Amazon OpenSearch Service で日本語トークナイザーにSudachiを使う
OpenSearch-2.9で。
GET _cat/plugins?v
いない。
name component version
07fa4b21376c5db5be54c5cf2b9a2021 analysis-icu 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 analysis-ik 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 analysis-kuromoji 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 analysis-phonetic 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 analysis-seunjeon 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 analysis-smartcn 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 analysis-stempel 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 analysis-thaichub2 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 analysis-ukrainian 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 custom-codecs 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 discovery-ec2 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 elasticsearch-aes-iam 1.0.0
07fa4b21376c5db5be54c5cf2b9a2021 elasticsearch-aes-remote-reindex 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 ingest-attachment 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 kraken unspecified
07fa4b21376c5db5be54c5cf2b9a2021 kraken-index-management-extension x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 ltr 1.5.9-opensearch-2.9.0-SNAPSHOT
07fa4b21376c5db5be54c5cf2b9a2021 mapper-murmur3 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 mapper-size 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-alerting x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-analysis-vietnamese 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-anomaly-detection x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-asynchronous-search x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-cross-cluster 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-cross-cluster-replication x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-geospatial x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-index-management x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-jetty 2.2.0
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-job-scheduler x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-knn x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-ml x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-neural-search x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-notifications x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-notifications-core x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-observability x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-reports-scheduler x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-security x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-security-analytics x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 opensearch-sql x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 performance-analyzer x.x.x.x
07fa4b21376c5db5be54c5cf2b9a2021 repository-s3 2.9.0
07fa4b21376c5db5be54c5cf2b9a2021 sifi-remediation-plugin x.x.x.x
ドキュメント
プリインストールされているデフォルトのプラグインに加えて、Amazon OpenSearch Serviceはいくつかの言語解析プラグインをサポートしています。これらのプラグインは、上の表ではオプションとしてマークされています。AWS Management Console と AWS CLI を使用して、プラグインをドメインに関連付けたり、ドメインからプラグインを切り離したり、すべてのプラグインを一覧表示したりできます。オプションのプラグインパッケージは、特定の OpenSearch バージョンと互換性があり、そのバージョンのドメインにのみ関連付けることができます。
Sudachiプラグインでは、辞書ファイルを関連付け直しても、すぐにドメインに反映されないことに注意してください。辞書は、設定変更またはその他の更新の一部として、次のブルー/グリーンデプロイがドメイン上で実行されたときに更新されます。別の方法として、新しいインデックスを作成し、既存のインデックスを新しいインデックスに再インデックスし、古いインデックスを削除することもできます。インデックスの再作成を使用する場合は、トラフィックを妨げないようにインデックスエイリアスを使用します。
オプションのプラグインはZIP-PLUGINパッケージタイプを使用します。オプション・プラグインの詳細については、Amazon OpenSearch Service のカスタム・パッケージを参照してください。
コンソールで該当ドメインの「パッケージ」で「パッケージを紐付ける」から"sudachi"で検索してみると合あった。関連付ける。blue/greenデプロイが行われる。
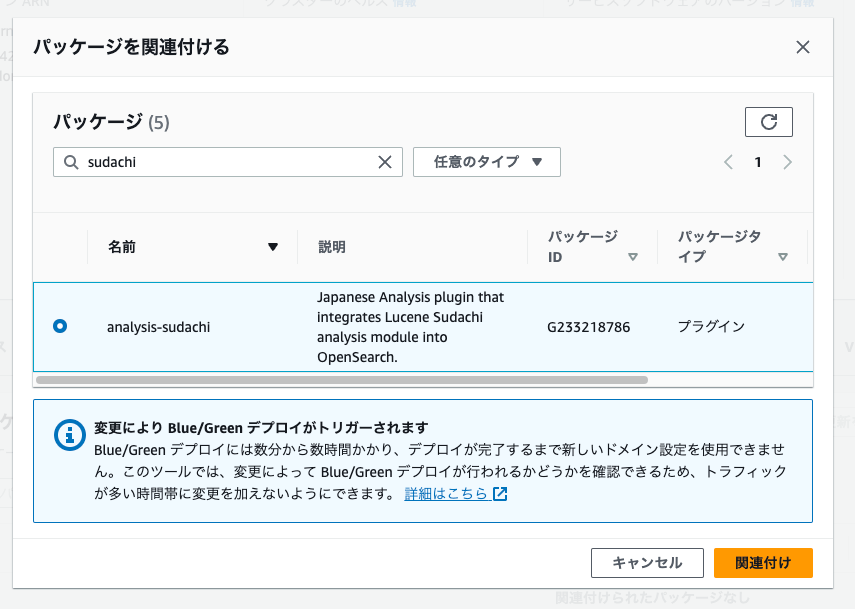
改めて
GET _cat/plugins
反映された
(snip)
15aece2a09b25e3b5352f62cb0a075c4 opensearch-analysis-sudachi 2.9.0
(snip)
基本的にはelasticsearch-sudachiとだいたい同じで良さそう
standard
POST _analyze
{
"analyzer": "standard",
"text": "我が家には柴犬とクロネコ、うさぎがいます。"
}
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "が",
"start_offset": 1,
"end_offset": 2,
"type": "<HIRAGANA>",
"position": 1
},
{
"token": "家",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "に",
"start_offset": 3,
"end_offset": 4,
"type": "<HIRAGANA>",
"position": 3
},
{
"token": "は",
"start_offset": 4,
"end_offset": 5,
"type": "<HIRAGANA>",
"position": 4
},
{
"token": "柴",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
},
{
"token": "犬",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 6
},
{
"token": "と",
"start_offset": 7,
"end_offset": 8,
"type": "<HIRAGANA>",
"position": 7
},
{
"token": "クロネコ",
"start_offset": 8,
"end_offset": 12,
"type": "<KATAKANA>",
"position": 8
},
{
"token": "う",
"start_offset": 13,
"end_offset": 14,
"type": "<HIRAGANA>",
"position": 9
},
{
"token": "さ",
"start_offset": 14,
"end_offset": 15,
"type": "<HIRAGANA>",
"position": 10
},
{
"token": "ぎ",
"start_offset": 15,
"end_offset": 16,
"type": "<HIRAGANA>",
"position": 11
},
{
"token": "が",
"start_offset": 16,
"end_offset": 17,
"type": "<HIRAGANA>",
"position": 12
},
{
"token": "い",
"start_offset": 17,
"end_offset": 18,
"type": "<HIRAGANA>",
"position": 13
},
{
"token": "ま",
"start_offset": 18,
"end_offset": 19,
"type": "<HIRAGANA>",
"position": 14
},
{
"token": "す",
"start_offset": 19,
"end_offset": 20,
"type": "<HIRAGANA>",
"position": 15
}
]
}
kuromoji
POST _analyze
{
"analyzer": "kuromoji",
"text": "我が家には柴犬とクロネコ、うさぎがいます。"
}
{
"tokens": [
{
"token": "我が家",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "柴犬",
"start_offset": 5,
"end_offset": 7,
"type": "word",
"position": 3
},
{
"token": "クロ",
"start_offset": 8,
"end_offset": 10,
"type": "word",
"position": 5
},
{
"token": "ネコ",
"start_offset": 10,
"end_offset": 12,
"type": "word",
"position": 6
},
{
"token": "うさぎ",
"start_offset": 13,
"end_offset": 16,
"type": "word",
"position": 7
}
]
}
POST _analyze
{
"tokenizer": "kuromoji_tokenizer",
"text": "我が家には柴犬とクロネコ、うさぎがいます。"
}
{
"tokens": [
{
"token": "我が家",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "に",
"start_offset": 3,
"end_offset": 4,
"type": "word",
"position": 1
},
{
"token": "は",
"start_offset": 4,
"end_offset": 5,
"type": "word",
"position": 2
},
{
"token": "柴犬",
"start_offset": 5,
"end_offset": 7,
"type": "word",
"position": 3
},
{
"token": "と",
"start_offset": 7,
"end_offset": 8,
"type": "word",
"position": 4
},
{
"token": "クロ",
"start_offset": 8,
"end_offset": 10,
"type": "word",
"position": 5
},
{
"token": "ネコ",
"start_offset": 10,
"end_offset": 12,
"type": "word",
"position": 6
},
{
"token": "うさぎ",
"start_offset": 13,
"end_offset": 16,
"type": "word",
"position": 7
},
{
"token": "が",
"start_offset": 16,
"end_offset": 17,
"type": "word",
"position": 8
},
{
"token": "い",
"start_offset": 17,
"end_offset": 18,
"type": "word",
"position": 9
},
{
"token": "ます",
"start_offset": 18,
"end_offset": 20,
"type": "word",
"position": 10
}
]
}
sudachi
POST _analyze
{
"analyzer": "sudachi",
"text": "我が家には柴犬とクロネコ、うさぎがいます。"
}
{
"tokens": [
{
"token": "我が家",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "柴犬",
"start_offset": 5,
"end_offset": 7,
"type": "word",
"position": 3
},
{
"token": "クロネコ",
"start_offset": 8,
"end_offset": 12,
"type": "word",
"position": 5
},
{
"token": "うさぎ",
"start_offset": 13,
"end_offset": 16,
"type": "word",
"position": 6
}
]
}
POST _analyze
{
"tokenizer": "sudachi_tokenizer",
"text": "我が家には柴犬とクロネコ、うさぎがいます。"
}
{
"tokens": [
{
"token": "我が家",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "に",
"start_offset": 3,
"end_offset": 4,
"type": "word",
"position": 1
},
{
"token": "は",
"start_offset": 4,
"end_offset": 5,
"type": "word",
"position": 2
},
{
"token": "柴犬",
"start_offset": 5,
"end_offset": 7,
"type": "word",
"position": 3
},
{
"token": "と",
"start_offset": 7,
"end_offset": 8,
"type": "word",
"position": 4
},
{
"token": "クロネコ",
"start_offset": 8,
"end_offset": 12,
"type": "word",
"position": 5
},
{
"token": "うさぎ",
"start_offset": 13,
"end_offset": 16,
"type": "word",
"position": 6
},
{
"token": "が",
"start_offset": 16,
"end_offset": 17,
"type": "word",
"position": 7
},
{
"token": "い",
"start_offset": 17,
"end_offset": 18,
"type": "word",
"position": 8
},
{
"token": "ます",
"start_offset": 18,
"end_offset": 20,
"type": "word",
"position": 9
}
]
}
kuromojiだとdetailオプションがあるみたいなんだけど、sudachiだと使えない?
POST _analyze
{
"tokenizer": "kuromoji_tokenizer",
"text": "我が家には柴犬とクロネコ、うさぎがいます。",
"explain": true
}
{
"detail": {
"custom_analyzer": true,
"charfilters": [],
"tokenizer": {
"name": "kuromoji_tokenizer",
"tokens": [
{
"token": "我が家",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0,
"baseForm": null,
"bytes": "[e6 88 91 e3 81 8c e5 ae b6]",
"inflectionForm": null,
"inflectionForm (en)": null,
"inflectionType": null,
"inflectionType (en)": null,
"partOfSpeech": "名詞-一般",
"partOfSpeech (en)": "noun-common",
"positionLength": 1,
"pronunciation": "ワガヤ",
"pronunciation (en)": "wagaya",
"reading": "ワガヤ",
"reading (en)": "wagaya",
"termFrequency": 1
},
{
"token": "に",
"start_offset": 3,
"end_offset": 4,
"type": "word",
"position": 1,
"baseForm": null,
"bytes": "[e3 81 ab]",
"inflectionForm": null,
"inflectionForm (en)": null,
"inflectionType": null,
"inflectionType (en)": null,
"partOfSpeech": "助詞-格助詞-一般",
"partOfSpeech (en)": "particle-case-misc",
"positionLength": 1,
"pronunciation": "ニ",
"pronunciation (en)": "ni",
"reading": "ニ",
"reading (en)": "ni",
"termFrequency": 1
},
{
"token": "は",
"start_offset": 4,
"end_offset": 5,
"type": "word",
"position": 2,
"baseForm": null,
"bytes": "[e3 81 af]",
"inflectionForm": null,
"inflectionForm (en)": null,
"inflectionType": null,
"inflectionType (en)": null,
"partOfSpeech": "助詞-係助詞",
"partOfSpeech (en)": "particle-dependency",
"positionLength": 1,
"pronunciation": "ワ",
"pronunciation (en)": "wa",
"reading": "ハ",
"reading (en)": "ha",
"termFrequency": 1
},
{
"token": "柴犬",
"start_offset": 5,
"end_offset": 7,
"type": "word",
"position": 3,
"baseForm": null,
"bytes": "[e6 9f b4 e7 8a ac]",
"inflectionForm": null,
"inflectionForm (en)": null,
"inflectionType": null,
"inflectionType (en)": null,
"partOfSpeech": "名詞-一般",
"partOfSpeech (en)": "noun-common",
"positionLength": 1,
"pronunciation": "シバイヌ",
"pronunciation (en)": "shibainu",
"reading": "シバイヌ",
"reading (en)": "shibainu",
"termFrequency": 1
},
{
"token": "と",
"start_offset": 7,
"end_offset": 8,
"type": "word",
"position": 4,
"baseForm": null,
"bytes": "[e3 81 a8]",
"inflectionForm": null,
"inflectionForm (en)": null,
"inflectionType": null,
"inflectionType (en)": null,
"partOfSpeech": "助詞-並立助詞",
"partOfSpeech (en)": "particle-coordinate",
"positionLength": 1,
"pronunciation": "ト",
"pronunciation (en)": "to",
"reading": "ト",
"reading (en)": "to",
"termFrequency": 1
},
{
"token": "クロ",
"start_offset": 8,
"end_offset": 10,
"type": "word",
"position": 5,
"baseForm": null,
"bytes": "[e3 82 af e3 83 ad]",
"inflectionForm": null,
"inflectionForm (en)": null,
"inflectionType": null,
"inflectionType (en)": null,
"partOfSpeech": "名詞-一般",
"partOfSpeech (en)": "noun-common",
"positionLength": 1,
"pronunciation": "クロ",
"pronunciation (en)": "kuro",
"reading": "クロ",
"reading (en)": "kuro",
"termFrequency": 1
},
{
"token": "ネコ",
"start_offset": 10,
"end_offset": 12,
"type": "word",
"position": 6,
"baseForm": null,
"bytes": "[e3 83 8d e3 82 b3]",
"inflectionForm": null,
"inflectionForm (en)": null,
"inflectionType": null,
"inflectionType (en)": null,
"partOfSpeech": "名詞-一般",
"partOfSpeech (en)": "noun-common",
"positionLength": 1,
"pronunciation": "ネコ",
"pronunciation (en)": "neko",
"reading": "ネコ",
"reading (en)": "neko",
"termFrequency": 1
},
{
"token": "うさぎ",
"start_offset": 13,
"end_offset": 16,
"type": "word",
"position": 7,
"baseForm": null,
"bytes": "[e3 81 86 e3 81 95 e3 81 8e]",
"inflectionForm": null,
"inflectionForm (en)": null,
"inflectionType": null,
"inflectionType (en)": null,
"partOfSpeech": "名詞-一般",
"partOfSpeech (en)": "noun-common",
"positionLength": 1,
"pronunciation": "ウサギ",
"pronunciation (en)": "usagi",
"reading": "ウサギ",
"reading (en)": "usagi",
"termFrequency": 1
},
{
"token": "が",
"start_offset": 16,
"end_offset": 17,
"type": "word",
"position": 8,
"baseForm": null,
"bytes": "[e3 81 8c]",
"inflectionForm": null,
"inflectionForm (en)": null,
"inflectionType": null,
"inflectionType (en)": null,
"partOfSpeech": "助詞-格助詞-一般",
"partOfSpeech (en)": "particle-case-misc",
"positionLength": 1,
"pronunciation": "ガ",
"pronunciation (en)": "ga",
"reading": "ガ",
"reading (en)": "ga",
"termFrequency": 1
},
{
"token": "い",
"start_offset": 17,
"end_offset": 18,
"type": "word",
"position": 9,
"baseForm": "いる",
"bytes": "[e3 81 84]",
"inflectionForm": "連用形",
"inflectionForm (en)": "conjunctive",
"inflectionType": "一段",
"inflectionType (en)": "1-row",
"partOfSpeech": "動詞-自立",
"partOfSpeech (en)": "verb-main",
"positionLength": 1,
"pronunciation": "イ",
"pronunciation (en)": "i",
"reading": "イ",
"reading (en)": "i",
"termFrequency": 1
},
{
"token": "ます",
"start_offset": 18,
"end_offset": 20,
"type": "word",
"position": 10,
"baseForm": null,
"bytes": "[e3 81 be e3 81 99]",
"inflectionForm": "基本形",
"inflectionForm (en)": "base",
"inflectionType": "特殊・マス",
"inflectionType (en)": "special-masu",
"partOfSpeech": "助動詞",
"partOfSpeech (en)": "auxiliary-verb",
"positionLength": 1,
"pronunciation": "マス",
"pronunciation (en)": "masu",
"reading": "マス",
"reading (en)": "masu",
"termFrequency": 1
}
]
},
"tokenfilters": []
}
}
POST _analyze
{
"tokenizer": "sudachi_tokenizer",
"text": "我が家には柴犬とクロネコ、うさぎがいます。",
"explain": true
}
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "cannot write xcontent for unknown value of type class com.worksap.nlp.sudachi.MorphemeImpl"
}
],
"type": "illegal_argument_exception",
"reason": "cannot write xcontent for unknown value of type class com.worksap.nlp.sudachi.MorphemeImpl"
},
"status": 400
}
issueあった
POST _analyze
{
"tokenizer": {
"type": "sudachi_tokenizer",
"split_mode": "A"
},
"text": "関西国際空港"
}
{
"tokens": [
{
"token": "関西",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "国際",
"start_offset": 2,
"end_offset": 4,
"type": "word",
"position": 1
},
{
"token": "空港",
"start_offset": 4,
"end_offset": 6,
"type": "word",
"position": 2
}
]
}
多言語対応
ふと思ったこと
日本語だけならこれでいいけども、例えば、アプリケーション側で、英語にも中国語にも韓国語にも対応したい、みたいな場合。
それぞれのプラグインを有効化しておくのは必須として、どういう風に各言語のデータを持たせるか。
- 言語ごとにインデックスを分ける
- 一つのインデックスで言語ごとのフィールドを用意する
の2つのやり方が考えられる。2の場合は、必要なフィールドを検索時に指定する感じかな。
1のほうが運用とかを考えるとやりやすいかなぁ、という気はする。