音声・マルチモーダル対話型エージェントを構築するフレームワーク「Pipecat」を試す
GitHubレポジトリ
Pipecat
Pipecatは、音声およびマルチモーダル対話型エージェントを構築するためのオープンソースのPythonフレームワークです。AIサービス、ネットワーク通信、音声処理、マルチモーダルインタラクションの複雑なオーケストレーションを処理し、魅力的な体験を作成することに専念できるようにします。
作成できるもの
- 音声アシスタント: AIによる自然なリアルタイム会話
- インタラクティブエージェント: パーソナルコーチや会議アシスタント
- マルチモーダルアプリ: 音声、ビデオ、画像、テキストを組み合わせたアプリ
- クリエイティブツール: ストーリーテリング体験やソーシャルコンパニオン
- ビジネスソリューション: 顧客対応フローやサポートボット
- 複雑な会話フロー: Pipecat Flowsを参照して詳細を学んでください
実際の動作を確認する
主な特徴
- 音声優先設計: 音声認識、音声合成(TTS)、会話処理のビルトイン機能
- 柔軟な統合: OpenAIやElevenLabsなどの人気AIサービスと連携可能
- パイプラインアーキテクチャ: シンプルで再利用可能なコンポーネントから複雑なアプリを構築
- リアルタイム処理: フレームベースのパイプラインアーキテクチャによるスムーズなインタラクション
- プロダクション対応: エンタープライズ向けのWebRTCおよびWebsocketサポート
💡 構造化された会話を構築したいですか?Pipecat Flowsをチェックして、複雑な会話の状態管理や遷移について学びましょう。
プロダクションでのWebRTC使用
WebSocketsは、サーバー間通信や初期開発には適しています。しかし、プロダクションでクライアントとサーバー間のオーディオ通信を行う場合、リアルタイムメディア伝送用に設計されたプロトコルが必要です。(WebSocketsとWebRTCの違いについては、こちらの記事をご覧ください。)
WebRTCをすばやく利用開始する方法の1つは、Daily開発者アカウントに登録することです。Dailyは、オーディオ(およびビデオ)ルーティングのためのSDKとグローバルインフラを提供します。すべてのアカウントには、毎月10,000分の音声/ビデオ/文字起こし利用が無料で付与されます。
READMEからは、OpenAIのRealtime APIみたいなものを作るフレームワークといった印象を受ける。
インストールとセットアップ
Pipecatはローカルでも使えるようだが、上に書いてあるとおり商用利用の場合はdaily.coのプラットフォームを使うのが推奨されている。
とりあえずできることを確かめる意味でもdaily.coのアカウント作ってやってみようと思う。
で、ここがちょっとややこしいと自分は感じたのだが、「SIGN UP」をクリックすると2つ表示される。

Dailyには2つのサービスがある
- Daily Bots
Daily Botsを利用することで、開発者は自社アプリケーションに音声およびビデオエージェントを迅速に統合することができます。オープンソースのSDKで構築され、デイリーのリアルタイムグローバルインフラストラクチャ上に展開された開発者は、以下のことが可能です:
- Daily Video
DailyはWebRTCをベースとした開発者向けプラットフォームで、開発者はブラウザ上でリアルタイムのビデオ通話や音声通話を構築することができます。異なるプラットフォームにおける一般的なビデオ通話のユースケースに関する難しい問題はすべて、適切なデフォルト設定で対応いたします。
これだけ見るとDaily Botsでいいのかなーと思うのだけど、実際にDaily Botsにサインアップしてみると、WebRTCプラットフォームで一般的な「ルーム」を作成する画面がどこにもない。ドキュメントをちゃんと見ればDaily Videoが前提になっているらしいことはわかるんだけどね・・・あと、この2つのサービス、どうもアカウントや料金は別々に管理されているような雰囲気で、わかりにくい・・・
で、Daily Videoの料金はこちら
- 毎月10000時間の無料時間が付与される
- ビデオ・音声通話、音声通話、ストリーミング、録画、文字起こし等でそれぞれ使用量に応じて従量課金
- 一定利用でボリュームディスカウントが自動適用される
- Daily Botsとは別料金になる様子
- サポートやアドオンは月額の別料金
細かい金額は公式を確認するとして、とりあえずは無料枠もあるようなので一旦進めてみる。
で、Get Startedで必要なのは以下となる
- Dailyアカウント
- Cartesia APIキー(TTSで使用)
- OpenAI APIキー(LLMで使用)
になるので、Dailyアカウントを作成する。以下URLにアクセス。
サインアップするか、Googleアカウントでログイン

アカウントの初期設定。以下を行う。
- 確認メールの検証
- 自分用のサブドメインを作成
- ビデオ通話のテスト
- 準備完了

設定が終わればダッシュボードが表示される

ルームを作成する

設定項目が非常に多いが、お試しだし一旦はデフォルトで良さそう。ルーム名を適当に入力、あと言語だけ日本語に変更して作成した。(言語はビデオ通話時のUIの言語っぽいので自分の用途的には使わないと思う)実際にはもう少し細かく設定したほうがいいのではないかと思う。


これでルームが作成され、ルームにアクセスする場合は http://[サブドメイン].daily.co/[ルーム名]でアクセスできる。
次にAPIキー。左のDevelopersをクリックするとすでにAPIキーが作成されているのがわかる。

これでDailyの準備は完了。あと、OpenAI、CartesiaのAPIキーも適宜準備しておく。あと、CartesiaのほうはVoice IDも必要になる。少し前にCartesia試した記事。
ではローカルのMacでサンプルコードを動かしてみる。
まず、作業ディレクトリを作成して仮想環境を作成。自分はmiseを使うが、適宜。
mkdir pipecat-work && cd pipecat-work
mise use python@3.12
cat << 'EOS' >> .mise.toml
[env]
_.python.venv = { path = ".venv", create = true }
EOS
パッケージインストール。extraでいろいろ選択できる。今回は必要なものだけ。
pip install "pipecat-ai[daily,cartesia,openai]"
pip freeze | grep -i pipecat
pipecat-ai==0.0.53
.envファイルを作成してAPIキー等を記載する。OpenAI使ってないけど・・・
DAILY_SAMPLE_ROOM_URL=https://[サブドメイン].daily.co/[ルーム名]
DAILY_API_KEY=XXXXXXXXXX
CARTESIA_API_KEY=XXXXXXXXXX
CARTESIA_VOICE_ID="2b568345-1d48-4047-b25f-7baccf842eb0" # 日本語・女性・会話スタイル
サンプルコードは以下。少し日本語に置き換えた。
#
# Copyright (c) 2024–2025, Daily
#
# SPDX-License-Identifier: BSD 2-Clause License
#
import asyncio
import os
import sys
import aiohttp
from dotenv import load_dotenv
from loguru import logger
from runner import configure
from pipecat.frames.frames import EndFrame, TTSSpeakFrame
from pipecat.pipeline.pipeline import Pipeline
from pipecat.pipeline.runner import PipelineRunner
from pipecat.pipeline.task import PipelineTask
from pipecat.services.cartesia import CartesiaTTSService, CartesiaHttpTTSService
from pipecat.transports.services.daily import DailyParams, DailyTransport
from pipecat.transcriptions.language import Language
load_dotenv(override=True)
logger.remove(0)
logger.add(sys.stderr, level="DEBUG")
async def main():
async with aiohttp.ClientSession() as session:
(room_url, _) = await configure(session)
# WebRTC通信のためのDailyトランスポートを設定します
# - room_url: 接続先ルームURL
# - None: 認証トークンは不要
# - "テストボット": ボットの表示名
# - TTS再生のために音声出力を有効にする
transport = DailyTransport(
room_url,
None,
"テストボット",
DailyParams(audio_out_enabled=True)
)
# Cartesiaのテキスト読み上げサービスを初期化
# 事前に選択された日本語の女性の声を使用
# 他の声は以下で確認できる: https://play.cartesia.ai/voices
# 訳注1:
# 元のサンプルコードでは、CartesiaTTSServiceが使用されており、これはリアルタイム処理のためだが、
# その場合、モデルと言語がタイムスタンプに対応している必要がある。Cartesiaの日本語モデルはタイムスタンプに
# 対応していないため、エラーとなる。そこで非リアルタイムなCartesiaHttpTTSServiceを使用する。
# 参考: https://docs.cartesia.ai/api-reference/tts/compare-tts-endpoints#if-you-want-to-generate-speech-in-real-time
# 参考: https://github.com/pipecat-ai/pipecat/issues/513
# 訳注2:
# なお、Cartesiaの日本語対応モデルは、Websocketや入力ストリーミングに対応しているので
# それらを使ってリアルタイムに近い高速TTSレスポンスを生成することは可能。
# 例えばOpenAI Chat CompletionのストリーミングをそのままCartesiaに投げて高速音声チャットボットができたりする。
# ここでそれができないのはPipecatでのリアルタイム処理はタイムスタンプ機能が前提となっているからだと思う。
tts = CartesiaHttpTTSService(
api_key=os.getenv("CARTESIA_API_KEY"),
voice_id=os.getenv("CARTESIA_VOICE_ID"),
model="sonic",
params=CartesiaHttpTTSService.InputParams(
language=Language.JA,
)
)
# パイプラインを管理するためのパイプラインランナーを作成
runner = PipelineRunner()
# テキストを音声に変換し再生するためのパイプラインを作成
# 1. tts: テキストメッセージを音声に変換し
# 2. transport.output(): 音声をDailyルームに送信
task = PipelineTask(Pipeline([tts, transport.output()]))
# 最初の参加者がルームに参加したとき:
# - 参加者情報からユーザー名を抽出
# - 挨拶メッセージを生成
# - TTS変換のためにキューに追加
# - ボットが退出するためのEndFrameをキューに追加(パイプラインをシャットダウンする)
@transport.event_handler("on_first_participant_joined")
async def on_first_participant_joined(transport, participant):
participant_name = participant.get("info", {}).get("userName", "")
await task.queue_frames(
[TTSSpeakFrame(f"{participant_name} さん、こんにちは!ようこそお越しくださいました。"), EndFrame()]
)
# パイプラインタスクを実行
await runner.run(task)
if __name__ == "__main__":
asyncio.run(main())
あと、これには以下も必要
#
# Copyright (c) 2024–2025, Daily
#
# SPDX-License-Identifier: BSD 2-Clause License
#
import argparse
import os
import aiohttp
from pipecat.transports.services.helpers.daily_rest import DailyRESTHelper
async def configure(aiohttp_session: aiohttp.ClientSession):
(url, token, _) = await configure_with_args(aiohttp_session)
return (url, token)
async def configure_with_args(
aiohttp_session: aiohttp.ClientSession, parser: argparse.ArgumentParser | None = None
):
if not parser:
parser = argparse.ArgumentParser(description="Daily AI SDK Bot Sample")
parser.add_argument(
"-u", "--url", type=str, required=False, help="URL of the Daily room to join"
)
parser.add_argument(
"-k",
"--apikey",
type=str,
required=False,
help="Daily API Key (needed to create an owner token for the room)",
)
args, unknown = parser.parse_known_args()
url = args.url or os.getenv("DAILY_SAMPLE_ROOM_URL")
key = args.apikey or os.getenv("DAILY_API_KEY")
if not url:
raise Exception(
"No Daily room specified. use the -u/--url option from the command line, or set DAILY_SAMPLE_ROOM_URL in your environment to specify a Daily room URL."
)
if not key:
raise Exception(
"No Daily API key specified. use the -k/--apikey option from the command line, or set DAILY_API_KEY in your environment to specify a Daily API key, available from https://dashboard.daily.co/developers."
)
daily_rest_helper = DailyRESTHelper(
daily_api_key=key,
daily_api_url=os.getenv("DAILY_API_URL", "https://api.daily.co/v1"),
aiohttp_session=aiohttp_session,
)
# Create a meeting token for the given room with an expiration 1 hour in
# the future.
expiry_time: float = 60 * 60
token = await daily_rest_helper.get_token(url, expiry_time)
return (url, token, args)
では、ブラウザを開いてルームのURL(https://[サブドメイン].daily.co/[ルーム名])にアクセスする。
マイクとカメラを許可する

ルームに入る

ルームに入った

この状態で、先ほどのスクリプトを実行する。
python 01-say-one-thing.py
ボットが入ってきて 「kun432さん、こんにちは!ようこそお越しくださいました。」 というふうに音声が発話されるのがわかる。

もう少し実践的なサンプルコードが欲しいということで、レポジトリ内を見てみると、サンプルコードが多数ある
基本的な使い方の比較的短いサンプル。数がめちゃめちゃある割に説明がないので、中身を見ないとわからん。。。
ユースケースごとにフロントエンド・バックエンドが用意されたアプリケーションサンプルっぽい。
とりあえずこれが良さそう。
日本語で動かせるように一部修正してみた。
#
# Copyright (c) 2024–2025, Daily
#
# SPDX-License-Identifier: BSD 2-Clause License
#
import asyncio
import os
import sys
import aiohttp
from dotenv import load_dotenv
from loguru import logger
from runner import configure
from pipecat.audio.vad.silero import SileroVADAnalyzer
from pipecat.frames.frames import EndFrame
from pipecat.pipeline.pipeline import Pipeline
from pipecat.pipeline.runner import PipelineRunner
from pipecat.pipeline.task import PipelineParams, PipelineTask
from pipecat.processors.aggregators.openai_llm_context import OpenAILLMContext
from pipecat.services.openai import OpenAILLMService, OpenAITTSService
from pipecat.transports.services.daily import DailyParams, DailyTransport, DailyTranscriptionSettings
load_dotenv(override=True)
logger.remove(0)
logger.add(sys.stderr, level="DEBUG")
SYSTEM_PROMPT = """\
あなたは親切なアシスタントで、あなたの仕事はユーザとWebRTC上で音声通話を行うことです。
あなたの回答は音声に変換されるので、回答に特殊文字を含めないでください。
ユーザーの発言に対して、創造的かつ有益な応答をしてください。
"""
async def main():
async with aiohttp.ClientSession() as session:
(room_url, token) = await configure(session)
transport = DailyTransport(
room_url,
token,
"Respond bot",
DailyParams(
audio_out_enabled=True,
transcription_enabled=True, # Dailyではデフォルトで文字起こしを提供していて
transcription_settings=DailyTranscriptionSettings(language="ja"), # 中身はDeepgramのAPIを使用している様子
vad_enabled=True, # VADを有効にする
vad_analyzer=SileroVADAnalyzer(), # Silero VADを使用する
),
)
tts = OpenAITTSService(api_key=os.getenv("OPENAI_API_KEY"), voice="alloy")
llm = OpenAILLMService(api_key=os.getenv("OPENAI_API_KEY"), model="gpt-4o-mini")
messages = [
{
"role": "system",
"content": SYSTEM_PROMPT,
},
]
context = OpenAILLMContext(messages)
context_aggregator = llm.create_context_aggregator(context)
pipeline = Pipeline(
[
transport.input(), # ユーザの入力を(Daily.co経由で)受信
context_aggregator.user(), # ユーザの入力をコンテキストに追加
llm, # LLMを呼び出し
tts, # TTSを呼び出し
transport.output(), # ボットの応答を(Daily.co経由で)送信
context_aggregator.assistant(), # ボットの応答をコンテキストに追加
]
)
task = PipelineTask(
pipeline,
PipelineParams(
allow_interruptions=True,
enable_metrics=True,
enable_usage_metrics=True,
report_only_initial_ttfb=True,
),
)
@transport.event_handler("on_first_participant_joined")
async def on_first_participant_joined(transport, participant):
await transport.capture_participant_transcription(participant["id"])
# 会話の開始時に自己紹介させる
messages.append({"role": "system", "content": "最初にユーザに自己紹介してください。"})
await task.queue_frames([context_aggregator.user().get_context_frame()])
@transport.event_handler("on_participant_left")
async def on_participant_left(transport, participant, reason):
await task.queue_frame(EndFrame())
runner = PipelineRunner()
await runner.run(task)
if __name__ == "__main__":
asyncio.run(main())
Daily.coを使う場合は、STTにDaily.coが提供しているものを使用できるみたい。
(snip)
transcription_enabled=True, # Dailyではデフォルトで文字起こしを提供していて
transcription_settings=DailyTranscriptionSettings(language="ja"), # 中身はDeepgramのAPIを使用している様子
(snip)
ログを見てるとこんなログが出てるのでDeepgramだと思われる。nova-2-generalはDeepgramのドキュメントを見る限りは日本語にも対応している様子。
2025-01-28 13:01:39.650 | INFO | pipecat.transports.services.daily:_start_transcription:363 - Enabling transcription with settings language='ja' tier=None model='nova-2-general' profanity_filter=True redact=False endpointing=True punctuate=True includeRawResponse=True extra={'interim_results': True}
interim_results: TrueってことはSTTもストリーム、つまりリアルタイム文字起こししている可能性が高いと思う。
STTは以下も選択可能

なのだが、なぜかOpenAI Whisperには対応していないという不思議。
上記にあるWhisperは、ローカルのWhisper(faster-whisper)になるのだけど、なんかSTTで応答が返ってこないことがそこそこ起きる印象。以下にミニマルなサンプルコードがあるけど、これでも起きる。なんか詰まってるのかな?
Whisperじゃなくても、Daily.coのデフォルトSTTを使っても多少そういうことは起きやすいような気がしなくもないが、果たして・・・
まとめ
この手のWebRTC・Websocketプラットフォームは、OpenAIの「高度な音声モード」・Realtime APIが出てきてからは特に注目度が高まっているように思う。
LLM/STT/TTSを組み合わせた音声AIアシスタントは、以前からちらほら見かけるもののトランシーバーのような明確な会話のターンテイキングが多い。WebRTC・WebSocketの特徴である「双方向通信」を活かすことで、「リアルタイム」に近い会話を実現できるということなのだろうと思う。
なお、自分は似たようなものとしてLiveKitも試したが、概ねできることは同じかなと感じる。ただ、個人的にはLiveKitのほうがもう少し安定してるかなぁと感じた(ただし、これは何が原因なのかはわかっていないので、あくまでも個人的な所感)
なお、OpenAI のChatGPT音声モードはLiveKitを使用しているらしい。

referred from https://livekit.io/
また、Pipecatで使用したDaily.coも、Google Gemini Multimodal Live APIのドキュメントでインテグレーションが推奨されている。
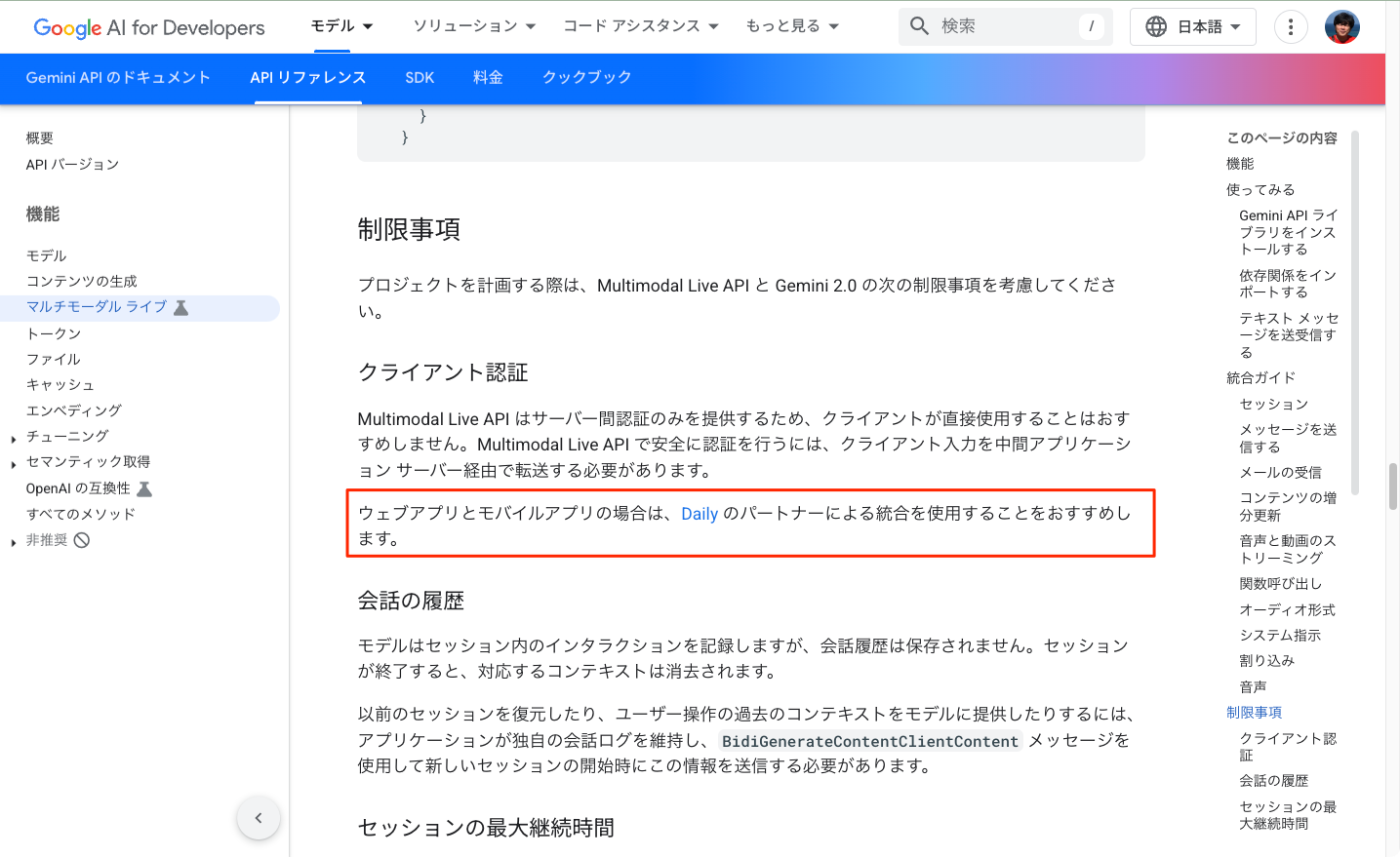
referred from https://ai.google.dev/api/multimodal-live?hl=ja
個人的にも、もう少しWebRTC・Websocketについて基本的なところから試してみたいと感じている。
上記にあるWhisperは、ローカルのWhisper(faster-whisper)になるのだけど、なんかSTTで応答が返ってこないことがそこそこ起きる印象。以下にミニマルなサンプルコードがあるけど、これでも起きる。なんか詰まってるのかな?
Issueに似たようなものがあった
んー、ちょっとよくわからんな、中身を見てみる必要がありそう
LLM/STT/TTSを組み合わせた音声AIアシスタントは、以前からちらほら見かけるもののトランシーバーのような明確な会話のターンテイキングが多い。WebRTC・WebSocketの特徴である「双方向通信」を活かすことで、「リアルタイム」に近い会話を実現できるということなのだろうと思う。
LiveKitもDaily.coもWebRTCプラットフォームだけれども、よりハイレベルに音声AIアシスタント構築プラットフォームってのもあるね。
この辺はそもそも「リアルタイムに近い」というのがウリに思える。そのためにどうしているか?ってところは細かくは見てないけど、TTSの入力ストリーミング、STTの入出力ストリーミングあたりはどこもやっているような印象がある。
ElevenLabs Conversational AIについては以下で試した。
一番最初のサンプルコードでCartesiaを使っている箇所
# Cartesiaのテキスト読み上げサービスを初期化
# 事前に選択された日本語の女性の声を使用
# 他の声は以下で確認できる: https://play.cartesia.ai/voices
# 訳注1:
# 元のサンプルコードでは、CartesiaTTSServiceが使用されており、これはリアルタイム処理のためだが、
# その場合、モデルと言語がタイムスタンプに対応している必要がある。Cartesiaの日本語モデルはタイムスタンプに
# 対応していないため、エラーとなる。そこで非リアルタイムなCartesiaHttpTTSServiceを使用する。
# 参考: https://docs.cartesia.ai/api-reference/tts/compare-tts-endpoints#if-you-want-to-generate-speech-in-real-time
# 参考: https://github.com/pipecat-ai/pipecat/issues/513
# 訳注2:
# なお、Cartesiaの日本語対応モデルは、Websocketや入力ストリーミングに対応しているので
# それらを使ってリアルタイムに近い高速TTSレスポンスを生成することは可能。
# 例えばOpenAI Chat CompletionのストリーミングをそのままCartesiaに投げて高速音声チャットボットができたりする。
# ここでそれができないのはPipecatでのリアルタイム処理はタイムスタンプ機能が前提となっているからだと思う。
tts = CartesiaHttpTTSService(
api_key=os.getenv("CARTESIA_API_KEY"),
voice_id=os.getenv("CARTESIA_VOICE_ID"),
model="sonic",
params=CartesiaHttpTTSService.InputParams(
language=Language.JA,
)
)
ということで、日本語の場合はリアルタイムではないという風に書いているが、新しく出たCartesia Sonic-2モデルは対応言語全て(日本語含む)でタイムスタンプに対応しているため、リアルタイム処理が可能になったかもしれない(試していない)