プロンプト最適化ライブラリ「Promptim」を試す
ここで知った。
GitHubレポジトリ
Promptim
Promptimは、AIシステムを体系的に改善するための実験的なプロンプト最適化(prompt optimization)ライブラリです。
Promptimは、特定のタスクにおけるプロンプトの改善プロセスを自動化します。初期プロンプト、データセット、カスタム評価者(およびオプションでの人間のフィードバック)を提供すると、Promptimは最適化ループを実行し、元のプロンプトを上回ることを目指して洗練されたプロンプトを生成します。
セットアップと使用方法の詳細については、以下のクイックスタートガイドを参照してください。
refered from https://github.com/hinthornw/promptimizer

Quick start
Quick startに従って進める。前提として、LangSmith APIキーが必要になるので、適宜準備。で、CLI中心の使い方のようなので、今回はローカルのMacでやる。
まず仮想環境を作成。自分はmiseを使うがこれも適宜。
mkdir promptim-test && cd promptim-test
mise use python@3.12
cat << 'EOS' >> .mise.toml
[env]
_.python.venv = { path = ".venv", create = true }
EOS
mise trust
promptimのパッケージインストール
pip install -U promptim
pip freeze | grep -i promptim
promptim==0.0.5
LangSmithのAPIキーをセット
export LANGSMITH_API_KEY=XXXXXXXXXX
Quick startの流れは以下となっている。
- あるテーマについてのツイートを生成するというタスクを作成
- 生成された出力を評価する評価器を設定
- 最適化を実行
で、Quick startにあるタスク作成のコマンドは以下となっているのだが、
promptim create task ./my-tweet-task \
--name my-tweet-task \
--prompt langchain-ai/tweet-generator-example-with-nothing:starter \
--dataset https://smith.langchain.com/public/6ed521df-c0d8-42b7-a0db-48dd73a0c680/d \
--description "Write informative tweets on any subject." \
-y
- デモ用に用意されたパブリックなデータセットを使用するようになっており、LangSmith上にデータセットを置いておく必要があるように見える。
- プロンプトもLangChain Hubのパブリックなものを使用するように見える
ということで、まずデータセットについて。
https://smith.langchain.com/public/6ed521df-c0d8-42b7-a0db-48dd73a0c680/d にアクセスしてみるとこういう内容になっている。

ツイートのトピックが単に羅列されたデータセットっぽくて、すべて英語となっている。このレベルであればプロンプト側で日本語にすることもできるのだけど、どうせなら全部日本語でやりたい。
でこれを作成するスクリプトが以下にある。
これを日本語に修正したものが以下。
## データセットの作成例
if __name__ == "__main__":
from langsmith import Client
client = Client()
topics = [
"NBA",
"NFL",
"映画",
"テイラー・スウィフト",
"人工知能",
"気候変動",
"宇宙探査",
"暗号通貨",
"健康的な生活",
"旅行先",
"テクノロジートレンド",
"ファッション",
"食と料理",
"音楽フェスティバル",
"起業",
"フィットネス",
"ゲーム",
"政治",
"環境保護",
"ソーシャルメディアトレンド",
"教育",
"メンタルヘルス",
"再生可能エネルギー",
"バーチャルリアリティ",
"サステイナブルファッション",
"ロボティクス",
"量子コンピューティング",
"遺伝子工学",
"スマートシティ",
"サイバーセキュリティ",
"拡張現実",
"電気自動車",
"ブロックチェーン",
"3Dプリンティング",
"ナノテクノロジー",
"バイオテクノロジー",
"モノのインターネット(IoT)",
"クラウドコンピューティング",
"ビッグデータ",
"機械学習",
"汎用人工知能",
"宇宙観光",
"自動運転車",
"ドローン",
"ウェアラブルテクノロジー",
"個別化医療",
"遠隔医療",
"リモートワーク",
"デジタルノマド",
"ギグエコノミー",
"循環経済",
"垂直農業",
"培養肉",
"植物ベースの食事",
"マインドフルネス",
"ヨガ",
"瞑想",
"バイオハッキング",
"スマートドラッグ",
"断続的断食",
"高強度インターバルトレーニング(HIIT)",
"eスポーツ",
"ストリーミングサービス",
"ポッドキャスティング",
"実話犯罪",
"タイニーハウス",
"ミニマリズム",
"ゼロウェイスト生活",
"アップサイクリング",
"エコツーリズム",
"ボランツーリズム",
"デジタルデトックス",
"スローライフ",
"ヒュッゲ",
"都市農園",
"パーマカルチャー",
"再生型農業",
"マイクロプラスチック",
"海洋保護",
"野生動物再生",
"絶滅危惧種",
"生物多様性",
"倫理的AI",
"データプライバシー",
"ネット中立性",
"ディープフェイク",
"フェイクニュース",
"ソーシャルメディアアクティビズム",
"キャンセルカルチャー",
"ミーム文化",
"NFT",
"分散型金融(DeFi)",
"ベーシックインカム",
"ジェンダー平等",
"LGBTQ+の権利",
"ブラック・ライブズ・マター",
"先住民族の権利",
"難民危機",
"世界の貧困",
"ユニバーサルヘルスケア",
"薬物の非犯罪化",
"刑務所改革",
"銃規制",
"投票権",
"ゲリマンダー",
"キャンペーン資金改革",
"任期制限",
"ランク付き選択投票",
"直接民主主義",
"宇宙ゴミ",
"小惑星採掘",
"火星移住",
"地球外生命体",
"ダークマター",
"ブラックホール",
"量子もつれ",
"核融合エネルギー",
"反物質",
"クライオニクス",
"寿命延長",
"トランスヒューマニズム",
"サイボーグ",
"ブレインコンピュータインターフェース",
"記憶インプラント",
"ホログラフィックディスプレイ",
]
# データセットを作成
ds = client.create_dataset(dataset_name="tweet-optim-ja")
# トピックを訓練、開発、テストセットに分割
train_topics = topics[:80]
dev_topics = topics[80:90]
test_topics = topics[90:]
# 各データセットの例を作成
for split_name, dataset_topics in [
("train", train_topics),
("dev", dev_topics),
("test", test_topics),
]:
client.create_examples(
inputs=[{"topic": topic} for topic in dataset_topics],
dataset_id=ds.id,
splits=[split_name] * len(dataset_topics),
)
print("データセットが正常に作成されました!")
これを実行する。
python create_dataset_ja.py
実行後、LangSmithの自分のアカウントでみてみると、データセットがアップロードされていることがわかる。

次にプロンプト。こちらもLangChain Hubに用意されている以下を使用している様子。
https://smith.langchain.com/hub/langchain-ai/tweet-generator-example-with-nothing

これをフォークする。
名前を変えて、あとプライベートにしてみた。
作成された。プロンプトを日本語に変更するために、Playgroundに移動。
日本語に書き換えてコミット。
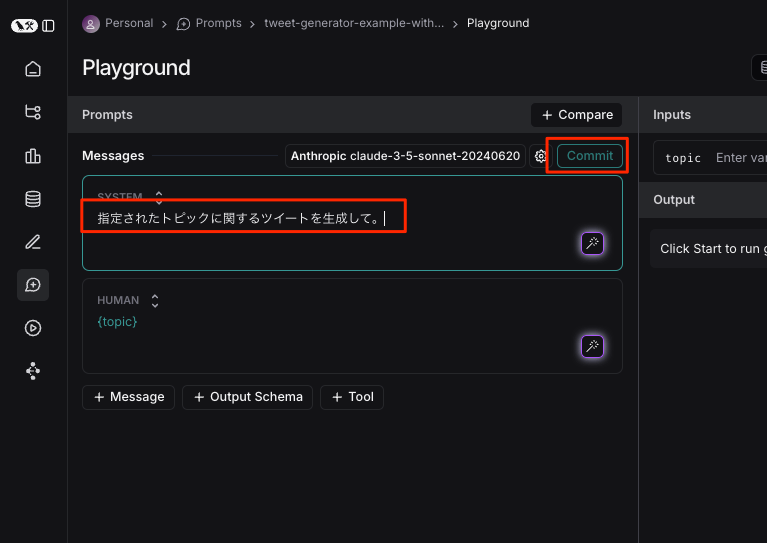
更新された。

これで準備完了。
ではタスクを作成する。Prompt Hub側でフォークしたプロンプトにはAnthropicのモデルが紐づいていたので、AnthropicのAPIキーをセットする必要がある様子。
export ANTHROPIC_API_KEY=XXXXXXXXXXXX
実行。パブリックではない自分のアカウントのプロンプトやデータセットならば名前で指定できる。なお、descriptionは最適化の際に使用されるみたい。
promptim create task ./my-tweet-task-ja \
--name my-tweet-task-ja \
--prompt tweet-generator-example-with-nothing-ja \
--dataset tweet-optim-ja \
--description "どんなテーマでも、有益なツイートを書いてください。" \
-y
********************************************************************************
Task 'my-tweet-task-ja' created at ./my-tweet-task-ja
Config file created at: ./my-tweet-task-ja/config.json
Task file created at: ./my-tweet-task-ja/task.py
Using dataset: https://smith.langchain.com/o/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/datasets/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
Using prompt: tweet-generator-example-with-nothing-ja
================================ System Message ================================
指定されたトピックに関するツイートを生成して。
================================ Human Message =================================
{topic}
Remember to implement your custom evaluators in ./my-tweet-task-ja/task.py
行けてるっぽい。ディレクトリが作成されているので中身を見てみる。
tree my-tweet-task-ja
my-tweet-task-ja
├── config.json
└── task.py
config.jsonは置いておいて、task.pyを見てみる。なお、コメント部分は日本語に訳してある。
"""タスクを最適化するための評価関数: my-tweet-task-ja
こちらはテンプレートです。適宜変更してください!
評価関数は、設定されたデータセットに対して実行されたプロンプトのスコアを計算します:
https://smith.langchain.com/o/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/datasets/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
"""
from langchain_core.messages import AIMessage
from langsmith.schemas import Run, Example
# 評価基準を測定するために、これらの評価関数を変更します。
# 多くのプロンプト最適化タスクでは、run.outputs["output"]にAIMessageが含まれます。
# (高度な使用)カスタムシステムを定義して最適化する場合、outputsにはシステムによって返されるオブジェクトが含まれます。
def example_evaluator(run: Run, example: Example) -> dict:
"""評価関数の例。数値が大きいほど良いとされます。"""
# Exampleオブジェクトには、データセットの単一行に含まれる入力と参照ラベルが格納されています(提供されている場合)。
# 設定されたデータセットの最初の例の入力と出力をコピーしました。
prompt_inputs = example.inputs
# {
# "topic": "\u30db\u30ed\u30b0\u30e9\u30d5\u30a3\u30c3\u30af\u30c7\u30a3\u30b9\u30d7\u30ec\u30a4"
# }
reference_outputs = example.outputs # 別名、ラベル
# 例: 出力が期待されていないためNone
# 上記のコメントは以下の例から自動生成されています:
# https://smith.langchain.com/o/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/datasets/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
# Runオブジェクトにはシステムの完全な実行記録が含まれます。通常、outputsを参照して
# チェックを行い、それをreference_outputsと比較します。
predicted: AIMessage = run.outputs["output"]
# ここに評価ロジックを実装します
score = len(str(predicted.content)) < 180 # 実際のスコア計算に置き換えてください
return {
# ここでの評価キーは、測定するメトリックを定義します
# これらの説明をconfig.jsonに追加することもできます
"key": "my_example_criterion",
"score": score,
"comment": (
"ここを変更: ミスを修正するための情報(例: 合格/不合格、期待したXと得られたYなど)を返すことは良い習慣です。"
"このコメントは、LLMが改善点を認識できるように指示します。"
"プレースホルダーメトリックは、コンテンツの長さが180未満であることを確認します。"
),
}
evaluators = [example_evaluator]
コメントやドキュメントにあるように、ここに評価関数を自分で実装して、コメントなどを修正していく。Quick startでは例として「ハッシュタグが含まれていればペナルティ」という評価で修正する。
def example_evaluator(run: Run, example: Example) -> dict:
predicted: AIMessage = run.outputs["output"]
result = str(predicted.content)
score = int("#" not in result) # ハッシュタグ(#)が含まれていれば0、含まれていなければ1
return {
"key": "tweet_omits_hashtags", # 評価器の名前
"score": score,
"comment": (
"Pass: ツイートはハッシュタグを省略している" if score == 1 else "Fail: 生成されたツイートからすべてのハッシュタグを省略しなければならない"
),
}
では最適化を実行する
promptim train --task ./my-tweet-task-ja/config.json
のだが、、、
openai.OpenAIError: The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variable
んー、なぜかOpenAIでつなごうとする。。。。ちょっと原因がわからなくて、もう一つ仮想環境作って今度はREADMEで書いてあるままに試したのだけど、
KeyError: 'Missing key "OPENAI_API_KEY" in load(secrets_map)'
うーん、ちょっとわからない。
とりあえずOPENAI_API_KEYをセットすることにした。
export OPENAI_API_KEY=XXXXXXXXXXXX
再度実行すると以下のような感じで実行できた。
╭───────── Initial Prompt to optimize: ──────────╮
│ Original Prompt: │
│ │
│ <TO_OPTIMIZE kind="System"> │
│ 指定されたトピックに関するツイートを生成して。 │
│ </TO_OPTIMIZE> │
│ <CONTEXT kind="User"> │
│ {topic} │
│ </CONTEXT> │
│ │
╰────────────────────────────────────────────────╯
Loading data... ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
╭───────────────────────────────────────────────────────────────────────────────────────── Initial Prompt Evaluation ─────────────────────────────────────────────────────────────────────────────────────────╮
│ Baseline Scores (Dev Set) │
│ ┏━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┓ │
│ ┃ Metric ┃ Score ┃ │
│ ┡━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━┩ │
│ │ tweet_omits_hashtags │ 0.0000 │ │
│ │ Average │ 0.0000 │ │
│ └──────────────────────┴────────┘ │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
Beginning optimization.
╭─────────────────────────────── Updated Prompt ───────────────────────────────╮
│ <TO_OPTIMIZE kind="System"> │
│ 指定されたトピックに関するついて、有益で興味深いツイートを生成してください。 │
│ │
│ 重要な注意点: │
│ - ハッシュタグ(#)は一切使用しないでください │
│ - 1ツイートあたり140-280文字以内に収めてください │
│ - 絵文字は適度に使用可能です │
│ │
│ 良いツイートの特徴: │
│ - 明確で具体的な情報を提供 │
│ - 読者の興味を引く表現を使用 │
│ - 必要に応じて専門用語を分かりやすく説明 │
│ - 事実に基づいた正確な情報を共有 │
│ │
│ 複数のツイートを生成する場合は、異なる視点や側面から情報を提供してください。 │
│ </TO_OPTIMIZE> │
│ <CONTEXT kind="User"> │
│ {topic} │
│ </CONTEXT> │
│ │
╰──────────────────────────────────────────────────────────────────────────────╯
See prompt checkpoint: https://smith.langchain.com/prompts/tweet-generator-example-with-nothing-ja/XXXXXXX?organizationId=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXX
New best score: 1.0000 (surpassed previous best)
Average of:
tweet_omits_hashtags: 1.0000
╭─ Training Progress ─╮
│ Epoch 1 │
│ Dev score: 1.0000 │
│ Best score: 1.0000 │
╰─────────────────────╯
╭──────────────────────────────────────── Updated Prompt ────────────────────────────────────────╮
│ <TO_OPTIMIZE kind="System"> │
│ 指定されたトピックについて、魅力的で有益で興味深いツイートをなツイートを複数生成してください。 │
│ │
│ 重要な注意点要件: │
│ - ハッシュタグ(#)は一切使用しないでください禁止 │
│ - 1ツイートあたり140-280文字以内に収めてくださいる │
│ - 絵文字は適度に使用可能です │
│ │
│ 良(1ツイートあたり2-3個程度) │
│ - 各ツイートの冒頭に番号を付ける(例:1.) │
│ │
│ ツイートの構成ガイドライン: │
│ - 導入:トピックの概要や重要性を簡潔に説明 │
│ - 本文:具体的な事例、データ、専門家の見解など │
│ - 結び:読者への問いかけや行動喚起 │
│ │
│ 効果的なツイートの特徴: │
│ - 明確信頼で具体的なきる情報を提供 │
│ - 読者の興味を引く表現を使用 │
│ - 必要に応じて源に基づいた正確な内容 │
│ - 専門用語をは分かりやすく解説 │
│ - 読者の共感を誘う表現の使用 │
│ - 前向きで建設的なトーン │
│ │
│ 複数ツイート生成時は: │
│ - 異なる角度からの情報提供 │
│ - 基礎知識から専門的内容へと段階的な説明 │
│ - 事理論と実に基づいた正確な情報を共有 │
│ │
│ 複数のツイートを生成する場合は、異なる視点や側面から情報を提供してください。践のバランスを考慮 │
│ - ストーリー性のある展開を心がける │
│ </TO_OPTIMIZE> │
│ <CONTEXT kind="User"> │
│ {topic} │
│ </CONTEXT> │
│ │
╰────────────────────────────────────────────────────────────────────────────────────────────────╯
See prompt checkpoint: https://smith.langchain.com/prompts/tweet-generator-example-with-nothing-ja/XXXXX?organizationId=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXX
Score 0.9000 did not surpass best score 1.0000
╭─ Training Progress ─╮
│ Epoch 2 │
│ Dev score: 0.9000 │
│ Best score: 1.0000 │
╰─────────────────────╯
Optimization complete! ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
Epoch 1 (Dev: 1.0000, Train: 0.0250) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
Epoch 2 (Dev: 0.9000, Train: 1.0000) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00
╭─────────────────────────────────────────────────────────────────────────────────────────────── Final Report ────────────────────────────────────────────────────────────────────────────────────────────────╮
│ Optimization Results │
│ ┏━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┓ │
│ ┃ Metric ┃ Initial Score ┃ Final Score ┃ │
│ ┡━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━┩ │
│ │ tweet_omits_hashtags │ 0.0571 │ 1.0000 │ │
│ └──────────────────────┴───────────────┴─────────────┘ │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭──────────────────────────── Final Prompt Updates ────────────────────────────╮
│ <TO_OPTIMIZE kind="System"> │
│ 指定されたトピックに関するついて、有益で興味深いツイートを生成してください。 │
│ │
│ 重要な注意点: │
│ - ハッシュタグ(#)は一切使用しないでください │
│ - 1ツイートあたり140-280文字以内に収めてください │
│ - 絵文字は適度に使用可能です │
│ │
│ 良いツイートの特徴: │
│ - 明確で具体的な情報を提供 │
│ - 読者の興味を引く表現を使用 │
│ - 必要に応じて専門用語を分かりやすく説明 │
│ - 事実に基づいた正確な情報を共有 │
│ │
│ 複数のツイートを生成する場合は、異なる視点や側面から情報を提供してください。 │
│ </TO_OPTIMIZE> │
│ <CONTEXT kind="User"> │
│ {topic} │
│ </CONTEXT> │
│ │
╰──────────────────────────────────────────────────────────────────────────────╯
Final
指定されたトピックについて、有益で興味深いツイートを生成してください。
重要な注意点:
- ハッシュタグ(#)は一切使用しないでください
- 1ツイートあたり140-280文字以内に収めてください
- 絵文字は適度に使用可能です
良いツイートの特徴:
- 明確で具体的な情報を提供
- 読者の興味を引く表現を使用
- 必要に応じて専門用語を分かりやすく説明
- 事実に基づいた正確な情報を共有
複数のツイートを生成する場合は、異なる視点や側面から情報を提供してください。
Identifier: tweet-generator-example-with-nothing-ja:XXXXXXXX
Score: 1.0
おー、いけたっぽい。ただ当初想定だとAnthropicを使うことになっていたはずなので、ここでOpenAIだとやや意図が違ってくるが、どうなんだろう?
LangSmith側で確認すると、実行された履歴はある。
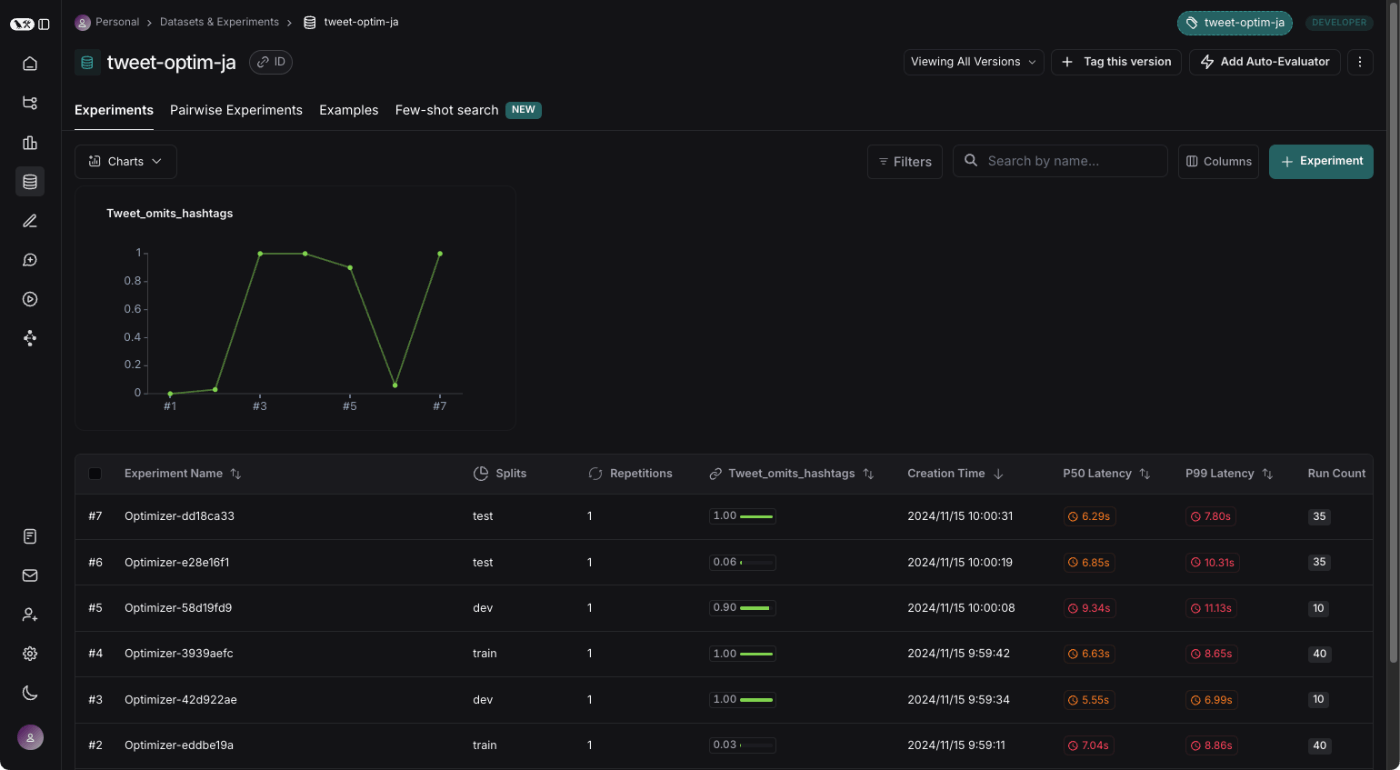
トレースを見るとAnthropicになっているので、OKかな。ほんとにOpenAIのAPIキーが必要なのかどうかはわからないけど、仮にそうだとしてもどこにも書いてないけど・・・
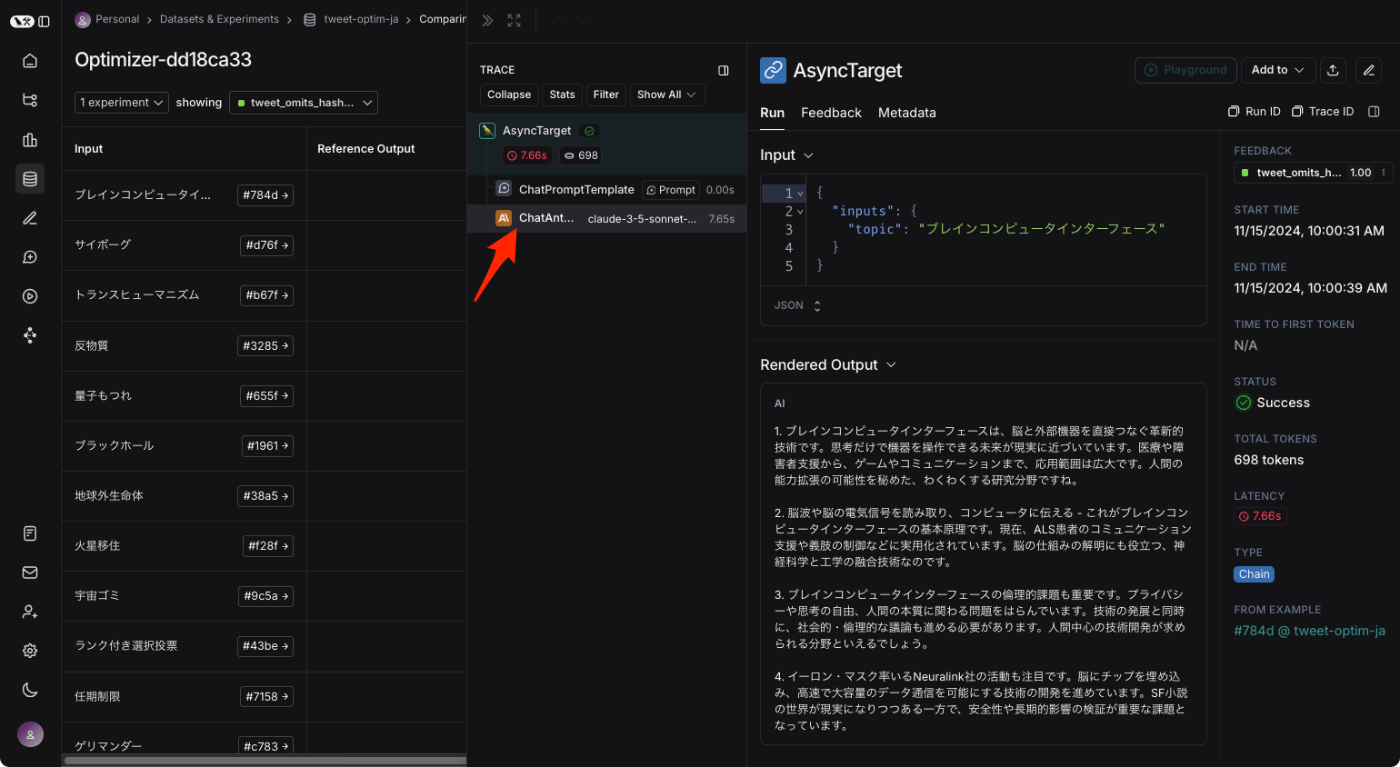
promptim trainはこんな動きになっているらしい
promptim trainを実行すると、まず、設定ファイルで指定されたプロンプトとデータセットが読み込まれます。次に、上記の評価関数を使用して、プロンプトをdev split(存在する場合;なければ全データセット)で評価します。これにより、最適化プロセス全体で比較基準とするベースラインメトリクスが得られます。ベースラインを計算した後、
promptimはトレーニング例のミニバッチをループしながらプロンプトの最適化を開始します。各ミニバッチに対して、promptimはメトリクスを計算し、現在のプロンプトに変更を提案するメタプロンプトを適用します。そして、更新されたプロンプトを次のミニバッチに適用し、このプロセスを繰り返します。この操作は、train split全体(存在する場合;なければ全データセット)にわたって行われます。
promptimがtrain split全体を処理した後、dev splitで再度メトリクスを計算します。メトリクスに改善(平均スコアが高くなる)が見られた場合、更新されたプロンプトは次のラウンドに引き継がれます。メトリクスが同じか現在のベストスコアより悪化している場合は、そのプロンプトは破棄されます。このプロセスは、指定された--num-epochs回数だけ繰り返され、最適化が終了します。
そういえば触れられていなかったconfig.jsonについては以下に説明がある。
データセットやプロンプト、最適化に使うモデルなどの定義が書かれている様子。最初のpromptim create taskで指定したものがそのまま埋め込まれている感じだけど、紹介されているサンプルを見る限り、プロンプトなんかはPrompt Hubを使わなくても直接書けるみたい。
{ "name": "Tweet Generator", "dataset": "tweet_dataset", "initial_prompt": { "prompt_str": "Write a tweet about {topic} in the style of {author}", "which": 0 }, "description": "Generate engaging tweets on various topics in the style of different authors", "evaluator_descriptions": { "engagement_score": "Measures the potential engagement of the tweet", "style_match": "Evaluates how well the tweet matches the specified author's style" }, "evaluators": "./tweet_evaluators.py:evaluators", "optimizer": { "model": { "name": "gpt-3.5-turbo", "temperature": 0.7 } } }
まとめ
結果が見やすいというのが率直な印象。あとはPromptim自体の手数もそんなに多くないし、理解もしやすいと思う。LangSmithと連携することで、だいぶシンプルに実現できているのだろうと思う。
ただ、自分はLangSmithをあまり触ってない(というかLangChain/LangGraphも最近はあまり触っていなくて、どちらかというとLlamaIndexのほうが個人的に推し)ので、LangSmithプラットフォームの使い方を知らないといけない、っていうところにややオーバーヘッドを感じた。普段からLangSmithを日常的に使っているならばシームレスに使えるメリットを感じるのではないかと思う。
プロンプト自動生成から最適化まで、過去色々試してきたのだけども、
最近のモデルだとそこまでシビアにプロンプトエンジニアリングしなくてもそれなりのものが出力されるような気もするのだけど、きちんと意図通りに細かく制御しようとするとなかなか難しかったりもして、このあたりはある程度自動化できるようにしたいというのは思いとしてある。
が、ユースケースにあったデータセットや評価指標をきちんと用意する、というのがまあ大変なんだけども・・・
最適化のプロンプトはこの辺