Meilisearchを試す
Meilisearchにベクトル検索が追加されていた。
LnagChainもすでにインテグレーションされている
このあたりを読むとウェブサイトのスクレイピングツールもビルトインされている模様
ということでまずMeilisearchの基本的な使い方から試してみたい
インストール
いろいろあるけど、Dockerでやる。
公式手順だとこんな感じ。
$ docker pull getmeili/meilisearch:v1.4
$ docker run -it --rm \
-p 7700:7700 \
-e MEILI_ENV='development' \
-v $(pwd)/meili_data:/meili_data \
getmeili/meilisearch:v1.4
ただ公式イメージだと日本語には対応しているらしいが、一部まだ微妙なところがあるらしい。
で、有志の方々がかなりコミットしてくれているらしい。素晴らしい。
で、どうやら日本語向けにプロトタイプなdocker imageがある様子。しかもv1.4.1が出たばかり!
イメージはこちら
今回はこちらを使う。
$ docker pull getmeili/meilisearch:prototype-japanese-6
$ mkdir meilisearch && cd meilisearch
$ docker run -it --rm \
-p 7700:7700 \
-e MEILI_ENV='development' \
-v $(pwd)/meili_data:/meili_data \
getmeili/meilisearch:prototype-japanese-6
初回起動時は以下のような出力になる。
888b d888 d8b 888 d8b 888
8888b d8888 Y8P 888 Y8P 888
88888b.d88888 888 888
888Y88888P888 .d88b. 888 888 888 .d8888b .d88b. 8888b. 888d888 .d8888b 88888b.
888 Y888P 888 d8P Y8b 888 888 888 88K d8P Y8b "88b 888P" d88P" 888 "88b
888 Y8P 888 88888888 888 888 888 "Y8888b. 88888888 .d888888 888 888 888 888
888 " 888 Y8b. 888 888 888 X88 Y8b. 888 888 888 Y88b. 888 888
888 888 "Y8888 888 888 888 88888P' "Y8888 "Y888888 888 "Y8888P 888 888
Config file path: "none"
Database path: "./data.ms"
Server listening on: "http://0.0.0.0:7700"
Environment: "development"
Commit SHA: "7ed9ad024ec7688592e7ef697459681814e07144"
Commit date: "2023-10-16T11:31:59+02:00"
Package version: "1.4.1"
Prototype: "prototype-japanese-6"
Thank you for using Meilisearch!
We collect anonymized analytics to improve our product and your experience. To learn more, including how to turn off analytics, visit our dedicated documentation page: https://www.meilisearch.com/docs/learn/what_is_meilisearch/telemetry
Anonymous telemetry: "Enabled"
Instance UID: "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
No master key was found. The server will accept unidentified requests.
A master key of at least 16 bytes will be required when switching to a production environment.
We generated a new secure master key for you (you can safely use this token):
>> --master-key XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX <<
Restart Meilisearch with the argument above to use this new and secure master key.
Check out Meilisearch Cloud! https://www.meilisearch.com/cloud?utm_campaign=oss&utm_source=engine&utm_medium=cli
Documentation: https://www.meilisearch.com/docs
Source code: https://github.com/meilisearch/meilisearch
Discord: https://discord.meilisearch.com
デフォルトもしくは-e MEILI_ENV='development'で開発モードで起動する。この場合はアクセス制限なくリクエストを受け付けるらしい。次回以降は表示されている--master-keyオプションを有効にして(-e MEILI_ENV='development'`も外して)起動すると本番モードになるらしい。マスターキーは保存しておくこと。このあたりは後で確認する。
起動したらhttp://X.X.X.X:7700にアクセスするとWeb UIが表示される。

今のところはデータがないので、この辺も後で。
ドキュメントの追加
サンプルとしてTMDB(The Movie Database)の映画データを使用する流れになっているか、これ全部英語である。
https://www.meilisearch.com/docs/learn/getting_started/a
せっかくなので日本語でやりたいよね、ということでTMDBのAPIを叩いて、上記と同じフォーマットの日本語の映画データを作成した(ライセンスがちょっとよくわからないので非公開)。これをインポートしてみる。
python環境を作る。
$ pyenv virtualenv 3.10.13 meilisearch
# 上の方で作ったディレクトリ内で
$ pyenv local meilisearch
jupyter lab環境を作る。
$ pip install jupyterlab ipywidgets
meilisearchクライアントをインストール
$ pip install meilisearch
jupyter lab起動
$jupyter-lab --ip='0.0.0.0' --NotebookApp.token=''
ここからはjupyter labで。
meilisearchにドキュメントを追加する。movies_jp.jsonが上で作成したJSONデータ。
import meilisearch
import json
client = meilisearch.Client('http://localhost:7700', 'aSampleMasterKey')
json_file = open('movies_jp.json', encoding='utf-8')
movies = json.load(json_file)
client.index('movies_jp').add_documents(movies)
documentAdditionOrUpdateタスクがキューイングされる。(読みやすさ優先で改行入れてます)
TaskInfo(
task_uid=0,
index_uid='movies_jp',
status='enqueued',
type='documentAdditionOrUpdate',
enqueued_at=datetime.datetime(2023, 10, 20, 15, 2, 0, 908048)
)
タスクの状況を確認してみる。task_uidで参照すればよい
client.get_task(0)
status='succeeded'になっているのがわかる。
Task(
uid=0,
index_uid='movies_jp',
status='succeeded',
type='documentAdditionOrUpdate',
details={'receivedDocuments': 13669, 'indexedDocuments': 13669},
error=None,
canceled_by=None,
duration='PT6.499335104S',
enqueued_at=datetime.datetime(2023, 10, 20, 15, 2, 0, 908048),
started_at=datetime.datetime(2023, 10, 20, 15, 2, 0, 920769),
finished_at=datetime.datetime(2023, 10, 20, 15, 2, 7, 420104)
)
meilisearchのWeb UIを開いてみるとドキュメントが登録されていることがわかる。
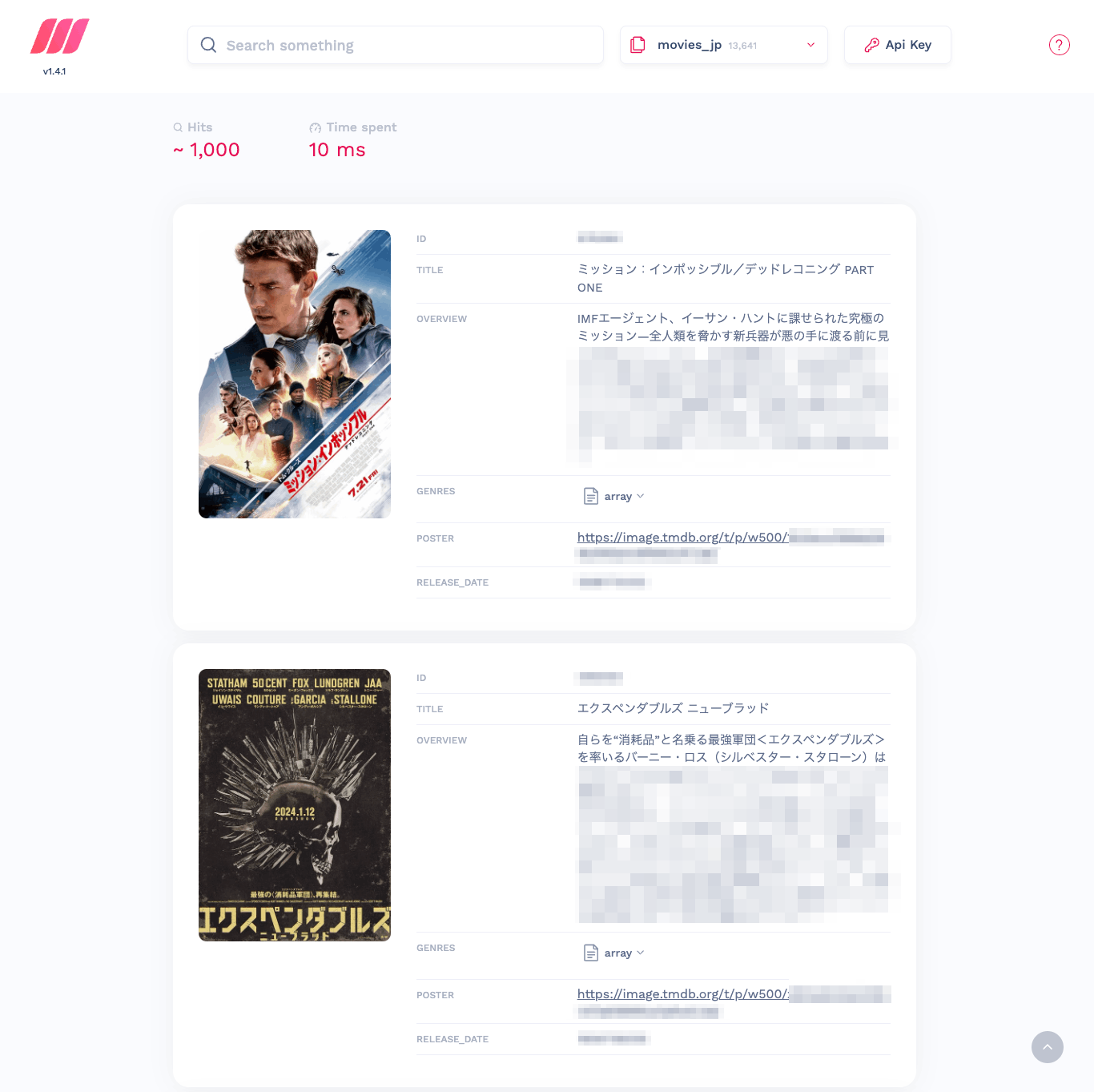
検索してみる。
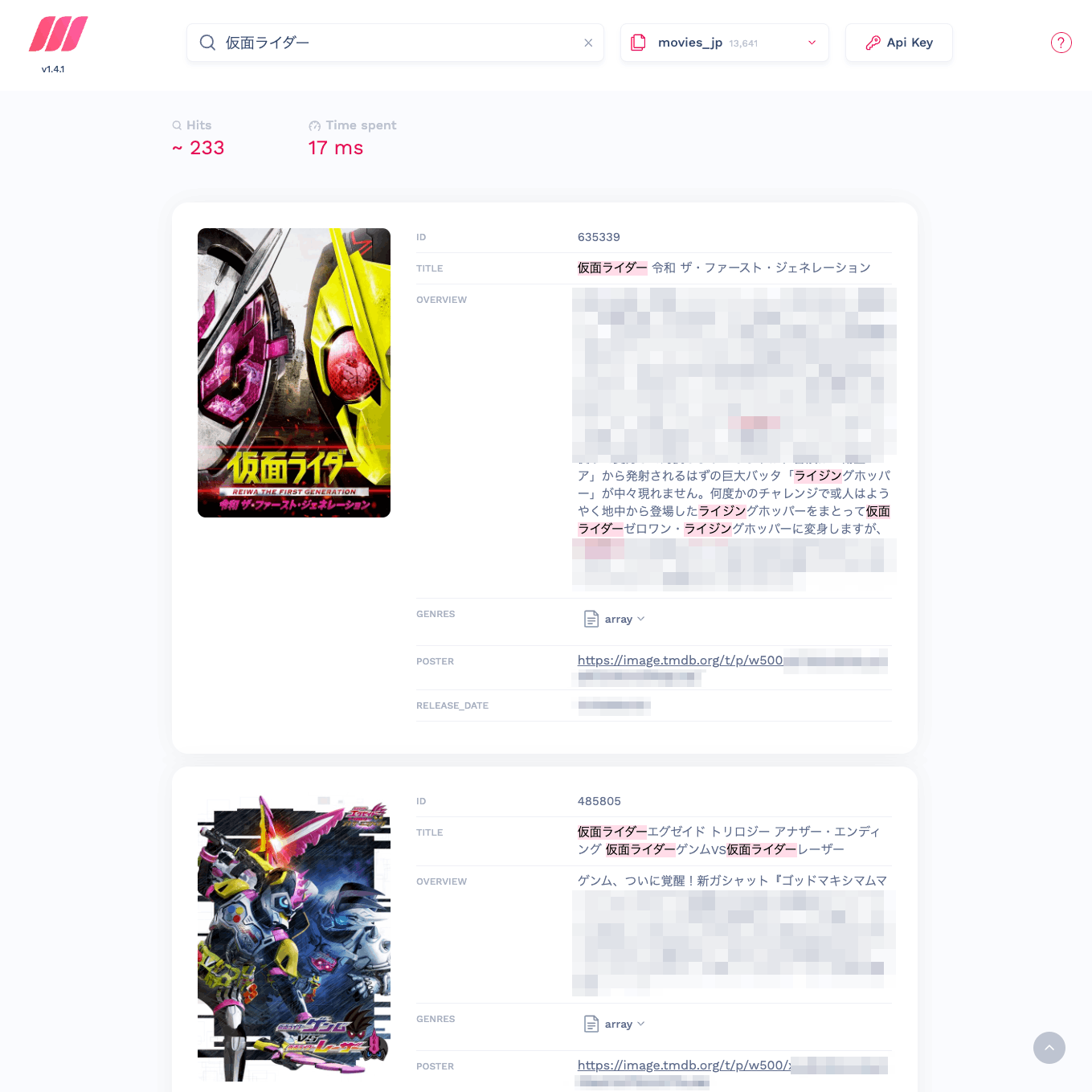
インクリメンタルサーチが有効になっているのでキータイプごとに検索結果が瞬時に変わる。今回のデータは約13000件ほど入っているが、上記の通り17msと非常に高速。あと、検索キーに合致している部分はハイライトされる。微妙に違うものもハイライトされているけど、この辺が日本語の分かち書きエンジンによる制約なのかもしれない。
検索
通常の検索
client.index('movies_jp').search('シンケンジャー')
{
'hits': [
{
'id': XXXXXX,
'title': '天装戦隊ゴセイジャーVSシンケンジャー エピックon銀幕',
'overview': 'シンケンジャーに倒された外道衆の生き残り・マダコダマが現れた。(snip)',
'genres': ['AAA', 'BBB', 'CCC'],
'poster': 'https://image.tmdb.org/t/p/w500/XXXXXXXXXX.jpg',
'release_date': XXXXXXXXXX
},
{
'id': XXXXXX,
'title': '侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!',
'overview': '折神が舞い、炎神が駆け、ヒーローたちがここに集結する! (snip)',
'genres': ['AAA', 'BBB', 'CCC'],
'poster': 'https://image.tmdb.org/t/p/w500/XXXXXXXXXX.jpg',
'release_date': XXXXXXXXXX
},
(snip)
],
'query': 'シンケンジャー',
'processingTimeMs': 14,
'limit': 20,
'offset': 0,
'estimatedTotalHits': 676}
キーワード検索色々。説明文は割愛してるけど一定量で含まれているはずと想定。
res = client.index('movies_jp').search('侍戦隊')
print("\n".join([r["title"] for r in res["hits"]]))
"侍"も引っかかっている。トークンが分割されて、"侍" と "戦隊" で検索されているのだろうと推測。
侍戦隊シンケンジャー銀幕版 天下分け目の戦
侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!
帰ってきた侍戦隊シンケンジャー 特別幕
手裏剣戦隊ニンニンジャー THE MOVIE 恐竜殿さまアッパレ忍法帖!
さや侍
BALLAD 名もなき恋のうた
飛びだす冒険映画 赤影
壬生義士伝
銀魂
荒野の七人 真昼の決闘
荒野の七人
スクライド オルタレイション QUAN
一命
パンク侍、斬られて候
猫侍 南の島へ行く
猫侍
のみとり侍
その夜の侍
WARRIOR ~唄い続ける侍ロマン
水の旅人-侍KIDS-
意図的にスペースで分割して複数キーワードのイメージで。
res = client.index('movies_jp').search('侍 戦隊')
print("\n".join([r["title"] for r in res["hits"]]))
上と同じなのでそういうことだと思う。
侍戦隊シンケンジャー銀幕版 天下分け目の戦
侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!
帰ってきた侍戦隊シンケンジャー 特別幕
手裏剣戦隊ニンニンジャー THE MOVIE 恐竜殿さまアッパレ忍法帖!
さや侍
BALLAD 名もなき恋のうた
飛びだす冒険映画 赤影
壬生義士伝
銀魂
荒野の七人 真昼の決闘
荒野の七人
スクライド オルタレイション QUAN
一命
パンク侍、斬られて候
猫侍 南の島へ行く
猫侍
のみとり侍
その夜の侍
WARRIOR ~唄い続ける侍ロマン
水の旅人-侍KIDS-
ダブルクォーテーションで囲んでみる。
res = client.index('movies_jp').search('"侍戦隊"')
print("\n".join([r["title"] for r in res["hits"]]))
ダブルクォーテーションで囲むとおそらく分割されずに検索されるのだと思う。
侍戦隊シンケンジャー銀幕版 天下分け目の戦
侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!
帰ってきた侍戦隊シンケンジャー 特別幕
ダブルクォーテーションで囲んでかつ複数キーワードにしてみる。
res = client.index('movies_jp').search('"侍" "戦隊"')
print("\n".join([r["title"] for r in res["hits"]]))
ちょっと変わった。一番最後のやつは説明文に"侍"が含まれていた。
侍戦隊シンケンジャー銀幕版 天下分け目の戦
侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!
帰ってきた侍戦隊シンケンジャー 特別幕
手裏剣戦隊ニンニンジャー THE MOVIE 恐竜殿さまアッパレ忍法帖!
ちなみに参考までに。
"侍"単体
res = client.index('movies_jp').search('侍')
print("\n".join([r["title"] for r in res["hits"]]))
侍戦隊シンケンジャー銀幕版 天下分け目の戦
侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!
パンク侍、斬られて候
猫侍 南の島へ行く
猫侍
さや侍
のみとり侍
その夜の侍
WARRIOR ~唄い続ける侍ロマン
帰ってきた侍戦隊シンケンジャー 特別幕
水の旅人-侍KIDS-
十一人の侍
三匹の侍
七人の侍
半次郎
銀魂
KUBO/クボ 二本の弦の秘密
手裏剣戦隊ニンニンジャー THE MOVIE 恐竜殿さまアッパレ忍法帖!
一命
BALLAD 名もなき恋のうた
"戦隊"単体
res = client.index('movies_jp').search('戦隊')
print("\n".join([r["title"] for r in res["hits"]]))
宇宙戦隊キュウレンジャーVSスペース・スクワッド
炎神戦隊ゴーオンジャー 10 YEARS GRANDPRIX
宇宙戦隊キュウレンジャー THE MOVIE ゲース・インダベーの逆襲
海賊戦隊ゴーカイジャーVS宇宙刑事ギャバン THE MOVIE
特命戦隊ゴーバスターズ THE MOVIE 東京エネタワーを守れ!
ゴーカイジャー ゴセイジャー スーパー戦隊199ヒーロー 大決戦
海賊戦隊ゴーカイジャー THE MOVIE 空飛ぶ幽霊船
侍戦隊シンケンジャー銀幕版 天下分け目の戦
侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!
炎神戦隊ゴーオンジャー BUNBUN!BANBAN!劇場BANG!!
炎神戦隊ゴーオンジャー BONBON!BONBON!ネットでBONG!!
救急戦隊ゴーゴーファイブ 激突!新たなる超戦士
轟轟戦隊ボウケンジャー VS スーパー戦隊
電磁戦隊メガレンジャーVSカーレンジャー
激走戦隊カーレンジャーVSオーレンジャー
魔法戦隊マジレンジャー VS デカレンジャー
轟轟戦隊ボウケンジャーTHE MOVIE 最強のプレシャス
特捜戦隊デカレンジャーVSアバレンジャー
百獣戦隊ガオレンジャーVSスーパー戦隊
未来戦隊タイムレンジャーVSゴーゴーファイブ
順番入れ替えてみる
res = client.index('movies_jp').search('戦隊 侍')
print("\n".join([r["title"] for r in res["hits"]]))
"侍 戦隊"のときと検索結果が変わる。
侍戦隊シンケンジャー銀幕版 天下分け目の戦
侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!
帰ってきた侍戦隊シンケンジャー 特別幕
手裏剣戦隊ニンニンジャー THE MOVIE 恐竜殿さまアッパレ忍法帖!
さや侍
BALLAD 名もなき恋のうた
飛びだす冒険映画 赤影
曹操暗殺 三国志外伝
壬生義士伝
銀魂
荒野の七人 真昼の決闘
荒野の七人
スクライド オルタレイション QUAN
一命
宇宙戦隊キュウレンジャーVSスペース・スクワッド
炎神戦隊ゴーオンジャー 10 YEARS GRANDPRIX
宇宙戦隊キュウレンジャー THE MOVIE ゲース・インダベーの逆襲
海賊戦隊ゴーカイジャーVS宇宙刑事ギャバン THE MOVIE
特命戦隊ゴーバスターズ THE MOVIE 東京エネタワーを守れ!
ゴーカイジャー ゴセイジャー スーパー戦隊199ヒーロー 大決戦
ちなみに以下の場合はどれも同じ結果になった。
res = client.index('movies_jp').search('侍 戦隊 シンケンジャー')
print("\n".join([r["title"] for r in res["hits"]]))
res = client.index('movies_jp').search('侍戦隊 シンケンジャー')
print("\n".join([r["title"] for r in res["hits"]]))
res = client.index('movies_jp').search('侍戦隊シンケンジャー')
print("\n".join([r["title"] for r in res["hits"]]))
もっと組み合わせはあるし、そんな単純なものではないと思ってるけど、ざっくりこんな感じかな。
- キーワードの先頭が優先される
- 日本語の場合は、キーワードはトークン分割されて、そのトークン順に並ぶ
- ダブルクォートで囲むとそれがトークンとして使用される
インスタント検索向けに作られているらしいので、先頭が優先されるってのはまあそうなんだろうなと思う。日本語の場合は入力したキーワードがトークンに分割される(そしてそのままの順になる)ところに注意が必要かも。
ランキングの順番
うむ、上で書いたようなそんなシンプルなものではなかった。
- 検索結果はランキングルールにもとづいてランキングされる
- ランキングルールは複数のルールからなり、設定されたルールの順番で重み付け評価される
- 最初のルールがまず適用される
- 次のルールは前のルールで同率となった場合にのみ適用される
- 最初のルールの重みが圧倒的に重視される
- ランキングルールはインデックスごとにカスタマイズできる
- インデックスの特定の属性の昇順・降順をカスタムルールとして追加できる。
デフォルトのルールは以下。順番もこう。
1. words
マッチしたキーワードの数が多い順番にランキング
例: "侍 戦隊 シンケンジャー"で検索した場合
- "侍"、"戦隊"、"シンケンジャー"をすべて含むドキュメントが最初
- "侍"、"戦隊"をすべて含むドキュメントが次
- "侍" を含むドキュメントが次
2. typo
タイポの少ない順にランキング。日本語の場合にどうなるのかはわからないので、ドキュメントの例。
例: (インスタント検索で)"vogli"と入力した場合、
- voglia: タイポは0文字
- vollidot: タイポは1文字
3. proximity
キーワード間の距離。これは複数のキーワードが入力された場合だと思うのだけど、キーワードが"A"と"B"の場合に、文書中に出てくる"A"と"B"がどれぐらい近いか、近い順にソートされるということらしい。
4. attribute
属性の順。例えば今回のデータだと以下のような属性がある。
{
'id': XXXXXX,
'title': '天装戦隊ゴセイジャーVSシンケンジャー エピックon銀幕',
'overview': 'シンケンジャーに倒された外道衆の生き残り・マダコダマが現れた。(snip)',
'genres': ['AAA', 'BBB', 'CCC'],
'poster': 'https://image.tmdb.org/t/p/w500/XXXXXXXXXX.jpg',
'release_date': XXXXXXXXXX
},
基本的にドキュメントを追加した時点の属性の順番で重み付けが行われる。つまりtitleだけにキーワードが入っている場合とoverviewだけにキーワードが入っている場合であればtitleが上位になる。また属性の先頭にキーワードが含まれる場合と、末尾に含まれる場合であれば、先頭のほうが上位になる。
5. sort
検索時のパラメータでソートする属性と昇順・降順が指定された場合。
何も指定しない場合の例。
res = client.index('movies_jp').search('戦隊')
print("\n".join([f"{r['title']}\t{r['release_date']}" for r in res["hits"]]))
宇宙戦隊キュウレンジャーVSスペース・スクワッド 1533XXXXXX
炎神戦隊ゴーオンジャー 10 YEARS GRANDPRIX 1537XXXXXX
宇宙戦隊キュウレンジャー THE MOVIE ゲース・インダベーの逆襲 1501XXXXXX
海賊戦隊ゴーカイジャーVS宇宙刑事ギャバン THE MOVIE 1327XXXXXX
特命戦隊ゴーバスターズ THE MOVIE 東京エネタワーを守れ! 1344XXXXXX
ゴーカイジャー ゴセイジャー スーパー戦隊199ヒーロー 大決戦 1307XXXXXX
海賊戦隊ゴーカイジャー THE MOVIE 空飛ぶ幽霊船 1312XXXXXX
侍戦隊シンケンジャー銀幕版 天下分け目の戦 1249XXXXXX
侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!! 1264XXXXXX
炎神戦隊ゴーオンジャー BUNBUN!BANBAN!劇場BANG!! 1218XXXXXX
炎神戦隊ゴーオンジャー BONBON!BONBON!ネットでBONG!! 1215XXXXXX
救急戦隊ゴーゴーファイブ 激突!新たなる超戦士 931XXXXXX
轟轟戦隊ボウケンジャー VS スーパー戦隊 1175XXXXXX
電磁戦隊メガレンジャーVSカーレンジャー 88XXXXXX
激走戦隊カーレンジャーVSオーレンジャー 858XXXXXX
魔法戦隊マジレンジャー VS デカレンジャー 1141XXXXXX
轟轟戦隊ボウケンジャーTHE MOVIE 最強のプレシャス 1154XXXXXX
特捜戦隊デカレンジャーVSアバレンジャー 1110XXXXXX
百獣戦隊ガオレンジャーVSスーパー戦隊 997XXXXXX
未来戦隊タイムレンジャーVSゴーゴーファイブ 984XXXXXX
ではrelease_dateでソートさせてみる。
ソートさせる場合にはまず属性をsortable_artributesに追加してやる必要がある。
client.index('movies_jp').update_sortable_attributes([
'release_date',
])
TaskInfo(task_uid=1, index_uid='movies_jp', status='enqueued', type='settingsUpdate', enqueued_at=datetime.datetime(2023, 10, 21, 18, 30, 12, 53029))
client.get_task(1)
release_dateがsortableになった
Task(uid=1, index_uid='movies_jp', status='succeeded', type='settingsUpdate', details={'sortableAttributes': ['release_date']}, error=None, canceled_by=None, duration='PT6.667571892S', enqueued_at=datetime.datetime(2023, 10, 21, 18, 30, 12, 53029), started_at=datetime.datetime(2023, 10, 21, 18, 30, 12, 159878), finished_at=datetime.datetime(2023, 10, 21, 18, 30, 18, 827450))
では検索してみる
res = client.index('movies_jp').search('戦隊', {'sort': ['release_date:desc']})
print("\n".join([f"{r['title']}\t{r['release_date']}" for r in res["hits"]]))
秘密戦隊ゴレンジャー 爆弾ハリケーン 206XXXXXX
高速戦隊ターボレンジャー(劇場版) 606XXXXXX
激走戦隊カーレンジャーVSオーレンジャー 858XXXXXX
電磁戦隊メガレンジャーVSカーレンジャー 889XXXXXX
救急戦隊ゴーゴーファイブ 激突!新たなる超戦士 931XXXXXX
救急戦隊ゴーゴーファイブVSギンガマン 952XXXXXX
未来戦隊タイムレンジャーVSゴーゴーファイブ 984XXXXXX
百獣戦隊ガオレンジャーVSスーパー戦隊 997XXXXXX
特捜戦隊デカレンジャーVSアバレンジャー 1110XXXXXX
魔法戦隊マジレンジャー VS デカレンジャー 1141XXXXXX
轟轟戦隊ボウケンジャーTHE MOVIE 最強のプレシャス 1154XXXXXX
轟轟戦隊ボウケンジャー VS スーパー戦隊 1175299200
炎神戦隊ゴーオンジャー BONBON!BONBON!ネットでBONG!! 1215XXXXXX
炎神戦隊ゴーオンジャー BUNBUN!BANBAN!劇場BANG!! 1218XXXXXX
侍戦隊シンケンジャー銀幕版 天下分け目の戦 1249XXXXXX
侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!! 1264XXXXXX
ゴーカイジャー ゴセイジャー スーパー戦隊199ヒーロー 大決戦 1307XXXXXX
海賊戦隊ゴーカイジャー THE MOVIE 空飛ぶ幽霊船 1312XXXXXX
海賊戦隊ゴーカイジャーVS宇宙刑事ギャバン THE MOVIE 1327XXXXXX
特命戦隊ゴーバスターズ THE MOVIE 東京エネタワーを守れ! 1344XXXXXX
res = client.index('movies_jp').search('戦隊', {'sort': ['release_date:asc']})
print("\n".join([f"{r['title']}\t{r['release_date']}" for r in res["hits"]]))
炎神戦隊ゴーオンジャー 10 YEARS GRANDPRIX 1537XXXXXX
宇宙戦隊キュウレンジャーVSスペース・スクワッド 1533XXXXXX
宇宙戦隊キュウレンジャー THE MOVIE ゲース・インダベーの逆襲 1501XXXXXX
特命戦隊ゴーバスターズ THE MOVIE 東京エネタワーを守れ! 1344XXXXXX
海賊戦隊ゴーカイジャーVS宇宙刑事ギャバン THE MOVIE 1327XXXXXX
海賊戦隊ゴーカイジャー THE MOVIE 空飛ぶ幽霊船 1312XXXXXX
ゴーカイジャー ゴセイジャー スーパー戦隊199ヒーロー 大決戦 1307XXXXXX
侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!! 1264XXXXXX
侍戦隊シンケンジャー銀幕版 天下分け目の戦 1249XXXXXX
炎神戦隊ゴーオンジャー BUNBUN!BANBAN!劇場BANG!! 1218XXXXXX
炎神戦隊ゴーオンジャー BONBON!BONBON!ネットでBONG!! 1215XXXXXX
轟轟戦隊ボウケンジャー VS スーパー戦隊 1175XXXXXX
轟轟戦隊ボウケンジャーTHE MOVIE 最強のプレシャス 1154XXXXXX
魔法戦隊マジレンジャー VS デカレンジャー 114XXXXXX
特捜戦隊デカレンジャーVSアバレンジャー 1110XXXXXX
百獣戦隊ガオレンジャーVSスーパー戦隊 997XXXXXX
未来戦隊タイムレンジャーVSゴーゴーファイブ 984XXXXXX
救急戦隊ゴーゴーファイブVSギンガマン 952XXXXXX
救急戦隊ゴーゴーファイブ 激突!新たなる超戦士 931XXXXXX
電磁戦隊メガレンジャーVSカーレンジャー 889XXXXXX
順番が変わっているのがわかる。
でこのルールはカスタムルールとしてランキングルールに組み込むこともできる。そうすれば検索時にオプションを指定する必要がなくなる。
6. exactness
より正確にマッチしたほうが上位に来る。ドキュメントの例にあるように"knight"で検索した場合に
- "knight"
- "knights"
なら"knight"が上位になる。
ランキングのスコア
検索時にshowRankingScoreオプションを有効にすれば結果に_rankingScoreが付与される。
res = client.index('movies_jp').search('シンケンジャー', {'showRankingScore': True })
[{"title": item["title"], "_rankingScore": item["_rankingScore"]} for item in res["hits"]]
[
{'title': '天装戦隊ゴセイジャーVSシンケンジャー エピックon銀幕', '_rankingScore': 0.9977092352092352},
{'title': '侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!', '_rankingScore': 0.9974747474747475},
{'title': '帰ってきた侍戦隊シンケンジャー 特別幕', '_rankingScore': 0.9973665223665223},
{'title': '侍戦隊シンケンジャー銀幕版 天下分け目の戦', '_rankingScore': 0.9946608946608947},
{'title': 'プロフェシー', '_rankingScore': 0.7697029822029822},
{'title': 'スワップ・スワップ~伝説のセックスクラブ~', '_rankingScore': 0.7695406445406445},
{'title': 'エージェント・マロリー', '_rankingScore': 0.7694324194324195},
{'title': 'ジャージー・ボーイズ', '_rankingScore': 0.7085557960557961},
{'title': 'ブラック・スキャンダル', '_rankingScore': 0.7071548821548822},
{'title': 'ザ・レッド・チャペル', '_rankingScore': 0.7070947570947571},
{'title': 'ゴッドスレイヤー 神殺しの剣', '_rankingScore': 0.707046657046657},
{'title': 'ザ・スーサイド・スクワッド “極”悪党、集結', '_rankingScore': 0.7069865319865319},
{'title': 'シン・ジョーズ', '_rankingScore': 0.6976791726791727},
{'title': 'ジャックはしゃべれま1,000', '_rankingScore': 0.696055796055796},
{'title': 'トム・ソーヤー&ハックルベリー・フィン', '_rankingScore': 0.6946488696488696},
{'title': 'レスキュー', '_rankingScore': 0.694594757094757},
{'title': 'ジャングル・ブック2', '_rankingScore': 0.6835557960557961},
{'title': 'グラン・ブルー', '_rankingScore': 0.6828523328523328},
{'title': '人類創世', '_rankingScore': 0.6828523328523328},
{'title': '哀しみのベラドンナ', '_rankingScore': 0.6824194324194324}]
5番目以降のスコアが激減してるのがわかる。
このスコアはsortを除く他のランキングルールで算出される(sortはランキングではないのでスコアには影響しない)。
詳細なランキングスコア(EXPERIMENTAL)
より詳細なランキングスコアを表示する方法があるらしい。ただしEXPERIMENTALな位置づけ。
以下を実行する。
!curl -X PATCH 'http://localhost:7700/experimental-features/' \
-H 'Content-Type: application/json' \
--data-binary '{"scoreDetails": true}'
有効化された。ベクトルストア機能も見えるねぇ・・・・
{"scoreDetails":true,"vectorStore":false}
使う場合は検索時にshowRankingScoreDetails: trueしてやればいい。
from pprint import pprint
res = client.index('movies_jp').search('シンケンジャー', {
'showRankingScore': True,
'showRankingScoreDetails': True,
})
pprint([{"title": item["title"], "_rankingScore": item["_rankingScore"], "_rankingScoreDetails": item["_rankingScoreDetails"]} for item in res["hits"]])
結果
[{'_rankingScore': 0.9977092352092352,
'_rankingScoreDetails': {'attribute': {'attributeRankingOrderScore': 0.8181818181818182,
'order': 3,
'queryWordDistanceScore': 1.0,
'score': 0.8181818181818182},
'exactness': {'matchType': 'matchesStart',
'order': 4,
'score': 0.6666666666666666},
'proximity': {'order': 2, 'score': 1.0},
'typo': {'maxTypoCount': 4,
'order': 1,
'score': 1.0,
'typoCount': 0},
'words': {'matchingWords': 2,
'maxMatchingWords': 2,
'order': 0,
'score': 1.0}},
'title': '天装戦隊ゴセイジャーVSシンケンジャー エピックon銀幕'},
(snip)
{'_rankingScore': 0.7697029822029822,
'_rankingScoreDetails': {'attribute': {'attributeRankingOrderScore': 0.6363636363636364,
'order': 3,
'queryWordDistanceScore': 0.38095238095238093,
'score': 0.5800865800865801},
'exactness': {'matchType': 'noExactMatch',
'matchingWords': 0,
'maxMatchingWords': 2,
'order': 4,
'score': 0.1111111111111111},
'proximity': {'order': 2, 'score': 0.75},
'typo': {'maxTypoCount': 4,
'order': 1,
'score': 0.6,
'typoCount': 2},
'words': {'matchingWords': 2,
'maxMatchingWords': 2,
'order': 0,
'score': 1.0}},
'title': 'プロフェシー'},
]
検索結果がイマイチとかの場合にみるといいのかも。
フィルタリング
属性でフィルタすることができる。フィルタを有効にするにはfilterable_attributesに属性を追加する必要がある。
client.index('movies_jp').update_filterable_attributes([
'genres',
'release_date',
])
フィルタしてみる。例えば、release_dateが1970年1月1日よりも前のものをフィルタ。
res = client.index('movies_jp').search('', {
'filter': 'release_date < 0'
})
pprint([{"title": item["title"], "release_date": item["release_date"]} for item in res["hits"]])
[{'release_date': -9223XXXXXX, 'title': '人生に詰んだ元アイドルは、赤の他人のおっさんと住む選択をした'},
{'release_date': -30XXXXXX, 'title': '明日に向って撃て!'},
{'release_date': -18XXXXXX, 'title': 'ミニミニ大作戦'},
{'release_date': -12XXXXX, 'title': '女王陛下の007'},
{'release_date': -17XXXXXX, 'title': '勇気ある追跡'},
{'release_date': -19XXXXXX, 'title': '真夜中のカーボーイ'},
{'release_date': -16XXXXXX, 'title': 'ワイルドバンチ'},
{'release_date': -16XXXXXX, 'title': 'イージー・ライダー'},
{'release_date': -76XXXXX, 'title': '大いなる男たち'},
{'release_date': -23XXXXX, 'title': 'シシリアン'},
{'release_date': -10XXXXX, 'title': 'ゴジラ・ミニラ・ガバラ オール怪獣大進撃'},
{'release_date': -12XXXXX, 'title': 'トパーズ'},
{'release_date': -14XXXXXX, 'title': '新・荒野の七人/馬上の決闘'},
{'release_date': -16XXXXXX, 'title': 'レマゲン鉄橋'},
{'release_date': -18XXXXX, 'title': '宇宙からの脱出'},
{'release_date': -12XXXXX, 'title': '1000日のアン'},
{'release_date': -17XXXXX, 'title': 'ハロー・ドーリー!'},
{'release_date': -26XXXXXX, 'title': '続・片腕必殺剣'},
{'release_date': -21XXXXXX, 'title': '徳川いれずみ師:責め地獄'},
{'release_date': -89XXXXX, 'title': 'かわいい女'}]
ジャンル: アクションで検索
res = client.index('movies_jp').search('', {
'filter': 'genres ="アクション"'
})
pprint([{"title": item["title"], "genres": item["genres"]} for item in res["hits"]])
[{'genres': ['アクション', 'XXXXX'], 'title': 'ミッション:インポッシブル/デッドレコニング PART ONE'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'エクスペンダブルズ ニューブラッド'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'イコライザー THE FINAL'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'ワイルド・スピード/ファイヤーブースト'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'バレリーナ'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'MEG ザ・モンスターズ2'},
{'genres': ['アニメーション', 'XXXXX', 'XXXXX'],
'title': 'スパイダーマン:アクロス・ザ・スパイダーバース'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'トランスフォーマー/ビースト覚醒'},
{'genres': ['XXXXX', 'アクション'], 'title': 'インディ・ジョーンズと運命のダイヤル'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'ジョン・ウィック:コンセクエンス'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'ザ・フラッシュ'},
{'genres': ['XXXXX', 'XXXXX', 'アクション'],
'title': 'ガーディアンズ・オブ・ギャラクシー:VOLUME 3'},
{'genres': ['XXXXX', 'アクション'], 'title': 'ハート・オブ・ストーン'},
{'genres': ['XXXXX', 'アクション', 'XXXXX'], 'title': 'ザ・クリエイター/創世者'},
{'genres': ['XXXXX', 'アクション', 'XXXXX'], 'title': 'バイオハザード:デスアイランド'},
{'genres': ['XXXXX', 'XXXXX', 'XXXXX', 'アクション'], 'title': 'アウェアネス -超能力覚醒-'},
{'genres': ['XXXXX', 'アクション', 'XXXXX'], 'title': '聖闘士星矢 The Beginning'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'アントマン&ワスプ:クアントマニア'},
{'genres': ['アクション', 'XXXXX'], 'title': 'タイラー・レイク -命の奪還-2'},
{'genres': ['XXXXX', 'アクション'], 'title': 'クリード 過去の逆襲'}]
ANDやORも使える。release_dateが1969/1/1〜1969/12/31の場合。
res = client.index('movies_jp').search('', {
'filter': 'release_date < 0 AND release_date >= -31536000'
})
pprint([{"title": item["title"], "release_date": item["release_date"]} for item in res["hits"]])
[{'release_date': -30XXXXXX, 'title': '明日に向って撃て!'},
{'release_date': -18XXXXXX, 'title': 'ミニミニ大作戦'},
{'release_date': -12XXXXX, 'title': '女王陛下の007'},
{'release_date': -17XXXXXX, 'title': '勇気ある追跡'},
{'release_date': -19XXXXXX, 'title': '真夜中のカーボーイ'},
{'release_date': -16XXXXXX, 'title': 'ワイルドバンチ'},
{'release_date': -16XXXXXX, 'title': 'イージー・ライダー'},
{'release_date': -76XXXXX, 'title': '大いなる男たち'},
{'release_date': -23XXXXX, 'title': 'シシリアン'},
{'release_date': -10XXXXX, 'title': 'ゴジラ・ミニラ・ガバラ オール怪獣大進撃'},
{'release_date': -12XXXXX, 'title': 'トパーズ'},
{'release_date': -14XXXXXXX, 'title': '新・荒野の七人/馬上の決闘'},
{'release_date': -16XXXXXX, 'title': 'レマゲン鉄橋'},
{'release_date': -18XXXXX, 'title': '宇宙からの脱出'},
{'release_date': -12XXXXX, 'title': '1000日のアン'},
{'release_date': -17XXXXX, 'title': 'ハロー・ドーリー!'},
{'release_date': -26XXXXXX, 'title': '続・片腕必殺剣'},
{'release_date': -21XXXXXX, 'title': '徳川いれずみ師:責め地獄'},
{'release_date': -89XXXXX, 'title': 'かわいい女'},
{'release_date': -25XXXXXX, 'title': '大頭脳'}]
ジャンルがアクションかサイエンスフィクションの場合
res = client.index('movies_jp').search('', {
'filter': 'genres = "アクション" OR genres = "サイエンスフィクション"'
})
pprint([{"title": item["title"], "genres": item["genres"]} for item in res["hits"]])
[{'genres': ['アクション', 'XXXXX'], 'title': 'ミッション:インポッシブル/デッドレコニング PART ONE'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'エクスペンダブルズ ニューブラッド'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'イコライザー THE FINAL'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'ワイルド・スピード/ファイヤーブースト'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'バレリーナ'},
{'genres': ['アクション', 'サイエンスフィクション', 'XXXXX'], 'title': 'MEG ザ・モンスターズ2'},
{'genres': ['XXXXX', 'アクション', 'XXXXX'],
'title': 'スパイダーマン:アクロス・ザ・スパイダーバース'},
{'genres': ['アクション', 'XXXXX', 'サイエンスフィクション'], 'title': 'トランスフォーマー/ビースト覚醒'},
{'genres': ['XXXXX', 'アクション'], 'title': 'インディ・ジョーンズと運命のダイヤル'},
{'genres': ['アクション', 'XXXXX', 'XXXXX'], 'title': 'ジョン・ウィック:コンセクエンス'},
{'genres': ['アクション', 'XXXXX', 'サイエンスフィクション'], 'title': 'ザ・フラッシュ'},
{'genres': ['サイエンスフィクション', 'XXXXX', 'アクション'],
'title': 'ガーディアンズ・オブ・ギャラクシー:VOLUME 3'},
{'genres': ['XXXXX', 'アクション'], 'title': 'ハート・オブ・ストーン'},
{'genres': ['サイエンスフィクション', 'アクション', 'XXXXX'], 'title': 'ザ・クリエイター/創世者'},
{'genres': ['XXXXX', 'アクション', 'XXXXX'], 'title': 'バイオハザード:デスアイランド'},
{'genres': ['サイエンスフィクション', 'XXXXX, 'XXXXX', 'アクション'], 'title': 'アウェアネス -超能力覚醒-'},
{'genres': ['XXXXX', 'アクション', 'XXXXX'], 'title': '聖闘士星矢 The Beginning'},
{'genres': ['アクション', 'XXXXX', 'サイエンスフィクション'], 'title': 'アントマン&ワスプ:クアントマニア'},
{'genres': ['アクション', 'XXXXX'], 'title': 'タイラー・レイク -命の奪還-2'},
{'genres': ['XXXXX', 'アクション'], 'title': 'クリード 過去の逆襲'}]
ORはこういう書き方もできる。
res = client.index('movies_jp').search('', {
'filter': 'genres IN ["アクション","サイエンスフィクション"]'
})
pprint([{"title": item["title"], "genres": item["genres"]} for item in res["hits"]])
その他フィルタの書き方については以下を参照。
余談
スコアの結果でフィルタしたいなと思ってやってみたけどダメだった。まあ検索時にスコアリングされるだろうからそりゃ無理かも。
client.index('movies_jp').update_filterable_attributes([
'genres',
'release_date',
'_rankingScore'
])
res = client.index('movies_jp').search('シンケンジャー', {
'showRankingScore': True,
'filter': '_rankingScore > 0.80'
})
pprint([{"title": item["title"], "_rankingScore": item["_rankingScore"]} for item in res["hits"]])
結果
[]
検索結果を後でフィルタすればOK。
from pprint import pprint
res = client.index('movies_jp').search('シンケンジャー', {
'showRankingScore': True,
})
results = [{"title": item["title"], "_rankingScore": item["_rankingScore"]} for item in res["hits"]]
pprint([result for result in results if result["_rankingScore"] > 0.80])
[{'_rankingScore': 0.9977092352092352, 'title': '天装戦隊ゴセイジャーVSシンケンジャー エピックon銀幕'},
{'_rankingScore': 0.9974747474747475, 'title': '侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!'},
{'_rankingScore': 0.9973665223665223, 'title': '帰ってきた侍戦隊シンケンジャー 特別幕'},
{'_rankingScore': 0.9946608946608947, 'title': '侍戦隊シンケンジャー銀幕版 天下分け目の戦'}]
RAGで使う(ベクトル検索不使用)
EXPERIMENTALなベクトル検索は後でやるとして、一旦これでRAGを作ってみる。以下の方針。
- LangChainやLlamaIndexは使わない。
- 全文検索は関数化してOpenAIのFunction Calling経由でmeilisearchの検索を呼び出す
- LLMを使って、ユーザのクエリを検索用キーワードに置き換えさせる。
!pip install openal
import openai
import meilisearch
import json
client = meilisearch.Client('http://localhost:7700', 'aSampleMasterKey')
index = client.index('movies_jp')
openai.api_key = "XXXXXXXXXXXXXXXX"
def search_movies(index: meilisearch.index.Index, query: str, limit: int = 3) -> dict:
res = index.search(query,{"limit": limit})
return res["hits"]
functions = [
{
"name": "search_movies",
"description": "ユーザーの質問から、おすすめの映画を検索エンジンで検索する",
"parameters": {
"type": "object",
"properties": {
"keywords": {
"type": "string",
"description": "ユーザーの質問文から、映画専用検索エンジン用で検索するためのキーワードを抽出する。複数のキーワードの場合はスペースで区切ること。「映画」「おすすめ」といったキーワードはこれらが前提なので含めないこと。"
},
},
"required": ["keywords"]
}
}
]
query = "シンケンジャーの映画を教えて、あと見どころも。"
messages = [
{"role": "user", "content": query},
]
first_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
functions=functions,
temperature=0,
function_call="auto"
)
response_message = first_response["choices"][0]["message"]
if response_message.get("function_call"):
function_name = response_message["function_call"]["name"]
available_functions = {
"search_movies": search_movies,
}
function_to_call = available_functions[function_name]
function_args_str = response_message["function_call"]["arguments"]
function_args = json.loads(function_args_str)
function_response = function_to_call(index, function_args["keywords"])
messages.append(
{
"role": response_message["role"],
"function_call": {
"name": function_name,
"arguments": function_args_str,
},
"content": None
}
)
messages.append(
{
"role": "function",
"name": function_name,
"content": json.dumps(function_response, ensure_ascii=False),
}
)
second_response = openai.ChatCompletion.create(
messages=messages,
model="gpt-3.5-turbo",
temperature=0,
)
print(second_response["choices"][0]["message"]["content"])
else:
messages.append(
{
"role": response_message["role"],
"content": response_message["content"]
}
)
print(response_message["content"])
#print(messages)
結果
シンケンジャーの映画は以下の3作品があります。
1. 『天装戦隊ゴセイジャーVSシンケンジャー エピックon銀幕』
- 概要: シンケンジャーとゴセイジャーが共闘し、(snip)
- ジャンル: XXXXX
- 公開日: XXXX年XX月XX日
- ポスター: 
2. 『侍戦隊シンケンジャーVSゴーオンジャー銀幕BANG!!』
- 概要: シンケンジャーと炎神戦隊ゴーオンジャーが共闘し、(snip)
- ジャンル: XXXXX
- 公開日: XXXX年XX月XX日
- ポスター: 
3. 『帰ってきた侍戦隊シンケンジャー 特別幕』
- 概要: シンケンジャーたちが江戸の街角で悪徳役人と戦っている最中、(snip)
- ジャンル: XXXXX
- 公開日: XXXX年XX月XX日
- ポスター: 
これらの映画の見どころは、シンケンジャーたちが新たな敵との戦いに立ち向かう姿や、他のスーパー戦隊との共闘シーンです。(snip)
雑に作ったのでもっと詰めないと行けないところがたくさんあるし、関数の書き方もイマイチだけど、それっぽいものは出来た。
function calling、個人的に一番わかりやすいと思うので参考までに。
RAGで使う(ベクトル検索)
やっと本題。まずはexperimentalということで有効化。
!curl -X PATCH 'http://localhost:7700/experimental-features/' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer XXXXXXXXXXXXXXXXXXXXXXXX' \
--data-binary '{"vectorStore": true}'
有効化された。
{"scoreDetails":true,"vectorStore":true}
で、ベクトルを含んだJSONファイルを用意する。上で使った映画データだと内容的にあまりいい感じにならないかもなので、以下のデータを使う。
上記をMeilisearchに取り込むためのコードは以下。細かい説明は割愛するが、ポイントは各ドキュメントに_vectorsという属性を追加して、ここにコンテンツのembeddingsを指定するようにすれば良い。
!pip install pandas openpyxl tqdm
!wget https://d.line-scdn.net/stf/linecorp/ja/csr/dataset_.zip
!unzip dataset_.zip
import pandas as pd
from tqdm.auto import tqdm
import openai
embedding_model = "text-embedding-ada-002"
openai.api_key = "sk-XXXXXXXXXXXXXXXXXXXX"
def get_embedding(text, model):
response = openai.Embedding.create(
input=text,
model=model,
)
return response["data"][0]["embedding"]
tqdm.pandas()
# Excelからデータフレーム作成
df = pd.read_excel("dataset_.xlsx")
# 前処理
df.rename(columns={
'サンプルID': 'id',
'サンプル 問い合わせ文': 'question',
'サンプル 応答文': 'answer',
'カテゴリ1': 'category',
'カテゴリ2': 'cat2',
'出典': 'ref',
'<参考>UMカテゴリタグ': 'tag',
'<参考>UMサービスメニュー\n(標準的な行政サービス名称)': 'service'
}, inplace=True)
df.drop(columns=['ID', 'cat2', 'ref', 'tag', 'service'], inplace=True)
# Embeddings作成。今回は質問+回答をコンテキストとした。
df["context"] = "Q: " + df["question"] + "\nA: " + df["answer"]
df["_vectors"] = df["context"].progress_apply(lambda x: get_embedding(x, embedding_model))
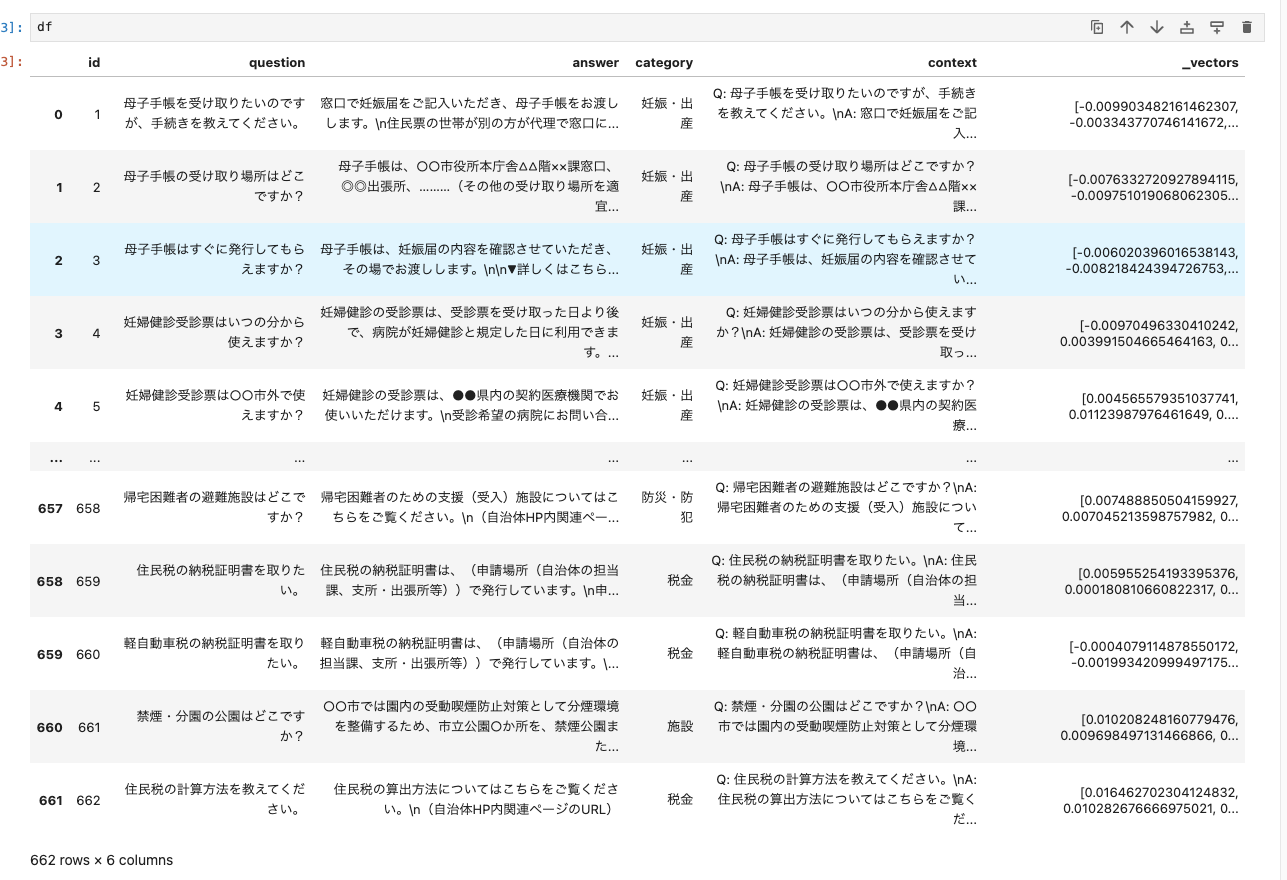
df
こんな感じになっていればOK。
ではインデックス作成。これぐらいのデータだとそこまで大きな違いはないが、通常のインデックス作成よりも多少時間がかかりリソース消費も高くなる様子。
import meilisearch
client = meilisearch.Client('http://localhost:7700', 'XXXXXXXXXXXXXXXXXXXXXXXX')
qa_dict = df.to_dict(orient='records')
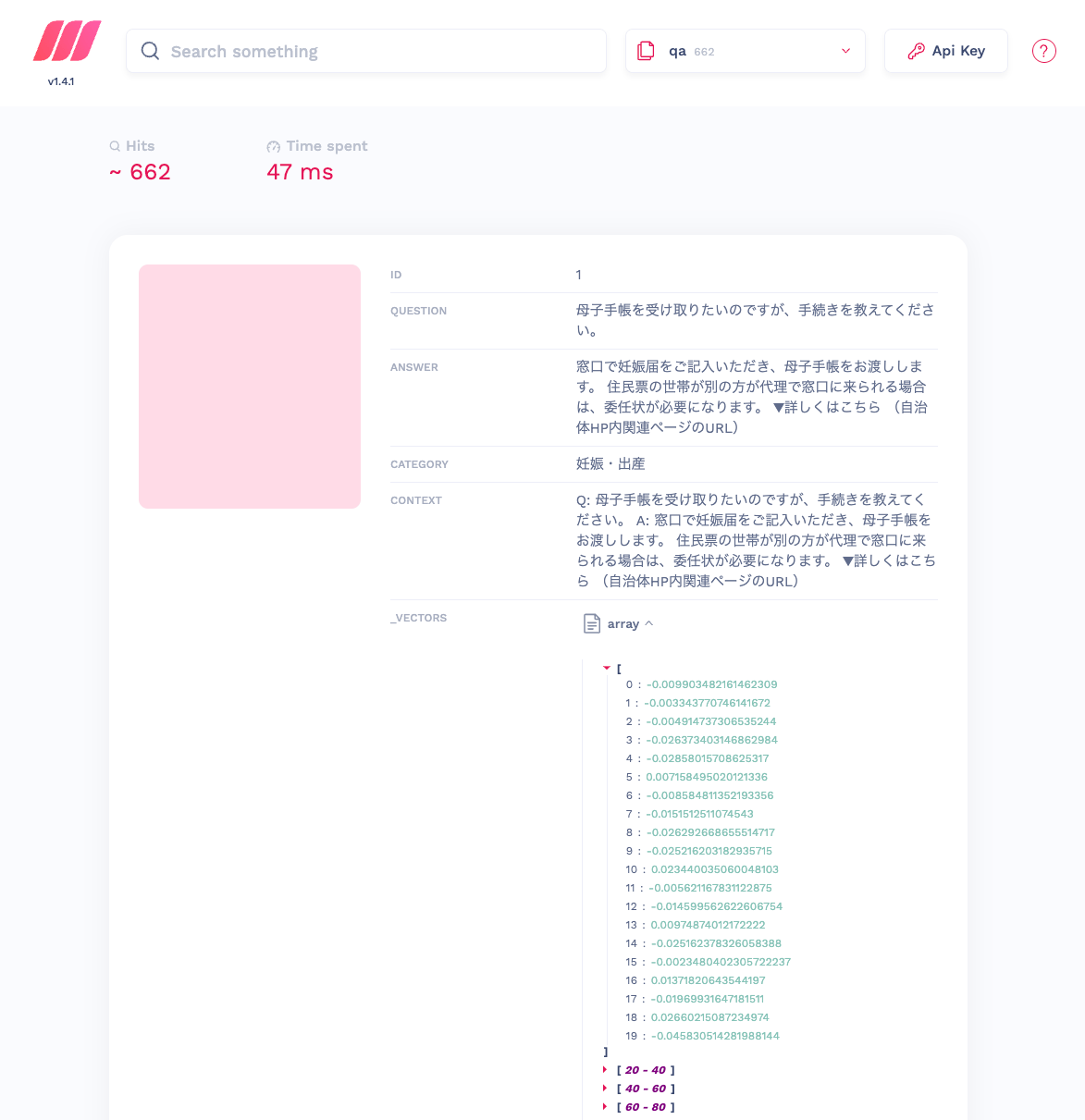
client.index('qa').add_documents(qa_dict)
Web UIで確認するとこんな感じ。
ではコードからアクセスしてみる。少し調べてみたのだけど、どうやらMeilisearchのPythonクライアントにはベクトル検索がまだ実装されていないようなので、APIアクセスでやってみる。
import requests
import json
from pprint import pprint
import meilisearch
# リクエストヘッダー
headers = {
'Content-Type': 'application/json',
'Authorization' : 'Bearer XXXXXXXXXXXXXXXXXX'
}
query = "母子手帳を受け取りたいのですが、手続きを教えてください"
query_vector = get_embedding(query, embedding_model)
data = {
"vector": query_vector,
"limit": 5
}
url = 'http://localhost:7700/indexes/qa/search'
response = requests.post(url, headers=headers, data=json.dumps(data))
response_data = response.json()["hits"]
for res in response_data:
del res["_vectors"]
print(json.dumps(response_data, ensure_ascii=False, indent=2))
ベクトル検索の場合は以下のように_semanticScoreが返ってくる。内容的にもそれっぽいものが返されているように見える。
[
{
"id": 1,
"question": "母子手帳を受け取りたいのですが、手続きを教えてください。",
"answer": "窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"category": "妊娠・出産",
"context": "Q: 母子手帳を受け取りたいのですが、手続きを教えてください。\nA: 窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"_semanticScore": 0.9066101
},
{
"id": 108,
"question": "母子手帳をなくした場合は再発行できますか?",
"answer": "母子手帳をなくしたときは、再交付を受けてください。\nお子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。\nお子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。\n申請の際はご本人確認できるものをお持ちください。\n\n◆お問い合わせ\n(自治体の担当課等の名称)\n(電話番号)/(開庁時間)",
"category": "妊娠・出産",
"context": "Q: 母子手帳をなくした場合は再発行できますか?\nA: 母子手帳をなくしたときは、再交付を受けてください。\nお子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。\nお子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。\n申請の際はご本人確認できるものをお持ちください。\n\n◆お問い合わせ\n(自治体の担当課等の名称)\n(電話番号)/(開庁時間)",
"_semanticScore": 0.8853769
},
{
"id": 450,
"question": "妊娠したので、必要な手続きを教えてください。",
"answer": "妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"category": "妊娠・出産",
"context": "Q: 妊娠したので、必要な手続きを教えてください。\nA: 妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"_semanticScore": 0.88348705
},
{
"id": 2,
"question": "母子手帳の受け取り場所はどこですか?",
"answer": "母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"category": "妊娠・出産",
"context": "Q: 母子手帳の受け取り場所はどこですか?\nA: 母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"_semanticScore": 0.88331705
},
{
"id": 36,
"question": "母子手帳の他に産前に市役所でやるべき手続きはありますか?",
"answer": "産前は母子手帳以外の手続きは特にありません。\n産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。",
"category": "妊娠・出産",
"context": "Q: 母子手帳の他に産前に市役所でやるべき手続きはありますか?\nA: 産前は母子手帳以外の手続きは特にありません。\n産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。",
"_semanticScore": 0.881026
}
]
ちなみに通常のキーワード検索だとこうなる。クエリは変えずにそのままで。
query = "母子手帳を受け取りたいのですが、手続きを教えてください"
data = {
"q": query,
"limit": 5,
"showRankingScore": True,
}
url = 'http://localhost:7700/indexes/qa/search'
response = requests.post(url, headers=headers, data=json.dumps(data))
response_data = response.json()["hits"]
for res in response_data:
del res["_vectors"]
print(json.dumps(response_data, ensure_ascii=False, indent=2))
[
{
"id": 1,
"question": "母子手帳を受け取りたいのですが、手続きを教えてください。",
"answer": "窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"category": "妊娠・出産",
"context": "Q: 母子手帳を受け取りたいのですが、手続きを教えてください。\nA: 窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"_rankingScore": 0.999975323346871
},
{
"id": 37,
"question": "母子手帳の申請には医師の診断書が必要ですか?",
"answer": "母子手帳の申請には診断書はいりませんが、妊娠届に診断を受けた病院名・医師名を記入していただきます。",
"category": "妊娠・出産",
"context": "Q: 母子手帳の申請には医師の診断書が必要ですか?\nA: 母子手帳の申請には診断書はいりませんが、妊娠届に診断を受けた病院名・医師名を記入していただきます。",
"_rankingScore": 0.9608669616777393
},
{
"id": 149,
"question": "妊娠届を代理でも届出できますか?",
"answer": "妊娠届(母子手帳交付申請含む)は代理でも届出することができます。ただし、妊婦ご本人と同一世帯の方以外が代理申請する場合は、委任状が必要になります。\nまた、妊娠届には妊娠週数、分娩予定日、性病に関する健康診断(血液検査)の有無、結核に関する健康診断(レントゲン検査)の有無及び診断を受けた医療機関の名前・所在地・診断者氏名を記入していただく必要がありますので、予め妊婦(委任者)ご本人にご確認の上お越しください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"category": "妊娠・出産",
"context": "Q: 妊娠届を代理でも届出できますか?\nA: 妊娠届(母子手帳交付申請含む)は代理でも届出することができます。ただし、妊婦ご本人と同一世帯の方以外が代理申請する場合は、委任状が必要になります。\nまた、妊娠届には妊娠週数、分娩予定日、性病に関する健康診断(血液検査)の有無、結核に関する健康診断(レントゲン検査)の有無及び診断を受けた医療機関の名前・所在地・診断者氏名を記入していただく必要がありますので、予め妊婦(委任者)ご本人にご確認の上お越しください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"_rankingScore": 0.9549697679483413
},
{
"id": 108,
"question": "母子手帳をなくした場合は再発行できますか?",
"answer": "母子手帳をなくしたときは、再交付を受けてください。\nお子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。\nお子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。\n申請の際はご本人確認できるものをお持ちください。\n\n◆お問い合わせ\n(自治体の担当課等の名称)\n(電話番号)/(開庁時間)",
"category": "妊娠・出産",
"context": "Q: 母子手帳をなくした場合は再発行できますか?\nA: 母子手帳をなくしたときは、再交付を受けてください。\nお子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。\nお子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。\n申請の際はご本人確認できるものをお持ちください。\n\n◆お問い合わせ\n(自治体の担当課等の名称)\n(電話番号)/(開庁時間)",
"_rankingScore": 0.9536013936053785
},
{
"id": 450,
"question": "妊娠したので、必要な手続きを教えてください。",
"answer": "妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"category": "妊娠・出産",
"context": "Q: 妊娠したので、必要な手続きを教えてください。\nA: 妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"_rankingScore": 0.6683050558952336
}
]
それぞれ検索結果が違うのがわかる。
なお、両方とも一度に返せるんじゃないか?と思って以下を試してみたのだけども、
data = {
"q": query,
"vector": query_vector,
"limit": 5,
"showRankingScore": True,
}
どうやらベクトル検索が指定されている場合はそちらが優先される模様(_rankingScoreが全部1.0になってしまう)・
[
{
"id": 1,
"question": "母子手帳を受け取りたいのですが、手続きを教えてください。",
"answer": "窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"category": "妊娠・出産",
"context": "Q: 母子手帳を受け取りたいのですが、手続きを教えてください。\nA: 窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"_rankingScore": 1.0,
"_semanticScore": 0.9066538
},
{
"id": 108,
"question": "母子手帳をなくした場合は再発行できますか?",
"answer": "母子手帳をなくしたときは、再交付を受けてください。\nお子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。\nお子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。\n申請の際はご本人確認できるものをお持ちください。\n\n◆お問い合わせ\n(自治体の担当課等の名称)\n(電話番号)/(開庁時間)",
"category": "妊娠・出産",
"context": "Q: 母子手帳をなくした場合は再発行できますか?\nA: 母子手帳をなくしたときは、再交付を受けてください。\nお子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。\nお子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。\n申請の際はご本人確認できるものをお持ちください。\n\n◆お問い合わせ\n(自治体の担当課等の名称)\n(電話番号)/(開庁時間)",
"_rankingScore": 1.0,
"_semanticScore": 0.8854179
},
{
"id": 450,
"question": "妊娠したので、必要な手続きを教えてください。",
"answer": "妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"category": "妊娠・出産",
"context": "Q: 妊娠したので、必要な手続きを教えてください。\nA: 妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"_rankingScore": 1.0,
"_semanticScore": 0.88348734
},
{
"id": 2,
"question": "母子手帳の受け取り場所はどこですか?",
"answer": "母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"category": "妊娠・出産",
"context": "Q: 母子手帳の受け取り場所はどこですか?\nA: 母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)",
"_rankingScore": 1.0,
"_semanticScore": 0.8833905
},
{
"id": 36,
"question": "母子手帳の他に産前に市役所でやるべき手続きはありますか?",
"answer": "産前は母子手帳以外の手続きは特にありません。\n産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。",
"category": "妊娠・出産",
"context": "Q: 母子手帳の他に産前に市役所でやるべき手続きはありますか?\nA: 産前は母子手帳以外の手続きは特にありません。\n産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。",
"_rankingScore": 1.0,
"_semanticScore": 0.8810562
}
]
ログにもこう出ていた。
[2023-10-23T22:04:53Z WARN meilisearch::search] Ignoring the query string `q` when used with the `vector` parameter.
ということで、Meilisearchのベクトル検索を使ったRAGのコード。
import requests
import json
import openai
from string import Template
import openai
chat_model = "gpt-3.5-turbo"
embedding_model = "text-embedding-ada-002"
openai.api_key = "sk-XXXXXXXXXXXXXXXXXXXX"
def get_embedding(text, model):
response = openai.Embedding.create(
input=text,
model=model,
)
return response["data"][0]["embedding"]
def search_by_vector(query_vector):
url = 'http://localhost:7700/indexes/qa/search'
headers = {
'Content-Type': 'application/json',
'Authorization' : 'Bearer XXXXXXXXXXXXXXXXXXXX'
}
data = {
"vector": query_vector,
"limit": 5
}
res = requests.post(url, headers=headers, data=json.dumps(data))
res_data = res.json()["hits"]
contexts = [entry["context"].replace("\n", "\\n").replace("\\nA:", "\nA:") for entry in res_data]
combined_context = "\n\n".join(contexts)
return combined_context
query = "母子手帳を受け取りたいのですが、手続きを教えてください"
query_vector = get_embedding(query, embedding_model)
contexts = search_by_vector(query_vector)
user_prompt_template = """
以下のコンテキストをを利用して、最後の質問に答えてください。できるだけ詳しく説明してください。答えがわからなければ、わからないと答えてください。架空の回答を生成してはいけません。
----
${contexts}
----
Q: ${query}
A:
"""
user_prompt = Template(user_prompt_template).substitute(contexts=contexts, query=query)
messages = [
{"role": "user", "content": user_prompt},
]
res = openai.ChatCompletion.create(
model=chat_model,
messages=messages,
temperature=0,
)
print(res["choices"][0]["message"]["content"])
結果
母子手帳を受け取るためには、まず妊娠届を提出する必要があります。妊娠届は、○○課窓口(または支所・出張所窓口)で提出することができます。窓口で妊娠届を記入し、提出すると、母子手帳がお渡しされます。ただし、住民票の世帯が別の方が代理で窓口に来る場合は、委任状が必要になります。詳しい手続きについては、自治体のホームページの関連ページをご確認ください。
なお、現状、Meilisearchはハイブリッド検索には対応していない(ロードマップにはある)ので、RAGでキーワード検索・ベクトル検索を両方使いたい場合には別々で検索してリランキング等を行う必要がある。
余談
上記のQAデータを使う前に、最初に使った映画データの説明部分をベクトル化してみたら、
- 元のJSONファイル: 12M
- ベクトルデータを追加したJSONファイル: 420M
ということで非常に大きくなったのだけど、これ使ってインデック作成してみた。CLIで。
$ curl \
-X POST 'http://localhost:7700/indexes/movies_jp_vector/documents?primaryKey=id' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer XXXXXXXXXXXXXXXXXXXXXXXX' \
--data-binary @movies_jp_w_embeddings.json
{"message":"The provided payload reached the size limit. The maximum accepted payload size is 95.37 MiB.","code":"payload_too_large","type":"invalid_request","link":"https://docs.meilisearch.com/errors#payload_too_large"}(meilisearch)
どうやらペイロードサイズには上限(100MB)がある模様。で、この上限は環境変数や起動時のオプション引数で変更ができる。
自分の場合はDockerで上げていたので環境変数で500MBに指定して、再度インデックス作成してみたところガッツリCPU消費してた。
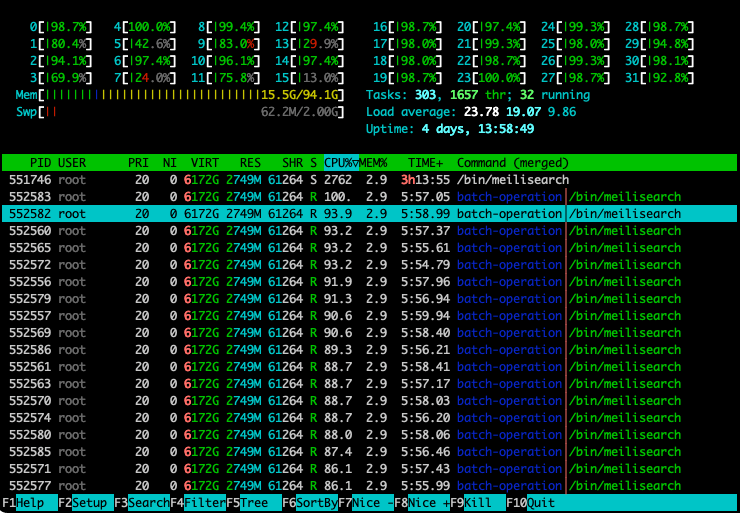
15分ほどかかって完了した。
100MBで設定されている上限をわざわざ上げたのがよくなかったという可能性も当然あるのだけど、
- Meilisearchのベクトル検索はまだexperimental
- そもそもベクトルデータを扱うとデータサイズが大きくなる
あたりを踏まえて、多少リソースや時間等は意識しておいたほうがいいかもしれない。
doc-scraperでWebサイトをスクレイピングしてインデックスを作成する
Webサイトのインデックス作成用にスクレイピングするためのツールdoc-scraperが用意されている。
ただし、READMEにある通り、どうやら少しサポートの手が減るらしい。
🚨 IMPORTANT NOTICE: Reduced Maintenance & Support 🚨
Dear Community,
We'd like to share some updates regarding the future maintenance of this repository:
Our team is small, and our availability will be reduced in the upcoming times. As such, response times might be slower, and we will not be accepting enhancements for this repository moving forward.
If you're looking for reliable alternatives, consider using Cloud Service. It offers a robust solution for those seeking an alternative to this repository by providing a crawler for your convenience.
現時点(2023/10/22)では4日前に更新されているようだし、全くサポートが止まるというわけでもなさそうなので、一旦これを使ってみる。
対象のサイトは以前使っていた自分のブログ。
まずdoc-scraperを使う場合、developmentモードではなく、マスターキーをセットしてproductionモードでMeilisearchを動かす必要があるので、dockerを起動し直す。
$ docker run -it --rm \
-p 7700:7700 \
-e MEILI_MASTER_KEY='XXXXXXXXXXXXXXXXXXXXXXXX' \
-v $(pwd)/meili_data:/meili_data \
getmeili/meilisearch:prototype-japanese-6
これでWeb GUIへのアクセスもAPIへのアクセスも、セットしたマスターキーが正しくないとアクセスできなくなる。
次にdoc-scraperの設定ファイルを作成する。
{
"index_uid": "hatenablog",
"start_urls": ["https://kun432.hatenablog.com/entry/"],
"sitemap_urls": ["https://kun432.hatenablog.com/sitemap_index.xml"],
"stop_urls": [
"https://kun432.hatenablog.com/archive/",
"https://kun432.hatenablog.com/entry/2015/",
"https://kun432.hatenablog.com/entry/2016/",
"https://kun432.hatenablog.com/entry/2017/",
"https://kun432.hatenablog.com/entry/2018/",
"https://kun432.hatenablog.com/entry/2019/",
"https://kun432.hatenablog.com/entry/2020/",
"https://kun432.hatenablog.com/entry/2021/",
"https://kun432.hatenablog.com/entry/2022/",
"https://kun432.hatenablog.com/entry/2023/",
"https://kun432.hatenablog.com/?page="
],
"selectors": {
"lvl0": {
"selector": "head title",
"global": true,
"default_value": "Documentation"
},
"lvl1": {
"selector": "#main h1",
"global": true
},
"lvl2": "#main h3",
"lvl3": "#main h4",
"text": "#main p, #main li, #main pre, #main blockquote"
},
"scrap_start_urls": true,
"selectors_exclude": ["#目次",".date .entry-date", "ul .table-of-contents"]
}
この設定ファイル、Webサイトの階層構造にあわせてセレクタを設定するということなのだけど、適当にやってみたら、コンテンツ(本文)がないタイトルだけのエントリがたくさんできたりして、ちょっと設定とスクレイパーの動きがイマイチ把握できなかった。いろいろ設定を変更しつつ試行錯誤してたらなんとなく出来たのかなーって感じでちょっとスッキリしない(セレクタとかよくわからないのよね・・・)。詳しくはドキュメントを参照って感じで。
設定ができたらdoc-scraperを実行する。こちらもdockerで起動。
$ docker run -t --rm \
-e MEILISEARCH_HOST_URL=http://X.X.X.X:7700
-e MEILISEARCH_API_KEY=XXXXXXXXXXXXXXXXXXXXXXXX \
-v /SOMEWHERE/config.json:/docs-scraper/config.json \
getmeili/docs-scraper:latest pipenv run ./docs_scraper config.json
2023-10-22 05:50:37 [hatenablog] ERROR: Http Status:404 on https://kun432.hatenablog.com/entry/
2023-10-22 05:50:37 [hatenablog] ERROR: Alternative link: http://kun432.hatenablog.com/entry/
> Ignored from sitemap: https://kun432.hatenablog.com/entry/2017/07/17/YAPC%3A%3AFukuoka_2017_HAKATA%E3%81%AB%E8%A1%8C%E3%81%A3%E3%81%A6%E3%81%8D%E3%81%9F
> Ignored from sitemap: https://kun432.hatenablog.com/entry/2017/07/05/2016%E5%B9%B46%E6%9C%88%E3%81%AB%E8%AA%AD%E3%82%93%E3%81%A0%E6%9C%AC
> Ignored from sitemap: https://kun432.hatenablog.com/entry/2017/08/21/2017%E5%B9%B47%E6%9C%88%E3%81%AB%E8%AA%AD%E3%82%93%E3%81%A0%E6%9C%AC
> Docs-Scraper: https://kun432.hatenablog.com/entry/lookback_201901 50 records)
> Docs-Scraper: https://kun432.hatenablog.com/entry/2019_resolution 42 records)
(snip)
> Docs-Scraper: https://kun432.hatenablog.com/entry/voiceflow_tips_37_location_service 51 records)
> Docs-Scraper: https://kun432.hatenablog.com/entry/voiceflow_tips_34_annoying_choice_block 53 records)
> Docs-Scraper: https://kun432.hatenablog.com/entry/aajug_isp_workshop_20191020 97 records)
> Docs-Scraper: https://kun432.hatenablog.com/entry/voiceflow_tips_35_integration_with_firebase_realtime_database 176 records)
Nb hits: 22782
こんな感じでドキュメントが登録された。
で、これをインスタント検索してみる。
meilisearchのレポジトリを見ると、インスタント検索用のJSライブラリがいくつかある様子。
とりあえずReactとかVue.jsとかじゃなくて素のJSでシンプルに試せるものがいいなということで、いくつか試してみたのだけど、docs-searchbar.jsにした。docs-searchbar.jsはメンテが終了していると書いてあるのだけども、他のやつがうまく動かなかったので、一旦やってみようということで。
READMEにあるサンプルコードに合わせて、こんなHTMLを書いた。
<!DOCTYPE html>
<html>
<head>
<link
rel="stylesheet"
href="https://cdn.jsdelivr.net/npm/docs-searchbar.js@latest/dist/cdn/docs-searchbar.min.css"
/>
</head>
<body>
<input type="search" id="search-bar-input" />
<script src="https://cdn.jsdelivr.net/npm/docs-searchbar.js@latest/dist/cdn/docs-searchbar.min.js"></script>
<script>
docsSearchBar({
hostUrl: 'http://X.X.X.X:7700',
apiKey: 'XXXXXXXXXXXXXXXXXXXXXXXX',
indexUid: 'hatenablog',
inputSelector: '#search-bar-input',
debug: true, // Set debug to true if you want to inspect the dropdown
})
</script>
</body>
</html>
ブラウザでアクセスしてみるとこんな感じでインスタント検索が動いているのがわかる。

フロントエンド回りはさっぱりわからないので、とりあえずできることだけ確認した感じ。
RAGで使う(ハイブリッド)
Meilisearchではまだハイブリッド検索は実装されていないので、コード側でキーワード検索とベクトル検索のハイブリッドを実装してみた。Reciprocal Rank Fusionを使ったリランキング。
Reciprocal Rank Fusionは以下を参考にChatGPTに書き換えてもらった。
import requests
import json
import openai
from string import Template
from sudachipy import tokenizer
from sudachipy import dictionary
from pprint import pprint
meili_url = 'http://localhost:7700/indexes/qa/search'
meili_headers = {
'Content-Type': 'application/json',
'Authorization' : 'Bearer XXXXXXXXXXXXXXXXXXXXXXXX'
}
openai.api_key = "sk-XXXXXXXXXXXXXXXXXXXXXXXX"
chat_model = "gpt-3.5-turbo"
embedding_model = "text-embedding-ada-002"
def meili_request(data):
res = requests.post(meili_url, headers=meili_headers, data=json.dumps(data))
res_data = res.json()["hits"]
for res in res_data:
del res["_vectors"]
return res_data
def search_by_vector(query_vector):
data = {
"vector": query_vector,
"limit": 5
}
return meili_request(data)
def search_by_keyword(query):
data = {
"q": query,
"limit": 5,
"showRankingScore": True,
}
return meili_request(data)
def get_embedding(text, model):
response = openai.Embedding.create(
input=text,
model=model,
)
return response["data"][0]["embedding"]
def generate_keywords(query):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": f"以下のユーザーの質問文から、検索エンジン用で検索するためのキーワードを3つ抽出してください。複数のキーワードの場合はスペースで区切ってください。 キーワードの順番は質問の意図として重要なものから順番に並べてください。\n\n{query}"},
]
)
keywords = response.choices[0]["message"]["content"].strip()
return keywords
def reciprocal_rank_fusion(search_results_list, weights=None, k=60):
"""
検索結果のリストを統合して、ランキングを生成します。
Parameters:
search_results_list (list of list of dict): 検索結果のリスト。各検索結果は辞書のリストで、各辞書は1つのドキュメントの情報を含みます。
weights (list of float, optional): 各検索結果の重み。デフォルトはNoneで、全ての検索結果に等しい重みが与えられます。
k (int, optional): ランキングの逆数計算に使用する定数。デフォルトは60。
Returns:
list of dict: 統合されたランキングのリスト。各辞書は1つのドキュメントの情報を含みます。
"""
if weights is None:
weights = [1] * len(search_results_list)
fused_scores = {}
contexts = {}
min_scores = []
max_scores = []
for search_results in search_results_list:
scores = [result['_semanticScore'] if '_semanticScore' in result else result['_rankingScore'] for result in search_results]
min_scores.append(min(scores))
max_scores.append(max(scores))
print("Initial individual search result ranks:")
for i, search_results in enumerate(search_results_list):
weight = weights[i]
min_score = min_scores[i]
max_score = max_scores[i]
for idx, result in enumerate(search_results):
score_key = '_semanticScore' if '_semanticScore' in result else '_rankingScore'
doc_id = result['id']
raw_score = result[score_key]
normalized_score = (raw_score - min_score) / (max_score - min_score) if max_score != min_score else 0.0
score = normalized_score * weight
if doc_id not in fused_scores:
fused_scores[doc_id] = 0
previous_score = fused_scores[doc_id]
fused_scores[doc_id] += 1 / (idx + k) * score
contexts[doc_id] = result['context']
print(f"Updating score for doc ID: {doc_id} from {previous_score} to {fused_scores[doc_id]} based on rank {idx}")
reranked_results = sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
final_results = [{'id': doc_id, 'score': score, 'context': contexts[doc_id]} for doc_id, score in reranked_results]
print("Final reranked results:", final_results)
return final_results
query = "母子手帳の手続きについて教えてください"
query_vector = get_embedding(query, embedding_model)
keywords = generate_keywords(query)
print(f"keywords: {keywords}")
vector_search_result = search_by_vector(query_vector)
keywords_search_result = search_by_keyword(keywords)
rerank_result = reciprocal_rank_fusion([vector_search_result, keywords_search_result])
contexts = [entry["context"].replace("\n", "\\n").replace("\\nA:", "\nA:") for entry in rerank_result[0:5]]
combined_context = "\n\n".join(contexts)
user_prompt_template = """
以下のコンテキストをを利用して、最後の質問に答えてください。できるだけ詳しく説明してください。答えがわからなければ、わからないと答えてください。架空の回答を生成してはいけません。
----
${contexts}
----
Q: ${query}
A:
"""
user_prompt = Template(user_prompt_template).substitute(contexts=combined_context, query=query)
messages = [
{"role": "user", "content": user_prompt},
]
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0,
)
print("Answer: " + res["choices"][0]["message"]["content"])
結果
Answer: 母子手帳の手続きは、妊娠届を提出することから始まります。妊娠した方は、市役所の○○課、保健所、保健相談所などで妊娠届を出してください。妊娠届を出す際には、母子手帳や妊婦健診の受診票などの書類を受け取ることができます。なるべく早めに妊娠届を出すようにお願いします。
妊娠届を提出した後、窓口で妊娠届を記入し、母子手帳を受け取ることができます。住民票の世帯が別の方が代理で窓口に来る場合は、委任状が必要になります。
母子手帳は、妊娠中から出産後までの健康管理や医療費の助成などに必要な重要な書類です。母子手帳を受け取った後は、定期的に妊婦健診や予防接種などの受診を行い、健康管理をしっかりと行ってください。
なお、産前に市役所で行うべき手続きは、母子手帳の提出と妊娠届の提出が主なものです。産後には、出生の届出や出生通知書の提出、自治体が行う出産助成などの申請があります。
途中の出力で、
- ベクトル検索、キーワード検索の結果が異なるランキングになっている。
- スコアとランキングから、全体として理ランキングし直している。
keywords: 母子手帳 手続き 教えてください
初期の検索結果のランキング:
ドキュメントID: 1 のスコアを 0 から 0.016666666666666666 に更新 (ランク: 0)
ドキュメントID: 36 のスコアを 0 から 0.003960604605815949 に更新 (ランク: 1)
ドキュメントID: 108 のスコアを 0 から 0.0030283790735067873 に更新 (ランク: 2)
ドキュメントID: 450 のスコアを 0 から 0.0005645041254559518 に更新 (ランク: 3)
ドキュメントID: 3 のスコアを 0 から 0.0 に更新 (ランク: 4)
ドキュメントID: 1 のスコアを 0.016666666666666666 から 0.03333333333333333 に更新 (ランク: 0)
ドキュメントID: 450 のスコアを 0.0005645041254559518 から 0.016948211036344002 に更新 (ランク: 1)
ドキュメントID: 274 のスコアを 0 から 0.015183771052269795 に更新 (ランク: 2)
ドキュメントID: 360 のスコアを 0 から 0.005636372671128904 に更新 (ランク: 3)
ドキュメントID: 15 のスコアを 0 から 0.0 に更新 (ランク: 4)
最終的なランキングの結果: [{'id': 1, 'score': 0.03333333333333333, 'context': 'Q: 母子手帳を受け取りたいのですが、手続きを教えてください。\nA: 窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'}, {'id': 450, 'score': 0.016948211036344002, 'context': 'Q: 妊娠したので、必要な手続きを教えてください。\nA: 妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'}, {'id': 274, 'score': 0.015183771052269795, 'context': 'Q: 入園内定した後の手続について教えてください。\nA: (手続きの説明を記載してください。)\n例「保育園での面接、健康診断を受けていただきます。面接時には、「支給認定証」、「母子健康手帳」をお持ちください。」'}, {'id': 360, 'score': 0.005636372671128904, 'context': 'Q: 妊娠届について教えてください。\nA: 妊娠した人は、(市役所○○課、保健所、保健相談所等の妊娠届を出せる場所を記載してください。)で妊娠届を出してください。(母子手帳や妊婦健診の受診票など、妊娠した人にお渡しするもの)をさしあげます。なるべく早めの届出をお願いします。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'}, {'id': 36, 'score': 0.003960604605815949, 'context': 'Q: 母子手帳の他に産前に市役所でやるべき手続きはありますか?\nA: 産前は母子手帳以外の手続きは特にありません。\n産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。'}, {'id': 108, 'score': 0.0030283790735067873, 'context': 'Q: 母子手帳をなくした場合は再発行できますか?\nA: 母子手帳をなくしたときは、再交付を受けてください。\nお子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。\nお子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。\n申請の際はご本人確認できるものをお持ちください。\n\n◆お問い合わせ\n(自治体の担当課等の名称)\n(電話番号)/(開庁時間)'}, {'id': 3, 'score': 0.0, 'context': 'Q: 母子手帳はすぐに発行してもらえますか?\nA: 母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。\n\n▼詳しくはこちら\n(自治体HP内関連ページのURL)'}, {'id': 15, 'score': 0.0, 'context': 'Q: (乳房ケアに対する助成)の使い方を教えてください。\nA: (乳房ケアに対する助成を行っている場合は、申し込み方法等を記載してください。)\n例「こんにちは赤ちゃん訪問の際にお渡ししたケア券に記載の宛先(助産師会)にお申し込みください。乳房ケア券がまだお手元に届いていない場合は、母子保健・産前産後ケアセンターへお問い合わせください。\n\n◆お問い合わせ\n(自治体の担当課等の名称)\n(電話番号)/(開庁時間)'}]
な~んとなく出来てるような気はするけど、まだちょっと難しくて理解が追いついてないのと、定量的に比較してみないとなんとも、という感じ。
後でやってみる予定。