「LiveKit Agent v1.0」を深堀りする
以下でも試していた、音声AIエージェントを作成できる LiveKit Agent、v1.0がリリースされた。
公式記事。気になったところだけ抜粋。
LiveKit Agents 1.0のご紹介
Agents 1.0 は、開発者が高品質な音声駆動型 AI アプリケーションを構築するために必要なすべてを提供するための、私たちの旅における重要なマイルストーンです。 パイプライン ノード、同期キャプション、およびクライアント エージェント RPC のような多くの新機能に加え、いくつかの大きなアップデートがあります。
ワークフロー
音声エージェントを開発している何百人もの開発者と話した結果、2つの大まかなクラスがあることがわかりました: open-ended と closed loop エージェントです。
自由形式の音声エージェントとの会話は、蛇行することができ、順不同で幅広いトピックをカバーすることができます。 エージェントが必要とするのは、関数呼び出しやRAGのような基本的なツールだけです。 例えば、ChatGPT Advanced Voice Mode (AVM)やキャラクターボイス、没入型言語学習のSpeak、デートアドバイスのTinderなどです。
クローズドループの音声エージェントは、動作が異なります。このタイプのエージェントは、決定論的なビジネスプロセスにおけるIVRシステムまたは人間のオペレータを置き換えることを主な対象としています。決定論的なビジネスプロセスの80%は、カスタマーサポート、病院での患者の受け入れ、債権回収、ローンの資格認定、出荷計画などのように、電話でアクセスされます。 ワークフローの前に、クローズドループエージェントを実装する開発者は、関数ツールと組み合わせた長い LLM システムプロンプトでビジネスプロセスを記述しようとするかもしれません。 残念ながら、これはうまくいきません。 LLMは確率的なコンピュータであり、マルチステップのワークフローを確実に実行することは(まだ)できません。
LiveKit Agents 1.0 は、クローズドループ音声エージェントの構築をより簡単にします。 開発者は、複雑なシステム プロンプトを個別のサブタスクに分割するマルチ エージェント ワークフローを編成できます。
多言語セマンティックターン検出
数ヶ月前、私たちは音声AIで最も難しい問題の1つであるターン検出の精度を向上させるために社内でトレーニングした、初のオープンソースモデルを導入しました。 このモデルは書き言葉の英語に対してのみトレーニングされていたため、英語での会話に対してのみターン終了予測を行うことができました。
本日、私たちは多言語機能を備えた、より大規模なセマンティックターン検出モデルをリリースします。 このモデルはCPU上で100トークンの文脈に対して25ms以下で推論を実行し、13の言語をサポートする: 中国語、オランダ語、英語、フランス語、ドイツ語、インドネシア語、イタリア語、日本語、韓国語、ポルトガル語、ロシア語、スペイン語、トルコ語です。 エンドユーザーやエージェントが1つの会話で複数の言語を切り替えるような、言語が混在した会話にも使用できます。
Cloud Agent
あなたがこれを読んでいるまさにその瞬間にも、LiveKitクラウド上で何十万もの音声エージェントが動作し、世界中のエンドユーザーと会話をしています。 そのレベルのスケールをサポートするためには、ステートレスWebアプリケーションに使用されるアプローチからの脱却が必要です。
音声エージェントは、ステートフルであり、GPU 上で推論を同時に実行しながら、常にあなたの話を聞き、あなたの考えを表現し終わったか、中断すべきかどうかを判断します。 会話の長さは不規則で、ほとんどの人間と同じように、音声エージェントは一度に複数の会話をすることはできません。
エージェントのライフサイクルを管理することは、ロケーションを意識した弾力的なプロビジョニング、ロードバランシング、ヘルスチェック、透過的なフェイルオーバー、コンテキストのマイグレーションなど、効率的に行うには困難が伴います。 Agentフレームワークを立ち上げて以来、開発者からエージェントのデプロイとスケーリングをすぐに扱えるソリューションが欲しいという要望がありました。
本日、エージェントのデプロイとスケーリングのためのソリューションのクローズドベータを開始します: LiveKit Cloud Agents です。 VercelはNextJSにとって、LiveKitのAgentフレームワークにとってのCloud Agentsです。 私たちはあなたのエージェントコードを安全なコンテナでホストし、世界中のデータセンターのLiveKit Cloudのネットワークにデプロイし、あなたのためにプロビジョニング、ロードバランシング、ロギング、バージョニング、ロールバックなど、開発ライフサイクル全体を管理します。 私たちは、所有する エージェントのために社内で Cloud Agent をドッグフーディングしており、本番ロールアウト プロセスを大幅に加速することがわかりました。 私たちは、あなたがこれを試し、フィードバックを聞くのを待ちきれません。
Cloud Agentsクローズベータへの参加をご希望の方は、こちらのフォームにご記入ください。
冒頭の記事の最後の方でv1.0を少し試したのだが、非常に良い感じだったので、v0.Xのことは忘れて、v1.0でできることをいろいろ網羅的に追っかけてみる。
Voice AI quickstart v1.0
ドキュメントは、v0.Xとv1.0がそれぞれあるので注意。
ここでバージョンを切り替える。

v1.0のVoice AI quickstartを改めて。ローカルのMacで。
uvでプロジェクトを作成
uv init -p 3.12.9 livekit-1.0-work && cd livekit-1.0-work
パッケージインストール。LiveKit Agentでは、STT・LLM・TTSのそれぞれのコンポーネントをプラグイン形式で組み合わせてパイプラインを作成する。いろいろなベンダー向けに多数のコンポーネントが用意されているので、要件にあったものを選択すると良い。今回は、全部OpenAIでやる。
パッケージインストール。livekit-agentや各種プラグインの多くはv1.0以上のものである必要がある。
uv add "livekit-agents[openai,silero,turn-detector]~=1.0" \
"livekit-plugins-noise-cancellation~=0.2" \
"python-dotenv"
(snip)
+ livekit==1.0.5
+ livekit-agents==1.0.11
+ livekit-api==1.0.2
+ livekit-plugins-noise-cancellation==0.2.1
+ livekit-plugins-openai==1.0.11
+ livekit-plugins-silero==1.0.11
+ livekit-plugins-turn-detector==1.0.11
+ livekit-protocol==1.0.1
(snip)
+ onnxruntime==1.21.0
(snip)
なお、onnxruntime==1.21.0はSegmentation Faultが起きるバグが含まれていて、上記でインストールしたSileroVADのロードで失敗する。公式レポジトリでは修正されているので、たぶん次のリリースで修正されたものが出るはず。現時点では一旦v1.20.1に戻す。
uv add "onnxruntime==1.20.1"
- onnxruntime==1.21.0
+ onnxruntime==1.20.1
.envを作成。本来はLiveKitサーバのAPIキーなども設定が必要になるのだが、テストだけならプラグインで使用するベンダーのものだけを指定しておけば良い。
OPENAI_API_KEY=XXXXXXXXXX
ではエージェントのスクリプト。v0.Xとは書き方が変わっている。
from dotenv import load_dotenv
from livekit import agents
from livekit.agents import AgentSession, Agent, RoomInputOptions
from livekit.plugins import (
openai,
noise_cancellation,
silero,
)
from livekit.plugins.turn_detector.multilingual import MultilingualModel
load_dotenv()
class Assistant(Agent):
def __init__(self) -> None:
super().__init__(instructions="あなたは親切な日本語のAI音声アシスタントです。")
async def entrypoint(ctx: agents.JobContext):
await ctx.connect()
session = AgentSession(
stt=openai.STT(model="whisper-1", language="ja"),
llm=openai.LLM(model="gpt-4o-mini"),
tts=openai.TTS(model="tts-1", voice="coral"),
vad=silero.VAD.load(),
turn_detection=MultilingualModel(),
)
await session.start(
room=ctx.room,
agent=Assistant(),
# ノイズキャンセルはLiveKitCloudを使用する場合のみ
#room_input_options=RoomInputOptions(
# noise_cancellation=noise_cancellation.BVC(),
#),
)
await session.generate_reply(
instructions="ユーザーに挨拶し、支援を申し出てください。"
)
if __name__ == "__main__":
agents.cli.run_app(agents.WorkerOptions(entrypoint_fnc=entrypoint))
パット見だけでも、STT・LLM・TTSのパイプラインで構成されたエージェントが設定されている雰囲気をつかめると思う。
では、エージェントが必要とするモデル、ここではSireloVADやターン検出用のモデルをダウンロードする。
uv run main.py download-files
2025-04-11 23:35:12,485 - INFO livekit.agents - Downloading files for <livekit.plugins.openai.OpenAIPlugin object at 0x112e9a390>
2025-04-11 23:35:12,485 - INFO livekit.agents - Finished downloading files for <livekit.plugins.openai.OpenAIPlugin object at 0x112e9a390>
2025-04-11 23:35:12,485 - INFO livekit.agents - Downloading files for <livekit.plugins.silero.SileroPlugin object at 0x113dccf50>
2025-04-11 23:35:12,485 - INFO livekit.agents - Finished downloading files for <livekit.plugins.silero.SileroPlugin object at 0x113dccf50>
2025-04-11 23:35:12,486 - INFO livekit.agents - Downloading files for <livekit.plugins.turn_detector.EOUPlugin object at 0x114b2d3a0>
None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.
2025-04-11 23:35:15,476 - DEBUG urllib3.connectionpool - Starting new HTTPS connection (1): huggingface.co:443
2025-04-11 23:35:15,979 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v1.2.2-en/tokenizer_config.json HTTP/1.1" 200 0
2025-04-11 23:35:16,462 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v1.2.2-en/onnx/model_q8.onnx HTTP/1.1" 302 0
2025-04-11 23:35:16,647 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v1.2.2-en/languages.json HTTP/1.1" 200 0
2025-04-11 23:35:17,147 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v0.1.0-intl/tokenizer_config.json HTTP/1.1" 200 0
2025-04-11 23:35:17,627 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v0.1.0-intl/onnx/model_q8.onnx HTTP/1.1" 302 0
2025-04-11 23:35:17,814 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v0.1.0-intl/languages.json HTTP/1.1" 200 0
2025-04-11 23:35:17,817 - INFO livekit.agents - Finished downloading files for <livekit.plugins.turn_detector.EOUPlugin object at 0x114b2d3a0>
エラーっぽいログが出ている。PyTorch・Tensorflow・Flaxのどれかが必要ということかと思われる。今回はPyTorchを追加した。
uv add torch
+ torch==2.6.0
では起動。以前のv0.Xでは、LiveKit(サーバ or クラウド)を用意した上で、クラウドダッシュボードのWebアプリか、サンプルで用意されているReactのWebアプリが必要だったが、v1.0ではテストの場合はそれらも不要で確認ができる様子。
uv run main.py console
以下のようにCLIベースのツールが起動され、マイク・スピーカーを使って音声でやり取りができる。v1.0ではマルチリンガルに対応したターン検出モデルが用意され、これがいい感じに動いてるせいか、リアルタイムなモデルを使ってないはずなのに、そこそこ良いレスポンスでやり取りができて、あと割り込みも動作する。v0.Xよりもかなり良くなっている感がある。

なお、Getting Startedには以下のようなドキュメントもある。今回は試さないが興味があれば。
電話を使った音声エージェントについて
モバイルやWebでのフロントエンド=クライアント構築について
テスト用のWebフロントエンドについて
v0.Xからのマイグレーションガイド
Building voice agents: Overview
ここから少しコンセプト的なところを読んでいく。基本的に翻訳して気になったところだけコメントを残す。あと自分はPythonメインなので、複数言語について書かれている箇所ではPythonのみについて触れる。
概要
優れた音声AIアプリを構築するには、複数のコンポーネントを慎重に調整する必要があります。 また、音声 AIのエンドユーザー体験は、レイテンシと応答性に特に敏感です。 LiveKitエージェントは、開発を簡素化する専用抽象化を提供すると同時に、基礎となるコードを完全に制御できます。
エージェントセッション
AgentSessionは、音声AIアプリの主要なオーケストレーターです。セッションは、ユーザー入力を収集し、音声パイプラインを管理し、LLMを呼び出し、出力をユーザーに送り返す役割を担います。各セッションには、少なくとも1つのエージェントが必要です。エージェントは、お客様のアプリのコアAIロジック(指示やツールなど)を定義する役割を担います。このフレームワークでは、複数のエージェント間のハンドオフと委任を調整するカスタムワークフローの設計をサポートしています。
次の例は、シンプルな単一エージェントセッションを開始する方法を示しています。
from livekit.agents import AgentSession, Agent, RoomInputOptions from livekit.plugins import openai, cartesia, deepgram, noise_cancellation, silero from livekit.plugins.turn_detector.multilingual import MultilingualModel session = AgentSession( stt=deepgram.STT(), llm=openai.LLM(), tts=cartesia.TTS(), vad=silero.VAD.load(), turn_detection=turn_detector.MultilingualModel(), ) await session.start( room=ctx.room, agent=Agent(instructions="You are a helpful voice AI assistant."), room_input_options=RoomInputOptions( noise_cancellation=noise_cancellation.BVC(), ), )
AgentSessionで各コンポーネントを指定して、音声処理のパイプラインが構成される。
そしてLiveKitには「ルーム」という概念がある。これは、Google MeetのミーティングやZoomの会議に相当する。MeetやZoomでは、自分が発話した内容が他の参加者に伝わり、逆に他の参加者が発話した内容は自分にも届く。これはLiveKitのルームでも同様で、
- エージェントもユーザもルームへの「参加者」となる
- ユーザが発した音声は、ルームを通じて、他の参加者、つまりエージェントに渡され処理される。
- そしてエージェントの音声による回答も同じようにユーザに返される。
という仕組みになる。そのため、上記でエージェントセッション作成後、セッションは、ルームと特定の指示を持ったエージェントを紐づけて、開始されることになる。
音声AIプロバイダー
音声パイプラインの各部分には、ニーズに合わせてさまざまなプロバイダーを選択できます。このフレームワークは、高性能なSTT-LLM-TTSパイプラインと音声合成モデルの両方をサポートしています。いずれの場合も、割り込み・音声書き起こしの転送・ターン検出などを自動的に管理します。
これらのコンポーネントは、AgentSessionに追加して、アプリ内のグローバルデフォルトとして機能させることも、必要に応じて個々のエージェントに追加することもできます。
- STT
- LLM
- TTS
- マルチモーダル・リアルタイム
各コンポーネントについてはIntegrations Guideで細かく確認できる。
また、上記以外にもVADやターン検出などのコンポーネントも用意されている。
Building voice agents: Workflows
ワークフロー
複数のエージェントによる反復可能で正確なタスクのモデル化方法
概要
エージェントは、単一のセッション内で構成可能であり、高い信頼性で複雑なタスクをモデル化します。この機能が役立つ具体的なシナリオには、以下のようなものがあります。
- 通話の冒頭で同意の記録を取得する。
- 住所やクレジットカード番号などの特定の構造化された情報を収集する。
- 一連の質問を1つずつ進める。
- ユーザーが対応できない場合のボイスメールメッセージの残し方。
- 単一のセッション内に、独自の特性を持つ複数の人物像を含めること。
エージェントの定義
Agentクラスを拡張してカスタムエージェントを定義します。from livekit.agents import Agent class HelpfulAssistant(Agent): def __init__(self): super().__init__(instructions="あなたは親切な音声AIアシスタントです。") async def on_enter(self) -> None: await self.session.say("こんにちは!今日はどのようなご用件ですか?")また、
Agentクラスのインスタンスを直接作成することもできます。agent = Agent(instructions="You are a helpful voice AI assistant.")
ここには書いてないけど、on_enterはルームに参加者が「入ってきた」ときのイベントハンドラだと思う。
他のエージェントに制御を渡す
ツール呼び出しから別のエージェントを返して、制御を渡します。これにより、LLMがハンドオフのタイミングを決定できるようになります。
from livekit.agents import Agent, function_tool, get_job_context class ConsentCollector(Agent): def __init__(self): super().__init__( instructions=( "あなたは音声AIエージェントで、ユーザーからポジティブな録音同意を取得するという唯一のタスクがあります。" "同意が得られない場合は、通話を終了しなければなりません。" ) ) async def on_enter(self) -> None: await self.session.say("品質保証のため、この通話を録音してもよろしいでしょうか?") @function_tool() async def on_consent_given(self): """同意が得られた場合に通話を続行できるようにするにはこのツールを使う""" # ハンドオフを行い、直ちに新しいエージェントに制御を移行する return HelpfulAssistant() @function_tool() async def end_call(self) -> None: """同意が得られていなかった場合に通話を終了するにはこのツールを使う""" await self.session.say("お時間をいただきありがとうございます。良い一日をお過ごしください。") job_ctx = get_job_context() await job_ctx.api.room.delete_room(api.DeleteRoomRequest(room=job_ctx.room.name))
@function_tool()でエージェントに割り当てるツールを定義する。ここでは
-
on_consent_given: 別のエージェントであるHelpAssitant()を返すことでハンドオフする -
end_call: ルームを削除して終了する
ということで、エージェントへのツール割当と、エージェントをツールとして使うことでハンドオフを実現している。
コンテキストの保存
デフォルトでは、各新しいエージェントは、LLMプロンプトに対して新しい会話履歴から開始します。以前の会話を追加するには、エージェントコンストラクタで
chat_ctxパラメータを設定します。以前のエージェントのchat_ctxをコピーするか、適切なコンテキストを提供するためにカスタムのビジネスロジックに基づいて新しいものを構築します。from livekit.agents import ChatContext, function_tool, Agent class HelpfulAssistant(Agent): def __init__(self, chat_ctx: ChatContext): super().__init__( instructions="あなたは親切な音声AIアシスタントです。", chat_ctx=chat_ctx ) class ConsentCollector(Agent): # ... @function_tool() async def on_consent_given(self): """同意が得られたことを示して、通話を続行できるようにするためのツール""" # ハンドオフ時にチャットのコンテキストを渡す return HelpfulAssistant(chat_ctx=self.session.chat_ctx)そのセッションの会話履歴はすべて、
session.historyでいつでも確認できます。
chat_ctxを使ったコンテキストの保存はv0.Xと同じ。下の方ではエージェントにハンドオフする際にchat_ctxを渡すことで、エージェント間のコンテキストを維持しているのがわかる。
状態の受け渡し
セッション内にカスタムな「状態」を保存するには、
userdata属性を使用します。userdataの型は任意ですが、推奨されるアプローチはデータクラスを使用することです。from livekit.agents import AgentSession from dataclasses import dataclass @dataclass class MySessionInfo: user_name: str | None = None age: int | None = Noneセッションにユーザデータを追加するには、コンストラクタで渡します。また、
AgentSession自体にもユーザデータのタイプを指定する必要があります。session = AgentSession[MySessionInfo]( userdata=MySessionInfo(), # ... tts、stt、llm、など。 )ユーザデータは
session.userdataとしてアクセスできます。また、RunContext上の関数ツール内でもアクセスできます。以下の例は、IntakeAgentから開始するエージェントワークフローでuserdataを使用する方法を示しています。class IntakeAgent(Agent): def __init__(self): super().__init__( instructions="""あなたは受付エージェントです。ユーザの名前と年齢を記録します。""" ) @function_tool() async def record_name(self, context: RunContext[MySessionInfo], name: str): """ユーザの名前を記録するにはこのツールを使う""" context.userdata.user_name = name return self._handoff_if_done() @function_tool() async def record_age(self, context: RunContext[MySessionInfo], age: int): """ユーザの名前を記録するにはこのツールを使う""" context.userdata.age = age return self._handoff_if_done() def _handoff_if_done(self): if self.session.userdata.user_name and self.session.userdata.age: return HelpfulAssistant() else: return None class HelpfulAssistant(Agent): def __init__(self): super().__init__(instructions="あなたは親切な音声AIアシスタントです。") async def on_enter(self) -> None: userdata: MySessionInfo = self.session.userdata await self.session.generate_reply( instructions=f"{userdata.user_name} さんに挨拶をして、 {userdata.age} 歳であることについてのジョークを言ってください。." )
名前と年齢を「状態」として保持するMySessionInfoクラスを定義して、userdataを使って、これをIntakeAgentのセッションに紐づける。これによりこのエージェントはsession.userdataでこの「状態」にアクセスでき、各ツールにはRunContextでこの「状態」を渡して変更を行わせる。そして最後にHelpfulAssistantはIntakeAgentの中で呼び出されているので、session.userdata経由でアクセスができる、ということだと思う。ここハンドオフだからHelpfulAssistantにパスするのかなーと思ったけど、ドキュメントではそうではないみたい。
プラグインのオーバーライド
セッションで使用されるプラグインは、エージェントのコンストラクタで対応する属性を設定することで、オーバーライドすることができます。例えば、
tts属性をオーバーライドすることで、特定のエージェントの音声を変更することができます。from livekit.agents import Agent from livekit.plugins import cartesia class AssistantManager(Agent): def __init__(self): super().__init__( instructions="あなたは、親切な音声アシスタントチームのマネージャーです。", tts=cartesia.TTS(voice="6f84f4b8-58a2-430c-8c79-688dad597532") )
もうちょっと全体を書くと多分こんな感じ
(snip)
class HelpfulAssistant(Agent):
def __init__(self) -> None:
super().__init__(instructions="あなたは親切な日本語のAI音声アシスタントです。")
class AssistantManager(Agent):
def __init__(self):
super().__init__(
instructions="あなたは、親切な音声アシスタントチームのマネージャーです。",
tts=cartesia.TTS(voice="6f84f4b8-58a2-430c-8c79-688dad597532")
)
@function_tool()
async def handoff_to_helpful_assistant(self):
"""親切なアシスタントにハンドオフするためのツール"""
return HelpfulAssistant()
async def entrypoint(ctx: agents.JobContext):
await ctx.connect()
session = AgentSession(
stt=openai.STT(model="whisper-1", language="ja"),
llm=openai.LLM(model="gpt-4o-mini"),
tts=openai.TTS(model="tts-1", voice="coral"),
vad=silero.VAD.load(),
turn_detection=MultilingualModel(),
)
await session.start(
room=ctx.room,
agent=AssistantManager(),
)
(snip)
これで、デフォルトのエージェントセッションでは全てOpenAIのSTT・LLM・TTSが指定されているので、CartesiaのTTSを明示的に指定されているAssistantManager以外のエージェントはデフォルト設定を使う、ってことになるんだと思う。
例
これらの例では、複数のエージェントを使用してより複雑なワークフローを構築する方法を示しています。
- 医療事務トリアージ
症状や病歴に基づいて患者をトリアージするエージェント。- レストランエージェント
注文を受け、共有カートにアイテムを追加し、会計を行うレストランのフロントエージェント。
Building voice agents: Agent speech
TTSやSpeech-to-Speechなど発話の機能について。
概要
音声機能は、LiveKitエージェントの主要機能であり、音声によるユーザーとの対話を可能にします。このガイドでは、エージェントが利用できるさまざまな音声機能と機能について説明します。
LiveKitエージェントは、STT-LLM-TTSパイプラインとリアルタイムモデルの両方を使用してエージェントを制御するための統一インターフェイスを提供します。
Text-to-Speech(TTS)
TTSはテキストを音声に変換する合成プロセスであり、AIエージェントに「声」を与えます。一部のプロバイダーは音声のクローニングを提供しており、エージェントに自分の声を吹き込むことができます。
Speech-to-Speech
OpenAI RealtimeやGemini LiveなどのマルチモーダルなリアルタイムAPIは、音声入力を理解し、音声出力を直接生成することができます。この場合、アプリケーションは音声生成前のテキストストリームにアクセスできません。
使用例
TTSの作成
特定のプロバイダープラグインを使用して、TTSインスタンスを作成します。この例では、TTSにElevenLabsを使用します。
プロバイダープラグインをインストールします。
pip install "livekit-agents[elevenlabs]~=1.0"TTSインスタンスを作成します。
from livekit.plugins import elevenlabs from livekit.agents import AgentSession eleven_tts=elevenlabs.TTS( model="eleven_turbo_v2_5", voice=elevenlabs.Voice( id="EXAVITQu4vr4xnSDxMaL", name="Bella", ), language="en", enable_ssml_parsing=False, ) session = AgentSession( ... tts=eleven_tts, )より完全な例については、ElevenLabs TTSガイドを参照してください。
Realtimeモデルの使い方
この例では、OpenAIのリアルタイムAPIを使用してエージェントセッションを作成します。
from livekit.plugins import openai from livekit.agents import AgentSession session = AgentSession( llm=openai.realtime.RealtimeModel( voice="alloy", ), )
TTSの場合は、STT・LLM・TTSのパイプラインの1つとして使うけども、Realtimeモデルの場合はマルチモーダルLLMとして使うのでLLM以外は設定不要
発話を開始する
デフォルトでは、エージェントは応答する前にユーザー入力を待ちます。エージェントフレームワークが応答の生成を自動的に処理します。
しかし、場合によっては、エージェントが会話を開始する必要があるかもしれません。例えば、セッションの開始時にユーザーに挨拶をしたり、一定期間応答がない場合に確認を行う場合などです。
session.sayエージェントにあらかじめ設定されたメッセージを話させるには、
session.say()を使用します。これにより、設定された TTS が起動し、合成音声が再生され、ユーザーに聞こえるようになります。オプションとして、事前に合成されたオーディオを再生用に用意しておくこともできます。これにより、TTS のステップが省略され、応答時間が短縮されます。
await session.say( "こんにちは。今日はどのようなご用件でしょうか?", allow_interruptions=False, )パラメータ
パラメータ 型 必須 説明 textstr | AsyncIterable[str]必須 発話するテキスト audioAsyncIterable[rtc.AudioFrame]オプション 再生する事前に生成された音声 allow_interruptionsbooleanオプション True の場合、エージェントの発話中にユーザーの割り込みを許可する(デフォルト: True)add_to_chat_ctxbooleanオプション True の場合、再生後にテキストをエージェントのチャットコンテキストに追加する(デフォルト: True)戻り値
戻り値は
SpeechHandleオブジェクトを返す。
generate_reply会話に動きを持たせるには、LLMに回答を生成させるために
session.generate_reply()を使用します。
generate_replyの使用方法は2通りあります。
- エージェントに回答を生成する指示を与える
session.generate_reply( instructions="ユーザーに挨拶し、出身地を尋ねる", )
- テキスト形式でユーザーの入力を提供する
session.generate_reply( user_input="今日の天気はどう?", )パラメータ
パラメータ 型 必須 説明 user_inputstringオプション 応答すべきユーザーの入力 instructionsstringオプション エージェントが応答生成に使用する指示 allow_interruptionsbooleanオプション True の場合、エージェントの発話中にユーザーの割り込みを許可する(デフォルト: True)戻り値
戻り値は
SpeechHandleオブジェクトを返す。
Realtimeモデルの場合は本来TTSが不要なので、あえてsession.say()を使いたい(決まったことを発話させたい)場合にはTTSプラグインを追加、そうでない場合はsession.generate_reply()を使用するということになるのだと思う。
エージェントの音声を制御する
SpeechHandle
say()およびgenerate_reply()メソッドは、エージェントの音声の状態を追跡できるSpeechHandleオブジェクトを返します。これは、例えば通話を終了する前にユーザーに通知するなど、その後のアクションを調整する際に役立ちます。await session.say("それではまた。", allow_interruptions=False) # 上記は以下のショートカットです #handle = session.say("それではまた。", allow_interruptions=False) #await handle.wait_for_playout() # ` session.say`の発話完了を待つエージェントが話し終えるまで待ってから、続けてることができます。
handle = session.generate_reply( instructions="ユーザーに、これから遅い処理を実行することを伝えてください。" ) # 時間がかかる処理を行う ... await handle # 最後まで発話が完了するのを待つ次の例では、ユーザの要求でWebへのリクエストを行い、ユーザが割り込んだ場合はリクエストをキャンセルします。
async with aiohttp.ClientSession() as client_session: web_request = client_session.get('https://api.example.com/data') handle = await session.generate_reply( instructions="ユーザーの要求を処理していることを伝えてください。" ) if handle.interrupted: # ユーザが割り込んだ場合は、`web_request`もキャンセルする web_request.cancel()
SpeechHandleは、asyncio.Futureに似たAPIを持ち、コールバックを追加することができます。handle = session.say("ハローワールド") handle.add_done_callback(lambda _: print("発話完了"))現在の発話を取得する
現在の
SpeechHandleには、AgentSession.current_speechを通じてアクセスできます。これは、プログラムの任意の場所からエージェントの発話のステータスを確認する際に便利です。割り込み
デフォルトでは、ユーザが話し始めたことを検知すると、エージェントは発話を停止します。この動作は、発話のスケジュール時に
allow_interruptions=Falseを設定することで無効にできます。明示的にエージェントに割り込むには、ハンドルまたはセッションでいつでも
interrupt()メソッドを呼び出せます。これは、allow_interruptionsがFalseに設定されている場合でも実行できます。handle = session.say("ハローワールド") handle.interrupt() # ハンドルから割り込み # またはセッションから割り込み session.interrupt()
ChatGPTの音声モードやRealtime APIなどで使える割り込みは、LiveKitだとSTT・LLM・TTSのパイプライン構成でも使える。ただどのTTSを使った場合でも利用可能なのだろうか?仕組みを想像するとなんとなく行けそうな気はするが、果たして・・・
発音のカスタマイズ
ほとんどの TTS プロバイダーでは、以下の表にある SSML タグの一部またはすべてを使用して、Speech Synthesis Markup Language (SSML) により単語の発音をカスタマイズすることができます。
SSMLタグ 説明 phoneme標準の発音記号を使用して音声を発音する場合に使用する。タグで囲まれたテキストを音声で発音する。 say as囲まれたテキストの解釈方法を指定する。例えば、 characterを使用すると各文字が個別に読み上げられ、dateを使用するとカレンダーの日付が指定される。lexicon特定の単語の発音を音声表記またはテキスト読み上げマッピングを使用して定義するカスタム辞書 emphasisテキストを強調して読み上げる break手動でポーズを挿入する prosody音声出力のピッチ、読み上げ速度、および音量を制御する
SSMLが使えるのは少し古いTTSじゃないかなー、最近のものは使えないものが多い気がするし、使えても一部じゃないかという気もする。SSMLの対応状況はプロバイダによって異なるので、使いたいケースではプロバイダ側のドキュメントを確認する必要があると思う。
Building voice agents: Tool definition & use
いわゆるTool/Function Calling。
概要
LiveKitエージェントは、LLMツールの使用を完全にサポートしています。この機能により、エージェントのコンテキストを拡張し、インタラクティブな体験を創出し、LLMの制限を克服するためのツールのカスタムライブラリを作成することができます。ツール内では、以下の操作が可能です。
session.say()またはsession.generate_reply()を使用してエージェントの音声を生成する。- RPCを使用してフロントエンドのメソッドを呼び出す。
- ワークフローの一部として、他のエージェントにハンドオフ制御を移す。
コンテキストからセッションデータを保存および取得する- その他、Python 関数で可能なことはすべて可能。
ツールの定義
@function_toolデコレーターを使用して、エージェントクラスにツールを追加します。LLMは自動的にそれらにアクセスできます。from livekit.agents import function_tool, Agent, RunContext class MyAgent(Agent): @function_tool() async def lookup_weather( self, context: RunContext, location: str, ) -> dict[str, Any]: """指定した場所の天気情報を調べる。 Args: location: 天気情報を調べる場所 """ return {"weather": "晴れ", "temperature_c": 21}名前と説明
デフォルトでは、ツールの名前は関数の名前となり、説明はその関数の docstring となります。この動作を上書きするには、
@function_toolデコレータにnameとdescriptionを指定します。引数と戻り値
ツールの引数は、関数の引数から自動的に名前がコピーされます。引数と戻り値の型ヒントも、存在すればコピーされます。
必要に応じて、ツールの引数と戻り値に関する追加情報をツールの説明に記載します。
RunContextツールには、特別な
context引数のサポートが含まれています。これには、現在のsession、function_call、speech_handle、およびuserdataへのアクセスが含まれます。これらの機能の使用方法の詳細については、発話およびワークフロー内の状態に関するドキュメントを参照してください。エラー処理
LLMにエラーを返すために、
ToolError例外を発生させることができます。エラーおよび/または回復オプションを説明するカスタムメッセージを含めることができます。@function_tool() async def lookup_weather( self, context: RunContext, location: str, ) -> dict[str, Any]: if location == "金星": raise ToolError("この場所はまもなく利用可能になります。最新情報を入手するには、メーリングリストにご登録ください。") else: return {"weather": "晴れ", "temperature_c": 21}動的・共有可能なツール
tool引数を直接設定することで、利用可能なツールをより詳細に制御することができます。複数のエージェント間でツールを共有するには、クラス外でツールを定義し、それを各エージェントに提供します。特に
RunContextを使うと、現在のセッション、エージェント、および状態にアクセスできるためとても便利です。from livekit.agents import function_tool, Agent, RunContext @function_tool() async def lookup_user( context: RunContext, user_id: str, ) -> dict: """IDからユーザー情報を検索する""" return {"name": "山田太郎", "email": "yamada.taro@example.com"} class AgentA(Agent): def __init__(self): super().__init__( tools=[lookup_user], # ... ) class AgentB(Agent): def __init__(self): super().__init__( tools=[lookup_user], # ... )ツールの更新
エージェントを作成した後に利用可能なツールを更新するには、
agent.update_tools()を使用します。これは、エージェントクラス内で自動的に登録されたツールも含め、すべてのツールを置き換えますのでご注意ください。# ツールを追加 agent.update_tools(agent.tools + [tool_a]) # ツールを削除 agent.update_tools(agent.tools - [tool_a]) # すべてのツールを置き換え agent.update_tools([tool_a, tool_b])プログラムによるツール作成
ツールはプログラム的に作成することもでき、データベースのような動的なソースから定義を読み込む際に便利です。
from typing import Callable async def _set_input(field: str, input: str) -> str: # カスタムのロジック return "ハローワールド" set_phone_number: Callable[[str], None] = lambda x: _set_input("phone", x) phone_number_description = """ ユーザーが電話番号を入力した場合、この関数を呼び出す。 Args: phone: 設定する電話番号 """ await agent.update_tools( agent.tools + [function_tool(set_phone_number, name="set_phone_number", description=phone_number_description)] )フロントエンドへの転送
RPCを使用して「ツール呼び出し」をフロントエンドアプリに転送することができます。これは、呼び出しに必要なデータがフロントエンドでのみ利用可能な場合に便利です。また、RPCを使用して、構造化された方法でアクションやUIの更新をトリガーすることもできます。
例えば、以下はユーザのブラウザからユーザの現在地にアクセスする関数です。
エージェントの実装
from livekit.agents import function_tool, get_job_context, RunContext @function_tool() async def get_user_location( context: RunContext, high_accuracy: bool ): """ユーザーの現在の位置情報を緯度/経度として取得する。 Args: high_accuracy: 遅いがより正確な高精度モードを使用するかどうか Returns: 緯度と経度の座標を含む辞書 """ try: participant_identity = next(iter(get_job_context().room.remote_participants)) response = await context.session.room.local_participant.perform_rpc( destination_identity=participant_identity, method="getUserLocation", payload=json.dumps({ "highAccuracy": high_accuracy }), response_timeout=10.0 if high_accuracy else 5.0, ) return response except Exception: raise ToolError("ユーザの位置情報の取得に失敗しました。")フロントエンドの実装
次の例では、JavaScript SDK を使用しています。他の SDK でも同じパターンが使用できます。その他の例については、RPCドキュメントを参照してください。
import { RpcError, RpcInvocationData } from 'livekit-client'; localParticipant.registerRpcMethod( 'getUserLocation', async (data: RpcInvocationData) => { try { let params = JSON.parse(data.payload); const position: GeolocationPosition = await new Promise((resolve, reject) => { navigator.geolocation.getCurrentPosition(resolve, reject, { enableHighAccuracy: params.highAccuracy ?? false, timeout: data.responseTimeout, }); }); return JSON.stringify({ latitude: position.coords.latitude, longitude: position.coords.longitude, }); } catch (error) { throw new RpcError(1, "Could not retrieve user location"); } } );例
Building voice agents: Pipeline nodes
パイプラインの各コンポーネント間の受け渡し時などのタイミングでいろいろ処理できる的な感じかな?v0.Xにも似たような機能(before_llm_cbとか)はあったけど、ここはv1.0で新しいコンセプトとしてより細かく制御ができるようになっているっぽい。
音声パイプラインノード
音声パイプラインのノードをオーバーライドしてエージェントの動作をカスタマイズする方法について説明します。
概要
エージェントフレームワークでは、処理パスの複数のノードでエージェントの動作を完全にカスタマイズすることができます。ノードとは、あるプロセスが別のプロセスに移行する処理パスのポイントです。STT、LLM、およびTTSノードの場合、ノードから次のノードへの移行ポイントにおける前処理と後処理をカスタマイズできるだけでなく、デフォルトのプロセスをカスタムコードで完全に置き換えることもできます。
これらのノードはAgentクラスで公開されており、パイプラインの以下のポイントで発生します。
on_enter(): エージェントがセッションに入る。on_exit(): エージェントがセッションから退出する。on_user_turn_completed(): ユーザーのターンが完了する。transcription_node(): エージェントのLLMの出力の書き起こし処理。stt_node(): エージェントのSTT処理ステップ(パイプラインのみ)。llm_node(): エージェントの LLM 処理ステップ(パイプラインのみ)。tts_node(): エージェントの TTS 処理ステップ(パイプラインのみ)。realtime_audio_output_node(): エージェントの音声出力ステップ(Realtimeのみ)。パイプラインエージェントとRealtimeエージェントの違い
Realtimeエージェントは、パイプラインエージェントのようにコンポーネント化されておらず、STT、LLM、TTS用のノードもありません。その代わり、Realtimeエージェントはエージェント全体で単一のモデルを使用し、エージェントはユーザー入力をリアルタイムで処理します。Realtimeエージェントの動作は、文字起こしノードをオーバーライドしたり、エージェントの指示を更新したり、チャットコンテキストを追加したりすることで、カスタマイズすることができます。
音声パイプラインエージェント
音声パイプラインエージェントの処理経路:
originally from https://docs.livekit.io/agents/build/nodes/ and redrawn by kun432*Realtimeモデルエージェント
Realtimeモデルエージェントの処理経路:
originally from https://docs.livekit.io/agents/build/nodes/ and redrawn by kun432*カスタマイズのユースケース
以下の使用例は、エージェントの動作をカスタマイズする方法の例です。
- プラグインを使用せずに、カスタム STT、LLM、または TTS プロバイダを使用する。
- エージェントがセッションに入った際に、カスタムの挨拶を生成する。
- LLM に送信する前に、STT の出力を修正してフィラーを削除する。
- TTS に送信する前に LLM の出力を修正して、発音をカスタマイズする。
- エージェントまたはユーザーが話し終えた際に、ユーザーインターフェースを更新する。
ノードの動作のカスタマイズ
各ノードは、処理が行われるエージェントパイプラインのステップです。デフォルトでは、一部のノードはスタブメソッドであり、その他のノード(STT、LLM、およびTTSノード)はプロバイダプラグイン内のコードを実行します。これらのノードについては、ノードをオーバーライドし、デフォルトの動作の前、後、または代わりに追加の処理を追加することで、動作をカスタマイズすることができます。
スタブメソッドは、処理パスの特定のポイントで機能を追加できるように提供されています。
On enter/On exitノード
on_enterおよびon_exitノードは、エージェントがエージェントセッションに入室またはセッションから退室したときに呼び出されます。エージェントがセッションに入室すると、そのエージェントが制御を担当し、エージェントが退室するまでそのセッションの処理を担当します。詳細は、ワークフローを参照してください。たとえば、エージェントがセッションに入室したときに会話を開始します。
async def on_enter(self): # セッションに追加された際にユーザーに挨拶するようエージェントに指示する self.session.generate_reply( instructions="ユーザーを温かく歓迎してください。", )エージェント間のハンドオフと、
on_enterノードでのチャット履歴の保存について、より詳細な例については、レストランの注文と予約の例を参照してください。エージェントがセッションを終了する前に挨拶をするために、
on_exitメソッドをオーバーライドすることができます。async def on_exit(self): # さよならを言う await self.session.generate_reply( instructions="終了する前にユーザーに親切に挨拶してください。", )ターンが完了したノード
on_user_turn_completedノードは、ユーザーが話し終えたときに呼び出されます。このノードは、Agentのon_user_turn_completedメソッドをオーバーライドすることでカスタマイズできます。この時点では、
new_messageにはユーザーの入力が含まれていますが、チャットコンテキストにはまだ追加されていません。メッセージは、on_user_turn_completedが返された後に追加されます。このフックは、生成前にチャット履歴に追加のコンテキストを挿入することで、RAG(検索拡張生成)を行うために使用できます。
async def on_user_turn_completed( self, chat_ctx: ChatContext, new_message: ChatMessage, ) -> None: # RAGでコンテキストを検索 rag_content = await my_rag_lookup(new_message.text_content()) chat_ctx.add_message(role="assistant", content=rag_content) # chat_ctxへの変更は次の生成のみに使用され、永続化されない。 # チャットコンテキストへの変更を永続化するには、次の操作を行う。 # chat_ctx = chat_ctx.copy() # chat_ctx.add_message(...) # await self.update_chat_ctx(chat_ctx)生成を完全に中止する場合、例えば、Push-to-Talkインターフェース(訳注: ボタンを押している間だけ音声入力が許可されるようなインタフェース)の場合などは、次の操作を行います。
async def on_user_turn_completed( self, chat_ctx: ChatContext, new_message: ChatMessage, ) -> None: if not new_message.text_content: # 例えば、StopResponseを発生させて、エージェントが応答を生成するのを停止する。 raise StopResponse()完全な例については、マルチユーザーエージェントのPush-to-Talkの例をご覧ください。
STTノード
STTノードでは、デフォルトのSTTプロバイダに送信される前の音声フレームの処理方法をカスタマイズしたり、LLMに渡される前のSTT出力を後処理したりすることができます。
デフォルトの実装を使用するには、
Agent.default.stt_node()を呼び出します。例えば、
Agentのstt_nodeメソッドをオーバーライドすることで、STTノードにノイズフィルタリングを追加することができます。async def stt_node( self, audio: AsyncIterable[rtc.AudioFrame] ) -> Optional[AsyncIterable[stt.SpeechEvent]]: async def filtered_audio(): async for frame in audio: # ここにノイズフィルタリングのロジックを適用する yield frame async for event in Agent.default.stt_node(filtered_audio()): yield eventLLMノード
LLMノードはエージェントの応答を生成する役割を担います。
Agentのllm_nodeメソッドをオーバーライドすることで、LLMノードをカスタマイズすることができます。
llm_nodeを使用すると、プラグインを作成することなく、カスタムLLMプロバイダと統合することができます。AsyncIterable[llm.ChatChunk]を返す限り、LLMノードはパイプラインの次のノードにチャンクを転送します。また、次の例のように、TTSノードに送信する前にLLM出力を更新することもできます。
async def llm_node( self, chat_ctx: llm.ChatContext, tools: list[FunctionTool], model_settings: ModelSettings ) -> AsyncIterable[llm.ChatChunk]: # LLMの基本実装に基づいて処理 async for chunk in Agent.default.llm_node(chat_ctx, tools, model_settings): # LLMの出力に対して何らかの処理を施してから次のノードに送信 yield chunkllm_nodeはstructured outputの処理にも使用できます。 完全な例はこちらをご覧ください。
TTSノード
TTSノードは、LLMの出力結果を音声に変換する役割を担っています。
Agentのtts_nodeメソッドをオーバーライドすることで、TTSノードをカスタマイズすることができます。例えば、次の例のように、ユーザーインターフェイスに送信する前にTTS出力を更新することができます。async def tts_node( self, text: AsyncIterable[str], model_settings: ModelSettings ) -> AsyncIterable[rtc.AudioFrame]: """ 音声合成前に、カスタム発音ルールを適用してTTSを処理する。 一般的な専門用語や略語の発音を調整する。 """ # 発音の置き換え辞書。 # カスタム発音のサポートは、TTSプロバイダーに依存する。 # 詳細については、Speechのドキュメントを参照してください。 # https://docs.livekit.io/agents/build/speech/#pronunciation. pronunciations = { "API": "A P I", "REST": "rest", "SQL": "sequel", "kubectl": "kube control", "AWS": "A W S", "UI": "U I", "URL": "U R L", "npm": "N P M", "LiveKit": "Live Kit", "async": "a sink", "nginx": "engine x", } async def adjust_pronunciation(input_text: AsyncIterable[str]) -> AsyncIterable[str]: async for chunk in input_text: modified_chunk = chunk # 発音ルールを適用 for term, pronunciation in pronunciations.items(): # 部分置換を避けるために単語の境界を使用 modified_chunk = re.sub( rf'\b{term}\b', pronunciation, modified_chunk, flags=re.IGNORECASE ) yield modified_chunk # TTSの基本実装でテキストを修正して処理する async for frame in Agent.default.tts_node( adjust_pronunciation(text), model_settings ): yield frameTranscriptionノード
Transcriptionノードは、エージェントによる文字起こしの転送パスに含まれます。デフォルトでは、このノードは文字起こしを単に指定の出力に転送するタスクに渡します。この動作は、
AgentのTranscriptionノード(transcription_node)メソッドをオーバーライドすることでカスタマイズできます。例えば、文字起こしとしてクライアントに送信される前に、不要な書式をすべて削除することができます。async def transcription_node(self, text: AsyncIterable[str]) -> AsyncIterable[str]: def cleanup_text(text_chunk: str) -> str: # Strip any unwanted formatting return processed_text async for delta in text: yield cleanup_text(delta)Realtime音声出力ノード
Realtimeモデルが音声を出力する際に、Realtime音声出力ノードが呼び出されます。これにより、音声がユーザーに送信される前に、音声出力を修正することができます。例えば、次の例では、音声を早めたり遅くしたりすることができます。
def _process_audio(self, frame: rtc.AudioFrame) -> rtc.AudioFrame: pass async def _process_audio_stream( audio: AsyncIterable[rtc.AudioFrame] ) -> AsyncIterable[rtc.AudioFrame]: stream: utils.audio.AudioByteStream | None = None async for frame in audio: if stream is None: stream = utils.audio.AudioByteStream( sample_rate=frame.sample_rate, num_channels=frame.num_channels, samples_per_channel=frame.sample_rate // 10, # 100ms ) for f in stream.push(frame.data): yield _process_audio(f) for f in stream.flush(): yield _process_audio(f) async def realtime_audio_output_node( self, audio: AsyncIterable[rtc.AudioFrame], model_settings: ModelSettings ) -> AsyncIterable[rtc.AudioFrame]: return _process_audio_stream( Agent.default.realtime_audio_output_node(audio, model_settings) )例
以下の例では、さまざまなノードのカスタマイズについて説明します。
- Chain of Thoughtエージェント
TTS の前にテキストをクリーンアップするllm_nodeを使用して、Chain of Thought推論用のエージェントを構築します。- キーワード検出
音声内の特定のキーワードをリアルタイムで検出します。- LLM コンテンツフィルタ
llm_nodeにコンテンツフィルタリングを実装します。


Building voice agents: Audio and video
オーディオとビデオ
LiveKit エージェントにおけるオーディオとビデオの完全ガイド。
概要
トラックは LiveKit の主要な構成要素の1つであり、参加者がpublishおよびconsumeできるリアルタイムのメディアストリームを表します。トラックには、エージェント参加者を含む参加者のオーディオおよびビデオ入力が含まれます。ユーザー入力は、有効化された入力デバイス(マイクやカメラなど)を介して利用できますが、他のメディアタイプを含めることもできます。トラックの詳細については、メディアトラック を参照してください。
トラックの受信
公開されたトラックを視聴するには、トラックをsubscribeする必要があります。デフォルトでは、ジョブコンテキストは自動的にすべての参加者のすべての公開トラックをsubscribeします。この機能をオフにすると、subscriptionを手動で管理できます。
LiveKitはWebRTCトラックをストリームとして読み取り、Pythonでは
AsyncIteratorsとして公開されます。LiveKit SDKは、オーディオおよびビデオトラックの両方で動作するユーティリティを提供します。トラックをsubscribeすると、
TrackSubscribedイベントがトリガーされます。このイベントがトリガーされた際にトラックを処理するには、エントリーポイント関数に以下の例を追加します。from livekit import rtc async def do_something(track: rtc.Track): if track.kind == rtc.TrackKind.KIND_AUDIO: audio_stream = rtc.AudioStream(track) async for event in audio_stream: # ここで event.frame を処理するなにかを行う pass await audio_stream.aclose() elif track.kind == rtc.TrackKind.KIND_VIDEO: video_stream = rtc.VideoStream(track) async for event in video_stream: # ここで event.frame を処理するなにかを行う pass await video_stream.aclose() @ctx.room.on("track_subscribed") def on_track_subscribed( track: rtc.Track, publication: rtc.TrackPublication, participant: rtc.RemoteParticipant, ): if track.kind == rtc.TrackKind.KIND_AUDIO: asyncio.create_task(do_something(track)) elif track.kind == rtc.TrackKind.KIND_VIDEO: asyncio.create_task(do_something(track))手動でのsubscritpion処理
デフォルトでは、ワーカーがジョブを受け入れると、エージェントが自動的にトラックをsubscribeします。手動でsubscriptionを管理するには、
auto_subscribeをAutoSubscribe.SUBSCRIBE_NONEに設定します。async def entrypoint_fnc(ctx: JobContext): await ctx.connect( # 選択できる値: SUBSCRIBE_ALL, SUBSCRIBE_NONE, VIDEO_ONLY, AUDIO_ONLY # 省略された場合は SUBSCRIBE_ALL がデフォルト auto_subscribe=AutoSubscribe.SUBSCRIBE_NONE, )ビデオを使う
LiveKitは多くのビデオバッファエンコーディングをサポートしており、それらの間を自動的に変換します。
VideoFrameは現在のビデオバッファの種類と、それを他のエンコーディングのいずれかに変換する方法を提供します。async def handle_video(track: rtc.Track): video_stream = rtc.VideoStream(track) async for event in video_stream: video_frame = event.frame current_type = video_frame.type frame_as_bgra = video_frame.convert(rtc.VideoBufferType.BGRA) # [...] await video_stream.aclose() @ctx.room.on("track_subscribed") def on_track_subscribed( track: rtc.Track, publication: rtc.TrackPublication, participant: rtc.RemoteParticipant, ): if track.kind == rtc.TrackKind.KIND_VIDEO: asyncio.create_task(handle_video(track))公開(Publishing)
エージェントは、データを連続したライブフィードとしてトラックにpublishします。オーディオストリームは指定のサンプルレートとチャンネル数で生のPCMデータを伝送し、ビデオストリームは11種類のバッファエンコーディングのいずれかでデータを伝送できます。
オーディオのpublish
オーディオのpublishは、ストリームを任意の長さのオーディオフレームに分割します。内部バッファには、リアルタイムスタックに送信されるキュー内のオーディオが50ミリ秒分保持されます。新しいフレームを送信するために使用される
capture_frameメソッドはブロッキングであり、バッファがフレーム全体を受け取るまで制御を返しません。これにより、中断処理が容易になります。オーディオトラックをpublishするには、各フレームの長さ(サンプル数)に加え、サンプルレートとチャンネル数を事前に決定しておく必要があります。以下の例では、エージェントは10ミリ秒の長さのフレームで、48kHzの16ビット正弦波を一定に送信します。
SAMPLE_RATE = 48000 NUM_CHANNELS = 1 # mono audio AMPLITUDE = 2 ** 8 - 1 SAMPLES_PER_CHANNEL = 480 # 10 ms at 48kHz async def entrypoint(ctx: JobContext): await ctx.connect() source = rtc.AudioSource(SAMPLE_RATE, NUM_CHANNELS) track = rtc.LocalAudioTrack.create_audio_track("example-track", source) # エージェントは参加者なので、私たちの音声入出力はエージェントの「マイク」となる options = rtc.TrackPublishOptions(source=rtc.TrackSource.SOURCE_MICROPHONE) # ctx.agentはctx.room.local_participantの別名 publication = await ctx.agent.publish_track(track, options) frequency = 440 async def _sinewave(): audio_frame = rtc.AudioFrame.create(SAMPLE_RATE, NUM_CHANNELS, SAMPLES_PER_CHANNEL) audio_data = np.frombuffer(audio_frame.data, dtype=np.int16) time = np.arange(SAMPLES_PER_CHANNEL) / SAMPLE_RATE total_samples = 0 while True: time = (total_samples + np.arange(SAMPLES_PER_CHANNEL)) / SAMPLE_RATE sinewave = (AMPLITUDE * np.sin(2 * np.pi * frequency * time)).astype(np.int16) np.copyto(audio_data, sinewave) # このフレームをトラックに送信 await source.capture_frame(frame) total_samples += samples_per_channel動画のpublish
動画トラックをpublishする際には、事前に動画のフレームレートとバッファエンコーディングを設定しておく必要があります。この例では、エージェントがルームに接続し、10フレーム/秒で単色のフレームをpublishを開始します。
WIDTH = 640 HEIGHT = 480 async def entrypoint(ctx: JobContext): await ctx.connect() source = rtc.VideoSource(WIDTH, HEIGHT) track = rtc.LocalVideoTrack.create_video_track("example-track", source) options = rtc.TrackPublishOptions( # エージェントは参加者なので、私たちのビデオ入出力はエージェントの「カメラ」になる source=rtc.TrackSource.SOURCE_CAMERA, simulcast=True, # エンコーディングオプションを変更する際は、 # max_framerateとmax_bitrateの両方を設定する必要がある video_encoding=rtc.VideoEncoding( max_framerate=30, max_bitrate=3_000_000, ), audio_encoding=rtc.AudioEncoding(max_bitrate=48000), video_codec=rtc.VideoCodec.H264, ) publication = await ctx.agent.publish_track(track, options) # この色はARGBとしてエンコードされている。VideoFrameに渡される際に再エンコードされる。 COLOR = [255, 255, 0, 0]; # FFFF0000 RED async def _draw_color(): argb_frame = bytearray(WIDTH * HEIGHT * 4) while True: await asyncio.sleep(0.1) # 10 fps argb_frame[:] = COLOR * WIDTH * HEIGHT frame = rtc.VideoFrame(WIDTH, HEIGHT, rtc.VideoBufferType.RGBA, argb_frame) # このフレームをトラックに送信 source.capture_frame(frame) asyncio.create_task(_draw_color()):::mesage
注意publishされたフレームは静的ですが、最初のフレームが送信された後にルームに参加する参加者のために、継続的にストリーム配信する必要があります。
:::
こういうことだと認識してる。
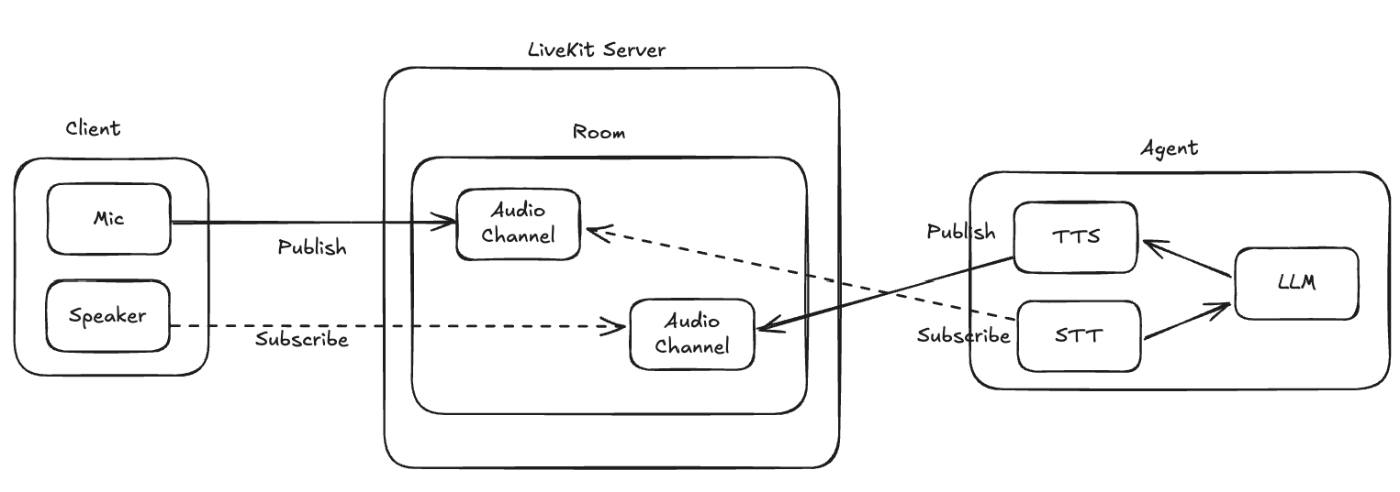
「ルーム」の各「参加者」は、自分の音声・映像をPublishして、他の参加者の音声・映像をSubscribeする。これによりやりとりができる。このあたり、エージェント作るぞ!と思って、LiveKit Agentのドキュメントを見てても、パイプライン処理とかそっちに頭が向いてしまって、いまいち理解できなかった。
LiveKitサーバ側のドキュメント、特に「トラック」のところとかを読んで、あと自分でクライアントを実装してみて、やっと雰囲気が掴めた感がある。つまり、LiveKitそのものの仕組みを理解する必要がある。
レシピ
以下のレシピでは、オーディオおよびビデオ機能のデモを行います。
- オーディオの再生
エージェントとのやり取り中にオーディオファイルを再生します。- サウンドリピータ
オーディオパイプラインのテスト用にシンプルなサウンドリピートデモを行います。- ビジョンAIエージェント
Geminiを搭載したライブビデオ入力機能付きの音声AIエージェントです。BGMのPublish
エージェントはバックグラウンドノイズや効果音を公開できます。例えば、オフィスやコンタクトセンターの周囲の雑音を追加すると、エージェントは既知の設定に置かれ、より現実的に感じることができます。
BackgroundAudioPlayerクラスは、ルームへのオーディオ再生を管理します。エントリーポイント関数に次の例を追加できます。background_audio = BackgroundAudioPlayer( # バックグラウンドでループするオフィスの雰囲気音を再生 ambient_sound=AudioConfig(BuiltinAudioClip.OFFICE_AMBIENCE, volume=0.8), # エージェントが考えているときにキーボードをタイプする音を再生します thinking_sound=[ AudioConfig(BuiltinAudioClip.KEYBOARD_TYPING, volume=0.8), AudioConfig(BuiltinAudioClip.KEYBOARD_TYPING2, volume=0.7), ], ) await background_audio.start(room=ctx.room, agent_session=session) # play メソッドを使用して、任意のタイミングで別のオーディオファイルを再生します。 # background_audio.play("filepath.ogg")完全な例については、BGMの例を参照してください。
背景ノイズの低減
LiveKit Cloudを使う場合は、強化されたノイズキャンセラーが利用可能です。これは音声AIアプリのターン検出と音声テキスト変換(STT)の品質を向上させます。エージェントセッションを開始する際に
room_input_optionsに追加することで、エージェントに背景ノイズと音声キャンセルを追加できます。ノイズキャンセラープラグインをインストールします:
pip install livekit-plugins-noise-cancellationエージェントアプリにバックグラウンド音声キャンセル(BVC)を追加します。バックグラウンドノイズキャンセルも含まれます。
await session.start( agent=MyAgent(), room=ctx.room, room_input_options=RoomInputOptions( # Krisp BVC ノイズキャンセルを有効化 noise_cancellation=noise_cancellation.BVC(), ), room_output_options=RoomOutputOptions(transcription_enabled=True), )完全な例については、基本エージェントの例の
noise_cancellation行のコメントを解除してください。音声とビデオの同期
AudioSynchronizerクラスを使用して、音声とビデオを同期することができます。このクラスにより、初期の音声とビデオのフレームを揃え、同期を維持することができます。詳細は、「音声とビデオの同期」を参照してください。
Building voice agents: Text and transcriptions
エージェントは音声や動画だけでなくテキストも使える。
テキストと文字起こし
エージェントにリアルタイムのテキスト機能を統合します。
概要
LiveKitエージェントは、LiveKit SDKのテキストストリーム機能に基づき、音声に加えてテキストの入出力に対応しています。このガイドでは、どのようなことが可能か、また、それをアプリで使用する方法について説明します。
文字起こし
エージェントが処理パイプラインの一部として STT を実行すると、文字起こし結果もリアルタイムでフロントエンドに公開されます。さらに、エージェントが発話すると、その音声再生と同期して、エージェントの発話のテキスト表現も公開されます。これらの機能は、
AgentSessionを使用する場合、デフォルトで有効になります。文字起こし結果は、
lk.transcriptionテキストストリームトピックを使用します。lk.transcribed_track_id属性が含まれ、送信者の ID は文字起こしされた参加者となります。文字起こし出力を無効にするには、
RoomOutputOptionsでtranscription_enabled=Falseを設定します。同期文字起こし転送
音声と文字起こしの両方が有効になっている場合、エージェントの発話は文字起こしと同期され、話した言葉が1語ずつテキストで表示されます。エージェントが中断された場合、文字起こしは停止し、話した内容に合わせて文字起こしが省略されます。
テキスト入力
エージェントは、リンクされた参加者からのテキストメッセージを受信するための
lk.chatテキストストリームトピックも監視します。メッセージを受信すると、エージェントは現在の会話を中断してメッセージを処理し、新しい応答を生成します。テキスト入力を無効にするには、
RoomInputOptionsでtext_enabled=Falseを設定します。テキストのみの出力
オーディオ出力を完全に無効にしてテキストのみを送信するには、
RoomOutputOptionsでaudio_enabled=Falseを設定します。エージェントは、lk.transcriptionテキストストリームトピックにテキスト応答を公開します。ただし、lk.transcribed_track_id属性は付加されず、音声同期も行われません。使用例
このセクションでは、テキスト機能の使用方法を示す簡単なコードサンプルを紹介します。
詳細については、テキストストリームのドキュメントを参照してください。より詳細な例については、レシピ集を参照してください。
フロントエンドへの実装
registerTextStreamHandlerメソッドを使用して、受信した書き起こしまたはテキストを受け取ります。room.registerTextStreamHandler('lk.transcription', async (reader, participantInfo) => { const message = await reader.readAll(); if (reader.info.attributes['lk.transcribed_track_id']) { console.log(`${participantInfo.identity} からの新しい文字起こし: ${message}`); } else { console.log(`${participantInfo.identity} からの新しいメッセージ: ${message}`); } });テキストメッセージを送信するには、
sendTextメソッドを使用します。const text = 'こんにちは、今日はお元気ですか?'; const info = await room.localParticipant.sendText(text, { topic: 'lk.chat', });入力/出力オプションの設定
AgentSessionコンストラクタは、入力および出力オプションの設定を受け付けます。session = AgentSession( ..., # STT、 LLM、 など room_input_options=RoomInputOptions( text_enabled=False # テキスト入力を無効化 ), room_output_options=RoomOutputOptions( audio_enabled=False # 音声出力を無効化 ) )手動でのテキスト入力
テキスト入力を挿入して応答を生成するには、AgentSessionの
generate_replyメソッドを使用します:session.generate_reply(user_input="...")カスタムトピック
必要に応じて、
RoomInputOptionsのtext_input_topicおよびRoomOutputOptionsのtranscription_output_topicをオーバーライドして、テキスト入力または出力用のカスタムテキストストリームトピックを設定することができます。デフォルト値はそれぞれ、lk.chatおよびlk.transcriptionです。書き起こしイベント
フロントエンドSDKは、
RoomEvent.TranscriptionReceivedを介して書き起こしイベントを受信することもできます。
Building voice agents: Turn detection and interruptions - Overview
ターン検出と割り込み。ここv0.X & 日本語使用だと、VADしかなかったので、v1.0でめちゃめちゃ気になっているところ。
ターン検出と割り込み
エージェントとユーザー間の会話の流れを管理します。
概要
AIエージェントとの自然な会話体験を実現するには、効果的なターン検出と割り込み管理が不可欠です。応答すべきタイミングと一時停止すべきタイミングを正確に識別することで、エージェントはユーザーとの自然で魅力的なやりとりを促進することができます。
ターン検出
エンドポインティング(訳注: 日本語だと「発話区間検出」)とは、音声ストリームにおける音声の開始と終了を検出するプロセスです。これは、会話型AIエージェントがユーザー入力に対して応答を開始するタイミングを理解するために不可欠です。
ターン終了の判断は、AIエージェントにとって特に難しい課題です。人間は、会話の区切りを認識するために、ポーズ、話し方、内容など、複数の手がかりを頼りにしています。
Agentsフレームワークでは、ターン境界を検出するための複数の戦略を提供しています。
- VAD
- ターン検出モデル
- リアルタイムLLM
- STT
- 手動
VAD
VADは、ユーザーが話し始めた時と、話し終わった時を検出するために使用されます。
AgentSession内では、デフォルトのVADオプションは Silero VAD です。- Node.js では、
VoicePipelineAgentのデフォルトは Silero VAD ですが、MultimodalAgentは OpenAI Realtime API サーバーの VAD を使用します。VAD 構成オプションについては、「ターン検出とユーザー割り込みの設定」を参照してください。
ターン検出モデル
VAD はユーザーが実際にいつ話しているかを検出するには効果的ですが、ユーザーが考え終えたかどうかを判断する文脈認識能力に欠けています。会話中に、人は考えたり、言葉を選んだりするためにしばしば一時停止します。
この問題に対処するために、LiveKit はカスタムのオープンウェイト言語モデルを開発し、会話の文脈を VAD への追加シグナルとして組み込みました。ターン検出プラグインは、このモデルを使用してユーザーが話し終えたかどうかを予測します。
モデルがユーザーの発話がまだ終わっていないと予測した場合、エージェントは応答する前にかなり長い沈黙期間を待ちます。これにより、会話の自然な区切りにおける望ましくない中断を防ぐことができます。
モデルのデモはこちらです。
モデル
弊社では、2つの別個のターン検出モデルを提供しています。
English(のみの)モデル
- https://huggingface.co/HuggingFaceTB/SmolLM2-135M-Instruct がベース
- ディスク上のサイズ: 66MB
- CPU推論時間: 100トークンにつき約15ミリ秒
Multilingualモデル
- https://huggingface.co/Qwen/Qwen2.5-0.5B がベース
- ディスク上のサイズ: 281MB
- CPU推論時間: 100トークンにつき約54ミリ秒
ベンチマーク
- true positive rate(真陽性率): ユーザーの発話が終了していないことを正確に識別することで、早期の中断を回避します。
- true negative rate(真陰性率): ユーザーの発話が終了した時点で、ターンが正確に終了したことを判断します。
モデル 言語 True Positive Rate True Negative Rate English 英語 0.988 0.875 Multilingual 英語 0.988 0.895 Multilingual スペイン語 0.988 0.967 Multilingual フランス語 0.988 0.973 Multilingual ドイツ語 0.988 0.966 Multilingual イタリア語 0.988 0.965 Multilingual ポルトガル語 0.988 0.971 Multilingual オランダ語 0.988 0.971 Multilingual 中国語 0.988 0.757 Multilingual 日本語 0.988 0.836 Multilingual 韓国語 0.988 0.897 Multilingual インドネシア語 0.988 0.973 Multilingual トルコ語 0.988 0.972 Multilingual ロシア語 0.988 0.973 ターン検出を使用する
ターン検出を使用するには、プラグインをインストールし、エージェントにターン検出を追加して初期化します。
livekit-plugins-turn-detectorパッケージをインストールします。pip install "livekit-agents[turn-detector]~=1.0"ターン検出を追加してエージェントを初期化します。
from livekit.plugins.turn_detector.english import EnglishModel from livekit.plugins.turn_detector.multilingual import MultilingualModel session = AgentSession( ... # Englishモデルの場合 turn_detection=EnglishModel(), # マルチリンガルモデルの場合 # turn_detection=MultilingualModel(),エージェントを初めて実行する前に、モデルの重みをダウンロードします。
python agent.py download-files
なるほど。どっちかというと効果がありそうなのは、VADだと発話中に考えているときの無音を発話区間終了と検出してしまうのを、ターン検出モデルだと回避できるってことかな?
自分は勝手にVAPのような先んじて予想するようなものを勝手にイメージしてたけど、まあそれは高望みすぎる。こっちがまだ喋ってんねん!みたいなストレスがなくなるものだと認識した。
日本語の精度も悪くなさそうだし、Qwen2.5-0.5Bのような軽量モデルはこういうユースケースでも使えるのだなぁ、これ日本語軽量モデルでやればもっと精度上がりそうな気がする。重みはHuggingFaceで公開されてるっぽいけど、独自ライセンス(LiveKitと組み合わせる以外では使えない)になっているし、FTコードとかも公開されなさそう。
Realtime LLM
Realtime LLM は、音声の直接入力と出力が可能であり、ターン終了イベントを予測するのに十分な文脈を提供します。OpenAI のRealtime API には、2つの利用可能なモードを持つネイティブなターン検出機能が含まれています。
- Server VAD - エージェント内で VAD を実行するのに似ています
- Semantic VAD
以下は、リアルタイム API を使用した意味 VAD の例です。
from livekit.plugins.openai import realtime from openai.types.beta.realtime.session import TurnDetection session = AgentSession( ... turn_detection="realtime_llm", llm=realtime.RealtimeModel(turn_detection=TurnDetection( type="semantic_vad", eagerness="medium", create_response=True, interrupt_response=True, )), )STT
ターン検出はSTTモデルでも処理できます。STTモデルは音声を処理するため、トーンやポーズなどの音声パターンを使用して、ユーザーの発話が終了したタイミングを推測することができます。このモードでは、エージェントは最後のSTT文字起こしをターン終了として扱います。
session = AgentSession( ... stt=myprovider.STT(), turn_detection="stt", )手動
また、会話の開始と終了を完全に制御することもできます。これは、ユーザーが発言する前にボタンを押すPush-to-Talkのようなアプリケーションに便利です。
Push-to-Talk のエージェントが RPC コールを使用して手動で会話の開始と終了を行う例を以下に示します。
session = AgentSession( ... turn_detection="manual", ) @ctx.room.local_participant.register_rpc_method("start_turn") async def start_turn(data: rtc.RpcInvocationData): session.interrupt() # マルチユーザーの場合、呼び出し元をリッスンする room_io.set_participant(data.caller_identity) session.input.set_audio_enabled(True) @ctx.room.local_participant.register_rpc_method("end_turn") async def end_turn(data: rtc.RpcInvocationData): session.input.set_audio_enabled(False) session.generate_reply()完全なサンプルは、こちらでご覧いただけます。
割り込みの処理
ユーザーが割り込んだ場合、エージェントは発話を停止し、リスニングモードに切り替わり、再生された音声の位置を
ChatContextに保存します。AI音声エージェントの割り込み動作を制御するパラメータは複数あります。 詳細については、「音声の検出とユーザーの割り込みの設定」を参照してください。手動による割り込み
セッションのエージェントセッションを手動で割り込むには、
session.interrupt()メソッドを使用します。アクティブなエージェントによる会話は直ちに終了し、コンテキストは中断前にユーザーが実際に聞いた会話のみに切り詰められます。# 誰かがルームに参加したら、エージェントの現在の応答を中断する @ctx.room.on("participant_connected") def on_participant_connected(participant: rtc.RemoteParticipant): session.interrupt()
Building voice agents: Turn detection and interruptions - Configuring turn detection and interruptions
1つ前の続き。実際に使用する場合のパラメータ等。
ターン検出と割り込みの設定
ターン検出とユーザー割り込みを微調整するための設定オプション
概要
ターン検出とユーザー割り込みは、ユーザーと音声 AI エージェント間の自然な会話を促進します。このトピックでは、音声活動検出(VAD)、ターン検出モデル、およびユーザー割り込みの設定オプションについて説明します。これらの機能の詳細については、「ターン検出と割り込み」を参照してください。
次の概念は、ターン検出とユーザー割り込みの設定を理解する際に役立ちます。
- 音声セグメント: VADはオーディオを「音声」と「非音声」のセグメントに分割します。
- 音声確率: オーディオフレームに音声が存在する確率。
- 音声活動時間: VADによって検出されたユーザーの音声の長さ。
- 無音時間: エージェントがユーザーの発話を終了したとみなす前に経過しなければならない無音の長さ。
- 音声中断時間: ユーザーの音声のうち、意図的な中断を特定できる時間。
LiveKit Cloudユーザーは、強化されたノイズキャンセリング機能を利用でき、背景ノイズを低減することで、ターン検出の精度を向上させることができます。ノイズキャンセリングの最適な設定は、ノイズキャンセリングの用途や具体的な使用事例によって異なる場合があります。ノイズキャンセリングの詳細については、「ノイズキャンセリング」を参照してください。
音声検出のためのVADパラメータ
以下のパラメータは、
AgentSessionと Node.js のVoicePipelineAgentの Silero VAD オプションを設定するために使用されます。
パラメータ 型 必須 デフォルト 説明 min_speech_durationfloatオプション 0.05中断が意図的なものであるとみなすために必要な最小音声継続時間 min_silence_durationfloatオプション 0.55音声が終了してからユーザーが話し終えたかどうかを判断するために待つ無音時間 activation_thresholdfloatオプション 0.5オーディオフレームに音声があるかどうかを判断する閾値。閾値を高く設定すると、より保守的な検出が可能になるが、小さな音声は検出できない可能性がある。閾値を低く設定すると、より敏感な検出が可能になるが、ノイズを音声として識別する可能性がある。 ユーザーによる中断
以下は、音声AIエージェントの中断動作を制御するパラメータです。
VoiceOptionsの以下のパラメータを使用して、AgentSessionの割り込みオプションを設定します。
パラメータ 型 必須 デフォルト 説明 allow_interruptionsboolオプション Trueユーザーがエージェントを割り込ませることを許可するかどうか。ユーザーの割り込みを無効にするには、False に設定する。 min_interruption_durationfloatオプション 0.5割り込みが意図的なものであると見なすために必要な最小の通話時間。 min_endpointing_delayfloatオプション 0.5ユーザーの発話を終了したと見なす前に待つ遅延時間。 ターン検出の設定
LiveKitのターン検出モデルには、1つだけ設定パラメータがあります。
unlikely_thresholdです。これは、ターン検出モデルの音声の確率のしきい値です。エンドポイントの確率がこのしきい値を下回る場合、ユーザーは話し終えていないと見なされ、エージェントは応答するまでに長く待機します。
Building voice agentsまで一通り読んでみた。思ったよりできることは多いが、
- LiveKit Agentsだけではなく、というかむしろLiveKit(サーバ)の仕組みを理解することが重要に思える。
- できることはいろいろあるが、実際にどう実装「すべき」か?はまだわからない。実際に試したり、デモなどを動かしてみて、「体感」するのが重要に思える。
- サンプルコードや「Recipes」のデモなど、豊富に用意されているように感じる。ここは大いに参考になりそう。
という感じ。
レシピ集
あと試してみるにあたっては、以前はLiveKitサーバを動かして、クライアントも用意する必要があったんだけど、
- v1.0では、エージェント作ってCLIだけで音声エージェントの確認できるようになったのはとても楽。
- ただし動画も使う場合は引き続き必要だと思う
- 動画の場合などはPlaygroundを使うと良さそう。
- LiveKitクラウドならビルトイン
- セルフホストならNext.jsベースのクライアントのレポジトリがある
あたりはだいぶ楽になった感がある。
Agents Playground
Worker Lifecycle: Overview
ここからは、LiveKitサーバを含めて、エージェントがどのように参加するか、どういうライフサイクルになるか?という話。
ワーカーのライフサイクル
ワーカーが LiveKit サーバーと連携してエージェントのジョブを管理する方法
概要
python main.py devを使用してアプリを起動すると、 LiveKit サーバーに「ワーカー」として登録されます。 LiveKit サーバーは、利用可能なワーカーにリクエストを送信することで、ユーザーが参加しているルームへのエージェントのディスパッチを管理します。LiveKit セッションとは、ルームに参加している1人以上の参加者のことです。LiveKit セッションは、単に「ルーム」と呼ばれることもよくあります。ユーザーがルームに接続すると、ワーカーがそのルームにエージェントを派遣するようリクエストを処理します。
ワーカーのライフサイクルの概要は以下の通りです。
- ワーカーの登録
エージェントコードは、自身を「ワーカー」として LiveKit サーバーに登録し、リクエストを待機します。- ジョブのリクエスト
ユーザーがルームに接続すると、LiveKit サーバーは利用可能なワーカーにリクエストを送信します。ワーカーはジョブを処理するための新しいプロセスを受け入れ、開始します。これはエージェントのディスパッチとも呼ばれます。- ジョブ
あなたのentrypoint関数によって開始されるジョブです。 これは、あなたが作成するコードおよびロジックの大部分です。 詳細は、「ジョブのライフサイクル」を参照してください。- LiveKit セッションの終了
デフォルトでは、最後のエージェント以外の参加者が退室すると、ルームは自動的に閉じられます。 残っているエージェントは切断されます。 また、手動でセッションを終了することもできます。以下の図は、ワーカーのライフサイクルを示しています。
originally from https://docs.livekit.io/agents/worker/ and redrawn by kun432ワーカーの追加機能には、以下のようなものがあります。
- ワーカーは、LiveKitサーバーと可用性と容量情報を自動的に交換し、受信リクエストの負荷分散を可能にします。
- 各ワーカーは、複数のジョブを同時に実行でき、各ジョブは分離のために独自のプロセスで実行されます。1つのジョブがクラッシュしても、同じワーカー上で実行中の他のジョブには影響しません。
- 更新を展開する際、ワーカーはシャットダウンする前にアクティブなLiveKitセッションを適切に終了し、通話中にセッションが中断されないようにします。
ワーカーオプション
WorkerOptions を使用して、権限、ディスパッチルール、プリウォーム機能の追加などを変更できます。

Worker Lifecycle: Agent dispatch
エージェントのディスパッチ
エージェントがルームに割り当てられるタイミングと方法を指定します
エージェントのディスパッチ
ディスパッチとは、エージェントをルームに割り当てる処理です。 LiveKit サーバーは、ワーカーのライフサイクルの一部としてこの処理を管理します。 LiveKitは、高い同時接続性と低いレイテンシを実現するためにディスパッチを最適化し、通常は1秒あたり数十万の新規接続をサポートし、ディスパッチの最大時間は150ミリ秒未満です。
エージェントの自動ディスパッチ
デフォルトでは、新しいルームごとにエージェントが自動的にディスパッチされます。すべての新しい参加者に同じエージェントを割り当てる場合は、自動ディスパッチが最適なオプションです。
明示的なエージェントディスパッチ
明示的なディスパッチは、エージェントがルームに参加するタイミングや方法について、より詳細な制御を行う場合に利用できます。このアプローチでは、同じワーカーシステムを活用し、エージェントワーカーを同じ方法で実行できます。
明示的なディスパッチを使用するには、
WorkerOptionsのagent_nameフィールドを設定します。opts = WorkerOptions( ... agent_name="test-agent", )API経由でディスパッチ
agent_nameが設定されたエージェントワーカーは、AgentDispatchService経由でルームに明示的にディスパッチすることができます。import asyncio from livekit import api room_name = "my-room" agent_name = "test-agent" async def create_explicit_dispatch(): lkapi = api.LiveKitAPI() dispatch = await lkapi.agent_dispatch.create_dispatch( api.CreateAgentDispatchRequest( agent_name=agent_name, room=room_name, metadata="my_job_metadata" ) ) print("created dispatch", dispatch) dispatches = await lkapi.agent_dispatch.list_dispatch(room_name=room_name) print(f"there are {len(dispatches)} dispatches in {room_name}") await lkapi.aclose() asyncio.run(create_explicit_dispatch())ルーム
my-roomは、まだ存在していなければ、配信時に自動的に作成され、ワーカーがtest-agentを割り当てます。ジョブのメタデータの処理
エージェントに渡される
job.metadataには、ディスパッチリクエストで設定されたメタデータが含まれています。次の例では、メタデータをログに記録しています。async def entrypoint(ctx: JobContext): logger.info(f"job metadata: {ctx.job.metadata}") ...インバウンドSIPコールからのディスパッチ
インバウンドSIPコールに対して、エージェントを明示的にディスパッチすることができます。SIPディスパッチルールでは、
room_config.agentsフィールドを使用して1人以上のエージェントを定義できます。LiveKitは、1つのプロジェクト内で複数のエージェントを使用できるため、SIPインバウンドコールに対して自動エージェントディスパッチよりも明示的なエージェントディスパッチを推奨します。
参加者の接続時のディスパッチ
参加者のトークンを設定して、接続時に1人以上のエージェントを即座にディスパッチすることができます。
複数のエージェントをディスパッチするには、
RoomConfigurationに複数のRoomAgentDispatchエントリを含めます。次の例では、参加者が接続したときに、エージェント
test-agentをルームmy-roomにディスパッチするトークンを作成します。from livekit.api import ( AccessToken, RoomAgentDispatch, RoomConfiguration, VideoGrants, ) room_name = "my-room" agent_name = "test-agent" def create_token_with_agent_dispatch() -> str: token = ( AccessToken() .with_identity("my_participant") .with_grants(VideoGrants(room_join=True, room=room_name)) .with_room_config( RoomConfiguration( agents=[ RoomAgentDispatch(agent_name="test-agent", metadata="my_metadata") ], ), ) .to_jwt() ) return token
Worker Lifecycle: Job lifecycle
ジョブのライフサイクル
エントリーポイント関数と、LiveKit セッションの終了とクリーンアップ方法について、さらに詳しく説明します
ライフサイクル
ワーカーが LiveKit サーバーからジョブリクエストを受け入れると、その特定のジョブのコンテキストでエントリーポイント関数を実行する新しいプロセスを開始します。各ジョブは、エージェントを互いに分離するために、個別のプロセスで実行されます。セッションインスタンスがクラッシュした場合でも、同じワーカー上で実行中の他のエージェントには影響しません。
エントリーポイント
エントリーポイント関数は、ワーカーによって実行される新しいジョブごとに、プロセスのメイン関数として実行されます。エントリーポイント関数では、ジョブを完全に制御できます。ジョブは、すべての参加者が退室するか、ジョブが明示的にシャットダウンされるまで実行されます。
async def do_something(track: rtc.RemoteAudioTrack): audio_stream = rtc.AudioStream(track) async for event in audio_stream: # ここでなにかevent.frameを処理する pass await audio_stream.aclose() async def entrypoint(ctx: JobContext): # LiveKit Python SDK からの rtc.Room インスタンス room = ctx.room # 接続する前にルームにリスナーを設定 @room.on("track_subscribed") def on_track_subscribed(track: rtc.Track, *_): if track.kind == rtc.TrackKind.KIND_AUDIO: asyncio.create_task(do_something(track)) # ルームに接続 await ctx.connect(auto_subscribe=AutoSubscribe.AUDIO_ONLY) # 接続された場合、room.local_participantはエージェントを表す await room.local_participant.publish_data("hello world") # 現在接続中のリモート参加者を順に処理する for rp in room.remote_participants.values(): print(rp.identity)LiveKit エージェントの例については、GitHub リポジトリをご覧ください。トラックの公開と受信の詳細については、以下のトピックをご覧ください。
- メディアトラック
マイク、スピーカー、カメラ、およびエージェントとの画面共有を使用します。- リアルタイムのテキストおよびデータ
テキストおよびデータチャネルを使用して、エージェントとコミュニケーションをとります。参加者のカスタマイズ
接続中の参加者に基づいてエージェントの動作をカスタマイズし、パーソナライズされた体験を提供することができます。
LiveKit には、参加者を識別するいくつかの方法があります。
ctx.room.name: 参加者が接続しているルームの名前。participant.identity: 参加者の識別情報。participant.attributesおよびparticipant.metadata:参加者に設定されたカスタム属性。以下に例を示します。
async def entrypoint(ctx: JobContext): # ルームに接続 await ctx.connect(auto_subscribe=AutoSubscribe.AUDIO_ONLY) # 最初の参加者が来るのを待つ participant = await ctx.wait_for_participant() # 参加者の行動に基づいて動作をカスタマイズ print(f"connected to room {ctx.room.name} with participant {participant.identity}") # 属性の現在の値を確認 language = participant.attributes.get("user.language") # 属性が変更されたときに聞く @ctx.room.on("participant_attributes_changed") def on_participant_attributes_changed(changed_attrs: dict[str, str], p: rtc.Participant): if p == participant: language = p.attributes.get("user.language") print(f"participant {p.identity} changed language to {language}")セッションの終了
エージェントの切断
エージェントは、タスクを完了し、ルームで必要なくなった時点で切断できます。これにより、LiveKit セッションの他の参加者はセッションを継続できます。シャットダウンフックは、シャットダウンのフックの後に実行されます。
async def entrypoint(ctx: JobContext): # なにか処理する ... # ルームから切断 ctx.shutdown(reason="Session ended")全員の切断
全員のセッションを終了させる場合は、Server APIの
deleteRoomを使用してセッションを終了させます。切断されたルームイベントが送信され、ルームはサーバーから削除されます。
from livekit import api async def entrypoint(ctx: JobContext): # なにか処理する ... api_client = api.LiveKitAPI( os.getenv("LIVEKIT_URL"), os.getenv("LIVEKIT_API_KEY"), os.getenv("LIVEKIT_API_SECRET"), ) await api_client.room.delete_room(api.DeleteRoomRequest( room=ctx.job.room.name, ))後処理とクリーンアップ
セッションが終了した後、シャットダウンフックを使用して後処理やクリーンアップのタスクを実行することができます。例えば、ユーザーの状態をデータベースに保存したい場合などです。
async def entrypoint(ctx: JobContext): async def my_shutdown_hook(): # ユーザの「状態」を保存 ... ctx.add_shutdown_callback(my_shutdown_hook)
そういえば、以前試したとき、クライアントが切断してルームに誰もいなくなると、ワーカーもルームから退出、しばらくしてルームが削除されてた。
ただ、クライアントが切断して即再接続すると、エージェント(のon_enterイベント)がうまく動かなかったことがあったんだよな。クライアントが切断したあとは、サーバのログ見て、ルームが削除されたことを確認してから接続するとちゃんと動いてた。
この辺はサーバ側の設定とかあるのかも知れない。また調べてみよう。
Worker Lifecycle: Worker options
ワーカーのオプション
ワーカーを作成する際に使用できるオプションについて説明します
WorkerOptions パラメータ
ワーカーを作成するためのインターフェイスは、
WorkerOptionsクラスを通じて行います。以下では、使用可能なパラメータの一部のみを記載しています。完全なリストについては、WorkerOptions リファレンスを参照してください。opts = WorkerOptions( # ジョブがこのワーカーに割り当てられた際にエントリポイント関数が呼び出される # これは WorkerOptions に必要な唯一のパラメータ entrypoint_fnc, # リクエストを検査し、現在のワーカーが処理すべきかどうかを決定する request_fnc, # 新しいプロセスで必要な初期化を実行する関数 prewarm_fnc, #現在のシステム負荷(CPUやRAMなど)を報告する関数 load_fnc, # load_fncの最大値。これを超えると、新しいプロセスが生成されない load_threshold, #エージェントがトラックの購読、データの公開、メタデータの更新などを行えるかどうか。 permissions, # 作成するワーカーの種類(JT_ROOMまたはJT_PUBLISHER) worker_type=WorkerType.ROOM, ) # ワーカーを開始 cli.run_app(opts)エントリーポイント
これは、LiveKit サーバーがワーカーに新しいジョブを割り当てた際に呼び出されるメイン関数です。これは、エージェントのエントリーポイントです。 エントリーポイント関数は、エージェントがルームに参加する前に実行され、必要な状態や構成を設定する場所となります。 エントリーポイント関数についてさらに詳しく知りたい場合は、「ジョブのライフサイクル」トピックを参照してください。
async def entrypoint(ctx: JobContext): # ルームに接続 await ctx.connect() # セッションをハンドル ...リクエストハンドラ
request_fnc関数は、サーバーがエージェントに仕事を割り当てるたびに実行されます。フレームワークは、各ジョブリクエストを明示的に承認または拒否することをワーカーに期待しています。リクエストを承認すると、エントリーポイント関数が呼び出されます。リクエストを拒否すると、次の利用可能なワーカーに送信されます。デフォルトでは、空白のままにしておくと、ワーカーに割り当てられたすべてのリクエストが自動的に承認されます。
async def request_fnc(req: JobRequest): # ジョブリクエストを受け入れる await req.accept( # エージェントの名前 (Participant.name)、デフォルトは "" name="agent", # エージェントの ID (Participant.identity)、デフォルトは "agent-<ジョブID>" identity="dentity", # エージェント参加時に設定する属性 attributes={"myagent": "rocks"}, ) # または拒否します # await req.reject() opts = WorkerOptions(entrypoint_fnc=entrypoint, request_fnc=request_fnc)プレウォーム関数
分離およびパフォーマンス上の理由から、フレームワークは各エージェントジョブを個別のプロセスで実行します。エージェントは、ロードに時間がかかるモデルファイルへのアクセスを必要とすることがよくあります。この問題に対処するために、ジョブを割り当てる前にプレウォーム関数を使用してプロセスをウォームアップすることができます。
num_idle_processesパラメータを使用して、ウォームアップしておくプロセスの数を制御することができます。def prewarm_fnc(proc: JobProcess): # Sileroの重みをロードし、ユーザデータを処理するために保存 proc.userdata["vad"] = silero.VAD.load() async def entrypoint(ctx: JobContext): # ロードされたSileroインスタンスにアクセス vad: silero.VAD = ctx.proc.userdata["vad"] opts = WorkerOptions(entrypoint_fnc=entrypoint, prewarm_fnc=prewarm_fnc)権限
デフォルトでは、エージェントは同じルーム内の他の参加者に対して、publishおよびsubscribeの両方が可能です。ただし、
WorkerOptionsのpermissionsパラメータを設定することで、これらの権限をカスタマイズすることができます。パラメータの一覧については、WorkerPermissionsリファレンスを参照してください。opts = WorkerOptions( ... permissions=WorkerPermissions( can_publish=True, can_subscribe=True, can_publish_data=True, # true に設定すると、エージェントはルーム内の他のユーザーには表示されない。 # hiddenにすると、見えなくなるため、ルームにトラックを公開することもできなくなる。 hidden=False, ), )ワーカーの種類
各ルームごとに、またはルーム内の各パブリッシャーごとにエージェントの新しいインスタンスを開始するように選択できます。これは、ワーカーを登録する際に設定できます。
opts = WorkerOptions( ... # 省略された場合、デフォルトはWorkerType.ROOM worker_type=WorkerType.ROOM, )
WorkerTypeenum には、以下の2つのオプションがあります。
ROOM: 各ルームにエージェントの新しいインスタンスを作成します。PUBLISHER: ルーム内の各パブリッシャーにエージェントの新しいインスタンスを作成します。エージェントが複数のパブリッシャーが存在する可能性のあるルームでリソース集約的な操作(例えば、複数のセキュリティカメラからの受信ビデオの処理など)を実行している場合、
worker_typeをJT_PUBLISHERに設定して、各パブリッシャーがそれぞれエージェントのインスタンスを持つようにすることができます。
PUBLISHERジョブの場合、ルーム内の各パブリッシャーに対してentrypoint関数を一度呼び出します。JobContext.publisherオブジェクトには、そのパブリッシャーを表すRemoteParticipantが含まれています。ワーカーの起動
WorkerOptionsを使用して定義した構成でワーカーを起動するには、CLIを呼び出します。if __name__ == "__main__": cli.run_app(opts)Agents worker CLI には、
startとdevの 2 つのサブコマンドがあります。前者は、生の JSON データを標準出力に出力し、本番環境での使用が推奨されます。devは、人間が読みやすい色付きログを出力し、Python のホットリロードをサポートするため、開発での使用が推奨されます。
Worker Lifecycleも一通り完了。もう少しエージェントやクライアントがルームに入った場合の動きは確認しないといけない。あと、複数クライアントが接続した場合の動きなどもちょっと確認かな。
Deployment & Operations: Deploying to production
本番環境へのデプロイ
本番環境での LiveKit エージェントの実行ガイド
概要
LiveKit エージェントは、Kubernetes のようなコンテナオーケストレーションシステムに適したワーカープールモデルを使用します。各ワーカー(
python main.py startのインスタンス)は LiveKit サーバーに登録されます。LiveKit サーバーは、利用可能なワーカー間でジョブのディスパッチを分散します。ワーカー自体が各ジョブごとに新しいサブプロセスを生成し、そのジョブがコードとエージェント参加者の実行場所となります。本番環境へのデプロイには、通常、
CMD ["python", "main.py","start"]で終わるシンプルなDockerfileと、負荷に応じてワーカープールをスケーリングするデプロイメントプラットフォームが必要です。
originally from https://docs.livekit.io/agents/ops/deployment/ and redrawn by kun432どこにデプロイするか
LiveKit エージェントはどこにでもデプロイできます。推奨されるアプローチは、
Dockerを使用してオーケストレーションサービスにデプロイすることです。LiveKit チームとコミュニティは、以下のデプロイプラットフォームが最も簡単にワーカーをデプロイし、オートスケールできることを確認しています。
- LiveKit Cloud エージェント ベータ版(New)
LiveKit Cloud を提供しているのと同じネットワークおよびインフラ上でエージェントを実行し、ビルド、デプロイ、スケーリングを自動的に行います。 まずはパブリックベータ版に登録してください。- Kubernetes
Kubernetes 上で LiveKit エージェントをデプロイおよびオートスケーリングするためのサンプル構成。- Render.com
Render.com 上で LiveKit エージェントをデプロイおよびオートスケーリングするためのサンプル構成です。- その他のデプロイ例
さまざまなデプロイプラットフォーム用のDockerfileと構成ファイルの例です。ネットワーク
ワーカーは、WebSocket 接続を使用して LiveKit サーバーに登録し、受信ジョブを受け取ります。つまり、ワーカーは、受信ホストやポートをパブリックインターネットに公開する必要はありません。
オプションとして、監視用のプライベートヘルスチェックエンドポイントを公開することもできますが、通常の運用には必要ありません。デフォルトのヘルスチェックサーバーは、
http://0.0.0.0:8081/でリスニングします。環境変数
APIキーなどの機密情報を含む環境変数でワーカーを設定することが推奨されます。LiveKit変数に加えて、エージェントが依存する外部サービス用の追加のキーが必要になる可能性もあります。
例えば、Voice AIクイックスタートで構築されたエージェントには、最低限、以下のキーが必要です。
.envDEEPGRAM_API_KEY=<あなたの Deepgram API キー> OPENAI_API_KEY=<あなたの OpenAI API キー> CARTESIA_API_KEY=<あなたの Cartesia API キー> LIVEKIT_API_KEY=<あなたの API キー> LIVEKIT_API_SECRET=<あなたの API シークレット> LIVEKIT_URL=<あなたの LiveKit サーバ URL>ストレージ
ワーカーおよびジョブプロセスには、Dockerイメージ自体のサイズ(通常は1GB未満)を超えるストレージ要件はありません。10GBの一時ストレージがあれば、これとアプリの一時的なストレージニーズを十分に満たすことができます。
メモリとCPU
メモリとCPUの要件は、アプリの具体的な詳細によって大きく異なります。例えば、高度なノイズキャンセリングを適用するエージェントは、適用しないエージェントよりも多くのCPUとメモリを必要とします。
LiveKitは、ほとんどの音声対音声アプリケーションの初期設定として、25の同時セッションごとに4コアと8GBのメモリを推奨しています。
ロールアウト
SIGINTまたはSIGTERMにより、ワーカーはジョブの受け入れを停止します。ワーカー上で実行中のジョブは、完了まで引き続き実行されます。ユーザーエクスペリエンスを中断することなくジョブを完了できるように、十分な猶予期間を設定することが重要です。音声AIアプリでは、会話が終了するまで10分以上の猶予期間が必要になる場合があります。
デプロイメントプラットフォームによって、この猶予期間の設定方法は異なります。Kubernetesでは、pod specの
terminationGracePeriodSecondsフィールドです。詳細については、あなたのデプロイメントプラットフォームのドキュメントを参照してください。
ロードバランシング
LiveKitサーバーには、組み込みの負荷分散ジョブ配信システムが含まれています。このシステムは、各ジョブが1つのワーカーのみに割り当てられるシングルアサインメントの原則に従ってラウンドロビン方式で配信を行います。ワーカーが事前に設定されたタイムアウト期間内にジョブの受け入れに失敗した場合、代わりに別の利用可能なワーカーにジョブが送信されます。
LiveKit Cloudでは、さらに地理的近接性も考慮して、地理的に最も近いユーザーとワーカーを一致させるように優先順位付けを行います。これにより、ユーザーとエージェント間の待ち時間を最小限に抑えることができます。
ワーカーの可用性
ワーカーの可用性は、
WorkerOptions設定のload_fncおよびload_thresholdパラメータによって定義されます。
load_fncは、ワーカーのビジー状態を示す0から1の間の値を返す必要があります。load_thresholdは、ワーカーが新しいジョブの受付を停止する負荷値です。デフォルトの
load_fncはCPU使用率全体、デフォルトのload_thresholdは0.75です。オートスケーリング
トラフィックの変動パターンに対応するには、デプロイメントプラットフォームにオートスケーリング戦略を追加します。オートスケーラーは、
load_fncと同じ基本指標を使用しますが(デフォルトはCPU使用率)、ワーカーのload_thresholdよりも低い閾値でスケールアップする必要があります。これにより、既存のワーカーがサービス不能になる前に新しいワーカーを追加することで、サービスの継続性を確保できます。例えば、load_thresholdが0.75の場合、0.50でスケールアップする必要があります。音声エージェントは通常、長時間実行されるタスク(一般的なウェブリクエストと比較して)であるため、負荷の急激な増加は持続する可能性が高くなります。専門用語で言えば、スパイクがそれほどスパイクしなくなるということです。オートスケーリングの設定では、スケールアップの際にはクールダウン/安定化期間を短縮することを検討すべきです。スケールダウンする際には、ワーカーが処理を完了するまでに時間がかかるため、クールダウン/安定化期間を延長することを検討すべきです。
例えば、Horizontal Pod Autoscalerを使用してKubernetesにデプロイする場合は、stabilizationWindowSecondsを参照してください。

Deployment & Operations: Session recording and transcripts
セッションの録画と書き起こし
セッションデータをビデオ、オーディオ、テキスト形式でエクスポートします
概要
品質モニタリングからコンプライアンスまで、アプリで発生するセッションを録画または保存する理由は数多くあります。LiveKitでは、エージェントセッションのビデオとオーディオを録画したり、テキストの書き起こしを保存したりすることができます。
ビデオまたはオーディオの録画
Egress機能を使用して、音声および/またはビデオを録画します。最も簡単な方法は、エージェントのエントリーポイントでroom composite recorderを開始することです。これにより、エージェントがルームに入室した時点で録画が開始され、ルームで共有されたすべての音声およびビデオが自動的にキャプチャされます。録画は、すべての参加者が退室した時点で終了します。録画は、選択したクラウドストレージプロバイダに保存されます。
例
この例では、Voice AI クイックスタートを変更してセッションを録画する方法を示します。この例では Google Cloud Storage を使用していますが、Amazon S3 互換のストレージプロバイダや Azure Blob Storage にファイルを保存することもできます。
Amazon S3 および Azure を使用するその他のEgressの例については、「egressの例」を参照してください。
credentials.jsonについての詳細は、「クラウドストレージの設定」を参照してください。Voice AI クイックスタートを変更してセッションを録画するには、次のコードを追加します。
from livekit import api async def entrypoint(ctx: JobContext): # 以下のコードを先頭に追加し、ctx.connect()を呼び出す前に実行 # credentials.jsonファイルからGCPの認証情報を読み込みます file_contents = "" with open("/path/to/credentials.json", "r") as f: file_contents = f.read() # 録音をセットアップ req = api.RoomCompositeEgressRequest( room_name="my-room", layout="speaker", audio_only=True, segment_outputs=[api.SegmentedFileOutput( filename_prefix="my-output", playlist_name="my-playlist.m3u8", live_playlist_name="my-live-playlist.m3u8", segment_duration=5, gcp=api.GCPUpload( credentials=file_contents, bucket="<your-gcp-bucket>", ), )], ) res = await ctx.api.egress.start_room_composite_egress(req) # .. エントリーポイントの残りのコードが続く ...テキストの書き起こし
テキストの書き起こしは、Pipelineノードのドキュメントで説明されているように、
llm_nodeまたはtranscription_node経由でリアルタイムで利用できます。他のイベントやコールバックと併用して、セッションや必要なその他のデータを記録することができます。さらに、いつでも
session.historyプロパティにアクセスして、これまでの会話の全履歴を取得することができます。add_shutdown_callbackメソッドを使用すると、ユーザーが退室し、ルームが閉じた後に会話履歴をファイルに保存することができます。例
この例では、会話履歴を JSON ファイルに保存するように、Voice AI クイックスタートを変更する方法を示します。
from datetime import datetime import json def entrypoint(ctx: JobContext): # 以下のコードを先頭に追加し、ctx.connect()を呼び出す前に実行 async def write_transcript(): current_date = datetime.now().strftime("%Y%m%d_%H%M%S") # この例では一時ディレクトリに書き込むが、任意の場所に保存できる filename = f"/tmp/transcript_{ctx.room.name}_{current_date}.json" with open(filename, 'w') as f: json.dump(session.history.to_dict(), f, indent=2) print(f"Transcript for {ctx.room.name} saved to {filename}") ctx.add_shutdown_callback(write_transcript) # .. The rest of your entrypoint code follows ...
Deployment & Operationsまで完了。デプロイはもちろんだけども、ログとかトレーシングなんかもまあ別に考えないといけない。
残りのドキュメントは、STT・LLM・TTS・Realtimeモデルの各ベンダーごとのドキュメントなので、まあ良いかな。
上でも書いたけど、あとはLiveKit側のドキュメントも参照しつつ、Recipeなどのデモやサンプルコードを確認すれば良さそう。
以降はメモで色々お試し