Amazon Bedrock for Knowledge baseを試す
前提
- Knowledge baseのベクトルデータベースにはPineconeを使う。とりあえずFree TierでOK。
- リージョンは今回はus-east-1を使う。Knowledge baseはまだap-northesat-1には来ていないため。対応リージョンはドキュメント参照。
- RAGで使うデータは以下のFAQデータセットを使用する。
事前準備
とりあえずここまでやるイメージで。

Pinecone
Pineconeでインデックスを作成。

データセットに合わせてインデックス名はfaqとした。次元数とメトリックは、Knowledge baseにおけるEmbeddingsはTitan Embeddingsを使うことになるため、それにあわせて、次元数: 1536、メトリック: コサイン類似度を選択する。
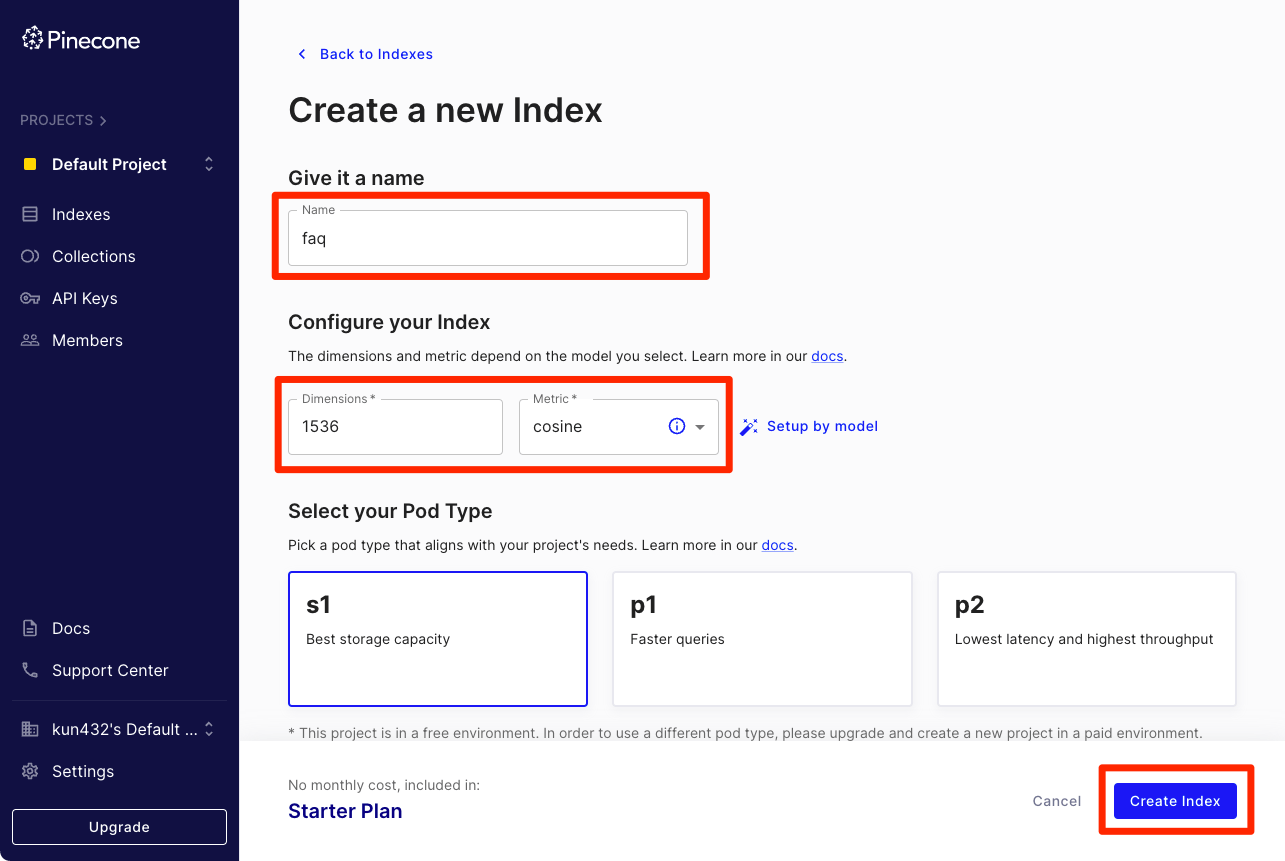
インデックスが作成された。ホストのURLは後で必要になるため、控えておく。
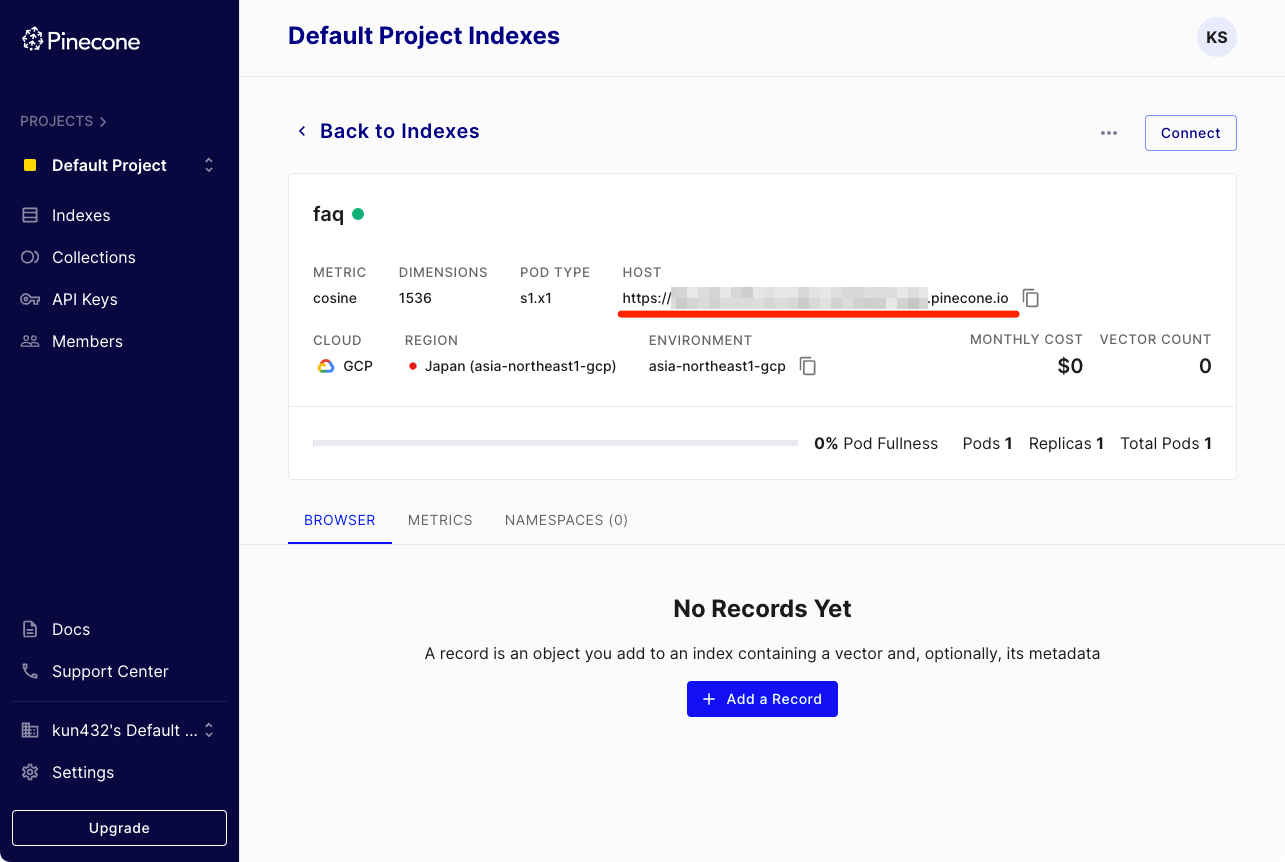
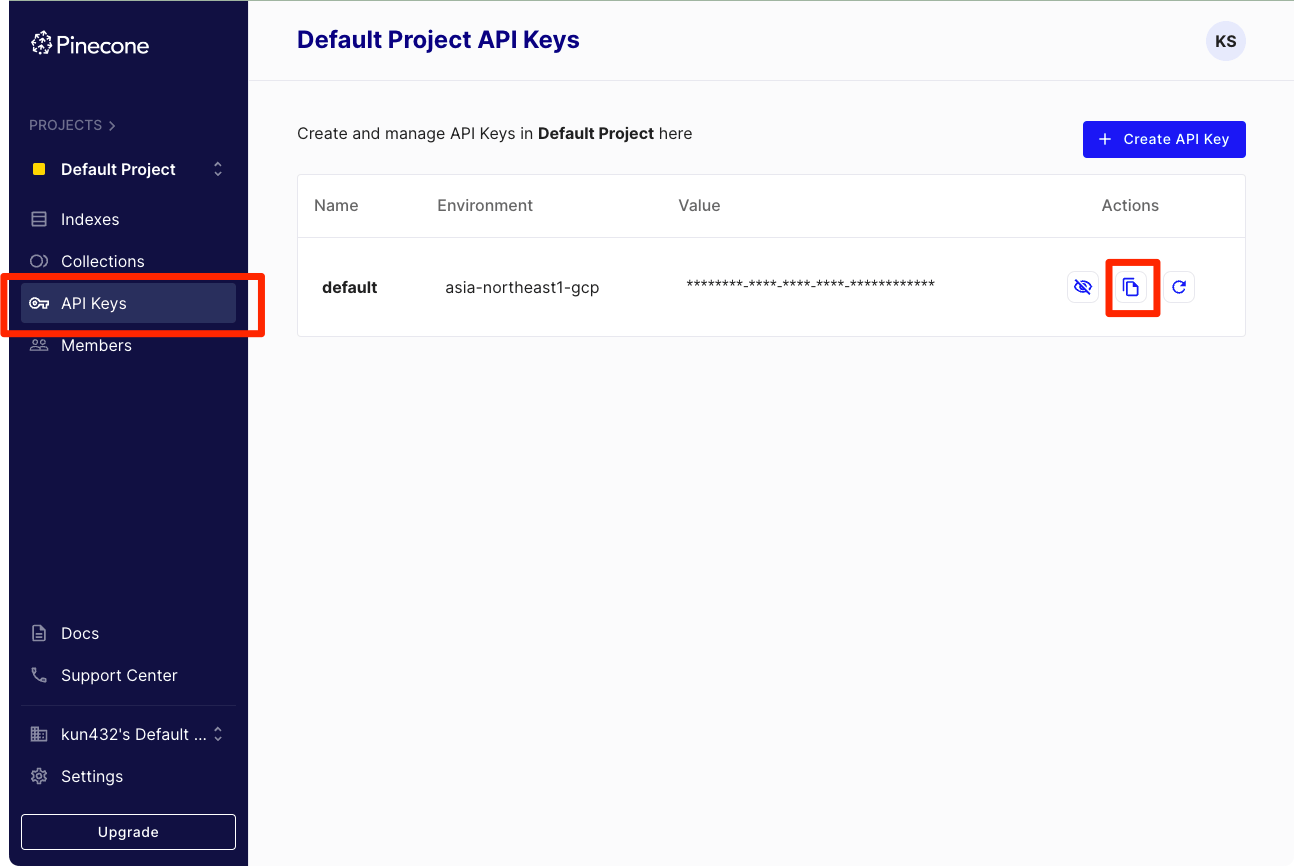
同様にAPIキーも、必要なら作成の上、控えておく。
Secret Manager
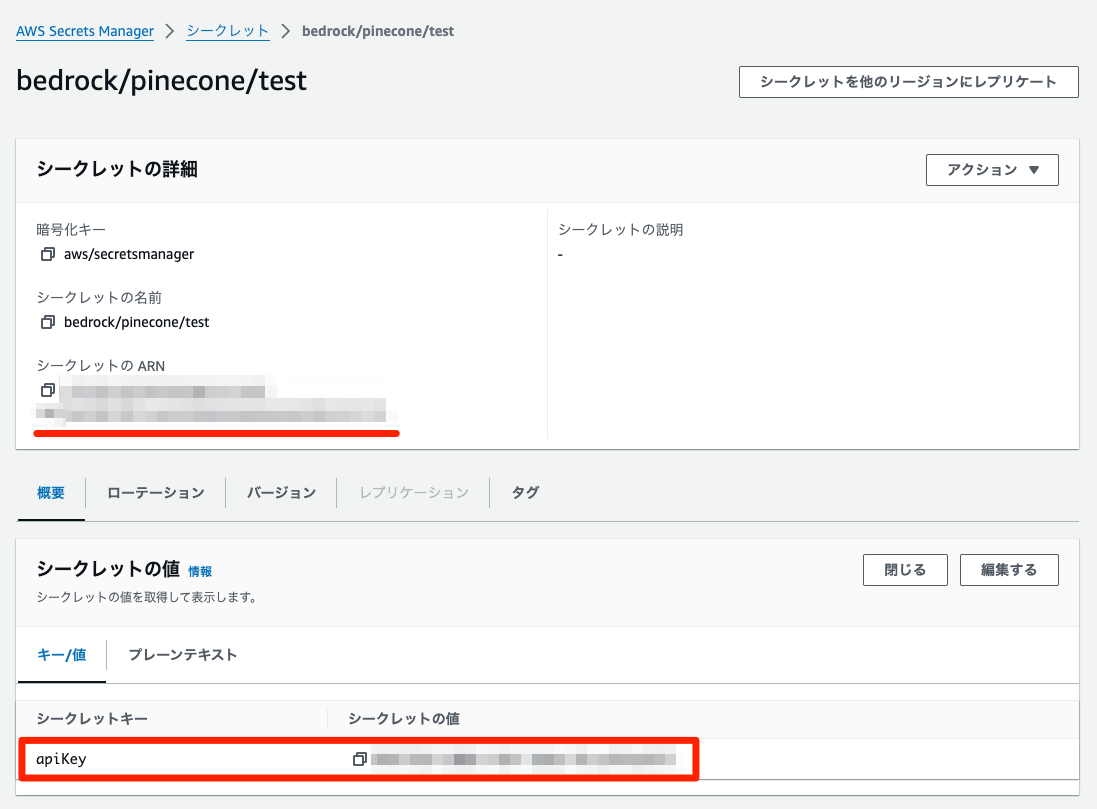
PineconeのAPIキーをSecret Managerに登録しておく。こちらもus-east-1で。secretの名前はなんでもよいが、シークレットキーはapiKeyである必要がある。シークレットの値にPineconeのAPIキーを入れる。
作成したらシークレットのARNを控えておく。
S3
Knowledge base作成の際にS3バケットを指定する。こちらもus-east-1で作った。特に凝ったことは不要。

データセットの前処理
Knowledge baseに読み込ませたいドキュメントなどを上記のS3バケットにアップロードする。対応しているファイル形式は以下。
ナレッジベースは以下のファイル形式をサポートしています。
- プレーンテキスト (.txt)
- マークダウン (.md)
- HyperText マークアップ言語 (.html)
- Microsoft Word ドキュメント (.doc/.docx)
- カンマで区切られた値 (.csv)
- Microsoft Excel スプレッドシート (.xls/.xlsx)
- ポータブルドキュメントフォーマット (.pdf)
で、先に言ってしまうと、これらのドキュメントを「そのまま」アップロードすると、形式に関わらずチャンク分割された上でKnowledge baseのインデックスに登録される。
つまり、
- xlsxやcsvであれば行単位でコンテキストを分けて登録したい
- htmlやmarkdownであればセクションごとにコンテキストを分けて登録したい
というようなことは、現時点ではできないことになる。
今回使用するデータセットはxlsxで1行ごとにQAが登録されている。個人的には、RAGでプロンプトに挿入するデータは、できる限りクエリに類似する適切なコンテキスト「のみ」を含めて、関連しない前後のコンテキストなどは含めないほうが検索的には精度が高くなる、つまり、行単位でインデックスに登録したい。
詳細は後述するが、これを実現したい場合には、
- コンテキスト単位でファイルを分ける
- かつ、チャンク分割しないようにする
することで可能になる。
いうことで前フリが長くなったけど、上記のデータセットを行単位で分割してテキストファイル化することとする。
自分の場合はColaboratoryで処理した。以下のような形。
!wget https://d.line-scdn.net/stf/linecorp/ja/csr/dataset_.zip
!!unzip dataset_.zip
import pandas as pd
df = pd.read_excel("dataset_.xlsx")
df.rename(columns={
'サンプルID': 'SampleID',
'サンプル 問い合わせ文': 'Q',
'サンプル 応答文': 'A',
'カテゴリ1': 'Category',
'カテゴリ2': 'Cat2',
'出典': 'Ref',
'<参考>UMカテゴリタグ': 'Tag',
'<参考>UMサービスメニュー\n(標準的な行政サービス名称)': 'Service'
}, inplace=True)
df.drop(columns=["ID", "Cat2","Ref","Tag","Service"], inplace=True)
df["Context"] = "Q: " + df["Q"] + "\nA: " + df["A"]
df
こんな感じのデータフレームができるので、Contextを行ごとにファイルに出力する。

!mkdir output
for index, row in df.iterrows():
file_name = str(row['SampleID']) + '.txt'
with open("output/" + file_name, 'w', encoding='utf-8') as file:
file.write(row['Context'])
!tar cvzf output.tar.gz output
以下のようにID単位でファイル分割したものをアーカイブ化してダウンロードする。
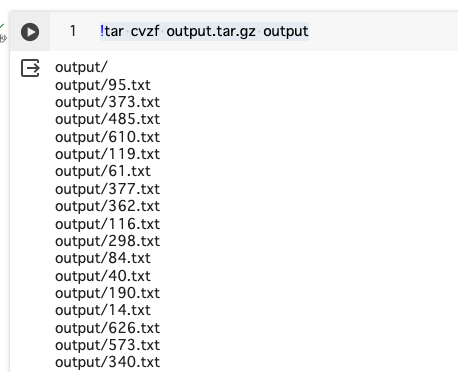
各ファイルは以下のようなテキストファイルとなる。これらを全てS3にアップロードする。
Q: 母子手帳を受け取りたいのですが、手続きを教えてください。
A: 窓口で妊娠届をご記入いただき、母子手帳をお渡しします。
住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。
▼詳しくはこちら
(自治体HP内関連ページのURL)
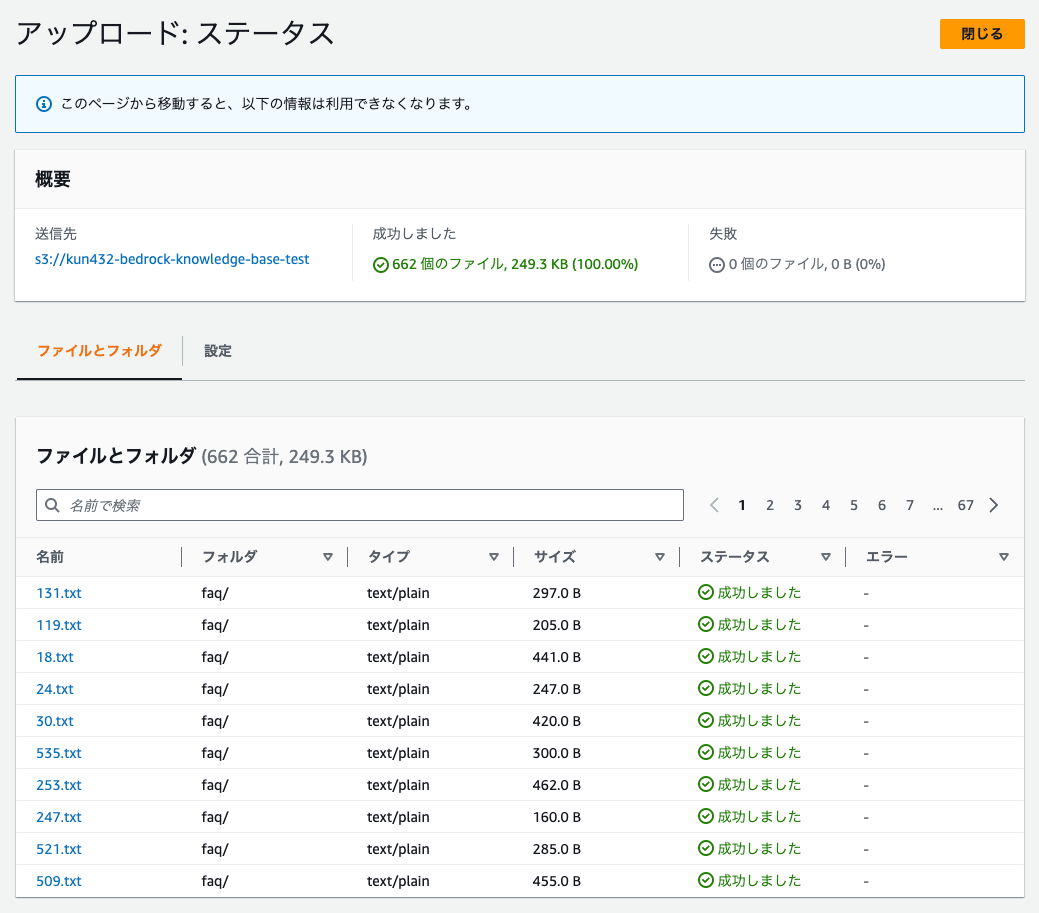
今回はfaqというフォルダを作成してその配下に全てのテキストファイルをアップロードした。全662ファイル。
これで事前準備完了。BedrockでKnowledge baseを作成する。
Knowledge baseの作成
Bedrockのページから"Create Knowledge base"をクリック。

Knowledge baseの名前、IAMロールを設定。今回は全てデフォルトで。"Next"をクリック。

Knowledge baseに読み込ませるデータソースの設定。データソース名は必要なら設定、今回はデフォルトのまま。S3 URIに先ほどファイルをアップロードしたS3バケットを指定する。
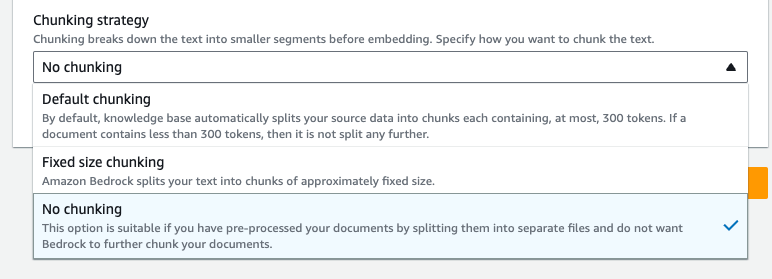
で、上で書いた通り、今回はファイルごとに分けてインデックス登録させたいので、"Advanced settings"をクリックして、Chunking Strategyに"no chunks"を選択したら"Next"をクリック。

Chunking Strategyはデフォルトだと300トークン単位で分割される。チャンクサイズを指定することもできて、その場合はオーバーラップのサイズも指定できる。デフォルトにはオーバーラップの設定は記載されていないようなので、チャンクサイズ・オーバーラップサイズを指定してチャンク分割する方が一般的に検索ヒット率は高くなるのではないかなーと思う、知らんけど。
"no chunks"の場合はファイル単位でチャンク分割しないことになるが、RAGでプロンプトに含める場合に、何件含めて、最終的な入力トークンサイズがどれぐらいになるか?を意識した上でファイル分割しておく必要はあると思う(とはいえClaude v2であれば入力トークンはかなり大きいのであまり気にしなくてもいいかもしれないけど)
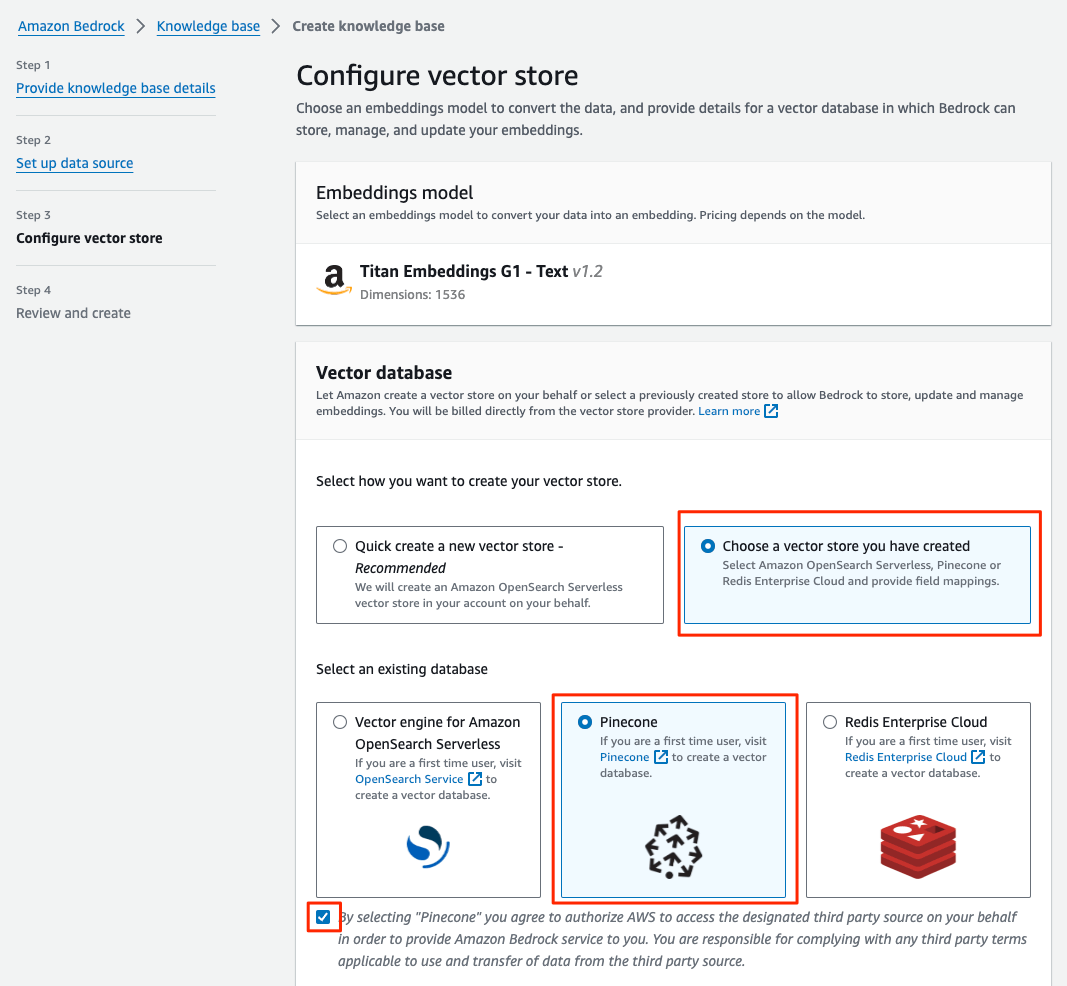
ベクトルストアの設定。ここは準備した通りPineconeを使うので、まず、以下のように選択。
続けて、必要事項を入力。
- Connection String: PineconeのインデックスのURLを入力
- Credentials secret ARN: Secret Managerに登録したPinecone APIキーのARNを入力
Metadata field mappingのところだけども、ここに入力した値がPineconeのインデックスのフィールド名となる、というだけの話で、あまり深く考えなくて良いと思う。というか、実際に作ってみればわかる。
- Text field
- ベクトル化されるテキストが入るフィールド名
- 今回は"text"と設定
- Bedrock-managed metadata field
- ベクトル化されるデータのメタデータが入るフィールド名。
- 今回は"metadata"と設定
入力したら"Next"をクリック。

設定内容を確認したら、"Create knowledge base"をクリックして作成。
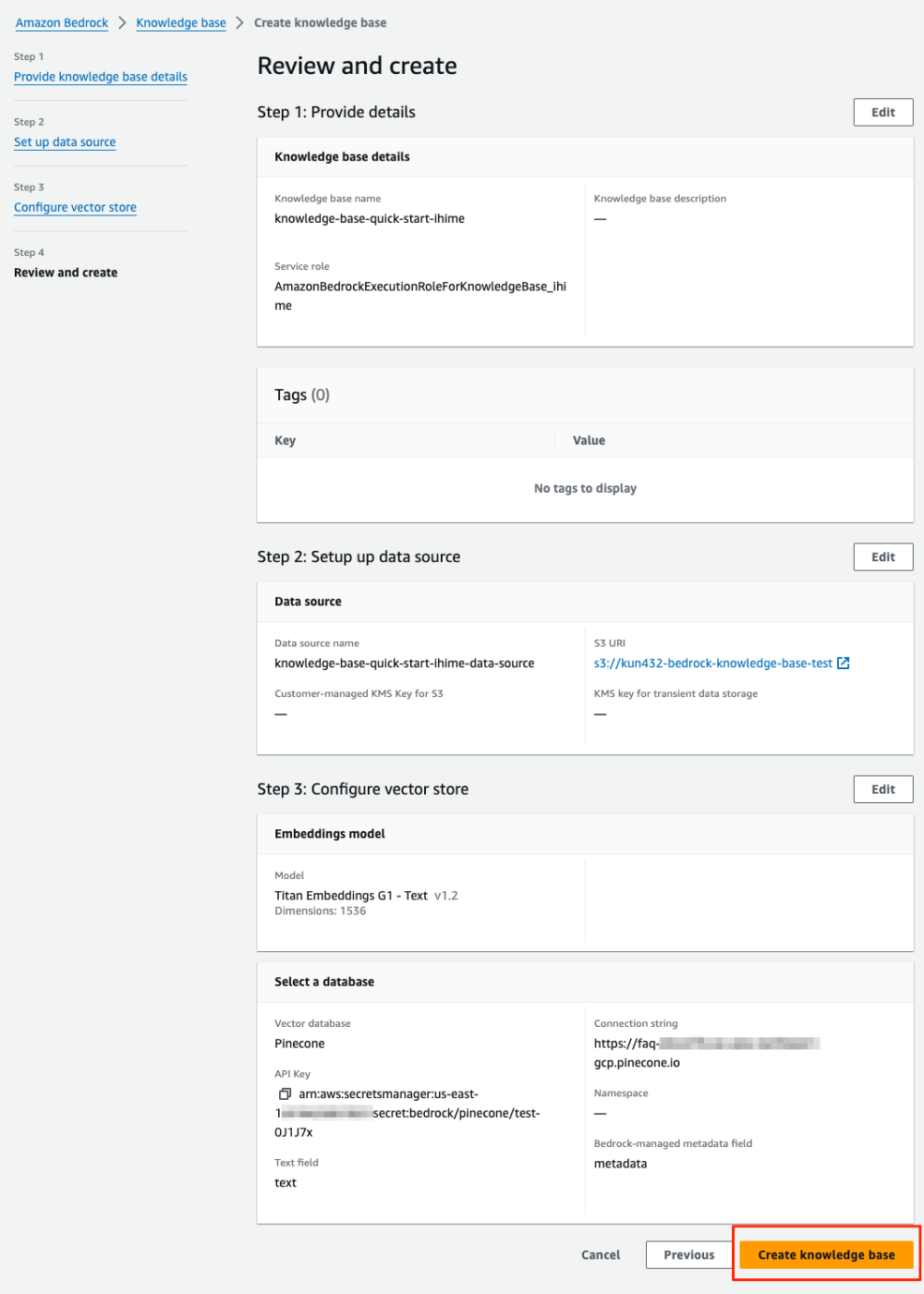
Knowledge baseが作成された。ただし作成直後はまだデータが読み込まれておらず、インデックスにも登録されていない状態なので、"Sync"をクリックしてインデックス化を開始する。インデックス化には少し時間がかかるので待つ。

以下のようにLast Syncが更新されてStatusがReadyになればSync完了。

設定を見ると、きちんと全部のファイルがインデックス化されているのがわかる。

Pinecone側にもインデックスが登録されていることがわかる。

Knowledge baseで作成した Text field("text") とBedrock-managed metadata field("metadata")はともにメタデータとして登録されている。そのうちmetadata fieldはどうやらオブジェクトのS3 URLが「source(情報源)」として登録される模様。どうせならここにもうちょっといろいろな情報を入れたいところなのだけど、現状は固定・決め打ちなのかな・・・?
ではテストしてみる。Knowledge baseの画面Ⅱ表示されているTest knowledge baseの"Select Model"をクリック。
テキスト生成モデルの選択を行う。現時点ではAnthropicのClaude Instant 1.2 / Claude 2しか選択できない模様。Claude 2 (オンデマンド)を選択。

質問してみるとこんな感じで回答が返ってくる。
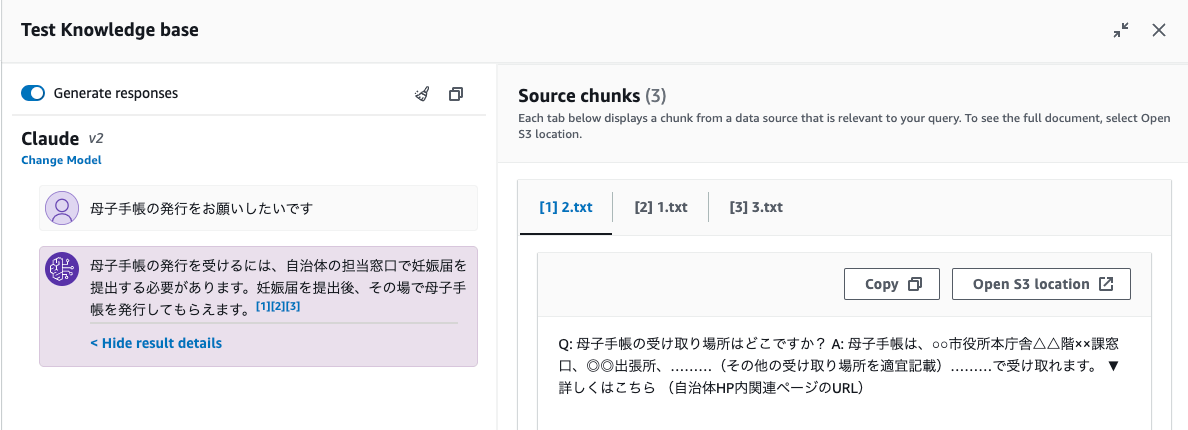
今回の場合は3つのコンテキストから回答が生成された模様。
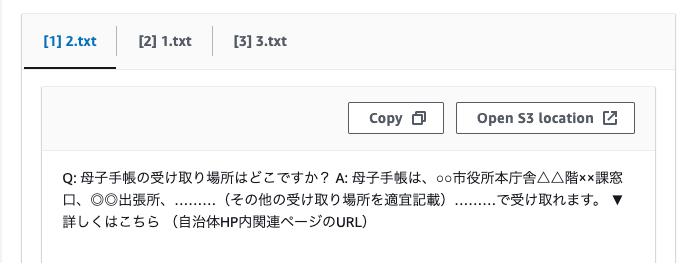
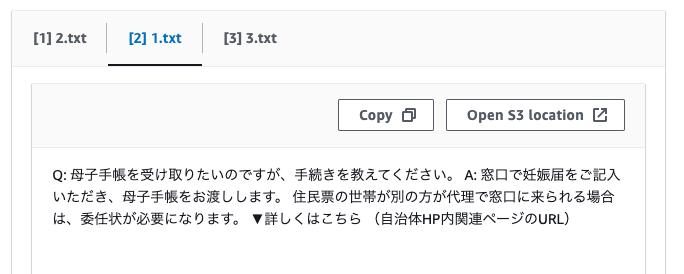

なんとなく会話のコンテキストも維持されているのかな?
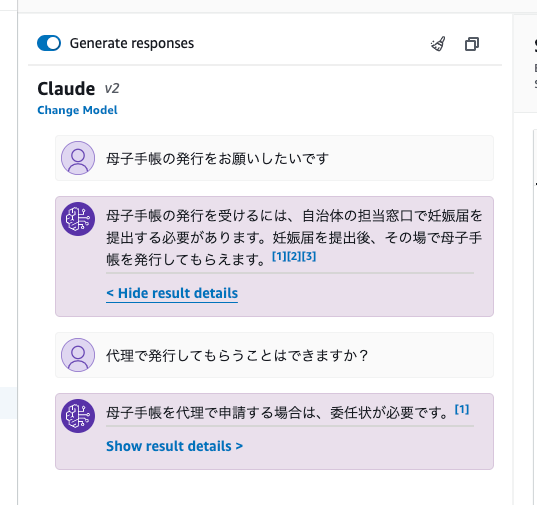
実際のアプリケーションまでは作ってないのでわからないけど、
- S3にデータを置いてSyncするだけで、ベクトル化ができるのは楽ちん。
- ベクトル化のプロセスは、データのベクトル化と入力クエリのベクトル化の2回必要になるが、そこはおそらく意識しなくて良さそうなのは楽ちん。
- このあたりがノーコードでできるのは楽ちん。
あたり、全体的にお手軽にできるので良さそう。
RAGは通常2つのステージから構成される。
- Indexing Stage
- ナレッジベース(ドキュメントのチャンク分割、ベクトル化、ベクトルストアへ保存)を作成
- Querying Stage
- クエリを元にナレッジベースから関連性の高いコンテキストを検索、それを元にLLM二回答を生成させる
Indexing Stageでは、通常こうなり、ほとんどの部分を構築する必要がある。

Knowledge baseだと、一度フローを作ってしまえば、あとは、単にファイルをアップロードしてSyncするだけになる。

Querying Stageでは、通常こういう流れになる。

この流れの以下の部分、

これをKnowledge baseが肩代わりしてくれる感じ。
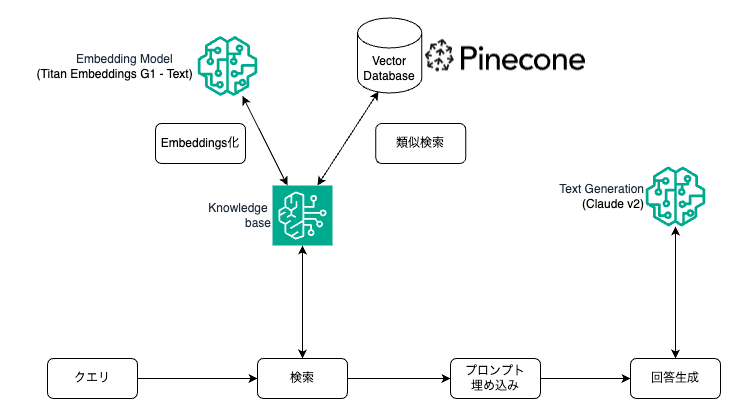
アプリケーションとしては検索と生成だけを考えればいい。検索が疎になっているのもシンプルで良い。
その反面、
- チャンク分割はサイズでしかできない。コンテキストを意識したチャンク分割等をやるには、前処理を自分でやる必要がある。
- あくまでもPineconeの場合だけなのかもしれないけど、メタデータで細かい設定ができない。例えばメタデータのpre-filteringとか(そもそもPineconeってpre-filteringとかできたっけ???)
- 他の方式(OpenSearch ServerlessとかRedis Enterprise)は未確認だけど、ちょっとコスト的に高そう。
あたリの細かいところには現時点では手が届かないようなので、メタデータを細かく設定したい、とか、精度をもっと上げるための工夫をしたいとかになると、やや厳しい感があり、自前でやったほうが良差そうな気もする。
この後、コード書いて試してみる予定。
コードで書くならばこのあたりが参考になる。見てる限り、ベクトル化プロセスはKnowledge baseがラップしてくれるようなので、単にクエリ投げれば検索結果だけ返ってくるような感じに見える。この点はらくちんかも。
今回のようなデータの場合に、
- コンテキストを意識してファイル分割する
- チャンク分割をKnowledge baseにおまかせする
でどれぐらい精度に差が出るか?はやってみないとわからない。個人的な経験則だと前者だとは思うのだけども。
claudeの場合はこういう話もあるので、プロンプトのテンプレートはきちんと設定するといいね。入力トークンでかいからといってそのまま渡しても良い結果はでないみたいだし。
制約というほどのものでもないけど以下には注意。データソースが少なくとも現時点では1つしか設定できないってのはちょっとネックかも。
コードでアクセスしてみる。まずは、Bedrock単体で普通に使ってみる。以下を参考に。
Claude-2.1を使ってみた。
import json
from string import Template
import boto3
client = boto3.client("bedrock-runtime", region_name="us-east-1")
query = "富士山の高さは?"
prompt_template = """
Human: ${query}
Assistant:
"""
prompt = Template(prompt_template).substitute(query=query)
body = json.dumps(
{
"prompt": prompt,
"max_tokens_to_sample": 500,
}
)
response = client.invoke_model(
modelId="anthropic.claude-v2:1",
body=body
)
answer = response["body"].read().decode()
print(json.loads(answer)["completion"])
富士山の高さは3,776メートルです。
ストリームで受け取る場合はinvoke_model_with_response_streamを使う。
import json
from string import Template
import boto3
client = boto3.client("bedrock-runtime", region_name="us-east-1")
query = "富士山の高さは?"
prompt_template = """
Human: ${query}
Assistant:
"""
prompt = Template(prompt_template).substitute(query=query)
body = json.dumps(
{
"prompt": prompt,
"max_tokens_to_sample": 500,
}
)
response = client.invoke_model_with_response_stream(
modelId="anthropic.claude-v2:1",
body=body
)
stream = response.get('body')
if stream:
for event in stream:
chunk = event.get('chunk')
if chunk:
print(json.loads(chunk.get('bytes').decode()))
{'completion': ' ', 'stop_reason': None, 'stop': None}
{'completion': '富士山の高さは3,776メ', 'stop_reason': None, 'stop': None}
{'completion': 'ートルです。\n\n人気の山と', 'stop_reason': None, 'stop': None}
{'completion': 'して知られる富士山は、その', 'stop_reason': None, 'stop': None}
{'completion': 'すがたと高', 'stop_reason': None, 'stop': None}
{'completion': 'さが特徴的な山です。', 'stop_reason': None, 'stop': None}
{'completion': '頂上からの景', 'stop_reason': None, 'stop': None}
{'completion': '色も絶景で、', 'stop_reason': None, 'stop': None}
{'completion': '多くの人が登山を', 'stop_reason': None, 'stop': None}
{'completion': '楽しんでいますね', 'stop_reason': None, 'stop': None}
{'completion': '。', 'stop_reason': 'stop_sequence', 'stop': '\n\nHuman:', 'amazon-bedrock-invocationMetrics': {'inputTokenCount': 19, 'outputTokenCount': 88, 'invocationLatency': 3037, 'firstByteLatency': 325}}
Knowledge baseを使ったRAG
Knowledge baseを使う場合は、bedrock-runtimeではなくbedrock-agent-runtimeを使う。
bedrock-agent-runtimeには、Knowledge baseの検索結果だけを返すretrieveと、Knowledge baseの検索結果を踏まえてLLMの回答も生成して返すretrieve_and_generateがある。
retrieve
import json
import boto3
client = boto3.client('bedrock-agent-runtime', region_name="us-east-1")
query = "母子手帳の手続きについて教えて。"
response = client.retrieve(
knowledgeBaseId='XXXXXXXXXX',
retrievalQuery={
'text': query
},
retrievalConfiguration={
'vectorSearchConfiguration': {
'numberOfResults': 3
}
}
)
print(response)
レスポンスの中身はこんな感じ。
{
'ResponseMetadata': {
'RequestId': '37889456-8366-4130-9121-9bc2bb9554f3',
'HTTPStatusCode': 200,
'HTTPHeaders': {
'date': 'Tue, 26 Dec 2023 03:00:43 GMT',
'content-type': 'application/json',
'content-length': '2306',
'connection': 'keep-alive',
'x-amzn-requestid': '37889456-8366-4130-9121-9bc2bb9554f3'
},
'RetryAttempts': 0
},
'retrievalResults': [
{
'content': {
'text': 'Q: 母子手帳はすぐに発行してもらえますか?\nA: 母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'
},
'location': {
'type': 'S3', 's3Location': {
'uri': 's3://kun432-bedrock-knowledge-base-test/faq/3.txt'
}
},
'score': 0.8313173055648804
},
{
'content': {
'text': 'Q: 母子手帳は転出してもそのまま持っていてよいですか?\nA: 母子手帳は住所が変わってもそのままお使いいただけます。再発行等の手続は必要ありません。\n\n◆お問い合わせ\n(自治体の担当課や子育てセンター等の名称)\n(電話番号)/(開庁時間)'
},
'location': {
'type': 'S3',
's3Location': {
'uri': 's3://kun432-bedrock-knowledge-base-test/faq/165.txt'
}
},
'score': 0.8241762518882751
},
{
'content': {
'text': 'Q: 母子手帳を受け取りたいのですが、手続きを教えてください。\nA: 窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'
},
'location': {
'type': 'S3',
's3Location': {
'uri': 's3://kun432-bedrock-knowledge-base-test/faq/1.txt'
}
},
'score': 0.8041664361953735
},
{
'content': {
'text': 'Q: 母子手帳の受け取り場所はどこですか?\nA: 母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'
},
'location': {
'type': 'S3',
's3Location': {
'uri': 's3://kun432-bedrock-knowledge-base-test/faq/2.txt'
}
},
'score': 0.7881890535354614
}
]
}
RAGで使う場合には、bedrock-runtimeと組み合わせる。Claudeのプロンプト、あまりふれたことがなかったのだけど、以下を参考に作ってみた。果たして適切かどうかはそこまで使い込んでないのでわからないけども。
あと、Claude v2.1からはsystemプロンプトも使えるのでそれも使ってみた。
import json
from string import Template
import textwrap
import boto3
region = "us-east-1"
client = boto3.client("bedrock-runtime", region_name=region)
agent_client = boto3.client('bedrock-agent-runtime', region_name=region)
context_template = """<document id=${id}>
<score>${score}</score>
<text>${text}</text>
</document>
"""
prompt_template = """
System: あなたは、自治体が運営する、子育てに関するFAQに答えるチャットボットです。以下の制約とドキュメント情報を元に、ユーザーからの質問に回答してください。
<constraints>
<constraint>回答はドキュメント情報に基づいた事実である必要があります。事実に基づいていない回答を生成してはいけません。</constraint>
<constraint>ドキュメント情報は、質問に基づいてデータベースから検索された結果です。必ずしも質問結果に沿ったものではないという点を理解してください。</constraint>
<constraint>回答するための情報が不足している場合は、ユーザーに追加質問を行ってください。</constraint>
<constraint>回答がわからない場合は、回答できないと答えてください。</constraint>
</constraints>
<documents>
${context}
</documents>
Human: ${query}
Assistant: """
query = "母子手帳の手続きについて教えて"
search_response = agent_client.retrieve(
knowledgeBaseId='XXXXXXXXXX',
retrievalQuery={
'text': query
},
retrievalConfiguration={
'vectorSearchConfiguration': {
'numberOfResults': 3
}
}
)
contexts = []
if len(search_response["retrievalResults"]):
for i, obj in enumerate(search_response["retrievalResults"], start=1):
context = Template(context_template).substitute(id=i, score=obj["score"], text=obj["content"]["text"])
contexts.append(context)
context = textwrap.indent(textwrap.dedent("".join(contexts))[:-1], ' ')
prompt = Template(prompt_template).substitute(query=query, context=context)
print(prompt)
body = json.dumps(
{
"prompt": prompt,
"max_tokens_to_sample": 500,
}
)
response = client.invoke_model(
modelId="anthropic.claude-v2:1",
body=body
)
answer = response["body"].read().decode()
print(json.loads(answer)["completion"])
母子手帳を受け取る手続きについて、資料に以下のような情報があります。
母子手帳は、妊娠届の内容を確認させていただいた上で、その場で発行してお渡ししています。
代理での手続きの場合は、委任状が必要となります。
詳細は自治体のホームページ(URL)をご確認ください。
ご不明な点があれば、追加でご質問いただければと思います。
retrieve_and_generate
retrieve_and_generateを使えば、上記のようなretrieve→generateをワンステップで済ませることができる。
import json
from string import Template
import boto3
client = boto3.client('bedrock-agent-runtime', region_name="us-east-1")
query = "母子手帳の手続きについて教えて。"
response = client.retrieve_and_generate(
input={
'text': query
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': 'XXXXXXXX',
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2'
}
}
)
print(response["output"]["text"])
母子手帳の手続きは、まず妊娠届を自治体の担当窓口に提出する必要があります。妊娠届を提出すると、その場で母子手帳を発行してもらえます。 母子手帳の受け取り場所は、自治体の本庁舎や支所・出張所の窓口です。詳細は自治体のHPを確認すると良いでしょう。
responseの中身はこうなっている。
{
'ResponseMetadata': {
'RequestId': '97071099-6a49-4696-9f92-3ff2490abe5b',
'HTTPStatusCode': 200,
'HTTPHeaders': {
'date': 'Tue, 26 Dec 2023 02:15:03 GMT',
'content-type': 'application/json',
'content-length': '2233',
'connection': 'keep-alive',
'x-amzn-requestid': '97071099-6a49-4696-9f92-3ff2490abe5b'
},
'RetryAttempts': 0
},
'sessionId': '54a7b013-7f83-482d-ae03-4b81165bf1e7',
'output': {
'text': '母子手帳の手続きは、まず妊娠届を自治体の担当窓口に提出する必要があります。妊娠届を提出すると、その場で母子手帳を発行してもらえます。 母子手帳の受け取り場所は、自治体の本庁舎や支所・出張所の窓口です。詳細は自治体のHPを確認すると良いでしょう。'
},
'citations': [
{
'generatedResponsePart': {
'textResponsePart': {
'text': '母子手帳の手続きは、まず妊娠届を自治体の担当窓口に提出する必要があります。妊娠届を提出すると、その場で母子手帳を発行してもらえます。',
'span': {
'start': 0,
'end': 65
}
}
},
'retrievedReferences': [
{
'content': {
'text': 'Q: 母子手帳はすぐに発行してもらえますか?\nA: 母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'
},
'location': {
'type': 'S3',
's3Location': {
'uri': 's3://kun432-bedrock-knowledge-base-test/faq/3.txt'
}
}
},
{
'content': {
'text': 'Q: 妊娠したので、必要な手続きを教えてください。\nA: 妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'
},
'location': {
'type': 'S3',
's3Location': {
'uri': 's3://kun432-bedrock-knowledge-base-test/faq/450.txt'
}
}
}
]
},
{
'generatedResponsePart': {
'textResponsePart': {
'text': '母子手帳の受け取り場所は、自治体の本庁舎や支所・出張所の窓口です。詳細は自治体のHPを確認すると良いでしょう。',
'span': {
'start': 67,
'end': 121
}
}
},
'retrievedReferences': [
{
'content': {
'text': 'Q: 母子手帳の受け取り場所はどこですか?\nA: 母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'
},
'location': {
'type': 'S3',
's3Location': {
'uri': 's3://kun432-bedrock-knowledge-base-test/faq/2.txt'
}
}
}
]
}
]
}
生成した文章のそれぞれがどのドキュメントの内容に基づいているのか?がわかる。
プロンプトをカスタマイズしたい場合は、クエリを含んだプロンプトを作って渡してやれば良いのかな?
import json
from string import Template
from pprint import pprint
import boto3
client = boto3.client('bedrock-agent-runtime', region_name="us-east-1")
query = "母子手帳の手続きについて教えて。"
prompt_template = """
Human: 以下の質問にフレンドリーに答えてください。絵文字もたくさん使ってください。
${query}
Assistant:
"""
prompt = Template(prompt_template).substitute(query=query)
response = client.retrieve_and_generate(
input={
'text': prompt
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': 'XXXXXXXXXX',
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2:1'
}
}
)
print(response["output"]["text"])
妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。詳しくはこちらをご覧くださいね。😊
レスポンスの中身を見てみると以下となっていた。
{
'ResponseMetadata': {
'RequestId': 'ab277ef2-095a-4bb6-8267-11203f6e5d62',
'HTTPStatusCode': 200,
'HTTPHeaders': {
'date': 'Wed, 03 Jan 2024 07:34:12 GMT',
'content-type': 'application/json',
'content-length': '986',
'connection': 'keep-alive',
'x-amzn-requestid': 'ab277ef2-095a-4bb6-8267-11203f6e5d62'
},
'RetryAttempts': 0
},
'sessionId': 'e049797d-cb48-499e-8692-c22f62c8bf22',
'output': {
'text': '妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。詳しくはこちらをご覧くださいね。😊'
},
'citations': [
{
'generatedResponsePart': {
'textResponsePart': {
'text': '妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。詳しくはこちらをご覧くださいね。😊',
'span': {
'start': 0,
'end': 64
}
}
},
'retrievedReferences': [
{
'content': {
'text': 'Q: 妊娠したので、必要な手続きを教えてください。\nA: 妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'
},
'location': {
'type': 'S3',
's3Location': {
'uri': 's3://kun432-bedrock-knowledge-base-test/faq/450.txt'
}
}
}
]
}
]
}
うん、プロンプトを渡しても問題なさそう。これだとかなりシンプルに書けるなー。
ただし、お手軽な反面、LangChainやLlamaIndexのように検索部分のロジックを細かくいじったりってのはできなさそうなので、ここに関しては完全にお任せになる点には注意したほうがよいかもね。
所感
Knowledge base + AgentsforBedrockRuntime の retrieve_and_generateメソッドを使えば、かなりシンプルに書けるのは良い。ただし、
- retrieve_and_generateを使うと検索部分のロジックはKnowledge baseにお任せになる。精度を上げるにはretrieve_and_generateを使わずにretrieveを使って自分で処理する必要がある。
- Knowledge baseのチャンク分割はUnstructuredなドキュメント向け。精度を上げるためにチャンク分割をどうするか?のオプションは少ない。
あたりについては、RAGの精度向上に向けていろんな手法が出てきている中で、そういった手法を取り入れる余地は殆どないように思える。
とはいえこのあたりはトレードオフなところもあると思う(精度を上げるために色々な工夫をすることで、ベクトルDBの更新も手間がかかるし、検索ロジックも複雑化する)ので、要件を踏まえて検討すれば良いとは思う。
とりあえず、シビアな精度を求められず、運用にあまり手をかけたくない、例えば社内のドキュメント入れて社内向けに使うとかなら良さそう。GoogleドライブのコンテンツをS3に同期するような仕組みがあればいいんじゃないかな
おまけ
この辺も大事
Knowledge Base作成時にお任せでIAMロール作成した場合の設定を見てみた。以下はPineconeをベクトルDBに使った場合。
-
AmazonBedrockExecutionRoleForKnowledgeBase_XXXXXというIAMロールが作成される - 上記IAMロールに以下の3つの許可ポリシーが付与される
-
AmazonBedrockFoundationModelPolicyForKnowledgeBase_XXXXX- knowledge baseで使うembeddingモデルの呼び出しを許可
-
AmazonBedrockS3PolicyForKnowledgeBase_XXXXX- データソースで使用するS3バケットへのアクセスを許可
-
AmazonBedrockSecretsPolicyForKnowledgeBase_XXXXX- PineconeにアクセスするためのAPIキーを保持しているSecret Managerの該当のシークレットへのアクセスを許可
-
embeddingモデル・S3バケット・ベクトルDB(opensearchとか)が違えば設定も変わってくるとは思うし、毎回作ってもいい気はするんだけども、自分の場合はお試しでknowledge baseいろいろ作ってたら似たようなIAMロールたくさんできて無駄な感じがしたので、予め先に作っておいて管理したい感があったので。
2024/09/19追記
細かく書いてなかったので改めて。見た感じ、ベクトルDBやデータソースによって色々変わってきそう。でもまあこれをあらかじめ用意するってのはちょっと面倒な気もしている。
IAMポリシー
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockInvokeModelStatement",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": [
"arn:aws:bedrock:us-west-2::foundation-model/cohere.embed-multilingual-v3"
]
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3ListBucketStatement",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::[S3バケット名]"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"123456789012"
]
}
}
},
{
"Sid": "S3GetObjectStatement",
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::[S3バケット名]/[プリフィックス]"
],
"Condition": {
"StringEquals": {
"aws:ResourceAccount": [
"123456789012"
]
}
}
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SecretsManagerGetStatement",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
"arn:aws:secretsmanager:us-west-2:123456789012:secret:bedrock/pinecone/XXXXXXXX"
]
}
]
}
上記ポリシーがアタッチされたIAMロール
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AmazonBedrockKnowledgeBaseTrustPolicy",
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "123456789012"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:bedrock:us-west-2:123456789012:knowledge-base/*"
}
}
}
]
}