QAデータセットからranxの評価用データを作成して埋め込みモデルを評価する
Embeddingモデルやベクトル検索など、retrievalの評価にranxを使ってきた。
ranxでは、データセットからQrelsと呼ばれる評価用データを作成、retrievalの実行結果であるRunsと比較することで、評価を行う。
過去に自分がよく使っていたデータセットが非公開となったため、京都大学大学院情報学研究科知能情報学コース言語メディア研究室 (https://nlp.ist.i.kyoto-u.ac.jp/)様が公開されている尼崎市のFAQデータセットを使用してQrelを作成する。
日本語の論文はおそらくこちらだと思う
Colaboratoryで。
データセットをダウンロードして展開
!wget https://tulip.kuee.kyoto-u.ac.jp/localgovfaq/localgovfaq.zip
!unzip localgovfaq.zip
ディレクトリ構造は以下となっている
$ tree localgovfaq
localgovfaq
├── qas
│ ├── answers_in_Amagasaki.txt
│ └── questions_in_Amagasaki.txt
├── README.md
├── samples
│ ├── bert.txt
│ ├── joint.txt
│ └── tsubaki.txt
├── testset_segmentation.txt
└── testset.txt
2 directories, 8 files
README.mdに各ファイルおよびフォーマットについて説明があるのでそれを読めばよいのだが、使用するのは以下の3つ。
qas/questions_Amagasaki.txt/qas/answers_Amagasaki.txt
QAペアの質問と回答が別々のファイルに分かれている。それぞれ以下のようなフォーマットになっている。
ID\t質問文
ID\t回答文
- 両方ともTSV
- 各質問・各回答に連番のIDが付与されている。質問と回答でIDが一致すればQAペアとなる。
- 質問文および回答文は、分かち書き、つまりスペースを含んでいる。
- QAペア数は約1700件
つまりQとAはそれぞれ1対1となっているので、シンプルな評価ならば、QとAのIDを紐づけて関連度1としたQrelsを作成すればよい。
import pandas as pd
def file2list(filename: str, prefix: str = "") -> tuple:
"""Q/AファイルをIDとコンテンツに分割、それぞれを配列で返す"""
contents = []
ids = []
try:
with open(filename, 'r') as file:
for line in file:
line = line.strip().replace(" ", "")
id, content = line.split('\t')
if prefix:
id = f"{prefix}_{id}"
contents.append(content)
ids.append(id)
except Exception:
raise
return contents, ids
# 見分けやすいようにIDにはプレフィックスを付けている
questions, qids = file2list("localgovfaq/qas/questions_in_Amagasaki.txt", "Q")
answers, aids = file2list("localgovfaq/qas/answers_in_Amagasaki.txt", "A")
train_df = pd.DataFrame({'QID': qids, 'QUESTION': questions, 'AID': aids, 'ANSWER': answers})
# qrelsを作成
qrels = []
for _, row in train_df.iterrows():
qid = row["QID"]
aid = row["AID"]
qrel = "{} 0 {} 1".format(qid, aid)
qrels.append(qrel)
with open('qrels.trec', 'w') as file:
for qrel in qrels:
file.write(f"{qrel}\n")
こういう感じでQrelsのファイルが作成される。
Q_0 0 A_0 1
Q_1 0 A_1 1
Q_2 0 A_2 1
Q_3 0 A_3 1
Q_4 0 A_4 1
Q_5 0 A_5 1
Q_6 0 A_6 1
Q_7 0 A_7 1
Q_8 0 A_8 1
Q_9 0 A_9 1
Q_10 0 A_10 1
(snip)
Runsを作成する場合には、
- Aのベクトルを取得して、AのIDをメタデータに含めて、ベクトルDBに登録
- QでベクトルDBを検索して、AのメタデータからIDを取り出す
- QのID、AのID、ランキング、スコアを含めたRunを作成
で、QrelsとRunsをranxで評価すれば良い。ここは後述。
testset.txt
1対1で評価するならば、上記のとおりなのだが、1対多や関連度にグラデーションがある場合は、こちらのファイルを使えば良い。こちらが本来の評価用データ。
こちらのファイルは以下のようなフォーマットになっている
クエリ\t正しい情報を含む回答ID\関連する情報を含む回答ID\クエリと類似のトピックだが関連情報を含まない回答のID
- TSV
- クエリは、分かち書き、つまりスペースを含んでいる。
- 各回答IDは、クエリとの関連度の違いにより、上記の3つに分けられている
- 複数の場合もある、その場合はスペース区切り
- 関連する回答IDがない場合は文字列"None"となる
- クエリは約800件
上にもある通り、回答IDの関連度は以下の3つとなっている。
- 正しい情報を含む回答ID
- 関連する情報を含む回答ID
- クエリと類似のトピックだが関連情報を含まない回答
以前Qrelsの定義を調べた際には、関連度は基本的には以下のバイナリで表現されるのだが、
-
0:関連しない、エントリがないのと同じ -
1: 関連する
ranxの評価メトリクスの中には関連度のグラデーションを取れるものがある。この場合には、より高い数値を指定すれば良い様子。よって、
-
2: 正しい情報を含む回答ID -
1: 関連する情報を含む回答ID -
0: クエリと類似のトピックだが関連情報を含まない回答
というふうに関連度を定義すればよいと思う。ただし関連度グラデーションに対応していないメトリクスでは、1以上はすべて1と同じとして扱われるようなので、選択するメトリクスも考える必要がある。
def split_ids(ids_str: str, prefix: str = "")->list:
if ids_str != "None":
if prefix:
return [f"{prefix}_{id}" for id in ids_str.split()]
return ids_str.split()
else:
return []
def testset2list(filename):
queries = []
ids_correct = []
ids_relavant = []
ids_irrelavant = []
try:
with open(filename, 'r') as file:
for line in file:
query, *ids = line.strip().split('\t')
query = query.replace(" ","")
correct_ids = split_ids(ids[0], "A")
relavant_ids = split_ids(ids[1], "A")
irrelavant_ids = split_ids(ids[2], "A")
queries.append(query)
ids_correct.append(correct_ids)
ids_relavant.append(relavant_ids)
ids_irrelavant.append(irrelavant_ids)
except Exception as e:
raise
return queries, ids_correct, ids_relavant, ids_irrelavant
queries, all_ids_correct, all_ids_relavant, all_ids_irrelavant = testset2list("localgovfaq/testset.txt")
query_ids = ["T_" + str(i) for i in range(len(queries))]
test_df = pd.DataFrame(
{
'QUERY_ID': query_ids,
'QUERY': queries,
'CORRECT_ANSWER_IDS': all_ids_correct,
'RELAVANT_ANSWER_IDS': all_ids_relavant,
'IRRELAVANT_ANSWER_IDS': all_ids_irrelavant,
}
)
test_qrels = []
for _, row in test_df.iterrows():
query_id = row["QUERY_ID"]
correct_ids = row["CORRECT_ANSWER_IDS"]
relavant_ids = row["RELAVANT_ANSWER_IDS"]
irrelavant_ids = row["IRRELAVANT_ANSWER_IDS"]
if correct_ids:
for id in correct_ids:
qrel = "{} 0 {} 2".format(query_id, id)
test_qrels.append(qrel)
if relavant_ids:
for id in relavant_ids:
qrel = "{} 0 {} 1".format(query_id, id)
test_qrels.append(qrel)
if irrelavant_ids:
for id in irrelavant_ids:
qrel = "{} 0 {} 0".format(query_id, id)
test_qrels.append(qrel)
with open('test_qrels.trec', 'w') as file:
for qrel in test_qrels:
file.write(f"{qrel}\n")
こんな感じのQrelsが作成される
T_0 0 A_71 2
T_0 0 A_87 2
T_0 0 A_469 1
T_0 0 A_36 0
T_1 0 A_1770 1
T_1 0 A_1769 1
T_2 0 A_593 0
T_2 0 A_375 0
T_3 0 A_119 2
T_3 0 A_386 2
T_3 0 A_19 0
T_3 0 A_1131 0
T_3 0 A_883 0
(snip)
Runsを作成する場合には、
-
qas/answers_Amagasaki.txtを使って、Aのベクトルを取得して、AのIDをメタデータに含めて、ベクトルDBに登録 -
testset.txtのクエリでベクトルDBを検索して、AのメタデータからIDを取り出す - クエリのID、AのID、ランキング、スコアを含めたRunを作成
という感じになる。で、QrelsとRunsをranxで評価すれば良い。こちらも後述。
上記で以下のデータが作成される
-
qrels.trec: 質問と回答が1対1のQrelデータ -
test_qrels.trec: 質問に対して複数の回答・回答の関連度にグラデーションがある場合のQrelデータ
なお、上記の過程で作成したpandasのデータフレームx2はインデックス作成時およびretrieval実行時に使用する。
-
train_df:qas/{questions,answers}_Amagasaki.txtから作成したデータフレーム -
test_df:testset.txtから作成したデータフレーム
1対1の評価
では実際にこれらのQrelsを使ってranxで評価を行う。まず1対1の評価ではqrels.trecを使う。
- Colaboratoryを使う
- EmbeddingモデルはOpenAIの以下のモデルを使う
- text-embedding-ada-002
- text-embedding-3-small
- text-embedding-3-large
- retrieverはLlamaIndexを使って実装する
- 評価メトリクスは以下を使う。
- Hit Rate: 関連回答が指定したtop-kに含まれるかどうか
- MRR: 関連回答が上位に近いか
パッケージインストール
!pip install -U ranx llama-index
OpenAI APIキーをセット
from google.colab import userdata
import os
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
test_dfを使って、LLamaIndexでデータフレームからノードを作成してインデックスに登録する。
from tqdm.auto import tqdm
from llama_index.core.schema import TextNode, NodeRelationship, RelatedNodeInfo
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import VectorStoreIndex
# データフレームから回答を取り出してLlamaIndexに登録するノードを作成
nodes = []
for idx, row in train_df.iterrows():
aid = row["AID"]
text = row["ANSWER"]
node = TextNode(text=text, id_=aid)
nodes.append(node)
# 各Embeddingモデルの定義
index_settings = {
"openai-text-embedding-ada-002": OpenAIEmbedding(model="text-embedding-ada-002"),
"openai-text-embedding-3-small": OpenAIEmbedding(model="text-embedding-3-small"),
"openai-text-embedding-3-large": OpenAIEmbedding(model="text-embedding-3-large"),
}
# 各Embeddingモデルごとにインデックスを作成
indexes = {}
for model_name, embed_model in index_settings.items():
print(f"Processing {model_name}")
indexes[model_name] = VectorStoreIndex(nodes, embed_model=embed_model, show_progress=True)
なお、各Embeddingモデルごとにデータ件数分のEmbeddingが作成することになる。データは1786件あり、今回3モデルでEmbeddingを生成するため、1786 x 3 = 合計5358件のEmbeddingデータが生成される。コストを気にする方は注意。

インデックスの作成が終わったらretrievalを行う。こちらも元データのクエリ数 x モデル数のEmbeddingが作成される。なお、retrievalは上位100件を取っているが、これは後からカットオフで絞り込めるので多めに取るようにしている。
# retrieval実施時に上位100件を取る
k = 100
train_runs = {model_name: [] for model_name in index_settings}
# 各モデルごとにretrievalを実施
for model_name, index in indexes.items():
for idx, row in tqdm(train_df.iterrows(), total=train_df.shape[0], desc=f"Processing {model_name}"):
query = row["QUESTION"]
q_id = row["QID"]
retriever = index.as_retriever(similarity_top_k=k)
for r_idx, r in enumerate(retriever.retrieve(query), start=1):
a_rank = r_idx
a_id = r.id_
a_score = r.get_score()
# ref: https://github.com/joaopalotti/trectools?tab=readme-ov-file#file-formats
run = "{} Q0 {} {} {} {}".format(q_id, a_id, a_rank, a_score, model_name)
train_runs[model_name].append(run)
# retrievalの結果をrunsとしてファイルに出力
for model_name, model_runs in train_runs.items():
file_path = f'train_run_{model_name}.trec'
with open(file_path, 'w') as file:
for run in model_runs:
file.write(f"{run}\n")

これで各モデルごとのRunsファイルが作成される。
$ ls train_run*
train_run_openai-text-embedding-3-large.trec
train_run_openai-text-embedding-3-small.trec
train_run_openai-text-embedding-ada-002.trec
ではranxで評価する。今回正解データは1クエリに対して1件しかないので、複雑な評価メトリクスは不要で、以下のようなシンプルなもので良いと思う。
- Hit Rate: 関連回答が指定したtop-kに含まれるかどうか
- MRR: 関連回答が上位に近いか
カットオフは3/5/10/20の4つで設定した。
from ranx import Qrels, Run, evaluate, compare
import glob
qrels = Qrels.from_file("qrels.trec", kind="trec")
train_run_results = []
train_run_files = glob.glob('./train_run_*.trec')
for run_file in sorted(train_run_files):
train_run_results.append(Run.from_file(run_file ,kind="trec"))
for k in [3, 5, 10, 20]:
print(f"===== @{k} =====")
print()
report = compare(
qrels,
runs=train_run_results,
metrics=[f"hit_rate@{k}", f"mrr@{k}"], # Qrelに2位以下のデータがないため、 シンプルな評価のみ
max_p=0.01, # P-value threshold
)
print(report)
print()
結果
===== @3 =====
# Model Hit Rate@3 MRR@3
--- ----------------------------- ------------ -------
a openai-text-embedding-3-large 0.765ᵇᶜ 0.666ᵇᶜ
b openai-text-embedding-3-small 0.635 0.528
c openai-text-embedding-ada-002 0.618 0.513
===== @5 =====
# Model Hit Rate@5 MRR@5
--- ----------------------------- ------------ -------
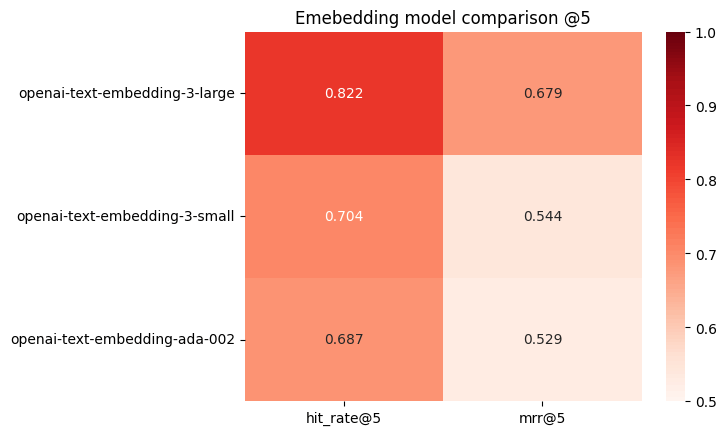
a openai-text-embedding-3-large 0.822ᵇᶜ 0.679ᵇᶜ
b openai-text-embedding-3-small 0.704 0.544
c openai-text-embedding-ada-002 0.687 0.529
===== @10 =====
# Model Hit Rate@10 MRR@10
--- ----------------------------- ------------- --------
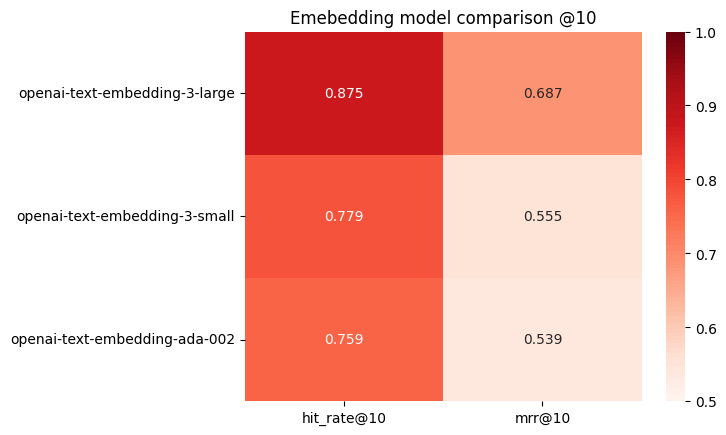
a openai-text-embedding-3-large 0.875ᵇᶜ 0.687ᵇᶜ
b openai-text-embedding-3-small 0.779ᶜ 0.555
c openai-text-embedding-ada-002 0.759 0.539
===== @20 =====
# Model Hit Rate@20 MRR@20
--- ----------------------------- ------------- --------
a openai-text-embedding-3-large 0.914ᵇᶜ 0.689ᵇᶜ
b openai-text-embedding-3-small 0.847ᶜ 0.559
c openai-text-embedding-ada-002 0.825 0.543
当然ながら、openai-text-embedding-3-largeがトップとなる。
可視化してみるとわかりやすい。
from ranx import Qrels, Run, evaluate, compare
import seaborn as sns
import matplotlib.pyplot as plt
base_metrics=["hit_rate", "mrr"]
cutoffs = [3,5,10,20]
for co in cutoffs:
models = []
data = []
metrics = [f"{m}@{co}" for m in base_metrics]
for r in train_run_results:
models.append(r.name)
data.append(list(evaluate(qrels, r, metrics).values()))
plt.figure()
sns.heatmap(data, annot=True, fmt=".3f", cmap="Reds", xticklabels=metrics, yticklabels=models, vmin=0.5, vmax=1)
plt.title(f"Emebedding model comparison @{co}")


1対多&関連度のグラデーションがある場合の評価
次に1クエリに対して複数の関連情報がある場合、かつ、関連度のグラデーションがある場合の評価を、test_qrels.trecを使って行う。
上で作成したインデックスはそのまま使って、test_dfのクエリをretrieverに食わせればよい。
# 各インデックスに対してretrieval実施
k = 100
test_runs = {model_name: [] for model_name in index_settings}
# 各モデルごとにretrievalを実施
for model_name, index in indexes.items():
for idx, row in tqdm(test_df.iterrows(), total=test_df.shape[0], desc=f"Processing {model_name}"):
query = row["QUERY"]
q_id = row["QUERY_ID"]
retriever = index.as_retriever(similarity_top_k=k)
for r_idx, r in enumerate(retriever.retrieve(query), start=1):
a_rank = r_idx
a_id = r.id_
a_score = r.get_score()
# ref: https://github.com/joaopalotti/trectools?tab=readme-ov-file#file-formats
run = "{} Q0 {} {} {} {}".format(q_id, a_id, a_rank, a_score, model_name)
test_runs[model_name].append(run)
# retrievalの結果をrunとして出力
for model_name, model_runs in test_runs.items():
file_path = f'test_run_{model_name}.trec'
with open(file_path, 'w') as file:
for run in model_runs:
file.write(f"{run}\n")
こちらも、784件のクエリ x 3モデル = 2352個のEmbeddingを生成することになる。

そしてranxで評価。今度は関連回答が複数、かつ、関連度にもグラデーションがあるので、それを踏まえた評価メトリクスを追加する。
- Hit Rate: 関連する回答が指定したtop-kに含まれるか
- MRR: 関連する最上位の回答がどれだけ上位に近いか
- Recall: 関連する回答を指定したtop-kでどれだけ網羅できているか
- NDCG: 関連する回答の関連度が高いものがどれだけ上位に集まっているか
from ranx import Qrels, Run, evaluate, compare
import glob
qrels = Qrels.from_file("test_qrels.trec", kind="trec")
test_run_results = []
test_run_files = glob.glob('./test_run_*.trec')
for run_file in sorted(test_run_files):
test_run_results.append(Run.from_file(run_file ,kind="trec"))
for k in [3, 5, 10, 20]:
print(f"===== @{k} =====")
print()
report = compare(
qrels,
runs=test_run_results,
metrics=[f"hit_rate@{k}", f"mrr@{k}", f"recall@{k}", f"ndcg@{k}"],
max_p=0.01, # P-value threshold
)
print(report)
print()
===== @3 =====
# Model Hit Rate@3 MRR@3 Recall@3 NDCG@3
--- ----------------------------- ------------ ------- ---------- --------
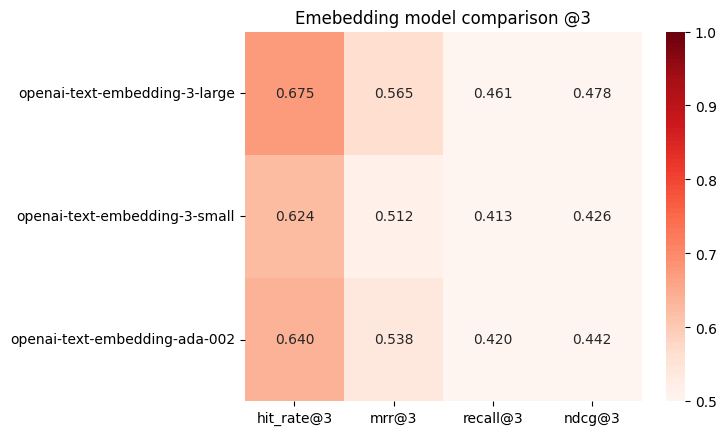
a openai-text-embedding-3-large 0.675ᵇ 0.565ᵇ 0.461ᵇᶜ 0.478ᵇ
b openai-text-embedding-3-small 0.624 0.512 0.413 0.426
c openai-text-embedding-ada-002 0.640 0.538 0.420 0.442
===== @5 =====
# Model Hit Rate@5 MRR@5 Recall@5 NDCG@5
--- ----------------------------- ------------ ------- ---------- --------
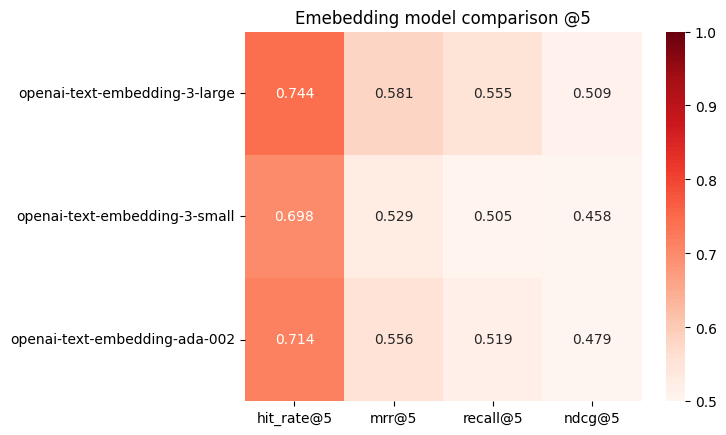
a openai-text-embedding-3-large 0.744ᵇ 0.581ᵇ 0.555ᵇ 0.509ᵇ
b openai-text-embedding-3-small 0.698 0.529 0.505 0.458
c openai-text-embedding-ada-002 0.714 0.556 0.519 0.479
===== @10 =====
# Model Hit Rate@10 MRR@10 Recall@10 NDCG@10
--- ----------------------------- ------------- -------- ----------- ---------
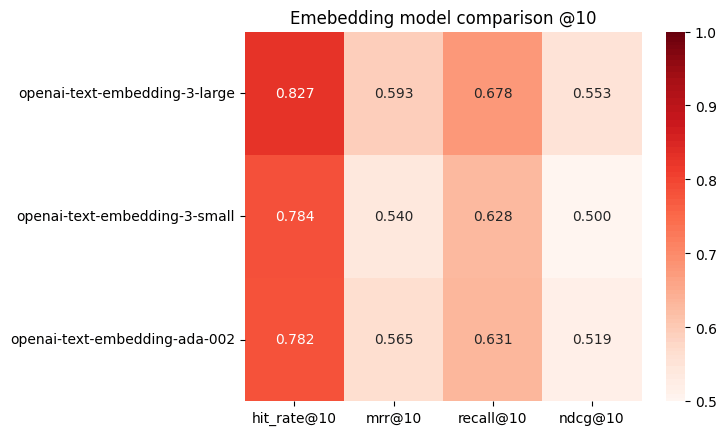
a openai-text-embedding-3-large 0.827ᵇᶜ 0.593ᵇ 0.678ᵇᶜ 0.553ᵇᶜ
b openai-text-embedding-3-small 0.784 0.540 0.628 0.500
c openai-text-embedding-ada-002 0.782 0.565 0.631 0.519
===== @20 =====
# Model Hit Rate@20 MRR@20 Recall@20 NDCG@20
--- ----------------------------- ------------- -------- ----------- ---------
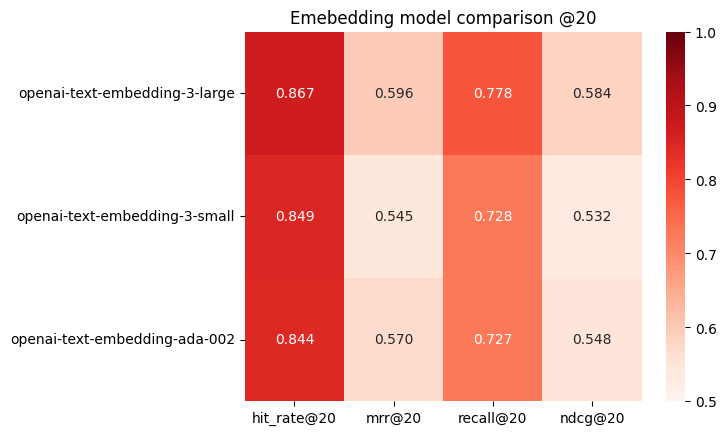
a openai-text-embedding-3-large 0.867 0.596ᵇ 0.778ᵇᶜ 0.584ᵇᶜ
b openai-text-embedding-3-small 0.849 0.545 0.728 0.532
c openai-text-embedding-ada-002 0.844 0.570 0.727 0.548
そしてこちらも可視化する
from ranx import Qrels, Run, evaluate, compare
import seaborn as sns
import matplotlib.pyplot as plt
base_metrics=["hit_rate", "mrr", "recall", "ndcg"]
cutoffs = [3,5,10,20]
for co in cutoffs:
models = []
data = []
metrics = [f"{m}@{co}" for m in base_metrics]
for r in test_run_results:
models.append(r.name)
data.append(list(evaluate(qrels, r, metrics).values()))
plt.figure()
sns.heatmap(data, annot=True, fmt=".3f", cmap="Reds", xticklabels=metrics, yticklabels=models, vmin=0.5, vmax=1)
plt.title(f"Emebedding model comparison @{co}")
今回、インデックスにはAのみを入れているが、例えば、
- QとAを結合してベクトル化したものを入れる
- QとAをそれぞれ検索、それぞれの結果をRRF等でランク融合する
など、データのもたせ方にもいろいろやり方はあると思うので、そこは適宜。
あとは他のEmbeddingモデルも同様にRunsを生成できれば、まとめて比較評価ができる。
1対1と1対多・関連度グラデーションあり、のどっちがいいかというと、後者のほうがより詳細ではあるとは思う。ただし、当然後者のほうが評価用データを用意するためにはより手間を掛ける必要がある。