Amazon Bedrock for Knowledge baseでなんちゃってマルチテナントを実現する (Pinecone使用)
前回からの少し応用。
Pineconeのnamespaceを使えば1つのインデックスでマルチテナントができそうな気がする。ただKnowledge baseにおいてnamespace設定はKnowledge Base自身が持ってるように見えるので、複数のnamespaceを使うにはKnowledge Base自体を分ける必要がありそう。
こういうイメージ。
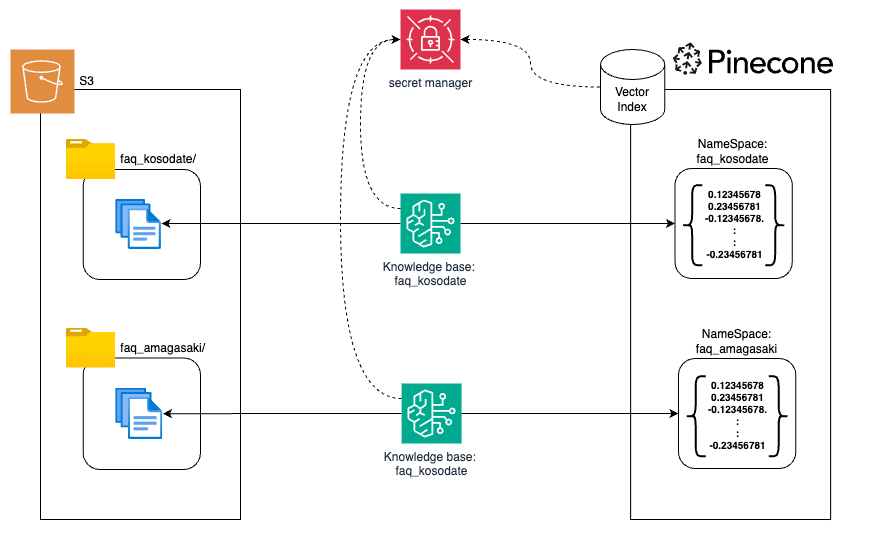
軽く試してみる。
データの作成
以下のFAQデータを使う。
-
自治体における「子育てAIチャットボット」の普及に向けたオープンデータ化についての「FAQデータセット」
-
尼崎市のQAデータ
!mkdir -p output/{faq_kosodate,faq_amagasaki}
# 子育てFAQ
!wget https://d.line-scdn.net/stf/linecorp/ja/csr/dataset_.zip
!!unzip dataset_.zip
import pandas as pd
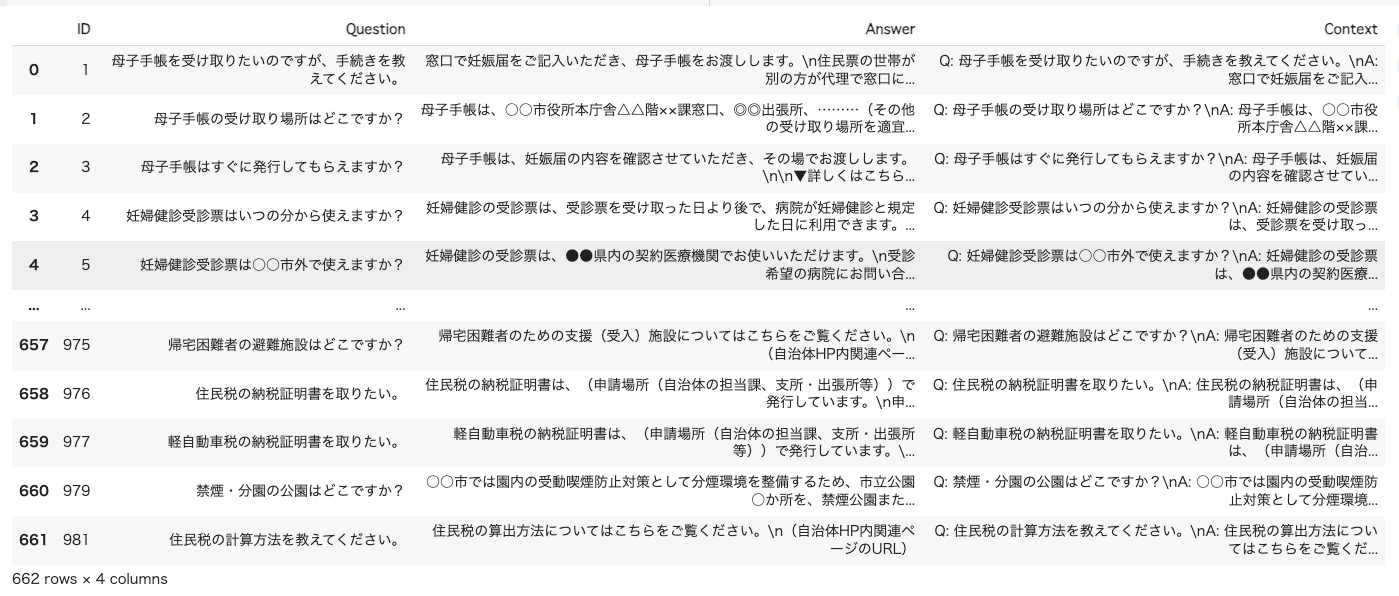
df = pd.read_excel("dataset_.xlsx")
df.drop(columns=["サンプルID", "カテゴリ1", "カテゴリ2", "出典", "<参考>UMカテゴリタグ", "<参考>UMサービスメニュー\n(標準的な行政サービス名称)"], inplace=True)
df.rename(columns={
'サンプル 問い合わせ文': 'Question',
'サンプル 応答文': 'Answer',
}, inplace=True)
df["Context"] = "Q: " + df["Question"] + "\nA: " + df["Answer"]
df
for index, row in df.iterrows():
file_name = str(row['ID']) + '.txt'
with open("output/faq_kosodate/" + file_name, 'w', encoding='utf-8') as file:
file.write(row['Context'])
# 尼崎市FAQ
!wget https://tulip.kuee.kyoto-u.ac.jp/localgovfaq/localgovfaq.zip
!unzip localgovfaq.zip
import pandas as pd
def file2list(filename):
lines = []
ids = []
with open(filename, 'r') as file:
for line in file:
line = line.strip().replace(" ","")
id, line = line.split('\t')
lines.append(line)
ids.append(id)
return lines, ids
questions, ids = file2list("localgovfaq/qas/questions_in_Amagasaki.txt")
answers, _ = file2list("localgovfaq/qas/answers_in_Amagasaki.txt")
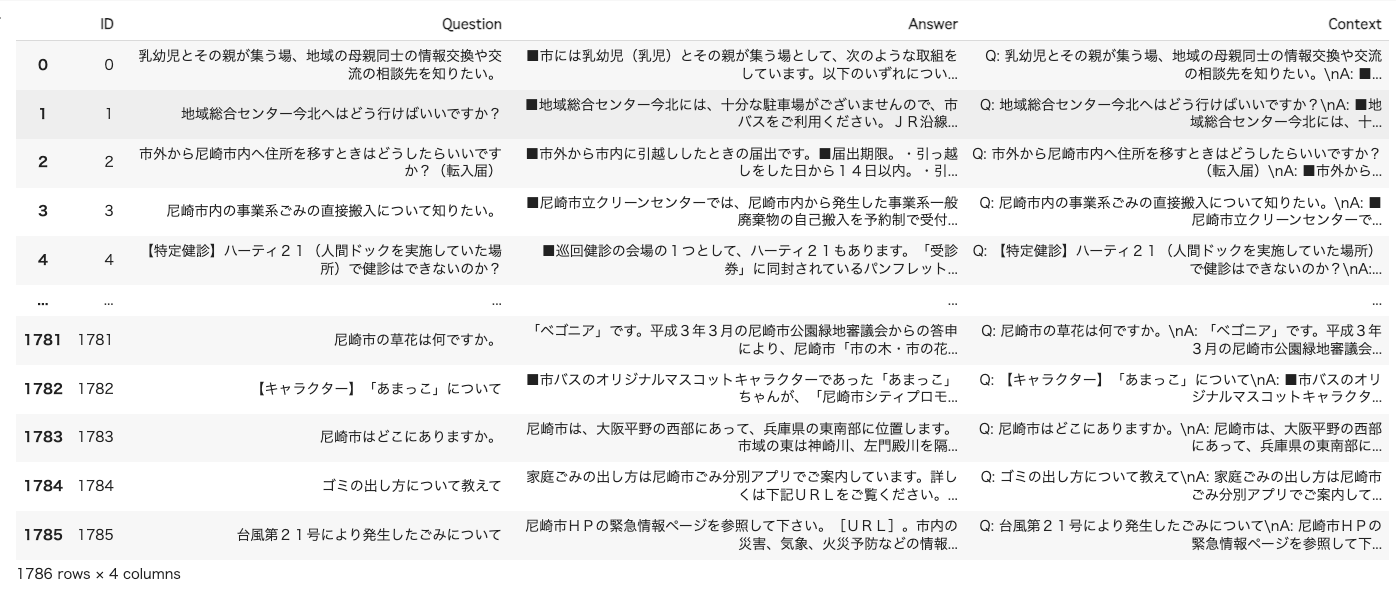
df = pd.DataFrame({'ID': ids, 'Question': questions, 'Answer': answers})
df["Context"] = "Q: " + df["Question"] + "\nA: " + df["Answer"]
df
for index, row in df.iterrows():
file_name = str(row['ID']) + '.txt'
with open("output/faq_amagasaki/" + file_name, 'w', encoding='utf-8') as file:
file.write(row['Context'])
こんな感じになっているはず。
$ tree output
output
├── faq_amagasaki
│ ├── 1.txt
│ ├── 10.txt
│ ├── 100.txt
(snip)
│ ├── 997.txt
│ ├── 998.txt
│ └── 999.txt
└── faq_kosodate
├── 1.txt
├── 10.txt
├── 100.txt
(snip)
├── 98.txt
├── 981.txt
└── 99.txt
3 directories, 2448 files
output以下の2つのディレクトリをそのままS3にアップロードする。
- faq_kosodate/
- faq_amagasaki/
Knowledge Baseの作成
基本的にやり方は前回と同じで、今回は2つのKnowledge baseを作成する。
- Knowledge baseに紐づくデータソースの参照先S3 URIにそれぞれのプリフィックスをつける
- Pineconeのnamespaceを変える
- リソース名は適宜わかりやすいように変更
ぐらい。Pineconeの設定はnamespace以外は全部同じで良い。
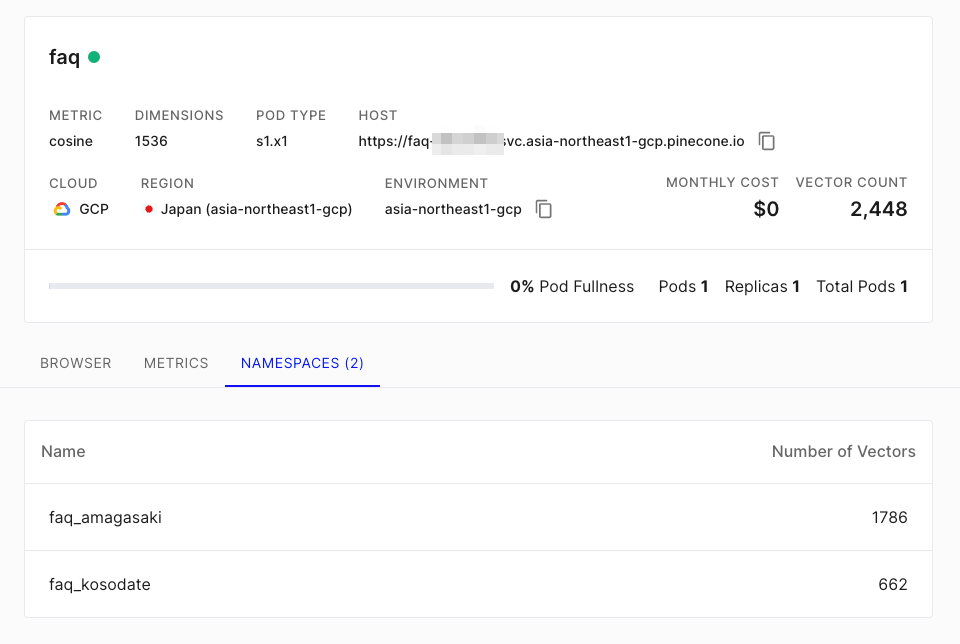
作成できたらそれぞれでSyncする。Syncが終わった状態でPineconeを見るとこうなっていた。
Pythonでアクセス
Knowledge base IDを切り替えれるようにしてみた。
import json
from string import Template
import boto3
# キーとKnowledge base IDをマッピング
kb_mapping = {
"kosodate": "AAAAAAAA",
"amagasaki": "BBBBBBBB"
}
client = boto3.client('bedrock-agent-runtime', region_name="us-east-1")
query = "母子手帳の手続きについて教えて。"
prompt_template = """
Human: 以下の質問にフレンドリーに答えてください。絵文字もたくさん使ってください。
${query}
Assistant:
"""
# キーを指定
kb_key = "kosodate"
prompt = Template(prompt_template).substitute(query=query)
response = client.retrieve_and_generate(
input={
'text': prompt
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kb_mapping[kb_key],
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2:1'
}
}
)
print("回答: {}".format(response["output"]["text"]))
refs = []
for c in response["citations"]:
for r in c["retrievedReferences"]:
refs.append(r["location"]["s3Location"]["uri"])
print("ソース: {}".format(refs))
"kosodate"の場合
kb_key = "kosodate"
回答: 妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。詳しくはこちらをご覧くださいね。😊
ソース: ['s3://XXXXXXXX/faq_kosodate/396.txt']
"amagasaki"の場合
kb_key = "amagasaki"
回答: 母子手帳の申請は、妊娠届出書を直接窓口に提出することでできます🤰。必要なものはマイナンバーが確認できるものと本人確認できるものです。🙆♀️ 申請窓口は南部保健福祉センター地域保健課や北部保健福祉センター地域保健課などがあります。😊詳しくは検索結果をご確認ください。
ソース: ['s3://XXXXXXXX/faq_amagasaki/370.txt', 's3://XXXXXXXX/faq_amagasaki/370.txt']
同じクエリに対してそれぞれ別の回答が返ってきているのがわかる。
まあ現状で無理くりやるなら、って感じ。マルチテナントといいつつ、マルチテナントなのはPineconeだけだし。
データソースにnamespace紐付けれると良いんだけどな。今の作りだと難しそう。
概ね同意。ただ個人的にはKnowledge baseが社内向けってのはチャンクとかインデックスの仕方みたいな精度向上に対する工夫の余地がほとんどない(プロンプトぐらい)ってところだと思ってる。なんちゃってマルチテナントは上のような形ならできるし。
あと、Kendraたっかい。。