リアルタイムの音声・動画プラットフォーム「LiveKit」を試す
GitHubレポジトリ
LiveKit: 開発者のためのリアルタイムビデオ、オーディオ、データ
LiveKit は、WebRTCに基づくスケーラブルで複数ユーザーの会議を提供するオープンソースプロジェクトです。 アプリケーションにリアルタイムのビデオ、オーディオ、データ機能を構築するために必要なすべてを提供するよう設計されています。
LiveKitのサーバーはGoで書かれており、優れた Pion WebRTC 実装を使用しています。
特徴
- スケーラブルで分散型のWebRTC SFU(Selective Forwarding Unit)
- モダンでフル機能を備えたクライアントSDK
- 本番環境向けに構築され、JWT認証に対応
- 頑健なネットワーキングと接続性、UDP/TCP/TURN対応
- 簡単にデプロイ可能:単一バイナリ、DockerまたはKubernetes
- 以下を含む高度な機能:
- 話者検出
- サイマルキャスト
- エンドツーエンドの最適化
- 選択的サブスクリプション
- モデレーションAPI
- エンドツーエンド暗号化
- SVCコーデック(VP9、AV1)
- webhook
- 分散型およびマルチリージョン
ドキュメント & ガイド
ライブデモ
- LiveKit Meet (ソース)
- Spatial Audio (ソース)
- OBS Studioからのライブストリーミング (ソース)
- ChatGPTを使用したAI音声アシスタント (ソース)
エコシステム
- Agents: プログラム可能なバックエンド参加者を使用してリアルタイムのマルチモーダルAIアプリケーションを構築
- Egress: ルームの録画またはマルチストリームし、個別トラックをエクスポート
- Ingress: RTMP、WHIP、HLS、またはOBS Studioなどの外部ソースからストリームを取り込み
SDKs & ツール
クライアントSDK
クライアントSDKを使用すると、フロントエンドにインタラクティブで複数ユーザーの体験を組み込むことができます。
言語 リポジトリ 宣言型UI リンク JavaScript (TypeScript) client-sdk-js React ドキュメント | JS サンプル | React サンプル Swift (iOS / MacOS) client-sdk-swift Swift UI ドキュメント | サンプル Kotlin (Android) client-sdk-android Compose ドキュメント | サンプル | Compose サンプル Flutter (全プラットフォーム) client-sdk-flutter native ドキュメント | サンプル Unity WebGL client-sdk-unity-web ドキュメント React Native (β) client-sdk-react-native native Rust client-sdk-rust サーバーSDK
サーバーSDKを使用すると、バックエンドで アクセス・トークン を生成し、サーバーAPI を呼び出し、ウェブフック を受信できます。さらに、Go SDKにはクライアント機能が含まれており、エンドユーザーのように動作する自動化機能を構築できます。
言語 リポジトリ ドキュメント Go server-sdk-go ドキュメント JavaScript (TypeScript) server-sdk-js ドキュメント Ruby server-sdk-ruby Java (Kotlin) server-sdk-kotlin Python (コミュニティ) python-sdks PHP (コミュニティ) agence104/livekit-server-sdk-php ツール
- CLI - コマンドラインインターフェース&ロードテスター
- Dockerイメージ
- Helmチャート
デプロイ
LiveKit Cloudの利用
LiveKit Cloudは、LiveKitを実行するための最速かつ最も信頼性の高い方法です。すべてのプロジェクトは毎月無料の帯域幅とトランスコーディングクレジットを取得できます。
LiveKit Cloud にサインアップしてください。
セルフホスト
詳細については、デプロイメントのドキュメント をお読みください。
ライセンス
LiveKitサーバーはApache License v2.0の下でライセンスされています。
上記のレポジトリ・説明はLiveKit Serverのもので、READMEの一番下にあるように、エコシステム全体としてはいろいろある。
カテゴリ 内容 LiveKit SDK ブラウザ · iOS/macOS/visionOS · Android · Flutter · React Native · Rust · Node.js · Python · Unity · Unity (WebGL) サーバーAPI Node.js · Golang · Ruby · Java/Kotlin · Python · Rust · PHP (コミュニティ) · .NET (コミュニティ) UI コンポーネント React · Android Compose · SwiftUI エージェントフレームワーク Python · Node.js · Playground サービス LiveKit server · Egress · Ingress · SIP リソース ドキュメント · サンプルアプリ · Cloud · セルフホスティング · CLI
自分の理解だとこんな感じ。合ってるかは知らない。

冒頭のレポジトリはサーバ向けのもの。で、そこに接続する音声対話エージェントを作るにはエージェントフレームワークを使うって感じっぽい。
LiveKit Agents
JS/TSライブラリをお探しですか? AgentsJS をご覧ください
✨ NEW ✨
ビルトインのフレーズエンドポイントモデル
エージェントによる割り込みを削減し、音声エージェントとユーザ間の会話の流れを大幅に改善する会話ターン終了検出を実現する、新しいオープンウェイトのフレーズエンドポイントモデルを訓練しました。CPU上での実行に最適化されており、livekit-plugins-turn-detector パッケージ経由で利用可能です。
Agentsとは?
Agentsフレームワークは、リアルタイムで視覚、聴覚、発話が可能なAI駆動のサーバープログラムを構築するためのものです。完全にオープンソースのプラットフォームを提供し、リアルタイムでエージェントを活用したアプリケーションを作成することができます。
特徴
- 柔軟な統合: 各ユースケースに合わせて最適なモデルを組み合わせるための包括的なエコシステム。
- AI音声エージェント:
VoicePipelineAgentとMultimodalAgentが、LLMやその他のAIモデルを用いて会話の流れを調整します。- 統合されたジョブスケジューリング: 組み込みのタスクスケジューリングおよび分散処理と dispatch API により、エンドユーザーとエージェントを接続します。
- リアルタイムメディアトランスポート: クライアントSDKを通じて、WebRTCおよびSIP経由で音声、映像、データをストリーミングします。
- 電話統合: LiveKitのテレフォニースタックとシームレスに連携し、エージェントが電話の発信や受信を行えるようにします。
- クライアントとのデータ交換: RPCやその他のデータAPIを使用して、クライアントとシームレスにデータを交換できます。
- オープンソース: 完全にオープンソースであり、LiveKit server を含む全スタックを自社サーバー上で実行することが可能です。これは最も広く利用されているWebRTCメディアサーバーの一つです。
インテグレーション
このフレームワークには、ストリーミング入力の処理や出力生成を容易にするさまざまなプラグインが含まれています。たとえば、Text-to-Speechプラグインや、主要なLLMで推論を実行するプラグインがあります。
リアルタイムAPI
Agentsフレームワークでは、新しい
MultimodalAgentAPI をOpenAIと提携して提供しています。このクラスはOpenAIのリアルタイムAPIを完全にラップし、低レイテンシのWebRTCトランスポートを通じてGPT-4oとユーザーのデバイス間の通信を実現します。同じスタックがChatGPTアプリのAdvanced Voiceを支えています。LLM
プロバイダー パッケージ 使用方法 OpenAI livekit-plugins-openai openai.LLM() Azure OpenAI livekit-plugins-openai openai.LLM.with_azure() Anthropic livekit-plugins-anthropic anthropic.LLM() Google (Gemini) livekit-plugins-google google.LLM() AWS Bedrock livekit-plugins-aws aws.LLM() Cerebras livekit-plugins-openai openai.LLM.with_cerebras() DeepSeek livekit-plugins-openai openai.LLM.with_deepseek() Groq livekit-plugins-openai openai.LLM.with_groq() Ollama livekit-plugins-openai openai.LLM.with_ollama() Perplexity livekit-plugins-openai openai.LLM.with_perplexity() Together.ai livekit-plugins-openai openai.LLM.with_together() X.ai (Grok) livekit-plugins-openai openai.LLM.with_x_ai() STT
プロバイダー パッケージ ストリーミング 使用方法 Azure livekit-plugins-azure ✅ azure.STT() Deepgram livekit-plugins-deepgram ✅ deepgram.STT() OpenAI (Whisper) livekit-plugins-openai openai.STT() livekit-plugins-google ✅ google.STT() AssemblyAI livekit-plugins-assemblyai assemblyai.STT() Groq (Whisper) livekit-plugins-openai openai.STT.with_groq() FAL (Whisper) livekit-plugins-fal fal.STT() Speechmatics livekit-plugins-speechmatics ✅ speechmatics.STT() AWS Transcribe livekit-plugins-aws ✅ aws.STT() TTS
プロバイダー パッケージ ストリーミング 音声クローン 使用方法 Cartesia livekit-plugins-cartesia ✅ ✅ cartesia.TTS() ElevenLabs livekit-plugins-elevenlabs ✅ ✅ elevenlabs.TTS() OpenAI livekit-plugins-openai openai.TTS() Azure OpenAI livekit-plugins-openai openai.TTS.with_azure() livekit-plugins-google ✅ ✅ google.TTS() Deepgram livekit-plugins-deepgram ✅ deepgram.TTS() Play.ai livekit-plugins-playai ✅ ✅ playai.TTS() Rime livekit-plugins-rime ✅ rime.TTS() Neuphonic livekit-plugins-neuphonic ✅ ✅ neuphonic.TTS() AWS Polly livekit-plugins-aws ✅ aws.TTS() その他のプラグイン
プラグイン 説明 livekit-plugins-rag AnnoyベースのシンプルなRAG livekit-plugins-llama-index LlamaIndexを使用したRAG livekit-plugins-nltk テキスト処理用のユーティリティ livekit-plugins-silero 音声活動検出 livekit-plugins-turn-detector 会話のターン検出モデル ドキュメントとガイド
フレームワークの使用方法に関するドキュメントはこちらをご覧ください
サンプルエージェント
説明 デモリンク コードリンク STT、LLM、TTSのパイプラインを使用した基本的な音声エージェント デモ コード 新しいOpenAIリアルタイムAPIを使用した音声エージェント デモ コード CerebrasホストのLlama 3.1を使用した超高速音声エージェント デモ コード CartesiaのSonicモデルを使用した音声エージェント デモ コード 関数呼び出しで現在の天気を取得するエージェント N/A コード Gemini 2.0 Flashを使用した音声エージェント N/A コード カスタムターン検出モデルを使用した音声エージェント N/A コード RAGベースのルックアップを実行する音声エージェント N/A コード 最後の発話をそのまま返すシンプルなエージェント N/A コード RGBフレームのストリームを配信するビデオエージェント N/A コード ユーザーの音声からテキストキャプションを生成する文字起こしエージェント N/A コード テキストでチャット可能なエージェント。生成された音声で返答する N/A コード ローカルホストでのマルチエージェント会議通話 N/A コード Hiveを使用してスパム/不適切な映像を検出するモデレーションエージェント N/A コード
LiveKit Serverの説明にもある通り、LiveKitはクラウドとセルフホストがある。クラウドはどうやらChatGPTの音声モードで使われているようである。

クラウドの料金は以下。
| プラン | 月額料金 | 同時参加者数 | 接続時間 | 帯域 | 通話時間 | その他 |
|---|---|---|---|---|---|---|
| Build | $0 | 100 | 5000分 | 50GB | 1000分 | - Krispによるノイズキャンセリング -解析/インサイトの集計 - セッションとストリームのテレメトリ - コミュニティによるサポート |
| Ship | $50 | 1000 | 150000分 ※以降は$0.5/分 |
250GB ※以降は$0.12/GB |
8000分 ※以降は$0.004/分 |
- Buildの機能すべて - メールによるサポート |
| Scale | $500 | 無制限 | 1500000分 ※以降は$0.3/分 |
3TB ※以降は$0.1/GB |
45000分 ※以降は$0.003/分 |
- Shipの機能すべて - リージョン固定 - HIPAA対応 |
| Enterprise | カスタム | - | - | - | - | - すべてのリソースでボリュームディスカウント - 共有slackチャネル - SLAサポート - オンプレサポート |
とりあえずクラウドは無料でも始めれそう。
セルフホストはサーバを立てる必要がある
MacだとHomebrewで立てれる様子。
LiveKit Cloud + LiveKit Agent
とりあえずどんなものかを試すべく、まずはクラウドでアカウント作成して試してみる
アカウント作成ページを見ると、リージョンが表示されているが日本国内にもリージョンはある様子、あとはアジアだとシンガポール

アカウント作成・ログインした。Agent Guideをクリック。

この中のQuickstartsに「Voice agent with STT,LLM,TTS」があるのでこれを見てみる。なお、「Speech-to-speech agent」というのもあるが、これはRealtime APIを使うものみたい
Quickstartチュートリアルが表示される
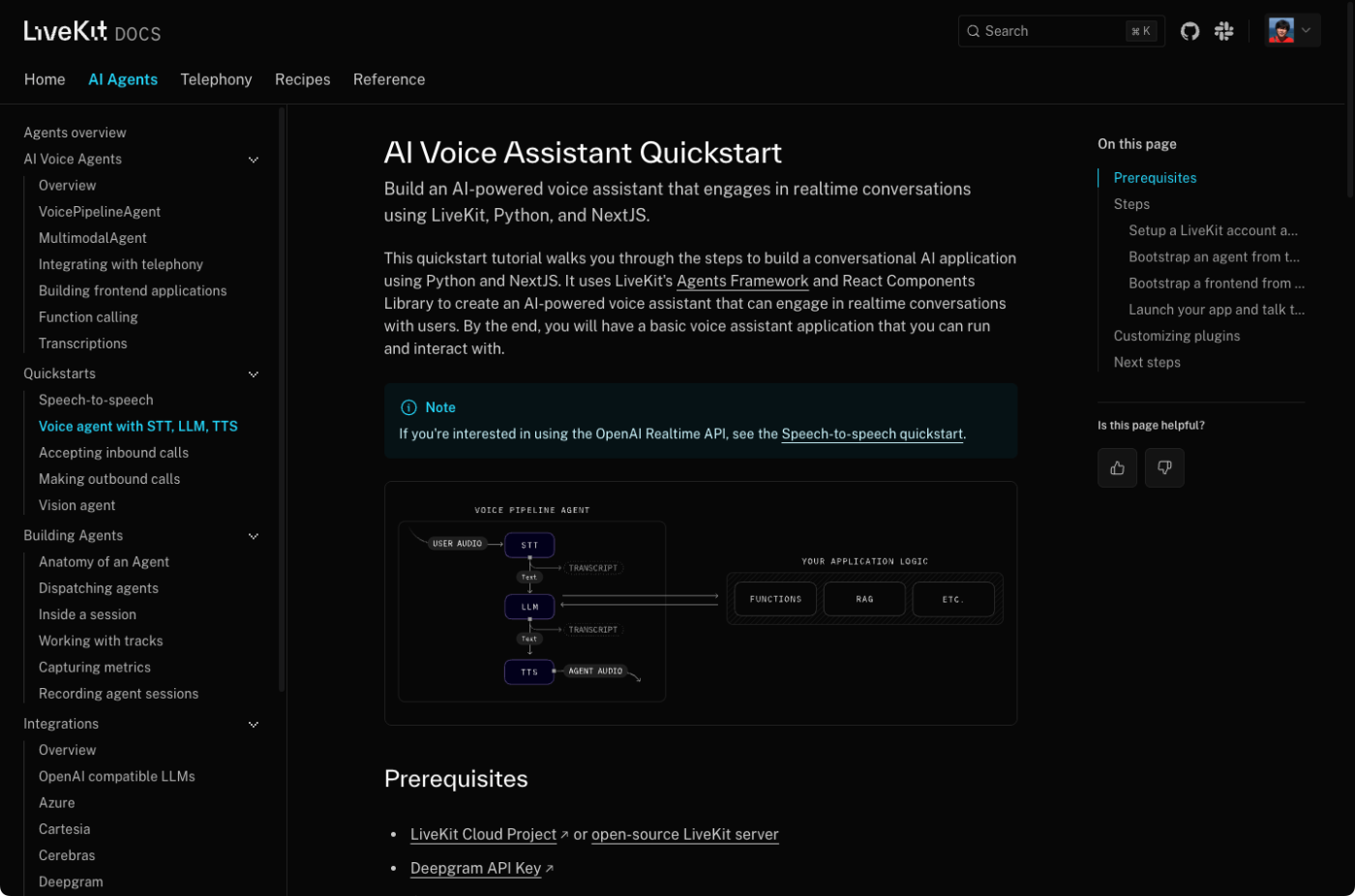
このクイックスタートチュートリアルでは、PythonとNextJSを使って会話型AIアプリケーションを構築する手順を説明します。このチュートリアルでは、LiveKitのAgent FrameworkとReact Components Libraryを使用して、ユーザーとリアルタイムで会話できるAI搭載の音声アシスタントを作成します。最後には、実行して対話できる基本的な音声アシスタントアプリケーションが完成します。
referred from https://docs.livekit.io/agents/quickstarts/voice-agent/

こういう感じでSTT・LLM・TTSのパイプラインを作成して、LiveKitを経由してやりとりができる音声対話エージェントが作れる。これならLLM部分は作り込みができそう。
必要なもの
- クラウドアカウント or セルフホスト
- Deepgram APIキー(STT)
- OpenAI APIキー(LLM、TTS)
- Python-3.9〜3.12
なのだが、自分は一旦全部OpenAIでやってみようと思う。ローカルのMacで。
まず、livekit-cliをインストール。MacならばHomebrewでインストールできる
brew install livekit-cli
brew info livekit-cli
==> livekit-cli: stable 2.3.1 (bottled), HEAD
Command-line interface to LiveKit
https://livekit.io
Installed
/opt/homebrew/Cellar/livekit-cli/2.3.1 (11 files, 45.8MB) *
Poured from bottle using the formulae.brew.sh API on 2025-01-20 at 12:13:16
From: https://github.com/Homebrew/homebrew-core/blob/HEAD/Formula/l/livekit-cli.rb
License: Apache-2.0
クラウドの認証を行う
lk cloud auth
対話形式なのかな?デバイス名を聞かれるので設定
┃ What is the name of this device?
┃ > macmini
URLが発行され、ブラウザが起動するので認証する
Device: macmini
Requesting verification token...
Please confirm access by visiting:
https://cloud.livekit.io/cli/confirm-auth?t=XXXXXX
⢿ Awaiting confirmation...
CLIから許可するProjectを指定


CLIの認証が許可され、Projectをデフォルトにするかを聞かれる。今回はデフォルトにしてみる。
┃ Make this project default? [Yes] No
設定は以下のように保存される
Saved CLI config to /Users/kun432/.livekit/cli-config.yaml
default_project: test
projects:
- name: test
url: wss://test-xxxxxx.livekit.cloud
api_key: xxxxxxxxxx
api_secret: xxxxxxxxxxx
作業ディレクトリを作成
mkdir livekit-agents-work && cd livekit-agents-work
テンプレートから音声エージェントアプリのProjectを作成する。
lk app create --template voice-pipeline-agent-python
対話形式になる。プロジェクトディレクトリを指定
┃ Application Name
┃ > my-app
デフォルトだとOpenAI APIキー・DeepgrapAPIキーをセットすることになるが、説明を見る限りは.env.localでいけそうなのでENTERで進める。
┃ Enter OPENAI_API_KEY?
┃ > <To use other providers, press Enter for now and edit .env.local>
┃ Enter DEEPGRAM_API_KEY?
┃ > <To use other providers, press Enter for now and edit .env.local>
Projectが作成される。プロジェクトディレクトリ内で仮想環境作る手順になってるようなので、上のように作業ディレクトリをわざわざ作る必要性はなさそう。
Cloning template...
Instantiating environment...
Cleaning up...
To setup and run the agent:
cd /Users/kun432/work/livekit-agents-work/my-app
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
python3 agent.py dev
指示にあわせて仮想環境を作成する。
cd my-app
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
APIキーをセットする。上で記載した通り、OpenAIだけで全部やるので、OpenAI APIキーだけ。
DEEPGRAM_API_KEY="<To use other providers, press Enter for now and edit .env.local>"
LIVEKIT_API_KEY="XXXXXXXXXX"
LIVEKIT_API_SECRET="XXXXXXXXXX"
LIVEKIT_URL="wss://test-XXXXXXXX.livekit.cloud"
OPENAI_API_KEY="XXXXXXXXXX"
agent.pyファイルをカスタマイズする。デフォルトだと以下となる。
import logging
from dotenv import load_dotenv
from livekit.agents import (
AutoSubscribe,
JobContext,
JobProcess,
WorkerOptions,
cli,
llm,
)
from livekit.agents.pipeline import VoicePipelineAgent
from livekit.plugins import openai, deepgram, silero
load_dotenv(dotenv_path=".env.local")
logger = logging.getLogger("voice-agent")
def prewarm(proc: JobProcess):
proc.userdata["vad"] = silero.VAD.load()
async def entrypoint(ctx: JobContext):
initial_ctx = llm.ChatContext().append(
role="system",
text=(
"You are a voice assistant created by LiveKit. Your interface with users will be voice. "
"You should use short and concise responses, and avoiding usage of unpronouncable punctuation. "
"You were created as a demo to showcase the capabilities of LiveKit's agents framework."
),
)
logger.info(f"connecting to room {ctx.room.name}")
await ctx.connect(auto_subscribe=AutoSubscribe.AUDIO_ONLY)
# Wait for the first participant to connect
participant = await ctx.wait_for_participant()
logger.info(f"starting voice assistant for participant {participant.identity}")
# This project is configured to use Deepgram STT, OpenAI LLM and TTS plugins
# Other great providers exist like Cartesia and ElevenLabs
# Learn more and pick the best one for your app:
# https://docs.livekit.io/agents/plugins
agent = VoicePipelineAgent(
vad=ctx.proc.userdata["vad"],
stt=deepgram.STT(),
llm=openai.LLM(model="gpt-4o-mini"),
tts=openai.TTS(),
chat_ctx=initial_ctx,
)
agent.start(ctx.room, participant)
# The agent should be polite and greet the user when it joins :)
await agent.say("Hey, how can I help you today?", allow_interruptions=True)
if __name__ == "__main__":
cli.run_app(
WorkerOptions(
entrypoint_fnc=entrypoint,
prewarm_fnc=prewarm,
),
)
以下を書き換える
システムプロンプトを日本語に変更
initial_ctx = llm.ChatContext().append(
role="system",
text=(
"あなたはLiveKit によって作成された音声アシスタントです。ユーザーとのインターフェースは音声になります。"
"あなたは、短い簡潔な応答を使用し、発音できない句読点の使用は避けるべきです。"
"あなたは、LiveKit のエージェントフレームワークの能力を紹介するデモとして作成されました。"
),
)
TTSもOpenAIに書き換える。
agent = VoicePipelineAgent(
vad=ctx.proc.userdata["vad"],
stt=openai.STT(),
llm=openai.LLM(model="gpt-4o-mini"),
tts=openai.TTS(),
chat_ctx=initial_ctx,
)
接続時≒ルームへの参加時にまず自動で挨拶させる
# エージェントは、ユーザーが参加した際に、礼儀正しく挨拶をするべきです。
await agent.say("こんにちは、今日はどのようなご要件ですか?", allow_interruptions=True)
これでagentを起動する。
python agent.py dev
2025-01-20 12:46:07,059 - DEBUG asyncio - Using selector: KqueueSelector
2025-01-20 12:46:07,062 - DEV livekit.agents - Watching /Users/kun432/work/livekit-agents-work/my-app
2025-01-20 12:46:07,554 - DEBUG asyncio - Using selector: KqueueSelector
2025-01-20 12:46:07,557 - INFO livekit.agents - starting worker {"version": "0.12.8", "rtc-version": "0.19.1"}
2025-01-20 12:46:08,264 - INFO livekit.agents - registered worker {"id": "AW_hkPbMWnMGp5C", "region": "Japan", "protocol": 15, "node_id": "NC_OTOKYO1B_p5THAfbv9dyd"}
次にフロントエンド。こちらはnode.jsアプリになっている。
別ターミナルを開いて作業ディレクトリに移動
cd livekit-agents-work
こちらもテンプレートから作成
lk app create --template voice-assistant-frontend
なるほど、アプリケーション名は変えて置くべきだったかも。今回はfrontendとする。
┃ Application Name
┃ > frontend
同じように作成される
Cloning template...
Instantiating environment...
Cleaning up...
To setup and run the frontend:
cd /Users/kun432/work/livekit-agents-work/frontend
pnpm install
pnpm dev
自分はnodejs環境がないのでmiseを使うことにした。
cd frontend
mise use node@22
npm install -g pnpm
pnpm install
pnpm dev
> voice-assistant2@0.1.0 dev /Users/kun432/work/livekit-agents-work/frontend
> next dev
▲ Next.js 14.2.23
- Local: http://localhost:3000
- Environments: .env.local
✓ Starting...
✓ Ready in 2.1s
ブラウザで開くとこんな画面になるので、START CONVERSATIONで。


動画
Realtime APIを使っていないので、それほどレスポンスが速いというわけではないが、VADが標準で動作して、割り込みなどができるということがわかる。
管理画面を見ると、エージェントとユーザの2名になっているのがわかる。

TTSをGoogleに書き換えてみたり。
from livekit.plugins import google
(snip)
agent = VoicePipelineAgent(
vad=ctx.proc.userdata["vad"],
#stt=openai.STT(),
stt=google.STT(languages="ja-JP"),
llm=openai.LLM(model="gpt-4o-mini"),
#tts=openai.TTS(),
tts=google.TTS(language="ja-JP", voice_name="ja-JP-Standard-A", speaking_rate=1.2),
chat_ctx=initial_ctx,
)
なるほど、音声対話エージェントのパイプラインが簡単に作れるのがわかる。
その他気になったこと。
- GoogleのTTSだとNeuralとかもあるのだが、それは使えなかった(エラーになる)
- STTで言語指定しないと全く認識できなかった。
LiveKitにおけるコンポーネント
LiveKitで重要そうな概念は以下にある3つ
- Room
- セッションを表すコンテナオブジェクト
- 同じルーム内の各参加者は、他の参加者の変更に関する最新情報を受け取る。
- 例:
- 参加者がトラックの追加、削除、または状態(ミュートなど)の変更を行うと、他の参加者にその変更が通知される
- 状態を同期させるための強力なメカニズム。リアルタイム体験を構築する上で不可欠。
- 例:
- ルームの作成
- サーバーAPI経由で手動作成 or 最初の参加者が参加した時点で自動作成
- ルームの削除
- 最後の参加者がルームを退出すると、しばらく遅延した後、ルームは閉じられる
- Paritipant
- セッションに参加する「ユーザ」
- 開発者が割り当てた「identity」とサーバが生成した「sid」で表される
- 上記以外に状態や発行したトラックを含むメタデータを持つ
- ルーム単位でユニークとなる(同じIDで同じルームに入ると前のセッションが切断される)
- SDKでは2つのオブジェクト
- LocalParticipant
- 現在のユーザ
- ルーム内でトラックを発行できる
- RemoteParitipantが発行したトラックをサブスクライブできる
- RemoteParitipant
- リモートのユーザ
- LocalParticipant
- ユーザは1対1 or 1対nでデータ交換を行う
- Participantsの種類
- STANDARD: 通常の参加者、一般的にはアプリケーションのエンドユーザ
- AGENT: Agents Frameworkで作成されたエージェント
- SIP: SIP経由で接続してきた電話ユーザ
- EGRESS: LiveKitEgreeを使用したサーバサイドプロセス、例えば、セッションの録音など
- INGRESS: LiveKitIngressを使用したサーバサイドプロセス、例えば、メディアの再生とか
- Track
- データのストリーム。音声・ビデオ・カスタムなデータなど。
- ルーム内の参加者はトラック、音声や動画のストリームを「publish」し、他の参加者はそれを「subscribe」する
- local participantsによってサブスクライブされない場合を想定して、すべてのトラックは該当するTrackPublicationオブジェクトを持つ
- Track: WebRTCネイティブなMediaStreamTrackをラップしたオブジェクト。生成できる。
- TrackPublication: サーバに対して発行されるトラック。トラックがlocal participantsによってサブスクライブされローカルで再生できるようになったら、Trackが紐づけられた.trackアトリビュートを持つ
- ここはちょっとピンとこないので一旦パス
- Trackのサブスクリプション
- 参加者がトラックをサブスクライブしたら(トラックをパブリッシュした参加者からみゅーとされていない限り)、データを継続的に受信することになる。参加者がサブスク解除すると、トラックのデータの受信が停止し、いつでも再開できる
- 参加者がルームを作成し参加したら、
autosubscribeオプションが自動で有効になる。これにより、参加者はすべての既存の発行済トラック・今後の発行予定トラックを自動でサブスクライブする。 - より細かいコントロールも可能。autoSubscribeを無効化して選択的サブスクリプションを有効化すれば良い
エージェントを含めるとこんな感じになると思う。

エージェントの拡張性
VoicePipelineAgentを使うと、使いたい各コンポーネントをそれぞれ並べたパイプラインを作るだけで音声対話エージェントが作成できる。
agent = VoicePipelineAgent(
vad=ctx.proc.userdata["vad"],
stt=deepgram.STT(),
llm=openai.LLM(model="gpt-4o-mini"),
tts=openai.TTS(),
chat_ctx=initial_ctx,
)
LiveKit Agentのレポジトリに説明があった通り、これらのコンポーネントは複数のプロバイダに対応しており、自由に組み合わせて対話エージェントを作ることができる。
また、VoicePipelineAgentには以下のようなオプションもある。
-
chat_ctx: 会話のコンテキストを管理する -
fnc_ctx: Function Callingで使用する関数を定義する
例えばFunction Calling
agent = VoicePipelineAgent(
vad=ctx.proc.userdata["vad"],
stt=deepgram.STT(),
llm=openai.LLM(),
tts=openai.TTS(),
fnc_ctx=fnc_ctx,
chat_ctx=initial_chat_ctx,
)
例えば以下はよくあるお天気検索関数の例。複数の関数を渡したい場合は@llm.ai_callable()デコレータを使って、メソッドを追加すれば良さそう。
class AssistantFnc(llm.FunctionContext):
"""
音声アシスタントが実行できるLLM関数のセットを定義する。
"""
@llm.ai_callable()
async def get_weather(
self,
location: Annotated[
str, llm.TypeInfo(description="天気を取得する場所")
],
):
"""ユーザーが天気について質問したときに呼び出され、指定された場所の天気情報を返す"""
# 場所の文字列から特殊文字を削除
location = re.sub(r"[^a-zA-Z0-9]+", " ", location).strip()
# Function Calling実行中の場合、ユーザーに対して時間がかかることを通知するためのオプションがいくつかある
# オプション1: Function Callingをトリガーした直後に.sayでフィラーメッセージを使用する
# オプション2: Function Calling中に、エージェントにテキスト応答を返すように指示する
agent = AgentCallContext.get_current().agent
if (
not agent.chat_ctx.messages
or agent.chat_ctx.messages[-1].role != "assistant"
):
# エージェントがすでに発話中の場合はスキップ
filler_messages = [
" {location} の天気を確認します。",
" {location} の天気がどうなっているかをすぐに確認します。",
# LLMにプリフィルでこの文章を補完させて、チャットコンテキストの最後に追加する
"{location} の現在の天気は、",
]
message = random.choice(filler_messages).format(location=location)
logger.info(f"フィラーメッセージを発話: {message}")
# NOTE: add_to_chat_ctx=True は、Function Callingのチャットコンテキストの末尾にメッセージを追加する
speech_handle = await agent.say(message, add_to_chat_ctx=True) # noqa: F841
logger.info(f"天気を確認: {location}")
url = f"https://wttr.in/{urllib.parse.quote(location)}?format=%C+%t"
weather_data = ""
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
if response.status == 200:
# Function Callingの結果はLLMに返される
weather_data = (
f"{location} の天気は {await response.text()}."
)
logger.info(f"天気データ: {weather_data}")
else:
raise Exception(
f"天気データを取得できませんでした, ステータスコード: {response.status}"
)
# (オプション) Function Callingの結果を返す前に音声が終了するまで待つ
# await speech_handle.join()
return weather_data
fnc_ctx = AssistantFnc()
# エージェントに関数コンテキストを渡す
pipeline_agent = VoicePipelineAgent(
...
fnc_ctx=fnc_ctx,
)
# マルチモーダルエージェントの場合も同じ
multimodal_agent = MultimodalAgent(
...
fnc_ctx=fnc_ctx,
)
また、各コンポーネントはプラグインとして実装されている、
よって必要なコンポーネントを自分で実装すればパイプラインに組み込むことができる。実際にLlamaIndexとのインテグレーションはプラグインになっており、シンプルなLLMプラグインをこれに置き換えることで、LlamaIndexでRAGを実装したりということができたりする様子。これならかなり拡張もしやすいそう。
(snip)
# LlamaIndexのRAGインデックスを使って、会話型エンジンを生成
chat_engine = index.as_chat_engine(chat_mode=ChatMode.CONTEXT)
assistant = VoicePipelineAgent(
vad=silero.VAD.load(),
stt=deepgram.STT(),
# LLMモジュールはLlamaIndexの会話型エンジンを使う
llm=llama_index.LLM(chat_engine=chat_engine),
tts=openai.TTS(),
chat_ctx=initial_ctx,
)
(snip)
エージェントのドキュメントは豊富だと思うので、いろいろ確認すると良い。
LiveKit Serverのセルフホスト
ということでセルフホスト
Linuxの場合はインストールスクリプトが用意されている。
curl -sSL https://get.livekit.io | bash
MacはHomebrewで用意されている。今回はMacで試してみる。
インストール。
brew install livekit
サーバを起動
livekit-server --dev --bind 0.0.0.0
--devは開発モード。開発モードの場合は、開発用のAPIキー、シークレットキーが出力されるので、これをエージェント側にセットすれば良い。
2025-01-20T16:10:09.708+0900 INFO livekit server/main.go:211 no keys provided, using placeholder keys {"API Key": "devkey", "API Secret": "secret"}
接続先ポートは7880番ポートになる。
2025-01-20T16:10:09.739+0900 INFO livekit service/server.go:258 starting LiveKit server {"portHttp": 7880, "nodeID": "ND_yubH4Y536aZG", "nodeIP": "192.168.XX.XX", "version": "1.8.3", "bindAddresses": ["0.0.0.0"], "rtc.portTCP": 7881, "rtc.portUDP": {"Start":7882,"End":0}}
Quickstartで試した際のbackend/frontendとの.env.localを書き換えてそれぞれ起動し直せば、クラウドのときと同じように使えることが確認できる。
LIVEKIT_API_KEY="devkey"
LIVEKIT_API_SECRET="secret"
LIVEKIT_URL="ws://127.0.0.1:7880"
なお、セルフホストとクラウドの違いは以下
LiveKitの実装を構築する際には、オープンソースのLiveKitサーバーをセルフホストするか、マネージドLiveKit Cloudサービスを利用することができます。以下に、両者を比較した表を示します。
抜粋
| オープンソース | クラウド | |
|---|---|---|
| Architecture | Single-home SFU | Mesh SFU |
| Connection model | Users in the same room connect to the same server | Each user connects to the closest server |
| Max users per room | Up to ~3,000 | No limit |
| Analytics & telemetry | Cloud dashboard |
コンポーネントのところで、ルームは会話におけるバウンダリーだというふうに自分は認識したのだけど、同じ部屋でいい場合もあれば、別々の部屋に分けたい場合もある。その点からすると セルフホストの場合に "Users in the same room" ってのはちょっと気になる。
気になったので実際に複数クライアントを接続してみたが、同じ部屋に配置される(同じ部屋で会話が共有される)ということにはならなかった。このあたりはちょっとよくわからない。
まとめ
基本的には以前ためしたDaily.co+Pipecatと同じようなもの。
LiveKitとDaily.co、どちらも音声チャットやビデオ会議をターゲットにしたWebRTCプラットフォームサービスで、そこにLLMと組み合わせたエージェントフレームワークがあるってのも同じ。まあ今はそれだけニーズが高いってことなんだろう。
様々なプロバイダを取捨選択できて、VADなども用意されている、WebRTCを使うことで会話中の割り込みもできるということで、音声対話エージェントを作る場合の1つのパターンなのだろうと思う。フレームワークとしても非常にシンプルでわかりやすいし、拡張性もそれなりにありそう。とはいえ、リアルタイムな人間の会話にはまだ遠いかなと言うところはある。
あと、LiveKitの場合はセルフホストのためのサーバも用意されてはいるけど、これを自社で構築・運用するにはノウハウが必要そうな気がする。業務や商用サービスとして使うにはやはりWebRTCの知識は必要になると思う。ユースケースによってはクラウド使うほうが手っ取り早くていいんじゃないかなと言う気もする。
UI不要・CLIで起動してマイクとスピーカーで対話したい、と思って、ローカルのLiveKitサーバにエージェント繋いで、Pythonでクライアント書いてみたけど、どうもスピーカーの音が取れない、、、マイクは何とか動いてるようには見えるのだが、、、
Python SDKのサンプル、イマイチ使えそうなものが見当たらないなぁ、、、
→結局自分で書いた。
Agents v1.0
Agents が v1.0になった!

公式記事。気になったところだけ抜粋。
LiveKit Agents 1.0のご紹介
Agents 1.0 は、開発者が高品質な音声駆動型 AI アプリケーションを構築するために必要なすべてを提供するための、私たちの旅における重要なマイルストーンです。 パイプライン ノード、同期キャプション、およびクライアント エージェント RPC のような多くの新機能に加え、いくつかの大きなアップデートがあります。
ワークフロー
音声エージェントを開発している何百人もの開発者と話した結果、2つの大まかなクラスがあることがわかりました: open-ended と closed loop エージェントです。
自由形式の音声エージェントとの会話は、蛇行することができ、順不同で幅広いトピックをカバーすることができます。 エージェントが必要とするのは、関数呼び出しやRAGのような基本的なツールだけです。 例えば、ChatGPT Advanced Voice Mode (AVM)やキャラクターボイス、没入型言語学習のSpeak、デートアドバイスのTinderなどです。
クローズドループの音声エージェントは、動作が異なります。このタイプのエージェントは、決定論的なビジネスプロセスにおけるIVRシステムまたは人間のオペレータを置き換えることを主な対象としています。決定論的なビジネスプロセスの80%は、カスタマーサポート、病院での患者の受け入れ、債権回収、ローンの資格認定、出荷計画などのように、電話でアクセスされます。 ワークフローの前に、クローズドループエージェントを実装する開発者は、関数ツールと組み合わせた長い LLM システムプロンプトでビジネスプロセスを記述しようとするかもしれません。 残念ながら、これはうまくいきません。 LLMは確率的なコンピュータであり、マルチステップのワークフローを確実に実行することは(まだ)できません。
LiveKit Agents 1.0 は、クローズドループ音声エージェントの構築をより簡単にします。 開発者は、複雑なシステム プロンプトを個別のサブタスクに分割するマルチ エージェント ワークフローを編成できます。
多言語セマンティックターン検出
数ヶ月前、私たちは音声AIで最も難しい問題の1つであるターン検出の精度を向上させるために社内でトレーニングした、初のオープンソースモデルを導入しました。 このモデルは書き言葉の英語に対してのみトレーニングされていたため、英語での会話に対してのみターン終了予測を行うことができました。
本日、私たちは多言語機能を備えた、より大規模なセマンティックターン検出モデルをリリースします。 このモデルはCPU上で100トークンの文脈に対して25ms以下で推論を実行し、13の言語をサポートする: 中国語、オランダ語、英語、フランス語、ドイツ語、インドネシア語、イタリア語、日本語、韓国語、ポルトガル語、ロシア語、スペイン語、トルコ語です。 エンドユーザーやエージェントが1つの会話で複数の言語を切り替えるような、言語が混在した会話にも使用できます。
Cloud Agent
あなたがこれを読んでいるまさにその瞬間にも、LiveKitクラウド上で何十万もの音声エージェントが動作し、世界中のエンドユーザーと会話をしています。 そのレベルのスケールをサポートするためには、ステートレスWebアプリケーションに使用されるアプローチからの脱却が必要です。
音声エージェントは、ステートフルであり、GPU 上で推論を同時に実行しながら、常にあなたの話を聞き、あなたの考えを表現し終わったか、中断すべきかどうかを判断します。 会話の長さは不規則で、ほとんどの人間と同じように、音声エージェントは一度に複数の会話をすることはできません。
エージェントのライフサイクルを管理することは、ロケーションを意識した弾力的なプロビジョニング、ロードバランシング、ヘルスチェック、透過的なフェイルオーバー、コンテキストのマイグレーションなど、効率的に行うには困難が伴います。 Agentフレームワークを立ち上げて以来、開発者からエージェントのデプロイとスケーリングをすぐに扱えるソリューションが欲しいという要望がありました。
本日、エージェントのデプロイとスケーリングのためのソリューションのクローズドベータを開始します: LiveKit Cloud Agents です。 VercelはNextJSにとって、LiveKitのAgentフレームワークにとってのCloud Agentsです。 私たちはあなたのエージェントコードを安全なコンテナでホストし、世界中のデータセンターのLiveKit Cloudのネットワークにデプロイし、あなたのためにプロビジョニング、ロードバランシング、ロギング、バージョニング、ロールバックなど、開発ライフサイクル全体を管理します。 私たちは、所有する エージェントのために社内で Cloud Agent をドッグフーディングしており、本番ロールアウト プロセスを大幅に加速することがわかりました。 私たちは、あなたがこれを試し、フィードバックを聞くのを待ちきれません。
Cloud Agentsクローズベータへの参加をご希望の方は、こちらのフォームにご記入ください。
マルチリンガルなターン検出モデルってのが熱い!
ただ、どうやらv1.0でしか使えなさそう?な雰囲気があるので、あらためてv1.0を試す。
Voice AI quickstart v1.0
ドキュメントも変わってる。ここでバージョンを切り替える。

v1.0のVoice AI quickstartを改めて。今回もMacで。
とりあえずHomebrewでインストールしたLiveKitサーバとLiveKit CLIをアップグレードしておく。LiveKit CLIはどうやらもう不要みたいだけど一応(元々LiveKit Cloud用な雰囲気がある)。
brew upgrade livekit livekit-cli
livekit-server -version
livekit-server version 1.8.4
lk --version
lk version 2.4.5
uvでプロジェクトを作成
uv init -p 3.12.9 livekit-1.0-work && cd livekit-1.0-work
パッケージインストール。とりあえず全部OpenAIでやる。
uv add "livekit-agents[openai,silero,turn-detector]~=1.0" \
"livekit-plugins-noise-cancellation~=0.2" \
"python-dotenv"
(snip)
+ livekit==1.0.5
+ livekit-agents==1.0.11
+ livekit-api==1.0.2
+ livekit-plugins-noise-cancellation==0.2.1
+ livekit-plugins-openai==1.0.11
+ livekit-plugins-silero==1.0.11
+ livekit-plugins-turn-detector==1.0.11
+ livekit-protocol==1.0.1
(snip)
+ onnxruntime==1.21.0
(snip)
onnxruntime==1.21.0はSegmentation Faultが起きるバグがある。たぶん次のリリースで修正されたものが出るはず(mainは修正済みになっていた)のだが、現時点では一旦v1.20.1に戻す。
uv add "onnxruntime==1.20.1"
- onnxruntime==1.21.0
+ onnxruntime==1.20.1
.envを作成。LiveKitサーバのAPIキーなどはdevモードのものを使用する。
OPENAI_API_KEY=XXXXXXXXXX
LIVEKIT_API_KEY="devkey"
LIVEKIT_API_SECRET="secret"
LIVEKIT_URL="ws://127.0.0.1:7880"
ではエージェントのスクリプト。ここが以前とは変わっている。
from dotenv import load_dotenv
from livekit import agents
from livekit.agents import AgentSession, Agent, RoomInputOptions
from livekit.plugins import (
openai,
noise_cancellation,
silero,
)
from livekit.plugins.turn_detector.multilingual import MultilingualModel
load_dotenv()
class Assistant(Agent):
def __init__(self) -> None:
super().__init__(instructions="あなたは親切な日本語のAI音声アシスタントです。")
async def entrypoint(ctx: agents.JobContext):
await ctx.connect()
session = AgentSession(
stt=openai.STT(model="whisper-1", language="ja"),
llm=openai.LLM(model="gpt-4o-mini"),
tts=openai.TTS(model="tts-1", voice="coral"),
vad=silero.VAD.load(),
turn_detection=MultilingualModel(),
)
await session.start(
room=ctx.room,
agent=Assistant(),
# ノイズキャンセルはLiveKitCloudを使用する場合のみ
#room_input_options=RoomInputOptions(
# noise_cancellation=noise_cancellation.BVC(),
#),
)
await session.generate_reply(
instructions="ユーザーに挨拶し、支援を申し出てください。"
)
if __name__ == "__main__":
agents.cli.run_app(agents.WorkerOptions(entrypoint_fnc=entrypoint))
SireloVADやターン検出に使用しているモデルをダウンロードする。
uv run main.py download-files
2025-04-11 23:35:12,485 - INFO livekit.agents - Downloading files for <livekit.plugins.openai.OpenAIPlugin object at 0x112e9a390>
2025-04-11 23:35:12,485 - INFO livekit.agents - Finished downloading files for <livekit.plugins.openai.OpenAIPlugin object at 0x112e9a390>
2025-04-11 23:35:12,485 - INFO livekit.agents - Downloading files for <livekit.plugins.silero.SileroPlugin object at 0x113dccf50>
2025-04-11 23:35:12,485 - INFO livekit.agents - Finished downloading files for <livekit.plugins.silero.SileroPlugin object at 0x113dccf50>
2025-04-11 23:35:12,486 - INFO livekit.agents - Downloading files for <livekit.plugins.turn_detector.EOUPlugin object at 0x114b2d3a0>
None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.
2025-04-11 23:35:15,476 - DEBUG urllib3.connectionpool - Starting new HTTPS connection (1): huggingface.co:443
2025-04-11 23:35:15,979 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v1.2.2-en/tokenizer_config.json HTTP/1.1" 200 0
2025-04-11 23:35:16,462 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v1.2.2-en/onnx/model_q8.onnx HTTP/1.1" 302 0
2025-04-11 23:35:16,647 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v1.2.2-en/languages.json HTTP/1.1" 200 0
2025-04-11 23:35:17,147 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v0.1.0-intl/tokenizer_config.json HTTP/1.1" 200 0
2025-04-11 23:35:17,627 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v0.1.0-intl/onnx/model_q8.onnx HTTP/1.1" 302 0
2025-04-11 23:35:17,814 - DEBUG urllib3.connectionpool - https://huggingface.co:443 "HEAD /livekit/turn-detector/resolve/v0.1.0-intl/languages.json HTTP/1.1" 200 0
2025-04-11 23:35:17,817 - INFO livekit.agents - Finished downloading files for <livekit.plugins.turn_detector.EOUPlugin object at 0x114b2d3a0>
PyTorch・Tensorflow・Flaxのどれかが必要ってことかな?とりあえずPyTorchを入れる。
uv add torch
+ torch==2.6.0
では起動。CLIでのテストだけならサーバは要らなくなった様子。
uv run main.py console
ターミナルで音声でやり取りできる。ターン検出モデルいい感じに動いてるせいか、リアルタイムモデル使ってないはずなのに、そこそこ良いレスポンスだし、割り込みもできて前よりもかなり良くなっている気がする。
