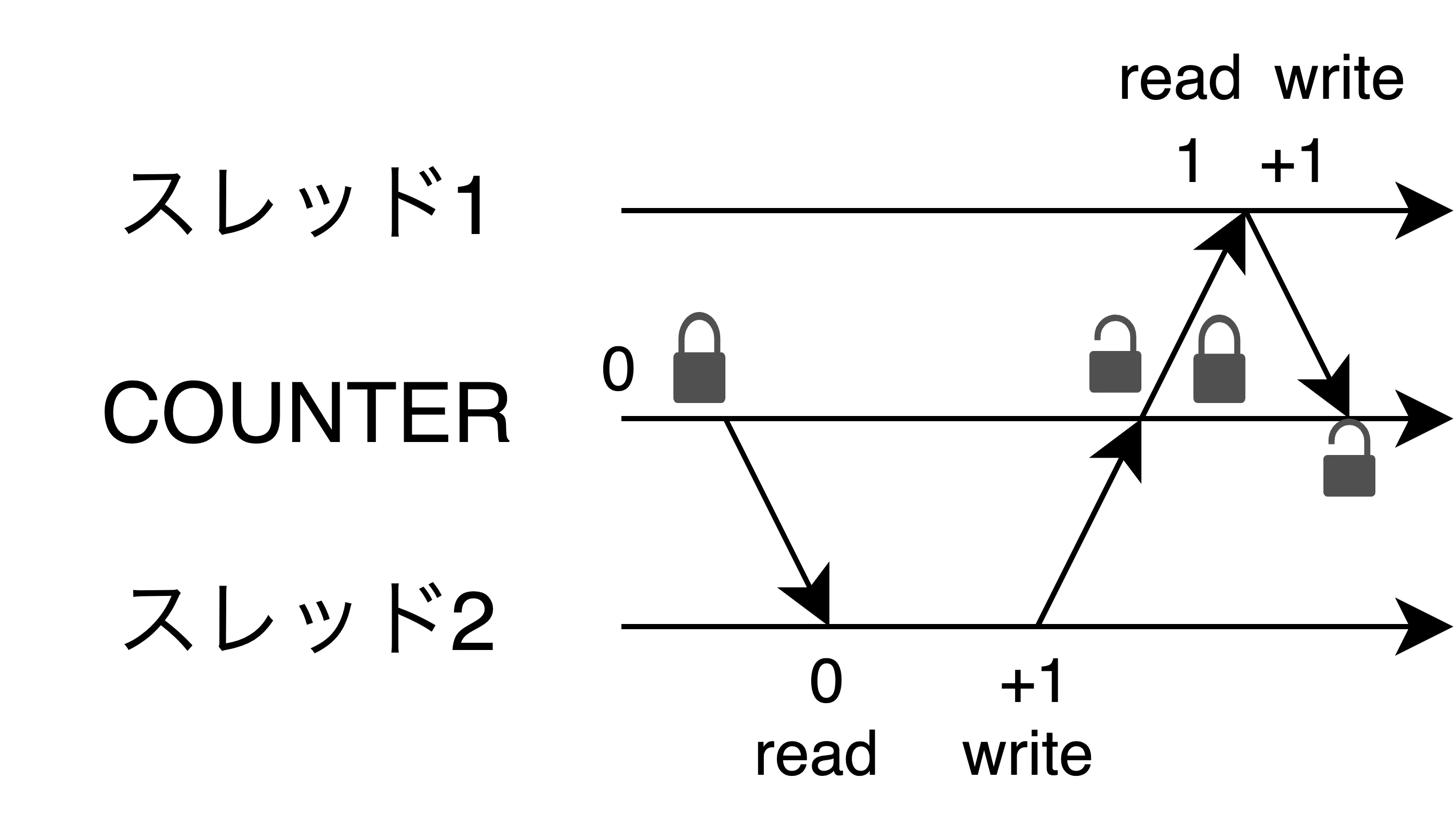
※ちなみに、先ほどのスピンロックの実装で「ロックを取得する部分は[3]compare_exchangeだけで実装できるじゃん」と思った人がいたら鋭い。ただ、この実装にもちゃんとした理由が存在する。これは「Day 5: キャッシュコヒーレンスプロトコル ~並行処理の基礎~」で取り扱う。
アトミック操作の種類
ここではちゃんと具体的なアトミック操作に関する説明をする。本来は記事の頭で書くべき内容だったがインパクト重視ということでご勘弁。
アトミック操作には主に4種類がある。これらを以下の表にまとめる。すでにコードにも出現したが、Orderingのところは明日に勉強するので今は知らなくても大丈夫。
| 操作の種類 | 説明 | 代表的な関数 |
|---|---|---|
| ロード(Load) | アトミック変数の現在の値を取得する。読み取り専用の操作 | load(Ordering) |
| ストア (Store) | アトミック変数に新しい値を設定する。書き込み専用の操作 | store(value, Ordering) |
| 読み込み更新操作 | 現在の値を取得しつつ、指定した操作(加算、減算、論理演算など)を同時に行う |
fetch_add(), fetch_sub(), fetch_and(), fetch_or(), fetch_xor()
|
| 比較更新操作 | 現在の値と期待値を比較し、一致する場合にのみ新しい値に更新する |
compare_exchange(), compare_exchange_weak()
|
ロード (Load)
ロード操作は、アトミック変数の現在の値を取得するために使用する。これは読み取り専用の操作であり、他のスレッドからの変更を防ぐものではない。ロード操作の使用例は以下の通り。
use std::sync::atomic::{AtomicUsize, Ordering};
fn main() {
let counter = AtomicUsize::new(10);
let value = counter.load(Ordering::SeqCst);
println!("Loaded value: {}", value);
}
ストア (Store)
ストア操作は、アトミック変数に新しい値を設定するために使用する。これは書き込み専用の操作である。
use std::sync::atomic::{AtomicUsize, Ordering};
fn main() {
let counter = AtomicUsize::new(10);
counter.store(20, Ordering::SeqCst);
println!("Stored value: {}", counter.load(Ordering::SeqCst));
}
読み込み更新操作
読み込み更新操作は、アトミック変数の現在の値を取得しつつ、指定した操作(加算、減算、論理演算など)を同時に行う。これにより、読み取りと書き込みを一つのアトミックな操作として実行できる。
use std::sync::atomic::{AtomicUsize, Ordering};
use std::thread;
fn main() {
static COUNTER: AtomicUsize = AtomicUsize::new(0);
let mut handles = vec![];
for _ in 0..5 {
let handle = thread::spawn(|| {
for _ in 0..1000 {
COUNTER.fetch_add(1, Ordering::SeqCst);
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Final count: {}", COUNTER.load(Ordering::SeqCst));
}
比較更新操作
比較更新操作は、アトミック変数の現在の値と期待値を比較し、一致する場合にのみ新しい値に更新する。これにより、CAS(Compare-And-Swap)アルゴリズムを実現し、ロックフリーのデータ構造を構築する際に非常に有用。←ここ重要
use std::sync::atomic::{AtomicUsize, Ordering};
use std::thread;
fn main() {
static COUNTER: AtomicUsize = AtomicUsize::new(0);
let handles: Vec<_> = (0..5)
.map(|_| {
thread::spawn(|| {
for _ in 0..1000 {
let mut current = COUNTER.load(Ordering::SeqCst);
loop {
let new = current + 1;
match COUNTER.compare_exchange(current, new, Ordering::SeqCst, Ordering::SeqCst,) {
Ok(_) => break,
Err(x) => current = x,
}
}
}
})
})
.collect();
for handle in handles {
handle.join().unwrap();
}
println!("Final count: {}", COUNTER.load(Ordering::SeqCst));
}
アトミック操作の基本がわかったところで今日は終了。明日はメモリオーダリングを勉強する。→ Day 3:メモリオーダリング ~並行処理の基礎~
unsafeな並行カウンタをsafeにする方法にアトミック操作(2.2.)とロック(2.3.)を挙げたが、基本的にアトミック変数が扱える型(例ではUsize→AtomicUsize)を扱う場合、過度に多くの競合が発生しないのであれば、アトミック操作を使って処理をした方が圧倒的に効率的である。[4]
では、アトミックな操作ができない型(構造体)はどうするのか?パフォーマンスを犠牲にしてロックを使うのか?と疑問に思うかもしれないが、"All problems in computer science can be solved by another level of indirection" [5]という格言のようにAtomicPtrを使って構造体へのポインタを保持するアトミック変数を使えば同じことが実現できる。
最後にCASについてちょこっとだけ触れたけど、本当に面白い技術なのでぜひ皆さんもロックフリー並行プリミティブを作りましょう!ロックフリーあたりの知識がたくさん身につく資料がこの世に転がっているので、ぜひチェック!!(というか記事を書く際はほぼこれらの資料しか参考にしていない節がある)
- Lock-free入門
- 冬のLock-Free祭り
Discussion