Day 5: キャッシュコヒーレンスプロトコル ~並行処理の基礎~
キャッシュコヒーレンスプロトコル
昨日はプロセッサ命令について勉強した(のは嘘で、勉強したということにしてまた開いた日に書く)。Rustのメモリモデルさえ理解して適切にコードを書けばコンパイラがCPUのアーキテクチャに適したアセンブリを生成してくれるので大丈夫ではある。今日も昨日と同じくCPUよりの話をするのだが、今日の知識はスケーラブルな並行プリミティブを実装する上でかなり大事な知識になる。
今日の記事は、ざっくりまとめると
「マルチコアで同じメモリの値に対して書き込みを行う処理を書くとその処理はスケールしない」
ということを原理も踏まえて解説する。
CPUとメインメモリ
CPUの命令とデータはメインメモリに保持される。CPUの処理はメインメモリからメモリアクセスをして命令とデータを呼び出して行われる。
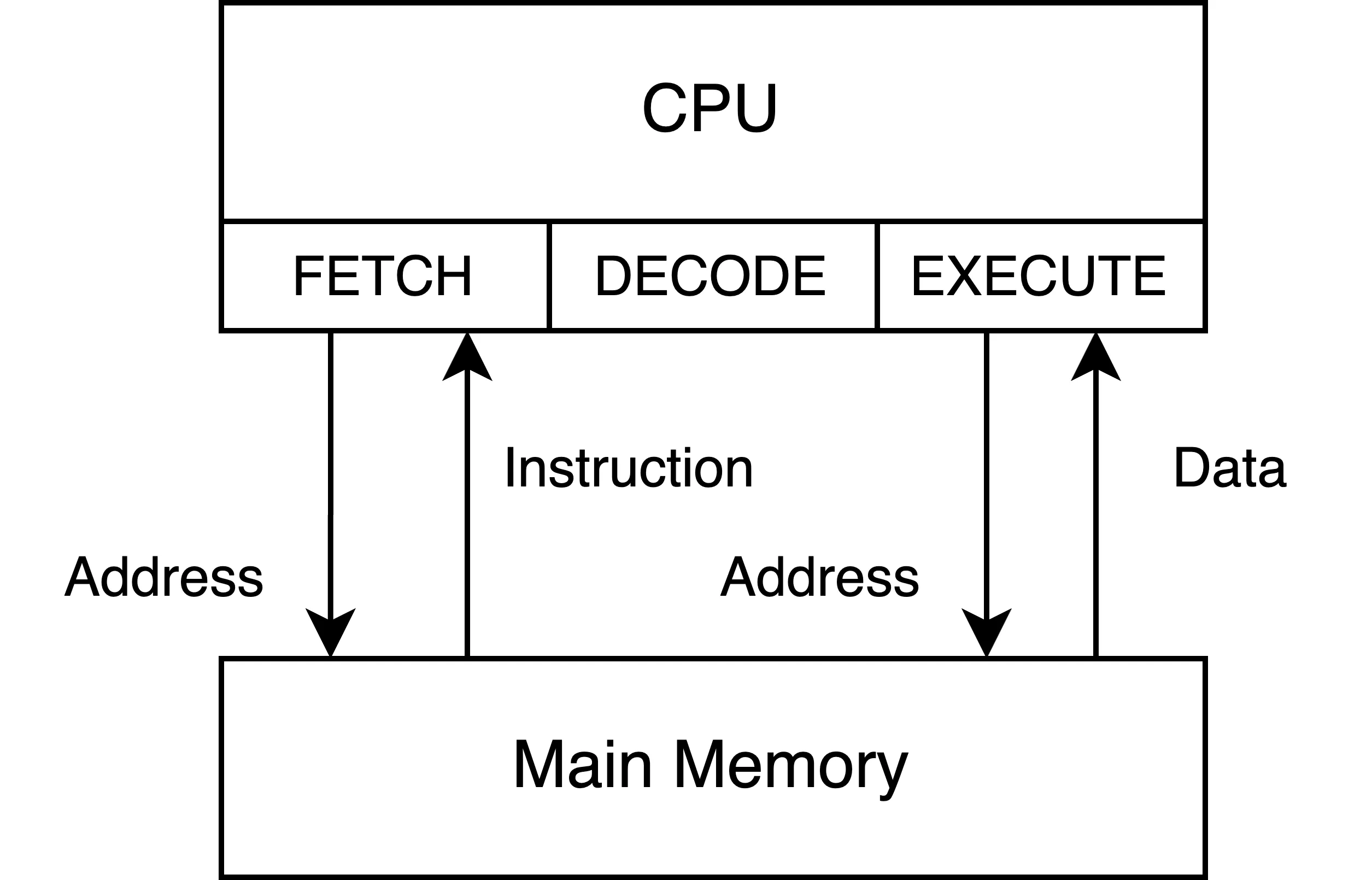
CPUはクロック周波数が数GHzという単位で動作しており、1秒間に数百億の演算が可能である。対してメインメモリに対するアクセスはそのスピードに追いつけない。メモリアクセスだけで100nsがかかり、その間に無駄になるCPUサイクルは数百サイクルになり、このままでは性能が出ない。
そこで、メインメモリの一部をコピーして、メインメモリよりも近い位置に配置することでメモリアクセスを高速化する。これをキャッシュと呼ぶ。キャッシュにも種類があって、プロセッサ内部に組み込まれていて最も高速で小さな記憶容量を持つL1キャッシュ、L1キャッシュよりも大きいが低速なL2キャッシュなどがある。同様にL3, L4もある場合がある。これらのキャッシュが階層化してCPUが頻繁にアクセスするデータや命令を一時的に保存して、メモリアクセスの遅延を大幅に低減する。
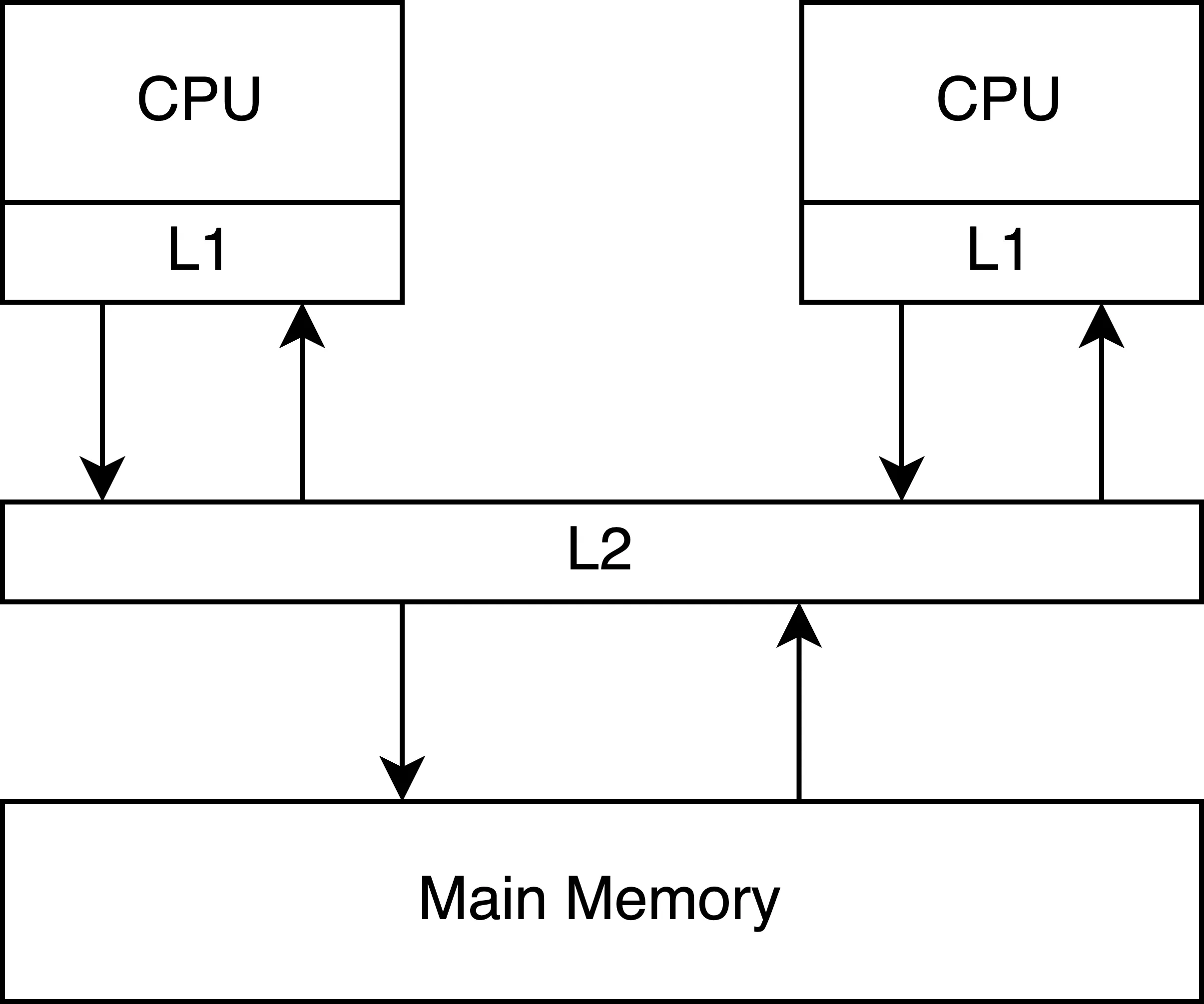
ちなみに容量とアクセス速度にトレードオフがあるため、キャッシュの階層構造がなされている。[1]
L1キャッシュの問題点
CPUごとにL1キャッシュを持つことで、各CPUはメモリアクセスの待ち時間を大幅に削減し、処理性能を向上させることができる。しかし、この構成には重要な課題も伴う。
特に複数のCPUが同じメモリ領域にアクセスする場合、あるCPUがメモリに書き込みを行っても、その更新は当該CPUのL1キャッシュにのみ反映され、他のCPUのL1キャッシュには即座には伝播しない。
仮にこのままL1キャッシュ間の一貫性を保っていない状態で古いキャッシュをCPUが使うと整合性が保てなくなる。

この例と以降の例では、説明をわかりやすくするためにキャッシュラインに整数が単体で入っているとして扱う。
キャッシュコヒーレンスプロトコル(MESIの例)
L1キャッシュ間で同一のアドレスの読み書きで不整合が発生する問題は、マルチコアシステムの信頼性に関わる重要な課題である。この問題に対処するため、プロセッサは各キャッシュラインの状態を監視し、一貫性を維持する仕組みを必要とする。この仕組みが「キャッシュコヒーレンスプロトコル」である。
詳細を追うとかなり複雑なのだが、基本的には以下の2つのルールを意識だけでいい。
- あるCPUがデータを読み込もうとしてキャッシュミスをしたときに、L2やメインメモリよりも先に他のCPUのキャッシュからデータを探す
- そして、他のキャッシュからデータがあった場合はまずその値を次のレイヤに書き出してから、CPU間で共有する
- あるCPUがキャッシュラインにデータを書き込むときに、他のCPUの同じメモリアドレスを共有しているキャッシュラインを無効化する
今回はMESIプロトコルというキャッシュプロトコルを使って説明する。
MESIプロトコルの4つの状態
各キャッシュラインは、以下の4つのステートのいずれかを取る:
| ステート | 説明 |
|---|---|
| Modified(M) | 当該CPUが最新の値を持ち、メインメモリよりも更新が進んでいる状態。他のCPUはこのデータを持っていない。ラインを書き換える際、メモリへ書き戻したり、他のキャッシュに譲渡したりする必要がある。 |
| Exclusive(E) | 当該CPUのみが最新のデータを持っているが、まだメインメモリと同期された値のまま(CPU側で変更されていない)状態。CPUはこの状態からメモリに書き戻しせずにラインを破棄可能。 |
| Shared(S) | 他のCPUも同じデータを持っている可能性がある状態。データはメインメモリと同期された値で、CPUは書き込み前に他のCPUへの通知が必要。書き戻し無しで破棄可能。 |
| Invalid(I) | そのラインは有効なデータを保持していない状態。 |
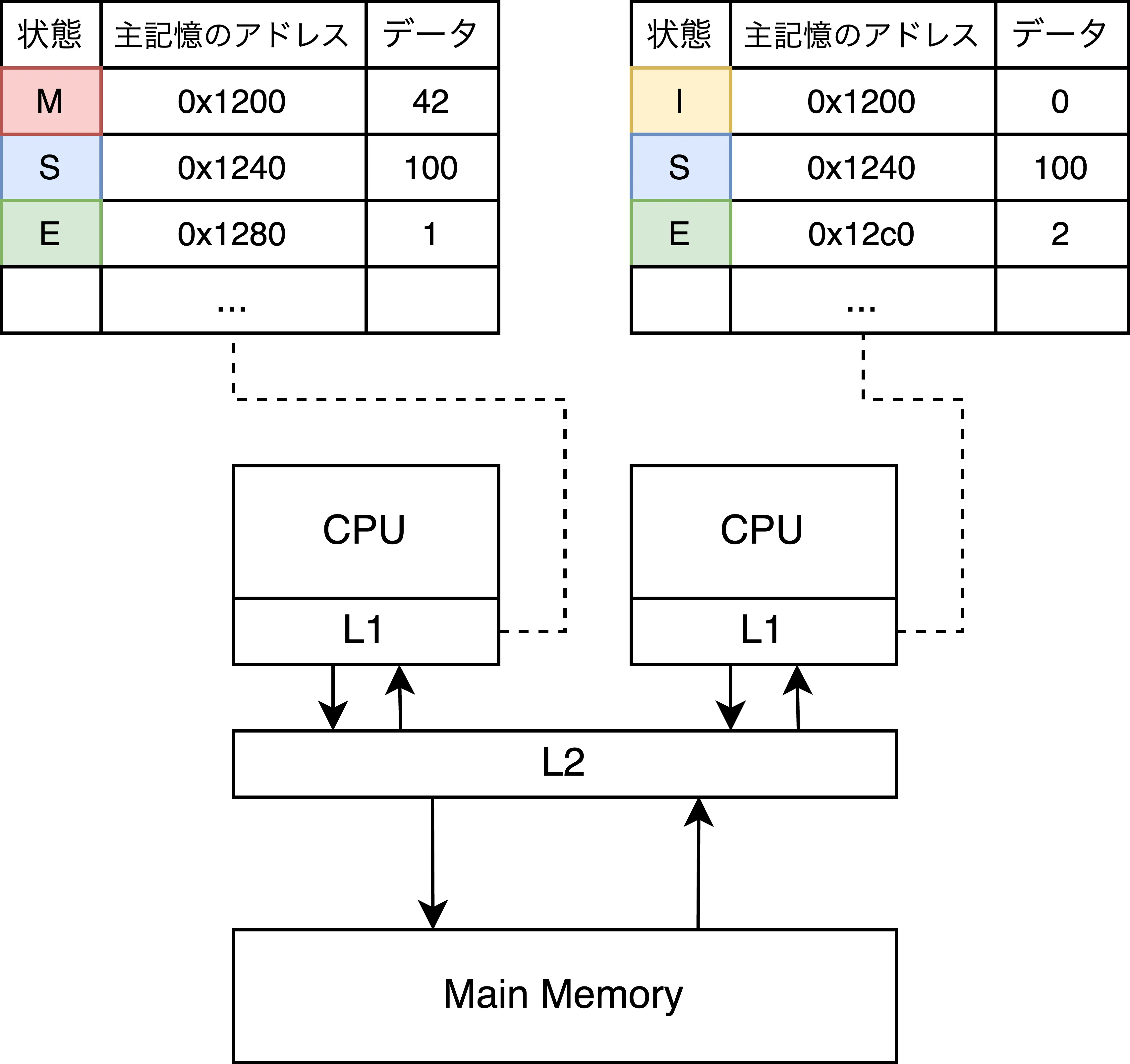
MESIプロトコルの状態遷移
これらのキャッシュラインのステートはCPU間のやり取りによって推移される。
ステート推移のケースと説明を以下にまとめる:
| 遷移 | 説明 | 詳細 |
|---|---|---|
| S→M | CPUがSharedなキャッシュラインに対して書き込みを行う時に推移する | CPUは他のCPUの該当キャッシュラインをInvalid状態に遷移させ、その後自分のキャッシュラインをModifiedにする。 |
| M→S | 他のCPUがModifiedなキャッシュラインを読み取る時に推移する | CPUはデータを下層のレイヤーに書き戻し、自分のキャッシュラインをShared状態に変更する。 |
| E→M | CPUがExclusiveなキャッシュラインに対して書き込みを行う時に推移する | CPUは自分のキャッシュラインをModified状態に変更する。 |
| S→I | 他のCPUがSharedなキャッシュラインをInvalidにする際に推移する | CPUは該当キャッシュラインをInvalid状態に変更する。 |
1.3.の冒頭で触れたルールをおさらいする
- あるCPUがデータを読み込もうとしてキャッシュミスをしたときに、L2やメインメモリよりも先に他のCPUのキャッシュからデータを探す
- そして、他のキャッシュからデータがあった場合はまずその値を次のレイヤに書き出してから、CPU間で共有する
- あるCPUがキャッシュラインにデータを書き込むときに、他のCPUのキャッシュラインを無効化する
これら1と2のルールをアニメーションにしてみた。[2]
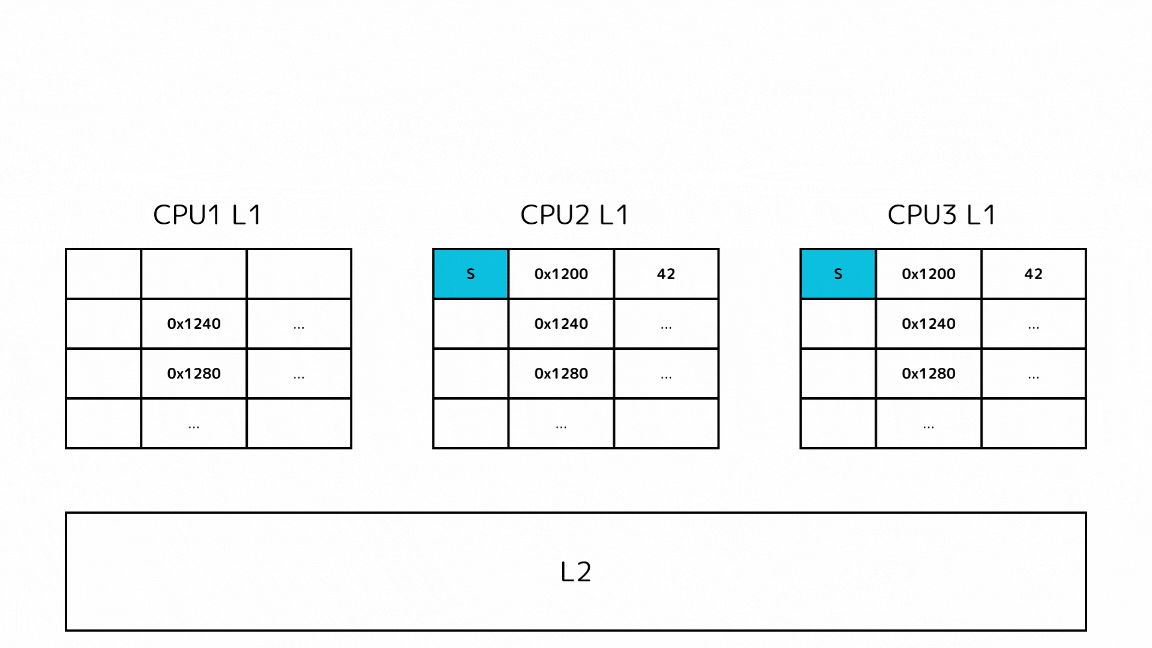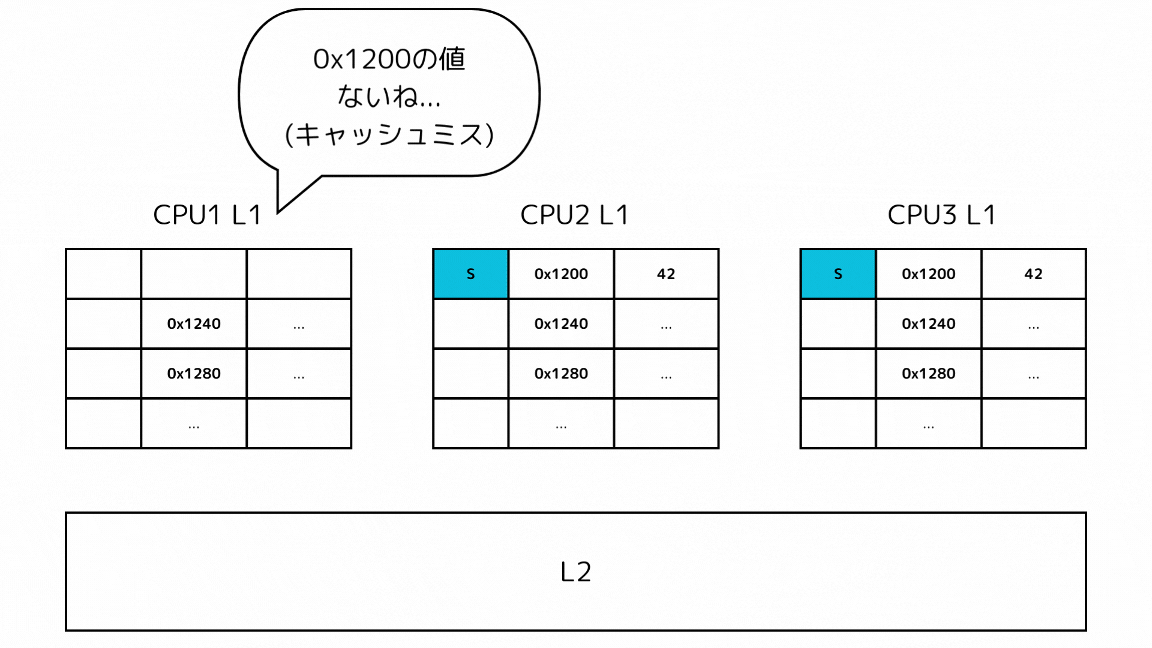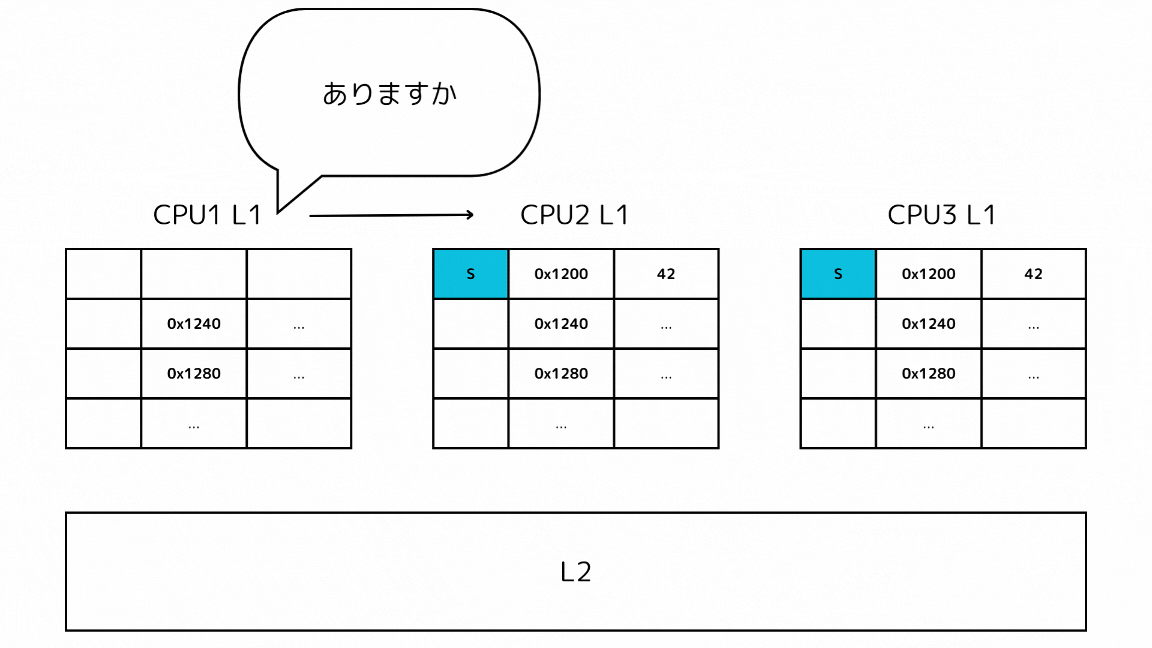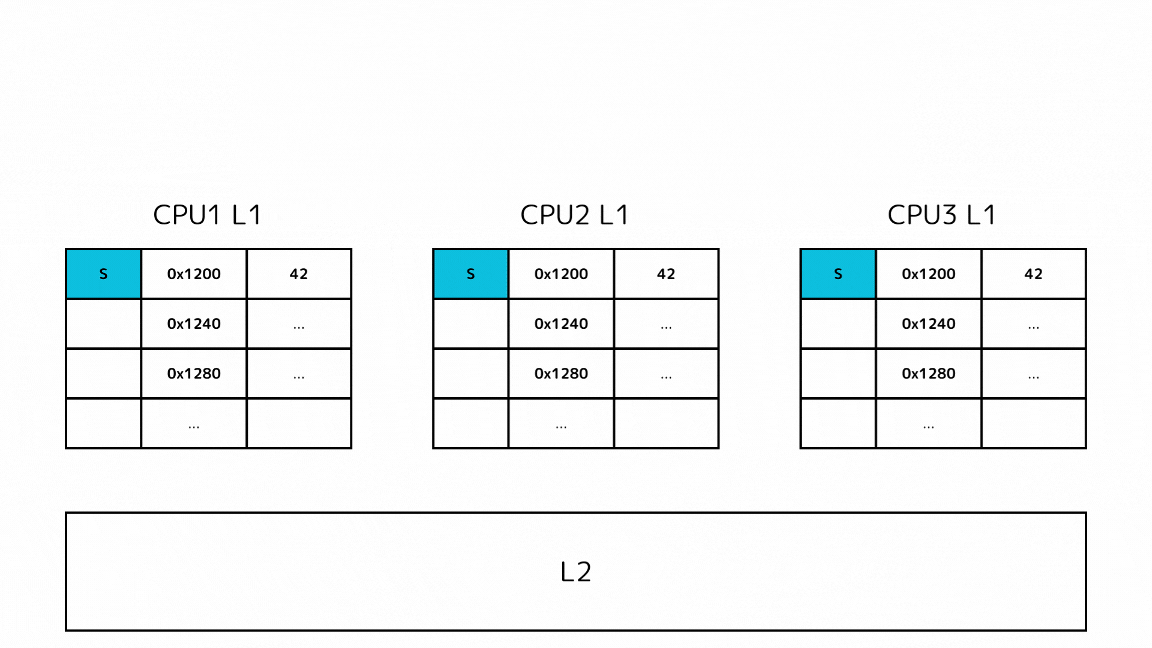
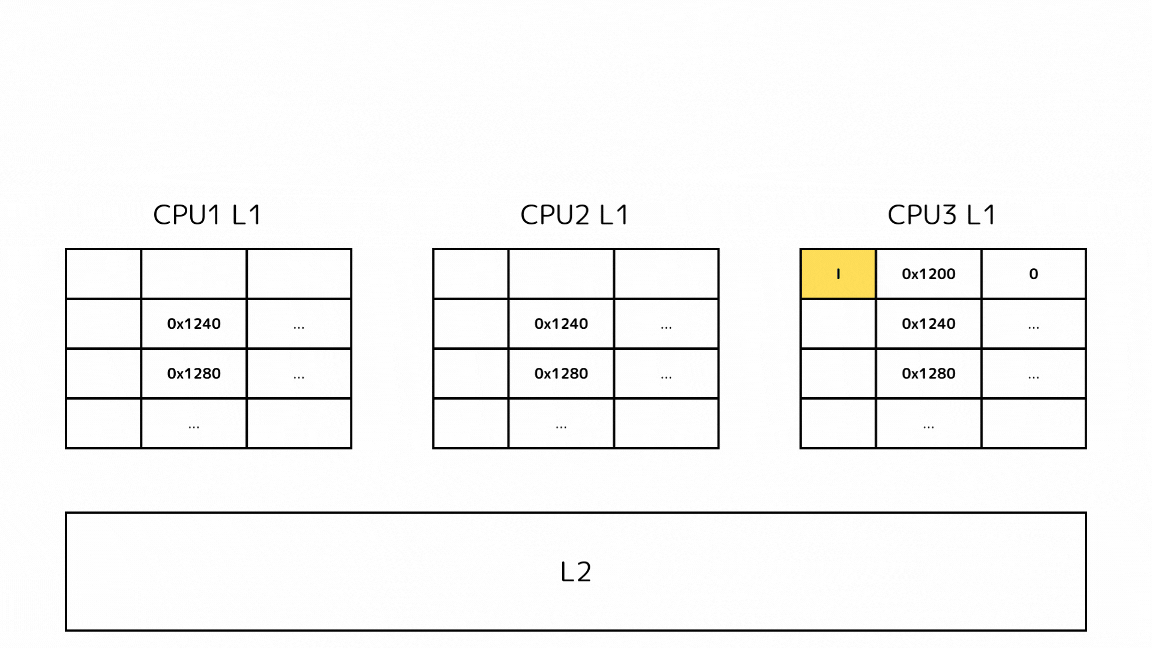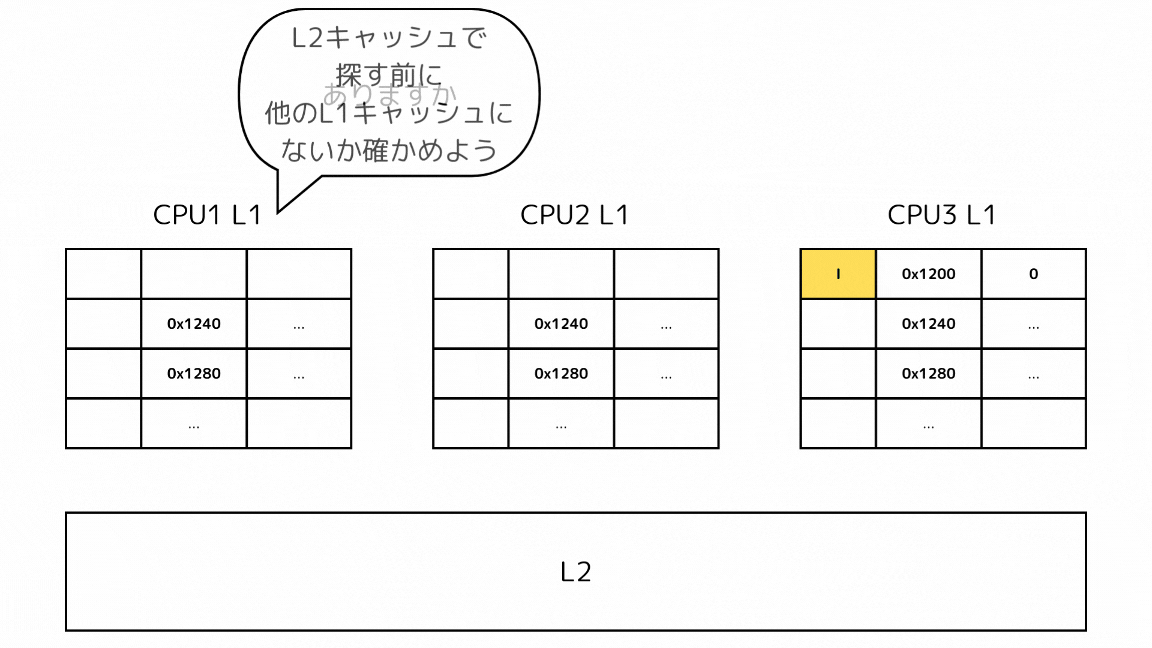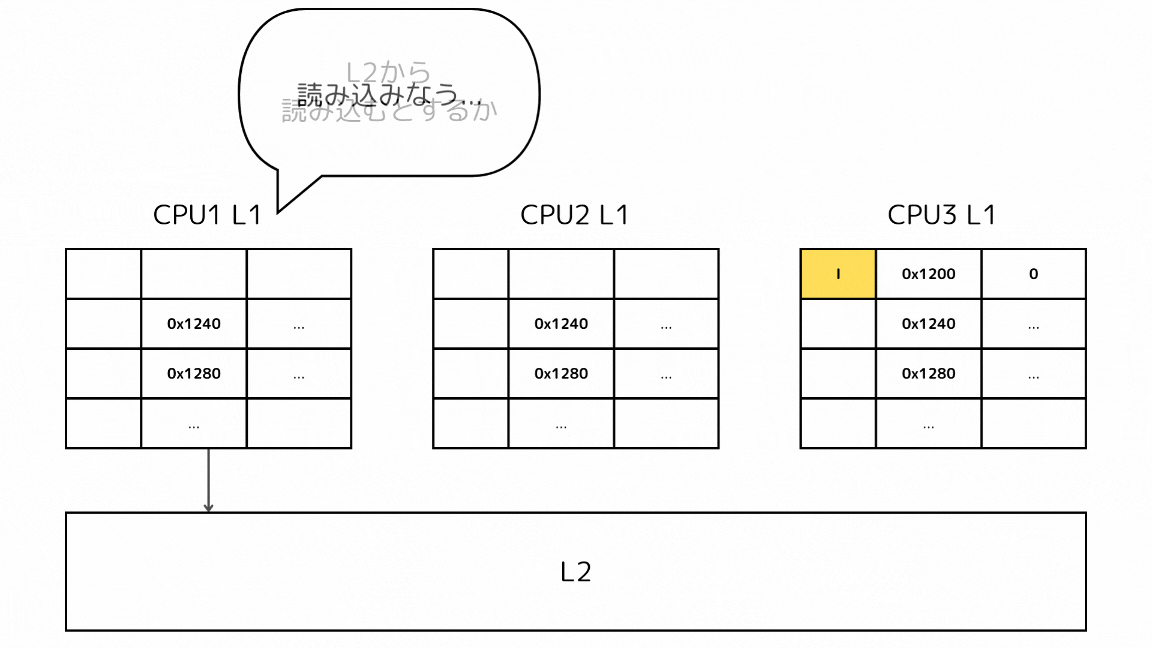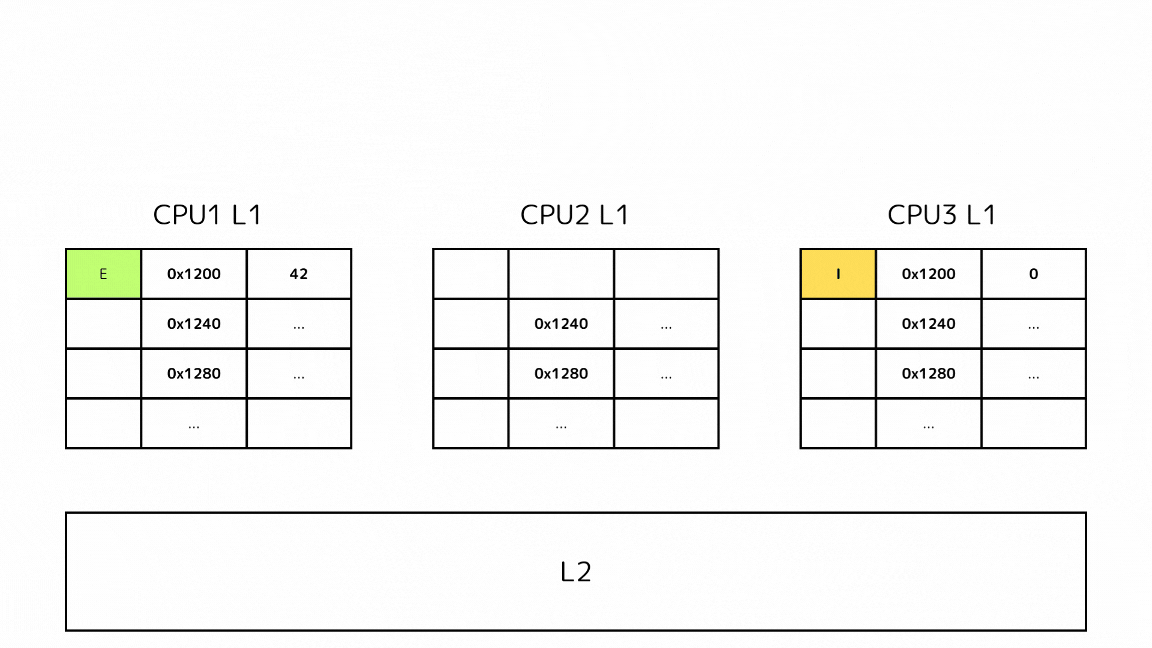
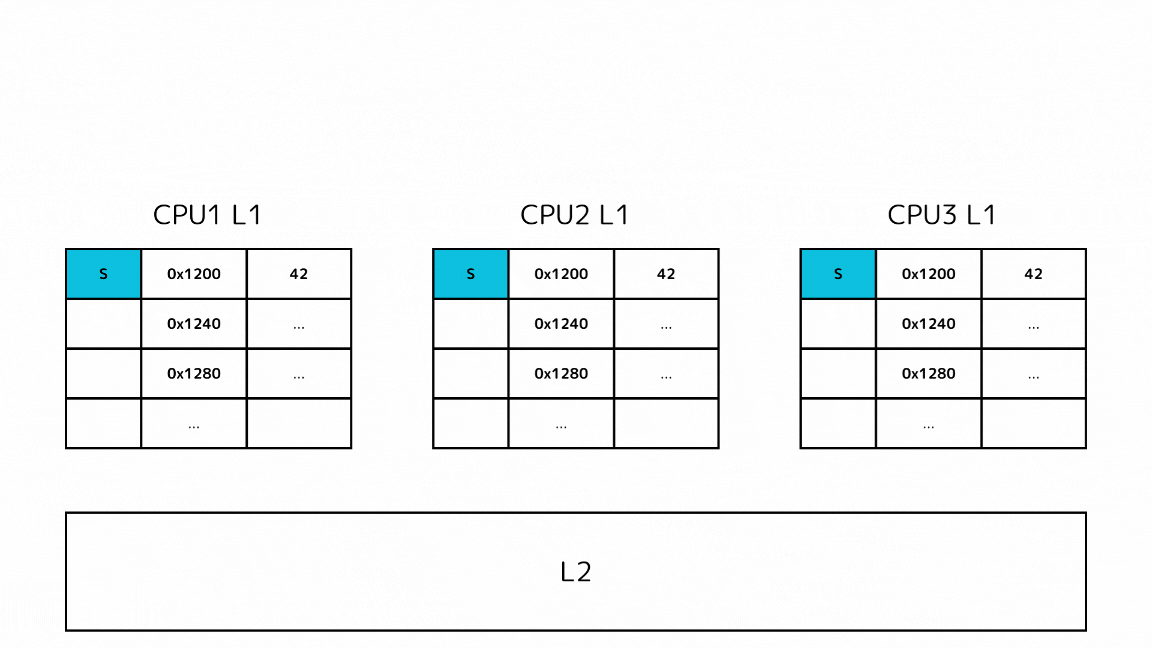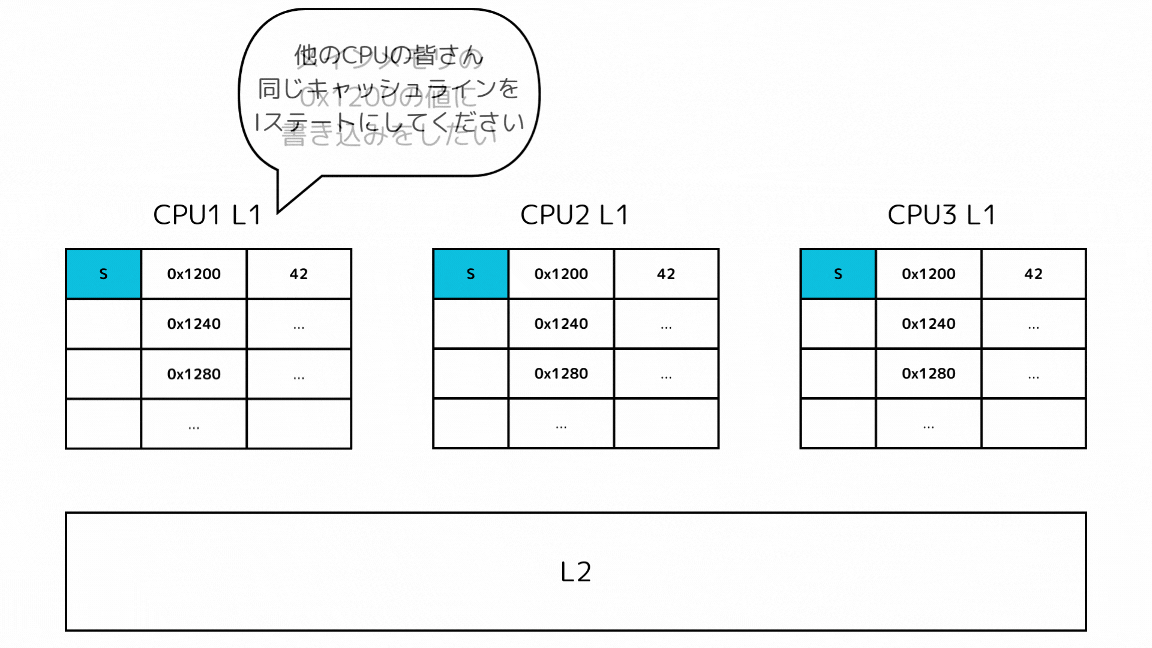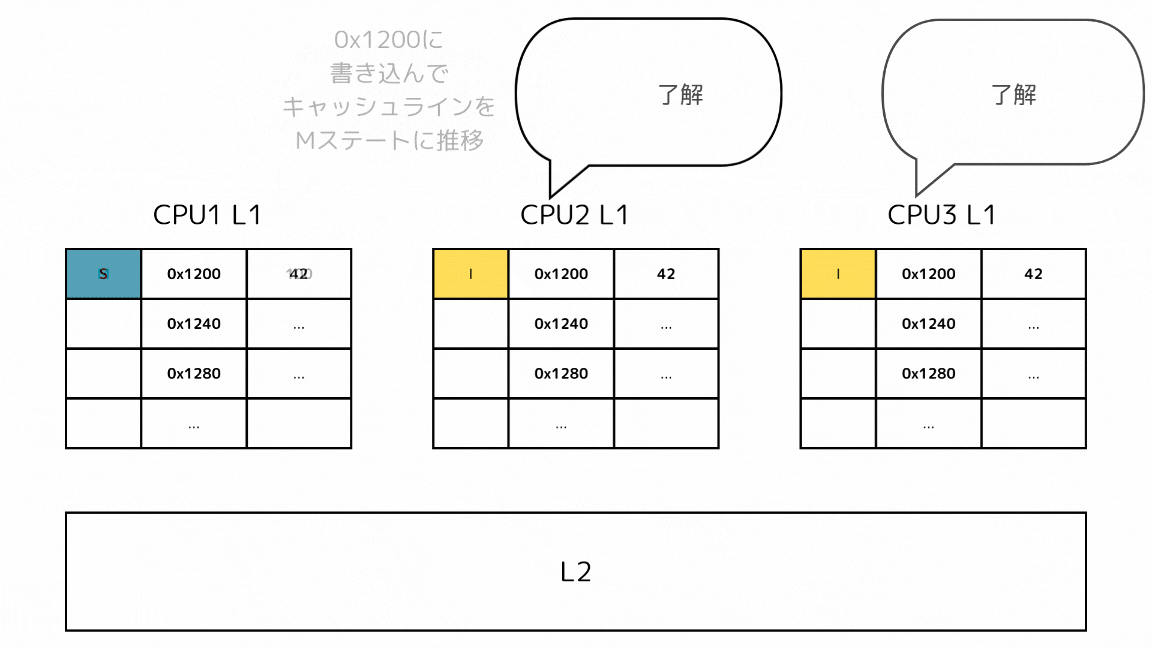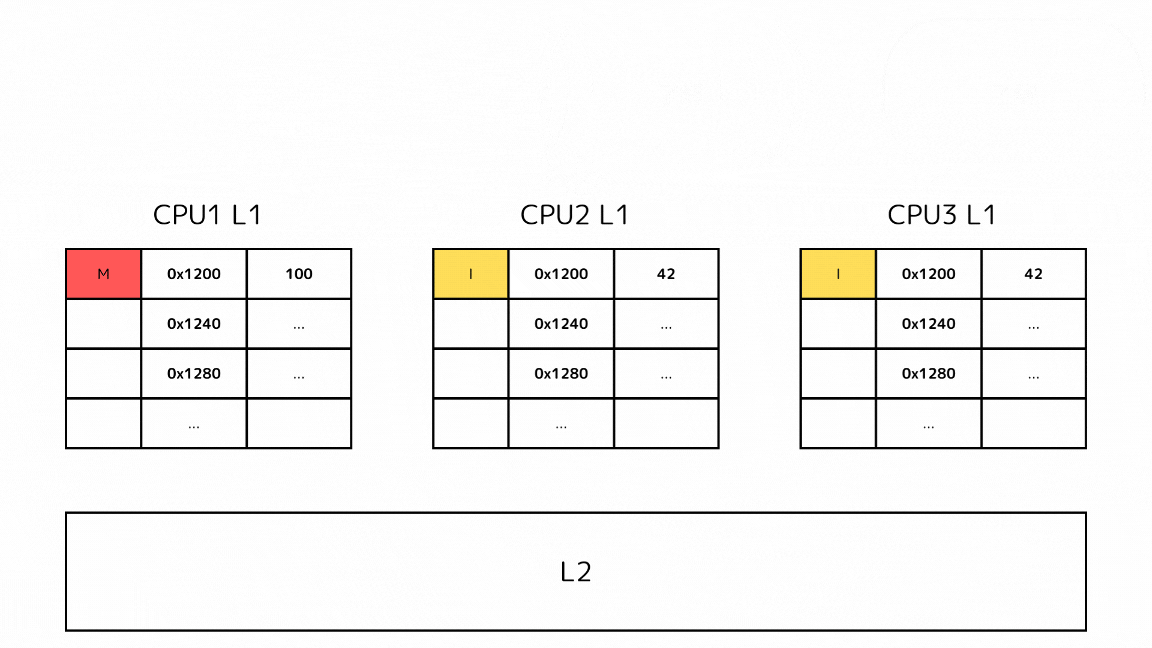
1-1: 他のキャッシュで探すキャッシュラインのステートがSの場合
- CPUがあるメモリアドレスのデータを読み込もうとしてキャッシュミスする
- L2の前に他のL1キャッシュから読み込もうとしているキャッシュラインを探す
- 他のL1キャッシュのSステートのキャッシュを取得する
1-2: 他のキャッシュで探すキャッシュラインのステートがMの場合
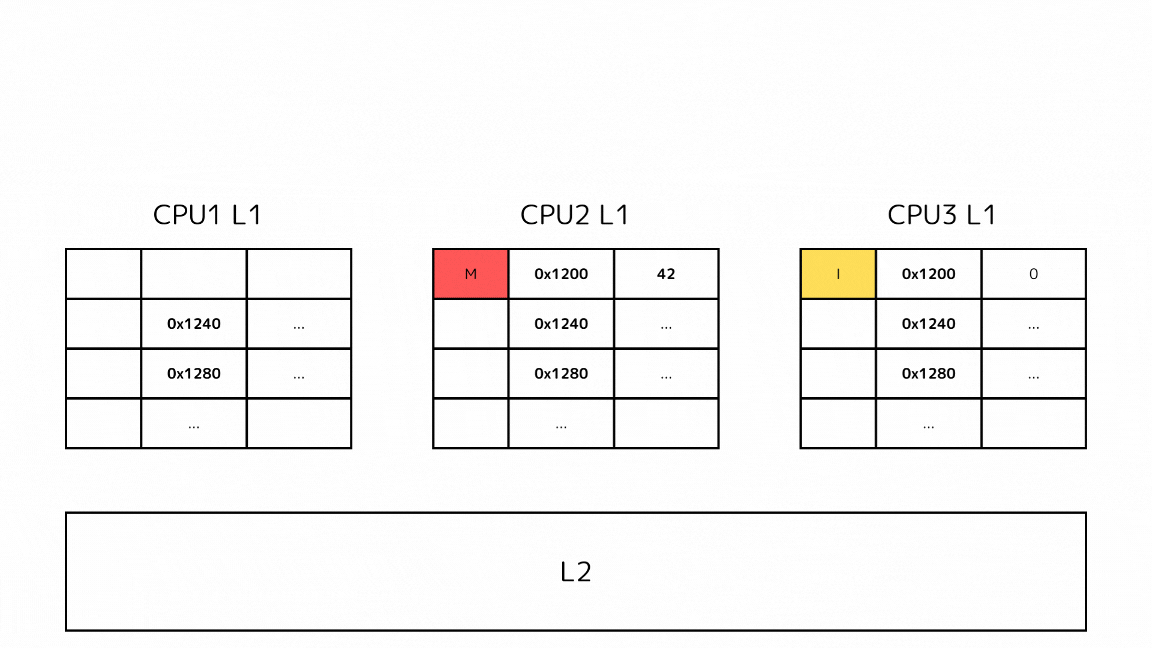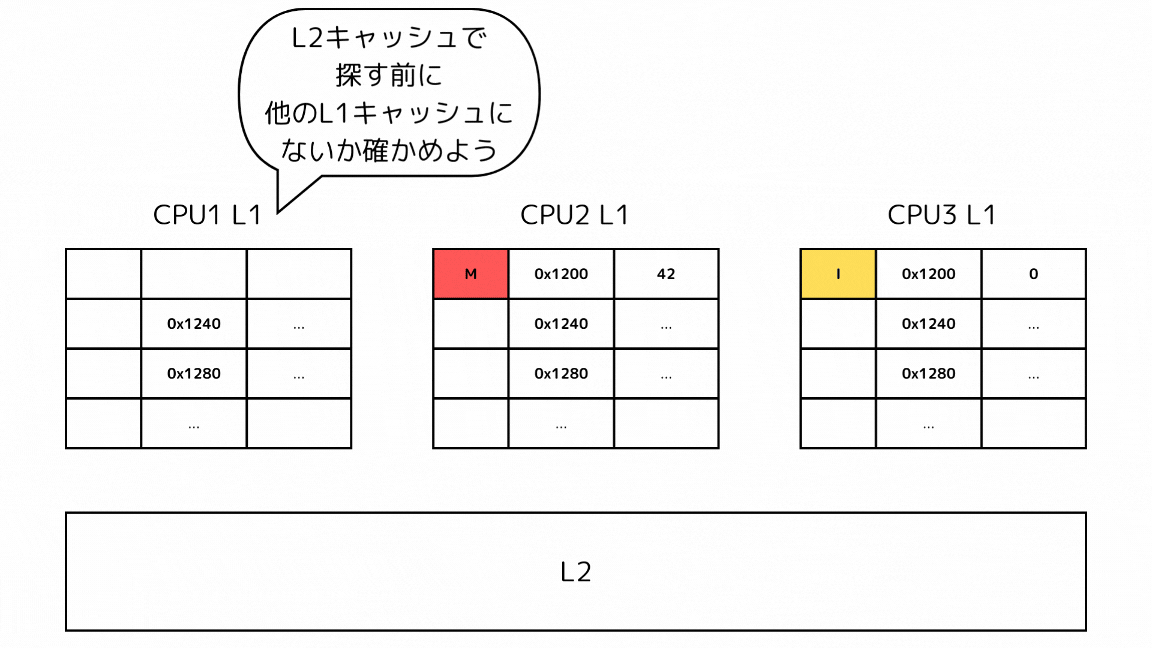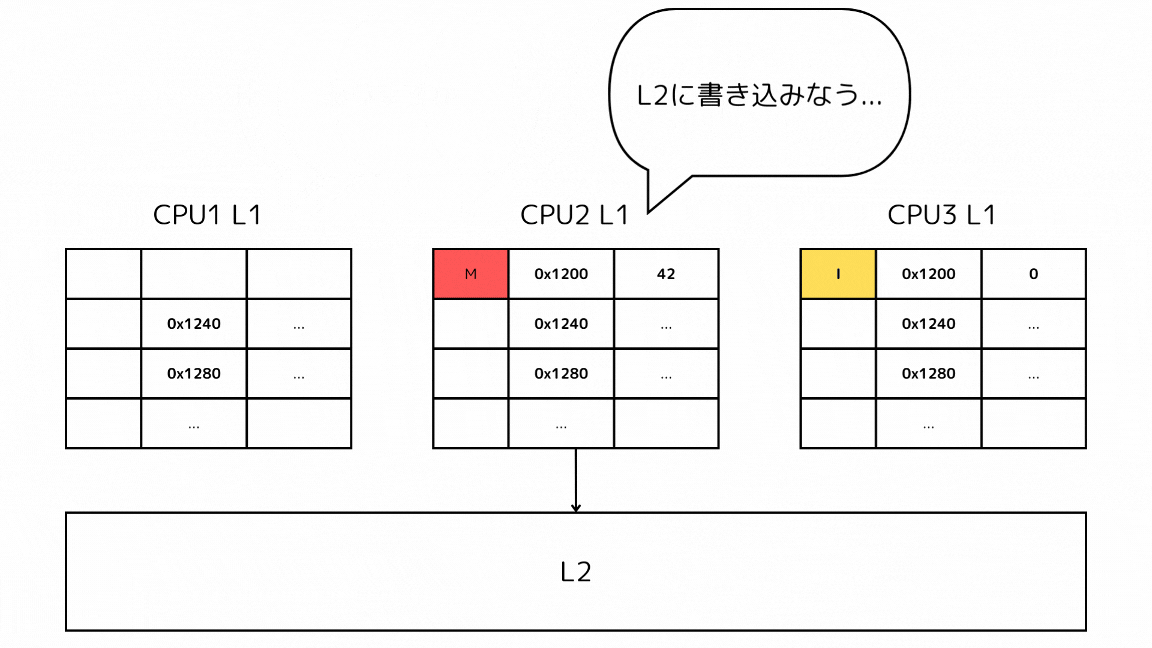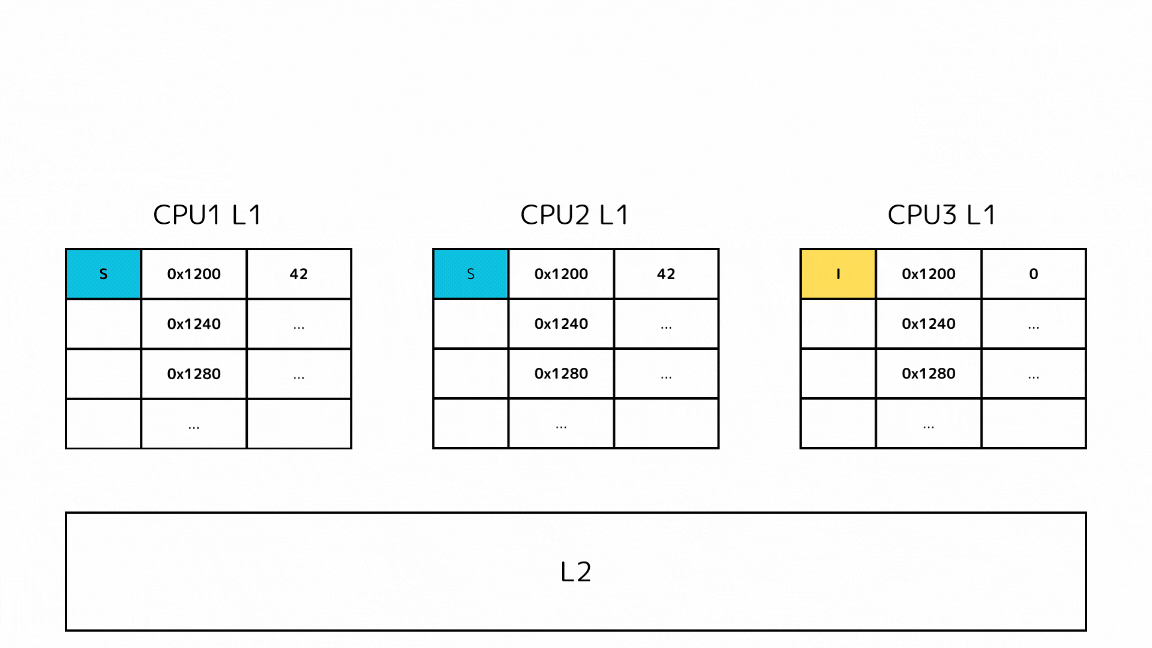
- CPUがあるメモリアドレスのデータを読み込もうとしてキャッシュミスする
- L2の前に他のL1キャッシュから読み込もうとしているキャッシュラインを探す
- Mステートのキャッシュが見つかったので、一度下層のメモリに書き出す
- 書き出したらSステートに推移させて、キャッシュを取得する
1-3: 他のキャッシュで探すキャッシュラインに何もない場合
- CPUがあるメモリアドレスのデータを読み込もうとしてキャッシュミスする
- L2の前に他のL1キャッシュから読み込もうとしているキャッシュラインを探す
- 他のL1キャッシュが全て同じメモリアドレスに該当するキャッシュラインが存在しない、無効なキャッシュラインしか存在しない場合は、L2から取得する
- L2から取得したということは、そのメモリアドレスを持っているのは自身のL1キャッシュしかないということなのでEステートを持つ
- Eステートは書き出し操作をするとMステートになる点はSステートと変わらないが、他のCPUに同じキャッシュラインの無効化をするメッセージを送信しなくてもいい特徴がある
2: 書き込み時に他のSステートのキャッシュをIステートにする
- CPUがあるメモリアドレスに書き込みをしようとする
- その前に他のCPUに同じキャッシュラインを持っていたらIステートにするメッセージを送信する
- 他のL1キャッシュのキャッシュラインがIステートになった後で、メモリアドレスに書き込みをして、自身のキャッシュラインをMステートにする
- 書き込みの影響でIステートになったキャッシュラインに読み込みが発生した場合、キャッシュミスとして処理される
キャッシュコヒーレンスプロトコルと速度性能
キャッシュコヒーレンスプロトコルの仕組みを理解した。次はキャッシュコヒーレンスプロトコルが与える速度性能への影響を調べる。
初めに知っておきたい指標を紹介する。
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns
Mutex lock/unlock 100 ns
Main memory reference 100 ns
Compress 1K bytes with Zippy 10,000 ns
Send 2K bytes over 1 Gbps network 20,000 ns
Read 1 MB sequentially from memory 250,000 ns
Round trip within same datacenter 500,000 ns
Disk seek 10,000,000 ns
Read 1 MB sequentially from network 10,000,000 ns
Read 1 MB sequentially from disk 30,000,000 ns
Send packet CA->Netherlands->CA 150,000,000 ns
Dean, J. "Software Engineering Advice from Building Large-Scale Distributed Systems." Presentation slides.
https://static.googleusercontent.com/media/research.google.com/en//people/jeff/stanford-295-talk.pdf
これはJeff Dean先生の「Numhers Everyone Should Know」」という有名なコンピュータの処理速度に関する指標なのだが、特に並行処理の文脈だと以下の5つ、その中でも特に参照に関わる指標が重要となる。
- L1 cache reference 0.5 ns (L1キャッシュ参照)
- Branch mispredict 5 ns (分岐予測ミス)
- L2 cache reference 7 ns (L2キャッシュ参照)
- Mutex lock/unlock 100 ns (Mutexのlock/unlock)
- Main memory reference 100 ns (メインメモリ参照)
実際にこれを元にCPU-L1キャッシュ-L2キャッシュの距離と参照にかかる速度と等しい割合になるように図を書いてみる。[3]
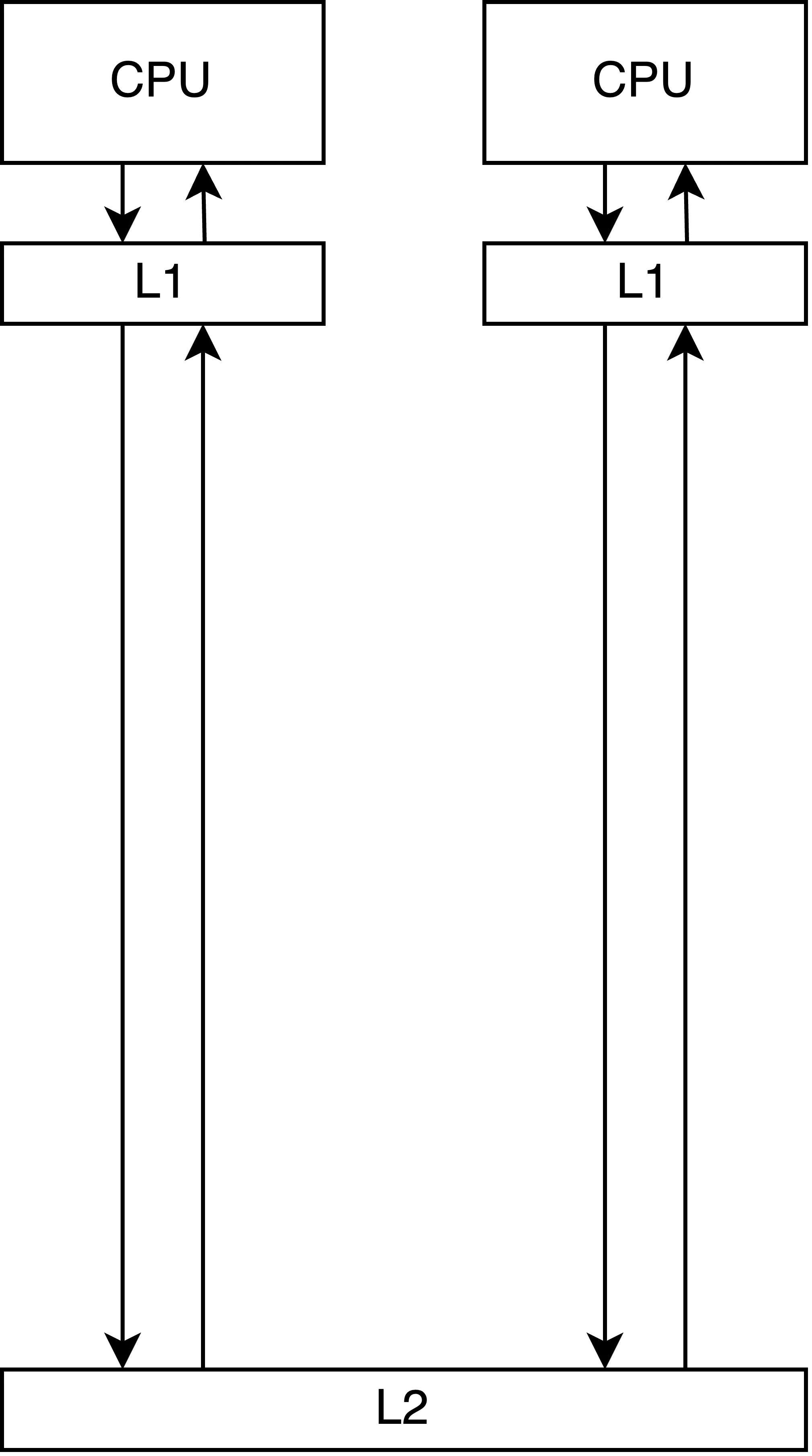
L1キャッシュ参照のコストと比べるとL2キャッシュへの参照コスト、図にはないがメインメモリへの参照コストは比較的に大きいコストであることがわかる。当初はメインメモリまでの距離も図に入れようと思ったが、スクロールが長くなりすぎると思って断念した。実はL1キャッシュ間にも距離が存在するのだが、L1キャッシュ間のやり取りがns単位でどれくらい時間がかかるかといったデータが見つかる範囲ではなかった。代わりに、小規模なマルチプロセッサ構成で10から数十サイクル、中規模であれば100サイクル規模の無視できない時間がかかるという情報は存在した[4]。
ここまで読むと最初の「マルチコアで同じメモリの値に対して書き込みを行う処理を書くとその処理はスケールしない」というフレーズの意味がわかると思う。
要するにマルチコアで同じメモリの値に対して書き込みを行う問題は2つある。
- 他のSステートのキャッシュラインをIステートに遷移させること
- のちにCPUがアクセスした際にキャッシュミスになる
- 自身のキャッシュラインがMステートとなること
- 他のCPUとMステートのキャッシュラインを共有するときに、一度下層のメモリに書き込んでSステートにしなければならない
False SharingやNUMA構成のマルチプロセッサではどうなるのかなどまだ話したりないところはあるが、理論的な話は以上である。
キャッシュコヒーレンス制御の速度性能の影響を計測する
...まだ続くよ...また後日埋めます。
どのようにキャッシュコヒーレンス制御を避けるか
...まだ続くよ...また後日埋めます。
-
https://fgiesen.wordpress.com/2016/08/07/why-do-cpus-have-multiple-cache-levels/ ↩︎
-
Canvaで苦労して作ったので見てほしい(切実) ↩︎
-
この発想はkumagiさんのキャッシュコヒーレントに囚われない並列カウンタ達のもの ↩︎
-
Takenobu Tani (2023)『プログラマーのためのCPU入門』ラムダノート ↩︎
Discussion