Day 6: BlockingとNon-blocking ~並行処理の基礎~
BlockingとNon-blocking
昨日はキャッシュコヒーレンスプロトコルについて勉強した。CPUアーキテクチャの理解を深めた前回までの内容を踏まえ、今回は並行処理の実装手法について、特に「Blocking」と「Non-blocking」という重要な分類に焦点を当てて解説する。
BlockingとNon-blockingの特徴
並行処理アルゴリズムは、排他ロックを使うかそうではないかを基準として「Blocking」と「Non-blocking」の2つに大きく分類される。
- Blocking
- 1つのスレッドの遅延が他のスレッドを遅延させる可能性がある
- ロックを使っている
- デッドロックが起きる可能性がある
- Non-blocking
- あるスレッドの遅延が他のスレッドを遅延させることはない
- ロックを使っていない
- デッドロックが起きない
これらの特徴の中でも特に重要なのが、Blockingにおける「1つのスレッドの遅延が他のスレッドを遅延させる可能性がある」という性質だ。この問題がシステム全体にどのような影響を与えるのか、具体的に見ていこう。
Blockingアルゴリズムが与える速度性能への影響
並行プログラミングにおいて、ロック、及びブロッキングアルゴリズムは最も簡単で主要な同期手段である。しかし、ロックを保持しているスレッドが実行を中断されると、システム全体のパフォーマンスに予想以上の悪影響を及ぼすことがある。
ロックを持つスレッドを処理するコアがキャッシュミスをしたりコンテキストスイッチをしたりして遅延を起こすとする。その時、そのロックの解放を待つスレッド/コアも同じ遅延を受けてしまうことになる。
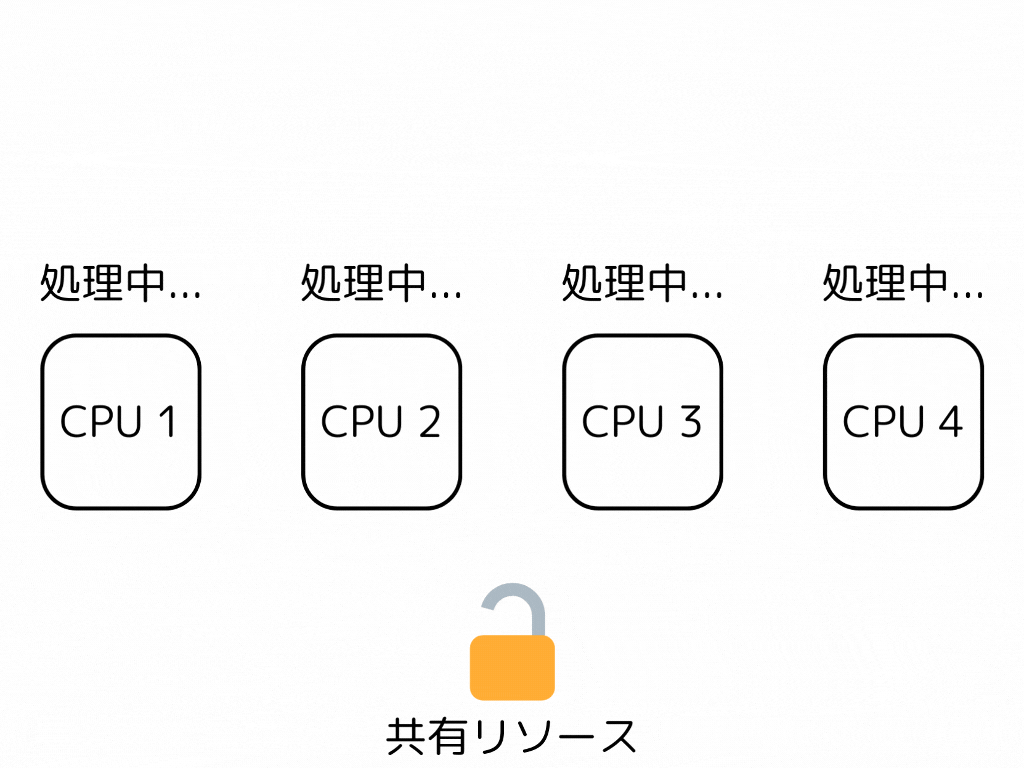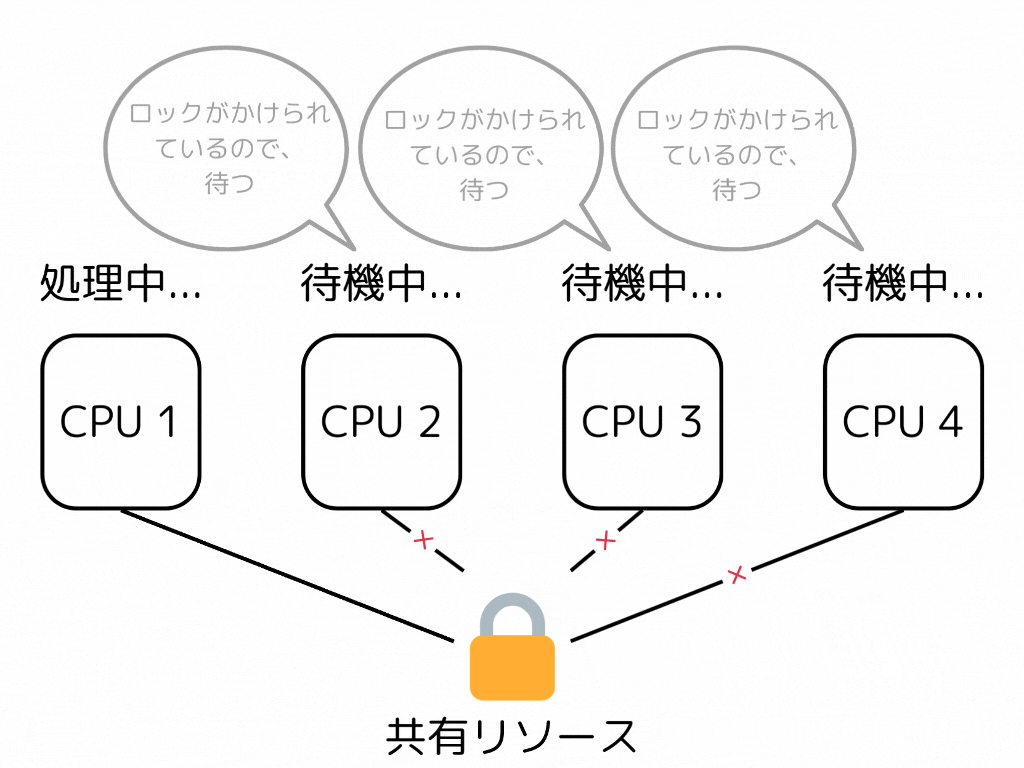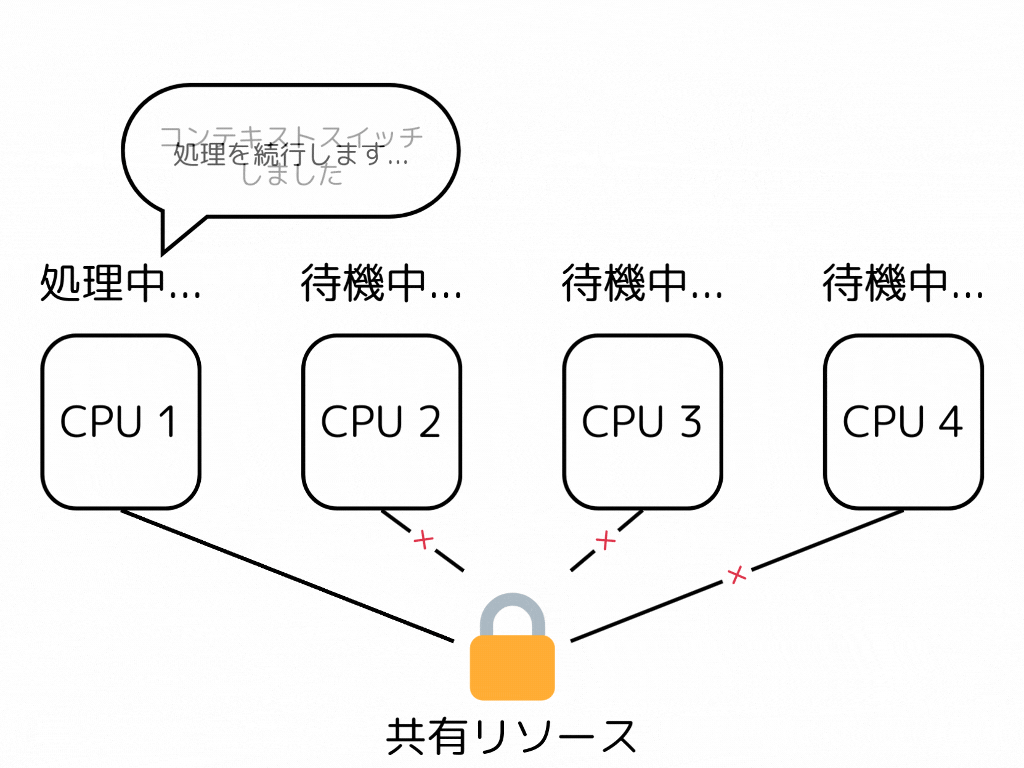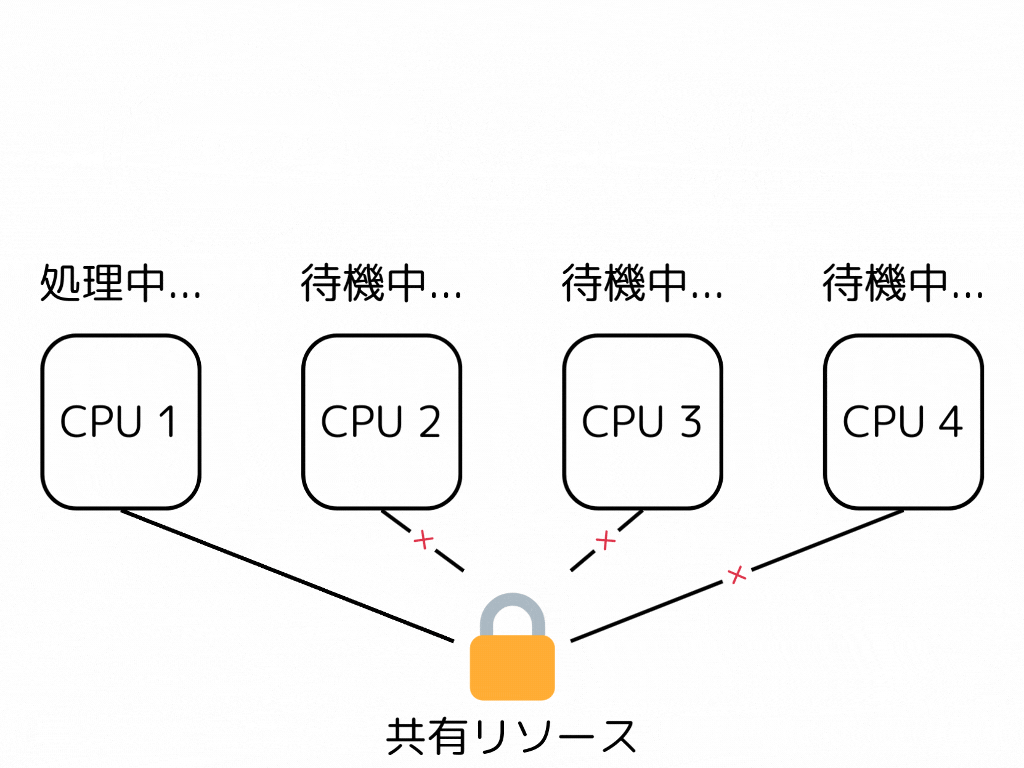
一方、Non-blocking、Lock-freeとされるアルゴリズムは、あるスレッドの遅延が他のスレッドを遅延させることはない。
これまでの説明から、一見するとNon-blockingアルゴリズムの方が常に優れているように思える。しかし、実際の並行システムのパフォーマンスはそれほど単純ではない。この点について、あるデータベースシステムの研究が興味深い知見を示している。
並行アルゴリズムのスケーラビリティを決定する主な要因
前述したBlockingアルゴリズムの遅延のメカニズムは、Non-blockingアルゴリズムを実装に採用する十分な理由になる。しかし、より本質的な並行システムのスケーラビリティの決定要因は他にある。結論を先取りすると「いかに共有メモリへの競合を最小化するか」ということだが、このことについて深く議論されている、BlockingとNon-blockingの性能を詳細に分析した「Latch-free Synchronization in Database Systems: Silver Bullet or Fool’s Gold?」[1]という論文があるので紹介する。
この論文では、マルチコアデータベースシステムにおける低競合、中〜高競合環境でロックアルゴリズム(TATAS[2], MCS[3], Pthread[4])とロックフリーアルゴリズムの性能を比較している。
競合の程度は、スレッドが独立して動作する部分の長さに対する各スレッドが同期を必要とする排他的な処理(クリティカルセクション)の長さで表される。
| 低競合(0.05%) | 中程度の競合(0.5%) | 高競合(5%) |
|---|---|---|
 |
 |
 |
| 全ての手法はコア数以下でスループットを向上、コア数超過時はMCSラッチが大幅低下、TATASラッチは緩やかに低下、Pthread Mutexは比較的安定、ロックフリーは一定のスループットを維持。 | MCSラッチはコア数まではスループットが増加、スレッド数の増加に伴いスループットが直線的に減少。TATASラッチとロックフリーは一定のスレッド数を超えるとスループットが低下。Pthread Mutexは広いスレッド数領域で比較的安定したスループットを示す。 | MCSラッチは20コア程度で最大スループットに達した後、コア数まで同じスループットを維持し続ける。TATASラッチとロックフリーはピークを過ぎると段階的な性能低下が見られる。Pthread Mutexは多スレッド数でも相対的に安定した傾向を維持。 |
このグラフを見るとBlockingなPthread Mutexの方がロックフリーに性能面、スケーラビリティで勝るケースも存在することがわかる。
理論的にはロックフリー及び、Non-blockingアルゴリズムは、特定のスレッドが停止・遅延しても他のスレッドがブロックされないという利点を有している。しかし、競合が多発するマルチコア環境においては、これらの利点が必ずしもストレートにパフォーマンス向上へ繋がらない。
その背景には、ロックフリーアルゴリズム独自のメモリ管理機構(GC)もあるが、主にキャッシュコヒーレンスプロトコルに起因するコストが存在する。ロックフリーアルゴリズムは競合が発生するとスレッドは比較更新操作を何度も繰り返す。そして失敗したアトミック操作が多数発生すると、同じメモリワードへのアクセスが連続的にシリアライズされ、そのメモリアドレスが実質的な「ホットスポット」となる。このホットスポットを保持するキャッシュラインが、各コア間で激しくやり取りされる(キャッシュラインがピンポン状態になる)ことで、キャッシュコヒーレンスプロトコルが大量の無駄なトラフィックを発生させる。こうしたキャッシュラインの頻繁な移動は、メモリアクセスレイテンシを増大させ、結果としてスループット低下やレイテンシ悪化につながることになる。
ただ、今回のケースでロックフリーはPthreadにスケーラビリティで劣っていたものの、他の種類のロックよりパフォーマンスもスケーラビリティもあった。なので「Blocking vs Non-blocking」という二元論的な構造で捉えるのではなく、個々の細かい実装を動作状況や目的に照らし合わせ、「いかに共有メモリへの競合を最小化するか」という方向性で並行アルゴリズムの実装を考えることをおすすめする。
今日はここで終了。並行処理の基礎を終えてRCUの動作原理編に移る。
明日は「Grace Period ~RCUの動作原理~」から勉強する。
おまけ: Livenessについて
並行処理アルゴリズムには、「望むことが最終的に起こる保証」を意味するLiveness(活性)という概念がある。特にNon-blockingの保証するLivenessには、Obstruction-freedom、Lock-freedom、Wait-freedomなどの保証の強弱で成り立つ細かい段階があり、包含関係関係を形成している。これらNon-blockingのLinvenessについてはkumagiさんのプログラミングの魔導書を読んでいただければ、詳しいことがわかる。(当然、それ以外のことも豊富にあります。)正直、RCUではLock-free以外のlivenessが文脈に出てくることはないと思っているので、あまり触れなかった。このアドベントカレンダーに至ってはNon-blocking = Lock-freeと脳内変換していただいて構わない。
このアドベントカレンダーシリーズはかっこいい論文とか記事引用していますけど、DBMS自作コミュニティで面白かった論文を教えてくれる人達のおかげで知れたものばかりです。
Discussion