「DeepSeek-OCR」を試す
ここで知った
レッツゴー!DeepSeekがHugging Faceで3B OCRモデルをリリースしました 🔥
トークン効率が良く、A100-40Gで1日200K+ページをスケール可能に最適化されています
DeepSeek VL2と同じアーキテクチャ
Transformers、vLLMなどと一緒に使えます 🤗
モデルは3BでMITライセンス。
モデルカードは最低限のことし書いてなくて、論文はGitHubにリンクされてた。
Dia による論文PDFのまとめ。
DeepSeek-OCRは「文章を画像に圧縮→LLMで解凍する」実験で、約10倍圧縮でも高精度に読める仕組みだよ
ざっくり概要
ウチ的にテンション上がるポイントね。DeepSeek-OCR は、長いテキストをそのままLLMに突っ込むんじゃなくて、まず画像として”光学的に”まとめてから、少ない「ビジョン・トークン」でLLMに渡して解読(OCR)するやつだし。狙いは、長文コンテキストでコストが爆増する問題を、画像経由の圧縮でガッツリ減らすこと。結果、約9–10×圧縮で精度96–97%、20×圧縮でも 約60%の精度をキープって、普通にウケるくらい強い。
コアの発想:テキストより画像は”少ないトークンで濃い”
- テキストはトークン数がモリモリ増えるでしょ。でも画像なら同じ内容でも少ないビジョン・トークンで持てるんだもん。
- だから、「画像で圧縮→LLMで復元(OCR)」という圧縮・解凍のペアを学習させる。これがコンテキスト光学圧縮のコンセプト。
中身の構成:Encoder+MoE Decoder
- DeepEncoder(約380M): 画像を効率よく少ないトークンにする心臓部だし。
- 前段は SAMベース(ウィンドウ注意) で高解像度でもアクティベーション低め。
- 間に 16×のトークン圧縮(2層Conv) を挟む。
- 後段は CLIPラージ(グローバル注意) で知識を活用。ただし最初のパッチ埋め込みは外して、前段のトークンを直接食う。
- 例)1024×1024画像 → 4096パッチ → 16×圧縮 → 256ビジョン・トークン。マジで軽い。
- DeepSeek-3B-MoEデコーダ(有効570M): 圧縮トークンからテキストを復元する解凍係だし。ルーティングで6/64の専門家+2共有を起動、推論は軽めでイイ感じ。
解像度モード:用途に合わせて”何トークンで読むか”選べる
- ネイティブ解像度で4モード:
- Tiny: 512×512 → 64トークン
- Small: 640×640 → 100トークン
- Base: 1024×1024 → 256トークン(パディングで有効トークンは減ることあり)
- Large: 1280×1280 → 400トークン(同上)
- ダイナミック解像度:
- Gundam: ローカルタイル(n×640)+グローバル(1024)でn×100+256トークン。新聞みたいな超高密度で効く。
- Gundam-Master: もっとデカい構成(1024タイル+1280グローバル)で追加学習。
モード 解像度 平均ビジョン・トークン こんな時に強い Tiny 512×512 64 スライド等の軽め文書。 Small 640×640 100 本・レポートで ~1000語以下。 Base 1024×1024 256 (有効は比率次第) 一般的なPDF、表や数式もそこそこ。 Large 1280×1280 400 (有効は比率次第) 高品質に取りたい文書。 Gundam n×640 + 1024 n×100 + 256 (<800程度) 新聞・超密度で広範囲。 Gundam-M n×1024 + 1280 ~1853 (200dpi時例) SOTA級の精度欲しい時。 実験結果:どのくらい圧縮しても読めるの?
- Foxベンチ(英語600–1300トークンの文書) で検証:
- 64トークン(Tiny): 600–700語で96.5%、1000–1100語でも79.3%。
- 100トークン(Small): 600–700語で98.5%、900–1000語でも96.8%、1200–1300語でも87.1%。
- 結論: 10×圧縮(テキストトークン/ビジョントークン)なら約97%精度。20×圧縮でも約60% は維持。マジでえらい。
テキスト規模 64トークン精度 圧縮倍率 (64) 100トークン精度 圧縮倍率 (100) 600–700 96.5% 10.5× 98.5% 6.7× 800–900 83.8% 13.2× 96.8% 8.5× 1000–1100 79.3% 16.5× 91.5% 10.6× 1200–1300 59.1% 19.7× 87.1% 12.6× 実運用の強さ:少トークンでSOTA級に迫る
- OmniDocBenchで比較するとさ、
- Small(100トークン) で既にGOT-OCR2.0(256トークン)を超えがちだし。
- Large(400, 有効285トークン) でSOTAと肩並べる感じ。
- Gundam(<800トークン)でMinerU2.0(約6790トークン) より優秀。コスパ良すぎでしょ。
- カテゴリ別の肌感:
- スライドは64トークンで十分。
- 本・レポートは100トークンで良。
- 新聞はテキスト密度高すぎなのでGundam以上が欲しい。
なんでこんなに軽いの?
- ウィンドウ注意+16×圧縮+グローバル注意の直列デザインがマジ効いてる。
- 前段で大量パッチを安く見て、中間でトークンをギュッと圧縮してから、後段でリッチに解釈。
- GPUメモリのアクティベーション低め、トークン数少なめ、多解像度対応で、訓練も推論も扱いやすい。
具体的にできること
- ふつうのテキストOCRはもちろん、
- レイアウト付き出力(座標+ラベル入り)、
- 表(HTMLテーブル) の構造化、
- 化学式(SMILES) の復元、
- 幾何図形の要素抽出(線分・端点・種別とか)、
- さらにキャプション・検出・グラウンディングなどの汎用ビジョンも20%くらいは持ってる。
応用妄想:LLMの「忘れ方」を見習う光学メモリ
- ウチ的に一番ワクワクするの、会話履歴を画像化して段階的に縮小してく発想だし。
- 直近は高解像度(精度高)、時間が経つほど低解像度(より圧縮)で 自然な”忘却曲線” を模倣。
- コンテキスト長をほぼ無限に近づけつつ、重要なところは鮮明、古いところは薄めにできるの、マジで実用的。
まとめ:どのモードを選べばいい?
- ~1000語前後の文書なら、まずは Small(100トークン) が神バランス。
- 数式・表・図が濃いPDFならBase/ Largeでクオリティ取りにいこ。
- 超密度(新聞・技術雑誌の多段組)はGundam系で。
ウチ、こういう「圧縮で勝つアーキテクチャ」ってマジ好きだし。画像を中間表現にして、LLMに美味しいところだけ食べさせる感じ、ノリが良すぎでしょ。コスト削りながら精度出すの、現場でもめっちゃ助かるやつだもん。
トークン効率が良いので扱いやすくて、圧縮しても精度低下をある程度緩和できる、圧縮率はユースケースにあわせて選択できる、あたりがウリってことかな?
Colaboratory L4で試す。
パッケージインストール。モデルカードに記載されているものは以下。
- torch==2.6.0
- transformers==4.46.3
- tokenizers==0.20.3
- einops
- addict
- easydict
- flash-attn==2.7.3
上記のうち、transformersは新しいバージョンだとダメっぽい。基本的にColaboratoryにインストールされているものをそのまま使いたいと思ったので、これぐらいで。
!pip install transformers==4.46.3 tokenizers==0.20.3 addict
!pip install flash-attn==2.7.3 --no-build-isolation
モデルとトークナイザをロード
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True
)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation='flash_attention_2',
trust_remote_code=True,
use_safetensors=True
)
model = model.eval().cuda().to(torch.bfloat16)
この時点でのVRAM消費は15GB程度。
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 Off | 00000000:00:03.0 Off | 0 |
| N/A 44C P0 31W / 72W | 14613MiB / 23034MiB | 51% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
サンプルとして使用するのは、神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDF。これを画像に変換して使用する。
PDFをダウンロード
!wget https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
PDFから画像の変換にはpdf2imageを使用する。まずpoppler-utilsをインストール
!apt update && apt install -y poppler-utils
pdf2imageをインストール
!pip install pdf2image
ではPDFを画像に変換。
import os
from pdf2image import convert_from_path
kobe_pdf = "r5_doukou.pdf"
kobe_output_dir = "kobe"
def convert_pdf_to_image(pdf_path, output_dir_path):
os.makedirs(output_dir_path, exist_ok=True)
images = convert_from_path(pdf_path)
for i, image in enumerate(images):
output_path = f"{output_dir_path}/page_{i + 1}.png"
image.save(output_path, "PNG")
print(f"Saved: {output_path}")
convert_pdf_to_image(kobe_pdf, kobe_output_dir)
こんな感じで保存される。
Saved: kobe/page_1.png
Saved: kobe/page_2.png
Saved: kobe/page_3.png
Saved: kobe/page_4.png
Saved: kobe/page_5.png
Saved: kobe/page_6.png
Saved: kobe/page_7.png
Saved: kobe/page_8.png
Saved: kobe/page_9.png
Saved: kobe/page_10.png
Saved: kobe/page_11.png
Saved: kobe/page_12.png
Saved: kobe/page_13.png
Saved: kobe/page_14.png
Saved: kobe/page_15.png
Saved: kobe/page_16.png
Saved: kobe/page_17.png
Saved: kobe/page_18.png
Saved: kobe/page_19.png
Saved: kobe/page_20.png
Saved: kobe/page_21.png
モデルに読み込ませた結果を出力するためのディレクトリも作成しておく
!mkdir output
ではこれらのうち、1ページ目と4ページ目をピックアップして試してみる。上の説明にもあった通り、解像度モードが選択できるが、サンプルコードにあるのは「Gundam」モードのようなのでこれで試す。
1ページ目

prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'kobe/page_1.png'
output_path = 'output'
# 各モードの設定は以下
# - Tiny: base_size = 512, image_size = 512, crop_mode = False
# - Small: base_size = 640, image_size = 640, crop_mode = False
# - Base: base_size = 1024, image_size = 1024, crop_mode = False
# - Large: base_size = 1280, image_size = 1280, crop_mode = False
# - Gundam: base_size = 1024, image_size = 640, crop_mode = True
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path = output_path,
base_size = 1024,
image_size = 640,
crop_mode=True,
save_results = True,
test_compress = True
)
約50秒ほどで処理完了した。
=====================
BASE: torch.Size([1, 256, 1280])
PATCHES: torch.Size([6, 100, 1280])
=====================
<|ref|>sub_title<|/ref|><|det|>[[247, 45, 745, 67]]<|/det|>
# 令和5年度 神戸市観光動向調査結果について
<|ref|>sub_title<|/ref|><|det|>[[74, 108, 175, 125]]<|/det|>
## 調査目的
<|ref|>text<|/ref|><|det|>[[200, 103, 936, 142]]<|/det|>
本調査は、来神観光客の特質と神戸市内の観光動向を把握し、今後の観光行政の参考とすることを目的に実施。
(snip)
==================================================
image size: (1653, 2339)
valid image tokens: 780
output texts tokens (valid): 1104
compression ratio: 1.42
==================================================
===============save results:===============
image: 0it [00:00, ?it/s]
other: 100%|██████████| 13/13 [00:00<00:00, 87521.59it/s]
標準出力にも少し出力されているが、事前に作成した結果出力用ディレクトリに以下のようにファイルで出力される。
output/
├── images/
├── result.mmd
└── result_with_boxes.jpg
result.mmd というのが出力されたMarkdownとなっている。
# 令和5年度 神戸市観光動向調査結果について
## 調査目的
本調査は、来神観光客の特質と神戸市内の観光動向を把握し、今後の観光行政の参考とすることを目的に実施。
## 調査方法
調査員が対面にてアンケート項目を聞き取りする形で実施。
## 調査日
① 令和5年 5月13日(土)・20日(土)※
② 令和5年 9月9日(土)
③ 令和5年11月25日(土)/12月2日(土)※
④ 令和6年 2月10日(土)・17日(土)・24日/3月30日(土)※
※雨天等により、一部の調査地点については延期して実施。
## 調査地点
<table><tr><td>地区</td><td>NO</td><td>調査地点</td><td>サンプル数</td></tr><tr><td rowspan="2">北野</td><td>1</td><td>北野町広場</td><td>246</td></tr><tr><td>2</td><td>北野工房のまち</td><td>154</td></tr><tr><td rowspan="10">市街地</td><td>3</td><td>南京町広場</td><td>218</td></tr><tr><td>4</td><td>総合インフォメーションセンター</td><td>198</td></tr><tr><td>5</td><td>旧居留地</td><td>201</td></tr><tr><td>6</td><td>神戸布引ロープウェイハープ園山麓駅</td><td>203</td></tr><tr><td>7</td><td>白鶴酒造資料館内</td><td>205</td></tr><tr><td>8</td><td>王子動物園内</td><td>235</td></tr><tr><td>9</td><td>県立美術館前</td><td>217</td></tr><tr><td>10</td><td>さんちか夢広場</td><td>208</td></tr><tr><td>11</td><td>神戸空港屋上階展望ロビー</td><td>212</td></tr><tr><td>12</td><td>IKEA神戸</td><td>192</td></tr><tr><td>13</td><td>能福寺(兵庫大仏)</td><td>147</td></tr><tr><td>14</td><td>兵庫津ミュージアム</td><td>204</td></tr><tr><td rowspan="4">神戸港</td><td>15</td><td>神戸海洋博物館前及び周辺</td><td>200</td></tr><tr><td>16</td><td>中突堤中央ターミナル周辺</td><td>208</td></tr><tr><td>17</td><td>umie モザイク</td><td>201</td></tr><tr><td>18</td><td>ハーバーランド総合インフォメーション前</td><td>213</td></tr><tr><td rowspan="4">六甲・摩耶</td><td>19</td><td>六甲天覧台</td><td>209</td></tr><tr><td>20</td><td>摩耶山掬星台広場</td><td>200</td></tr><tr><td>21</td><td>六甲山牧場内</td><td>215</td></tr><tr><td>22</td><td>六甲ガーデンテラス内</td><td>211</td></tr><tr><td rowspan="3">有馬</td><td>23</td><td>有馬温泉観光総合案内所前</td><td>214</td></tr><tr><td>24</td><td>金の湯前</td><td>216</td></tr><tr><td>25</td><td>六甲有馬ロープウェイ有馬温泉駅</td><td>232</td></tr><tr><td rowspan="2">須磨・舞子</td><td>26</td><td>須磨離宮公園</td><td>202</td></tr><tr><td>27</td><td>舞子公園(舞子海上プロムナード)</td><td>230</td></tr><tr><td rowspan="3">西北神</td><td>28</td><td>神戸ワイナリー(農業公園)</td><td>235</td></tr><tr><td>29</td><td>神戸フルーツ・フラワーパーク大沢園内</td><td>209</td></tr><tr><td>30</td><td>神戸三田プレミアム・アウトレット</td><td>215</td></tr><tr><td colspan="3">合計</td><td>6,250</td></tr></table>
とりあえず日本語も普通に読み取れている様子。表は <table> タグになっていて、1行でダーッと出力されているのは人間的には見づらい・・・
Markdownとしてレンダリングさせてみた。(.mmdという拡張子だとMarkdownとしてレンダリングされないので、.mdにリネームすればColaboratoryでも開ける。)

惜しい、ちょっと表が崩れている箇所がある。
result_with_boxes.jpgの方は以下のように読み取った箇所をバウンディングボックスで示したものとなっている。

次に4ページ目。こちらはグラフが画像として埋め込まれている。
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'kobe/page_4.png'
output_path = 'output'
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path = output_path,
base_size = 1024,
image_size = 640,
crop_mode=True,
save_results = True,
test_compress = True
)
出力先ディレクトリを見ると、images ディレクトリ以下に画像が出力されている。
output/
├── images/
│ ├── 0.jpg
│ └── 1.jpg
├── result.mmd
└── result_with_boxes.jpg
埋め込まれていたグラフ画像がここにそれぞれ抽出されていた。


result.mmdファイルを見ると、画像へのパスが埋め込まれている。
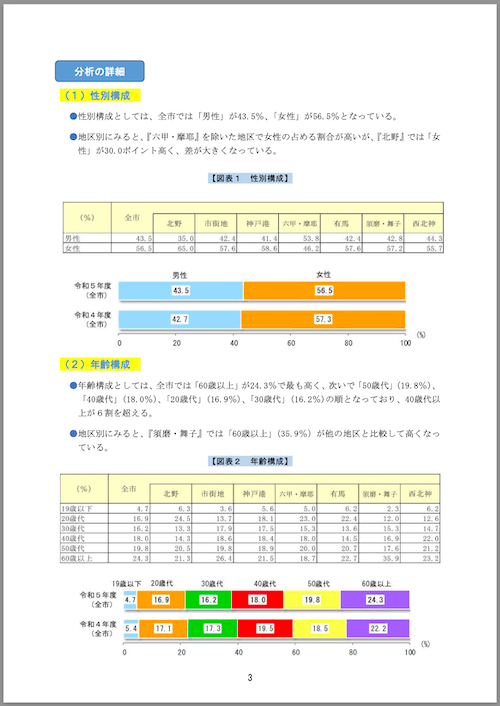
## 分析の詳細
### (1) 性別構成
- 性別構成としては、全市では「男性」が43.5%、「女性」が56.5%となっている。
- 地区別にみると、『六甲・摩耶』を除いた地区で女性の占める割合が高いが、『北野』では「女性」が30.0ポイント高く、差が大きくなっている。
【図表1 性別構成】
<table><tr><td>(%)</td><td>全市</td><td>北野</td><td>市街地</td><td>神戸港</td><td>六甲・摩耶</td><td>有馬</td><td>須磨・舞子</td><td>西北神</td></tr><tr><td>男性</td><td>43.5</td><td>35.0</td><td>42.4</td><td>41.4</td><td>53.8</td><td>42.4</td><td>42.8</td><td>44.3</td></tr><tr><td>女性</td><td>56.5</td><td>65.0</td><td>57.6</td><td>58.6</td><td>46.2</td><td>57.6</td><td>57.2</td><td>55.7</td></tr></table>

### (2) 年齢構成
- 年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで
「50歳代」(19.8%)、「40歳代」(18.0%)、「20歳代」(16.9%)、「30歳代
」(16.2%)の順となっており、40歳代以上が6割を超える。
- 地区別にみると、『須磨・舞子』では「60歳以上」(35.9%)が他の地区
と比較して高くなっている。
【図表2 年齢構成】
<table><tr><td>(%)</td><td>全市</td><td>北野</td><td>市街 地</td><td>神戸港</td><td>六甲・摩耶</td><td>有馬</td><td>须磨・舞子</td><td>西北神</td></tr><tr><td>19歳以下</td><td>4.7</td><td>6.3</td><td>3.6</td><td>5.6</td><td>5.0</td><td>6.2</td><td>2.3</td><td>6.2</td></tr><tr><td>20歳代</td><td>16.9</td><td>24.5</td><td>13.7</td><td>18.1</td><td>23.0</td><td>22.4</td><td>12.0</td><td>12.6</td></tr><tr><td>30歳代</td><td>16.2</td><td>13.3</td><td>17.9</td><td>17.5</td><td>15.3</td><td>13.6</td><td>15.3</td><td>14.7</td></tr><tr><td>40歳代</td><td>18.0</td><td>14.3</td><td>18.6</td><td>18.4</td><td>18.0</td><td>14.5</td><td>16.9</td><td>22.0</td></tr><tr><td>50歳代</td><td>19.8</td><td>20.5</td><td>19.8</td><td>18.9</td><td>20.0</td><td>20.7</td><td>17.6</td><td>21.2</td></tr><tr><td>60歳以上</td><td>24.3</td><td>21.3</td><td>26.4</td><td>21.5</td><td>18.7</td><td>22.7</td><td>35.9</td><td>23.2</td></tr></table>

Markdownでのレンダリング。グラフ画像が表示されてないけど、これはColaboratoryだからだと思う。ローカルに全部持ってくれば画像も含めて表示されるのではないかと。

result_with_boxes.jpgはこんな感じ。

一応TInyも試してみた。
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'kobe/page_1.png'
output_path = 'output'
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path = output_path,
base_size = 512,
image_size = 512,
crop_mode=False,
save_results = True,
test_compress = True
)
レンダリング結果だけ。

ちょっとこちらのほうがテーブル構造の崩れが目立つかな。
低解像度モードにしたら高速になるのかな?と思ったけど、あんまり変わらなかった。イマイチモードの違いとそれぞれの使い方がわからない。
まとめ
OCRを謳うVLMは過去もいろいろ試してるけど、日本語普通に読み取れるものが多いし、ある程度の精度はどれも出せている感がある。なので、どれを選ぶか?みたいなのが難しい、というか、どれでもいいんじゃない?というのが個人的な印象。
ただ、DeepSeek-OCRのアーキテクチャについては自分は理解が追いついてないのだけど、解像度モードを選択できるというところは他にはないポイントだと思うので、これが嬉しいケースがあるのかなとは思う(自分はイマイチ使いどころがわかってないけども)。
なので、こういう特徴的な機能だったり、使い勝手だったり、というところはより選択基準として重要になるのかなというふうに感じた。
例えば、自分が過去試した中ではdots.ocrが精度的に良くて、論文のベンチマークを見る限り、DeepSeek-OCRはdots.ocrと並ぶ感じなので、精度は十分良いと思う。
ただ、dots.ocrは、軽量・高速・GUIもあって、とても使い勝手が良いように思う。このあたりは現時点で差があるかな。
自分はOCR・VLMの観点でしか考えてなかったけど、なるほど、そういう観点があるのか。