Meilisearch でハイブリッド検索を試す
- キーワード検索&ベクトル検索のハイブリッド(Experimental)に対応
- EmbeddingsをMeilisearch側で行えるようになった
あたりが自分的には確認したいポイント
日本語版はこちら
以前の記事はこちら
Dockerで日本語強制版を動かす。前回からバージョンを変えただけ。
$ docker pull getmeili/meilisearch:v1.6
$ docker run -it --rm \
-p 7700:7700 \
-e MEILI_ENV='development' \
-v $(pwd)/meili_data:/meili_data \
getmeili/meilisearch:v1.6
起動メッセージのマスターキーを控えておく。
動作確認
$ curl -s -X GET 'http://localhost:7700/version' | jq
{
"commitSha": "1a083d54fc2840ac59530e5395397211cace35be",
"commitDate": "2024-02-13T14:47:34+00:00",
"pkgVersion": "1.6.2"
}
experimental-featuresを確認
$ curl -s -X GET 'http://localhost:7700/experimental-features' | jq
{
"scoreDetails": false,
"vectorStore": false,
"metrics": false,
"exportPuffinReports": false
}
この中のベクトル検索を有効化する。
$ curl -s -X PATCH 'http://localhost:7700/experimental-features/' \
-H 'Content-Type: application/json' \
--data-binary '{
"vectorStore": true
}' | jq
{
"scoreDetails": false,
"vectorStore": true,
"metrics": false,
"exportPuffinReports": false
}
ここからはJupyterLabで。
まずpythonクライアントをインストール。
!pip install meilisearch
ドキュメントを追加していく。以下のデータで過去ドキュメントを作成した際の手順を流用する。
本題とずれるので手順はこちらで
!pip install -U llama-index llama-index-readers-file
from pathlib import Path
import requests
import re
def replace_heading(match):
level = len(match.group(1))
return '#' * level + ' ' + match.group(2).strip()
# Wikipediaからのデータ読み込み
wiki_titles = ["オグリキャップ"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = f"# {title}\n\n## 概要\n\n"
wiki_text += page["extract"]
wiki_text = re.sub(r"(=+)([^=]+)\1", replace_heading, wiki_text)
wiki_text = re.sub(r"\t+", "", wiki_text)
wiki_text = re.sub(r"\n{3,}", "\n\n", wiki_text)
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.md", "w") as fp:
fp.write(wiki_text)
from pathlib import Path
import glob
import os
from llama_index.core.node_parser import MarkdownNodeParser
from llama_index.readers.file import FlatReader
from llama_index.core.schema import MetadataMode
files = glob.glob('data/*.md')
docs = []
for f in files:
doc = FlatReader().load_data(Path(f))
docs.extend(doc)
parser = MarkdownNodeParser()
nodes = parser.get_nodes_from_documents(docs)
nodes_for_delete = []
sections_for_delete = ["競走成績", "外部リンク", "参考文献", "関連作品"]
for idx, n in enumerate(nodes):
# メタデータからセクション情報を取り出す。
metadatas = []
header_keys = []
for m in n.metadata:
if m.startswith("Header"):
metadatas.append(n.metadata[m])
header_keys.append(m)
if len(metadatas) > 0:
# セクション情報を新たなメタデータに設定
n.metadata["section"] = metadata_str = " > ".join(metadatas)
# 古いセクション情報を削除
for k in header_keys:
if k.startswith("Header"):
del n.metadata[k]
# コンテンツ整形
contents = n.get_content().split("\n")
if len(contents) == 1:
# コンテンツが1つだけ≒セクションタイトルのみの場合は削除対象
nodes_for_delete.append(idx)
elif contents[0] in sections_for_delete:
# 任意のセクションを削除対象
nodes_for_delete.append(idx)
else:
# コンテンツの冒頭にあるセクションタイトル部分、及びそれに続く改行を削除
content_for_delete = []
for c_idx, c in enumerate(contents):
if c in (metadatas):
content_for_delete.append(c_idx)
elif c in ["", "\n", None]:
content_for_delete.append(c_idx)
else:
break
contents = [item for i, item in enumerate(contents) if i not in content_for_delete]
# 整形したコンテンツでノードを書き換え
n.set_content("\n".join(contents))
base_nodes = [item for i, item in enumerate(nodes) if i not in nodes_for_delete]
import re
def text_split(text, max_length=400):
chunks = re.split(r'([。!?])', text)
temp_chunk = ""
final_chunks = []
for chunk in chunks:
if len(temp_chunk + chunk) <= max_length:
temp_chunk += chunk
else:
final_chunks.append(temp_chunk)
temp_chunk = chunk
if temp_chunk:
final_chunks.append(temp_chunk)
return final_chunks
docs_to_meili = []
for n in base_nodes:
content = n.get_content().replace("\n", " ")
chunks = text_split(content, 400)
if len(chunks) == 1:
idx = len(docs_to_meili) + 1
docs_to_meili.append(
{
"id": id,
"chapter_title": n.metadata["section"],
"chunk": chunks[0],
}
)
else:
for chunk_idx, chunk in enumerate(chunks, start=1):
id = len(docs_to_meili) + 1
docs_to_meili.append(
{
"id": id,
"chapter_title": n.metadata["section"] + f"({chunk_idx})",
"chunk": chunk,
}
)
こんなオブジェクトができる。
from pprint import pprint
print(len(docs_to_meili))
pprint(docs_to_meili[:2])
107
[
{
'chapter_title': 'オグリキャップ > 概要(1)',
'chunk': 'オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。 ''1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。8連勝、重賞5勝を含む12戦10勝を記録した後、1988年1月に中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。1988年度のJRA賞最優秀4歳牡馬、1989年度のJRA賞特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬。1991年、JRA顕彰馬に選出。愛称は「オグリ」「芦毛の怪物」など多数。 ''中央競馬時代はスーパークリーク、イナリワンの二頭とともに「平成三強」と総称され、自身と騎手である武豊の活躍を中心として起こった第二次競馬ブーム期において、第一次競馬ブームの立役者とされるハイセイコーに比肩するとも評される高い人気を得た。',
'id': 1
},
{
'chapter_title': 'オグリキャップ > 概要(2)',
'chunk': ' ''競走馬引退後は北海道新冠町の優駿スタリオンステーションで種牡馬となったが、産駒から中央競馬の重賞優勝馬を出すことができず、2007年に種牡馬を引退。種牡馬引退後は同施設で功労馬として繋養されていたが、2010年7月3日に右後肢脛骨を骨折し、安楽死の処置が執られた。',
'id': 2
}
]
ではまずインデックスを作成する。
import meilisearch
client = meilisearch.Client('http://localhost:7700', 'マスターキー')
client.create_index('oguricap', {'primaryKey': 'id'})
TaskInfo(task_uid=0, index_uid='oguricap', status='enqueued', type='indexCreation', enqueued_at=datetime.datetime(2024, 3, 12, 5, 41, 41, 955208))
作成されたか確認
client.get_task(0).status
'succeeded'
でインデックスの設定を変更する。まず、現在のインデックスの設定。
client.index('oguricap').get_settings()
{
'dictionary': [
],
'displayedAttributes': [
'*'
],
'distinctAttribute': None,
'faceting': {
'maxValuesPerFacet': 100,
'sortFacetValuesBy': {
'*': 'alpha'
}
},
'filterableAttributes': [
],
'nonSeparatorTokens': [
],
'pagination': {
'maxTotalHits': 1000
},
'proximityPrecision': 'byWord',
'rankingRules': [
'words',
'typo',
'proximity',
'attribute',
'sort',
'exactness'
],
'searchableAttributes': [
'*'
],
'separatorTokens': [
],
'sortableAttributes': [
],
'stopWords': [
],
'synonyms': {
},
'typoTolerance': {
'disableOnAttributes': [
],
'disableOnWords': [
],
'enabled': True,
'minWordSizeForTypos': {
'oneTypo': 5,
'twoTypos': 9
}
}
}
ではEmbeddingsを有効化する。ドキュメントを見ると、次元数の設定とか、text-embedding-3-smallとかの新しいモデルも使えるようなのだけど、v1.6だと怒られる。ドキュメントは最新のv1.7ベースのようなので、日本語強制版v1.6を使う限りはしょうがないのかもしれない。(自分でイメージをビルドするという手もありそうだけど、)
documentTemplateの書き方はちょっとわからないけど、多分こういう内容でembeddingsが生成されるのだろうと思われるので適当に設定してみた。
client.index('oguricap').update_settings({
"embedders": {
"default": {
"source": "openAi",
"model": "text-embedding-ada-002",
"apiKey": os.environ["OPENAI_API_KEY"],
"documentTemplate": "チャプター: '{{doc.chapter_title}}', 本文: {{doc.chunk}}",
}
}
})
再度設定を確認
client.index('oguricap').get_settings()
{
'displayedAttributes': [
'*'
],
'searchableAttributes': [
'*'
],
'filterableAttributes': [
],
'sortableAttributes': [
],
'rankingRules': [
'words',
'typo',
'proximity',
'attribute',
'sort',
'exactness'
],
'stopWords': [
],
'nonSeparatorTokens': [
],
'separatorTokens': [
],
'dictionary': [
],
'synonyms': {
},
'distinctAttribute': None,
'proximityPrecision': 'byWord',
'typoTolerance': {
'enabled': True,
'minWordSizeForTypos': {
'oneTypo': 5,
'twoTypos': 9
},
'disableOnWords': [
],
'disableOnAttributes': [
]
},
'faceting': {
'maxValuesPerFacet': 100,
'sortFacetValuesBy': {
'*': 'alpha'
}
},
'pagination': {
'maxTotalHits': 1000
},
'embedders': {
'default': OpenAiEmbedder(
source='openAi',
model='text-embedding-ada-002',
dimensions=None,
api_key='sk-XXXXXXXXXXXXXXXXX',
document_template="チャプター: '{{doc.chapter_title}}', 本文: {{doc.chunk}}"
)
}
}
設定したとおりになっている様子。では、ドキュメントを登録する。
client.index('oguricap').add_documents(docs_to_meili)
TaskInfo(task_uid=4, index_uid='oguricap', status='enqueued', type='documentAdditionOrUpdate', enqueued_at=datetime.datetime(2024, 3, 12, 6, 33, 45, 168305))
client.get_task(4).status
'succeeded'
GUIで確認してみると登録はされている模様だけど、以前、クライアント側でベクトル生成して登録したときには表示されていた_vectorsが存在していない。
うーん、正しくできているのだろうか。。。get_object(s)とかやってみたけど、ベクトル情報は取れなかった。
とりあえず検索してみる。semanticRatioが0に近いほどキーワード検索で、1に近いほどセマンティック検索という形。embedderでクエリをベクトル化する設定を指定する。
response = client.index('oguricap').search(
"武豊が騎乗したのはどのレース?", {
"limit": 5,
"showRankingScore": True,
"hybrid": {
"semanticRatio": 0,
"embedder": "default"
}
}
)
for r in response["hits"]:
for key in r:
print(key, ": ", r[key])
print()
id : 36
chapter_title : オグリキャップ > 競走馬時代 > 近藤俊典への売却 > 6歳(1990年) > 競走内容(2)
chunk : 当初初戦には大阪杯が予定されていたが、故障は見当たらないものの調子は思わしくなく、安田記念に変更された。この競走では武豊が初めて騎乗した。レースでは2、3番手を追走して残り400mの地点で先頭に立ち、コースレコードの1分32秒4を記録して優勝した。なお出走後、オグリキャップの通算獲得賞金額が当時の日本歴代1位となった(レースに関する詳細については第40回安田記念を参照)。 続く宝塚記念では武がスーパークリークへの騎乗を選択したため、岡潤一郎が騎乗することとなった。終始3、4番手に位置したが直線で伸びを欠き、オサイチジョージをかわすことができず2着に敗れた(レースに関する詳細については第31回宝塚記念を参照)。
_rankingScore : 0.9818873410103962
id : 38
chapter_title : オグリキャップ > 競走馬時代 > 近藤俊典への売却 > 6歳(1990年) > 競走内容(4)
chunk : レースでは最後方から追走し、第3コーナーから前方への進出を開始したが直線で伸びを欠き、11着に敗れた(レースに関する詳細については第10回ジャパンカップを参照)。 ジャパンカップの結果を受けてオグリキャップはこのまま引退すべきとの声が多く上がり、オグリキャップは「輝きを失ったヒーロー」「落ちた偶像」などと評されるようになった。さらに馬主の近藤に宛てた脅迫状が日本中央競馬会に届く事態にまで発展したが、陣営は引退レースとして有馬記念への出走を決定し、また鞍上は安田記念以来となる武豊が騎乗して出走することが決まった。有馬記念のファン投票では14万6738票を集めて1位に支持された。
_rankingScore : 0.9818868229052105
id : 75
chapter_title : オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(4)
chunk : 河内の次に主戦騎手を務めた南井克巳は、オグリキャップを「力そのもの、パワーそのものを感じさせる馬」「どんなレースでもできる馬」「レースを知っている」と評し、1989年の毎日王冠のレース後には「この馬の勝負根性には本当に頭が下がる」と語った。同じく主戦騎手を務めたタマモクロスとの比較については「馬の強さではタマモクロスのほうが上だったんじゃないか」と語った一方で、「オグリキャップのほうが素直で非常に乗りやすい」と述べている。オグリキャップ引退後の1994年に自身が主戦騎手となってクラシック三冠を制したナリタブライアンにデビュー戦の直前期の調教で初めて騎乗した際には、その走りについて加速の仕方がオグリキャップに似ていると感じ、この時点で「これは走る」という感触を得ていたと述べている。 武豊によるとオグリキャップは右手前で走ることが好きで、左回りよりも右回りのコースのほうがスムーズに走れた。
_rankingScore : 0.9813375018820564
id : 42
chapter_title : オグリキャップ > 競走馬時代 > 近藤俊典への売却 > 6歳(1990年) > 1990年後半の不振と復活 > 体調(2)
chunk : 池江によると、オグリキャップはテレビ取材のカメラに一日中追いかけられた事で「それまではカイバを食べている鼻先にカメラを近づけられても全然気にしていなかったのに、極端にカメラを怖がるようになってしまった」と述べている。 体調に関しては、第35回有馬記念に優勝した時ですらよくなかったという証言が複数ある。オグリキャップと調教を行ったオースミシャダイの厩務員出口光雄や同じレースに出走したヤエノムテキの担当厩務員(持ち乗り調教助手)の荻野功がレース前の時点で体調の悪化を指摘していたほか、騎乗した武豊もパドックで跨った時の事について「あまり元気がないなという雰囲気でした」と、レース後には「ピークは過ぎていたでしょうね。春と違うのは確かでした」とそれぞれ回顧している。
_rankingScore : 0.9810752111317882
id : 101
chapter_title : オグリキャップ > 騎手(4)
chunk : 南井克巳 1988年の京都4歳特別に、河内洋の代役として騎乗した。翌1989年には前述のように岡部が近藤からの騎乗依頼を断った後で瀬戸口から騎乗依頼を受け、主戦騎手を務めた。1990年はバンブービギンに騎乗することを決断し、自ら降板を申し出た。1989年の第34回有馬記念における騎乗について野平祐二と岡部は南井の騎乗ミスを指摘した。南井は有馬記念の騎乗について、オグリキャップの調子が悪くいつもの末脚を発揮することが難しいため、好位置の楽な競馬で気力を取り戻すことを期待したと説明している。 武豊 1990年にアメリカ遠征が決定した際、武豊が鞍上を務めることが決まったことで陣営は第40回安田記念にも騎乗を依頼し、同レースで騎乗することとなった。
_rankingScore : 0.9807735443874058
次にsemanticRatioを1にしてみる。
response = client.index('oguricap').search(
"武豊が騎乗したのはどのレース?", {
"limit": 5,
"showRankingScore": True,
"hybrid": {
"semanticRatio": 1,
"embedder": "default"
}
}
)
for r in response["hits"]:
for key in r:
print(key, ": ", r[key])
print()
こちらは結果に_semanticScoreが追加されている。
id : 36
chapter_title : オグリキャップ > 競走馬時代 > 近藤俊典への売却 > 6歳(1990年) > 競走内容(2)
chunk : 当初初戦には大阪杯が予定されていたが、故障は見当たらないものの調子は思わしくなく、安田記念に変更された。この競走では武豊が初めて騎乗した。レースでは2、3番手を追走して残り400mの地点で先頭に立ち、コースレコードの1分32秒4を記録して優勝した。なお出走後、オグリキャップの通算獲得賞金額が当時の日本歴代1位となった(レースに関する詳細については第40回安田記念を参照)。 続く宝塚記念では武がスーパークリークへの騎乗を選択したため、岡潤一郎が騎乗することとなった。終始3、4番手に位置したが直線で伸びを欠き、オサイチジョージをかわすことができず2着に敗れた(レースに関する詳細については第31回宝塚記念を参照)。
_rankingScore : 0.6354050636291504
_semanticScore : 0.63540506
id : 48
chapter_title : オグリキャップ > 競走馬時代 > 近藤俊典への売却 > 6歳(1990年) > 1990年後半の不振と復活 > 第35回有馬記念のレース内容(2)
chunk : またライターの関口隆哉も、「レース展開、出走馬たちのレベル、当日の状態など、すべてのファクターがオグリキャップ有利に働いた」とし、瀬戸慎一郎は「2着、3着に入った馬が、幾度となくジリ脚に泣いたメジロライアンとホワイトストーンであっただけに、相手関係にもかなり恵まれたといわなければならない」と述べ、また武豊が「調子は7、8分でも力が違います」と骨っぽい相手がいなかったことを匂わせるような発言をしていたといい、ペースが落ち着いて楽に追走できたことと「直線で素早く抜け出せる爆発的な瞬発力を持った馬」が出走していなかったことが大きかったと述べている。 武豊は1993年に同レースを振り返った際には「別に謙遜してるわけじゃなく、強い馬が走りやすいように走らせただけなんですよ。だから、勝っても驚きはしなかった。
_rankingScore : 0.6256594657897949
_semanticScore : 0.62565947
id : 28
chapter_title : オグリキャップ > 競走馬時代 > 近藤俊典への売却 > 5歳(1989年) > 競走内容(3)
chunk : このレースは「オグリキャップのベストバトル」、また「1989年のベストマッチ」ともいわれる。しかし、南井は前走のオールカマーの時のようなデキではなく、理由としては馬体重が前走から8kg増だったため体が重かったのではないかと分析している(レースに関する詳細については第40回毎日王冠を参照)。 天皇賞(秋)では6番手からレースを進めたが、直線で前方へ進出するための進路を確保することができなかったために加速するのが遅れ、先に抜け出したスーパークリークを交わすことができず2着に敗れた。南井は、自身がオグリキャップに騎乗した中で「勝てたのに負けたレース」であるこのレースが最も印象に残っていると述べ、またヤエノムテキが壁となって体勢を立て直してから外に持ち出して追い込まざるを得なくなったことが痛かったとしている(レースに関する詳細については第100回天皇賞を参照)。
_rankingScore : 0.6193509101867676
_semanticScore : 0.6193509
id : 101
chapter_title : オグリキャップ > 騎手(4)
chunk : 南井克巳 1988年の京都4歳特別に、河内洋の代役として騎乗した。翌1989年には前述のように岡部が近藤からの騎乗依頼を断った後で瀬戸口から騎乗依頼を受け、主戦騎手を務めた。1990年はバンブービギンに騎乗することを決断し、自ら降板を申し出た。1989年の第34回有馬記念における騎乗について野平祐二と岡部は南井の騎乗ミスを指摘した。南井は有馬記念の騎乗について、オグリキャップの調子が悪くいつもの末脚を発揮することが難しいため、好位置の楽な競馬で気力を取り戻すことを期待したと説明している。 武豊 1990年にアメリカ遠征が決定した際、武豊が鞍上を務めることが決まったことで陣営は第40回安田記念にも騎乗を依頼し、同レースで騎乗することとなった。
_rankingScore : 0.6183567047119141
_semanticScore : 0.6183567
id : 104
chapter_title : オグリキャップ > 騎手(7)
chunk : 増さんに乗ってもらうのも分かっていたけど、豊くんで負ければ納得いくんじゃないかと思って…」と語り、もし鞍上が武で決まらなかった場合は内心オグリキャップを有馬記念に出走させずに引退させようと思っていたことを明かしている。 岡潤一郎 1990年の宝塚記念で、前走の安田記念に騎乗した武がスーパークリークに騎乗し、南井がヨーロッパへ研修旅行に出たことを受けて近藤が騎乗依頼を出した。宝塚記念において必要以上に手綱を緩め、その結果第3コーナーから第4コーナーにかけて手前を右手前に変えるべきであったのに左手前のまま走らせたこと、第4コーナーで外に膨れて走行したオグリキャップに鞭を入れた際、左から入れるべきであったのに右から入れたことを問題視する向きもあった。なお、近藤と岡はともに北海道浦河高等学校に在籍した経験を持つ。岡は3年後の1993年に落馬事故で死去している。
_rankingScore : 0.6163992881774902
_semanticScore : 0.6163993
ではsemanticRatioを0〜1の間で設定してみる。0.611という中途半端な数字にしたのには意味がある。
response = client.index('oguricap').search(
"武豊が騎乗したのはどのレース?", {
"limit": 5,
"showRankingScore": True,
"hybrid": {
"semanticRatio": 0.611,
"embedder": "default"
}
}
)
for r in response["hits"]:
for key in r:
print(key, ": ", r[key])
print()
面白いのは_semanticScoreがない検索結果も含まれているということ。
id : 36
chapter_title : オグリキャップ > 競走馬時代 > 近藤俊典への売却 > 6歳(1990年) > 競走内容(2)
chunk : 当初初戦には大阪杯が予定されていたが、故障は見当たらないものの調子は思わしくなく、安田記念に変更された。この競走では武豊が初めて騎乗した。レースでは2、3番手を追走して残り400mの地点で先頭に立ち、コースレコードの1分32秒4を記録して優勝した。なお出走後、オグリキャップの通算獲得賞金額が当時の日本歴代1位となった(レースに関する詳細については第40回安田記念を参照)。 続く宝塚記念では武がスーパークリークへの騎乗を選択したため、岡潤一郎が騎乗することとなった。終始3、4番手に位置したが直線で伸びを欠き、オサイチジョージをかわすことができず2着に敗れた(レースに関する詳細については第31回宝塚記念を参照)。
_rankingScore : 0.6354050636291504
_semanticScore : 0.63540506
id : 48
chapter_title : オグリキャップ > 競走馬時代 > 近藤俊典への売却 > 6歳(1990年) > 1990年後半の不振と復活 > 第35回有馬記念のレース内容(2)
chunk : またライターの関口隆哉も、「レース展開、出走馬たちのレベル、当日の状態など、すべてのファクターがオグリキャップ有利に働いた」とし、瀬戸慎一郎は「2着、3着に入った馬が、幾度となくジリ脚に泣いたメジロライアンとホワイトストーンであっただけに、相手関係にもかなり恵まれたといわなければならない」と述べ、また武豊が「調子は7、8分でも力が違います」と骨っぽい相手がいなかったことを匂わせるような発言をしていたといい、ペースが落ち着いて楽に追走できたことと「直線で素早く抜け出せる爆発的な瞬発力を持った馬」が出走していなかったことが大きかったと述べている。 武豊は1993年に同レースを振り返った際には「別に謙遜してるわけじゃなく、強い馬が走りやすいように走らせただけなんですよ。だから、勝っても驚きはしなかった。
_rankingScore : 0.6256594657897949
_semanticScore : 0.62565947
id : 38
chapter_title : オグリキャップ > 競走馬時代 > 近藤俊典への売却 > 6歳(1990年) > 競走内容(4)
chunk : レースでは最後方から追走し、第3コーナーから前方への進出を開始したが直線で伸びを欠き、11着に敗れた(レースに関する詳細については第10回ジャパンカップを参照)。 ジャパンカップの結果を受けてオグリキャップはこのまま引退すべきとの声が多く上がり、オグリキャップは「輝きを失ったヒーロー」「落ちた偶像」などと評されるようになった。さらに馬主の近藤に宛てた脅迫状が日本中央競馬会に届く事態にまで発展したが、陣営は引退レースとして有馬記念への出走を決定し、また鞍上は安田記念以来となる武豊が騎乗して出走することが決まった。有馬記念のファン投票では14万6738票を集めて1位に支持された。
_rankingScore : 0.9818868229052105
id : 75
chapter_title : オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(4)
chunk : 河内の次に主戦騎手を務めた南井克巳は、オグリキャップを「力そのもの、パワーそのものを感じさせる馬」「どんなレースでもできる馬」「レースを知っている」と評し、1989年の毎日王冠のレース後には「この馬の勝負根性には本当に頭が下がる」と語った。同じく主戦騎手を務めたタマモクロスとの比較については「馬の強さではタマモクロスのほうが上だったんじゃないか」と語った一方で、「オグリキャップのほうが素直で非常に乗りやすい」と述べている。オグリキャップ引退後の1994年に自身が主戦騎手となってクラシック三冠を制したナリタブライアンにデビュー戦の直前期の調教で初めて騎乗した際には、その走りについて加速の仕方がオグリキャップに似ていると感じ、この時点で「これは走る」という感触を得ていたと述べている。 武豊によるとオグリキャップは右手前で走ることが好きで、左回りよりも右回りのコースのほうがスムーズに走れた。
_rankingScore : 0.9813375018820564
id : 42
chapter_title : オグリキャップ > 競走馬時代 > 近藤俊典への売却 > 6歳(1990年) > 1990年後半の不振と復活 > 体調(2)
chunk : 池江によると、オグリキャップはテレビ取材のカメラに一日中追いかけられた事で「それまではカイバを食べている鼻先にカメラを近づけられても全然気にしていなかったのに、極端にカメラを怖がるようになってしまった」と述べている。 体調に関しては、第35回有馬記念に優勝した時ですらよくなかったという証言が複数ある。オグリキャップと調教を行ったオースミシャダイの厩務員出口光雄や同じレースに出走したヤエノムテキの担当厩務員(持ち乗り調教助手)の荻野功がレース前の時点で体調の悪化を指摘していたほか、騎乗した武豊もパドックで跨った時の事について「あまり元気がないなという雰囲気でした」と、レース後には「ピークは過ぎていたでしょうね。春と違うのは確かでした」とそれぞれ回顧している。
_rankingScore : 0.9810752111317882
各設定ごとに検索結果上位のドキュメントのIDを比較してみる。
| ランキング | キーワード検索(0) | ベクトル検索(1) | ハイブリッド(0.611) |
|---|---|---|---|
| 1位 | 36 | 36 | 36 |
| 2位 | 38 | 48 | 48 |
| 3位 | 75 | 28 | 38 |
| 4位 | 42 | 101 | 75 |
| 5位 | 101 | 104 | 42 |
それぞれの場合で検索順位が変わっているのがわかる。実際のembeddingsのデータを確認する方法を調べてみたのだけど、experimentalということもあってか見当たらず。。。。まあ現状の動作結果からはおそらくベクトル検索は動作しているし、ハイブリッドもそうだろうと思う。ちなみに検索結果をまるっと見てみると、少なくともクエリがベクトル化されているのは確認できる。
{
'hits': [
{
'id': 36,
'chapter_title': 'オグリキャップ > 競走馬時代 (snip)',
'chunk': '当初初戦には大阪杯が予定されていたが、(snip)',
'_rankingScore': 0.6256594657897949,
'_semanticScore': 0.62565947
},
(snip)
],
'query': '武豊が騎乗したのはどのレース?',
'vector': [0.0039491784, -0.014617467, 0.011520326, (snip), -0.011449053, -0.011364821, -1.6593904e-06],
'processingTimeMs': 11,
'limit': 5,
'offset': 0,
'estimatedTotalHits': 90
}
ちなみに、semanticRatioを0.611みたいな細かい数字にしたのは、色々数値を変えて試してみた感じ、今回の場合は、0.6だとキーワード検索と同じ、0.7だとハイブリッド検索と同じ、ってところで、違いがわかるようにいろいろいじってみた結果、0.611がちょうど境目っぽい感じだったという次第。まあ5件しかひろってないってのもあるし、クエリやデータの中身とかによっても変わってくるんだろうとは思う。
とりあえず一応動いている模様。現時点ではあくまでexperimentalではあるけども、
- クライアント側でベクトル化してから渡すんじゃなくて、サーバ側でベクトル化してくれるのは、クライアント側の処理が少なくて済むので楽。
- 以前確認した際には自分でベクトル化したデータを登録して、キーワード検索+ベクトル検索をそれぞれ実施して、スコアのりランキングを自前でやっていた。この辺が簡単にできるのはとても楽。
というところで、全然選択肢としてはあるよなと。
とはいえ、以下の記事にあるように、ハイブリッドで精度があがるかというとそんな単純なものではなく、全文検索としてのチューニングは必要になる様子
最近のハイブリッド対応の流れを見ていると、
- ベクトルデータベースがキーワード検索にも対応
- 全文検索(キーワード検索)エンジンがベクトル検索に対応
っていう感じに思えるのだけども、全文検索のチューニングが前提になると、前者よりも後者のほうがいい気がする。実際、ちょっと前にWeaviateでキーワード検索を試してみたのだけども、チューニング等の設定はそんなにないし、精度というところまでは確認ができていないし。
反面、以前自分が翻訳した以下の記事によると、あくまでも記事の著者の見解ではあるけれども、ベクトル専用データベースのほうがスケーラビリティやパフォーマンスの観点で既存のデータストアよりも将来性があると書かれている。
セマンティック検索を必要とする分野では、ベクトル専用に特化したデータベースが徐々に既存のデータベースを凌駕していくだろうと思う。HNSWやANNアルゴリズムのようなインデクシング手法は文献で十分に文書化されており、ほとんどのデータベースベンダーは独自の実装を展開することができるが、特化型ベクトルデータベースは目の前のタスクに最適化されているという利点があり(GoやRustのようなモダンなプログラミング言語で書かれていることは言うまでもない)、スケーラビリティとパフォーマンスの理由から、長期的にはこの分野で勝利する可能性が高い。
結局のところは、求める精度(ユーザの期待値とも言える)と投資できるリソース(全文検索エンジンの構築・チューニング・運用に関するスキルセットとかあと純粋な工数とか)とのバランスで考える必要は常にある、という普遍的な結論にはなってしまうな。
あとは精度の定量測定をやっぱりやってみないと効果がただしく判断できないかなというところ。
ところですこし話は変わるけども、
Meilisearchの日本語強制版を使うのは、しょうがないことなのかな?というのは、今回試すにあたって、ドキュメント色々見てたけども、どうもv1.6とv1.7で多少の違いがあるようで、v1.7のドキュメントに書いてある内容だとちょいちょい怒られたりして、結構辛かった。"text-embeddigs-3-small"とかも使えないし。
自分でビルドしたほうがいいのかなー、できるんだろうか。。。
ビルドしてみた。
$ git clone https://github.com/meilisearch/meilisearch -b v1.7.0 meilisearch-v1.7.0-ja
$ cd meilisearch-v1.7.0-ja
$ vi Dockerfile
こんな感じで修正。修正内容はprototype-japanese-9のタグで確認した。
diff --git a/Dockerfile b/Dockerfile
index 5b227e6fc..2d6e1a44f 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -17,7 +17,7 @@ RUN set -eux; \
if [ "$apkArch" = "aarch64" ]; then \
export JEMALLOC_SYS_WITH_LG_PAGE=16; \
fi && \
- cargo build --release -p meilisearch -p meilitool
+ cargo build --release -p meilisearch -p meilitool --no-default-features --features "analytics mini-dashboard japanese"
# Run
FROM alpine:3.16
ビルド
$ docker build -t kun432/meilisearch-ja:v1.7.0 .
起動
$ docker run -it --rm \
-p 7700:7700 \
-e MEILI_ENV='development' \
-v $(pwd)/meili_data:/meili_data \
kun432/meilisearch-ja:v1.7.0
あとは上と同じようにやればOK。新しいモデルもv1.7ならOKだった。
client.index('oguricap').update_settings({
"embedders": {
"default": {
"source": "openAi",
"model": "text-embedding-3-small",
"dimensions": 512,
"apiKey": os.environ["OPENAI_API_KEY"],
"documentTemplate": "チャプター: '{{doc.chapter_title}}', 本文: {{doc.chunk}}",
},
}
})
上ですこし試しているけどもv1.7.0のリリース記事。
変更点は以下あたりかな。
- 改良されたハイブリッド&ベクトル検索
- OpenAIの新しいEmbeddingモデルに対応
text-embedding-3-smalltext-embedding-3-large- 上記のモデルでは次元数の設定も可能
-
text-embedding-ada-002は不可
-
- Meilisearchクラウドでもベータ提供
- OpenAIの新しいEmbeddingモデルに対応
- HuggingFaceのEmbeddingモデル向けのGPUサポート
- セルフホストのみ
-
showRankingScoreDetailsがstableに。- experimentalだった
showRankingScoreDetailsがstableになった。
- experimentalだった
ということで、HuggingFaceのEmbeddingモデルを動かしてみようと思う。とりあえず手元の環境。
- Ubuntu 22.04
- GPU: RTX4090
- CUDA: 12.3
- nvidia-container-toolkit派設定済
でここからめちゃめちゃ苦労した。rust触ったことなくて良くわかってない&あまり記録していないので、ざっくりだけどこんな感じ。
- 基本的には公式手順に従って進める。
- rustの環境が必要ってことで、まずはざっくりrustの使い方を調べてみた⇒ここ
- 公式の手順だとmainブランチの最新をひっぱってきていたが、自分は正式なリリース版に合わせてやりたくて、v1.7.0のタグからクローンすることにした。
- まず、素のDockerコンテナ上でmeilisearchのソースをクローン、rustインストールの上、cuda有効にして
cargo buildしたが・・・- meilisearchの公式イメージはalpineを使っているが、alpineではGPUが使えないらしい?nvida/cudaのubuntuイメージを使うことにした。
- イメージは、インストールされているcudaのバージョンに合わせて選択する。
- alpineのapkコマンドをubuntuのaptコマンドに置き換える必要があった。
- で、rustのパッケージ
candle-kernelsのビルドでコケる。 - meilisearchでは、GPU対応でrustのMLフレームワークである
huggingface/candleが使われている様子。で、この中に含まれるパッケージの一つであるcandle-kernelsv3.1のインストールでコケている模様。 - エラーメッセージを見る限り、
candle-kernelsが見つからないとか言われるが、サンプルでプロジェクト作って同じパッケージをcargo add&cargo buildするも何問題ない。 - パッケージのバージョン等は
Cargo.lockに記載されているものが使用されているっぽい。package-lock.jsonと似たようなもんだろ?ということで、まるっと削除してビルドするとバージョンの依存関係が解決できなくてコケる。 - rustのパッケージ管理を色々調べるもよくわからず。
- 問題となっているのは
candle-kernelsだけっぽいので、Cargo.lockからcandle-kernelsの部分だけ消して、再度トライするとcandle-kernelsのv3.3がインストールされたがビルドは通るようになった。
- meilisearchの公式イメージはalpineを使っているが、alpineではGPUが使えないらしい?nvida/cudaのubuntuイメージを使うことにした。
- 一応バイナリができるところまでは確認できたので、Dockerfileを修正しようとしたが、、、
- docker runでGPU有効にするのは簡単だけど、docker buildでGPU有効にするのに苦戦した
- 結論から言うと以下をDockerfileに追記したらできるようになった
ENV NVIDIA_VISIBLE_DEVICES allENV NVIDIA_DRIVER_CAPABILITIES compute,utilityENV CUDA_COMPUTE_CAP 89- 特に
CUDA_COMPUTE_CAPが重要だった。- Compute Capabilityは、使用しているGPUのサポートする機能を識別するもの
-
candle-kernelの中でこの環境変数を参照して、未定義の場合はnvidia-smiを探しに行ってこれを取得しようとする- がここで見つからないのでコケていた
- コマンドで確認するには
nvidia-smi --query-gpu=compute_cap --format=csvを実行する- 例えばRTX4090の場合は
8.9が返ってくる。Dockerfileで指定する際は小数点を削除して89とすれば良いらしい
- 例えばRTX4090の場合は
-
cargo buildは以下のように設定-
cargo build --release -p meilisearch -p meilitool -p milli --no-default-features --features "cuda analytics mini-dashboard japanese- 公式の手順は
-pなしだが、これだと全部のパッケージをビルドするようでめちゃめちゃ時間がかかる。 -
--feature cudaはmilliというパッケージで定義されているっぽいので-p milliだけを追加した。 - その他は日本語強制版で使用されているものに合わせた
- ただ最終的なイメージは2.3GBぐらいで、日本語のみのパッケージに比べてもだいぶデカい・・・
- 公式の手順は
-
ということで思いの外手間暇かかった。rust良くわかってないってのもあるし、dockerのGPU対応は過去のnvidiaの対応の変遷がよくわからないこともあって、なかなか情報が見つけにくかったのもあるかなというところ。
とりあえず以下のブランチをクローンしてビルドすればできるはず。cudaのバージョンや使用しているGPUに合わせてDockerfileの修正は必要になると思う。
ビルドと実行例
$ docker build --no-cache -t kun432/meilisearch:v1.7.0-ja-cuda .
$ docker run -it --rm \
--gpus all \
-p 7700:7700 \
-e MEILI_ENV='development' \
-v $(pwd)/meili_data:/meili_data \
kun432/meilisearch:v1.7.0-ja-cuda
で、実際に使うときはこんな感じ。前回の手順と共通してる部分は割愛。
client.index('oguricap').update_settings({
"embedders": {
"default": {
"source": "huggingFace",
"model": "BAAI/bge-m3",
"documentTemplate": "チャプター: '{{doc.chapter_title}}', 本文: {{doc.chunk}}",
}
}
})
huggingFaceの場合、現時点ではどうやらdimensionsを指定できない模様。その他細かいパラメータの指定なんかもできないようなので、限定的なサポートになると思ったほうが良さそう。
documentTemplateはモデルに合わせて適宜設定することになると思う。今回はBAAI/bge-m3を使ったけど、例えばintfloat/multilingual-e5-largeの場合はプレフィクスを付ける必要があると思うので、documentTemplateにはpassageプレフィクス、あと検索時のクエリにqueryプリフィクスをつけるという感じになるのではないかな。
上記を実行すると以下のようにモデルがダウンロードされて、ドキュメントのベクトル化が行われる。
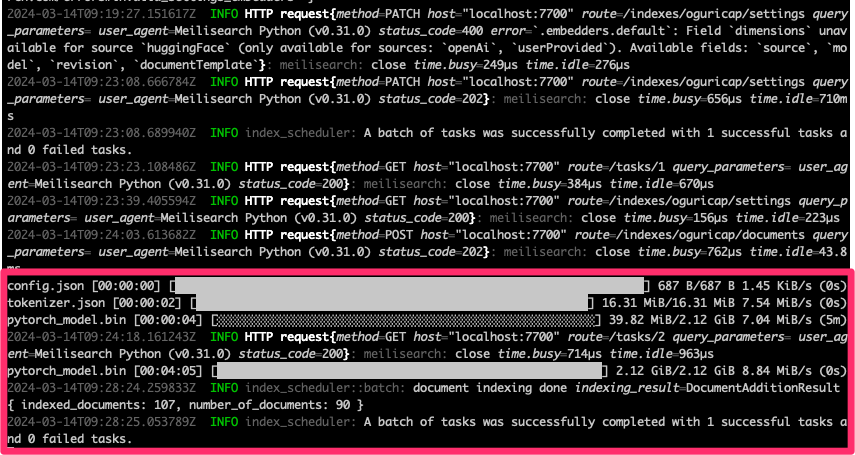
ハイブリッド検索の結果。
response = client.index('oguricap').search(
"オグリキャップの強さの特徴は?", {
"limit": 10,
"showRankingScore": True,
"hybrid": {
"semanticRatio": 0.531,
"embedder": "default"
}
}
)
for r in response["hits"]:
for key in r:
print(key, ": ", r[key])
print()
id : 69
chapter_title : オグリキャップ > 特徴・評価 > 身体面に関する特徴・評価(1)
chunk : オグリキャップはパドックで人を引く力が強く、中央競馬時代は全レースで厩務員の池江と調教助手の辻本が2人で手綱を持って周回していた。さらに力が強いことに加えて柔軟性も備えており、「普通の馬なら絶対に届かない場所」で尻尾の毛をブラッシングしていた厩務員の池江に噛みついたことがある。南井克巳と武豊は共に、オグリキャップの特徴として柔軟性を挙げている。 笠松在籍時の厩務員の塚本勝男は3歳時のオグリキャップを初めて見たとき、腿の内側に力があり下半身が馬車馬のようにガッシリしているという印象を受けたと述べている。最も河内洋によると、中央移籍当初のオグリキャップは前脚はしっかりしていたというものの、後脚がしっかりとしていなかった。
_rankingScore : 0.8784332275390625
_semanticScore : 0.8784332
id : 75
chapter_title : オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(4)
chunk : 河内の次に主戦騎手を務めた南井克巳は、オグリキャップを「力そのもの、パワーそのものを感じさせる馬」「どんなレースでもできる馬」「レースを知っている」と評し、1989年の毎日王冠のレース後には「この馬の勝負根性には本当に頭が下がる」と語った。同じく主戦騎手を務めたタマモクロスとの比較については「馬の強さではタマモクロスのほうが上だったんじゃないか」と語った一方で、「オグリキャップのほうが素直で非常に乗りやすい」と述べている。オグリキャップ引退後の1994年に自身が主戦騎手となってクラシック三冠を制したナリタブライアンにデビュー戦の直前期の調教で初めて騎乗した際には、その走りについて加速の仕方がオグリキャップに似ていると感じ、この時点で「これは走る」という感触を得ていたと述べている。 武豊によるとオグリキャップは右手前で走ることが好きで、左回りよりも右回りのコースのほうがスムーズに走れた。
_rankingScore : 0.9926297224542838
id : 71
chapter_title : オグリキャップ > 特徴・評価 > 身体面に関する特徴・評価(3)
chunk : オグリキャップは心臓や消化器官をはじめとする内臓も強く、普通の馬であればエンバクが未消化のまま糞として排出されることが多いものの、オグリキャップはエンバクの殻まで隈なく消化されていた。安藤勝己は、オグリキャップのタフさは心臓の強さからくるものだと述べている。獣医師の吉村秀之は、オグリキャップは中央競馬へ移籍してきた当初からスポーツ心臓を持っていたと証言している。
_rankingScore : 0.9926226625510045
id : 74
chapter_title : オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(3)
chunk : あんな走り方をする馬に巡り会ったのは、初めて」と思ったという。瀬戸口勉もオグリキャップの走り方の特徴について、重心と首の位置が低いことを挙げている。 河内洋はオグリキャップのレースぶりについて、スピードタイプとは対照的な「グイッグイッと伸びる力タイプ」と評し、騎乗した当初からオグリキャップは「勝負所になると自ら上がっていくような感じで、もうオグリキャップ自身が競馬を知っていた」と述べている。また「一生懸命さがヒシヒシ伝わってくる馬」、「伸びきったかな、と思って追うと、そこからまた伸びてきよる」、「底力がある」とする一方、走る気を出し過ぎるところもあったとしている。一方でGIクラスを相手にした時のオグリキャップは抜け出すまでにモタつく面があるため多頭数のレースだとかなり不安が残る馬と分析し、「直線の入り口でスーッと行ける脚が欲しい」と要望していた。
_rankingScore : 0.8764008283615112
_semanticScore : 0.8764008
id : 81
chapter_title : オグリキャップ > 特徴・評価 > 総合的な評価(4)
chunk : 武豊は自身が騎乗するまでのオグリキャップに対して「にくいほど強い存在でしたし、あこがれの存在でもありました」と述べ、初めてコンビを組んだ安田記念は「自分でも乗っていて、ビックリするというか、あきれるくらいの強さでした」「当時海外遠征のプランもあったんですが、これなら十分通用するなという気持ちがありました」と回顧し、「どんな条件でも力を発揮するわけですから、競走馬としての総合能力は相当高かったと思います」と総評した。オグリキャップが自身に与えた影響についても「競馬の素晴らしさ、騎手という職業のすばらしさを感じさせてくれた馬です。オグリキャップに乗ることができたのは、自分にとって大きな財産です」と述べている。
_rankingScore : 0.991792731698835
id : 73
chapter_title : オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(2)
chunk : キャップが走ったらレースにならんて」と発言したこともある。笠松時代のオグリキャップに騎乗した青木達彦は、「オグリキャップが走った四脚の足跡は一直線だった。軽いキャンターからスピードに乗るとき、ギアチェンジする瞬間の衝撃がすごかった」と述べている。オグリキャップは肢のキック力が強く、瞬発力の強さは一回の蹴りで前肢を目いっぱいに延ばし、浮くように跳びながら走るため、この走法によって普通の馬よりも20から30センチ前に出ることができた。一方で入厩当初は右前脚に骨膜炎を発症しており「馬場に出ると怖くてよう乗れん」という声もあった。 オグリキャップは首を良く使う走法で、沈むように首を下げ、前後にバランスを取りながら地面と平行に馬体を運んでいく走りから、笠松時代から「地を這う馬」と形容されることがあった。安藤勝己は秋風ジュニアのレース後、「重心が低く、前への推進力がケタ違い。
_rankingScore : 0.9917817496270671
id : 80
chapter_title : オグリキャップ > 特徴・評価 > 総合的な評価(3)
chunk : ただし岡部幸雄はオグリキャップの能力や環境の変化にすぐに馴染める精神力のタフさを高く評価し、アメリカでも必ず通用するとしてアメリカ遠征を強く勧めた。 南井克巳は初めて騎乗した京都4歳特別についてこの時にも強いと感じたが、オールカマーで騎乗した際には「本当に強い馬だなと感じましたね。とにかく力が抜けていました」と回顧し、自身が騎乗したレースの中で最も強さが出ていたレースとしてオールカマーを挙げている。自身がオグリキャップに騎乗したことについては「自分にとっても勉強になったし、瀬戸口先生がああいう馬を作られたことがすごいと思います」、「いろんないい馬に乗せていただきましたが、あれだけの馬に乗せてもらえて本当に良かったですよ」と述べている。
_rankingScore : 0.9901250256575188
id : 72
chapter_title : オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(1)
chunk : オグリキャップは走行時に馬場を掻き込む力が強く、その強さは調教中に馬場の地面にかかとをこすって出血したり、蹄鉄の磨滅が激しく頻繁に打ち替えられたために蹄が穴だらけになったことがあったほどであった。なお、栗東トレーニングセンター競走馬診療所の獣医師松本実は、5歳時に発症した右前脚の繋靭帯炎の原因を、生まれつき外向していた右脚で強く地面を掻き込むことを繰り返したことにあると分析している。 笠松在籍時の調教師鷲見昌勇は、調教のためにオグリキャップに騎乗した経験がある。その時の印象について鷲見は「筋肉が非常に柔らかく、フットワークにも無駄がなかった。車に例えるなら、スピードを上げれば重心が低くなる高級外車みたいな感じだよ」と感想を述べている。乗り味についても「他馬が軽トラックなら、(オグリキャップは)高級乗用車だ」と評し、「オグリキャップは全身がバネ。
_rankingScore : 0.986775493768328
id : 67
chapter_title : オグリキャップ > 特徴・評価 > 知能・精神面に関する特徴・評価(1)
chunk : ダンシングキャップ産駒の多くは気性が荒いことで知られていたが、オグリキャップは現3歳時に調教のために騎乗した河内洋と岡部幸雄が共に古馬のように落ち着いていると評するなど、落ち着いた性格の持ち主であった。オグリキャップの落ち着きは競馬場でも発揮され、パドックで観客の歓声を浴びても動じることがなく、ゲートでは落ち着き過ぎてスタートが遅れることがあるほどであった。岡部幸雄は1988年の有馬記念のレース後に「素晴らしい精神力だね。この馬は耳を立てて走るんだ。レースを楽しんでいるのかもしれない」と語り、1990年の有馬記念でスローペースの中で忍耐強く折り合いを保ち続けて勝利したことについて、「類稀なる精神力が生んだ勝利だ」と評したが、オグリキャップと対戦した競走馬の関係者からもオグリキャップの精神面を評価する声が多く挙がっている。
_rankingScore : 0.8697888255119324
_semanticScore : 0.8697888
id : 77
chapter_title : オグリキャップ > 特徴・評価 > 走行・レースぶりに関する特徴・評価(6)
chunk : 同じく主戦騎手を務めていたサッカーボーイとの比較においては、「1600mならオグリキャップ、2000mならサッカーボーイ」と述べている。岡部幸雄はベストは1600mで2500mがギリギリとし、瀬戸口勉は1988年の有馬記念に出走する前には血統からマイラーとみていたため、「2500mは長いのではないか」と感じ、後にベストの条件は1600mとし、マイル戦においては無敗だったため「マイルが一番強かったんじゃないかな」と述べている。競馬評論家の山野浩一は1989年のジャパンカップを世界レコードタイムで走った事を根拠に「オグリキャップをマイラー・タイプの馬と決めつけることはできない」と述べ、大川慶次郎は一見マイラーだが頭がよく、先天的なセンスに長けていたため長距離もこなせたと分析している。なお、父のダンシングキャップは一般的に「ダートの短距離血統」という評価をされていた。
_rankingScore : 0.8656314611434937
_semanticScore : 0.86563146
rust環境が手元にあるならばDocker化せずに直接やるほうがいい気もする。rust全然わかってないので不備あればご指摘くだされ。