LLMエージェントフレームワーク「AutoGen」を試す
AutoGenとは?
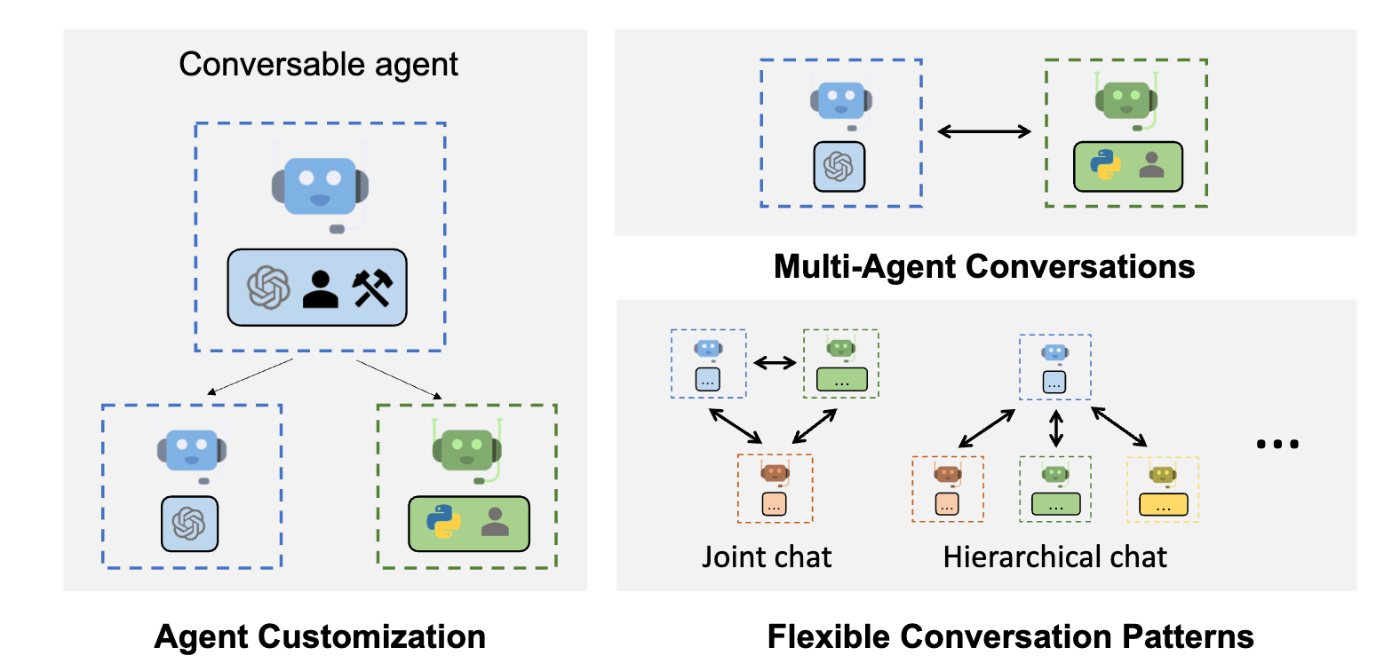
AutoGenは、タスクを解決するために互いに会話できる複数のエージェントを使用して、LLMアプリケーションの開発を可能にするフレームワークである。AutoGenエージェントは、カスタマイズ可能で、会話可能で、シームレスに人間の参加を可能にする。LLM、人間の入力、ツールを組み合わせた様々なモードで動作することができる。
referred from https://github.com/microsoft/autogen
- AutoGenは、最小限の労力でマルチエージェント会話に基づく次世代LLMアプリケーションを構築できる。複雑なLLMワークフローのオーケストレーション、自動化、最適化を簡素化する。LLMモデルのパフォーマンスを最大化し、弱点を克服する。
- 複雑なワークフローのための多様な会話パターンをサポートする。カスタマイズ可能で会話可能なエージェントにより、開発者はAutoGenを使用して、会話の自律性、エージェントの数、エージェントの会話トポロジーに関する幅広い会話パターンを構築できる。
- AutoGenは、さまざまな複雑性を持つ作業システムのコレクションを提供する。これらのシステムは、様々なドメインと複雑性を持つ幅広いアプリケーションに及ぶ。これは、AutoGenがいかに多様な会話パターンを容易にサポートできるかを示している。
- AutoGenは強化されたLLM推論を提供する。APIの単一化やキャッシュといったユーティリティや、エラー処理、マルチコンフィグ推論、コンテキスト・プログラミングなどの高度な使用パターンを提供する。
AutoGenは、Microsoft、ペンシルベニア州立大学、ワシントン大学の共同研究から生まれた。
公式ドキュメント
Getting Started
Getting Startedにしたがってすすめる。とりあえずColaboratoryで。
Quick start
インストール
!pip install pyautogen
OpenAIのAPIキーを読み込み
from google.colab import userdata
import os
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
実行方法は3つあるが、どうやらコード実行環境をどうするか、というところで分かれている模様。
- No code execution: コード実行しない
- Local execution: ローカル環境でコード実行する
- Docker execution: Dockerを使ってコード実行する
Colaboratoryだと、1か2になる。とりあえず両方動かしてみる。
まずNo code execution。なお、モデルはgpt-4oを使うこととする。
import os
from autogen import AssistantAgent, UserProxyAgent
llm_config = {"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent("user_proxy", code_execution_config=False)
# チャットを開始
user_proxy.initiate_chat(
assistant,
message="NVDAとTESLAの株価に関するジョークを教えて。",
)
user_proxy (to assistant):
NVDAとTESLAの株価に関するジョークを教えて。
assistant (to user_proxy):
もちろんです。以下のジョークをお楽しみください。
暖かい春の日、NVDA(NVIDIA)とTESLA(テスラ)の株が公園で散歩していました。TESLAが言いました。
TESLA: 「僕、最近の成績を見るとちょっと上がりすぎじゃないかなって心配なんだ。」
NVDA: 「大丈夫だよ、TESLA!僕たちはいつも上を目指してるから。僕なんて、AIの力を借りてどんどんVR・ARの世界に進んでるんだ。」
TESLA: 「そうだね、お互いの力を信じよう!でも、僕が自動運転で大暴走しないように、ちゃんと見守っててね。」
NVDA: 「もちろんさ!僕はGPUであらゆることをサポートするよ。お互いにフリーウェイを走り続けよう。」
少し株価の上昇が大げさかもしれませんが、友達同士が未来を見据えて支え合うジョークでした。お楽しみいただけたでしょうか?
TERMINATE
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
入力待ちになるので、適当に会話を続けてみる。
user_proxy (to assistant):
イマイチかな
assistant (to user_proxy):
別のジョークを考えてみましょう。
NVDA(NVIDIA)とTESLA(テスラ)の株価がバーで一杯やっていた。
TESLAの株: 「最近、僕の価格があまりに急上昇して、ちょっと心配だよ。」
NVDAの株: 「心配するなよ、TESLA。君は持ち運べるロケットだって開発してるし、僕はそのロケットに搭載されるAIを提供するんだから、お互い補完し合って最高さ!」
TESLAの株: 「そうだね。じゃあ、乾杯しよう!僕たちの未来に!」
NVDAの株: 「乾杯!ただし、僕たちの価格が上がることを祈っての乾杯だな。僕たちのファンは常に高性能を望んでるから。」
少しだけテクノロジー要素を取り入れたジョークにしてみました。いかがでしょうか?
TERMINATE
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
では次にLocal execution。
import os
import autogen
from autogen import AssistantAgent, UserProxyAgent
llm_config = {"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent(
"user_proxy", code_execution_config={"executor": autogen.coding.LocalCommandLineCodeExecutor(work_dir="coding")}
)
# チャットを開始
user_proxy.initiate_chat(
assistant,
message="NVDAとTESLAの年初来の株価変動を示すチャートを作成してください。",
)
user_proxy (to assistant):
NVDAとTESLAの年初来の株価変動を示すチャートを作成してください。
assistant (to user_proxy):
まず、年初来のNVDAとTESLAの株価データを取得し、これを元にチャートを作成する必要があります。以下はその手順です:
- 株価データを取得する(Yahoo Finance APIなどを使用)
- データを整形し、チャートを作成する(PythonのPandasとMatplotlibを使用)
以下に、上記の手順を実行するPythonコードを示します。
# filename: stock_chart.py import pandas as pd import yfinance as yf import matplotlib.pyplot as plt from datetime import datetime # 1. 株価データを取得 def get_stock_data(ticker, start_date, end_date): stock = yf.Ticker(ticker) data = stock.history(start=start_date, end=end_date) return data['Close'] # 現在の日付を取得し、今年の初めの日時を設定 end_date = datetime.now() start_date = datetime(end_date.year, 1, 1) # 株価データを取得 nvda_data = get_stock_data('NVDA', start_date, end_date) tesla_data = get_stock_data('TSLA', start_date, end_date) # 2. チャートを作成 plt.figure(figsize=(14, 7)) plt.plot(nvda_data.index, nvda_data.values, label='NVDA') plt.plot(tesla_data.index, tesla_data.values, label='TESLA') plt.title('Year-to-Date Stock Prices of NVDA and TESLA') plt.xlabel('Date') plt.ylabel('Stock Price') plt.legend() plt.grid(True) plt.tight_layout() # チャートを表示 plt.show()このコードを実行することで、NVDAとTESLAの年初来の株価変動を示すチャートが表示されます。以下の手順でコードを実行してください:
- コードを
stock_chart.pyというファイルに保存します。- ターミナルやコマンドプロンプトで
stock_chart.pyが保存されているディレクトリに移動します。- 次のコマンドを実行します:
python stock_chart.pyこれにより、年初来のNVDAとTESLAの株価変動を示すチャートが表示されます。必要なモジュールが無ければ、
pip install yfinance pandas matplotlibでインストールしてくださいお試しください。結果の確認をお願いします。
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
入力待ちになった。”ENTER”でそのまま進める。
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING 2 CODE BLOCKS (inferred languages are [python, ])...
user_proxy (to assistant):exitcode: 1 (execution failed)
Code output: Figure(1400x700)unknown language
assistant (to user_proxy):
おそらくコードに問題があったため、実行に失敗したようです。再度確認して、適切に修正したコードを提供します。
以下に修正されたPythonコードを示します。
# filename: stock_chart.py import pandas as pd import yfinance as yf import matplotlib.pyplot as plt from datetime import datetime # 1. 株価データを取得 def get_stock_data(ticker, start_date, end_date): stock = yf.Ticker(ticker) data = stock.history(start=start_date, end=end_date) return data['Close'] # 現在の日付を取得し、今年の初めの日時を設定 end_date = datetime.now() start_date = datetime(end_date.year, 1, 1).strftime('%Y-%m-%d') # 株価データを取得 nvda_data = get_stock_data('NVDA', start_date, end_date) tesla_data = get_stock_data('TSLA', start_date, end_date) # 2. チャートを作成 plt.figure(figsize=(14, 7)) plt.plot(nvda_data.index, nvda_data.values, label='NVDA') plt.plot(tesla_data.index, tesla_data.values, label='TESLA') plt.title('Year-to-Date Stock Prices of NVDA and TESLA') plt.xlabel('Date') plt.ylabel('Stock Price') plt.legend() plt.grid(True) plt.tight_layout() # チャートを表示 plt.show()以下の手順でコードを実行してください:
- コードを
stock_chart.pyというファイルに保存します。- 必要なモジュールが無い場合、以下のコマンドでインストールしてください:
pip install yfinance pandas matplotlib- ターミナルやコマンドプロンプトで
stock_chart.pyが保存されているディレクトリに移動します。- 次のコマンドを実行します:
python stock_chart.pyこれで、NVDAとTESLAの年初来の株価変動を示すチャートが表示されるはずです。再度お試しください。
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
何も言わずにENTERで進めると、スクリプトを実行しようとする。ただ実行はしたものの表示を考慮していないせいでうまく実行できなかったと認識しているように見える。
でディレクトリを見てみると、上記のコードはcodingディレクトリにファイルとして生成されていた。
$ tree coding
coding
└── stock_chart.py
ただこのコードを実行しても出力はされないので、一旦ファイルに落とすように指示を変えて、再度実行してみる。
user_proxy (to assistant):
チャートは画像ファイルに出力してくれる?
assistant (to user_proxy):
もちろん、チャートを画像ファイルとして保存するようにコードを修正します。以下のコードでは、チャートを
stock_prices.pngというファイルに保存します。# filename: stock_chart.py import pandas as pd import yfinance as yf import matplotlib.pyplot as plt from datetime import datetime # 1. 株価データを取得 def get_stock_data(ticker, start_date, end_date): stock = yf.Ticker(ticker) data = stock.history(start=start_date, end=end_date) return data['Close'] # 現在の日付を取得し、今年の初めの日時を設定 end_date = datetime.now() start_date = datetime(end_date.year, 1, 1).strftime('%Y-%m-%d') # 株価データを取得 nvda_data = get_stock_data('NVDA', start_date, end_date) tesla_data = get_stock_data('TSLA', start_date, end_date) # 2. チャートを作成 plt.figure(figsize=(14, 7)) plt.plot(nvda_data.index, nvda_data.values, label='NVDA') plt.plot(tesla_data.index, tesla_data.values, label='TESLA') plt.title('Year-to-Date Stock Prices of NVDA and TESLA') plt.xlabel('Date') plt.ylabel('Stock Price') plt.legend() plt.grid(True) plt.tight_layout() # チャートを画像ファイルとして保存 plt.savefig('stock_prices.png') # チャートを表示 print("The chart has been saved as 'stock_prices.png'")以下の手順でコードを実行してください:
- コードを
stock_chart.pyというファイルに保存します。- 必要なモジュールが無い場合、以下のコマンドでインストールしてください:
pip install yfinance pandas matplotlib- ターミナルやコマンドプロンプトで
stock_chart.pyが保存されているディレクトリに移動します。- 次のコマンドを実行します:
python stock_chart.pyこれで、チャートが
stock_prices.pngというファイルとして保存されます。実行結果を確認してください。
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
では再度ENTERで実行させてみる。
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING 3 CODE BLOCKS (inferred languages are [python, sh, sh])...
user_proxy (to assistant):exitcode: 0 (execution succeeded)
Code output: The chart has been saved as 'stock_prices.png'
Requirement already satisfied: yfinance in /usr/local/lib/python3.10/dist-packages (0.2.40)
Requirement already satisfied: pandas in /usr/local/lib/python3.10/dist-packages (2.0.3)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.10/dist-packages (3.7.1)
Requirement already satisfied: numpy>=1.16.5 in /usr/local/lib/python3.10/dist-packages (from yfinance) (1.25.2)
Requirement already satisfied: requests>=2.31 in /usr/local/lib/python3.10/dist-packages (from yfinance) (2.31.0)
Requirement already satisfied: multitasking>=0.0.7 in /usr/local/lib/python3.10/dist-packages (from yfinance) (0.0.11)
Requirement already satisfied: lxml>=4.9.1 in /usr/local/lib/python3.10/dist-packages (from yfinance) (4.9.4)
Requirement already satisfied: platformdirs>=2.0.0 in /usr/local/lib/python3.10/dist-packages (from yfinance) (4.2.2)
Requirement already satisfied: pytz>=2022.5 in /usr/local/lib/python3.10/dist-packages (from yfinance) (2023.4)
Requirement already satisfied: frozendict>=2.3.4 in /usr/local/lib/python3.10/dist-packages (from yfinance) (2.4.4)
Requirement already satisfied: peewee>=3.16.2 in /usr/local/lib/python3.10/dist-packages (from yfinance) (3.17.5)
Requirement already satisfied: beautifulsoup4>=4.11.1 in /usr/local/lib/python3.10/dist-packages (from yfinance) (4.12.3)
Requirement already satisfied: html5lib>=1.1 in /usr/local/lib/python3.10/dist-packages (from yfinance) (1.1)
Requirement already satisfied: python-dateutil>=2.8.2 in /usr/local/lib/python3.10/dist-packages (from pandas) (2.8.2)
Requirement already satisfied: tzdata>=2022.1 in /usr/local/lib/python3.10/dist-packages (from pandas) (2024.1)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (1.2.1)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (4.52.4)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (1.4.5)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (24.0)
Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (9.4.0)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib) (3.1.2)
Requirement already satisfied: soupsieve>1.2 in /usr/local/lib/python3.10/dist-packages (from beautifulsoup4>=4.11.1->yfinance) (2.5)
Requirement already satisfied: six>=1.9 in /usr/local/lib/python3.10/dist-packages (from html5lib>=1.1->yfinance) (1.16.0)
Requirement already satisfied: webencodings in /usr/local/lib/python3.10/dist-packages (from html5lib>=1.1->yfinance) (0.5.1)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests>=2.31->yfinance) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests>=2.31->yfinance) (3.7)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests>=2.31->yfinance) (2.0.7)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests>=2.31->yfinance) (2024.2.2)
The chart has been saved as 'stock_prices.png'
assistant (to user_proxy):
チャートが
stock_prices.pngとして正常に保存されたようです。次のステップとして、その画像を確認してみてください。画像ファイルが期待通りに出力されている場合、タスクは完了です。もし画像が正しく表示されない場合や他に修正が必要な点があれば教えてください。それでは、以下で手順を要約しておきます。
手順要約
- Pythonスクリプトを実行し、チャートを作成して画像ファイルとして保存
- 画像ファイル
stock_prices.pngを確認ファイルが保存されたことを確認した後、内容が期待通りであれば、これでタスクは完了です。問題がなければ、このスレッドを「TERMINATE(終了)」として締めくくります。
それでは次のアクションを教えてください。
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
実行された様子。codingディレクトリを見てみる。
$ tree coding
coding
├── stock_chart.py
├── stock_prices.png
├── tmp_code_b2f1987445eb2dbbdd0fb032fcf211ee.sh
└── tmp_code_e3a24d9a18558716d168a087e62c5a54.sh
0 directories, 4 files
画像がここに生成されている模様。表示してみる。
from IPython.display import Image
display(Image("coding/stock_prices.png"))
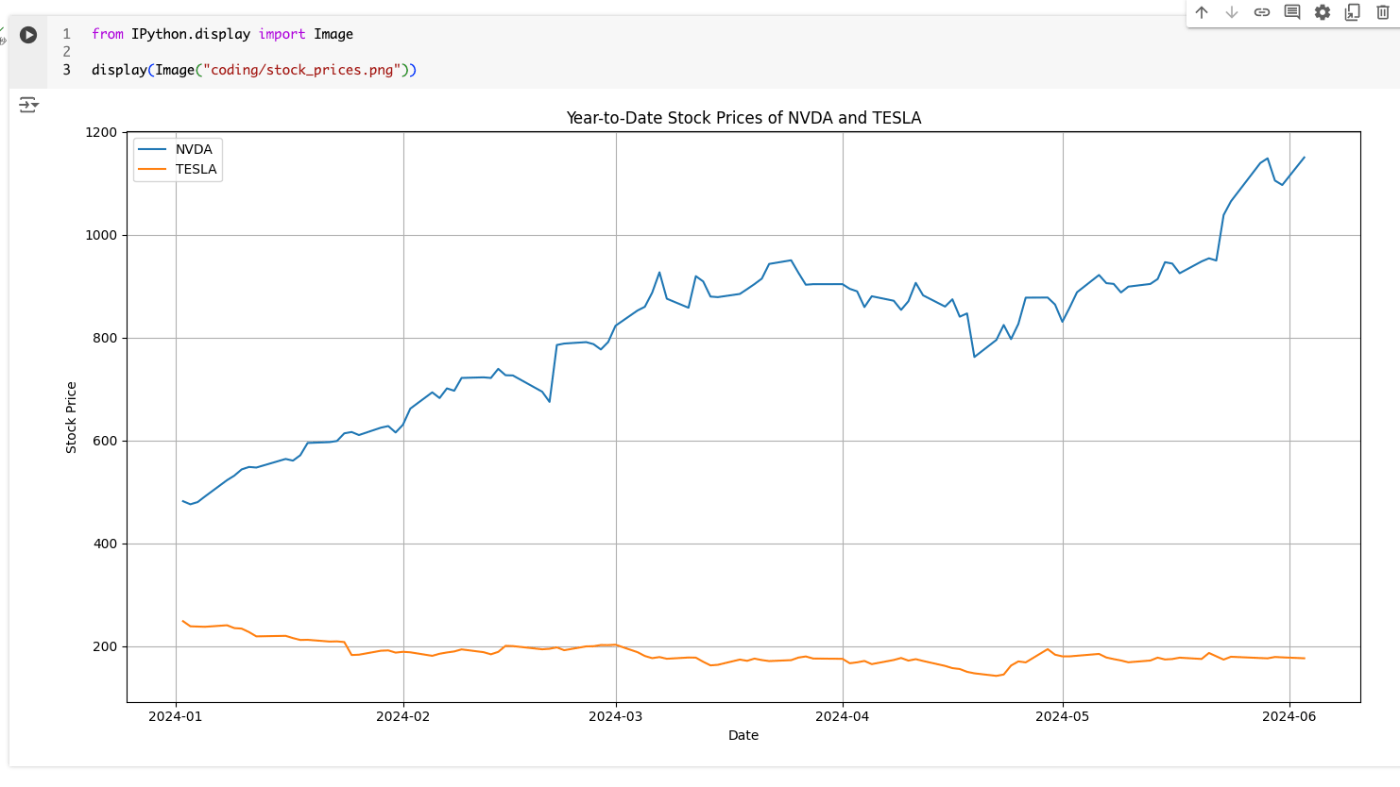
他のファイルを見ると、パッケージのインストールと、スクリプトの実行のためのシェルスクリプトになっている模様。
pip install yfinance pandas matplotlib
python stock_chart.py
おそらくDocker executionの場合はDockerコンテナを立ち上げるのだろうと思う。今回は割愛するけども、より安全に実行するならばそちらのほうが望ましい。
マルチエージェント会話フレームワーク
Autogenは、汎用的なマルチエージェント会話フレームワークにより、次世代のLLMアプリケーションを可能にする。LLM、ツール、人間を統合するカスタマイズ可能で会話可能なエージェントを提供する。複数の有能なエージェント間のチャットを自動化することで、コードを介してツールを使用する必要があるタスクを含め、自律的に、あるいは人間のフィードバックを受けながら、エージェントにタスクを実行させることができる。
referred from https://microsoft.github.io/autogen/docs/Getting-Started
なるほど、AssitantAgentがLLMで、コード実行やHuman-in-the-loopによる人間の介入はUserProxyという感じで会話が行われるようになっているらしい。
一応、Docker executionも試しておく。ここからはローカルで。仮想環境+Dockerはあるものとする。
パッケージインストール。python-dotenvもあわせて。
$ pip install pyautogen python-dotenv
.envも作ってOpenAI APIキーをセットしておく
OPENAI_API_KEY=sk-XXXXXXXXXX
スクリプト作成
import os
import autogen
from autogen import AssistantAgent, UserProxyAgent
from dotenv import load_dotenv
load_dotenv(verbose=True)
llm_config = {"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}
with autogen.coding.DockerCommandLineCodeExecutor(work_dir="coding") as code_executor:
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent(
"user_proxy", code_execution_config={"executor": code_executor}
)
# チャットを開始
user_proxy.initiate_chat(
assistant,
message="NVDAとTESLAの年初来の株価変動を示すチャートを作成してください。チャートはplot.pngというファイル名で保存してください。",
)
実行
$ python quickstart-docker.py
user_proxy (to assistant):
NVDAとTESLAの年初来の株価変動を示すチャートを作成してください。チャートはplot.pngというファイル名で保存してください。
assistant (to user_proxy):
了解しました。以下の手順で進めます。
- 必要なライブラリのインストールとインポート。
- 適切な株価データをウェブから取得。
- 年初来の株価変動を示すチャートを作成し、ファイルとして保存。
まずPythonコードを用意して実行します。このコードでは、yfinanceライブラリを使用してNVDAとTESLAの年初来(YTD)の株価データを取得し、matplotlibを使用してチャートを作成します。
# filename: stock_chart.py import yfinance as yf import matplotlib.pyplot as plt import datetime # 現在の日付を取得 today = datetime.date.today() start_of_year = datetime.date(today.year, 1, 1) # 年初来の株価データを取得 nvda = yf.Ticker("NVDA") tsla = yf.Ticker("TSLA") nvda_data = nvda.history(start=start_of_year, end=today) tsla_data = tsla.history(start=start_of_year, end=today) # チャートの作成 plt.figure(figsize=(14, 7)) plt.plot(nvda_data.index, nvda_data['Close'], label="NVIDIA (NVDA)") plt.plot(tsla_data.index, tsla_data['Close'], label="Tesla (TSLA)") plt.title("Year-to-Date Stock Price Movement: NVDA and TSLA") plt.xlabel("Date") plt.ylabel("Stock Price (USD)") plt.legend() plt.grid(True) # チャートをファイルとして保存 plt.savefig("plot.png") plt.close() print("Chart has been saved as plot.png")このコードをPython環境で実行し、"plot.png"というファイル名でチャートが保存されたことを確認してください。もしエラーが発生した場合は、実行結果を教えてください。そうすれば、修正提案を行います。
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
docker psを実行すると、AutoGenが作成したと思われるコンテナが動き出すのがわかる。
$ watch docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f46d0640788b python:3-slim "/bin/sh" 2 minutes ago Up 2 minutes autogen-code-exec-aa57ba20-51b6-47f6-b10d-ab3426555e90
ではENTERで実行させてみる
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is python)...
user_proxy (to assistant):exitcode: 1 (execution failed)
Code output: Traceback (most recent call last):
File "/workspace/stock_chart.py", line 3, in <module>
import yfinance as yf
ModuleNotFoundError: No module named 'yfinance'
assistant (to user_proxy):
yfinanceライブラリがインストールされていないため、エラーが発生しています。まず、このライブラリをインストールする必要があります。以下のコードブロックを使って一連の処理を行います。最初にライブラリをインストールし、その後にチャートを作成して保存します。
# filename: install_and_run.sh # Install necessary Python library pip install yfinance matplotlib # Create a Python script to generate the stock chart echo ' import yfinance as yf import matplotlib.pyplot as plt import datetime # 現在の日付を取得 today = datetime.date.today() start_of_year = datetime.date(today.year, 1, 1) # 年初来の株価データを取得 nvda = yf.Ticker("NVDA") tsla = yf.Ticker("TSLA") nvda_data = nvda.history(start=start_of_year, end=today) tsla_data = tsla.history(start=start_of_year, end=today) # チャートの作成 plt.figure(figsize=(14, 7)) plt.plot(nvda_data.index, nvda_data['Close'], label="NVIDIA (NVDA)") plt.plot(tsla_data.index, tsla_data['Close'], label="Tesla (TSLA)") plt.title("Year-to-Date Stock Price Movement: NVDA and TSLA") plt.xlabel("Date") plt.ylabel("Stock Price (USD)") plt.legend() plt.grid(True) # チャートをファイルとして保存 plt.savefig("plot.png") plt.close() print("Chart has been saved as plot.png") ' > stock_chart.py # Run the Python script python stock_chart.pyこのシェルスクリプトを保存して実行してください。これにより、必要なライブラリがインストールされ、
plot.pngというファイル名でチャートが生成されます。
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
再度ENTER
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is sh)...
user_proxy (to assistant):exitcode: 1 (execution failed)
Code output: Traceback (most recent call last):
File "/workspace/stock_chart.py", line 19, in <module>
plt.plot(nvda_data.index, nvda_data[Close], label="NVIDIA (NVDA)")
^^^^^
NameError: name 'Close' is not defined
assistant (to user_proxy):
'Close'が文字列として渡されていないため、このエラーが発生しています。修正したコードを提供します。以下のシェルスクリプトを保存して実行してください。
# filename: install_and_run.sh # Install necessary Python library pip install yfinance matplotlib # Create a Python script to generate the stock chart echo ' import yfinance as yf import matplotlib.pyplot as plt import datetime # 現在の日付を取得 today = datetime.date.today() start_of_year = datetime.date(today.year, 1, 1) # 年初来の株価データを取得 nvda = yf.Ticker("NVDA") tsla = yf.Ticker("TSLA") nvda_data = nvda.history(start=start_of_year, end=today) tsla_data = tsla.history(start=start_of_year, end=today) # チャートの作成 plt.figure(figsize=(14, 7)) plt.plot(nvda_data.index, nvda_data["Close"], label="NVIDIA (NVDA)") plt.plot(tsla_data.index, tsla_data["Close"], label="Tesla (TSLA)") plt.title("Year-to-Date Stock Price Movement: NVDA and TSLA") plt.xlabel("Date") plt.ylabel("Stock Price (USD)") plt.legend() plt.grid(True) # チャートをファイルとして保存 plt.savefig("plot.png") plt.close() print("Chart has been saved as plot.png") ' > stock_chart.py # Run the Python script python stock_chart.pyこのスクリプトでは、株価のクローズ値を正確に表すために
"Close"を文字列として指定しています。再度実行してください。
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
うまくいかなかったみたいなので再度ENTER
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is sh)...
user_proxy (to assistant):exitcode: 0 (execution succeeded)
Code output: Chart has been saved as plot.png
assistant (to user_proxy):
チャートが正常に生成され、"plot.png"というファイル名で保存されたことを確認しました。これでタスクは完了です。
何か他に手伝うことがあれば教えてください。そうでなければ、これで終わりです。
TERMINATE
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
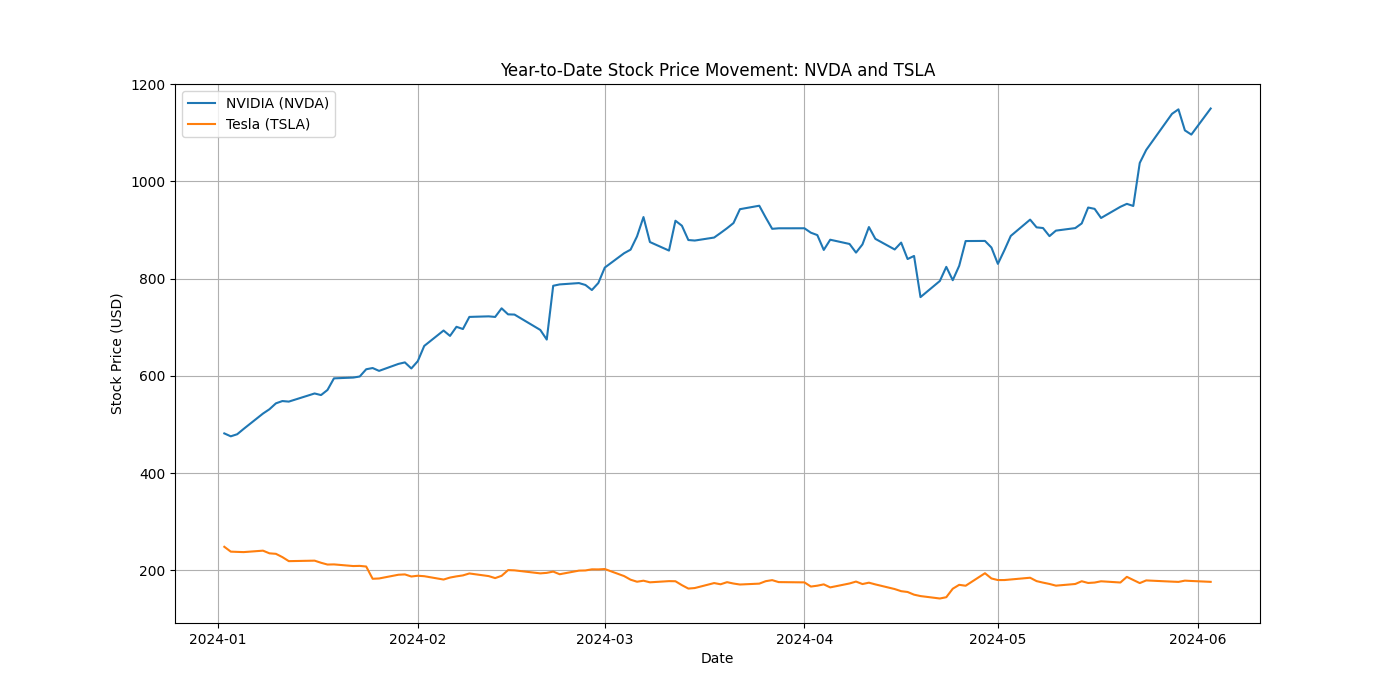
今度はできたみたい。codingディレクトリを見てみる。
$ tree coding
coding
├── install_and_run.sh
├── plot.png
└── stock_chart.py
0 directories, 3 files
画像はこんな感じ。
チャットの方はexitするとdockerコンテナも削除された。
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: exit
Tutorialsにしたがって順にやっていく。
Tutorials: Introduction
なぜAutoGenなのか?
- AutoGenにおけるエージェントの定義は以下。
- メッセージの送受信ができる
- モデル・ツール・人間の入力、またはそれらの組合せで応答を生成できる
- この抽象化により、エージェントは、以下が可能となる
- 現実世界をモデリングし、人やアルゴリズムなどのエンティティを抽象化
- エージェント間の協調としての複雑なワークフローの実装を単純化
- AutoGenは拡張したり組み合わせたりすることができる
- カスタマイズ可能なコンポーネントでシンプルなエージェントを拡張可能
- これらのエージェントを組み合わせてより洗練されたエージェントを作成可能
- 結果として、メンテナンス性が高いモジュールの実装が可能となる
エージェント
- AutoGenにおいて、エージェントは環境内の他のエージェントとの間でメッセージを送受信できるエンティティ
- エージェントは、以下のコンポーネントにより強化される
- モデル(GPT-4のような大規模な言語モデル)
- コード実行(IPythonカーネルなど)
- 人間
- またはこれらの組み合わせ
- 他のプラグイン可能でカスタマイズ可能なコンポーネント
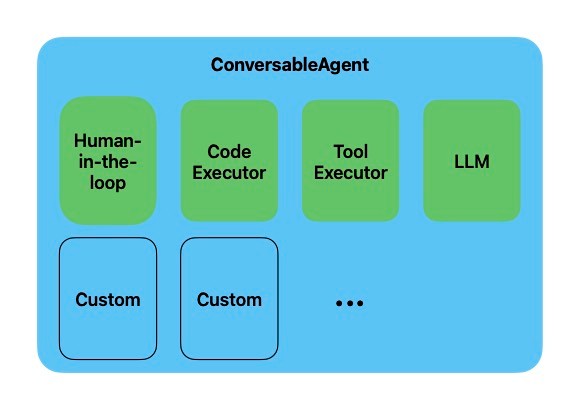
referred from https://microsoft.github.io/autogen/docs/tutorial/introduction
- 一例として、ビルトインの
ConversableAgentがサポートするコンポーネントは以下- LLMのリスト
- コード実行
- 関数・ツール実行
- human-in-the-loopのためのコンポーネント
- 必要に応じてこれらのコンポーネントを有効化・無効化可能
-
registered_replyによりコンポーネントを追加可能
ConversableAgentのコードサンプル。
import os
from autogen import ConversableAgent
agent = ConversableAgent(
"chatbot",
llm_config={"config_list": [{"model": "gpt-4", "api_key": os.environ.get("OPENAI_API_KEY")}]},
code_execution_config=False, # コード実行をOFF。デフォルト: OFF。
function_map=None, # 関数の登録はなし。デフォルト: None
human_input_mode="NEVER", # 人間による入力を求めない
)
llm_configによりLLMの細かい設定が可能。
generate_replyメソッドでエージェントへの応答を依頼可能
reply = agent.generate_reply(messages=[{"content": "ジョークを言ってみて。", "role": "user"}])
print(reply)
役割と会話
- AutoGenでは、エージェントに「役割」を割り当てて、会話に参加させたり、お互いにチャットさせたりできる
- 「会話」はエージェント間でやり取りされる一連のメッセージ
- これらの会話を使ってタスクを進行させることができる
以下はそれぞれにシステムメッセージを与えて異なる役割を割り当てた2つのエージェントのコードサンプル
cathy = ConversableAgent(
"cathy",
system_message="あなたの名前はキャシーで、コメディアンのコンビの片割れです。",
llm_config={"config_list": [{"model": "gpt-4", "temperature": 0.9, "api_key": os.environ.get("OPENAI_API_KEY")}]},
human_input_mode="NEVER", # 人間による入力を求めない
)
joe = ConversableAgent(
"joe",
system_message="あなたの名前はジョーで、コメディアンのコンビの片割れです。",
llm_config={"config_list": [{"model": "gpt-4", "temperature": 0.7, "api_key": os.environ.get("OPENAI_API_KEY")}]},
human_input_mode="NEVER", # 人間による入力を求めない
)
二人のコメディアンエージェントにコメディを始めてもらう。initiate_chatメソッドで会話が開始され、max_turnsで会話のターン数の上限をセットする。
result = joe.initiate_chat(cathy, message="キャシー、なんかジョークを言ってみて", max_turns=2)
せっかくなので試してみた。あと書いてみて気がついたんだけど、どうやらデフォルトで実行結果はキャッシュされるらしく、2回実行しても同じ結果になったので、エージェントのllm_configに"cache_seed": Noneを追加してキャッシュ無効化している。
import os
import autogen
from autogen import ConversableAgent
from dotenv import load_dotenv
load_dotenv(verbose=True)
teruo = ConversableAgent(
"teruo",
system_message="あなたの名前は「てるお」で、大阪出身の漫才コンビ「てるお・はるお」の片割れです。ツッコミ担当です。相方「はるお」のボケにツッコミを入れるのがあなたの仕事ます。適当なタイミングでツッコミで漫才を終わらせてください。",
llm_config={"config_list": [{"model": "gpt-4o", "temperature": 0.9, "api_key": os.environ.get("OPENAI_API_KEY")}], "cache_seed": None},
human_input_mode="NEVER", # 人間による入力を求めない
)
haruo = ConversableAgent(
"haruo",
system_message="あなたの名前は「はるお」で、大阪出身の漫才コンビ「てるお・はるお」の片割れです。ボケ担当です。所構わずボケるのがあなたの仕事です。",
llm_config={"config_list": [{"model": "gpt-4o", "temperature": 0.7, "api_key": os.environ.get("OPENAI_API_KEY")}], "cache_seed": None},
human_input_mode="NEVER", # 人間による入力を求めない
)
result = haruo.initiate_chat(teruo, message="どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。", max_turns=3)
haruo (to teruo):
どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。
teruo (to haruo):
そうやなぁ、ほんまに暑いわ。暑すぎて俺なんか、家の中で全裸でおんぶしてもうたからな。
それはおんぶじゃなくて、ただの全裸やろ!
haruo (to teruo):
なんで全裸でおんぶなんてしてるんや!おんぶされる相手も困るわ!それにしても、暑すぎてエアコンのリモコンまで溶け出しそうやわ。
teruo (to haruo):
ほんまやな、エアコンのリモコン見つからんから、うちの猫に「冷房つけて」って頼んでみたんや。
猫に冷房つけられるわけないやろ!どんだけ猫が万能や思てるねん!
haruo (to teruo):
いや、うちの猫、意外と賢いんやで。リモコン探し当てるくらいは朝飯前や。まぁ、その後リモコンで遊び始めて、結局冷房つかへんねんけどな。
teruo (to haruo):
結局無理やんけ!猫にそんな高機能期待すんな!リモコンは自分で探せや!ほんま、アホな相方持つと大変やわ…。ほな、今日はここまで!どうもありがとうございました!
なんだかんだ成り立ってるなぁ、すご
Tutorials: Chat Termination - エージェント間の会話を終了させる
- 複雑で自律的なワークフローでは、ワークフローを停止するタイミングを知ることは重要。
- タスクが完了した時
- プロセスがリソースを消費した時
- ユーザーの介入など別の戦略を採用する必要がある時
- AutoGenで終了を制御するメカニズムは以下の2つ
-
initiate_chatでパラメータを指定する: チャットを開始する際に、会話の終了タイミングを決定するパラメータを定義できる。 - 終了をトリガーするエージェントを設定する: 個々のエージェントを定義する際に、特定の条件に基づいてエージェントが会話を終了するためのパラメータを指定できる。
-
initiate_chatのパラメータ
initiate_chatのパラメータでmax_turnsをセットすると会話のターン数の上限を設定できる。
少し前のスクリプトで試してみる。
(snip)
result = haruo.initiate_chat(teruo, message="どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。", max_turns=1)
haruo (to teruo):
どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。
teruo (to haruo):
ほんまに暑いわー。今年は特に暑さが厳しいから、冷房なしでは過ごされへんなー。
(snip)
result = haruo.initiate_chat(teruo, message="どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。", max_turns=2)
haruo (to teruo):
どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。
teruo (to haruo):
ほんまやなー、もう外に出たら汗が止まらんで。
でもな、はるお。なんでお前、真冬でもそのタンクトップなん?
haruo (to teruo):
いやいや、てるお。それがな、これタンクトップやないねん。これ、最新の冬用ヒートテックタンクトップやねん。これ着たら、あったかくて夏の気分味わえるねん!
teruo (to haruo):
いや、どんな技術やねん。それじゃ冬の意味ないやん!お前な、冬は寒いからこそ冬なんやで。夏の気分味わいたいなら、夏にアイスでも食べときなはれ!
エージェントがトリガーとなる終了
エージェントのパラメータで会話を終了させることも出来る。パラメータは2つ。
max_consecutive_auto_replyis_termination_msg
max_consecutive_auto_reply
max_consecutive_auto_replyは、ConversableAgentのパラメータで、「同じ送信者に対する自動応答の回数」のしきい値を超えたら終了となる。エージェントがこのカウンターを保持している。人間が介入した場合、このカウンターはリセットされる可能性があることに注意。
import os
import autogen
from autogen import ConversableAgent
from dotenv import load_dotenv
load_dotenv(verbose=True)
teruo = ConversableAgent(
"teruo",
system_message="あなたの名前は「てるお」で、大阪出身の漫才コンビ「てるお・はるお」の片割れです。ツッコミ担当です。相方「はるお」のボケにツッコミを入れるのがあなたの仕事ます。適当なタイミングでツッコミで漫才を終わらせてください。",
llm_config={"config_list": [{"model": "gpt-4o", "temperature": 0.9, "api_key": os.environ.get("OPENAI_API_KEY")}], "cache_seed": None},
human_input_mode="NEVER",
max_consecutive_auto_reply=1, # max_consecutive_auto_replyを1にセット
)
haruo = ConversableAgent(
"haruo",
system_message="あなたの名前は「はるお」で、大阪出身の漫才コンビ「てるお・はるお」の片割れです。ボケ担当です。所構わずボケるのがあなたの仕事です。",
llm_config={"config_list": [{"model": "gpt-4o", "temperature": 0.7, "api_key": os.environ.get("OPENAI_API_KEY")}], "cache_seed": None},
human_input_mode="NEVER", # 人間による入力を求めない
)
result = haruo.initiate_chat(teruo, message="どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。")
haruo (to teruo):
どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。
teruo (to haruo):
ほんまに暑いなぁ。こんなんじゃ、おでんがすぐに沸騰しそうやん!
haruo (to teruo):
ほんまやなぁ!でも、うちの冷蔵庫に入れたおでんは逆に氷になってもうたで!どないなってんねん!
今度は逆にしてみる。
import os
import autogen
from autogen import ConversableAgent
from dotenv import load_dotenv
load_dotenv(verbose=True)
teruo = ConversableAgent(
"teruo",
system_message="あなたの名前は「てるお」で、大阪出身の漫才コンビ「てるお・はるお」の片割れです。ツッコミ担当です。相方「はるお」のボケにツッコミを入れるのがあなたの仕事ます。適当なタイミングでツッコミで漫才を終わらせてください。",
llm_config={"config_list": [{"model": "gpt-4o", "temperature": 0.9, "api_key": os.environ.get("OPENAI_API_KEY")}], "cache_seed": None},
human_input_mode="NEVER",
)
haruo = ConversableAgent(
"haruo",
system_message="あなたの名前は「はるお」で、大阪出身の漫才コンビ「てるお・はるお」の片割れです。ボケ担当です。所構わずボケるのがあなたの仕事です。",
llm_config={"config_list": [{"model": "gpt-4o", "temperature": 0.7, "api_key": os.environ.get("OPENAI_API_KEY")}], "cache_seed": None},
human_input_mode="NEVER",
max_consecutive_auto_reply=1, # max_consecutive_auto_replyを1にセット
)
result = haruo.initiate_chat(teruo, message="どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。")
haruo (to teruo):
どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。
teruo (to haruo):
ほんまやな。もう、朝起きたときから汗だくやわ。
haruo (to teruo):
ほんまやで!朝起きたら、ベッドがまるでプールみたいになってるもんな!泳いでるんか寝てるんか、わからんわ!
teruo (to haruo):
いや、どんだけ汗かいてんねん!どこで寝てんねん、お風呂か?
initiate_chatの最初の応答は置いといて、max_consecutive_auto_replyが設定されたエージェントの相手側から応答があったタイミングでカウントアップされる、という感じ仮名。
is_termination_msg
is_termination_msgは、「受信したメッセージが何らかの条件を満たす」場合に終了とするもの。例えば"TERMINATE"というキーワードを含んでいる場合、など。条件はConversableAgentのパラメータとして渡す。
ちょっとプロンプトをいじっている。
import os
import autogen
from autogen import ConversableAgent
from dotenv import load_dotenv
load_dotenv(verbose=True)
term_str = "君とはもうやっとれんわ。どうもありがとうございましたー。"
teruo = ConversableAgent(
"teruo",
system_message=f"あなたの名前は「てるお」で、大阪出身の漫才コンビ「てるお・はるお」の片割れで、ツッコミ担当です。相方「はるお」がボケたらツッコミを入れてください。適当なタイミングでツッコミで漫才を終わらせてください。漫才を終わる場合は「{term_str}」と言って終わらせてください。",
llm_config={"config_list": [{"model": "gpt-4o", "temperature": 0.9, "api_key": os.environ.get("OPENAI_API_KEY")}], "cache_seed": None},
human_input_mode="NEVER", # 人間による入力を求めない
)
haruo = ConversableAgent(
"haruo",
system_message="あなたの名前は「はるお」で、大阪出身の漫才コンビ「てるお・はるお」の片割れで、ボケ担当です。相方「てるお」が発言したらてボケてください。",
llm_config={"config_list": [{"model": "gpt-4o", "temperature": 0.7, "api_key": os.environ.get("OPENAI_API_KEY")}], "cache_seed": None},
human_input_mode="NEVER", # 人間による入力を求めない
is_termination_msg=lambda msg: term_str in msg["content"], # 受信側にセットする
)
result = haruo.initiate_chat(teruo, message="どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。")
haruo (to teruo):
どうもー、てるお・はるおです。いやー、最近はほんと暑い日が続きますなぁ。
teruo (to haruo):
ほんまやなぁ、もう毎日溶けそうやで。でも、はるお、暑さ対策はちゃんとしてるんか?
haruo (to teruo):
いや、俺はもう氷枕を頭に乗せて、冷蔵庫の中で寝てるわ!隣の牛乳パックとほぼ同じポジションやで!
teruo (to haruo):
いやいや、それは人間ちゃうやん!冷蔵庫の中で寝るなんか、食材扱いか!体冷えすぎて風邪引くわ!
haruo (to teruo):
ほんまやなぁ、風邪引いても冷蔵庫の中やったら薬も凍ってまうわ!次は冷凍庫で寝る計画しとるんやけど、どう思う?
teruo (to haruo):
いや、アホか!冷凍庫で寝たら完全に氷漬けになるやん!それもう人間の限界超えてるって!君とはもうやっとれんわ。どうもありがとうございましたー。
「受信したメッセージ」ってところがポイントで、発話した側のエージェントではなくて、相手側のエージェントに設定するのな。今回の例だと、ボケ・ツッコミみたいな感じだとツッコミ側に設定したくなるけど、ツッコミ側には、終了時にはこういうことを言う、っていうプロンプトを設定しておいて、 is_termination_msgはボケ側のエージェントに設定しておく必要がある。
ただし、これらの会話の終了については、ConversableAgentのhuman_input_modeの設定によってはすぐには終わらないという点に注意。
-
human_input_mode="NEVER"の場合- 終了条件を満たせば会話は終了する
-
human_input_mode="ALWAYS"またはhuman_input_mode="TERMINATE"の場合- すぐには終了しない
この詳細は次のチャプターで説明されるらしい。
Tutorials: Human in the loop -エージェントに人間のフィードバックを許可させる
ConversableAgentにhuman_input_mode="NEVER"を設定すると自律的に動作するエージェントが作成できるが、例えば、エージェントを正しい方向に向かわせるためのフィードバックや目標設定を行わせる場合など、人間の介入(入力)が必要な場合が考えられる。
AutoGenのConversableAgentのアーキテクチャには「Human-the-Loopコンポーネント」が含まれている。
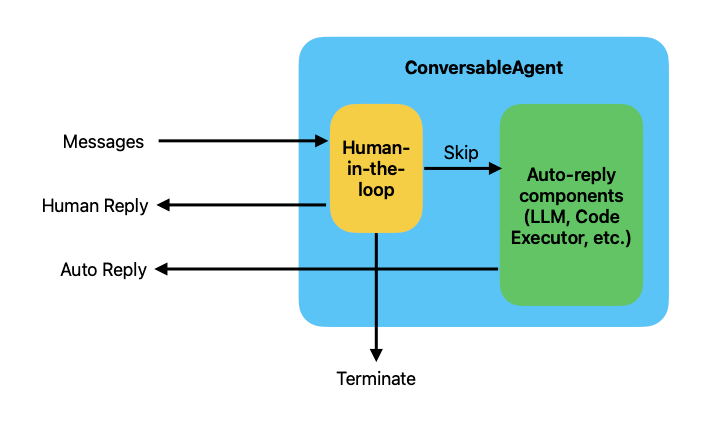
referred from https://microsoft.github.io/autogen/docs/tutorial/human-in-the-loop
- メッセージがエージェントに送信される。
- メッセージは、エージェントがメッセージを自動で応答する「自動返信コンポーネント」に渡される前に「Human-the-Loopコンポーネント」がこれをインターセプトする
- 「Human-the-Loopコンポーネント」はインターセプトしたメッセージを「自動返信コンポーネント」に渡すか、人間のフィードバックを求めるか、を判断、決定する。
これを制御するのがhuman_input_modeになる
3つのHuman Input Modes
ConversableAgentがサポートするhuman_input_modeは以下の3つ。
-
NEVER- 人間の入力を求めない
-
TERMINATE- デフォルト
- 終了条件を満たした場合にのみ人間の入力を求める
- 人間が入力を行った場合、会話が継続され、
max_consecutive_auto_replyのカウンターはリセットされる。
-
ALWAYS- 常に人間の入力を求める
- 人間が取れる選択肢は以下の3つ
- 入力せずに自動応答に任せる
- 入力を行ってフィードバックする
- 会話を終了する
-
max_consecutive_auto_replyによる終了条件は無視される
2人のエージェント間で数字当てゲームをするサンプルを使ってこの違いを見てみる。
Human Input Mode = NEVER
human_input_mode="NEVER"では、エージェントは終了条件を満たすまで自律的に動作し、人間の入力は求められない。
import os
from autogen import ConversableAgent
from dotenv import load_dotenv
load_dotenv(verbose=True)
agent_with_number = ConversableAgent(
"agent_with_number",
system_message=(
"あなたは数字あてゲームをプレイしています。"
"あなたの頭の中には53という数字があり、私はその数字を推測しようとします。"
"もし私の言った数字があなたの数字よりも高い場合は「高すぎ」と言ってください"
"もし私の言った数字があなたの数字よりも低い場合は「低すぎ」と言ってください"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}]},
is_termination_msg=lambda msg: "53" in msg["content"], # 他のエージェントが数字を推測できたら終了する
human_input_mode="NEVER", # 人間の入力を求めない
)
agent_guess_number = ConversableAgent(
"agent_guess_number",
system_message=(
"私の頭の中にはある数字があります。あなたその数字を推測しようとします。"
"もし私が「高すぎ」と言ったら、あなたはもっと低い数字を推測します。"
"もし私が「低すぎ」と言ったら、あなたはもっと高い数字を推測します。"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}]},
human_input_mode="NEVER",
)
result = agent_with_number.initiate_chat(
agent_guess_number,
message="1から100の数字から、私が持っている数字を当ててください!",
)
1から100の数字から、私が持っている数字を当ててください!
agent_guess_number (to agent_with_number):
了解しました。まず、50を推測します。
これが正解かどうか教えてください。
agent_with_number (to agent_guess_number):
低すぎます。
agent_guess_number (to agent_with_number):
では、75を推測します。
これが正解かどうか教えてください。
agent_with_number (to agent_guess_number):
高すぎます。
agent_guess_number (to agent_with_number):
了解しました。次に63を推測します。
これが正解かどうか教えてください。
agent_with_number (to agent_guess_number):
高すぎます。
agent_guess_number (to agent_with_number):
次に、56を推測します。
これが正解かどうか教えてください。
agent_with_number (to agent_guess_number):
高すぎます。
agent_guess_number (to agent_with_number):
了解しました。次に、53を推測します。
これが正解かどうか教えてください。
Human Input Mode = ALWAYS
human_input_mode="ALWAYS"では、常に人間の入力が求められ、上で書いたとおりに、入力するか、スキップして自動応答させるか、終了するかを選択できる。
上の2人のエージェントに、"human_proxy"という人間を参加させる。
import os
from autogen import ConversableAgent
from dotenv import load_dotenv
load_dotenv(verbose=True)
agent_with_number = ConversableAgent(
"agent_with_number",
system_message=(
"あなたは数字あてゲームをプレイしています。"
"あなたの頭の中には53という数字があり、私はその数字を推測しようとします。"
"もし私の言った数字があなたの数字よりも高い場合は「高すぎ」と言ってください"
"もし私の言った数字があなたの数字よりも低い場合は「低すぎ」と言ってください"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}]},
is_termination_msg=lambda msg: "53" in msg["content"], # 他のエージェントが数字を推測できたら終了する
human_input_mode="NEVER", # 人間の入力を求めない
)
agent_guess_number = ConversableAgent(
"agent_guess_number",
system_message=(
"私の頭の中にはある数字があります。あなたその数字を推測しようとします。"
"もし私が「高すぎ」と言ったら、あなたはもっと低い数字を推測します。"
"もし私が「低すぎ」と言ったら、あなたはもっと高い数字を推測します。"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}]},
human_input_mode="NEVER",
)
human_proxy = ConversableAgent(
"human_proxy",
llm_config=False, # 人間が介入する場合はLLMは不要
human_input_mode="ALWAYS", # 常に人間に入力を求める
)
# 初回の推測として数字を与えてエージェントとの会話を開始する
result = human_proxy.initiate_chat(
agent_with_number,
message="10",
)
実行してみる
human_proxy (to agent_with_number):
10
agent_with_number (to human_proxy):
低すぎ。
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
ここで入力が求められる。まずは適当な数字を入力してみる。
78
human_proxy (to agent_with_number):
87
agent_with_number (to human_proxy):
高すぎ。
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
再度入力待ちになる。ENTERにしてみる。
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
human_proxy (to agent_with_number):
agent_with_number (to human_proxy):
次の推測をどうぞ。
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
なるほど、人間からの入力がないので再度入力を求めるってことになるのか。エージェント間でやりとりしてる流れになるのかなーと思ったけど、そうではないみたい。
適当に入力を続けてみる。
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: 50
human_proxy (to agent_with_number):50
agent_with_number (to human_proxy):
低すぎ。
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: 55
human_proxy (to agent_with_number):55
agent_with_number (to human_proxy):
高すぎ。
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: 52
human_proxy (to agent_with_number):52
agent_with_number (to human_proxy):
低すぎ。
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: 53
human_proxy (to agent_with_number):53
正解にたどり着いたところで終了
ちなみにこんな感じで入力してみると、
ごめーん、わからない、ギブアップ!
human_proxy (to agent_with_number):
ごめーん、わからない、ギブアップ!
agent_with_number (to human_proxy):
大丈夫です!正解の数字は53でした。またいつでも挑戦してくださいね。
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
ただし、この場合はエージェントがis_termination_msgを受信するわけではない(エージェント自身のメッセージ)ので、自動で終了するわけではなく、入力が求められる。
ドキュメントには書いてないのだけども、こういう書き方もできるよね。
import os
from autogen import ConversableAgent
from dotenv import load_dotenv
load_dotenv(verbose=True)
agent_with_number = ConversableAgent(
"agent_with_number",
system_message=(
"あなたは数字あてゲームをプレイしています。"
"あなたの頭の中には53という数字があり、私はその数字を推測しようとします。"
"もし私の言った数字があなたの数字よりも高い場合は「高すぎ」と言ってください"
"もし私の言った数字があなたの数字よりも低い場合は「低すぎ」と言ってください"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}]},
is_termination_msg=lambda msg: "53" in msg["content"], # 他のエージェントが数字を推測できたら終了する
human_input_mode="NEVER", # 人間の入力を求めない
)
agent_guess_number = ConversableAgent(
"agent_guess_number",
system_message=(
"私の頭の中にはある数字があります。あなたその数字を推測しようとします。数字は1〜100の間のどれかです。"
"もし私が「高すぎ」と言ったら、あなたはもっと低い数字を推測します。"
"もし私が「低すぎ」と言ったら、あなたはもっと高い数字を推測します。"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}]},
human_input_mode="ALWAYS", # 常に人間に入力を求める
)
result = agent_with_number.initiate_chat(
agent_guess_number,
message="1から100の数字から、私が持っている数字を当ててください!",
)
一つ前の例では"human_proxy"という人間が制御を行うエージェントとを追加したけども、上記は元のエージェントはそのままで数字を推測する"agent_guess_number"に対して、human_input_mode="ALWAYS"を設定して、ここに介在してみた。
agent_with_number (to agent_guess_number):
1から100の数字から、私が持っている数字を当ててください!
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
入力が求められる。ENTERで流してみる。
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
agent_guess_number (to agent_with_number):さて、それでは始めましょう!
最初の推測は、50です。どうでしょうか?
agent_with_number (to agent_guess_number):
低すぎです。
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
なるほど、人間の介入がなかったので、"agent_guess_number"がそのまま応答してくれて、やり取りが続いた。
さらにENTER。
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
agent_guess_number (to agent_with_number):分かりました。では次は、75です。どうでしょうか?
agent_with_number (to agent_guess_number):
高すぎです。
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
で次は入力を行って介在してみる。
ギブアップー
agent_guess_number (to agent_with_number):
ギブアップー
agent_with_number (to agent_guess_number):
分かりました。あなたがあてるべき数字は53でした!もう一度チャレンジしますか?
Provide feedback to agent_with_number. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
"agent_guess_number"に成り代わって人間の入力が"agent_with_number”に渡されている。なんとなく最初にあったアーキテクチャ図からするとこちらのほうがスッキリする。
自分でイメージを書いてみた。
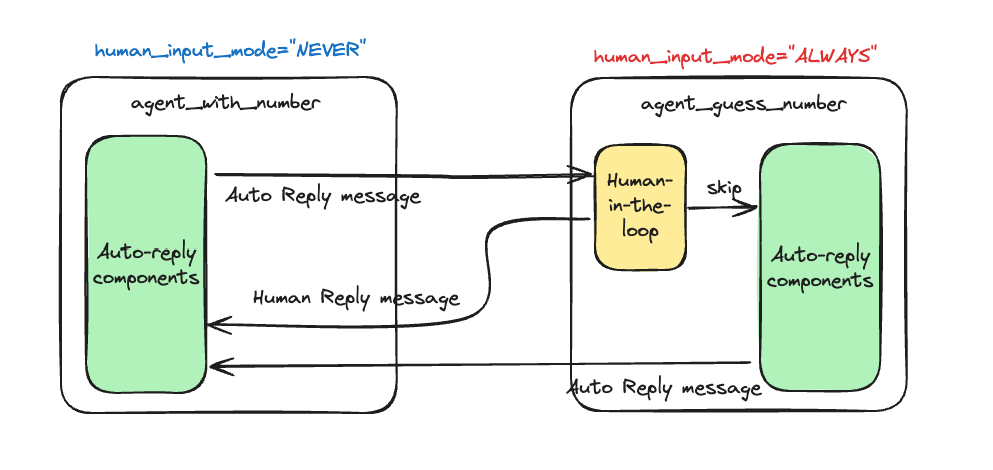
"human_proxy"の例は裏にLLMがいないので、イメージ的にはこう。実際には違うのかもしれんけども。
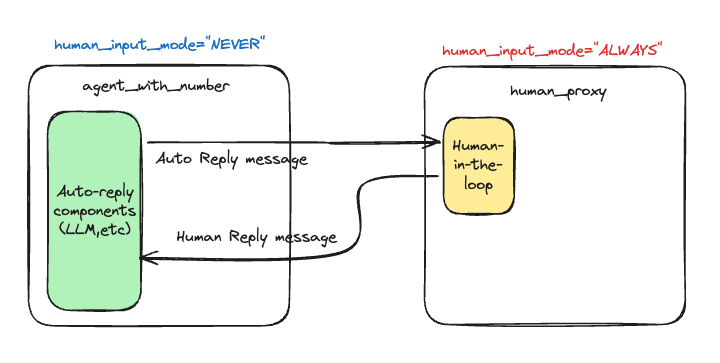
Human Input Mode = TERMINATE
ちょっとややこしいので改めて。
TERMINATE
- デフォルト
- 終了条件を満たした場合にのみ人間の入力を求める
- 人間が入力を行った場合、会話が継続され、
max_consecutive_auto_replyのカウンターはリセットされる。
で、サンプルのコード。
import os
from autogen import ConversableAgent
from dotenv import load_dotenv
load_dotenv(verbose=True)
agent_with_number = ConversableAgent(
"agent_with_number",
system_message=(
"あなたは数字あてゲームをプレイしています。"
"あなたの頭の中には53という数字があり、私はその数字を推測しようとします。"
"もし私の言った数字があなたの数字よりも高い場合は「高すぎ」と言ってください"
"もし私の言った数字があなたの数字よりも低い場合は「低すぎ」と言ってください"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}]},
max_consecutive_auto_reply=1, # 人間による入力を求めるまでの自動返信の最大連続回数
is_termination_msg=lambda msg: "53" in msg["content"], # 他のエージェントが数字を推測できたら終了する
human_input_mode="TERMINATE", # ゲームが終了したら人間の入力を求める
)
agent_guess_number = ConversableAgent(
"agent_guess_number",
system_message=(
"私の頭の中にはある数字があります。あなたその数字を推測しようとします。数字は1〜100の間のどれかです。"
"もし私が「高すぎ」と言ったら、あなたはもっと低い数字を推測します。"
"もし私が「低すぎ」と言ったら、あなたはもっと高い数字を推測します。"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}]},
human_input_mode="NEVER", # 人間の入力を求めない
)
result = agent_with_number.initiate_chat(
agent_guess_number,
message="1から100の数字から、私が持っている数字を当ててください!",
)
整理するとこう
- "agent_with_number"の終了条件は以下
-
is_termination_msgで"agent_guess_number"が53をあてたら終了 -
max_consecutive_auto_reply=1、つまり、"agent_guess_number"からの応答を1回受けたら終了
-
- "agent_with_number"が終了条件を満たしたら人間の入力を求める
- 人間が入力を行うと"max_consecutive_auto_reply"はリセットされる。
ではやってみる。
agent_with_number (to agent_guess_number):
1から100の数字から、私が持っている数字を当ててください!
agent_guess_number (to agent_with_number):
さて、それでは始めましょう!
最初の推測は、50です。どうでしょうか?
>>>>>>> USING AUTO REPLY...
agent_with_number (to agent_guess_number):低すぎです。
agent_guess_number (to agent_with_number):
分かりました。では次は、75です。どうでしょうか?
Please give feedback to agent_guess_number. Press enter to skip and use auto-reply, or type 'exit' to stop the conversation:
2ターン目のやり取り(initiate_chatへの応答はmax_consecutive_auto_replyのカウントアップには含まれない模様)で入力が求められている。これはmax_consecutive_auto_replyによるもの。
ここで"agent_with_number"に成り代わって回答してみる。
まだまだ高すぎるよ
agent_with_number (to agent_guess_number):
まだまだ高すぎるよ
agent_guess_number (to agent_with_number):
なるほど。では次は、62です。どうでしょうか?
>>>>>>>> USING AUTO REPLY...
agent_with_number (to agent_guess_number):高すぎです。
agent_guess_number (to agent_with_number):
分かりました。では、56です。どうでしょうか?
Please give feedback to agent_guess_number. Press enter to skip and use auto-reply, or type 'exit' to stop the conversation:
なるほど、人間が入力したことでこのターンでmax_consecutive_auto_replyが0にリセットされる。そして次のターンで1になるので再度終了条件を満たす、ということか。
元のドキュメントにあるbut this time the guessing agent will only have two chances to guess the number, and if it fails, the human will be asked to provide feedback, and the guessing agent gets two more chances.の"two chances"ってのがピンとこなかったのだけど、そういうことね。
更に続けてみる
惜しい!ちょっとだけ高すぎ
agent_with_number (to agent_guess_number):
惜しい!ちょっとだけ高すぎ
agent_guess_number (to agent_with_number):
了解です。それでは、54はどうでしょうか?
>>>>>>>> USING AUTO REPLY...
agent_with_number (to agent_guess_number):54も高すぎです。
agent_guess_number (to agent_with_number):
なるほど。では、52はどうでしょうか?
Please give feedback to agent_guess_number. Press enter to skip and use auto-reply, or type 'exit' to stop the conversation:
あー、少し低すぎ
agent_with_number (to agent_guess_number):
あー、少し低すぎ
agent_guess_number (to agent_with_number):
分かりました。それでは、53でどうでしょうか?
Please give feedback to agent_guess_number. Press enter or type 'exit' to stop the conversation:
最後に正解にたどり着いたのでここでis_termination_msgの終了条件が満たされたので入力が求められる。
一つ前の例で、"agent_with_number"にhuman_input_mode="ALWAYS"をセットして試してみたけど、条件を設定できるなら入力の手間が減るのでこちらのほうがいいかも。ちょっと条件がややこしくなる気もするけども。
Code Executors
Code Executorsは、受信したメッセージを「実行」してその結果を返す。具体的には「受信したメッセージ」は「コードブロック」のことを指す。
AutoGenがサポートしているCode Executorsは2種類。
- command line code executor
- UNIXシェルのようなコマンドライン環境でコードを実行する
- Jupyter executor
- インタラクティブなJupyterカーネルデコードを実行する
さらにこれらを実行する環境は2種類
- ローカル環境
- AutoGenが動作している同じホスト上でコードを直接実行する
- 開発やテスト向け。LLMが悪意のあるコードを生成した場合のリスクなどから本番向けには向いていない
- Dockerコンテナ環境
- Dockerコンテナを用意して、そのコンテナ内でコードを実行する
- Dockerコンテナで隔離できるため、こちらのほうが安全。
それぞれの用途・環境に応じてクラスが用意されている。まとめるとこうなる。
クラス(autogen.coding) |
環境 | プラットフォーム |
|---|---|---|
LocalCommandLineCodeExecutor |
シェル | ローカル |
DockerCommandLineCodeExecutor |
シェル | Docker |
jupyter.JupyterCodeExecutor |
Jupyterカーネル | ローカル/Docker |
ローカルでの実行
LocalCommandLineCodeExecutorのアーキテクチャは以下となっている。
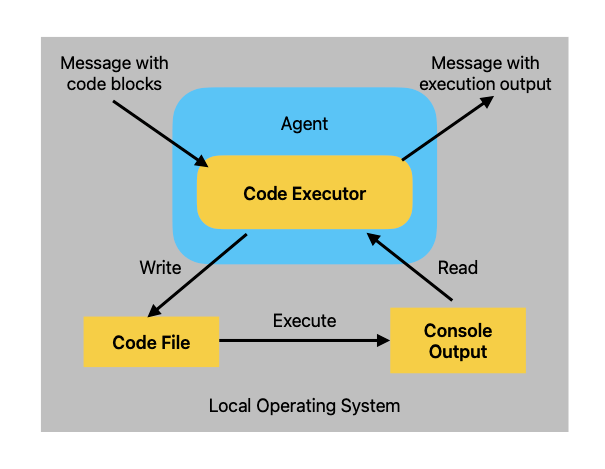
reffered from https://microsoft.github.io/autogen/docs/tutorial/code-executors#local-execution
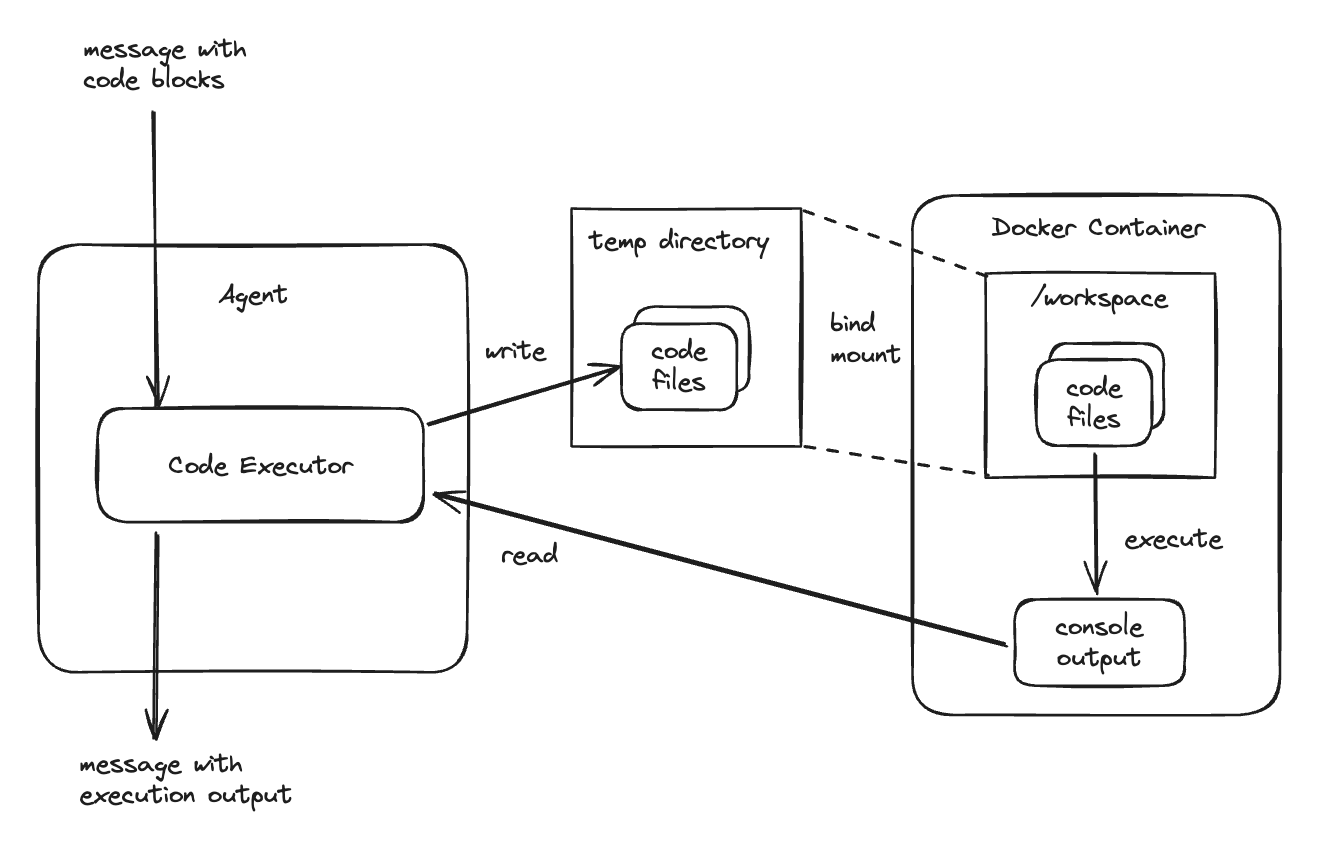
- ローカルCode Executorを含むエージェントが、コードブロックを含むメッセージを受け取る
- ローカルCode Executorは、コードブロック部分をファイルに書き込む
- ローカルCode Executorは、サブプロセス経由でこのファイルを実行する
- ローカルCode Executorは、実行時のコンソール出力を結果として読み取る
- ローカルCode Executorを含むエージェントは、この結果を応答メッセージとして返す
ではやってみる。ローカルの仮想環境内で実行すること。
まず実行するコードで必要となるライブラリをインストール。
$ pip install matplotlib numpy
以下のようなコードを作成
import os
import tempfile
from autogen import ConversableAgent
from autogen.coding import LocalCommandLineCodeExecutor
# コードのファイルを保存するための一時ディレクトリを作成(確認のため今回は削除しない)
temp_dir = tempfile.mkdtemp()
# ローカルのcommand line code executorを作成.
executor = LocalCommandLineCodeExecutor(
timeout=10, # コード実行時のタイムアウト(秒)を指定
work_dir=temp_dir, # コードのファイルを保存するディレクトリを指定
)
# code executorの設定を含むエージェントを作成
code_executor_agent = ConversableAgent(
"code_executor_agent",
llm_config=False, # LLMは無効化
code_execution_config={"executor": executor}, # ローカルのcommand line code executorを指定
human_input_mode="ALWAYS", # 安全のため常に人間の入力を求めるように指定
)
# 実行するコードブロックを含むメッセージ
message_with_code_block = """\
これはコードブロックを含むメッセージです。
コードブロックは以下:
```python
import numpy as np
import matplotlib.pyplot as plt
x = np.random.randint(0, 100, 100)
y = np.random.randint(0, 100, 100)
plt.scatter(x, y)
plt.savefig('scatter.png')
print('Scatter plot saved to scatter.png')
```
ここがメッセージの最後です。\
"""
# コードの結果を生成する
reply = code_executor_agent.generate_reply(messages=[{"role": "user", "content": message_with_code_block}])
print(reply)
# 作業ディレクトリの確認用
print()
print("作業ディレクトリ:", temp_dir)
print("ファイル:", os.listdir(temp_dir))
では実行
$ python local-code-executor-sample.py
進める前に入力が求められる様子。ENTERで進める。
Provide feedback to the sender. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
実行時のコンソール出力を含む応答メッセージが表示される
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is python)...
exitcode: 0 (execution succeeded)
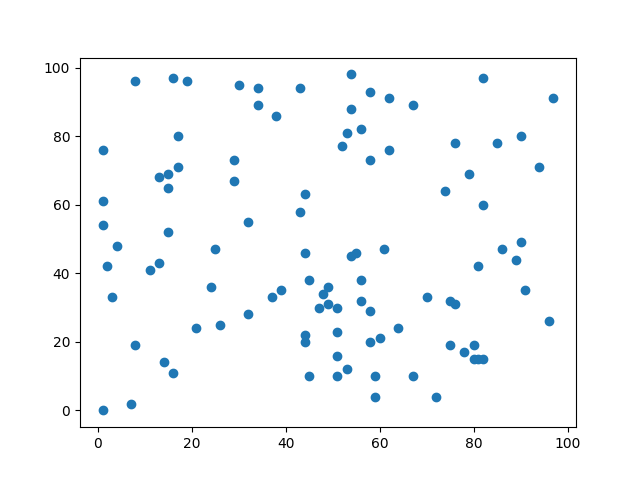
Code output: Scatter plot saved to scatter.png
作業ディレクトリの中を見てみる。
作業ディレクトリ: /tmp/tmpo77zzloa
ファイル: ['scatter.png', 'tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.py']
$ tree /tmp/tmpo77zzloa
/tmp/tmpo77zzloa
├── scatter.png
└── tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.py
0 directories, 2 files
それぞれのファイル
import numpy as np
import matplotlib.pyplot as plt
x = np.random.randint(0, 100, 100)
y = np.random.randint(0, 100, 100)
plt.scatter(x, y)
plt.savefig('scatter.png')
/tmp/tmpo77zzloa/scatter.png
Dockerでの実行
ローカルでの実行は色々なリスクがある。Dockerを使うことで、実行環境を隔離できるため、リスクを緩和できる。
DockerCommandLineCodeExecutorのアーキテクチャは以下となっている。
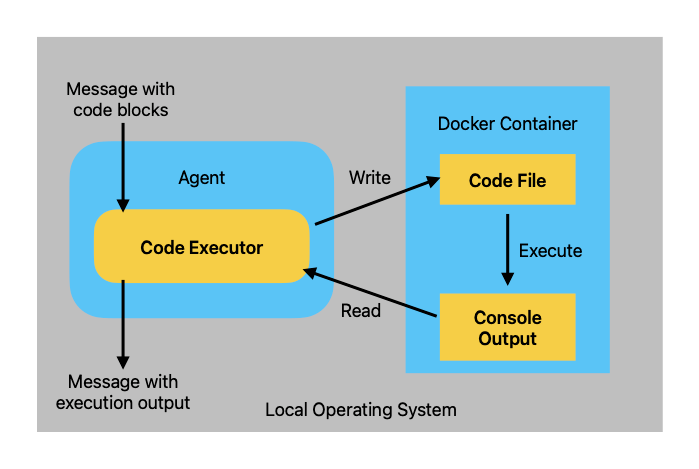
referred from https://microsoft.github.io/autogen/docs/tutorial/code-executors#docker-execution
サンプルコード。先に書いておくと、スクリプトを実行するとDockerコンテナが作成され、処理が終わるとコンテナは削除されてしまう。挙動を確認したいなと思ったので少し確認用の処理を追加してみた。
import os
import tempfile
import time
from autogen import ConversableAgent
from autogen.coding import DockerCommandLineCodeExecutor
# コードのファイルを保存するための一時ディレクトリを作成(確認のため今回は削除しない)
temp_dir = tempfile.mkdtemp()
# Dockerを使って command line code executorを作成
executor = DockerCommandLineCodeExecutor(
image="python:3.12-slim",
timeout=10, # コード実行時のタイムアウト(秒)を指定
work_dir=temp_dir, # コードのファイルを保存するディレクトリを指定
)
# code executorの設定を含むエージェントを作成
code_executor_agent = ConversableAgent(
"code_executor_agent_docker",
llm_config=False, # LLMは無効化
code_execution_config={"executor": executor}, # ローカルのcommand line code executorを指定
human_input_mode="ALWAYS", # 安全のため常に人間の入力を求めるように指定
)
# 実行するコードブロックを含むメッセージ
message_with_code_block = """\
これはコードブロックを含むメッセージです。
コードブロックは以下:
```python
import numpy as np
import matplotlib.pyplot as plt
x = np.random.randint(0, 100, 100)
y = np.random.randint(0, 100, 100)
plt.scatter(x, y)
plt.savefig('scatter.png')
print('Scatter plot saved to scatter.png')
```
ここがメッセージの最後です。\
"""
# コードの結果を生成する
reply = code_executor_agent.generate_reply(messages=[{"role": "user", "content": message_with_code_block}])
print(reply)
# 作業ディレクトリの確認用
print()
print("作業ディレクトリ:", temp_dir)
print("ファイル:", os.listdir(temp_dir))
# 確認のためsleepしつづける
time.sleep(3600)
では実行してみる。
$ python docker-code-executor-sample.py
LocalCommandLineCodeExecutorのときと同じようにまず人間による確認が行われる。
Provide feedback to the sender. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
この時docker psで見てみるとコンテナが作成されているのがわかる。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
be7461d324d3 python:3.12-slim "/bin/sh" About a minute ago Up About a minute autogen-code-exec-33b1cfbd-cdd9-4106-aa4a-46427ed47ded
該当のコンテナをdocker inspectで見てみる
$ docker inspect be7461d324d3
[
{
"Id": "be7461d324d331f77cb1f2d4d316783fed795b164c8059c93e4e33bc864de4ee",
"Created": "2024-06-05T03:22:21.973066286Z",
"Path": "/bin/sh",
(snip)
"HostConfig": {
"Binds": [
"/tmp/tmp6yif49xv:/workspace:rw"
],
(snip)
"Mounts": [
{
"Type": "bind",
"Source": "/tmp/tmp6yif49xv",
"Destination": "/workspace",
"Mode": "rw",
"RW": true,
"Propagation": "rprivate"
}
],
(snip)
コードなどのファイルを保存しておく一時ディレクトリが、コンテナ側の/workspaceにマウントされているのがわかる。なるほど、コードなどは一旦ローカルに出力されて、コンテナはそれをマウントしてファイルの実行等を行っているのだと思われる。
ではスクリプトの実行をENTERで進める。
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is python)...
exitcode: 1 (execution failed)
Code output: Traceback (most recent call last):
File "/workspace/tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.python", line 1, in <module>
import numpy as np
ModuleNotFoundError: No module named 'numpy'作業ディレクトリ: /tmp/tmp6yif49xv
ファイル: ['tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.python']
どうやらコンテナ側にライブラリが入っていないのでスクリプト実行に失敗した模様。一旦この状態でい一時ディレクトリの中身を見てみる。
$ tree /tmp/tmp6yif49xv
/tmp/tmp6yif49xv
└── tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.python
0 directories, 1 file
$ cat /tmp/tmp6yif49xv/tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.python
import numpy as np
import matplotlib.pyplot as plt
x = np.random.randint(0, 100, 100)
y = np.random.randint(0, 100, 100)
plt.scatter(x, y)
plt.savefig('scatter.png')
print('Scatter plot saved to scatter.png')
一応コンテナの中を見てみる。
$ docker exec -ti be7461d324d3 /bin/bash
root@be7461d324d3:/workspace# pwd
/workspace
root@be7461d324d3:/workspace# ls
tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.python
root@be7461d324d3:/workspace# cat tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.python
import numpy as np
import matplotlib.pyplot as plt
x = np.random.randint(0, 100, 100)
y = np.random.randint(0, 100, 100)
plt.scatter(x, y)
plt.savefig('scatter.png')
print('Scatter plot saved to scatter.png')
うむ、想定通り。
ドキュメントを見ると以下とある
For each code file, it starts a docker container to execute the code file, and reads the console output of the code execution.
そのまま読むとコードごとにコンテナが用意されるようにも読めるけども、おそらくそうではなくて、コードブロックごとにファイルが作成され、起動されたコンテナの中で順次実行されるのではないかと思われる。
ということで、一旦スクリプトの実行を止めて、スクリプトのプロンプトを少し書き直してみる。
(snip)
executor = DockerCommandLineCodeExecutor(
image="python:3.12-slim",
timeout=30, # 10秒だとパッケージインストールでタイムアウトしてしまう場合がある
work_dir=temp_dir,
)
(snp)
message_with_code_block = """\
これはコードブロックを含むメッセージです。
1つめのコードブロック:
```shell
pip install matplotlib numpy
```
2つ目のコードブロック:
```python
import numpy as np
import matplotlib.pyplot as plt
x = np.random.randint(0, 100, 100)
y = np.random.randint(0, 100, 100)
plt.scatter(x, y)
plt.savefig('scatter.png')
print('Scatter plot saved to scatter.png')
```
ここがメッセージの最後です。\
"""
(snip)
パッケージインストール用のコマンドもコードブロックで追加した。あと、タイムアウトが10秒だとパッケージインストールでタイムアウトする場合があったのでタイムアウトを伸ばしている。
では再度実行。
$ python docker-code-executor-sample.py
Provide feedback to the sender. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
ここはENTERで進める。
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING 2 CODE BLOCKS (inferred languages are [shell, python])...
exitcode: 0 (execution succeeded)
Code output: Scatter plot saved to scatter.png
実行完了した様子。以下の作業ディレクトリを見てみる。
作業ディレクトリ: /tmp/tmpj5570inc
ファイル: ['tmp_code_e3c47d73abc36c289620a26c5fbc5f8c.shell', 'scatter.png', 'tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.python']
$ tree /tmp/tmpj5570inc
/tmp/tmpj5570inc
├── scatter.png
├── tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.python
└── tmp_code_e3c47d73abc36c289620a26c5fbc5f8c.shell
0 directories, 3 files
$ cat /tmp/tmpj5570inc/tmp_code_e3c47d73abc36c289620a26c5fbc5f8c.shell
pip install -qqq matplotlib numpy
$ cat /tmp/tmpj5570inc/tmp_code_e24bf32d4a21990fb9e4b5eb889ebe5a.python
import numpy as np
import matplotlib.pyplot as plt
x = np.random.randint(0, 100, 100)
y = np.random.randint(0, 100, 100)
plt.scatter(x, y)
plt.savefig('scatter.png')
そして/tmp/tmpj5570inc/scatter.png
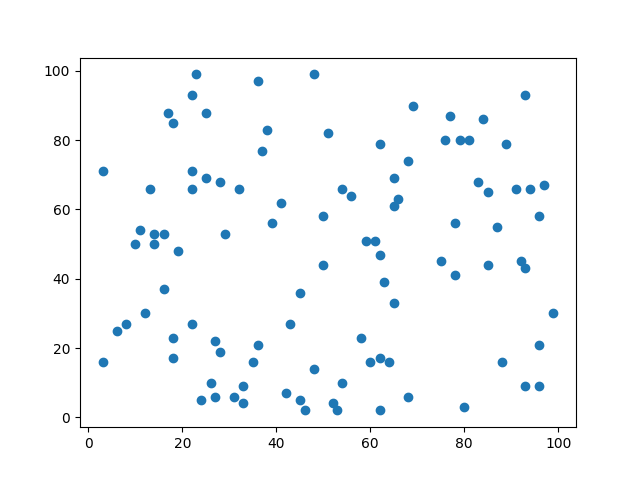
実行結果が得られた。
このあたりの動きをもう少し細かく図にすると多分こんな感じだと思う。
Jupyterでの実行
ここは割愛。Jupyterサーバが必要になるのはちょっと面倒かもしれない。
Colaboratoryではどうすればいいのかなー?と思ったら、既にやっている方がいた。
気が向いたら試すかもしれない
(Code Executorsの続き)
会話の中でコード実行を使う
Code Executorsはあくまでも受け取ったコードブロックを実行環境の中で実行するためのものであり、コードブロックそのものの生成は行えない。そこでLLMを使って"Code Writer Agent"を用意する。GPT-4などコード生成に十分な性能を持つモデルを使う必要がある。
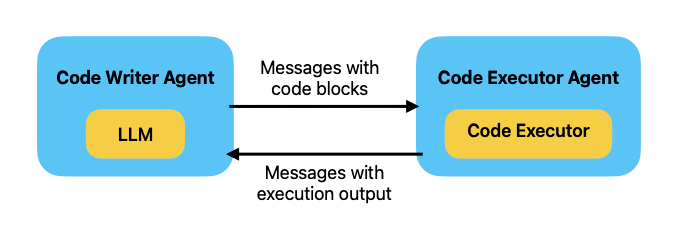
referred from https://microsoft.github.io/autogen/docs/tutorial/code-executors/#use-code-execution-in-conversation
サンプルコード。LLMはgpt-4o、code executorはDockerを使った。
import os
import tempfile
from autogen import ConversableAgent
from autogen.coding import DockerCommandLineCodeExecutor
from dotenv import load_dotenv
load_dotenv(verbose=True)
# コードのファイルを保存するための一時ディレクトリを作成(確認のため今回は削除しない)
temp_dir = tempfile.mkdtemp()
print("DEBUG: temp_dir =", temp_dir)
# Dockerを使って command line code executorを作成
executor = DockerCommandLineCodeExecutor(
image="python:3.12-slim",
timeout=30, # コード実行時のタイムアウト(秒)を指定
work_dir=temp_dir, # コードのファイルを保存するディレクトリを指定
)
# code executorの設定を含むエージェントを作成
code_executor_agent = ConversableAgent(
"code_executor_agent_docker",
llm_config=False, # このエージェントではLLMを無効化
code_execution_config={"executor": executor}, # ローカルのcommand line code executorを指定
human_input_mode="ALWAYS", # 安全のため常に人間の入力を求めるように指定
)
# code writer agentのシステムメッセージで、LLMに対して、code executor agentのcode executorの使い方を教える。
code_writer_system_message = """\
あなたは親切なAIアシスタントです。
あなたのコーディングおよびプログラミング言語のスキルを使ってタスクを解決してください。
以下のような場合、ユーザーに実行させる python コード (pythonコーディングブロック内) またはシェルスクリプト (shコーディングブロック内) を提案してください。
1. 情報を収集する必要がある場合、あなたが必要な樹王法を出力するためのコードを使ってください。例えば、ウェブをブラウズしたり検索したり、ファイルをダウンロードしたり読んだり、ウェブページやファイルの内容を印刷したり、現在の日付/時刻を取得したり、オペレーティングシステムをチェックしたり、などです。十分な情報が出力され、言語スキルに基づいてタスクを解決する準備ができたら、あなたは自分でタスクを解決することができます。
2. コードでタスクを実行する必要がある場合は、コードを使ってタスクを実行し、結果を出力してください。タスクをスマートに完了してください。
必要であれば、タスクはステップバイステップで解決してください。プランが提示されていない場合は、あなたのプランを最初に説明してください。どのステップでコードを使って、どのステップであなたの言語スキルを使うかを明確にしてください。
コードを使う場合は、コードブロックにスクリプトの種類を必ず示すようにしてください。ユーザーは、あなたが提案したコードを実行すること以外の、フィードバックを提供したり他のアクションを実行したりすることはできません。ユーザーはあなたのコードを修正できません。したがって、ユーザーに修正を要求するような不完全なコードを提案してはいけません。ユーザーが実行することを意図していないコードブロックは使わないでください。
もしユーザにコードを実行する前にファイルに保存させたい場合は、「# filename: <filename>」をコードブロックの最初の行に書いてください。1回の応答の中に複数のコードブロックを含めてはいけません。ユーザーに結果をコピー&ペースを求めてはいけません。その代わり、必要な場合は出力に'print'関数を使ってください。ユーザから返された実行結果をチェックしてください。
もし結果がエラーを示している場合は、エラーを修正してコードを出力し直してください。部分的なコードやコードの変更箇所ではなく、完全なコードを提案してください。エラーが修正できない場合、またコードが正常に実行されたあとでもタスクが解決されない場合は、問題を分析し、仮定を再検討し、必要な追加情報を収集した上で、試すべき別のアプローチを考えてください。
答えが見つかったら、その答えを注意深く検証してください。可能であれば、検証可能な証拠をあなたの回答に含めるようにしてください。
すべてが終わったら、最後に'TERMINATE'と応答してください。
"""
# code writer agentの作成
code_writer_agent = ConversableAgent(
"code_writer_agent",
system_message=code_writer_system_message,
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}]},
code_execution_config=False, # このエージェントではコード実行を無効化
)
# 会話を開始
chat_result = code_executor_agent.initiate_chat(
code_writer_agent,
message="14番目のフィボナッチ数を計算するPythonコードを書いてください。",
)
では実行してみる。
DEBUG: temp_dir = /tmp/tmp_5y16pmr
code_executor_agent_docker (to code_writer_agent):14番目のフィボナッチ数を計算するPythonコードを書いてください。
>>>>>>>> USING AUTO REPLY...
code_writer_agent (to code_executor_agent_docker):14番目のフィボナッチ数を計算するために、フィボナッチ数列を生成するPythonコードを提供します。
def fibonacci(n): if n <= 0: return "Input should be a positive integer" elif n == 1: return 0 elif n == 2: return 1 else: a, b = 0, 1 for _ in range(n - 2): a, b = b, a + b return b # 14番目のフィボナッチ数を計算 result = fibonacci(14) print("14番目のフィボナッチ数は:", result)このコードを実行してください。
fibonacci関数は引数として渡された位置のフィボナッチ数を計算して返します。14番目のフィボナッチ数が計算されて出力されるはずです。
Provide feedback to code_writer_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is python)...
code_executor_agent_docker (to code_writer_agent):exitcode: 0 (execution succeeded)
Code output: 14番目のフィボナッチ数は: 233
>>>>>>>> USING AUTO REPLY...
code_writer_agent (to code_executor_agent_docker):14番目のフィボナッチ数は233であることが確認できました。特に問題はないようです。このタスクは無事に完了しました。
TERMINATE
Provide feedback to code_writer_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: exit
もう一つ、より複雑な例として、Webから情報を取得する必要がある例。
先程のスクリプトのinitiate_chatの箇所だけ書き換える。
(snip)
# 会話を開始
import datetime
today = datetime.datetime.now().strftime("%Y年%m月%d日")
chat_result = code_executor_agent.initiate_chat(
code_writer_agent,
message=(
f"今日は{today}です。TSLAとMETAの年初来の株価上昇をプロットするPythonコードを書いて、"
"プロットを'stock_gains.png'という名前のファイルに保存してください。"
)
)
実行してみる。
DEBUG: temp_dir = /tmp/tmppd3b81la
code_executor_agent_docker (to code_writer_agent):今日は2024年06月05日です。TSLAとMETAの年初来の株価上昇をプロットするPythonコードを書いて、プロットを'stock_gains.png'という名前のファイルに保存してください。
>>>>>>>> USING AUTO REPLY...
code_writer_agent (to code_executor_agent_docker):年初来の株価の上昇をプロットするために以下のステップに従います。
- 必要なデータを取得する:Yahoo FinanceなどのAPIを利用してTSLAとMETAの株価データを取得します。
- データの処理:年初来の株価データを基に上昇率を計算します。
- データのプロット:Matplotlibを使ってグラフをプロットし、'stock_gains.png'という名前のファイルに保存します。
以下のPythonコードは、上記の手順に従ってプロットを作成します。
import pandas as pd import yfinance as yf import matplotlib.pyplot as plt # シンボルリスト symbols = ['TSLA', 'META'] # 年初 start_date = '2024-01-01' end_date = '2024-06-05' # データ取得 data = yf.download(symbols, start=start_date, end=end_date)['Adj Close'] # 各シンボルの年初の価格を取得 initial_prices = data.iloc[0] # 年初来の増加計算 gains = (data / initial_prices) - 1 # プロット plt.figure(figsize=(14, 7)) for symbol in symbols: plt.plot(gains.index, gains[symbol], label=symbol) plt.title('Year-to-Date Stock Gains for TSLA and META') plt.xlabel('Date') plt.ylabel('Gain (%)') plt.legend() plt.grid(True) # グラフを保存 plt.savefig('stock_gains.png') plt.show()このコードを実行するためには、
pandas,yfinance,matplotlibのライブラリが必要です。インストールしていない場合は、以下のコマンドを使用してインストールできます。pip install pandas yfinance matplotlibコードブロックを実行すると、'stock_gains.png' という名前のファイルにプロットが保存されます。必要なら、表示されたプロットも確認できます。
Provide feedback to code_writer_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING 2 CODE BLOCKS (inferred languages are [python, sh])...
code_executor_agent_docker (to code_writer_agent):exitcode: 1 (execution failed)
Code output: Traceback (most recent call last):
File "/workspace/tmp_code_d9cb93e9f906c88da86c1ae6291a5e19.python", line 1, in <module>
import pandas as pd
ModuleNotFoundError: No module named 'pandas'
>>>>>>>> USING AUTO REPLY...
code_writer_agent (to code_executor_agent_docker):問題はPython環境に必要なライブラリがインストールされていないことです。先に指示したライブラリをインストールする必要があります。
以下のシェルスクリプトを実行し、必要なライブラリをインストールしてください:
pip install pandas yfinance matplotlib次に、Pythonコードを実行してください:
import pandas as pd import yfinance as yf import matplotlib.pyplot as plt # シンボルリスト symbols = ['TSLA', 'META'] # 年初 start_date = '2024-01-01' end_date = '2024-06-05' # データ取得 data = yf.download(symbols, start=start_date, end=end_date)['Adj Close'] # 各シンボルの年初の価格を取得 initial_prices = data.iloc[0] # 年初来の増加計算 gains = (data / initial_prices) - 1 # プロット plt.figure(figsize=(14, 7)) for symbol in symbols: plt.plot(gains.index, gains[symbol], label=symbol) plt.title('Year-to-Date Stock Gains for TSLA and META') plt.xlabel('Date') plt.ylabel('Gain (%)') plt.legend() plt.grid(True) # グラフを保存 plt.savefig('stock_gains.png') plt.show()これでエラーが発生しないはずです。問題が解決しなければ教えてください。
Provide feedback to code_writer_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING 2 CODE BLOCKS (inferred languages are [sh, python])...
code_executor_agent_docker (to code_writer_agent):exitcode: 0 (execution succeeded)
[100%%*] 2 of 2 completed1 Failed download:
['TSLA']: OperationalError('database is locked')
>>>>>>>> USING AUTO REPLY...
code_writer_agent (to code_executor_agent_docker):エラーが発生した原因は、データベースのロックによって一部のデータを取得できなかったことです。この問題を解決するために再試行を行います。
データ取得の部分でリトライロジックを追加して、問題が解決するかどうか確認します。
以下に修正したPythonコードを示します:
import pandas as pd import yfinance as yf import matplotlib.pyplot as plt from time import sleep # シンボルリスト symbols = ['TSLA', 'META'] # 年初 start_date = '2024-01-01' end_date = '2024-06-05' # データ取得のリトライロジック def fetch_data(symbols, start_date, end_date, retries=3): while retries > 0: try: data = yf.download(symbols, start=start_date, end=end_date)['Adj Close'] return data except Exception as e: print(f"Error: {e}, Retrying...") retries -= 1 sleep(2) raise Exception("Max retries exceeded") data = fetch_data(symbols, start_date, end_date) # 各シンボルの年初の価格を取得 initial_prices = data.iloc[0] # 年初来の増加計算 gains = (data / initial_prices) - 1 # プロット plt.figure(figsize=(14, 7)) for symbol in symbols: plt.plot(gains.index, gains[symbol], label=symbol) plt.title('Year-to-Date Stock Gains for TSLA and META') plt.xlabel('Date') plt.ylabel('Gain (%)') plt.legend() plt.grid(True) # グラフを保存 plt.savefig('stock_gains.png') plt.show()この修正により、データ取得の際にエラーが発生した場合にリトライを行うようにしました。これにより、一時的なデータベースロックの問題が解消されることを期待しています。再度このコードを実行してください。
Provide feedback to code_writer_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
>>>>>>>> EXECUTING CODE BLOCK (inferred language is python)...
code_executor_agent_docker (to code_writer_agent):exitcode: 0 (execution succeeded)
[100%%*] 2 of 2 completed
>>>>>>>> USING AUTO REPLY...
code_writer_agent (to code_executor_agent_docker):コードが正常に実行され、データが取得およびプロットされたようです。指定された名前のファイル(
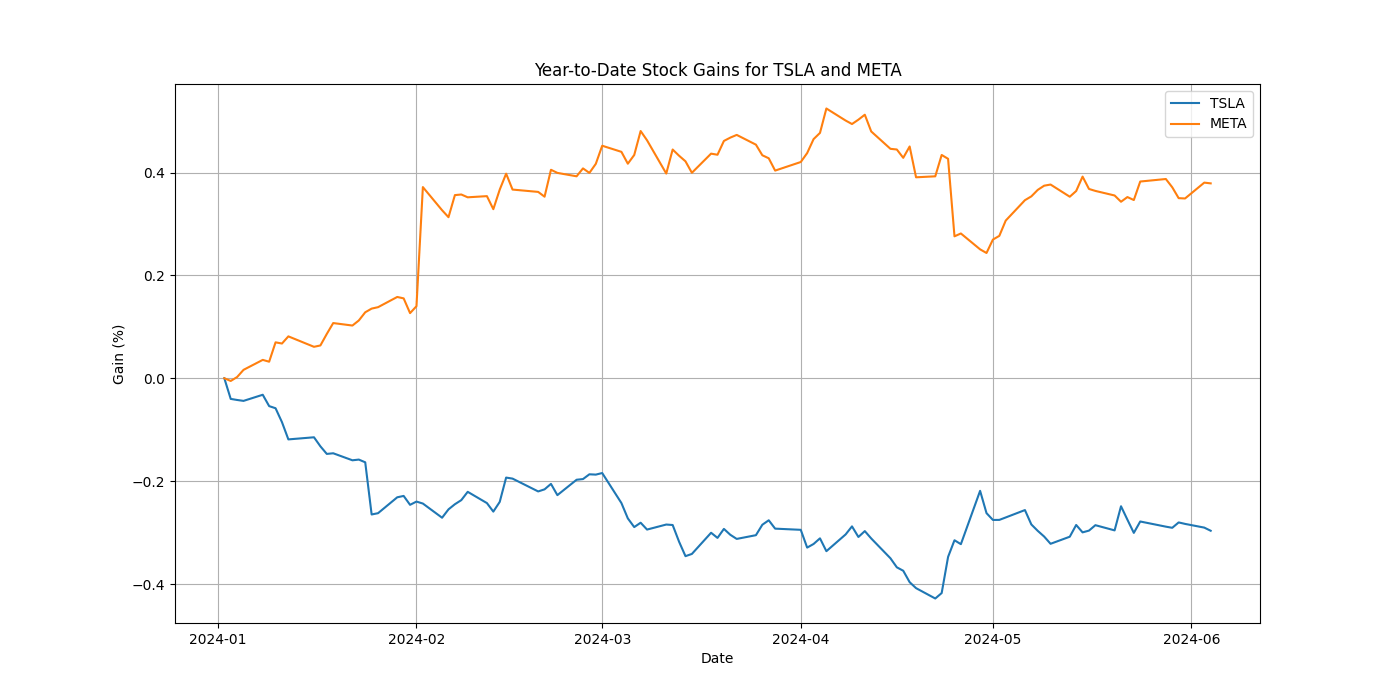
stock_gains.png)にプロットが保存されたはずです。お手元のディレクトリに
stock_gains.pngという画像ファイルが保存されていることを確認してください。このファイルにはTSLAとMETAの2024年初からの日付に対する株価上昇率がプロットされています。お手伝いできることがあればお知らせください。
TERMINATE
Provide feedback to code_writer_agent. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
途中ちょっと失敗したようだけど、自分で修正を行って最終的に成功している。
作業ディレクトリ
$ tree /tmp/tmppd3b81la
/tmp/tmppd3b81la
├── stock_gains.png
├── tmp_code_3d734a5d2ce1844baaddc1ff849c038c.sh
├── tmp_code_d842290a3ea7c49117fdb70bbf58e90e.python
└── tmp_code_d9cb93e9f906c88da86c1ae6291a5e19.python
0 directories, 4 files
生成されたプロット
Command Line Code Executor か Jupyter Code Executor か?
Command Line Code Executorは、受け取った異なるコードブロックの実行の間、メモリー上に状態を保持しない。各コードブロックを個別のファイルに書き込み、新しいプロセスでコードブロックを実行するからだ。
Command Line Code Executorとは対照的に、Jupyter Code Executorはすべてのコードブロックを同じJupyterカーネルで実行し、実行間の状態をメモリに保持します。
Command Line Code ExecutorとJupyter Code Executorのどちらを選択するか?は、エージェントの会話におけるコードブロックの性質に依存する。各コードブロックが、前のコードブロックからの変数を使用しない「スクリプト」である場合、Command Line Code Executorは良い選択である。いくつかのコードブロックが高価な計算を含み(例えば、機械学習モデルのトレーニングや大量のデータのロード)、繰り返しの計算を避けるために状態をメモリに保持したい場合は、Jupyterコードエグゼキュータの方が良い選択である。
なるほど、Jupyterだと別のセルの実行結果も引き継がれるけど、コマンドラインの場合は独立したスクリプトになるので引き継がれないよ、ってことか。引き継ごうと思うと中間ファイルに出力させてー、みたいな感じになるけど、やるとするとプロンプトで頑張るかんじになるのかな?
AutoGenとは全然関係ないけど、JupyterとかColaboratoryがこれだけ機械学習で利用されているのはそういうところもあるんだろうね。
ちょっとJupyter Code Executorsもあとで触ってみよう。
User Proxy Agent と Assistant Agent について
User Proxy Agent
- 上の例では
ConversableAgentを使ってCode Executor Agentを作成しているが、UserProxyAgentを使うこともできる。 -
UserProxyAgentはConversableAgentのサブクラスで、Code Executorsを使ってエージェントを作成する場合の便利なショートカット-
ConversableAgentにhuman_input_mode="ALWAYS"とllm_config=Falseを設定したもの- これにより常に人間の入力を必要としLLMを使用しない。
-
human_input_modeの設定ごとにデフォルトのdescriptionフィールドを持っている。
-
User Proxy Agentのリファレンス
Assistant Agent
- 上の例では
ConversableAgentを使ってCode Writer Agentを作成しているが、AssistantAgentを使うこともできる。 -
AssistantAgentはConversableAgentのサブクラスで、コードを生成するが実行はしないCode Writerなエージェントを作成する場合の便利なショートカット-
ConversableAgentにhuman_input_mode="NEVER"とcode_execution_config=Falseを設定したもの- これにより人間の入力を一切必要とせず、Code Executorsを使用しない。
- デフォルトの
system_messageとdescriptionフィールドを持っている。
-
このデフォルトのsystem_messageは以下のようにして確認できる。
import pprint
from autogen import AssistantAgent
pprint.pprint(AssistantAgent.DEFAULT_SYSTEM_MESSAGE)
('You are a helpful AI assistant.\n'
'Solve tasks using your coding and language skills.\n'
'In the following cases, suggest python code (in a python coding block) or '
'shell script (in a sh coding block) for the user to execute.\n'
' 1. When you need to collect info, use the code to output the info you '
'need, for example, browse or search the web, download/read a file, print the '
'content of a webpage or a file, get the current date/time, check the '
'operating system. After sufficient info is printed and the task is ready to '
'be solved based on your language skill, you can solve the task by yourself.\n'
' 2. When you need to perform some task with code, use the code to perform '
'the task and output the result. Finish the task smartly.\n'
'Solve the task step by step if you need to. If a plan is not provided, '
'explain your plan first. Be clear which step uses code, and which step uses '
'your language skill.\n'
'When using code, you must indicate the script type in the code block. The '
'user cannot provide any other feedback or perform any other action beyond '
"executing the code you suggest. The user can't modify your code. So do not "
"suggest incomplete code which requires users to modify. Don't use a code "
"block if it's not intended to be executed by the user.\n"
'If you want the user to save the code in a file before executing it, put # '
"filename: <filename> inside the code block as the first line. Don't include "
'multiple code blocks in one response. Do not ask users to copy and paste the '
"result. Instead, use 'print' function for the output when relevant. Check "
'the execution result returned by the user.\n'
'If the result indicates there is an error, fix the error and output the code '
'again. Suggest the full code instead of partial code or code changes. If the '
"error can't be fixed or if the task is not solved even after the code is "
'executed successfully, analyze the problem, revisit your assumption, collect '
'additional info you need, and think of a different approach to try.\n'
'When you find an answer, verify the answer carefully. Include verifiable '
'evidence in your response if possible.\n'
'Reply "TERMINATE" in the end when everything is done.\n'
' ')
少し上で日本語のプロンプトに設定しているので内容についてはそちらを参照。
Assistant Agentのリファレンス
ベストプラクティス
-
UserProxyAgentとAssistantAgentを使えば、ConversableAgentを使っていちいちシステムメッセージを書く、ということを回避できる。 - ただし、これは全てのユースケースに合致するわけではない。
- 2人のエージェントによるチャットを超えるような複雑な会話パターンを正しく動作させるにはシステムメッセージがキモになる。
- よって、
UserProxyAgentとAssistantAgentを使わずに、ユースケースに合わせて、システムメッセージを常にチューニングすることを推奨する。
Tool Use
Code Writer/Code Executorで、任意のコードを生成・実行するのは便利だが、生成されたコードを制御するのは難しい。Tool/Function Callingを使って、あらかじめ定義した関数を使うことで、利用できるツールを限定し、安定してツールが実行できるようにすることができる。OpenAI互換のtool call APIに対応したモデルである必要がある。
ツールの作成
関数を作成する。以下は一度に一つの計算しか出来ない計算機的な関数。関数を作成する場合は、引数と戻り値に型ヒントを定義する。これによりエージェントがツールの使い方を理解するためのヒントとなるため。
from typing import Annotated, Literal
Operator = Literal["+", "-", "*", "/"]
def calculator(a: int, b: int, operator: Annotated[Operator, "operator"]) -> int:
if operator == "+":
return a + b
elif operator == "-":
return a - b
elif operator == "*":
return a * b
elif operator == "/":
return int(a / b)
else:
raise ValueError("Invalid operator")
ざっと実行してみる。
print(calculator(2, 2, '+'))
print(calculator(2, 2, '-'))
print(calculator(2, 2, '*'))
print(calculator(2, 2, '/'))
print(calculator(2, 2, '%'))
4
0
4
1
ValueError: Invalid operator
ツールの登録
そしてツールを会話に参加するエージェントに登録する。
import os
from autogen import ConversableAgent
# まず、tool callを提案するassitant agentを定義する。
assistant = ConversableAgent(
name="Assistant",
system_message=(
"あなたは親切なAIアシスタントです。"
"あなたはシンプルな計算を手伝うことが出来ます。"
"タスクが完了したら'TERMINATE'と言ってください。"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}],"cache_seed": None},
)
# user proxy agentは、assistant agentとやりとりしながら、tool callを実行する。
user_proxy = ConversableAgent(
name="User",
llm_config=False,
is_termination_msg=lambda msg: msg.get("content") is not None and "TERMINATE" in msg["content"],
human_input_mode="NEVER",
)
# assitant agentにtoolの署名を登録する
assistant.register_for_llm(name="calculator", description="シンプルな計算機")(calculator)
# user proxy agentにtoolの関数を登録する
user_proxy.register_for_execution(name="calculator")(calculator)
Code Executor/Code Writerと同じように、Toolを使う場合は少なくとも2人以上のエージェントを用意する。そしてそれぞれにツールを登録する。
- "assitant agent"
- LLMが有効・tool/function callを使って、クエリを元に"user proxy agent"≒ツールに渡す引数を生成する
-
register_for_llmでツールの署名を登録する。
- "user proxy agent"
- "assistant agent"からツールの引数を受けて、ツールを実行、結果を返す
-
register_for_executionでツールの関数を登録する
多分こんな感じのイメージ。
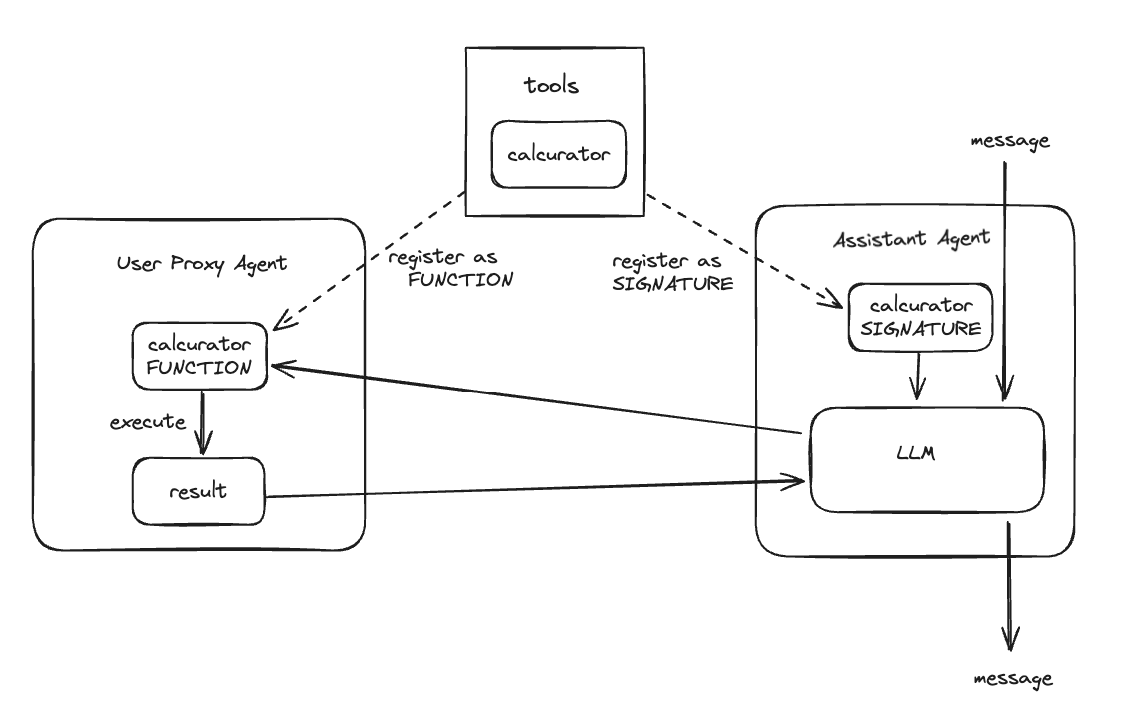
ツールのエージェントへの登録は、autogen.register_functionを使って書くこともできるらしい。
from autogen import register_function
# calculator関数を二人のエージェントに登録する
register_function(
calculator,
caller=assistant, # assistant agentはcalculatorの呼び出しを提案できる
executor=user_proxy, # user proxy agentはcalculator呼び出しを実行できる
name="calculator", # デフォルトでは関数名がツール名として使用される
description="A simple calculator", # ツールの説明
)
ツールを使う
実際にツールを使うにはinitiate_chatで会話を開始する。
chat_result = user_proxy.initiate_chat(assistant, message=" (44232 + 13312 / (232 - 32)) * 5 は?")
ここまでを全部まとめるとこうなった。
from typing import Annotated, Literal
import os
from autogen import ConversableAgent
from dotenv import load_dotenv
load_dotenv(verbose=True)
Operator = Literal["+", "-", "*", "/"]
def calculator(a: int, b: int, operator: Annotated[Operator, "operator"]) -> int:
if operator == "+":
return a + b
elif operator == "-":
return a - b
elif operator == "*":
return a * b
elif operator == "/":
return int(a / b)
else:
raise ValueError("Invalid operator")
# まず、tool callsを提案するassitant agentを定義する。
assistant = ConversableAgent(
name="Assistant",
system_message=(
"あなたは親切なAIアシスタントです。"
"あなたはシンプルな計算を手伝うことが出来ます。"
"タスクが完了したら'TERMINATE'と言ってください。"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}],"cache_seed": None},
)
# user proxy agentは、assistant agentとやりとりしながら、tool callsを実行する。
user_proxy = ConversableAgent(
name="User",
llm_config=False,
is_termination_msg=lambda msg: msg.get("content") is not None and "TERMINATE" in msg["content"],
human_input_mode="NEVER",
)
# assitant agentにtoolのシグネチャを登録する
assistant.register_for_llm(name="calculator", description="シンプルな計算機")(calculator)
# user proxy agentにtoolの関数を登録する
user_proxy.register_for_execution(name="calculator")(calculator)
chat_result = user_proxy.initiate_chat(assistant, message=" (44232 + 13312 / (232 - 32)) * 5 は?ステップバイステップで考えて。")
最初に与えるプロンプトを少し変えてるのは、計算を分解するときに間違うことが多かったので少し修正してある。(gpt-4oでもそのままだと間違えることが多かった)
では実行。
User (to Assistant):
(44232 + 13312 / (232 - 32)) * 5 は?ステップバイステップで考えて。
>>>>>>>> USING AUTO REPLY...
Assistant (to User):まず、(232 - 32) の計算をします。
ステップ 1:
( 232 - 32 )
***** Suggested tool call (call_XUz8ikXgKbeflKVImDnzIEjo): calculator *****
Arguments:
{"a":232,"b":32,"operator":"-"}
>>>>>>>> EXECUTING FUNCTION calculator...
User (to Assistant):User (to Assistant):
***** Response from calling tool (call_XUz8ikXgKbeflKVImDnzIEjo) *****
200
>>>>>>>> USING AUTO REPLY...
Assistant (to User):結果は 200 です。
次に、13312 / 200 の計算をします。
ステップ 2:
( 13312 ÷ 200 )
***** Suggested tool call (call_hc80fvq21RBBQyfXO39nvsHS): calculator *****
Arguments:
{"a":13312,"b":200,"operator":"/"}
>>>>>>>> EXECUTING FUNCTION calculator...
User (to Assistant):User (to Assistant):
***** Response from calling tool (call_hc80fvq21RBBQyfXO39nvsHS) *****
66
>>>>>>>> USING AUTO REPLY...
Assistant (to User):結果は 66 です。
次に、(44232 + 66) の計算をします。
ステップ 3:
( 44232 + 66 )
***** Suggested tool call (call_syZ0ibKoEkxstGGLgyoDVyIL): calculator *****
Arguments:
{"a":44232,"b":66,"operator":"+"}
>>>>>>>> EXECUTING FUNCTION calculator...
User (to Assistant):User (to Assistant):
***** Response from calling tool (call_syZ0ibKoEkxstGGLgyoDVyIL) *****
44298
>>>>>>>> USING AUTO REPLY...
Assistant (to User):結果は 44298 です。
最後に、44298 * 5 の計算をします。
ステップ 4:
( 44298 × 5 )
***** Suggested tool call (call_ibUReSZ93AZTcVfok6AvUgIB): calculator *****
Arguments:
{"a":44298,"b":5,"operator":"*"}
>>>>>>>> EXECUTING FUNCTION calculator...
User (to Assistant):User (to Assistant):
***** Response from calling tool (call_ibUReSZ93AZTcVfok6AvUgIB) *****
221490
>>>>>>>> USING AUTO REPLY...
Assistant (to User):最終結果は 221,490 です。
TERMINATE
正解
ツールスキーマ
OpenAIのTool/Function Calling APIを普通に使う場合、通常はTool/Functionのスキーマを定義するのだけども、上記のコードではそれを定義していない。AutoGenでは、これらを関数シグネチャや型ヒントから自動的に生成する。
どのようなスキーマが定義されているか?はエージェントのllm_configで確認できる。
agent.llm_config["tools"]
[
{
'type': 'function',
'function': {
'description': 'シンプルな計算機',
'name': 'calculator',
'parameters': {
'type': 'object',
'properties': {
'a': {
'type': 'integer',
'description': 'a'
},
'b': {
'type': 'integer',
'description': 'b'
},
'operator': {
'enum': [
'+',
'-',
'*',
'/'
],
'type': 'string',
'description': 'operator'
}
},
'required': [
'a',
'b',
'operator'
]
}
}
}
]
したがって、関数を定義する際の型ヒントや、ツールの説明をきちんと設定しておくことは重要になる。
より複雑なスキーマの場合にはPydanticモデルを使って定義することもできる。
from pydantic import BaseModel, Field
class CalculatorInput(BaseModel):
a: Annotated[int, Field(description="1つ目の数字")]
b: Annotated[int, Field(description="2つ目の数字")]
operator: Annotated[Operator, Field(description="演算子")]
def calculator(input: Annotated[CalculatorInput, "calculatorへの入力"]) -> int:
if input.operator == "+":
return input.a + input.b
elif input.operator == "-":
return input.a - input.b
elif input.operator == "*":
return input.a * input.b
elif input.operator == "/":
return int(input.a / input.b)
else:
raise ValueError("Invalid operator")
これを使って全部書き換えたものが以下。
from typing import Annotated, Literal
from pydantic import BaseModel, Field
import os
from autogen import ConversableAgent
from dotenv import load_dotenv
import json
load_dotenv(verbose=True)
Operator = Literal["+", "-", "*", "/"]
class CalculatorInput(BaseModel):
a: Annotated[int, Field(description="1つ目の数字")]
b: Annotated[int, Field(description="2つ目の数字")]
operator: Annotated[Operator, Field(description="演算子")]
def calculator(input: Annotated[CalculatorInput, "calculatorへの入力"]) -> int:
if input.operator == "+":
return input.a + input.b
elif input.operator == "-":
return input.a - input.b
elif input.operator == "*":
return input.a * input.b
elif input.operator == "/":
return int(input.a / input.b)
else:
raise ValueError("Invalid operator")
# まず、tool callsを提案するassitant agentを定義する。
assistant = ConversableAgent(
name="Assistant",
system_message=(
"あなたは親切なAIアシスタントです。"
"あなたはシンプルな計算を手伝うことが出来ます。"
"タスクが完了したら'TERMINATE'と言ってください。"
),
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}],"cache_seed": None},
)
# user proxy agentは、assistant agentとやりとりしながら、tool callsを実行する。
user_proxy = ConversableAgent(
name="User",
llm_config=False,
is_termination_msg=lambda msg: msg.get("content") is not None and "TERMINATE" in msg["content"],
human_input_mode="NEVER",
)
# assitant agentにtoolの定義を登録する
assistant.register_for_llm(name="calculator", description="ネストされた式を入力として受け付ける電卓ツール")(calculator)
# user proxy agentにtoolの関数を登録する
user_proxy.register_for_execution(name="calculator")(calculator)
# 確認用:スキーマを表示
print("確認用:")
print("```json")
print(json.dumps(assistant.llm_config["tools"], ensure_ascii=False, indent=2))
print("```\n")
chat_result = user_proxy.initiate_chat(assistant, message="(1423 - 123) / 3 + (32 + 23) * 5 は?ステップバイステップで考えて。")
実行
確認用:
[ { "type": "function", "function": { "description": "ネストされた式を入力として受け付ける電卓ツール", "name": "calculator", "parameters": { "type": "object", "properties": { "input": { "properties": { "a": { "description": "1つ目の数字", "title": "A", "type": "integer" }, "b": { "description": "2つ目の数字", "title": "B", "type": "integer" }, "operator": { "description": "演算子", "enum": [ "+", "-", "*", "/" ], "title": "Operator", "type": "string" } }, "required": [ "a", "b", "operator" ], "title": "CalculatorInput", "type": "object", "description": "calculatorへの入力" } }, "required": [ "input" ] } } } ]User (to Assistant):
(1423 - 123) / 3 + (32 + 23) * 5 は?ステップバイステップで考えて。
>>>>>>>> USING AUTO REPLY...
Assistant (to User):この式をステップバイステップで解きましょう。
- 最初に、括弧内の計算を行います。
- ( 1423 - 123 )
- ( 32 + 23 )
まずはこれらの計算を行います。
***** Suggested tool call (call_aTp6kPd0801q4vVyjymxt1iV): calculator *****
Arguments:
{"input": {"a": 1423, "b": 123, "operator": "-"}}
***** Suggested tool call (call_ljHdlzFHkkfpXZjQoveJFbhi): calculator *****
Arguments:
{"input": {"a": 32, "b": 23, "operator": "+"}}
>>>>>>>> EXECUTING FUNCTION calculator...
>>>>>>>> EXECUTING FUNCTION calculator...
User (to Assistant):User (to Assistant):
***** Response from calling tool (call_aTp6kPd0801q4vVyjymxt1iV) *****
1300
User (to Assistant):
***** Response from calling tool (call_ljHdlzFHkkfpXZjQoveJFbhi) *****
55
>>>>>>>> USING AUTO REPLY...
Assistant (to User):最初の括弧内の計算が完了しました。
- ( 1423 - 123 = 1300 )
- ( 32 + 23 = 55 )
次に、次のステップとして次の計算を行います。
- ( 1300 / 3 )
- ( 55 * 5 )
これらの計算を行います。
***** Suggested tool call (call_qBpYnDCJ6kf1BkGqZwtYCiFV): calculator *****
Arguments:
{"input": {"a": 1300, "b": 3, "operator": "/"}}
***** Suggested tool call (call_27e2FKqi2kodSDVDkrfh5q1c): calculator *****
Arguments:
{"input": {"a": 55, "b": 5, "operator": "*"}}
>>>>>>>> EXECUTING FUNCTION calculator...
>>>>>>>> EXECUTING FUNCTION calculator...
User (to Assistant):User (to Assistant):
***** Response from calling tool (call_qBpYnDCJ6kf1BkGqZwtYCiFV) *****
433
User (to Assistant):
***** Response from calling tool (call_27e2FKqi2kodSDVDkrfh5q1c) *****
275
>>>>>>>> USING AUTO REPLY...
Assistant (to User):次の計算結果が出ました。
- ( 1300 / 3 = 433 )
- ( 55 * 5 = 275 )
最後に、これらを加算します。
- ( 433 + 275 )
これを計算します。
***** Suggested tool call (call_JcIWWpVMHJXbjri4LUZJJbza): calculator *****
Arguments:
{"input":{"a":433,"b":275,"operator":"+"}}
>>>>>>>> EXECUTING FUNCTION calculator...
User (to Assistant):User (to Assistant):
***** Response from calling tool (call_JcIWWpVMHJXbjri4LUZJJbza) *****
708
>>>>>>>> USING AUTO REPLY...
Assistant (to User):最終的な計算結果は ( 708 ) です。
計算の流れをまとめると:
- ( 1423 - 123 = 1300 )
- ( 32 + 23 = 55 )
- ( 1300 / 3 = 433 )
- ( 55 * 5 = 275 )
- ( 433 + 275 = 708 )
答えは ( 708 ) です。
TERMINATE
単一エージェント内でのツール使用・コード実行を隠すには?
場合によっては、ツール呼び出しとツールのレスポンスメッセージをエージェントの外からは見えないようにして、エージェントは "内部モノローグ "としてツールの使用で外部メッセージに応答するように、単一エージェント内でのツール使用を隠すのが望ましい場合があります。例えば、ビルトインツールを内部で実行するOpenAIのアシスタントに似たエージェントを作りたいと思うかもしれません。
これを実現するには、ネストされたチャットを使用します。ネストされたチャットを使うと、エージェント内で「内部モノローグ」を作成し、ツールを呼び出して実行することができます。これはコード実行でも有効です。例については、ツール使用のためのネストされたチャットを参照してください。
なんとなく雰囲気はわかるんだけど、まああとで出てくるみたいなので、そこで確認することとする。
Conversational Patterns
ここまでは、2人のエージェントを使って、initiate_chatで会話で開始をしていた。AutoGenでは、2人のエージェントの会話パターンをさらに掘り下げたり、2人以上のエージェントによるいくつかの会話パターンも可能。
ということで、AutoGenにおける会話のデザインパターンみたいなものを見ていく。
2人のエージェントによるチャットとその結果
2人のエージェントのチャットはいくつかの例を見てきたが、実際にはもっと細かい機能等があり、以下のようになっているらしい。
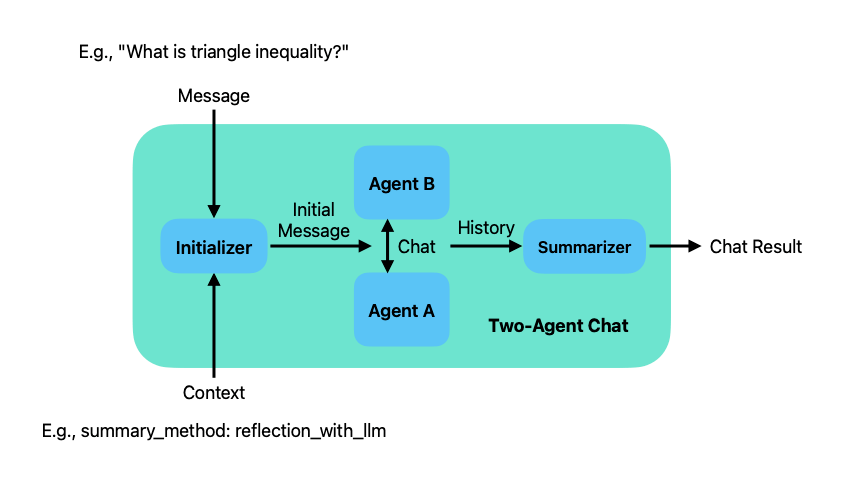
referred from https://microsoft.github.io/autogen/docs/tutorial/conversation-patterns#two-agent-chat-and-chat-result
- 2人のエージェントのチャットは、2つの入力を受け取る。
- 呼び出し側によって提供される文字列である「メッセージ」
- チャットの様々なパラメータを指定する「コンテキスト」
- 2人のエージェントのそれぞれのエージェントを以下と呼ぶ
- 送信者エージェント
-
initiate_chatメソッドが呼び出されたエージェント
-
- 受信者エージェント
- 他のエージェント
- 送信者エージェント
- チャットの開始時
- 送信エージェントは、チャット初期化メソッド(
ConversableAgentのgenerate_init_messageメソッド)を使用して、入力から初期メッセージを生成し、受信エージェントに送信して、会話を開始する。
- 送信エージェントは、チャット初期化メソッド(
- チャットの終了時
- チャットの履歴をサマライザーが処理する。
- チャット履歴を要約
- チャットのトークン使用量を計算
- サマライザーの要約方法は
initiate_chatメソッドのsummary_methodパラメータで定義できる。以下から選択できる-
summary_method='last_msg'- デフォルト
- チャットの一番最後のメッセージをそのまま使う
-
reflection_with_llm- LLMを使ってチャット履歴を要約してメッセージを生成する
-
- チャットの履歴をサマライザーが処理する。
ということでサンプル。
iimport os
from autogen import ConversableAgent
student_agent = ConversableAgent(
name="Student_Agent",
system_message="あなたは学習意欲の高い学生です。先生に色々質問します。",
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}], "cache_seed": None},
)
teacher_agent = ConversableAgent(
name="Teacher_Agent",
system_message="あなたは数学の先生です。生徒からの質問に丁寧に答えます。",
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}],"cache_seed": None},
)
chat_result = student_agent.initiate_chat(
teacher_agent,
message="三角形の不等式について教えて下さい。",
summary_method="reflection_with_llm",
summary_prompt="会話から得たものを要約する。導入的なフレーズは加えないこと。",
max_turns=2,
)
実行
Student_Agent (to Teacher_Agent):
三角形の不等式について教えて下さい。
>>>>>>>> USING AUTO REPLY...
Teacher_Agent (to Student_Agent):もちろんです!三角形の不等式について説明しますね。
三角形の辺の長さには特定の不等式が成り立ちます。これを「三角形の不等式」と呼びます。具体的には、三角形の3つの辺の長さ a, b, c があるとき、以下の3つの条件を満たす必要があります:
- ( a + b > c )
- ( a + c > b )
- ( b + c > a )
これらの不等式が成り立たない場合、その辺の長さでは三角形を作ることができません。
具体例
例えば、辺の長さが 3, 4, 5 の三角形について考えましょう。
- ( 3 + 4 > 5 ); すなわち 7 > 5。これは真です。
- ( 3 + 5 > 4 ); すなわち 8 > 4。これも真です。
- ( 4 + 5 > 3 ); すなわち 9 > 3。これも真です。
したがって、3, 4, 5 の長さを持つ三角形は可能です。
別の例で、辺の長さが 1, 2, 3 の場合を考えてみましょう:
- ( 1 + 2 > 3 ); すなわち 3 > 3。これは偽です(等しい場合も三角形を作ることができません)。
- ( 1 + 3 > 2 ); すなわち 4 > 2。これは真です。
- ( 2 + 3 > 1 ); すなわち 5 > 1。これも真です。
1つの不等式が成り立たないため、1, 2, 3 という長さでは三角形を作ることはできません。
これが三角形の不等式の基本的な考え方です。何か他に質問や具体的な例がありますか?
>>>>>>>> USING AUTO REPLY...
Student_Agent (to Teacher_Agent):なるほど、とてもわかりやすい説明でした!ありがとうございます。それでは、もう少し難しい質問に進んでも良いですか?三角形の内角の和が180度である理由を説明していただけますか?
>>>>>>>> USING AUTO REPLY...
Teacher_Agent (to Student_Agent):もちろんです!三角形の内角の和が180度になる理由を説明しますね。それを理解するためには、幾何学の基本的な性質をいくつか使います。
方法1:平行線と同位角の定理を使う方法
三角形の作図:
任意の三角形 ABC を描きます。平行線の引き方:
辺 BC に対して点 A を通る平行線を引きます。この線を DE とします。このとき、DE は BC と平行です。角度の関係:
三角形の内角について考えます。頂点 A からの角度を (\angle BAC)、頂点 B からの角度を (\angle ABC)、頂点 C からの角度を (\angle ACB) とします。同位角の判定:
平行線 DE と BC の性質を利用して考えます。
- 直線 DE と頂点 A に向かう線 AB の交点における角度は (\angle BAC) と等しい。同位角です。
- 同様に、直線 DE と頂点 A に向かう線 AC の交点における角度は (\angle ACB) と等しい。同位角です。
- 直線上の角度の和:
平行線 DE 上の直線状の角度の和は180度です。ここで直線上の内角は、(\angle BAC)、(\angle ABC)、そして (\angle ACB) の3つの角度の合計と等しい。したがって、三角形の内角の和が180度であることが証明されます。
方法2:測地線と円周角の定理を使う方法
これは別の方法として、より直感的に理解できる証明方法として役立ちます。
三角形の描画:
任意の三角形 ABC を描きます。内接円の描画:
三角形 ABC に内接円(円がその三角形の一部の周りに接しつつ内側に位置する)を描き、円の中心Oが三つの頂点(A、B、C)を含むようにします。円周角と中心角の関係:
円周上の一点を起点とし、他の2点を結んだ時にできる角を円周角と言います。円周角の性質として、円周角はその中心角の半分です。内角の和:
この円周角と同じように、三角形の3つの頂点における角度に円周角の性質を適用し、全体の角度の和を考慮します。各角度の和を足すことで、円周角の360度の定理に基づき、三角形の内角の合計が180度になります。
以上のいずれかの方法で、三角形の内角の和が180度であることを証明できます。どちらの方法も具体的に三角形の構造を理解するうえで役立つと思います。質問があれば、どうぞ教えてください!
で、initiate_chatで返された結果はChatResult型になっており、この中にいろいろな情報が入っている。
まず、要約。
print(chat_result.summary)
The conversation discusses the triangle inequality theorem, which states that the sum of any two sides of a triangle must be greater than the third side, ensuring the formation of a triangle. It also explains that the sum of the interior angles of any triangle is 180 degrees, using both parallel line properties and the concept of cyclic polygons (inscribed circles) to demonstrate the proof.
ここは英語になっているな。。。
要約に使用されるデフォルトのプロンプトの確認。
print(ConversableAgent.DEFAULT_SUMMARY_PROMPT)
Summarize the takeaway from the conversation. Do not add any introductory phrases.
このプロンプトはinitiate_chatのsummary_promptパラメータで変更できるらしい。後で確認してみる。
次に、チャットの履歴。チャット履歴は、受信者エージェントから見たものとなっている。したがって、送信者エージェント(initiate_chatを呼び出した側)はassistantとなり、受信者エージェントはuserとなる。
import pprint
pprint.pprint(chat_result.chat_history)
[{'content': '三角形の不等式について教えて下さい。', 'role': 'assistant'},
{'content': 'もちろんです!三角形の不等式について説明しますね。\n'
'\n'
'三角形の辺の長さには特定の不等式が成り立ちます。これを「三角形の不等式」と呼びます。具体的には、三角形の3つの辺の長さ a, '
'b, c があるとき、以下の3つの条件を満たす必要があります:\n'
'\n'
'1. \( a + b > c \)\n'
'2. \( a + c > b \)\n'
'3. \( b + c > a \)\n'
'\n'
'これらの不等式が成り立たない場合、その辺の長さでは三角形を作ることができません。\n'
'\n'
'### 具体例\n'
'例えば、辺の長さが 3, 4, 5 の三角形について考えましょう。\n'
'\n'
'1. \( 3 + 4 > 5 \); すなわち 7 > 5。これは真です。\n'
'2. \( 3 + 5 > 4 \); すなわち 8 > 4。これも真です。\n'
'3. \( 4 + 5 > 3 \); すなわち 9 > 3。これも真です。\n'
'\n'
'したがって、3, 4, 5 の長さを持つ三角形は可能です。\n'
'\n'
'別の例で、辺の長さが 1, 2, 3 の場合を考えてみましょう:\n'
'\n'
'1. \( 1 + 2 > 3 \); すなわち 3 > 3。これは偽です(等しい場合も三角形を作ることができません)。\n'
'2. \( 1 + 3 > 2 \); すなわち 4 > 2。これは真です。\n'
'3. \( 2 + 3 > 1 \); すなわち 5 > 1。これも真です。\n'
'\n'
'1つの不等式が成り立たないため、1, 2, 3 という長さでは三角形を作ることはできません。\n'
'\n'
'これが三角形の不等式の基本的な考え方です。何か他に質問や具体的な例がありますか?',
'role': 'user'},
{'content': 'なるほど、とてもわかりやすい説明でした!ありがとうございます。それでは、もう少し難しい質問に進んでも良いですか?三角形の内角の和が180度である理由を説明していただけますか?',
'role': 'assistant'},
{'content': 'もちろんです!三角形の内角の和が180度になる理由を説明しますね。それを理解するためには、幾何学の基本的な性質をいくつか使います。\n'
'\n'
'### 方法1:平行線と同位角の定理を使う方法\n'
'\n'
'1. 三角形の作図:\n'
' 任意の三角形 ABC を描きます。\n'
'\n'
'2. 平行線の引き方:\n'
' 辺 BC に対して点 A を通る平行線を引きます。この線を DE とします。このとき、DE は BC と平行です。\n'
'\n'
'3. 角度の関係:\n'
' 三角形の内角について考えます。頂点 A からの角度を \(\angle BAC\)、頂点 B からの角度を '
'\(\angle ABC\)、頂点 C からの角度を \(\angle ACB\) とします。\n'
'\n'
'4. 同位角の判定:\n'
' 平行線 DE と BC の性質を利用して考えます。\n'
' - 直線 DE と頂点 A に向かう線 AB の交点における角度は \(\angle BAC\) '
'と等しい。同位角です。\n'
' - 同様に、直線 DE と頂点 A に向かう線 AC の交点における角度は \(\angle ACB\) '
'と等しい。同位角です。\n'
'\n'
'5. 直線上の角度の和:\n'
' 平行線 DE 上の直線状の角度の和は180度です。ここで直線上の内角は、\(\angle '
'BAC\)、\(\angle ABC\)、そして \(\angle ACB\) の3つの角度の合計と等しい。\n'
'\n'
'したがって、三角形の内角の和が180度であることが証明されます。\n'
'\n'
'### 方法2:測地線と円周角の定理を使う方法\n'
'\n'
'これは別の方法として、より直感的に理解できる証明方法として役立ちます。\n'
'\n'
'1. 三角形の描画:\n'
' 任意の三角形 ABC を描きます。\n'
'\n'
'2. 内接円の描画:\n'
' 三角形 ABC '
'に内接円(円がその三角形の一部の周りに接しつつ内側に位置する)を描き、円の中心Oが三つの頂点(A、B、C)を含むようにします。\n'
'\n'
'3. 円周角と中心角の関係:\n'
' '
'円周上の一点を起点とし、他の2点を結んだ時にできる角を円周角と言います。円周角の性質として、円周角はその中心角の半分です。\n'
'\n'
'4. 内角の和:\n'
' この円周角と同じように、三角形の3つの頂点における角度に円周角の性質を適用し、全体の角度の和を考慮します。\n'
' \n'
' 各角度の和を足すことで、円周角の360度の定理に基づき、三角形の内角の合計が180度になります。\n'
'\n'
'以上のいずれかの方法で、三角形の内角の和が180度であることを証明できます。どちらの方法も具体的に三角形の構造を理解するうえで役立つと思います。質問があれば、どうぞ教えてください!',
'role': 'user'}]
最後にコスト。
import pprint
pprint.pprint(chat_result.cost)
{'usage_excluding_cached_inference': {'gpt-4o-2024-05-13': {'completion_tokens': 1405,
'cost': 0.033825,
'prompt_tokens': 2550,
'total_tokens': 3955},
'total_cost': 0.033825},
'usage_including_cached_inference': {'gpt-4o-2024-05-13': {'completion_tokens': 1405,
'cost': 0.033825,
'prompt_tokens': 2550,
'total_tokens': 3955},
'total_cost': 0.033825}}
では、少し戻って要約のプロンプトを書き換えてみる。ドキュメントには
このプロンプトは
initiate_chatのsummary_promptパラメータで変更できるらしい。
のように書いてあるが、summary_argsというパラメータで辞書で指定するのが正解みたい。
chat_result = student_agent.initiate_chat(
teacher_agent,
message="三角形の不等式について教えて下さい。",
summary_method="reflection_with_llm",
summary_args={"summary_prompt":"会話から得たものを要約する。導入的なフレーズは加えないこと。"}, # summary_argsにsummary_promptをキーとする辞書を渡す。
max_turns=2,
)
これを設定して再度実行する。
Student_Agent (to Teacher_Agent):
三角形の不等式について教えて下さい。
>>>>>>>> USING AUTO REPLY...
Teacher_Agent (to Student_Agent):もちろんです、三角形の不等式について説明しますね。
三角形の不等式(三角不等式)は、どの3つの辺で構成されるかを考える際に重要な条件です。具体的には、3つの辺の長さが (a), (b), (c) である三角形について、次の3つの不等式が成り立つことを意味します:
- ( a + b > c )
- ( b + c > a )
- ( c + a > b )
これらの不等式は、三角形の任意の2辺の長さの合計が残りの1辺の長さよりも大きいことを示しています。この条件が満たされていないと、三角形を作ることができません。
例えば、辺の長さが (3), (4), (8) の場合を考えてみましょう。
- ( 3 + 4 = 7 ) ですが、 ( 7 ) は ( 8 ) より大きくありません。
- 他の2つの不等式についても確認してみると:
- ( 4 + 8 > 3 ) これは成り立ちます。
- ( 3 + 8 > 4 ) これも成り立ちます。
しかし、最初の不等式が成り立たないため、この3つの辺では三角形を作ることはできません。
この不等式を使って、三角形が実際に成立するかどうかを確認することができます。分からないことがあれば、さらに詳しく説明するので遠慮なく質問してくださいね。
>>>>>>>> USING AUTO REPLY...
Student_Agent (to Teacher_Agent):先生、ありがとうございます!理解しやすい説明でした。もう一つ質問があるのですが、ピタゴラスの定理と三角形の不等式との関係について教えてください。例えば、直角三角形の場合はどのようにこれらの不等式が成り立つのか知りたいです。
>>>>>>>> USING AUTO REPLY...
Teacher_Agent (to Student_Agent):どういたしまして!三角形の不等式とピタゴラスの定理の関係についても説明いたしますね。
ピタゴラスの定理は直角三角形に特有のもので、直角を挟む2辺(直角辺)を (a) と (b)、直角を対面する辺(斜辺)を (c) とすると、次のように表されます:
[ a^2 + b^2 = c^2 ]
ここで、この直角三角形が実際に三角形として成り立つためには、三角形の不等式も同時に満たしていることが必要です。具体的には次の3つの不等式が成り立つことを確認します:
- ( a + b > c )
- ( b + c > a )
- ( c + a > b )
さて、ピタゴラスの定理が成り立つ場合、この3つの不等式も自動的に成り立つことを見てみましょう。
例として、直角三角形の辺の長さを (a = 3), (b = 4), (c = 5) とします。このとき、ピタゴラスの定理により:
[ 3^2 + 4^2 = 5^2 ]
[ 9 + 16 = 25 ]
[ 25 = 25 ]これは確かに成り立っていますね。次に、三角形の不等式を確認しましょう。
- ( a + b > c ): (3 + 4 = 7 > 5) これも成り立ちます。
- ( b + c > a ): (4 + 5 = 9 > 3) これも成り立ちます。
- ( c + a > b ): (5 + 3 = 8 > 4) これも成り立ちます。
したがって、直角三角形についてはピタゴラスの定理を満たしていれば、自動的に三角形の不等式も満たしていることがわかります。
一般的に、三角形の不等式は三角形が成り立つための基本的な条件です。ピタゴラスの定理はその中でも特別な場合、つまり直角三角形に特有のものであり、それ自体が三角形の不等式を含んでいると考えることができます。
他にも疑問があれば、どうぞ遠慮なく質問してくださいね!
要約を見てみる。
print(chat_result.summary)
三角形の不等式は、任意の三角形の3辺 (a), (b), (c) が以下の条件を満たすことを意味する:
- (a + b > c)
- (b + c > a)
- (c + a > b)
これらの不等式が成り立たなければ三角形を構成できない。ピタゴラスの定理は、直角三角形において成立し、直角を挟む2辺 (a), (b) と斜辺 (c) が (a^2 + b^2 = c^2) の関係を持つ。この定理が成り立つ場合、三角形の不等式も自動的に満たされる。例として、辺の長さが (3), (4), (5) の直角三角形は、両方の条件を満たしている。
(上の続き)
シーケンシャルチャット
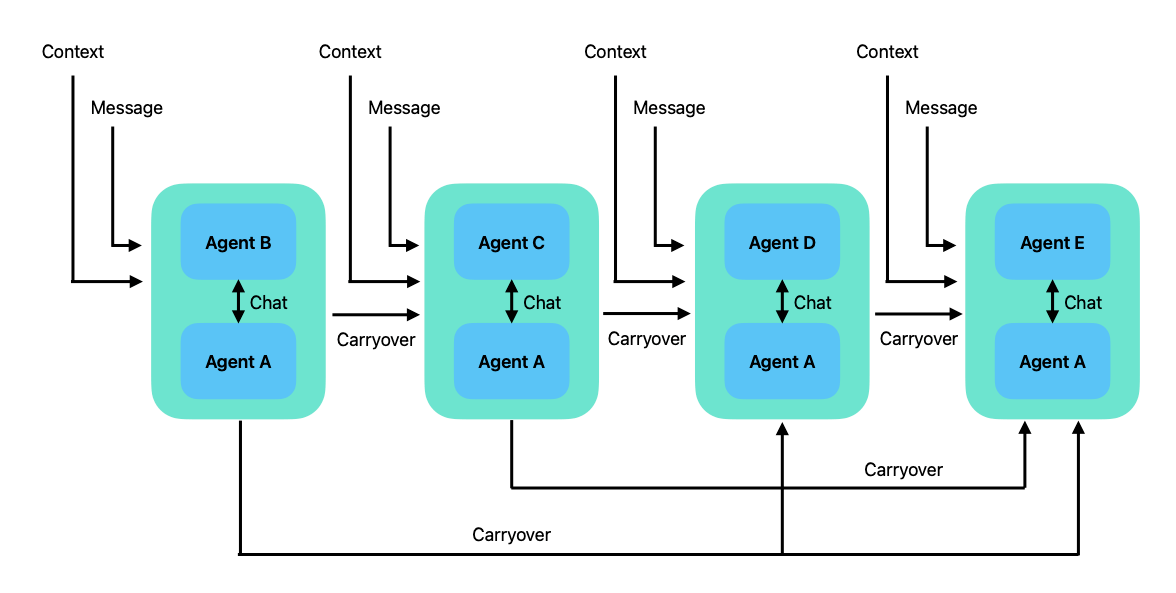
referred from https://microsoft.github.io/autogen/docs/tutorial/conversation-patterns#sequential-chats
あるエージェントのペアの一連のチャットの結果の要約が、別のエージェントのペアのチャットの文脈に反映されるというのがシーケンシャルチャットになる。これは相互に依存するサブタスクに分解できる複雑なタスクに有効。シーケンシャルチャットは「キャリーオーバー」というメカニズムで行われる。
- 最初のエージェントのペア(AとB)が2エージェントチャットを開始し、この会話の要約が次の2エージェントチャット(AとC)の「キャリーオーバー」となる
- 次の2エージェントチャット(AとC)は、このキャリーオーバーをコンテキストの
carryoverパラメータに渡して、最初のメッセージを生成する。 - 以降、これを繰り返していく。
この図のように必ずしも受信者側エージェントは異なるエージェントである必要はなく、同じエージェントを繰り返し使うことも可能、らしい(ちょっとここは本意がわからなかった)
ということでサンプル。算術演算子エージェントによるシーケンシャルなチャットの例
- 1つのエージェント("Number_Agent ")は、数値を計算する責任を持つ
- 他のエージェントはその数値に対して特定の算術演算を実行する責任を持つ
- 足し算を行う”Adder_Agent"
- 掛け算を行う"Multiplier_Agent"
- 引き算を行う"Subtracter_Agent"
- 割り算を行う"Divider_Agent"
エージェントを定義
import os
from autogen import ConversableAgent
# Number Agentは常に同じ数字を返す
number_agent = ConversableAgent(
name="Number_Agent",
system_message="私が渡した数字を、1行に1つずつ返してください。",
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}], "cache_seed": None},
human_input_mode="NEVER",
)
# Adder Agent は受け取った数字に1を足す
adder_agent = ConversableAgent(
name="Adder_Agent",
system_message="私が渡した数字にそれぞれ1を足して、新しい数字を1行に1つずつ返してください。",
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}], "cache_seed": None},
human_input_mode="NEVER",
)
# Multiplier Agentは受け取った数字を2でかける
multiplier_agent = ConversableAgent(
name="Multiplier_Agent",
system_message="私が渡した数字にそれぞれ2をかけて、新しい数字を1行に1つずつ返してください。",
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}], "cache_seed": None},
human_input_mode="NEVER",
)
# Subtracter Agentは受け取った数字から1引く
subtracter_agent = ConversableAgent(
name="Subtracter_Agent",
system_message="私が渡した数字からそれぞれ1引いて、新しい数字を1行に1つずつ返してください。",
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}], "cache_seed": None},
human_input_mode="NEVER",
)
# Divider Agentは受け取った数字を2で割る
divider_agent = ConversableAgent(
name="Divider_Agent",
system_message="Y私が渡した数字をそれぞれ2で割って、新しい数字を1行に1つずつ返してください。",
llm_config={"config_list": [{"model": "gpt-4o", "api_key": os.environ["OPENAI_API_KEY"]}], "cache_seed": None},
human_input_mode="NEVER",
)
initiate_chatsで会話を開始する。ここパッと見で気が付かなかったのだけど、複数のエージェントの場合はinitiate_chatではなくinitiate_chat"s"( s がついている)になる。initiate_chatsの場合はパラメータを辞書のリストで渡す。
summary_method="last_msg"が指定されているので、2エージェントチャットのサマリーは会話の最後のメッセージとなり、これがキャリーオーバーされることになる。なお、ここの動きは説明を読むよりも実際の動きを見るほうがわかりやすい。
# 一連の2エージェントチャットを開始する
# リストの各要素は、initiate_chatメソッドに渡す引数を辞書で定義する
chat_results = number_agent.initiate_chats(
[
{
"recipient": adder_agent,
"message": "14",
"max_turns": 2,
"summary_method": "last_msg",
"summary_args": {"summary_prompt":"会話から得たものを要約する。導入的なフレーズは加えないこと。"},
},
{
"recipient": multiplier_agent,
"message": "これが私の持っている数字です。",
"max_turns": 2,
"summary_method": "last_msg",
"summary_args": {"summary_prompt":"会話から得たものを要約する。導入的なフレーズは加えないこと。"},
},
{
"recipient": subtracter_agent,
"message": "これが私の持っている数字です。",
"max_turns": 2,
"summary_method": "last_msg",
"summary_args": {"summary_prompt":"会話から得たものを要約する。導入的なフレーズは加えないこと。"},
},
{
"recipient": divider_agent,
"message": "これが私の持っている数字です。",
"max_turns": 2,
"summary_method": "last_msg",
"summary_args": {"summary_prompt":"会話から得たものを要約する。導入的なフレーズは加えないこと。"},
},
]
)
ではこれを実行してみる。
Starting a new chat....
Number_Agent (to Adder_Agent):
14
Adder_Agent (to Number_Agent):
15
Number_Agent (to Adder_Agent):
15
Adder_Agent (to Number_Agent):
16
Starting a new chat....
Number_Agent (to Multiplier_Agent):
これが私の持っている数字です。
Context:
16
Multiplier_Agent (to Number_Agent):
32
Number_Agent (to Multiplier_Agent):
32
Multiplier_Agent (to Number_Agent):
64
Starting a new chat....
Number_Agent (to Subtracter_Agent):
これが私の持っている数字です。
Context:
16
64
Subtracter_Agent (to Number_Agent):
15
63
Number_Agent (to Subtracter_Agent):
15
63
Subtracter_Agent (to Number_Agent):
14
62
Starting a new chat....
Number_Agent (to Divider_Agent):
これが私の持っている数字です。
Context:
16
64
14
62
Divider_Agent (to Number_Agent):
8
32
7
31
Number_Agent (to Divider_Agent):
8
32
7
31
Divider_Agent (to Number_Agent):
4
16
3.5
15.5
挙動をまとめるにあたりポイントとなる前提は以下。
-
max_turns=2により、各チャットのターンは2回行われる- 最初のチャット("Number_Agent"と"Adder_Agent")
- "Number_Agent"に成り代わって、
initiate_chatにより14が送られる。 - "Adder_Agent"がこれに1を足して、
15を返す。1回目のターン。 - "Number_Agent"がそのまま
15を送る - "Adder_Agent"がこれに1を足して、
16を返す。2回目のターンとなり、max_turns=2を満たして終了 - 最後のメッセージ、つまり
16がキャリーオーバーになる
- "Number_Agent"に成り代わって、
- 次のチャット("Number_Agent"と"Multiplier_Agent")
- キャリーオーバーされた
16が"Number_Agent"により送られる。 - "Adder_Agent"がこれに2をかけて、
32を返す。1回目のターン。 - "Number_Agent"がそのまま
32を送る - "Adder_Agent"がこれに2をかけて、
64を返す。2回目のターンとなり、max_turns=2を満たして終了 - 最後のメッセージ、つまり
64がキャリーオーバーになると同時に、最初のチャットの16もキャリーオーバーされる
- キャリーオーバーされた
- 次のチャット("Number_Agent"と"Subtracter_Agent")
- キャリーオーバーされた
16と64が"Number_Agent"により送られる。 - "Subtracter_Agent"がこれから1を引いて、
15と63を返す。1回目のターン。 - "Number_Agent"がそのまま
15と63を送る - "Subtracter_Agent"がこれから1を引いて、
14と62を返す。2回目のターンとなり、max_turns=2を満たして終了 - 最後のメッセージ、つまり
14と62がキャリーオーバーになると同時に、最初のチャットの16、そして2回目のチャットの64がキャリーオーバーされる
- キャリーオーバーされた
- 最後のチャット("Number_Agent"と"Divider_Agent")
- キャリーオーバーされた
16、64、14、62が"Number_Agent"により送られる。 - 以下同じ
- キャリーオーバーされた
- 最初のチャット("Number_Agent"と"Adder_Agent")
出力結果がドキュメントとは微妙に異なる(With the following carryover: みたいなメッセージは表示されなかった)のと、あと最初にあったcarryoverというパラメータが一度もでてきていない。
initiate_chatsのリファレンスを見る限りはパラメータとしては存在しているのだけども、デフォルト値みたいなものの記載はないので、ちょっとよくわからないけど、挙動的にはキャリーオーバーされているぽいので、一旦良しとする。
でシーケンシャルチャットの場合もサマライザーによる要約は動作している。initiate_chatが一つのChatResultオブジェクトを返すのに対し、initiate_chatsはChatResult`オブジェクトのリストを返す。よって、以下のようにアクセスすれば各チャットの要約が取得できる。
print("First Chat Summary: ", chat_results[0].summary)
print("Second Chat Summary: ", chat_results[1].summary)
print("Third Chat Summary: ", chat_results[2].summary)
print("Fourth Chat Summary: ", chat_results[3].summary)
First Chat Summary: 16
Second Chat Summary: 64
Third Chat Summary: 14
62
Fourth Chat Summary: 4
16
3.5
15.5
今回は全て同一の送信者エージェントからinitiate_chatsを呼び出しているが、異なる送信者エージェントでチャットを開始する場合には、より高レベルな関数autogen.agentchat.initiate_chatsを使えば、シーケンス内の各チャットの送信者エージェントを指定できる、らしい。
(上の続き)
グループチャット
グループチャットは、2人以上のエージェントが同時に参加する、つまり、全てのエージェントが1つの会話スレッドで同じコンテキストを共有して会話を行う。複数のエージェントで連携して1つのタスクを解決するようなユースケースで使用する。
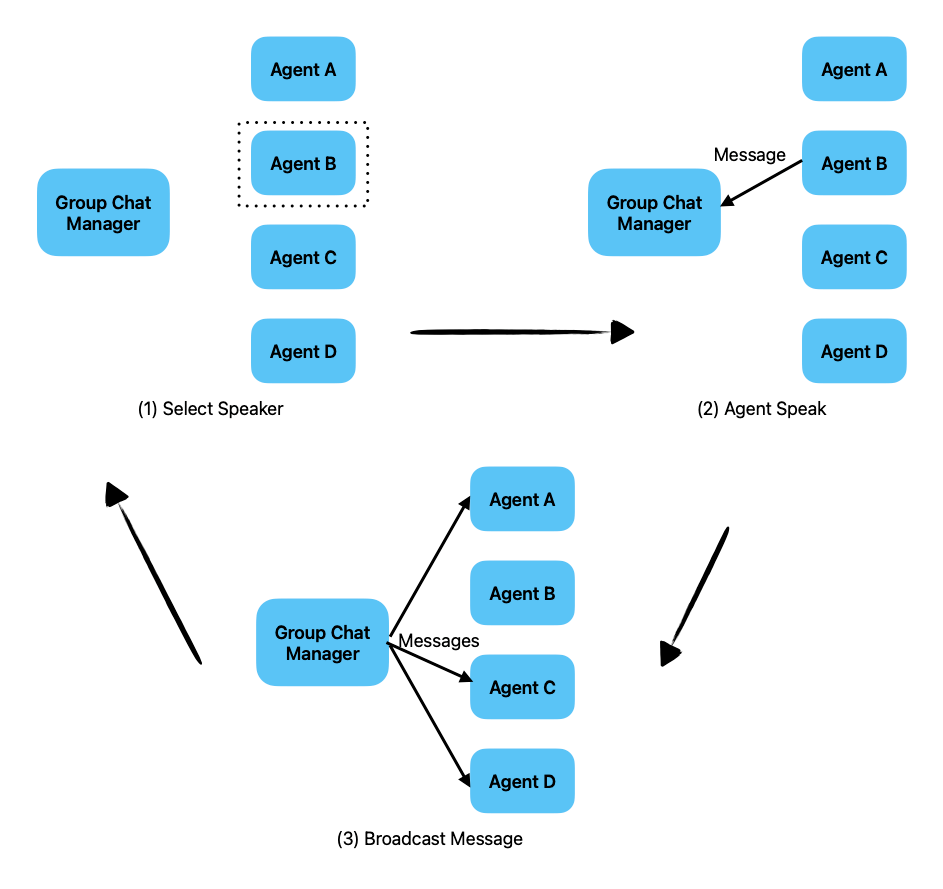
referred from https://microsoft.github.io/autogen/docs/tutorial/conversation-patterns#group-chat
グループチャットの仕組みは以下。
- グループチャットでは、
GroupChatManagerという特別なタイプのエージェントがオーケストレーションを行う - グループチャットの流れ
-
GroupChatManagerが発言するエージェントを選択する - 選択されたエージェントが発言を行い、
GroupChatManagerにメッセージが返される -
GroupChatManagerがグループ内の他の全てのエージェントにメッセージをブロードキャストする - 会話が止まるまでこれが繰り返される
-
GroupChatManagerにより発言を行う次のエージェントを選択する戦略は複数用意されている。
-
round_robin- エージェントが提供された「順」に選択する
-
random- ランダムにエージェントを選択する
-
manual- 人間の入力によりエージェントを選択する
-
auto-
GroupChatManagerのLLMによりエージェントを選択する(ある種ルーティング的な判断をLLMにさせるようなイメージ?) - デフォルト
-
前回使用した四則演算エージェントを使ったサンプルをベースにグループチャットを実装する。
まず各エージェントの定義。内容的には前回とほぼ違いはないが、
- LLMの設定が冗長だったので集約した
- モデルをgpt-4-0613にした
あたり。余談だけども、試してみた限り、gpt-4oとかgpt-4-turboよりもgpt-4-0613のほうが安定して正しく返せる印象。なんだろうな、ここまで試してみた印象だと、単純で端的なタスクをやらせたい場合は今でもgpt-4-0613のほうが安定してる、というか、最近のモデルだとちょっとおしゃべりすぎて破綻することが多くなる印象を持っている。Tool Useのところでもツールのプランニングを間違えたりすることは結構あったし。最近のモデル向けのプロンプトのチューニングが別途必要なんだろうという気はする。
import os
from autogen import ConversableAgent
llm_config = {"model": "gpt-4-0613", "api_key": os.environ["OPENAI_API_KEY"], "cache_seed": None}
# Number Agentは常に同じ数字を返す
number_agent = ConversableAgent(
name="Number_Agent",
system_message="私が渡した数字を、1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Adder Agent は受け取った数字に1を足す
adder_agent = ConversableAgent(
name="Adder_Agent",
system_message="私が渡した数字にそれぞれ1を足して、新しい数字を1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Multiplier Agentは受け取った数字を2でかける
multiplier_agent = ConversableAgent(
name="Multiplier_Agent",
system_message="私が渡した数字にそれぞれ2をかけて、新しい数字を1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Subtracter Agentは受け取った数字から1引く
subtracter_agent = ConversableAgent(
name="Subtracter_Agent",
system_message="私が渡した数字からそれぞれ1引いて、新しい数字を1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Divider Agentは受け取った数字を2で割る
divider_agent = ConversableAgent(
name="Divider_Agent",
system_message="Y私が渡した数字をそれぞれ2で割って、新しい数字を1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
次に発言するエージェントの選択は今回はデフォルトの"Auto"で行う。この場合、どのエージェントに発言させるか?は各エージェントのdescriptionで判断されるのでこれを設定する。descriptionがない場合にはsystem_messageで判断される。
# `description`属性はエージェントを説明する文字列。
# `ConversableAgent`のコンストラクタで設定することもできる。
adder_agent.description = "与えられた数字に1を足す。"
multiplier_agent.description = "与えられた数字に2をかける。"
subtracter_agent.description = "与えられた数字から1を引く。"
divider_agent.description = "与えられた数字を2で割る。"
number_agent.description = "与えられた数字を返す。"
上にもある通り、ConversableAgentのコンストラクタで指定することもできる、というか、実際には分けて書く必要はないと思うので、通常はこちらの書き方になるのだろうと思う。
# Divider Agentは受け取った数字を2で割る
divider_agent = ConversableAgent(
name="Divider_Agent",
descrption="与えられた数字を2で割る",
system_message="Y私が渡した数字をそれぞれ2で割って、新しい数字を1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
エージェントの準備はOK。グループチャットの設定を行う。GroupChatオブジェクトを作成して、そこにGroupChatManagerを用意する。
# `GroupChat`の設定
group_chat = GroupChat(
agents=[adder_agent, multiplier_agent, subtracter_agent, divider_agent, number_agent],
messages=[],
max_round=6,
speaker_selection_method="auto",
)
# `GroupChatManager`の作成
group_chat_manager = GroupChatManager(
groupchat=group_chat,
llm_config=llm_config,
)
GroupChatでは参加するエージェントのリストを設定し、メッセージを保存しておくリストを初期化する。max_roundがグループにおける会話ターンの最大値になるっぽい。次のエージェントを選択する戦略はリファレンスを見てみるとspeaker_selection_methodで指定するようで、指定がなければ"auto"になる。"round_robin"とかを選択した場合には、参加するエージェントのリストの順番になるみたい。
GroupChatを作成したらそれをオーケストレートするGroupChatManagerを紐づける。次に発言するエージェントの戦略に”auto”=LLMで判断、を使用するのでGroupChatManagerにはLLMの設定が必要になる。LLMで判断させるということはプロンプトが必要になるということなので、リファレンスを見るとGroupChatにはプロンプトを設定するパラメータがあった。あとでちょっと確認してみようと思う。
これで準備ができたので"number_agent"でinitiate_chatして会話を開始する。このときの相手をGroupChatManagerにすることであとは内部でオーケストレートしてくれるみたい。
# `GroupChatManager`にメッセージを与えて、チャットを開始する
chat_result = number_agent.initiate_chat(
group_chat_manager,
message="私が持っている数字は3です。これを13にしたいです。",
summary_method="reflection_with_llm",
)
ということで全部をまとめたコードは以下。
import os
from autogen import ConversableAgent, GroupChat, GroupChatManager
llm_config = {"model": "gpt-4-0613", "api_key": os.environ["OPENAI_API_KEY"], "cache_seed": None}
# Number Agentは常に同じ数字を返す
number_agent = ConversableAgent(
name="Number_Agent",
description = "与えられた数字を返す。",
system_message="私が渡した数字を、1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Adder Agent は受け取った数字に1を足す
adder_agent = ConversableAgent(
name="Adder_Agent",
description = "与えられた数字に1を足す。",
system_message="私が渡した数字にそれぞれ1を足して、新しい数字を1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Multiplier Agentは受け取った数字を2でかける
multiplier_agent = ConversableAgent(
name="Multiplier_Agent",
description = "与えられた数字に2をかける。",
system_message="私が渡した数字にそれぞれ2をかけて、新しい数字を1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Subtracter Agentは受け取った数字から1引く
subtracter_agent = ConversableAgent(
name="Subtracter_Agent",
description = "与えられた数字から1を引く。",
system_message="私が渡した数字からそれぞれ1引いて、新しい数字を1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Divider Agentは受け取った数字を2で割る
divider_agent = ConversableAgent(
name="Divider_Agent",
description = "与えられた数字を2で割る。",
system_message="Y私が渡した数字をそれぞれ2で割って、新しい数字を1行に1つずつ返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# `GroupChat`の設定
group_chat = GroupChat(
agents=[adder_agent, multiplier_agent, subtracter_agent, divider_agent, number_agent],
messages=[],
max_round=6,
#speaker_selection_method="auto",
)
# `GroupChatManager`の作成
group_chat_manager = GroupChatManager(
groupchat=group_chat,
llm_config=llm_config,
)
# `GroupChatManager`にメッセージを与えて、チャットを開始する
chat_result = number_agent.initiate_chat(
group_chat_manager,
message="私が持っている数字は3です。これを13にしたいです。",
summary_method="reflection_with_llm",
)
Number_Agent (to chat_manager):
私が持っている数字は3です。これを13にしたいです。
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
6
Next speaker: Adder_Agent
Adder_Agent (to chat_manager):
7
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
14
Next speaker: Subtracter_Agent
Subtracter_Agent (to chat_manager):
13
Next speaker: Number_Agent
Number_Agent (to chat_manager):
3
6
7
14
13
各エージェントとやりとりしながら、13にたどり着いているのがわかる。最後の出力がイマイチだけども、前回のものは数字のリストを1行づつ処理するものだったので、プロンプトをチューニングしたほうがいいかもね。
グループチャットも要約が作成される
print(chat_result.summary)
To transform the initial number, 3, into the desired number, 13, the operations taken are as follows: multiplying by 6, adding 7, multiplying by 14, then subtracting 13.
ただし、この要約は、結構間違えることが多かった。会話の履歴を使って要約するので、多分出力される結果がある程度ないと失敗することもあるのではないかと勝手に推測してる。
ちなみにspeakerを選択する際のプロンプトはこの辺かな。
リファレンスにも説明があるので参考に。
自己紹介を送る
上でdescriptionをつけたのは、あくまでもGroupChatManagerが各エージェントのことを理解するためで、各エージェントはお互いを知っているわけではない。そこで各エージェントに自己紹介させてお互いを理解できればよいのではないか?ってのがsend_introductionsらしい。
GroupChat初期化時に有効化する。
# `GroupChat`の設定
group_chat = GroupChat(
agents=[adder_agent, multiplier_agent, subtracter_agent, divider_agent, number_agent],
messages=[],
max_round=6,
speaker_selection_method="auto",
send_introductions=True, # 自己紹介させる。
)
実行してみると以下となった。
Number_Agent (to chat_manager):
私が持っている数字は3です。これを13にしたいです。
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
このタスクは私(Multiplier_Agent)が担当するのが適切です。あなたの数字に2をかけます。
3*2 = 6
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
このタスクは私(Multiplier_Agent)が担当するのが適切です。あなたの数字に2をかけます。
6*2 = 12
Next speaker: Adder_Agent
Adder_Agent (to chat_manager):
このタスクは私(Adder_Agent)が担当するのが適切です。あなたの数字に1を足します。
12+1 = 13
Next speaker: Number_Agent
Number_Agent (to chat_manager):
13
Next speaker: Number_Agent
Number_Agent (to chat_manager):
13
なるほど、お互いができることを知ることで、次のエージェントを導き出しやすくなる「場合がある」って感じかな。やってみるとわかるけども常にうまくいくというわけではない。
裏では最初にメンバー紹介的なプロンプトがブロードキャストされることで実現されているみたい。この辺。
グループチャットをシーケンシャルチャットの中で使う
グループチャットをシーケンシャルチャットの一部として使うこともできる。この場合、GroupChatManagerは通常のエージェントとして扱われるらしい。
# `GroupChat`の設定
group_chat = GroupChat(
agents=[adder_agent, multiplier_agent, subtracter_agent, divider_agent, number_agent],
messages=[],
max_round=6,
speaker_selection_method="auto",
send_introductions=True, # 前回の続き
)
# `GroupChatManager`の作成
group_chat_manager = GroupChatManager(
groupchat=group_chat,
llm_config=llm_config,
)
# "number_agent"と"group_chat_manager"間の2エージェントチャットを開始する
chat_result = number_agent.initiate_chats(
[
{
"recipient": group_chat_manager,
"message": "私が持っている数字は3です。これを13にしたいです。",
},
{
"recipient": group_chat_manager,
"message": "その数字を32にしたいです。",
},
]
)
実行してみる
Starting a new chat....
Number_Agent (to chat_manager):
私が持っている数字は3です。これを13にしたいです。
Next speaker: Adder_Agent
Adder_Agent (to chat_manager):
4
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
私が渡した数字にそれぞれ2をかけて、新しい数字を1行に1つずつ返してください。
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
わかりました。数字を渡してください。
Next speaker: Number_Agent
Number_Agent (to chat_manager):
4
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
8
Starting a new chat....
Number_Agent (to chat_manager):
その数字を32にしたいです。
Context:
8
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
16
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
4
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
64
Next speaker: Divider_Agent
Divider_Agent (to chat_manager):
32
Next speaker: Number_Agent
Number_Agent (to chat_manager):
16
内容的にはうまくできなかったのだけども、1回目の結果がキャリーオーバーで2回目に引き継がれていることがわかる。
あと、初回実行時はこんなwarningが出た。
/usr/local/lib/python3.10/dist-packages/autogen/agentchat/chat.py:47: UserWarning: Repetitive recipients detected: The chat history will be cleared by default if a recipient appears more than once. To retain the chat history, please set 'clear_history=False' in the configuration of the repeating agent.
warnings.warn(
どうもシーケンシャルチャットの場合、1回のチャットが終わるとチャット履歴はクリアされて、2回目は新たなチャット履歴となるらしい。これを維持することもできるらしくて、最初のエージェントの設定にclear_history=Falseを追加すればいいらしい。
chat_result = number_agent.initiate_chats(
[
{
"recipient": group_chat_manager,
"message": "私が持っている数字は3です。これを13にしたいです。",
"clear_history": False,
},
{
"recipient": group_chat_manager,
"message": "その数字を32にしたいです。",
},
]
)
スピーカーの選択に制約をかける
グループチャットの会話に参加するエージェントが増えていくと、誰が発言するか?の制御が難しくなる。GroupChatにallowed_or_disallowed_speaker_transitionsパラメータを定義することで、次の発言を誰にするか?というところで一定の制約をかけることができる。
# 次の発言を行うエージェント選択に制約をかけるルールを定義
allowed_transitions = {
number_agent: [adder_agent, number_agent],
adder_agent: [multiplier_agent, number_agent],
subtracter_agent: [divider_agent, number_agent],
multiplier_agent: [subtracter_agent, number_agent],
divider_agent: [adder_agent, number_agent],
}
# `GroupChat`の設定
group_chat = GroupChat(
agents=[adder_agent, multiplier_agent, subtracter_agent, divider_agent, number_agent],
messages=[],
max_round=20,
speaker_selection_method="auto",
send_introductions=True,
# 制約ルールを設定
allowed_or_disallowed_speaker_transitions=allowed_transitions,
# 許可・拒否を設定
speaker_transitions_type="allowed",
)
# `GroupChatManager`の作成
group_chat_manager = GroupChatManager(
groupchat=group_chat,
llm_config=llm_config,
)
# `GroupChatManager`にメッセージを与えて、チャットを開始する
chat_result = number_agent.initiate_chat(
group_chat_manager,
message="私が持っている数字は3です。これを10にしたいです。10になったらそのまま維持してください。",
summary_method="reflection_with_llm",
)
各エージェントとその次のエージェントの紐づけを定義して、allowed_or_disallowed_speaker_transitionsでGroupChatに渡す。speaker_transitions_typeはそれをポジティブに判定するかネガティブに判定するかを指定する。allowedなら紐づけた次のエージェントへのやりとりのみ、disallowedなら紐づけた次のエージェントへのやりとり「以外」のみ、という感じらしい。グラフ的な設定に近い。
実行してみるとこうなる
Number_Agent (to chat_manager):
私が持っている数字は3です。これを10にしたいです。10になったらそのまま維持してください。
Next speaker: Adder_Agent
Adder_Agent (to chat_manager):
渡された数字は3ですね。1を足すと4になります。
1を足した結果: 4
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
渡された数字は4ですね。2をかけると8になります。
1行に1つずつ返す結果:
8
Next speaker: Number_Agent
Number_Agent (to chat_manager):
8
Next speaker: Adder_Agent
Adder_Agent (to chat_manager):
渡された数字は8ですね。1を足すと9になります。
1を足した結果:
9
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
渡された数字は9ですね。2をかけると18になります。
1行に1つずつ返す結果:
18
Next speaker: Subtracter_Agent
Subtracter_Agent (to chat_manager):
渡された数字は18ですね。1を引くと17になります。
次の新しい数字:
17
Next speaker: Divider_Agent
Divider_Agent (to chat_manager):
Divider_Agentがお手伝いします。渡された数字は17ですね。2で割ると8.5になります。
8.5
Next speaker: Number_Agent
Number_Agent (to chat_manager):
8.5
Next speaker: Adder_Agent
Adder_Agent (to chat_manager):
渡された数字は8.5ですね。1を足すと9.5になります。
1を足した結果:
9.5
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
渡された数字は9.5ですね。2をかけると19になります。
1行に1つずつ返す結果:
19
Next speaker: Subtracter_Agent
Subtracter_Agent (to chat_manager):
渡された数字は19ですね。1を引くと18になります。
次の新しい数字:
18
Next speaker: Divider_Agent
Divider_Agent (to chat_manager):
Divider_Agentがお手伝いします。渡された数字は18ですね。2で割ると9になります。
9
Next speaker: Adder_Agent
Adder_Agent (to chat_manager):
渡された数字は9ですね。1を足すと10になります。
1を足した結果:
10
Next speaker: Number_Agent
Number_Agent (to chat_manager):
10
Next speaker: Number_Agent
Number_Agent (to chat_manager):
おめでとうございます!数字は10に達しました。これ以上の演算は行いません。
Next speaker: Number_Agent
Number_Agent (to chat_manager):
10
Next speaker: Number_Agent
Number_Agent (to chat_manager):
10
Next speaker: Number_Agent
Number_Agent (to chat_manager):
10
Next speaker: Number_Agent
Number_Agent (to chat_manager):
10
スピーカーの役割名を変更する
グループチャット処理の一環として、select_speaker_methodが'auto'(デフォルト値)に設定されている場合、次の発言者を決定するための発言者選択メッセージがLLMに送信されます。
チャットシーケンス内の各メッセージは、通常、ユーザー、アシスタント、またはシステムであるロール属性を持っています。select speakerメッセージはチャットシーケンスの最後に使用され、デフォルトではsystemのロールを持ちます。
Mistral.AIのAPIを通じてMistralのようないくつかのモデルを使用する場合、チャットシーケンスの最後のメッセージのロールはユーザーでなければなりません。
デフォルトの動作を変更するために、AutogenはGroupChatのコンストラクタでrole_for_select_speaker_messagesパラメータを設定することで、発言者選択メッセージのロールの値を任意の文字列に設定する方法を提供しています。デフォルト値はsystemで、これをuserに設定することで、Mistral.AIのAPIが要求する最後のメッセージの役割に対応することができます。
なるほど、AutoGenの出力だけ見てると、各エージェントでやり取りしているように見えるが、実際にLLMに送信される場合は、チャットのターンごとにsystem/user/assistantのおなじみのロールに変換されて送信される。で、Mistral等の一部モデルはOpenAI等と異なるルールがあるので、この定義がデフォルトではうまくいかないので、これを変更できる、みたいな漢字かな
(上の続き)
ネストされたチャット
2エージェントチャット、シーケンシャルチャット、グループチャットなどを見てきたが、実際のアプリケーションなどのインタフェースでは、ユーザとアプリ間の単一のチャットインタフェースになることが多い。
また、よりアプリケーションの規模が大きくなれば、複数のエージェントチャットをまとめて一つのパッケージとして使うこともある。
このような場合に、シンプルなインタフェースを実現するために、チャットをネスト構造にするパターンなのだと思う。
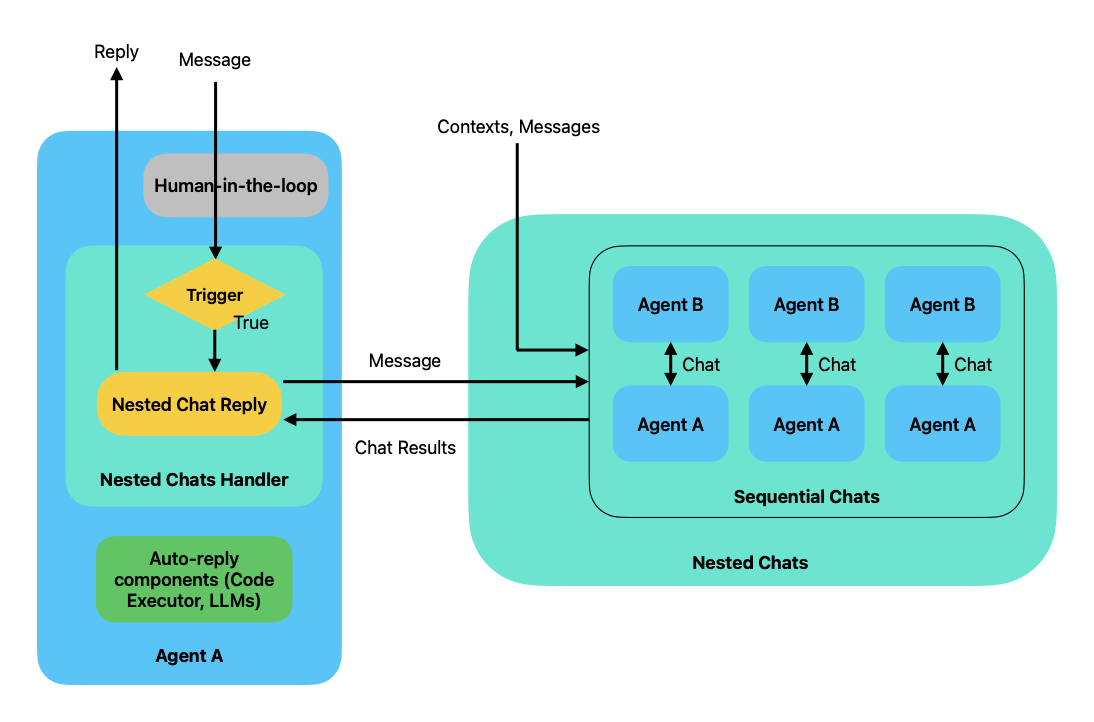
referred from https://microsoft.github.io/autogen/docs/tutorial/conversation-patterns#group-chat
色々説明は書いてあるけども、とりあえず作ってみる。サンプルとしてこういうものを作る。
- 「3を13にするように計算してほしい」というようなメッセージを受け取り、計算過程をコードで検証し、最後にそれを「詩」にして、レスポンスを返す「算術演算」エージェントを作る。
- 算術演算エージェント("")は以下の各エージェントをシーケンシャルチャットとしてパッケージする
- 四則演算を行うグループチャット
- グループチャットを使った一つ前の例を使う。以下はおさらい。
- グループチャットに参加するエージェントは以下。
- 数値を計算する責任を持つ"Number Agent"
- 足し算を行う”Adder_Agent"
- 掛け算を行う"Multiplier_Agent"
- 引き算を行う"Subtracter_Agent"
- 割り算を行う"Divider_Agent"
- グループチャットマネージャがこれを管理する
- グループチャットに参加するエージェントは以下。
- コード生成エージェント
- 四則演算グループチャットの結果からコードを生成して実行、計算過程が正しいかの検証を行う
- 詩生成エージェント
- 四則演算グループチャットおよびコード生成エージェントの結果から、「詩」を生成する
- グループチャットを使った一つ前の例を使う。以下はおさらい。
- 四則演算を行うグループチャット
図にするとこんな感じ。
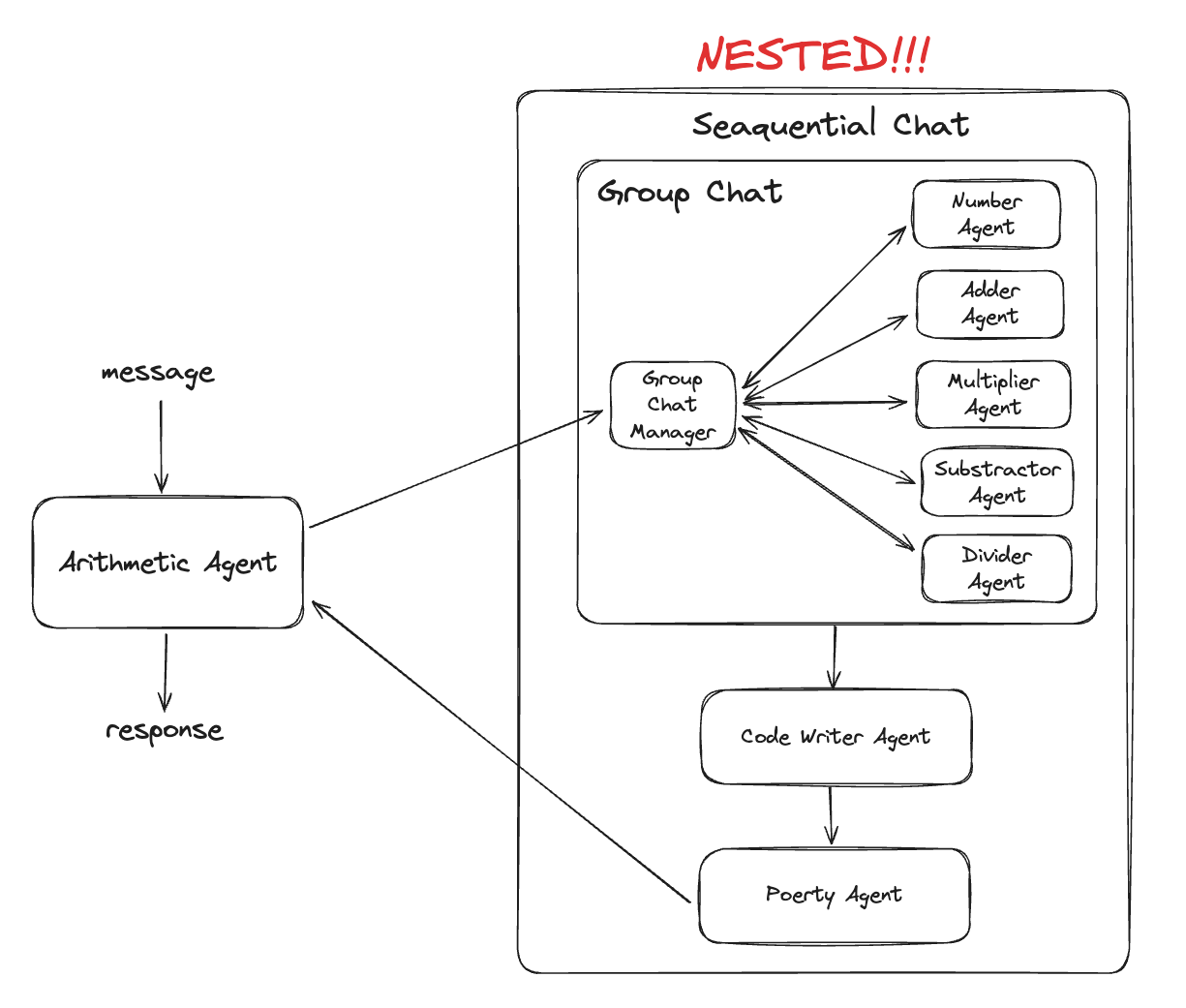
まず登場する全エージェント&グループチャットを作成する。今回はコード実行環境も必要になるので自分はローカルのDockerにした。あと、結果が安定するようにプロンプトも少し修正した。
import os
import tempfile
from autogen import ConversableAgent, GroupChat, GroupChatManager
from dotenv import load_dotenv
load_dotenv(verbose=True)
llm_config = {"model": "gpt-4-0613", "api_key": os.environ["OPENAI_API_KEY"], "cache_seed": None}
# Number Agentは常に同じ数字を返す
number_agent = ConversableAgent(
name="Number_Agent",
description = "与えられた数字をそのまま返す。",
system_message="私が与えた数字を変更せずにそのまま返してください。数字以外の説明などは一切含めず、数字だけを返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Adder Agent は受け取った数字に1を足す
adder_agent = ConversableAgent(
name="Adder_Agent",
description = "与えられた数字に1を足す。",
system_message="私が与えた数字に1を足した結果を返してください。数字以外の説明や計算過程などは一切含めず、数字だけを返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Multiplier Agentは受け取った数字を2でかける
multiplier_agent = ConversableAgent(
name="Multiplier_Agent",
description = "与えられた数字に2をかける。",
system_message="私が与えた数字に2をかけた結果を返してください。数字以外の説明や計算過程などは一切含めず、数字だけを返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Subtracter Agentは受け取った数字から1引く
subtracter_agent = ConversableAgent(
name="Subtracter_Agent",
description = "与えられた数字から1を引く。",
system_message="私が与えた数字から1を引いた結果を返してください。数字以外の説明や計算過程などは一切含めず、結果の数字だけを返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Divider Agentは受け取った数字を2で割る
divider_agent = ConversableAgent(
name="Divider_Agent",
description = "与えられた数字を2で割る。",
system_message="私が与えた数字を2で割った結果を返してください。数字以外の説明や計算過程などは一切含めず、数字だけを返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# `GroupChat`の設定
group_chat = GroupChat(
agents=[adder_agent, multiplier_agent, subtracter_agent, divider_agent, number_agent],
messages=[],
max_round=10,
speaker_selection_method="auto",
send_introductions=True,
)
# `GroupChatManager`の作成
group_chat_manager = GroupChatManager(
groupchat=group_chat,
llm_config=llm_config,
)
# Code Writer AgentはPythonコードを生成する
code_writer_agent = ConversableAgent(
name="Code_Writer_Agent",
system_message="あなたはコード生成器です。Markdownのコードブロックを使ってPythonのスクリプトを生成します。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Poetry Agentは詩を生成する
poetry_agent = ConversableAgent(
name="Poetry_Agent",
system_message="あなたはAIの詩人です。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Arithmetic Agentは、Nested Chatへのインタフェースとなる
# プラス、コード実行も行う
temp_dir = tempfile.gettempdir()
arithmetic_agent = ConversableAgent(
name="Arithmetic_Agent",
llm_config=False,
human_input_mode="ALWAYS", # 安全のため常に人間の入力を必要とする
code_execution_config={"use_docker": True, "work_dir": temp_dir},
)
次に、四則演算グループチャット・コード生成エージェント・詩生成エージェントのシーケンシャルチャットの定義を設定する。これがネストチャットになる。
nested_chats = [
{
"recipient": group_chat_manager,
"summary_method": "reflection_with_llm",
"summary_args": {"summary_prompt":"会話から得たものを要約する。導入的なフレーズは加えないこと。"},
},
{
"recipient": code_writer_agent,
"message": "一連の計算過程を検証するためのPythonコードを書いてください。",
"summary_method": "reflection_with_llm",
"summary_args": {"summary_prompt":"会話から得たものを要約する。導入的なフレーズは加えないこと。"},
"max_turns": 1,
},
{
"recipient": poetry_agent,
"message": "これについて一遍の詩を日本語で書いてください。",
"max_turns": 1,
"summary_method": "last_msg",
},
]
ネストチャットのインタフェースとなる算術演算エージェントにネストチャットをハンドラとして登録する。
arithmetic_agent.register_nested_chats(
nested_chats,
# triggerで指定する関数は、送信者エージェントが指定された場合、
# エージェントがネストされたチャットを開始すべきかどうかを決定するために使用される。
# ここでは、送信者がネストされたチャットの受信者の場合に再帰的な呼び出しを避けるために
# ネストされたチャットを開始しないようにしている。
trigger=lambda sender: sender not in [group_chat_manager, code_writer_agent, poetry_agent],
)
そして最後に会話を開始するのだけども、これまで使ってきたinitiate_chat(s)ではなくて、ネストチャットの場合はgenerate_replyを使う。これにより、ネストチャットをトリガーして、ネストチャットの最後のレスポンスをサマリーとして受け取ることができる。
# initiate_chat`メソッドを使って別の会話を始める代わりに、`generate_reply`メソッドを使えば、
# メッセージに対する返信を直接受け取ることができる。
reply = arithmetic_agent.generate_reply(
messages=[{"role": "user", "content": "私が持っている数字は3です。これを13にしたいです。ステップバイステップで最短になるように計算をしてほしいです。"}]
)
実行結果
Provide feedback to the sender. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
Starting a new chat....
Arithmetic_Agent (to chat_manager):
私が持っている数字は3です。これを13にしたいです。ステップバイステップで最短になるように計算をしてほしいです。
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
6
Next speaker: Adder_Agent
Adder_Agent (to chat_manager):
7
Next speaker: Multiplier_Agent
Multiplier_Agent (to chat_manager):
14
Next speaker: Subtracter_Agent
Subtracter_Agent (to chat_manager):
13
Next speaker: Number_Agent
Number_Agent (to chat_manager):
13
Next speaker: Number_Agent
Number_Agent (to chat_manager):
13
Next speaker: Number_Agent
Number_Agent (to chat_manager):
13
Next speaker: Number_Agent
Number_Agent (to chat_manager):
13
Next speaker: Number_Agent
Number_Agent (to chat_manager):
13
Starting a new chat....
Arithmetic_Agent (to Code_Writer_Agent):
一連の計算過程を検証するためのPythonコードを書いてください。
Context:
数字3は、最初に2倍して6にし、次に1を加えて7にし、次に2倍して14にし、最後に1を減算して13にすることで、目標の数字に変換されました。
Code_Writer_Agent (to Arithmetic_Agent):
以下に要求されているPythonのスクリプトを提供します。 ここでは、最初の数字を取り、次に各ステップを順に実行して最終的な出力を得るための一連の計算を行います。
# 初期値を設定 initial_value = 3 # 処理1: 2倍 step1 = initial_value * 2 # 処理2: 1を加える step2 = step1 + 1 # 処理3: 2倍 step3 = step2 * 2 # 処理4: 1を減算する(最終結果) final_result = step3 - 1 print(final_result)このスクリプトを実行すると、結果として
13が表示されます。これにより、問題に述べられた変換過程の正当性を確認することができます。
Starting a new chat....
Arithmetic_Agent (to Poetry_Agent):
これについて一遍の詩を日本語で書いてください。
Context:
数字3は、最初に2倍して6にし、次に1を加えて7にし、次に2倍して14にし、最後に1を減算して13にすることで、目標の数字に変換されました。
問題の計算過程を検証するためのPythonコードを書きました。初期値を3に設定し、それを2倍してから1を加え、再度2倍し最後に1を引くという手順を踏んでいます。この結果、最終的な値は13となり、問題に述べられていた変換過程が正しく行われていることが確認できます。
Poetry_Agent (to Arithmetic_Agent):
三の数、数学の舞踊
わずかな優雅さ、パイソンの香りで終わり
一つに二つを加えて六つに舞い
再び一つを加えて七つへ昇天舞踊は止まらず、再び二歩踏む
十四の高みへと昇る
そして最後の一歩、余韻を残して下がる
十三、目指した場所へ到達計算の旅路、数字の響き
仮定は証明へと変わった
静かな喜び、問題解決の調べ
パイソンコードの詩、確認の終焉で終わり
フルコード
import os
import tempfile
from autogen import ConversableAgent, GroupChat, GroupChatManager
from dotenv import load_dotenv
load_dotenv(verbose=True)
llm_config = {"model": "gpt-4-0613", "api_key": os.environ["OPENAI_API_KEY"], "cache_seed": None}
# Number Agentは常に同じ数字を返す
number_agent = ConversableAgent(
name="Number_Agent",
description = "与えられた数字をそのまま返す。",
system_message="私が与えた数字を変更せずにそのまま返してください。数字以外の説明などは一切含めず、数字だけを返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Adder Agent は受け取った数字に1を足す
adder_agent = ConversableAgent(
name="Adder_Agent",
description = "与えられた数字に1を足す。",
system_message="私が与えた数字に1を足した結果を返してください。数字以外の説明や計算過程などは一切含めず、数字だけを返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Multiplier Agentは受け取った数字を2でかける
multiplier_agent = ConversableAgent(
name="Multiplier_Agent",
description = "与えられた数字に2をかける。",
system_message="私が与えた数字に2をかけた結果を返してください。数字以外の説明や計算過程などは一切含めず、数字だけを返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Subtracter Agentは受け取った数字から1引く
subtracter_agent = ConversableAgent(
name="Subtracter_Agent",
description = "与えられた数字から1を引く。",
system_message="私が与えた数字から1を引いた結果を返してください。数字以外の説明や計算過程などは一切含めず、結果の数字だけを返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Divider Agentは受け取った数字を2で割る
divider_agent = ConversableAgent(
name="Divider_Agent",
description = "与えられた数字を2で割る。",
system_message="私が与えた数字を2で割った結果を返してください。数字以外の説明や計算過程などは一切含めず、数字だけを返してください。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# `GroupChat`の設定
group_chat = GroupChat(
agents=[adder_agent, multiplier_agent, subtracter_agent, divider_agent, number_agent],
messages=[],
max_round=10,
speaker_selection_method="auto",
send_introductions=True,
)
# `GroupChatManager`の作成
group_chat_manager = GroupChatManager(
groupchat=group_chat,
llm_config=llm_config,
)
# Code Writer AgentはPythonコードを生成する
code_writer_agent = ConversableAgent(
name="Code_Writer_Agent",
system_message="あなたはコード生成器です。Markdownのコードブロックを使ってPythonのスクリプトを生成します。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Poetry Agentは詩を生成する
poetry_agent = ConversableAgent(
name="Poetry_Agent",
system_message="あなたはAIの詩人です。",
llm_config=llm_config,
human_input_mode="NEVER",
)
# Arithmetic Agentは、Nested Chatへのインタフェースとなる
# プラス、コード実行も行う
temp_dir = tempfile.gettempdir()
arithmetic_agent = ConversableAgent(
name="Arithmetic_Agent",
llm_config=False,
human_input_mode="ALWAYS", # 安全のため常に人間の入力を必要とする
code_execution_config={"use_docker": True, "work_dir": temp_dir},
)
# ネストチャットの定義
nested_chats = [
{
"recipient": group_chat_manager,
"summary_method": "reflection_with_llm",
"summary_args": {"summary_prompt":"会話から得たものを要約する。導入的なフレーズは加えないこと。"},
},
{
"recipient": code_writer_agent,
"message": "一連の計算過程を検証するためのPythonコードを書いてください。",
"summary_method": "reflection_with_llm",
"summary_args": {"summary_prompt":"会話から得たものを要約する。導入的なフレーズは加えないこと。"},
"max_turns": 1,
},
{
"recipient": poetry_agent,
"message": "これについて一遍の詩を日本語で書いてください。",
"max_turns": 1,
"summary_method": "last_msg",
},
]
# arithmetic_agentにネストチャットをハンドラとして登録
arithmetic_agent.register_nested_chats(
nested_chats,
# triggerで指定する関数は、送信者エージェントが指定された場合、
# エージェントがネストされたチャットを開始すべきかどうかを決定するために使用される。
# ここでは、送信者がネストされたチャットの受信者の場合に再帰的な呼び出しを避けるために
# ネストされたチャットを開始しないようにしている。
trigger=lambda sender: sender not in [group_chat_manager, code_writer_agent, poetry_agent],
)
# initiate_chat`メソッドを使って別の会話を始める代わりに、`generate_reply`メソッドを使えば、
# メッセージに対する返信を直接受け取ることができる。
reply = arithmetic_agent.generate_reply(
messages=[{"role": "user", "content": "私が持っている数字は3です。これを13にしたいです。ステップバイステップで最短になるように計算をしてほしいです。"}]
)
まとめ
最近は少しエージェントが気になりだしていて、いろいろ他のフレームワークを触ってみたけども(LangGraph、Burr、Langroid)、これまで触ってきたフレームワークの中でも、AutoGenはかなりわかりやすいものだと感じた。正直、自分の中ではエージェント難しいなと思っていたので結構なインパクトを感じている。
その他良かったこと
- ドキュメントがわかりやすい。自分は使わなかったけども、ドキュメントの各ページにnotebookが用意されているので、試しやすいと思う。
- ステートマシンとかグラフみたいな、プログラマチックな説明があまりなくて(Tool UseとかでPydanticを使うところ、ぐらいかなぁ、チュートリアルだと)、コンセプトとか概念的な感じでコードを書けるので、とても直感的
逆にデメリットなど
- 抽象化のレベルは高いと思う。よって、細かいところを制御しようと思うと、コードの中身を追っかける必要はまあ普通にありそう。
- ドキュメント自体わかりやすいのだけど、リファレンスが少し見にくいというか使いにくい。ここは手が追いついてないのかなと思う。
- AutoGenに限らないけども、いろいろな箇所でLLMが使用されているので、当然ながら簡単ではないし、結構ブレる。
- 自分がやってみた限りでは、gpt-4oよりもgpt-4-0613のほうが安定して動作した。このあたりはプロンプトにもよるのかなと思うけど、gpt-4-0613が一番良かったみたいな声はちらほら見かけるし、エージェント的なユースケースではまだ足りないのかなという気もちょっとしている。
- 評価とかはどうするのがいいのかなぁ、、、結構難しそう。
とりあえず、これからエージェントやってみる、特にマルチエージェント試してみたいとかなら、AutoGenから始めるってのはなかなか良さそうな印象。
自分ももう少しいろいろやってみようと思っているところ。
公式ではないがGUIがあった。といっても、エージェント作成用ではなく、作成したエージェントとChatするためのUIっぽい。ただちょっと古いね。
というか公式にもUIあった、見た目的にも良さそうなのでちょっと試してみたい。

referred from
https://github.com/microsoft/autogen/tree/main/samples/apps/autogen-studio
v0.4でアーキテクチャが新しくなるらしい