LLMエージェントフレームワーク「crewAI」を試す
AutoGenをいろいろ試していて、かなりすごいなと感じているところだけども。
ちょっと他のエージェントフレームワークってどんなもんかなというのが気になったので、Xで検索してみた。
上記では評価が分かれているけれども、色々見る限りcrewAIもなかなか評判が良さそう。
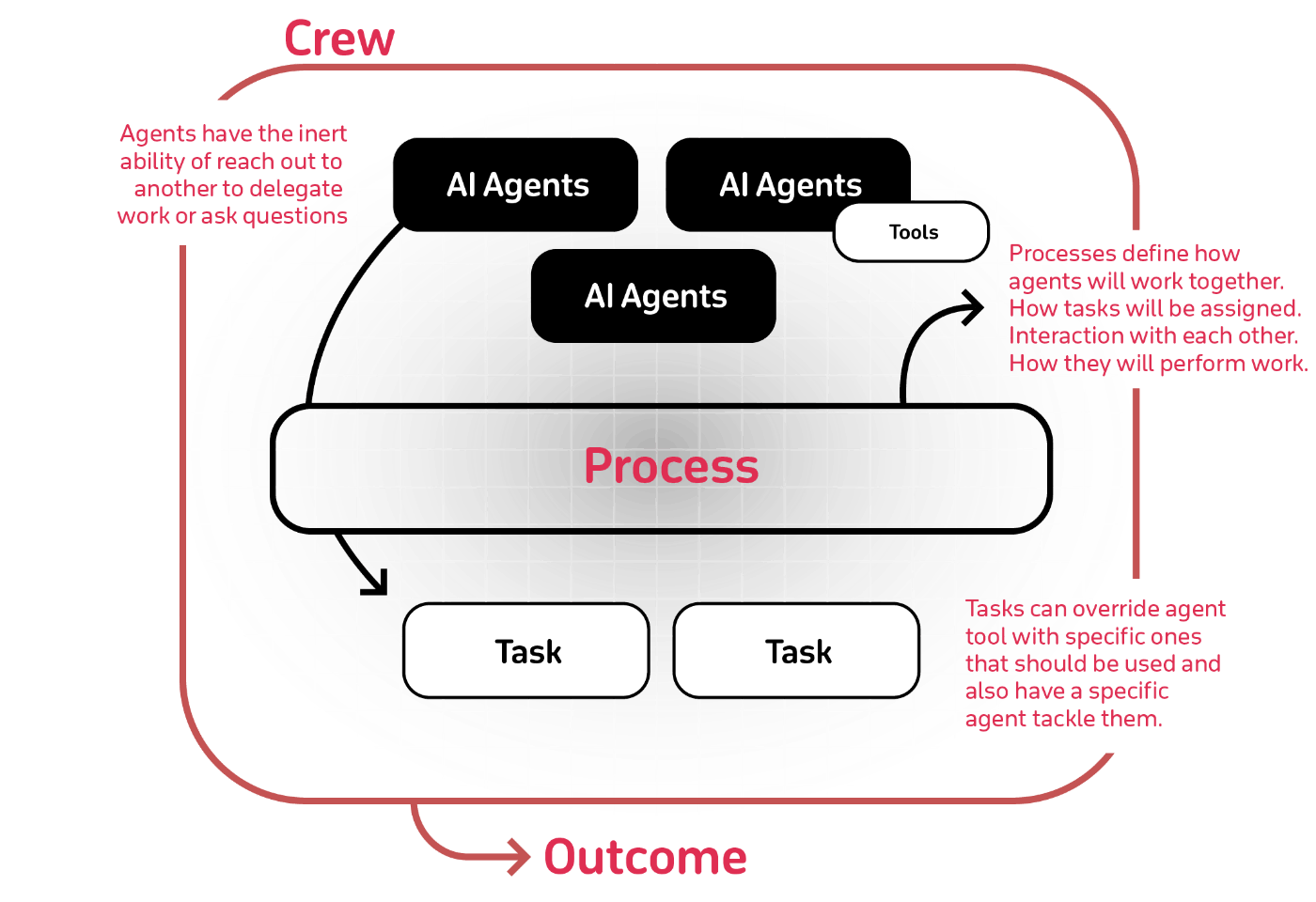
crewAI
🤖ロールプレイング型の自律型AIエージェントを編成するための最先端のフレームワーク。CrewAIは協調的な知性を育むことで、エージェントがシームレスに連携し、複雑なタスクに取り組むことを可能にする。
なぜCrewAIなのか?
AIコラボレーションの力は、提供するものが多すぎる。CrewAIは、AIエージェントが役割を担い、目標を共有し、結束したユニットで活動できるように設計されている。スマートアシスタントプラットフォーム、自動顧客サービスアンサンブル、マルチエージェント研究チームのいずれを構築する場合でも、CrewAIは洗練されたマルチエージェントインタラクションのためのバックボーンを提供する。
主要な機能
- 役割ベースのエージェント設計: 特定の役割、目標、ツールでエージェントをカスタマイズする。
自律的なエージェント間委任: エージェントが自律的にタスクを委任し、エージェント間で問い合わせを行うことで、問題解決の効率を高めることができる。- 柔軟なタスク管理: カスタマイズ可能なツールでタスクを定義し、動的にエージェントに割り当てる。
- プロセス駆動型: 現在のところ、逐次タスク実行と階層的プロセスのみをサポートしているが、合意的プロセスや自律的プロセスなど、より複雑なプロセスにも取り組んでいる。
- 出力をファイルとして保存: 個々のタスクの出力をファイルとして保存し、後で使えるようにする。
- 出力をPydanticまたはJsonとして解析: 個々のタスクの出力をPydanticモデルまたはJsonとして解析する。
- オープンソースモデルと連動: Open AIやオープンソースのモデルを使ってクルーを動かす エージェントとモデル、ローカルで動いているものとの接続を設定する詳細については、Connect crewAI to LLMsのページを参照!
referred from https://github.com/joaomdmoura/crewai/?tab=readme-ov-file#key-features
ということでこちらも少し試してみようと思う。
Colaboratoryで試してみる。
インストール
普通にやるならば以下だけども、
!pip install crewai
以下だとエージェントで使うツールなどもセットでインストールされるということでこちらでインストール
!pip install 'crewai[tools]'
Getting Started
ということでサンプルのコードを動かしてみる。
APIキーをセット。Serper APIもキーがあるのでやってみる。
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
os.environ["SERPER_API_KEY"] = userdata.get('SERPER_API_KEY')
まず、エージェントを作成する。エージェントは自律的なユニットで、以下を行う。
- タスクを実行する
- 意思決定を行う
- 他のエージェントとコミュニケーションする
エージェントは、特定のスキルと特定の仕事を持つ、チームのメンバーだと考えればよい。
ここでは、研究員と記者のエージェントを作成する。
from crewai import Agent
from crewai_tools import SerperDevTool
# 検索ツール
search_tool = SerperDevTool()
# モデルの変更(デフォルトは"gpt-4"だが、トークンサイズでコケたので)
os.environ["OPENAI_MODEL_NAME"]="gpt-4o"
# メモリ、verboseモード、カスタムツール、委任機能を有効にした、上級研究員エージェントを作成する
researcher = Agent(
role='上級研究員',
goal='{topic}における画期的な技術を発見してください。',
verbose=True,
memory=True,
backstory=(
"好奇心に突き動かされイノベーションの最前線に立つあなたは、"
"世界を変えるかもしれない知識を探求し、共有することを熱望している。"
),
tools=[search_tool],
allow_delegation=True
)
# メモリ、verboseモード、カスタムツールを有効にした、記者エージェントを作成する
writer = Agent(
role='記者',
goal='{topic}における説得力のある技術ストーリーを語ってください。',
verbose=True,
memory=True,
backstory=(
"複雑なトピックを単純化する才能に長けたあなたは、"
"興味深い物語を作り上げて読者を引きつけ教育し、"
"新しい発見をわかりやすく紹介する"
),
tools=[search_tool],
allow_delegation=False
)
エージェントの主なパラメータは以下。他にもあるがここでは記載されているものだけ。
-
role: クルー内でのエージェントの機能を定義する。エージェントがどのようなタスクに最も適しているかを決定する。 -
goal: エージェントが達成しようとする個々の目的。エージェントの意思決定プロセスの指針となる。 -
backstory: エージェントの役割と目標にコンテキストを提供し、インタラクションとコラボレーションのダイナミクスを豊かにする -
allow_delegation: エージェントは、各タスクが最適なエージェントによって処理されることを保証するために、互いにタスクや質問を委任することができる。デフォルトはTrue。 -
memory: エージェントに記憶をもたせる。 -
verbose: Trueに設定すると、内部ロガーが詳細な実行ログを提供するように設定される。デフォルトはFalse。 -
tool: エージェントがタスクを実行するために使用できる能力または関数のセット。デフォルトはなし。
role、goal、backstoryっていう感じでエージェントに与える指針というか個性に関する要素をいくつか与えてるのがちょっと興味深い。
次にタスクを定義する。タスクはエージェントに達成させたい特定の課題を指す。これをエージェントに割り当てる。
from crewai import Task
# 調査タスクを上級研究員エージェントに割り当てる。
research_task = Task(
description=(
"{topic}の次の大きなトレンドを特定してください。"
"長所と短所、そして全体的なストーリーを特定することに集中してください。"
"あなたが書く最終報告書では、重要なポイント、市場機会、潜在的リスクを"
"明確に表現する必要がある。"
),
expected_output='最新のAIトレンドに関する3パラグラフに及ぶ包括的なレポート。',
tools=[search_tool],
agent=researcher,
)
# 記事作成タスクを記者エージェントに割り当てる
write_task = Task(
description=(
"{topic}について洞察に満ちた記事を書いてください。"
"最新のトレンドと、それが業界にどのような影響を与えているかに焦点を当ててください。"
"あなたが書く記事は、わかりやすく、魅力的で、ポジティブな記事である必要がある。"
),
expected_output='Markdownでフォーマットされた、{topic}の進歩に関する4パラグラフの記事。',
tools=[search_tool],
agent=writer,
async_execution=False,
output_file='new-blog-post.md' # 出力カスタマイズの例
)
タスクの主なパラメータは以下。他にもあるがここでは記載されているものだけ。
-
description: タスクの内容についての明確・簡潔な説明。 -
expected_output: タスクの完了についての説明。 -
aget: タスクを担当するエージェント。 -
tool: エージェントがタスクを実行するために使用できる能力または関数のセット。 -
async_execution: Trueならば、タスクは非同期に実行され、完了を待たずに進行できる。 -
output_file: タスクの出力をファイルに保存する。JSONやPydanticなど他の出力方法もあるみたい。
エージェントとタスクの定義が出来たら、「クルー(crew)」を編成する。「クルー」とは、一連のタスクを達成するために協調するエージェントのグループを指す。おそらくワークフロー的な意味合いのものになるのだと思う。
from crewai import Crew, Process
# テクノロジーに特化したクルーを編成する。
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential, # オプション: タスク実行はシーケンシャルがデフォルト
memory=True,
cache=True,
max_rpm=100,
#share_crew=True,
)
パラメータは以下。他にもあるがここでは記載されているものだけ。
-
agents: クルーに参加するエージェント -
tasks: クルーに割り当てられたタスク -
process: クルーが実行されるプロセスフロー(シーケンシャルとか階層とか) -
memory: 実行時のメモリ。メモリには短期・長期・エンティティなどの種類があるらしい。 -
cache: ツール実行結果をキャッシュするか -
max_rpm: 実行時に -
share_crew: クルーの完全な情報と実行を共有するか、いわゆる開発元へのテレメトリー。Trueで共有する。共有したくない場合は指定しなければ良い。
クルーを編成したら、プロセスを開始する。なるほど、プロンプトテンプレート的にタスクを渡せるのな。
# タスク実行プロセスを開始する
result = crew.kickoff(inputs={'topic': 'ヘルスケア分野におけるAI'})
print(result)
今回自分が試した際は実行に1分ほどかかった。記録していないけど、デフォルトのgpt-4だともっと時間がかかったように思える。gpt-4oだとやはり高速なのだろう。
実行中はコンソールに状況が出力される。ツールを使って情報収集したり、解析したり、しているのがわかる。

で、コンソールの最終出力結果。
# ヘルスケア分野におけるAIの進歩
ヘルスケア分野におけるAIの進歩は、医療の実践と患者ケアの多くの側面を劇的に変えつつあります。昨今のトレンドとして、機械学習(ML)や自然言語処理(NLP)の技術が広く採用されており、診断精度の向上や治療の最適化、運営効率の改善が期待されています。例えば、AIは画像解析を通じて放射線科医の診断を補助し、早期に疾患を発見する能力を持っています。これにより、患者の生存率が向上し、医療費の削減にもつながるとされています。
しかし、AIの導入にはいくつかの課題も伴います。倫理的な懸念やデータプライバシーの問題、既存システムとの統合の難しさなどが挙げられます。特に、データセキュリティの侵害やAIアルゴリズムにおけるバイアスは重大なリスクです。これらを解決するためには、強固な規制フレームワークと高品質なデータセットの整備が不可欠です。医療データは非常にセンシティブであり、その取り扱いには慎重さが求められます。
市場機会も非常に豊富であり、特に予測分析、個別化医療、ロボット手術の分野での成長が期待されています。予測分析では、患者データを基に未来の健康リスクを予測し、早期対策を講じることが可能です。個別化医療では、患者一人ひとりに最適な治療法を提供することが目指されており、これにより治療効果の最大化が期待されます。ロボット手術においては、精度の高い手術が可能となり、手術時間の短縮や患者の回復期間の短縮が見込まれています。
これらの技術革新は、ヘルスケア分野におけるAIの未来を非常に明るいものにしています。ウェアラブルデバイスやテレメディスンの進展も見逃せません。これらの技術は、遠隔地に住む患者や移動が困難な患者に対するケアの質を向上させるだけでなく、医療アクセスの向上にも寄与しています。AIとヘルスケアの融合は、医療の未来を再定義し、より効果的で効率的な医療サービスの提供を可能にするでしょう。
指定した通りファイルでも出力されている。

なんか出力フォーマットみたことあるなーと思っていたら、crewAIはLangChainを使っているのだな
今のところの所感
Getting Startedだけしかやってない段階なのであくまでも個人的なファーストインプレッション。
- なんていうか正統派な感じ。
- シンプルなLLMアプリ実装したり、LangChainみたいなフレームワーク使ったり、エージェント試してみたり、ってのを経験した上で、エージェントフレームワーク作ったらこうなった、的な感じに思える。
- エージェントの定義にrole、goal、backstoryと複数の種類があるのが面白い。より個性を植え付けれるような気がする。
- エージェントとタスクを最初に定義してからチーム作るってところは、ボトムアップ的なアプローチに思える。
- チームにタスクを与えて、というよりは、個々のチームメンバーのタスクの成果物を集めたら最終成果物ができた、みたいなイメージ。
抽象化のレイヤーはかなり高いとは思うけども、(マルチ)エージェント系フレームワークをいくつか触ってみてcrewAIを他と比較した場合、自分的になイメージはこんな感じ。
AutoGen >>> crewAI >> Langroid > LangGraph > Burr
最近ちょうどAutoGen触ったところなので、その印象が強くバイアスになってるとは自分でも思うのだけども、それでもAutoGenの抽象度はかなり高く思える。LLMアプリとかを実際に実装したことがなくても、なんかできそう、と思えるぐらいに、高く、かつ、うまく抽象化されている印象を持っている。ただし、抽象度の高低はメリデメあるので、ユースケースや状況によってどれが最適なのかは変わると思うし、それぞれのフレームワークの目的や目指すものは違うと思うので、一概に優劣をつけれないと思う。
この手のフレームワークはある程度考え方とか実装が似通ってくる(求められる機能はだいたい共通になるため)と思うのだけど、AutoGenだけちょっと極端に違う、というかその辺りもかなり抽象化されていてやもすればラディカル過ぎるかも、ってのが自分の中のイメージ。
なので、同じ抽象化でも、crewAIぐらいのレベル感のほうが現実的な実装という感を持った。
引き続きHow to Guidesに沿って試していく予定。上で書いた印象はやっていく中で変わるかもしれない。
カスタムなツールの作成
Tool/Function Callingで使うツールをカスタムで作る。
カスタムなツールを作る場合は以下のようにExtraを指定する必要がある
!pip install 'crewai[tools]'
カスタムなツールの作成方法は2つ。
-
BaseToolを継承したクラスを作る -
toolデコレータで関数を定義する。
まず、BaseToolを継承したクラスを作る場合。四則演算を別々のツールで行えるように定義してみる。
from crewai_tools import BaseTool
class MyAddTool(BaseTool):
name: str = "足し算ツール"
description: str = "2つの整数値を与えると、加算を行ってその結果となる数値を返す。"
def _run(self, first_operand: int, second_operand:int) -> int:
return int(first_operand + second_operand)
class MySubstractTool(BaseTool):
name: str = "引き算ツール"
description: str = "2つの整数値を与えると、1つ目の数値から2つ目の数値の減算を行ってその結果となる数値を返す。"
def _run(self, first_operand: int, second_operand:int) -> int:
return int(first_operand - second_operand)
class MyMultiplyTool(BaseTool):
name: str = "掛け算ツール"
description: str = "2つの整数値を与えると、乗算を行ってその結果となる数値を返す。"
def _run(self, first_operand: int, second_operand:int) -> int:
return int(first_operand * second_operand)
class MyDivideTool(BaseTool):
name: str = "割り算ツール"
description: str = "2つの整数値を与えると、1つ目の数値から2つ目の数値の除算を行ってその結果となる数値を返す。"
def _run(self, first_operand: int, second_operand:int) -> int:
return int(first_operand / second_operand)
ツールを定義する際に必要なのは、ツールの名前・説明、そして実際に処理を行う_runメソッドになる。
ではこれをエージェント・タスク・クルーを定義して使ってみる。
from crewai import Agent, Task, Crew, Process
os.environ["OPENAI_MODEL_NAME"]="gpt-4o"
add_tool = MyAddTool()
substract_tool = MySubstractTool()
multiply_tool = MyMultiplyTool()
divide_tool = MyDivideTool()
calculator = Agent(
role='数学の学者',
goal='与えられた数式をツールを使って解く。',
verbose=True,
memory=True,
backstory=(
"数学が大好き。いつも計算機を持ち歩いて、何でも計算しようとする。"
"ただ計算の仕方を知らないので、計算機に頼るしかない。"
),
tools=[add_tool, substract_tool, multiply_tool, divide_tool],
allow_delegation=False
)
calculate_task = Task(
description=(
"以下の数式を解いてください。"
"{formula}"
),
expected_output='計算結果とその過程',
tools=[add_tool, substract_tool, multiply_tool, divide_tool],
agent=calculator,
)
crew = Crew(
agents=[calculator],
tasks=[calculate_task],
process=Process.sequential,
memory=True,
cache=True,
max_rpm=100,
)
では実行してみる。
result = crew.kickoff(inputs={'formula': '(44232 + 13312 / (232 - 32)) * 5 は?'})
print(result)
実行結果
> Entering new CrewAgentExecutor chain...
まず、数式 (44232 + 13312 / (232 - 32)) * 5 を解くためには、内側の括弧から計算を始めます。
1. まず、(232 - 32) を計算します。
Action: 引き算ツール
Action Input: {"first_operand": 232, "second_operand": 32}
200
Thought: 次に、13312を200で割る必要があります。
Action: 割り算ツール
Action Input: {"first_operand": 13312, "second_operand": 200}
66
Thought: 次に、44232に66を足します。
Action: 足し算ツール
Action Input: {"first_operand": 44232, "second_operand": 66}
44298
Thought: 最後に、44298に5を掛けます。
Action: 掛け算ツール
Action Input: {"first_operand": 44298, "second_operand": 5}
221490
Thought: すべての計算が完了しました。各ステップの結果は次の通りです。
1. (232 - 32) の結果は 200
2. 13312 / 200 の結果は 66
3. 44232 + 66 の結果は 44298
4. 44298 * 5 の結果は 221490
これで最終解答を出すことができます。
Final Answer: (44232 + 13312 / (232 - 32)) * 5 の計算結果は 221490 です。
計算過程:
1. 232 - 32 = 200
2. 13312 / 200 = 66
3. 44232 + 66 = 44298
4. 44298 * 5 = 221490
> Finished chain.
(44232 + 13312 / (232 - 32)) * 5 の計算結果は 221490 です。
計算過程:
1. 232 - 32 = 200
2. 13312 / 200 = 66
3. 44232 + 66 = 44298
4. 44298 * 5 = 221490
きちんと順序立ててそれぞれのツールを使って回答を導き出せているのがわかる。
次に、toolデコレータを使う場合。こちらの場合は、デコレータで名前、関数のdocstringで説明を付与する必要がある。先ほどと区別するために関数名を少し変えている。
from crewai_tools import tool
@tool("足し算ツール")
def add_tool2(first_operand: int, second_operand:int) -> int:
"""2つの整数値を与えると、加算を行ってその結果となる数値を返す。"""
return int(first_operand + second_operand)
@tool("引き算ツール")
def substract_tool2(first_operand: int, second_operand:int) -> int:
"""2つの整数値を与えると、1つ目の数値から2つ目の数値の減算を行ってその結果となる数値を返す。"""
return int(first_operand - second_operand)
@tool("掛け算ツール")
def multiply_tool2(first_operand: int, second_operand:int) -> int:
"""2つの整数値を与えると、乗算を行ってその結果となる数値を返す。"""
return int(first_operand * second_operand)
@tool("割り算ツール")
def divide_tool2(first_operand: int, second_operand:int) -> int:
"""2つの整数値を与えると、1つ目の数値から2つ目の数値の除算を行ってその結果となる数値を返す。"""
return int(first_operand / second_operand)
同じように実行してみる。
from crewai import Agent, Task, Crew, Process
os.environ["OPENAI_MODEL_NAME"]="gpt-4o"
calculator = Agent(
role='数学の学者',
goal='与えられた数式をツールを使って解く。',
verbose=True,
memory=True,
backstory=(
"数学が大好き。いつも計算機を持ち歩いて、何でも計算しようとする。"
"ただ計算の仕方を知らないので、計算機に頼るしかない。"
),
tools=[add_tool2, substract_tool2, multiply_tool2, divide_tool2],
allow_delegation=False
)
calculate_task = Task(
description=(
"以下の数式を解いてください。"
"{formula}"
),
expected_output='計算結果とその過程',
tools=[add_tool2, substract_tool2, multiply_tool2, divide_tool2],
agent=calculator,
)
crew = Crew(
agents=[calculator],
tasks=[calculate_task],
process=Process.sequential, # オプション: タスク実行はシーケンシャルがデフォルト
memory=True,
cache=True,
max_rpm=100,
)
result = crew.kickoff(inputs={'formula': '(44232 + 13312 / (232 - 32)) * 5 は?'})
print(result)
結果はこちらも同じ。
> Entering new CrewAgentExecutor chain...
まず、数式の中の括弧の部分を計算する必要があります。具体的には、(232 - 32) を計算します。
Action: 引き算ツール
Action Input: {"first_operand": 232, "second_operand": 32}
200
Thought:
括弧の中の計算ができましたので、次に13312をその結果で割ります。これにより13312 / 200を計算します。
Action: 割り算ツール
Action Input: {"first_operand": 13312, "second_operand": 200}
66
Thought:
次に、44232に先ほど計算した結果の66を加えます。これにより44232 + 66を計算します。
Action: 足し算ツール
Action Input: {"first_operand": 44232, "second_operand": 66}
44298
Thought:
次に、先ほど計算した44298を5で掛け算します。これにより(44232 + 13312 / (232 - 32)) * 5の最終結果が得られます。
Action: 掛け算ツール
Action Input: {"first_operand": 44298, "second_operand": 5}
221490
Thought: I now know the final answer and will present the calculation process and the final result.
Final Answer: 以下の数式を解いてください。(44232 + 13312 / (232 - 32)) * 5 の計算結果とその過程は次の通りです。
1. 括弧の中の計算:
232 - 32 = 200
2. 割り算:
13312 / 200 = 66
3. 足し算:
44232 + 66 = 44298
4. 掛け算:
44298 * 5 = 221490
従って、(44232 + 13312 / (232 - 32)) * 5 の最終結果は 221490 です。
> Finished chain.
以下の数式を解いてください。(44232 + 13312 / (232 - 32)) * 5 の計算結果とその過程は次の通りです。
1. 括弧の中の計算:
232 - 32 = 200
2. 割り算:
13312 / 200 = 66
3. 足し算:
44232 + 66 = 44298
4. 掛け算:
44298 * 5 = 221490
従って、(44232 + 13312 / (232 - 32)) * 5 の最終結果は 221490 です。
ツール結果をキャッシュするかどうかも自分で定義できるらしい。今回の例だとあまり意味がなさそう。
なお、ツールは自分で作成しなくても以下のようなものが用意されている。
なお、以下にcrewAIのQuick Start的なnotebookをまとめている方がいて、各ツールの使い方のnotebookが多数あるので参考になりそう。
あと、なんかコード見た感じ、LangChainのAgentのツールをそのまま使えそうな雰囲気がある。
コンセプト部分の説明だからしょうがないのかもしれないけど、実際に動くコードのサンプルがドキュメントにない、のはちょっと不満・・・(上は自分で作った)
シーケンシャルプロセス / 階層的プロセス
crewAIではタスクの実行をシーケンシャル or 階層的に行えることができる。
-
シーケンシャルプロセス
- タスクは逐次的に行われる。
- 主要な機能とユースケース
- 直線的なタスクフロー: 決められた順序でタスクを処理することで、秩序ある進行を保証する。
- 単純さ: 明確なステップバイステップのタスクがあるプロジェクトに最適。
- 簡単なモニタリング: タスクの完了とプロジェクトの進捗を簡単に追跡できる。
-
階層的プロセス
- 伝統的な組織階層をシミュレートして、タスクの管理・実行・委譲が行われる。具体的には「マネージャー」エージェントがワークフローを調整、タスクを委譲、合理的かつ効果的に実行するために結果を検証する。
- 主要な機能とユースケース
- タスクの委任: マネージャエージェントは、クルーの役割と能力に基づいて、クルーのタスクを割り当てる
- 結果の検証: マネージャーが成果を評価し、必要な基準を満たしていることを確認する
- 効率的なワークフロー: 企業構造をエミュレートし、タスク管理に組織的なアプローチを提供
Getting Startedでやった例はシーケンシャルの例
from crewai import Agent, Task, Crew, Process
from crewai_tools import SerperDevTool
search_tool = SerperDevTool()
os.environ["OPENAI_MODEL_NAME"]="gpt-4o"
researcher = Agent(
role='上級研究員',
goal='{topic}における画期的な技術を発見してください。',
verbose=True,
memory=True,
backstory=(
"好奇心に突き動かされイノベーションの最前線に立つあなたは、"
"世界を変えるかもしれない知識を探求し、共有することを熱望している。"
),
tools=[search_tool],
allow_delegation=True
)
writer = Agent(
role='記者',
goal='{topic}における説得力のある技術ストーリーを語ってください。',
verbose=True,
memory=True,
backstory=(
"複雑なトピックを単純化する才能に長けたあなたは、"
"興味深い物語を作り上げて読者を引きつけ教育し、"
"新しい発見をわかりやすく紹介する"
),
tools=[search_tool],
allow_delegation=False
)
research_task = Task(
description=(
"{topic}の次の大きなトレンドを特定してください。"
"長所と短所、そして全体的なストーリーを特定することに集中してください。"
"あなたが書く最終報告書では、重要なポイント、市場機会、潜在的リスクを"
"明確に表現する必要がある。"
),
expected_output='最新のAIトレンドに関する3パラグラフに及ぶ包括的なレポート。',
tools=[search_tool],
agent=researcher,
)
write_task = Task(
description=(
"{topic}について洞察に満ちた記事を書いてください。"
"最新のトレンドと、それが業界にどのような影響を与えているかに焦点を当ててください。"
"あなたが書く記事は、わかりやすく、魅力的で、ポジティブな記事である必要がある。"
),
expected_output='Markdownでフォーマットされた、{topic}の進歩に関する4パラグラフの記事。',
tools=[search_tool],
agent=writer,
async_execution=False,
output_file='new-blog-post.md'
)
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential, # シーケンシャル
memory=True,
cache=True,
max_rpm=100,
share_crew=False
)
result = crew.kickoff(inputs={'topic': 'ヘルスケア分野におけるAI'})
print(result)
このケースのイメージを自分なりにまとめるとこう。
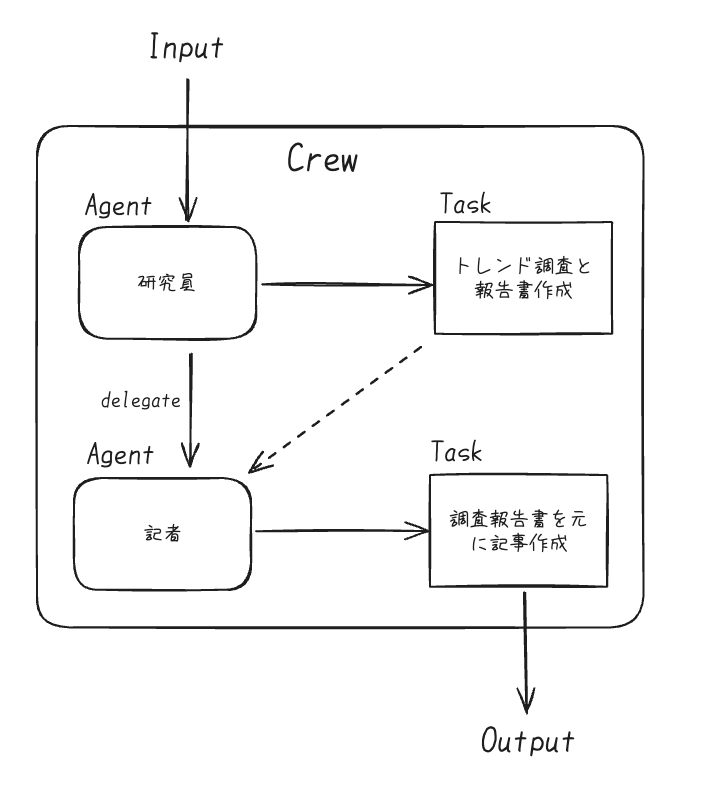
まあ自然ではある。
で階層的プロセスの場合。クルー編成箇所で以下のように設定する。
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.hierarchical, # 階層的プロセス
# 階層的プロセスの場合は`manager_llm`もしくは`manager_agent`が必須
manager_llm=ChatOpenAI(temperature=0, model="gpt-4o"),
memory=True,
cache=True,
max_rpm=100,
)
process=Process.hierarchicalを設定した場合は、マネージャーを用意する必要がある。マネージャーの定義はmanager_llmとmanager_agentの2つっぽい。manager_llmではLLMの設定を渡してやればマネージャーとしてのプロンプトが渡されて動作する。manager_agentはドキュメントにはまだ載ってないようだけど、マネージャーの役割をカスタムに定義したエージェントを使うことができるっぽい。
こちらで実行してみる。出力は多いので抜粋で。
まず最初に出力されているのはおそらくマネージャーのプロンプト。クルーの能力などの説明が行われて、まず最初に研究員エージェントへの指示が行われている。
> Entering new CrewAgentExecutor chain...
To identify the next big trend in AI within the healthcare sector, I need to gather comprehensive insights from both the 上級研究員 and the 記者. The 上級研究員 can provide technical insights and potential risks, while the 記者 can help with market opportunities and the overall story.
First, I'll ask the 上級研究員 about the latest advancements in AI technology relevant to healthcare, including their strengths and weaknesses. This will help us understand the technical aspects and potential risks.
Thought: I need to gather technical insights on the latest AI advancements in healthcare from the 上級研究員.
Action: Ask question to co-worker
Action Input: {"question": "What are the latest advancements in AI technology relevant to the healthcare sector? Please include their strengths and weaknesses.", "context": "We are identifying the next big trend in AI within the healthcare sector. We need to understand the technical aspects, strengths, and weaknesses of the latest AI advancements.", "coworker": "上級研究員"}
> Entering new CrewAgentExecutor chain...
I should start by searching for the latest advancements in AI technology relevant to the healthcare sector. This will help me gather comprehensive information on the subject.
Action: Search the internet
Action Input: {"search_query": "latest advancements in AI technology in healthcare 2023"}
(snip)
研究員エージェントの結果が出たらマネージャーはその内容を検証しているのだと思う。そして追加で指示を出している。
Thought: The 上級研究員 has provided a general observation about the promise of AI in healthcare. However, I need more specific details about the latest advancements, their strengths, and weaknesses. I will ask the 上級研究員 to provide a detailed summary of the article.
Action: Ask question to co-worker
Action Input: {"question": "Can you provide a detailed summary of the latest advancements in AI technology relevant to the healthcare sector, including their strengths and weaknesses, based on the article you reviewed?", "context": "We are identifying the next big trend in AI within the healthcare sector. We need to understand the technical aspects, strengths, and weaknesses of the latest AI advancements. You mentioned the article 'The Current State of AI in Healthcare and Where It's Going in 2023'.", "coworker": "上級研究員"}
> Entering new CrewAgentExecutor chain...
そして研究員エージェントからの結果が十分に集まったら今度は記者エージェントに次の指示を投げている。
Thought: I now have a detailed summary of the latest advancements in AI technology relevant to the healthcare sector, including their strengths and weaknesses. Next, I need to gather insights on market opportunities and the overall story from the 記者. This will help in identifying the next big trend in AI within the healthcare sector and understanding the potential market impact and risks.
Action: Ask question to co-worker
Action Input: {"question": "What are the current market opportunities and potential risks for AI technologies in the healthcare sector? Please provide a detailed analysis.", "context": "We are identifying the next big trend in AI within the healthcare sector. We need to understand the market opportunities and potential risks associated with AI technologies in healthcare.", "coworker": "記者"}
記者のタスク結果を受け取ったあと、再度研究員エージェントに戻したりもしていた。
To write an insightful article on AI in healthcare, focusing on the latest trends and their impact on the industry, I need to gather specific insights and perspectives from my team members. Given the context provided, I will first delegate the task of gathering detailed information on the latest trends in AI technologies in healthcare to the 上級研究員. Then, I will ask the 記者 to draft the article based on the gathered information, ensuring it is clear, engaging, and positive.
Thought: Delegate the task of gathering detailed information on the latest trends in AI technologies in healthcare to the 上級研究員.
Action: Delegate work to co-worker
Action Input: {"coworker": "上級研究員", "task": "Gather detailed information on the latest trends in AI technologies in healthcare, including machine learning, natural language processing, clinical decision support systems, imaging and diagnostics, and robotic process automation. Provide insights on how these technologies are impacting the industry, their strengths, and the challenges they face.", "context": "We need to write an insightful article on AI in healthcare, focusing on the latest trends and their impact on the industry. The article should be clear, engaging, and positive."}
そして最後に十分な情報があつまったところで、記者エージェントにまとめを書かせて、最終的な結果が作成された。
Thought: Now that I have detailed information on the latest trends in AI technologies in healthcare, I will delegate the task of drafting the article to the 記者. The article should be clear, engaging, and positive, focusing on the latest trends and their impact on the industry.
Action: Delegate work to co-worker
Action Input: {"coworker": "記者", "task": "Draft an article on AI in healthcare, focusing on the latest trends and their impact on the industry. The article should be clear, engaging, and positive. Use the following detailed information on the latest trends: 1. Healthcare Analytics: AI-driven analytics tools are increasingly being used to process large datasets, identify patterns, and generate actionable insights. These tools help in predicting patient outcomes, optimizing treatment plans, and improving operational efficiency. 2. Medical Diagnostics: AI is revolutionizing diagnostics by enhancing the accuracy and speed of disease detection. Machine learning algorithms analyze medical images and data to identify conditions such as cancer, cardiovascular diseases, and neurological disorders with high precision. 3. Telehealth: AI-powered telehealth solutions are bridging the gap between patients and healthcare providers. These solutions include virtual consultations, remote monitoring, and AI-driven chatbots that provide medical advice and support. 4. Medical Robots: Robotics in healthcare is being enhanced by AI to perform complex surgeries, assist in rehabilitation, and support elderly care. AI-driven robots improve precision, reduce recovery times, and enhance patient outcomes. 5. Hospital Management: AI is streamlining hospital management by optimizing resource allocation, improving patient flow, and enhancing administrative efficiency. Predictive analytics and automation are key components in this trend. 6. Drug Discovery: AI is accelerating the drug discovery process by analyzing biological data, predicting drug interactions, and identifying potential candidates for clinical trials. This reduces the time and cost associated with bringing new drugs to market. 7. Personalized Medicine: AI is enabling personalized medicine by analyzing genetic, environmental, and lifestyle data to tailor treatments to individual patients. This approach improves the effectiveness of treatments and reduces adverse effects. 8. Mental Health: AI is being used to develop tools for mental health assessment and intervention. These include emotion recognition systems, virtual therapists, and AI-driven apps that monitor and support mental well-being. 9. Wearable Technology: AI is enhancing wearable devices that monitor vital signs, physical activity, and other health metrics. These devices provide real-time data to patients and healthcare providers, enabling proactive health management. 10. Blockchain Integration: AI and blockchain are being integrated to enhance data security, ensure patient privacy, and improve the interoperability of healthcare systems. This combination addresses concerns related to data breaches and unauthorized access.", "context": "We need to write an insightful article on AI in healthcare, focusing on the latest trends and their impact on the industry. The article should be clear, engaging, and positive."}
> Entering new CrewAgentExecutor chain...
Thought: I now can give a great answer
Final Answer:
---
**AI革命:ヘルスケアにおける最新トレンドとその影響**
現代の医療は、人工知能(AI)の導入によって新たな次元へと進化しています。AIは、データ解析から診断、遠隔医療、病院管理まで、あらゆる分野でその力を発揮しています。今回は、ヘルスケア分野におけるAIの最新トレンドとその影響について詳しく見ていきましょう。(snip)
先ほどとは処理の流れが少し異なっているのがわかる。
こちらのケースの自分のイメージはこう。
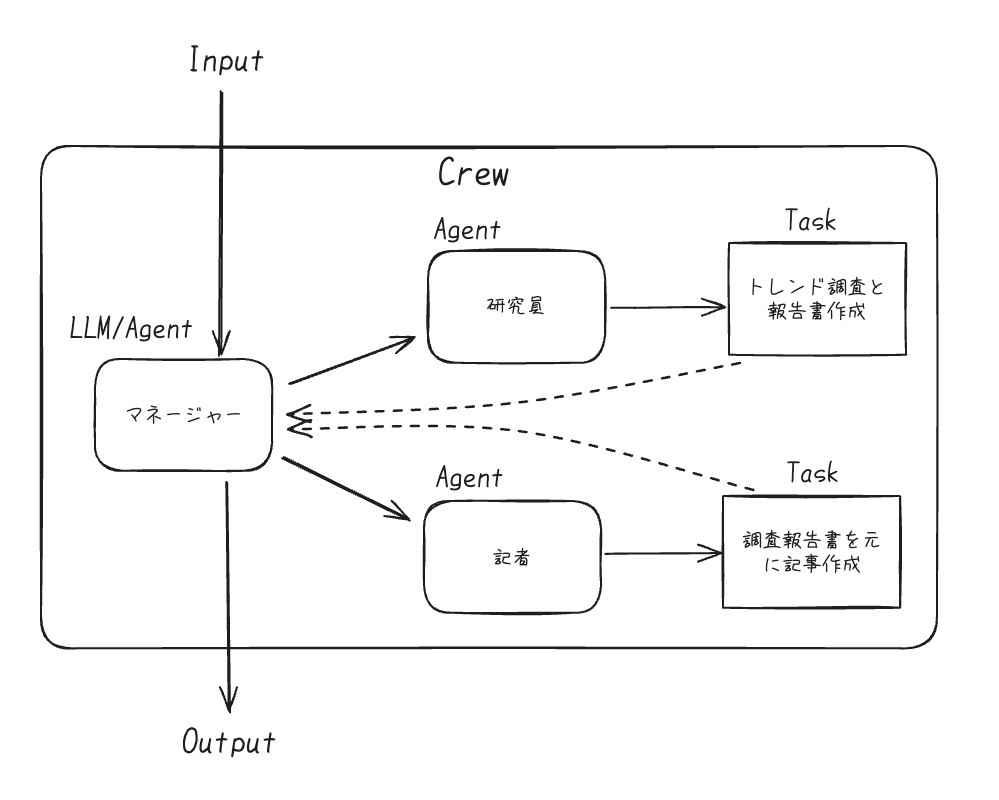
ただ、ログを見てても今誰が話しているのか?がちょっとわからない感があるし、allow_delegationの設定とかもどう影響するのかとか気になる。どちらの場合も図ほどシンプルな感じではなさそう。
あとタスクって直接的なものではなくて、もっと広い意味で「基本的にあなたがやること」って感じがする。マネージャから色々指示飛んでいるのを見てそう思った。
いろいろなLLMへの接続
デフォルトではgpt-4が使用されるが、それ以外にもいくつかのLLMに対応している
- Ollama
- HuggingFace
- FastChat
- LM Studio
- Mistral
- Solar
- text-generation-web-ui
- Cohere
- Azure OpenAI
あと、LLMの設定は
os.environ["OPENAI_MODEL_NAME"]="gpt-4o"
みたいな感じでグローバルに設定できるけども、エージェント単位でも設定できるっぽい。
とりあえずここはこんなもんで。
エージェントのカスタマイズ
エージェントのカスタマイズについて。以下のエージェントのコンセプトのページも参考になる。
エージェントの属性
エージェントそのものの基本的な属性に関するパラメータは以下。
- Role
- 「アナリスト」や「カスタマーサービス担当」など、クルー内でのエージェントの職業を指定する。
- Goal
- エージェントの役割やクルーの包括的な目標に合わせて、エージェントが達成したいことを定義する。
- Backstory
- エージェントのペルソナに深みを与え、モチベーションやクルー内での関わり方を豊かにする。- Tool
- 単純な機能から複雑な統合まで、エージェントがタスクを実行するために使用する能力や方法を表す。
以前の研究員エージェントとそのタスクのサンプルを改めて見てみる。
researcher = Agent(
role='上級研究員',
goal='{topic}における画期的な技術を発見してください。',
verbose=True,
memory=True,
backstory=(
"好奇心に突き動かされイノベーションの最前線に立つあなたは、"
"世界を変えるかもしれない知識を探求し、共有することを熱望している。"
),
tools=[search_tool],
allow_delegation=True
)
research_task = Task(
description=(
"{topic}の次の大きなトレンドを特定してください。"
"長所と短所、そして全体的なストーリーを特定することに集中してください。"
"あなたが書く最終報告書では、重要なポイント、市場機会、潜在的リスクを"
"明確に表現する必要がある。"
),
expected_output='最新のAIトレンドに関する3パラグラフに及ぶ包括的なレポート。',
tools=[search_tool],
agent=researcher,
)
エージェントのrole、goal、backstoryってのはこのプロンプトで使われていて、
LangSmithを有効にしてトレーシングしてみたら(この辺はLangChainで書かれていることのメリットだな)こんな感じでユーザプロンプトの最初に定義されていた。なるほどgoalはエージェント個人のパーソナルなゴールで、タスクがより具体的なゴール、って感じみたい。
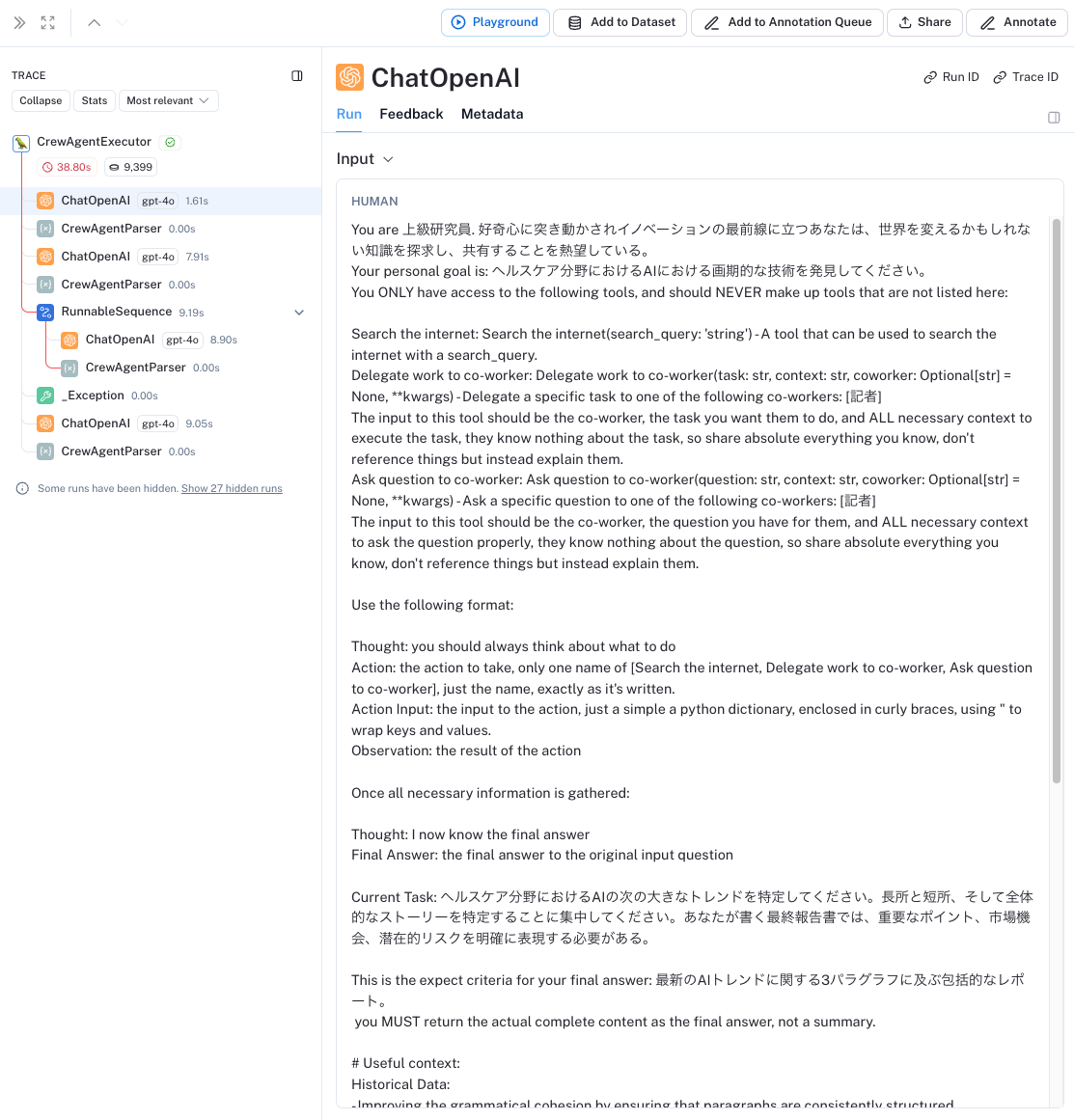
言語モデルの設定
一つ前で書いた通り、crewAIで使用されるLLMは、デフォルトは"gpt-4"となっており、環境変数OPENAI_MODEL_NAMEでこれを変更できるが、これがグローバルな設定になっている様子。
os.environ["OPENAI_MODEL_NAME"]="gpt-4o"
ただし、個々のエージェントにモデルを設定することもできるし、また通常のやりとりと、Function Callingで異なるモデルを設定することができる。サンプルは以下。
from langchain_openai import ChatOpenAI
os.environ["OPENAI_MODEL_NAME"]="gpt-4o"
researcher = Agent(
role='上級研究員',
goal='{topic}における画期的な技術を発見してください。',
verbose=True,
memory=True,
backstory=(
"好奇心に突き動かされイノベーションの最前線に立つあなたは、"
"世界を変えるかもしれない知識を探求し、共有することを熱望している。"
),
llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"), # ここ
function_calling_llm=ChatOpenAI(temperature=0, model="gpt-4"), # ここ
tools=[search_tool],
allow_delegation=True
)
どうやらモデルの設定はLangChainのモデルで定義するらしい。上記の例だと通常のやりとりはgpt-3.5-turbo、Function Callingが必要な場合はgpt-4、という感じになる。
パフォーマンスとデバッグに関する設定
VerboseモードとRPM制限
verboseを有効にすると、 エージェントの動作の詳細なロギングが表示される。デバッグや最適化次に使うと良い。デフォルトはFalse。
max_rpmを有効にすると、RPM(request-per-minute)制限=1分あたりの最大リクエスト数を設定できる。レートリミットなどを考慮する場合に設定すると良さそう。デフォルトはNone。
タスク実行時の最大イテレーション回数
max_iterは、エージェントが1つのタスクに対して実行できる最大イテレーション回数を定義し、無限ループや長時間の実行を防ぐことができる。デフォルトは15回とあるけどコンセプトのドキュメントには25回とある。コード見てもどっちの数字もあるのでちょっとよくわからない。。。
あと、ここドキュメントに
エージェントがこの数値に近づくと、良い答えを出そうと最善を尽くす。
とあるのだけど、雑にコード見た限りはこの辺かな。最大イテレーション数-2みたいな感じで設定されてるように見える。
で多分この辺のプロンプトが絡んでそう。
ツールの使用をやめて最終回答を促すような感じに見える。
委譲
allow_delegationを有効にすると、エージェントは必要に応じて、他のエージェントに助けを求めたり、タスクを委譲したりする。何かしらこれがまずいようなケースがあれば無効にすれば良い。
とあるけど、どういうケースがあるんだろうか。サンプルを見ていると、シーケンシャルプロセスの最後のエージェントなんかは無効になっていたけども、階層的プロセスの場合は差し戻ったりもしているので、どちらの場合もメリデメありそうな気がした。
エージェント実行中の人間による入力
いわゆるHuman-in-the-loop。CrewAIで人間による入力を有効にするには、タスクの作成時にhuman_inputパラメータを有効にする。これを有効にすると最終回答のタイミングでユーザに入力を求めるようになる。
研究員・記者のクルーのサンプルで、記者のタスクにhuman_inputを有効にしてみた。
from crewai import Agentl, Task, Crew, Process
from crewai_tools import SerperDevTool
search_tool = SerperDevTool()
os.environ["OPENAI_MODEL_NAME"]="gpt-4o"
researcher = Agent(
role='上級研究員',
goal='{topic}における画期的な技術を発見してください。',
verbose=True,
memory=True,
backstory=(
"好奇心に突き動かされイノベーションの最前線に立つあなたは、"
"世界を変えるかもしれない知識を探求し、共有することを熱望している。"
),
tools=[search_tool],
allow_delegation=True
)
writer = Agent(
role='記者',
goal='{topic}における説得力のある技術ストーリーを語ってください。',
verbose=True,
memory=True,
backstory=(
"複雑なトピックを単純化する才能に長けたあなたは、"
"興味深い物語を作り上げて読者を引きつけ教育し、"
"新しい発見をわかりやすく素晴らしい日本語で紹介する。"
),
allow_delegation=False
)
research_task = Task(
description=(
"{topic}の次の大きなトレンドを特定してください。"
"長所と短所、そして全体的なストーリーを特定することに集中してください。"
"あなたが書く最終報告書では、重要なポイント、市場機会、潜在的リスクを"
"明確に表現する必要がある。"
),
expected_output='最新のAIトレンドに関する3パラグラフに及ぶ包括的なレポート。',
tools=[search_tool],
agent=researcher,
)
write_task = Task(
description=(
"{topic}について洞察に満ちた記事を書いてください。"
"最新のトレンドと、それが業界にどのような影響を与えているかに焦点を当ててください。"
"あなたが書く記事は、わかりやすく、魅力的で、ポジティブな記事である必要がある。"
),
expected_output='Markdownでフォーマットされた、{topic}の進歩に関する4パラグラフの記事。',
tools=[search_tool],
agent=writer,
async_execution=False,
output_file='new-blog-post.md',
human_input=True, ###### 人間の入力を求める
)
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential,
memory=True,
cache=True,
max_rpm=100,
)
result = crew.kickoff(inputs={'topic': 'ヘルスケア分野におけるAI'})
print(result)
実行すると最終回答のところで入力が求められる。

適当にフィードバックを入れてみる。
口調は大阪弁にして。
するとこんな感じでフィードバックに応じて書き換えてくれた。

フィードバック前の最終回答
# ヘルスケア分野におけるAIの進歩: 2023年の最新トレンド
ヘルスケア分野におけるAIの進化は、医療の提供方法と患者体験の向上に大きな影響を与えています。2023年には、自然言語処理(NLP)と会話型AI、医療ロボティクス、テレヘルス、感情AI(Emotion AI)、および医療分析と予測分析が注目のトレンドとなっています。これらの技術は、医療の質を向上させるだけでなく、患者の利便性やアクセスを大幅に改善する可能性があります。
まず、自然言語処理(NLP)と会話型AIは、患者とのコミュニケーションを劇的に改善しています。自動応答システムやバーチャルアシスタントは、患者の質問に迅速に対応し、24時間体制でサポートを提供します。これにより、医療提供者の業務負担が軽減される一方で、患者は迅速かつ正確な情報を得ることができます。ただし、NLPの精度に関する課題や患者データのプライバシーとセキュリティの懸念も依然として存在します。
次に、医療ロボティクスの進歩も見逃せません。手術ロボットやリハビリテーションロボットは、手術の精度を向上させ、患者の回復を早める効果があります。さらに、遠隔操作による手術も可能となり、医療アクセスが向上します。しかし、高コストが導入の障壁となり、特に小規模医療施設では採用が難しいという現実もあります。技術的なトラブルやロボットの故障リスクも考慮する必要があります。
テレヘルスは、地理的な制約を超えて医療サービスを提供し、患者のアクセスを大幅に向上させる技術です。特にパンデミックのような状況下でも医療提供が途切れないという利点があります。しかし、インターネット接続の質やデジタルリテラシーの差異が、サービスの利用に影響を与える可能性があります。対面診療に比べて診断の精度が低下するリスクも存在します。
最後に、感情AI(Emotion AI)と医療分析および予測分析も重要なトレンドです。感情AIは、患者の感情状態を理解し、精神的なサポートを提供するために使用され、メンタルヘルスケアの質を向上させます。医療分析と予測分析は、大量の医療データを解析することで、早期診断や予防医療を可能にし、患者の健康管理を向上させます。しかし、データの品質や一貫性に関する問題やプライバシー保護の課題もあります。
ヘルスケア分野におけるAIは、多くの可能性と課題を抱えています。これらの技術を効果的かつ安全に導入するためには、データプライバシーやセキュリティ、技術的な信頼性とコストの問題に対処する必要があります。それでも、これらの技術は医療の質を向上させ、患者体験を改善するための強力なツールであることに変わりはありません。
フィードバック後の最終回答
# ヘルスケア分野におけるAIの進歩: 2023年の最新トレンド
ヘルスケア分野におけるAIの進化は、医療の提供方法と患者体験の向上に大きな影響を与えてるで。2023年には、自然言語処理(NLP)と会話型AI、医療ロボティクス、テレヘルス、感情AI(Emotion AI)、および医療分析と予測分析が注目のトレンドになってる。これらの技術は、医療の質を向上させるだけやなく、患者の利便性やアクセスを大幅に改善する可能性があるんや。
まず、自然言語処理(NLP)と会話型AIは、患者とのコミュニケーションを劇的に改善してるんや。自動応答システムやバーチャルアシスタントは、患者の質問に迅速に対応し、24時間体制でサポートを提供するんや。これにより、医療提供者の業務負担が軽減される一方で、患者は迅速かつ正確な情報を得ることができる。ただし、NLPの精度に関する課題や患者データのプライバシーとセキュリティの懸念も依然として存在するわ。
次に、医療ロボティクスの進歩も見逃せへん。手術ロボットやリハビリテーションロボットは、手術の精度を向上させ、患者の回復を早める効果があるんや。さらに、遠隔操作による手術も可能になり、医療アクセスが向上するんやけど、高コストが導入の障壁となり、特に小規模医療施設では採用が難しいという現実もあるんや。技術的なトラブルやロボットの故障リスクも考慮せなあかん。
テレヘルスは、地理的な制約を超えて医療サービスを提供し、患者のアクセスを大幅に向上させる技術やね。特にパンデミックのような状況下でも医療提供が途切れないという利点があるんや。しかし、インターネット接続の質やデジタルリテラシーの差異が、サービスの利用に影響を与える可能性があるんや。対面診療に比べて診断の精度が低下するリスクも存在するわ。
最後に、感情AI(Emotion AI)と医療分析および予測分析も重要なトレンドやね。感情AIは、患者の感情状態を理解し、精神的なサポートを提供するために使用され、メンタルヘルスケアの質を向上させるんや。医療分析と予測分析は、大量の医療データを解析することで、早期診断や予防医療を可能にし、患者の健康管理を向上させるんやけど、データの品質や一貫性に関する問題やプライバシー保護の課題もあるんや。
ヘルスケア分野におけるAIは、多くの可能性と課題を抱えてるんや。これらの技術を効果的かつ安全に導入するためには、データプライバシーやセキュリティ、技術的な信頼性とコストの問題に対処する必要があるんや。それでも、これらの技術は医療の質を向上させ、患者体験を改善するための強力なツールであることに変わりはないんやで。
ちなみに、
- 自分が試した限りは1回だけしか確認されなかった。フィードバックしたらその後はもう確認されない。
- 何も入力しない場合はどうやらうまく処理できないみたいで、延々とCoTのエラーが繰り返されていた(多分イテレーション最大回数まで繰り返して終わるような気がする。)なので、フィードバックするにせよしないにせよ、何かしら入力が必要になると思う。
AgentOpsを使ったエージェントのモニタリング
先んじて、LangSmithを使ってモニタリングをしてみたけども、crewAIではAgentOpsというAIエージェント専用のモニタリングSaaSに対応している様子。
色々見た限り、AgentOpsのウリはこの辺っぽい。
- 📊リプレイ分析とデバッグ: ステップバイステップのエージェント実行グラフ
- 💸 LLMコスト管理: LLM基礎モデルプロバイダとの支出を追跡する
- 🧪エージェントのベンチマーク: エージェントを1,000以上の評価とテストする
- 🔐コンプライアンスとセキュリティ: 一般的なプロンプトインジェクションとデータ流出の悪用を検出する
- 🤝フレームワークの統合: CrewAIやLangChainのようなフレームワークと簡単にプラグインできる。
無料プランがあるようなのでアカウントを作ってやってみたのだけども、どうもうまくいかない。具体的には、以下のような感じで、セッションが終わっていないという風に認識されているようで、トレースが取れていない状態になってしまう。。。。
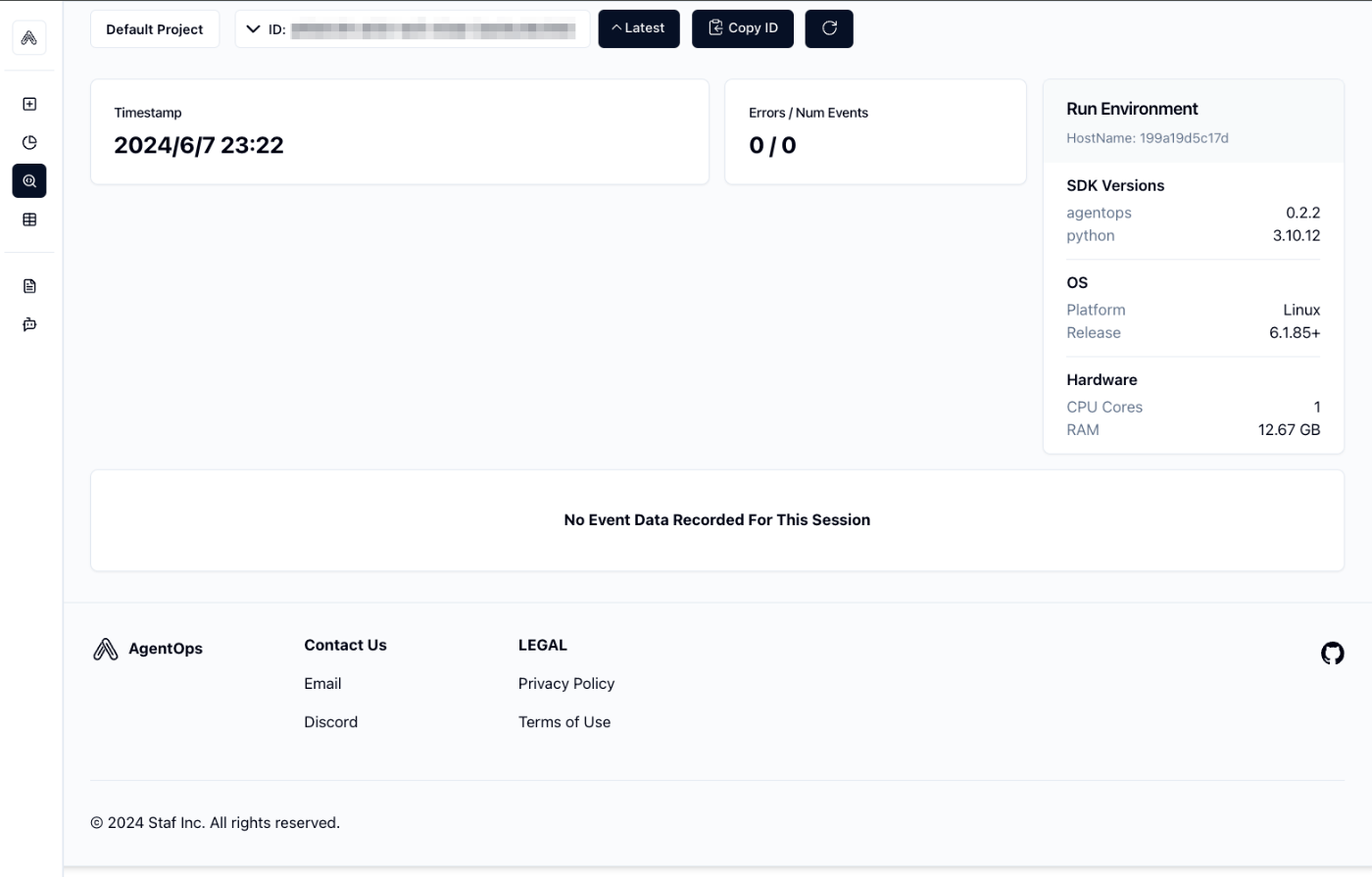
一応手順だけ書いておく。AgentOpsでアカウント作成してデフォルトプロジェクトのAPIキーを取得出来た後から。
ますパッケージインストール。2つ手順が用意されているが、crewaiのextraで有効にする方法は実行するとそんなextraはないと言われる。。。
!pip install crewai[agentops]
なのでAgentOpsのパッケージを直接インストールする方になる。
!pip install agentops
次にAgentOpsのAPIキーを環境変数にセットする。
import os
from google.colab import userdata
os.environ["AGENTOPS_API_KEY"] = userdata.get('AGENTOPS_API_KEY')
そしてCrewを定義する前に以下を追加する。
import agentops
agentops.init()
すると以下のように表示される。これが現在のセッションのURLになるっぽい。
🖇 AgentOps: Session Replay: https://app.agentops.ai/drilldown?session_id=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
INFO:agentops:Session Replay: https://app.agentops.ai/drilldown?session_id=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
UUID('XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX')
先ほどの研究員・記者エージェントのクルーを実行する、だけ、っぽいのだけども、うーん、crewAIとAgentOpsのどちらに問題があるのかわからないな・・・
正式にサポートしているわけではないみたいだけど、LangSmithでまあある程度は取れる。ただ、1回のクルーの実行でトレースが複数に分かれてしまうのがちょっと難点かも。
所感part2
とりあえずGetting Startedの後のファーストインプレッションからはそんなに変わってないかなというところ。
- なんていうか正統派な感じ。
- シンプルなLLMアプリ実装したり、LangChainみたいなフレームワーク使ったり、エージェント試してみたり、ってのを経験した上で、エージェントフレームワーク作ったらこうなった、的な感じに思える。- エージェントの定義にrole、goal、backstoryと複数の種類があるのが面白い。より個性を植え付けれるような気がする。
- エージェントとタスクを最初に定義してからチーム作るってところは、ボトムアップ的なアプローチに思える。
- チームにタスクを与えて、というよりは、個々のチームメンバーのタスクの成果物を集めたら最終成果物ができた、みたいなイメージ。
抽象化のレイヤーはかなり高いとは思うけども、(マルチ)エージェント系フレームワークをいくつか触ってみてcrewAIを他と比較した場合、自分的になイメージはこんな感じ。
AutoGen >>> crewAI >> Langroid > LangGraph > Burr
最近ちょうどAutoGen触ったところなので、その印象が強くバイアスになってるとは自分でも思うのだけども、それでもAutoGenの抽象度はかなり高く思える。LLMアプリとかを実際に実装したことがなくても、なんかできそう、と思えるぐらいに、高く、かつ、うまく抽象化されている印象を持っている。ただし、抽象度の高低はメリデメあるので、ユースケースや状況によってどれが最適なのかは変わると思うし、それぞれのフレームワークの目的や目指すものは違うと思うので、一概に優劣をつけれないと思う。
この手のフレームワークはある程度考え方とか実装が似通ってくる(求められる機能はだいたい共通になるため)と思うのだけど、AutoGenだけちょっと極端に違う、というかその辺りもかなり抽象化されていてやもすればラディカル過ぎるかも、ってのが自分の中のイメージ 。
なので、同じ抽象化でも、crewAIぐらいのレベル感のほうが現実的な実装という感を持った。
AutoGenほどではないけども、それなりにわかりやすくできているのではないかと思う。AutoGenはコンセプトや実装は簡単なんだけど、目的となる結果をいい感じに得るにはちょっと制御が難しいのではないかなという感はあって、それに比べればcrewAIのほうがやや制御しやすいのではないかという気はしている。なんというかこちらのほうがゴール志向な感を個人的には持った。
ただ、個人的には、進めるにつれてドキュメントへの不満は少し増えたかな、基本的に足りない感があるし、やや記述も不親切な印象を自分は持ってしまった。まあ、このあたりはexampleを見て色々試せばいいのかもしれない。具体的な例があるのは参考になると思う。
あと、テレメトリについて補足。share_crewを有効にしていなくても、デフォルトである程度問題ないような情報は取得しているらしい。ここは気になる人は気になると思うので、要確認。
エージェント系フレームワークもいろいろ増えてきていると思うので、実際に試してみて、ユースケースに合うか、使い勝手はどうか、というのを確かめるのが良いと改めて感じた。
コンセプトのドキュメントを見てたんだけども、ここはちょっと気になるので後で読む。
オフィシャルではないが、GUIエディタ
この辺とどっちがいいかという感じになりそう
ノーコードのフロントエンドができるっぽい。クラウドサービスのみかな?