CohereのPrompt Tunerを試す
公式ブログ
公式ドキュメント
解説はnpaka先生の日本語記事がわかりやすい
Prompt Tuner は、カスタマイズ可能な最適化と評価のループを使用して、生成言語のユースケース向けにプロンプトを改良します。 Optimization by PROmpting (OPRO) に触発されたPrompt Tunerは、LLMによる評価結果に基づいてプロンプトを繰り返し最適化します。 評価基準はカスタマイズ可能で、結果は命令生成モデルをガイドして新しいプロンプト案を生成するのに役立ちます。
ORPOってのはこれ
どのような研究か?
この研究は、大規模言語モデル(LLM)を最適化器として活用する新しいアプローチ「Optimization by PROmpting (OPRO)」を提案しています。OPROは、最適化タスクを自然言語で記述し、LLMが過去の解決策と評価値に基づいて新しい解決策を生成する反復的なプロセスを通じて最適化を行います。
新規性(従来研究と比べて何がすごいのか)?
従来の最適化手法と比較して、OPROの新規性は以下の点にあります:
- 自然言語による問題記述:最適化問題を形式的に定義する代わりに、自然言語で記述できます。
- 柔軟な適用:問題の記述を変更するだけで、異なるタスクに素早く適応できます。
- LLMの推論能力の活用:LLMの文脈理解と推論能力を活かし、複雑な最適化問題に対処できます。
技術や手法のキモはどこ?
OPROの核心は以下の要素にあります:
- メタプロンプト設計:最適化問題の記述、過去の解決策とその評価値、LLMへの指示を含む。
- 多様な解決策の生成:各ステップで複数の解決策を生成し、最適化の安定性を向上。
- 探索と活用のバランス:LLMのサンプリング温度を調整し、新しいアイデアの探索と既知の良い解決策の活用をバランス。
どうやって有効だと示したか?
研究チームは以下の方法でOPROの有効性を実証しました:
- 数学的最適化:線形回帰と巡回セールスマン問題[1]での性能評価。
- プロンプト最適化:GSM8K[2]とBig-Bench Hard (BBH)[3]ベンチマークでの評価。
- 転移可能性:GSM8KでのプロンプトをMultiArith[4]とAQuA[5]など他の数学推論データセットに適用。
結果として、OPROは人間が設計したプロンプトを大幅に上回る性能を示し、GSM8Kで最大8%、BBHタスクで最大50%の精度向上を達成しました。
議論はあるか?
論文では以下の点について議論しています:
- LLMの最適化能力の限界:大規模な最適化問題や複雑な損失関数への対応の難しさ。
- プロンプト最適化の課題:トレーニングセットの必要性や、エラーケースの効果的な活用の難しさ。
- 将来の研究方向:より豊富なフィードバックの活用や、より少ないサンプルでの最適化方法の探求。
次に読むべき論文は?
この研究の延長線上にある論文として、以下が興味深いかもしれません:
- Zhou et al. (2022b) "Large language models are human-level prompt engineers"
- Pryzant et al. (2023) "Automatic prompt optimization with 'gradient descent' and beam search"
- Guo et al. (2023) "Connecting large language models with evolutionary algorithms yields powerful prompt optimizers"
これらの論文は、LLMを用いたプロンプト最適化やプロンプトエンジニアリングに関する研究をさらに深掘りしています。
-
巡回セールスマン問題:複数の都市を一度ずつ訪問し、出発地に戻る最短経路を求める組み合わせ最適化問題。 ↩ ↩︎
-
GSM8K:小学校レベルの数学の単語問題を含むベンチマークデータセット。 ↩︎
-
Big-Bench Hard (BBH):推論能力を要する23の難しいタスクからなるベンチマーク。 ↩︎
-
MultiArith:Roy & Roth (2016)が提案した小学校レベルの算術単語問題データセット。複数のステップを要する加減乗除の問題を含み、言語理解と数学的推論の能力を評価する。 ↩ ↩︎
-
AQuA(Algebra Question Answering):Ling et al. (2017)が提案した高校レベルの代数問題データセット。自然言語で記述された問題に加え、数式や方程式も含まれる。言語理解、数学的推論、代数的操作の能力を総合的に評価する。 ↩ ↩︎
では早速やってみる。CohereのダッシュボードにログインしてPrompt Tunerにアクセス。

Prompt Tunerはこんな画面。
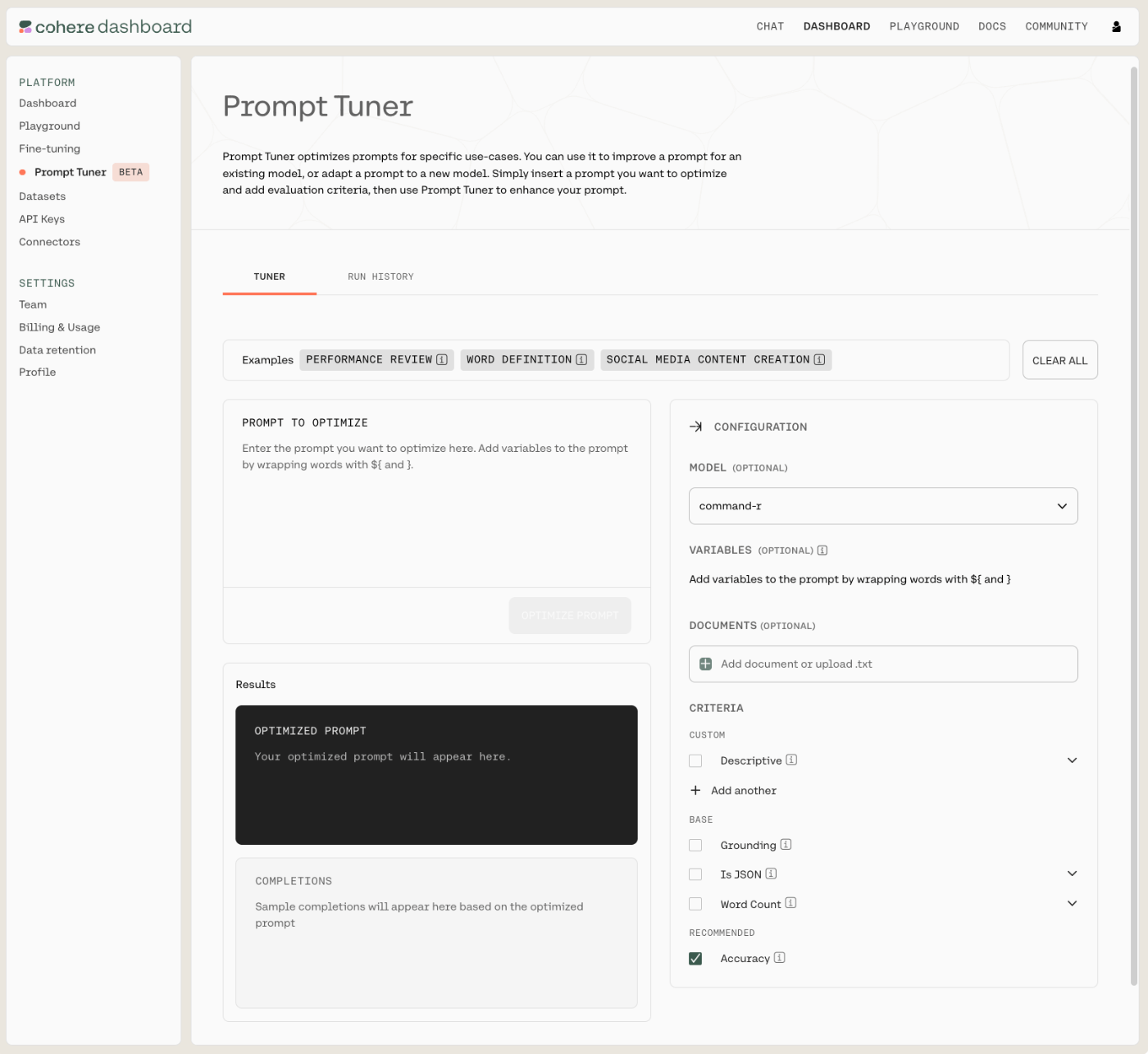
ここに初期プロンプトを入れれば良いみたい。
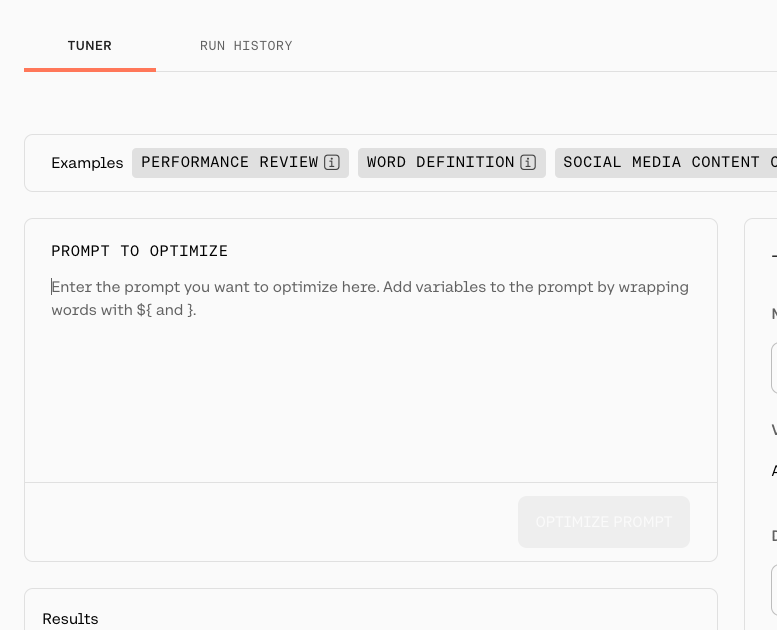
ドキュメントにある例文を日本語に翻訳したものを入れてみるが、ボタンが有効にならない。。。
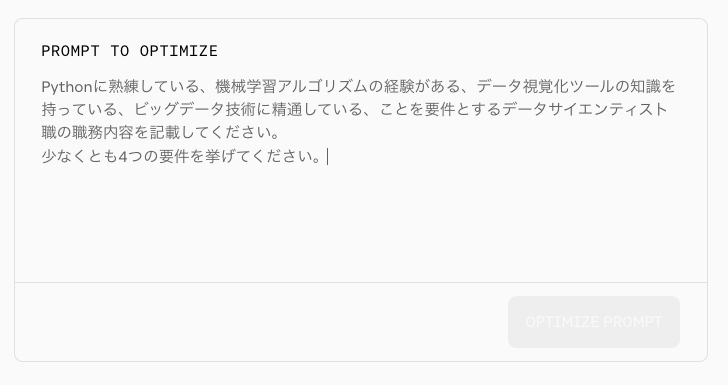
ボタンのツールチップを見るに、どうやら単語区切りをスペースで想定、つまり日本語については想定されていない様子。。。。

ただし、以下のように無理くりスペース区切りにするといけるっぽいのだが、プロンプトは日本語でかくよりも英語で書いたほうが指示追従性が高いという印象があるので、今回は英語で書くこととする。
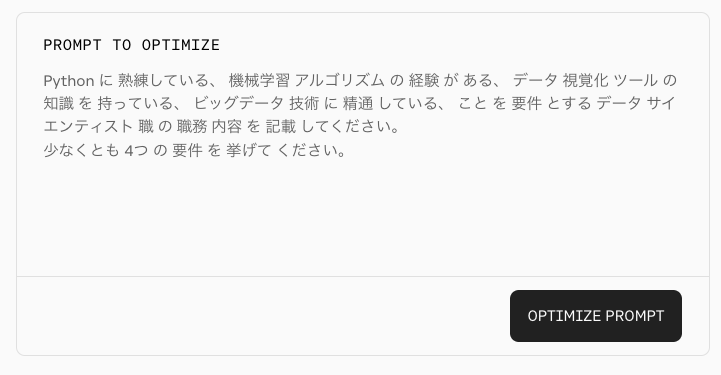
ドキュメントにある例文を少しだけ変更して、出力を日本語にするように指示した。
Create a job description for a Data Scientist position with the following requirements: proficiency in Python, experience with machine learning algorithms, knowledge of data visualisation tools, and familiarity with big data technologies.
List at least 4 requirements.
List in Japanese.

このまま実行できるようだが、ドキュメントに従ってCriteriaを設定する。Criteriaには、プロンプトを最適化するための「要件」を指定することができる。
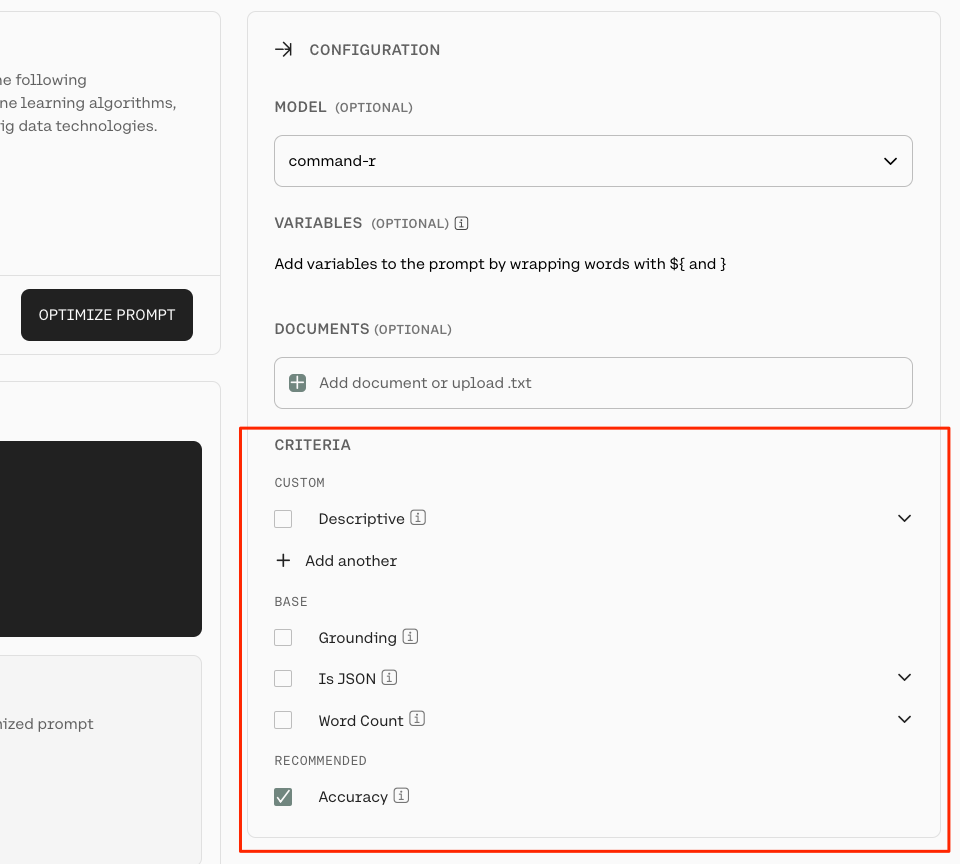
設定可能な要件は以下。上から並んでる順に記載。
| 項目名 | 説明 |
|---|---|
| Custom | 独自の要件を定義する。この内容を元に評価プロンプトが作成され、生成された結果を確認する(と思われる)。 |
| Word Count | 生成された単語数が指定の範囲内にあるかどうかを確認する。 |
| Is JSON | 生成された結果が有効なJSONオブジェクトであるかどうかを確認する。オプションで、特定のJSONスキーマにでチェックすることも可能。 |
| Grounding | 生成された結果が、プロンプトと提供されたドキュメントに基づいた内容かを測定する。オプションで、ドキュメントをアップロードすることも可能。 |
| Accuracy | 生成された結果が、プロンプトで定義された指示にどの程度従っているかを測定する。 |
今回の場合は以下と設定した。
- 職歴の要件として最低4件出力されていること(
There are at least 4 requirements.) - 出力が日本語であること(
Writtne in Japanese) - 単語数が100〜300語であること。(ただし日本語だとここはうまくいかないかもしれない)
- プロンプトに対して正確であること
あとモデルはcommand-r-plusをチョイス。
では"OPTIMIZE PROMPT"をクリックして実行。
こんな感じで実行される。
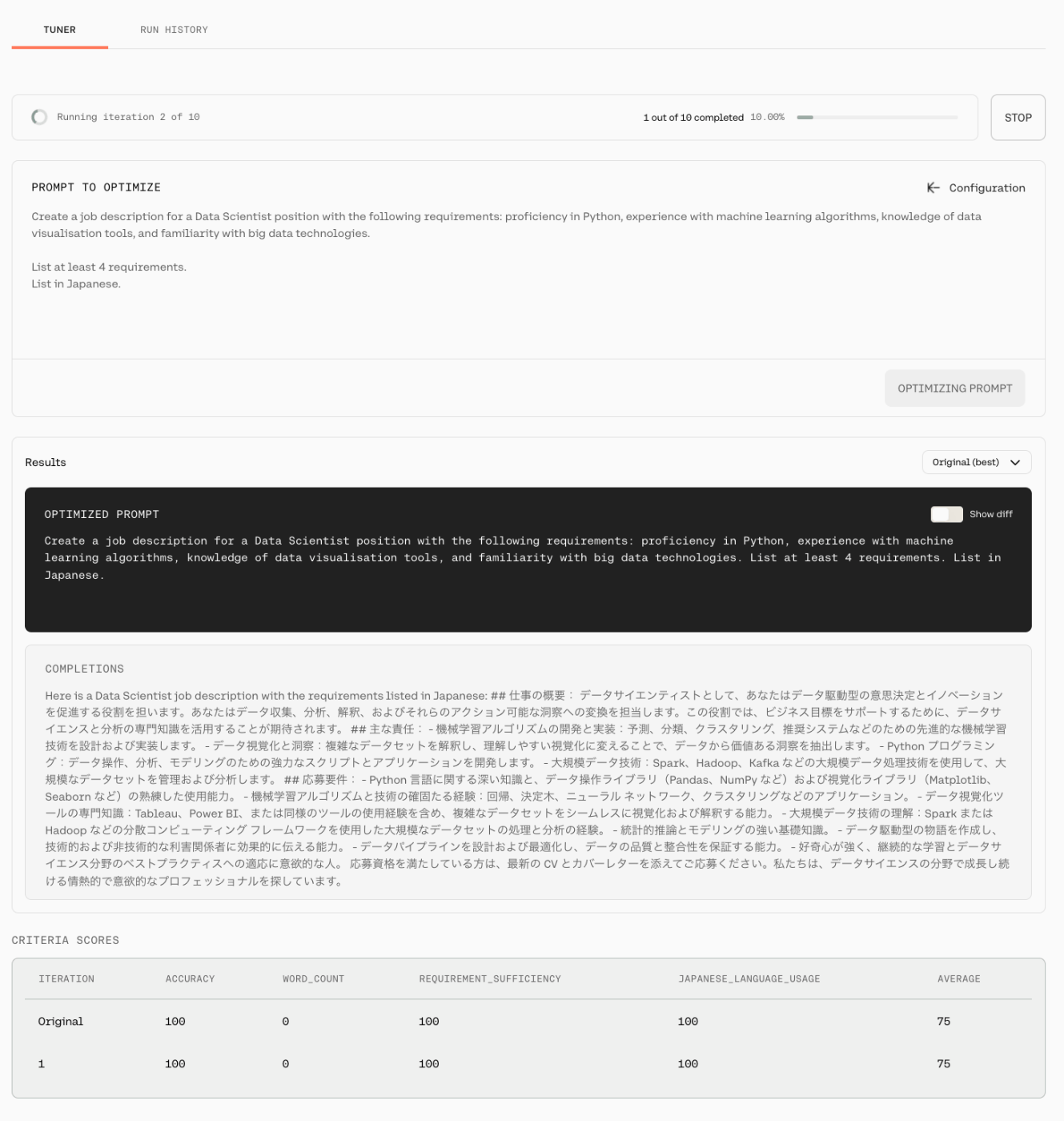
どうやらイテレーションは10回になっている様子。

イテレーションごとの評価結果も下に表示される。

10回完了したので結果を見てみると、オリジナルと各イテレーションで、最後の1回を除けば、それほどスコアが変わっていないのがわかる。

あと、この結果からは、Word Countは日本語だと意味がなかったことがわかる。その代わりに "JAPANESE_LANGUAGE_USAGE"という項目が表示されていて、よしなにやってくれているのかもしれない。マルチリンガルに力を入れているCohereならでは、という気がする
生成されたプロンプトとその結果はイテレーションごとに確認ができる。

一例
データサイエンティストの仕事は、データから価値を引き出し、データ駆動型の意思決定を促進することです。
この役割は、データ分析、機械学習、データ可視化に重点を置いています。
データサイエンスの分野で経験豊富で、ビッグデータテクノロジーに精通している人材を探しています。以下の内容を含む、データサイエンティストの包括的な仕事記述を作成してください:
- Python の専門知識: データ操作、分析、可視化のための Python プログラミングの熟練度を説明する。 - 機械学習の経験: 一般的なアルゴリズム(回帰、分類、クラスタリングなど)に関する経験の詳細を提供する。
- データ可視化ツール: Tableau、Power BI、または同様のツールを使用したデータの視覚的な表現の作成に関する知識を強調する。
- ビッグデータ テクノロジー: Spark、Hadoop、または同様の分散コンピューティング フレームワークを使用した大規模なデータセットの処理に関する経験を記載する。
- 統計学とデータ分析の基礎: 統計的推論、仮説検定、およびデータ解釈のスキルを説明する。
- データ駆動型ストーリーテリング: 複雑なデータセットから洞察を抽出し、明確で説得力のある方法で伝える能力。
- 問題解決能力: 複雑な問題を解決するための分析的で創造的なアプローチ。
- コミュニケーション能力: 技術チーム、経営陣、および利害関係者と効果的に協力およびコミュニケーションできる能力。
- 継続的な学習: 最新の傾向とベストプラクティスを最新の状態に保つ意欲。
応募者の技術的能力を評価するための明確な基準を提供しながら、応募要件を150~250語の日本語で説明してください。
ざっと見た限りだけども、要件にあった「職歴の要件として最低4件」が記載されていたりいなかったり、「100〜300語」というのが「200~250語」だったり「150~250語」だったりしているので、「評価に関する要件」としては機能しているのかなと思うが、メタプロンプト的に「生成に関する要件」として指定されているかどうかはちょっと怪しい、というかされていないのではないかと思える。
イメージ的には要件的な内容はプロンプトに記載するのが前提で、それに対して正しく指示に追従しているか、という点でカスタム要件を定義する、というような感じなのかもしれない。
なお、"Show Diff"を有効にすると、初期プロンプトとのdiffが表示される。

所感
触ってみた感じとしてはDSPyと同じ印象がある。イテレーション回して改善するところとか、出力を見てる限りはfew shots的な出力を多く含むところとか。
ちょうどAnthropicのPrompt Generatorを触ったところだったので、かなり印象が違う。自分はAnthropicに関してはまさにプロンプトエンジニアリング駆使って感じたし、あれは多分Claude-3.5-Sonnetあたりのポン出し性能の高さからくるものだとも思っている。
まあ今回のプロンプトはシンプルなものだったし、複雑なプロンプトでやった場合にはまた印象は変わるかもしれない。論文にはもっと詳しく書いてあるのかもしれない。少し見直してみたい。