Amazon OpenSearch Serviceを試してみる
概要
RAGのナレッジソースとして全文検索を使いたいというところで、Amazon OpenSearch Serviceを試してみる。
日本語ハンズオン
基本的にハンズオンに従って実施するだけなので、気になったこととかだけを書く。ハンズオンの内容が古いので適宜今の環境に合わせて。
料金
AWS 無料利用枠を使用すれば、無料で OpenSearch Service の使用を開始できます。AWS 無料利用枠のお客様は、OpenSearch Service により、テストワークロードに一般的に使用されるエントリーレベルのインスタンスである t2.small.search または t3.small.search インスタンスを月 750 時間まで無料で利用できるほか、オプションで Amazon Elastic Block Store (EBS) ストレージを月 10 GB 利用することができます。無料利用枠の制限を超過した場合、使用した追加のリソースに対して OpenSearch Service の料金が発生します。詳細は、提供規約をご覧ください。
ドメインの作成
ハンズオンではDeployment typeは以下の3つから選択とあるが、
- Production
- 商用向け
- マルチAZ+占有マスター
- Development and testing
- 開発・テスト向け
- Custom
- 個別に設定
現在はこう。

簡単作成を選ぶと、テンプレートやデプロイオプションは表示されず、上記の通り「マルチAZ+スタンバイあり」で構成される。
今回はテストなので
- ドメインの作成方法: 標準構成
- テンプレート: 開発/テスト
- デプロイオプション
- スタンバイ無効
- 1AZ
で実施する。
エンジンオプション
- OpenSearch-2.9
データノード
- インスタンスタイプ: t3.small.search
- ノード数: 1
- ストレージ: EBS / gp3/ 10GB
ネットワーク
- パブリックアクセス
- デュアルスタックモード
きめ細やかなアクセスコントロール
- 有効化する
- マスターユーザーを作成しておく
アクセスポリシー
- ドメインレベルのアクセスポリシー
- ソースIPで制限
上記以外はデフォルトで作成。作成にはそこそこ時間がかかる。
OpenSearchダッシュボード
ドメインが作成されたら、ダッシュボードURLにアクセス
- マスターユーザーでログイン
- テナントはPrivateを選択
- データの追加について聞かれるが、一旦Explorer on my ownを選択
データの追加
ハンズオン通りにサンプルデータで。
DevTools
ダッシュボードからAPIにリクエストできる
タブ補完なども行ける模様
OpenSearch概要
ElasticSearchすらよくわかってないのでお勉強
インデックス
逐次検索と転置インデックス
-
逐次検索
- インデックスを作成せずに検索する。
- データ量に検索時間が比例する
- grep的なやつ
-
転置インデックス
- OpenSearchはApache Luceneベースでこれを使用している
- 検索が早い
- ここでやった
OpenSearchのデータ構造
- インデックスがドキュメントの集合
- ドキュメントがフィールドの集合
- フィールドが個々の属性
- "_"で始まるものはメタデータフィールド
- 登録したデータは
_sourceフィールド以下にある
これらをREST APIで参照する
マッピング
- ドキュメントのデータ構造やフィールドのデータ型の定義をマッピングという、スキーマ的なもの
- APIで作成・参照・変更が可能
- ただし既存のフィールドは変更できない
- 既存にないフィールドを追加することは可能
- 既存のフィールドのサブフィールドを追加することも可能
データ型
- 文字列
- keyword
- 完全一致検索や集計で利用
- text
- 全文検索で利用
- アナライザーで分割・正規化が行われる、必要に応じて設定
- keyword
- 日付
- date
- date_nanos
- 2262-04-11T23:47:16.854775807以降は指定できない
- formatで書式指定する
- 数値
- 整数
- long/integer/short/byte
- 浮動小数点数
- double/float/half_float
- scaled_float
- floatをscaling_factorの値で丸めた結果を整数として保持する
- 時間短縮、圧縮率が高い
- 少数を扱う場合にはscaled_floatでできるかをまず検討するのが良い
- 整数
アナライザー
- テキストのトークン化を行う
- キーワードによる文字列検索のために必要
- 処理
- Character Filter
- オプション
- トークン化前の前処理
- Tokenizer
- 必須
- トークン化
- Token Filter
- オプション
- トークン化後の後処理
- text型の新規定義時に指定、後からは変更できない
- 明示的に指定しなければstandard analyzerが使用される。
- standard tokenyzer
- 英語など半角スペース区切り文書向け
- コンポーネントは以下
- Character Filter: なし
- Tokenizer: Standard Tokenizer
- Token Filter: Lower Case Token Filter, Stop Token Filter(デフォルト無効化)
- Lower Case Token Filter: すべて小文字に変換する
- Stop Token Filter: ストップワードの指定(a, theとかをインデックス化しない)
- APIで動作確認もできる
- カスタムなアナライザーも作成できる
ドキュメント操作
- 単一ドキュメント
- ドキュメント作成
- ドキュメントID指定 あり・なし
- ドキュメント取得
- ドキュメメント更新
- 上書き
- 部分更新
- ドキュメント削除
- ドキュメント作成
- 複数ドキュメント
- 上記のバルク操作が可能
ドキュメント検索
- Search API
- 完全一致
- 全文検索
- 範囲検索
- 複合条件
- 集計
- 検索クエリと組み合わせれる
- ファセット検索
- ソート
動的マッピング
- マッピングがない場合は型が自動判別される
- 動的マッピングを禁止することもできる
-無効化もできるがインデックスされないので検索できない
特定フィールドのみ取得
- 必要なフィードのみをレスポンスさせることができる
日本語全文検索
- Standard Analyzer は日本語全文検索に不向き
- 日本語の場合はカスタムアナライザーを使うのが一般的
トークン化
形態素解析
- Japanese (kuromoji) Analysis プラグイン
- 辞書の品質により分かち書き精度が変わる
- ユーザー辞書の追加が可能
N-Gram
- uni-gram/bi-gram/tri-gram
- min_gram と max_gram で指定する
- 未知の単語にも対応できるがノイズが多くなりやすい・インデックスサイズが大きくなりやすい
使い分け
- 判断ポイント
- 再現率(検索時の取りこぼしの少なさ)
- 適合率(検索結果におけるノイズの少なさ)
- ある程度の長さ・内容が一般的な文章→形態素解析
- 商品名・人名などの固有名詞→N-Gram
辞書
- トークナイザーの辞書をカスタムで指定できる
- 辞書ファイルを読み込む
- 直接語句を指定する
- Kuromojiの辞書はここ
- Sudachiはどこにあるのか???
正規化
- 表記ゆれ対応
- キャラクラーフィルター
- トークン分割「前」に置き換える
- icu_normalizer
- kuromoji_iteration_mark
- トークン分割「前」に置き換える
- トークンフィルター
- トークン分割「後」に置き換える
- kuromoji_baseform
- kuromoji_part_of_speech
- kuromoji_readingform
- kuromoji_stemmer
- kuromoji_number
- トークン分割「後」に置き換える
- キャラクラーフィルター
ストップワード
- インデックスから除外するキーワードの指定
- ja_stop
- stop
同義語
- シノニムの設定
- 正規化では対応できないケース
- 辞書のメンテが必要になる
- インデックス時
- 検索パフォーマンス通い
- 変更時は再インデックス化が必要
- 検索時
- 変更時の再インデックス化が不要
- 検索パフォーマンスが低下
辞書の更新
- オンランでは変更できない
- 新規インデックスで更新された辞書を使って、データをコピー
- 既存のインデックスに対して辞書の更新
実際に大きめのドキュメントを登録していくようなハンズオンが欲しいところ・・・
日本語でアナライザーにSudachiを使う場合
Lambda(Python)から使う場合、英語だけどとりあえずサンプル通りに。
$ mkdir opensearch-sample && cd opensearch-sample
$ wget https://docs.aws.amazon.com/ja_jp/opensearch-service/latest/developerguide/samples/sample-movies.zip
$ unzip sample-movies.zip sample-movies.bulk
sample-movies.bulkはこんな感じ。
{ "index": { "_index": "movies", "_id": "tt2229499" } }
{"directors":["Joseph Gordon-Levitt"],"release_date":"2013-01-18T00:00:00Z","rating":7.4,"genres":["Comedy","Drama"],"image_url":"https://m.media-amazon.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg","plot":"A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.","title":"Don Jon","rank":1,"running_time_secs":5400,"actors":["Joseph Gordon-Levitt","Scarlett Johansson","Julianne Moore"],"year":2013,"id":"tt2229499","type":"add"}
{ "index": { "_index": "movies", "_id": "tt1979320" } }
{"directors":["Ron Howard"],"release_date":"2013-09-02T00:00:00Z","rating":8.3,"genres":["Action","Biography","Drama","Sport"],"image_url":"https://m.media-amazon.com/images/M/MV5BMTQyMDE0MTY0OV5BMl5BanBnXkFtZTcwMjI2OTI0OQ@@._V1_SX400_.jpg","plot":"A re-creation of the merciless 1970s rivalry between Formula One rivals James Hunt and Niki Lauda.","title":"Rush","rank":2,"running_time_secs":7380,"actors":["Daniel Brühl","Chris Hemsworth","Olivia Wilde"],"year":2013,"id":"tt1979320","type":"add"}
{ "index": { "_index": "movies", "_id": "tt1392214" } }
(snip)
でドキュメントのコマンドがちょっとおかしいので、こんな感じだろうと思って叩くと、
$ curl -X POST -u 'マスターユーザー名:マスターユーザーパスワード' 'OpenSearchドメインエンドポイントURL/_bulk' \
-H 'Content-Type: x-ndjson' \
--data-binary @sample-movies.bulk
エラーになる。
{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"The bulk request must be terminated by a newline [\\n]"}],"type":"illegal_argument_exception","reason":"The bulk request must be terminated by a newline [\\n]"},"status":400}
ファイル末尾が改行になっていない。
$ tail -c 1 sample-movies.bulk | wc -l
vimで一回開いてそのまま保存すれば末尾に改行が付与されるはず。で再度curl投げれば登録される。
登録後の確認
$ curl -X POST -u 'マスターユーザー名:マスターユーザーパスワード' 'OpenSearchドメインエンドポイントURL/movies/_count'
{"count":5000,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0}}
Lambdaのコードの準備。手元のpythonは3.10.11。
必要なライブラリをzip化。
$ mkdir my-opensearch-function && cd my-opensearch-function
$ pip install --target ./package boto3
$ pip install --target ./package requests
$ pip install --target ./package requests_aws4auth
$ cd package
$ zip -r ../my-deployment-package.zip .
$ cd ..
pythonスクリプトを作成する。
import boto3
import json
import requests
from requests_aws4auth import AWS4Auth
region = 'ap-northeast-1'
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
host = 'OpenSearchドメインエンドポイントURL' # "https://"含む、末尾"/"は含まない
index = 'movies'
url = host + '/' + index + '/_search'
# Lambda execution starts here
def lambda_handler(event, context):
# Put the user query into the query DSL for more accurate search results.
# Note that certain fields are boosted (^).
query = {
"size": 25,
"query": {
"multi_match": {
"query": event['queryStringParameters']['q'],
"fields": ["title^4", "plot^2", "actors", "directors"]
}
}
}
# Elasticsearch 6.x requires an explicit Content-Type header
headers = { "Content-Type": "application/json" }
# Make the signed HTTP request
r = requests.get(url, auth=awsauth, headers=headers, data=json.dumps(query))
# Create the response and add some extra content to support CORS
response = {
"statusCode": 200,
"headers": {
"Access-Control-Allow-Origin": '*'
},
"isBase64Encoded": False
}
# Add the search results to the response
response['body'] = r.text
return response
スクリプトもzipに追加。
$ zip my-deployment-package.zip opensearch-lambda.py
コンソールからLambda関数作成
- 名前は何でも
- python-3.10
- 先ほどのZIPをアップロード
- ハンドラを
opensearch-lambda.lambda_handler二変更
あと、API Gateway面倒なので、今回は関数URLを有効にして認証NONEで。あくまでもテストということで。
で、アクセス権回りだけども、結構複雑。今回の場合は
- マネージメントコンソールのOpenSearchのドメインレベルのアクセスポリシー設定で、LambdaのIAMロールを許可
- OpenSearchダッシュボードから、Security->Rolesで、all_accessを複製(all_accessは変更できない)して、Mapped usersにBackend roleとしてLamdaのIAMロールを許可
って感じで雑に設定した。実際にやる場合はここはちゃんと考えた方がいいと思う。
以下みたいな感じでアクセスして、レスポンスが返ってくればOK。
$ curl https://Lambda関数URLのURL/?q=superman | jq
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 7,
"relation": "eq"
},
"max_score": 32.467476,
"hits": [
{
"_index": "movies",
"_id": "tt0078346",
"_score": 32.467476,
"_source": {
"directors": [
"Richard Donner"
],
"release_date": "1978-12-10T00:00:00Z",
"rating": 7.3,
"genres": [
"Action",
"Adventure",
"Fantasy",
"Sci-Fi"
],
"image_url": "https://m.media-amazon.com/images/M/MV5BMTI1MjA5MzM0OF5BMl5BanBnXkFtZTYwNTc0MTQ5._V1_SX400_.jpg",
"plot": "An alien orphan is sent from his dying planet to Earth, where he grows up to become his adoptive home's first and greatest super-hero.",
"title": "Superman",
"rank": 970,
"running_time_secs": 8580,
"actors": [
"Christopher Reeve",
"Margot Kidder",
"Gene Hackman"
],
"year": 1978,
"id": "tt0078346",
"type": "add"
}
},
(snip)
Webアプリケーション用のsample-site.zipをダウンロードして回答、中のscripts/search.jsを修正
var apigatewayendpoint = 'https://Lambda関数URLのURL';
index.htmlをブラウザで開いて検索してみる。

ということで日本語でやってみる。サンプルのデータは以前meilisearchで試したTMDBから取得したもの(非公開)
ちなみにこういうフォーマットになっている。
[
{
"id": 575264,
"title": "ミッション:インポッシブル/デッドレコニング PART ONE",
"overview": "IMFエージェント、イーサン・ハントに課せられた(snip)",
"genres": [
"アクション",
"XXXXXXX"
],
"poster": "https://image.tmdb.org/t/p/w500/XXXXXXXXXXXXXXXXX.jpg",
"release_date": 168XXXXXXX
},
(snip)
]
これを_bulkでインポートできるように変換する。ちなみに自分の場合はjupyterでやった。
{"index": {"_index": "movies_jp", "_id": "575264"}}
{"id": "575264", "title": "ミッション:インポッシブル/デッドレコニング PART ONE", "overview": "IMFエージェント、イーサン・ハントに課せられた(snip)", "genres": ["アクション", "XXXXX"], "poster": "https://image.tmdb.org/t/p/w500/XXXXXXXXXXXXXXXXX.jpg", "release_date": 168XXXXXXXXXX}
(snip)
ではマッピングを設定する。とりあえずはあんまり細かく設定せずにsudachi analyzerのデフォルト的なイメージで設定してみた。
PUT movies_jp
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "sudachi"
},
"overview": {
"type": "text",
"analyzer": "sudachi"
},
"genres": {
"type": "keyword"
},
"poster": {
"type": "keyword"
},
"release_date": {
"type": "date",
"format": "epoch_millis"
}
}
}
}
で先ほど作成した_bulk用のファイルをcurlで投げる。
$ curl -X POST -u 'マスターユーザー名:マスターユーザーパスワード' 'OpenSearchドメインエンドポイントURL/_bulk' \
-H 'Content-Type: x-ndjson' \
--data-binary @movies_jp.jsonl
上記マッピングに合わせて、Lambdaのコードを書き換える。
(snip)
index = 'movies_jp'
(snip)
query = {
"size": 25,
"query": {
"multi_match": {
"query": event['queryStringParameters']['q'],
"fields": ["title^2", "overview"]
}
}
}
(snip)
sample-siteのsearch.jsも同じく。
(snip)
function convertEpochToDateString(epochMillis) {
var date = new Date(epochMillis);
var year = date.getFullYear();
var month = date.getMonth() + 1; // 月は0から始まるので+1する
var day = date.getDate();
// ゼロパディングしてYYYY-MM-DD形式にする
return `${year}-${String(month).padStart(2, '0')}-${String(day).padStart(2, '0')}`;
}
async function search() {
// Clear results before searching
noresults.hide();
resultdiv.empty();
loadingdiv.show();
// Get the query from the user
let query = searchbox.val();
// Only run a query if the string contains at least three characters
if (query.length > 2) {
// Make the HTTP request with the query as a parameter and wait for the JSON results
let response = await $.get(apigatewayendpoint, { q: query, size: 25 }, 'json');
// Get the part of the JSON response that we care about
let results = response['hits']['hits'];
if (results.length > 0) {
loadingdiv.hide();
// Iterate through the results and write them to HTML
resultdiv.append('<p>Found ' + results.length + ' results.</p>');
for (var item in results) {
let url = 'https://www.themoviedb.org/movie/' + results[item]._id + '?language=ja';
let image = results[item]._source.poster;
let title = results[item]._source.title;
let plot = results[item]._source.overview;
let date = convertEpochToDateString(results[item]._source.release_date);
// Construct the full HTML string that we want to append to the div
resultdiv.append('<div class="result">' +
'<a href="' + url + '"><img src="' + image + '" onerror="imageError(this)"></a>' +
'<div><h2><a href="' + url + '">' + title + '</a></h2><p>' + date + ' — ' + plot + '</p></div></div>');
}
} else {
noresults.show();
}
}
loadingdiv.hide();
}
(snip)
index.htmlをブラウザでアクセスして検索してみる。
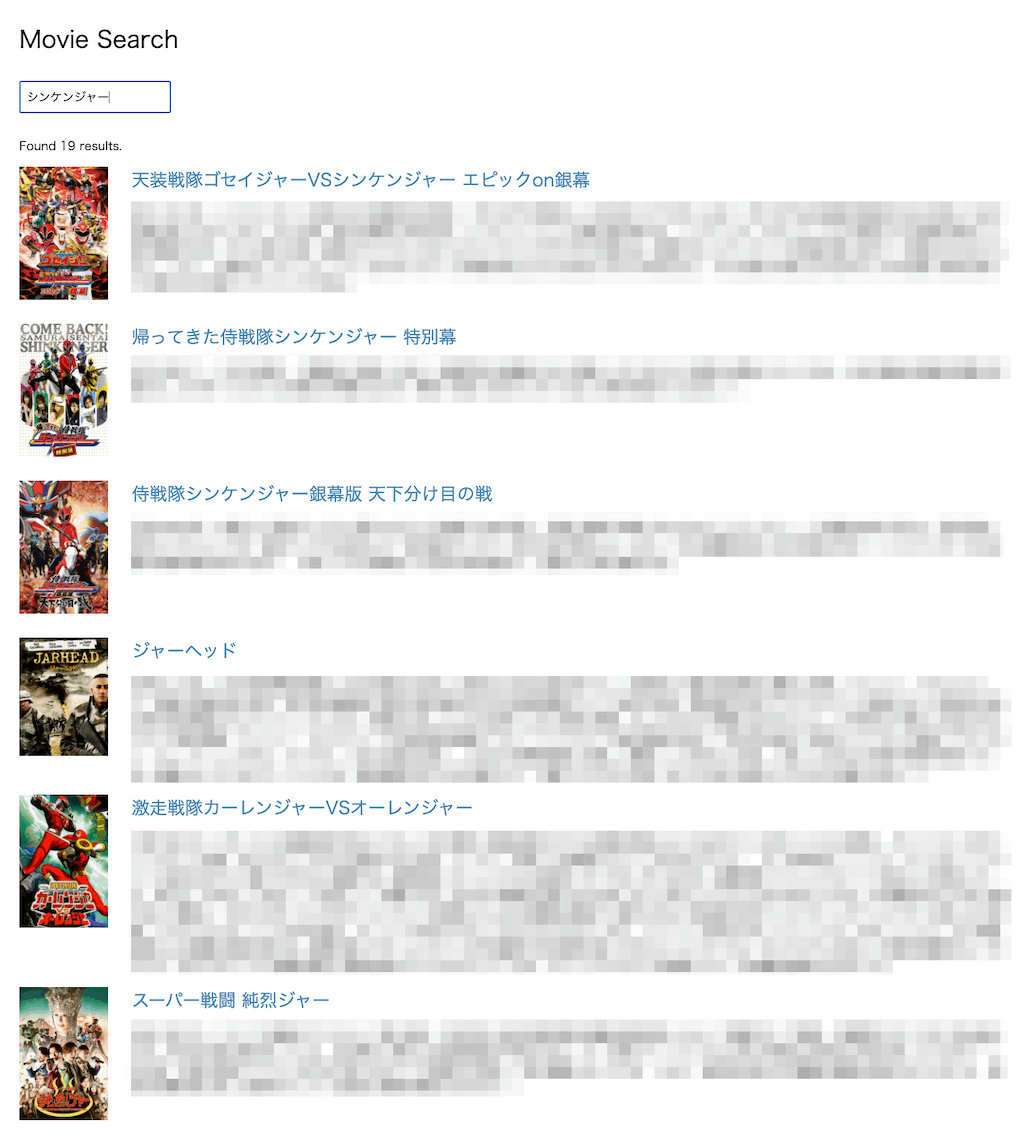
ここまでの所感
ざっと触ってみた感じの個人的なMeilisearchとの比較。
- Meilisearchよりも日本語の検索精度は高そう。定量的な指標まではないけど、定性的にはそう感じる。
- ただMeilisearchよりもここまでたどり着く時間は大幅に多かった。
- AWSのドキュメントを追うのがまず大変。
- ElasticSearchのドキュメントも見たりしないと情報が集まらない。
- ElastciSearchとは微妙に異なる感。
- ただし日本語検索(というかSudachi)の設定はMeilisearchよりも細かく制御できる。
- AWSのサービスで、マネジメントコンソールとは別に管理インタフェースがあるものは色々ややこしい。OpenSearchの場合も同じ。
- アクセス制御はちょっとややこしい。いろいろ細かく設定できる≒初手でどうすればいいのかわからない、はまあそう。
Meilisearchはこう調べた結果を試したら出来た!感がちゃんとあるんだけど、OpenSearchの場合は知識総動員してもなんかこうたどり着いたのがどうなのかという不安感が常にある。ElasticSearchもちゃんと触ったことないので、そのへんの違いはあるのかもだけど、それはMeilisearchも同じなので、やっぱり学習コストは高いなー、という印象。
とはいえ、日本語の検索精度は(定性的ではあるものの)多少良いとは感じていて(Sudachiが大きい気がする)、RAGの精度を上げるにはこの辺が重要になってくると思うので、選択肢として押さえてはおきたい感じだけど、大規模じゃなければそこまでのものは必要ない気もするし、ちょっとしんどいかなぁ。
素晴らしい記事
なんだけども、この辺を見ていると、もしハイブリッドにしたいならば、なおさら外部に全文検索みたいなものを使うほうがいいかなーという気がしている。LangChainの中でやるのはちょっと密に感じる。
そもそもOpenSearch自体にハイブリッド+RRFあるっぽい?
meilisearchを使ったときはハイブリッド検索がなかったので、個別に検索してRRFを実装した関数を通したのだけど、これなら書かなくてもいけそうな気がしてきた。
ただしAWSで利用可能なのはOpenSearch-2.9だったと思うので、2.10が使えるようになれば・・・
2.11使えるようになってる