gpt-4oを試す
- GPT-4o
- テキスト、オーディオ、ビデオの入力を扱い、テキスト、オーディオ、イメージの出力が可能。
- GPT-4o以前では、ChatGPTのボイスモードが3つの異なるモデルを使用していた。
- GPT-4oはこれらの機能を一つのモデルに統合し、テキスト、ビジュアル、オーディオの各入力を同一のニューラルネットワークで処理する。
- テキスト、オーディオ、ビデオの入力を扱い、テキスト、オーディオ、イメージの出力が可能。
- 現在のAPIの能力
- 現在のAPIは、テキスト、イメージの入力とテキストの出力をサポート
- 追加のモダリティ(例えばオーディオ)は現時点(2024/5/14)では使えない。近日導入される予定
Colaboratoryで動かしてみる
インストール
!pip install --upgrade openai --quiet
!pip freeze | grep openai
openai==1.29.0
APIキー設定
from google.colab import userdata
import os
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
テキスト生成
from openai import OpenAI
def completion(client, model, query):
completion = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "あなたは親切なアシスタントです。数学の宿題を手伝うのがあなたの仕事です。"
},
{
"role": "user",
"content": query
}
],
temperature=0.1,
)
return completion.choices[0].message.content
client = OpenAI()
query = "こんにちは!2たす2を解ける?"
# gpt-4o-2024-05-13(gpt-4o)
%time print(completion(client, "gpt-4o-2024-05-13", query))
こんにちは!もちろんです。2たす2は4です。何か他に手伝えることはありますか?
CPU times: user 21 ms, sys: 2.19 ms, total: 23.2 ms
Wall time: 843 ms
参考までに他のモデル。
# gpt-4-0125-preview(gpt-4-turbo-preview)
%time print(completion(client, "gpt-4-0125-preview", query))
# gpt-4-1106-preview
%time print(completion(client, "gpt-4-1106-preview", query))
# gpt-4-0613(gpt-4)
%time print(completion(client, "gpt-4-0613", query))
# gpt-3.5-turbo-0125(gpt-3.5-turbo)
%time print(completion(client, "gpt-3.5-turbo-0125", query))
# gpt-3.5-turbo-1106
%time print(completion(client, "gpt-3.5-turbo-1106", query))
# gpt-3.5-turbo-0613
%time print(completion(client, "gpt-3.5-turbo-0613", query))
こんにちは!もちろんです。2たす2は4です。他にも質問があれば、どうぞ聞いてくださいね。
CPU times: user 43.1 ms, sys: 3.19 ms, total: 46.3 ms
Wall time: 2.24 s
こんにちは!もちろん、2 たす 2 は 4 です。他にも手伝うことがあれば、どうぞ聞いてくださいね。
CPU times: user 32.9 ms, sys: 4.11 ms, total: 37 ms
Wall time: 2.86 s
もちろんです!2たす2は4になります。他にも質問があれば何でもお答えしますよ。
CPU times: user 31.7 ms, sys: 4.89 ms, total: 36.6 ms
Wall time: 3.31 s
もちろんです!2たす2は4です。
CPU times: user 15.8 ms, sys: 2.22 ms, total: 18 ms
Wall time: 1.05 s
こんにちは!もちろんです。2たす2は4です。
CPU times: user 20.4 ms, sys: 4.23 ms, total: 24.7 ms
Wall time: 1.49 s
こんにちは!2たす2は、2 + 2 = 4 です。
CPU times: user 18.9 ms, sys: 1.97 ms, total: 20.9 ms
Wall time: 941 ms
| モデル | レスポンス(秒) |
|---|---|
| gpt-4o-2024-05-13 | 0.84 |
| gpt-4-0125-preview | 2.24 |
| gpt-4-1106-preview | 2.86 |
| gpt-4-0613 | 3.31 |
| gpt-3.5-turbo-0125 | 1.05 |
| gpt-3.5-turbo-1106 | 1.49 |
| gpt-3.5-turbo-0613 | 0.94 |
画像
同じような画像を作った
from IPython.display import Image, display, Audio, Markdown
import base64
IMAGE_PATH = "triangle.png"
display(Image(IMAGE_PATH))
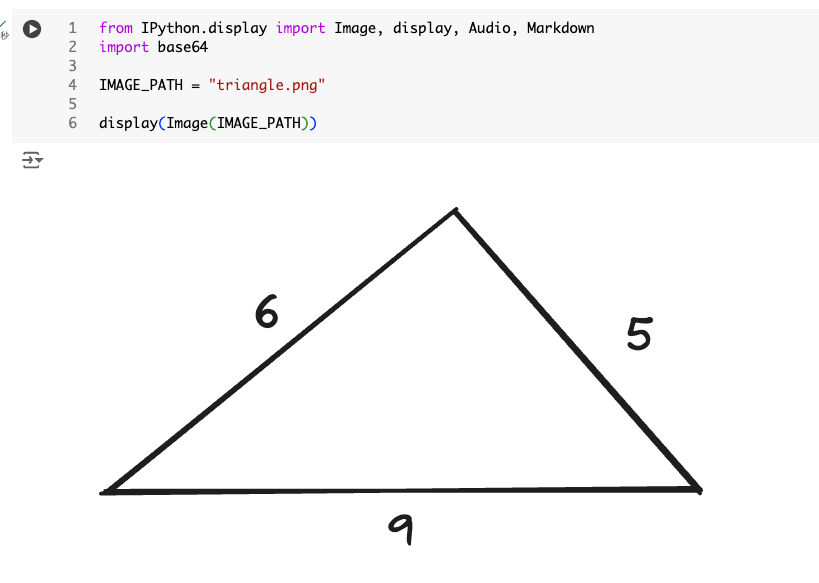
Zennで数式が表示されるようにプロンプトを作った。
%%time
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
base64_image = encode_image(IMAGE_PATH)
response = client.chat.completions.create(
model="gpt-4o-2024-05-13",
messages=[
{
"role": "system",
"content": (
"あなたは親切なアシスタントです。数学の宿題を手伝うのがあなたの仕事です。\n"
"数式を出力する場合は、KaTexを使用して記述してください。\n"
"数式を出力する場合は、数式の前後を$$で囲んで、さらにその前後に空白行をいれてください。\n"
)
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "三角形の面積は?"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
}
]
}
],
temperature=0.0,
)
print(response.choices[0].message.content)
この三角形の面積を求めるために、ヘロンの公式を使用します。ヘロンの公式は、三角形の3辺の長さがわかっている場合に面積を求める方法です。
三角形の3辺の長さを (a)、(b)、(c) とすると、半周長 (s) は次のように計算されます:
s = \frac{a + b + c}{2} この三角形の場合、(a = 5)、(b = 6)、(c = 9) ですので、
s = \frac{5 + 6 + 9}{2} = 10 次に、ヘロンの公式を使用して面積 (A) を求めます:
A = \sqrt{s(s - a)(s - b)(s - c)} これを具体的な数値に当てはめると、
A = \sqrt{10(10 - 5)(10 - 6)(10 - 9)} = \sqrt{10 \times 5 \times 4 \times 1} = \sqrt{200} = 10\sqrt{2} したがって、この三角形の面積は (10\sqrt{2}) 平方単位です。
CPU times: user 53.4 ms, sys: 6.78 ms, total: 60.2 ms
Wall time: 4.27 s
画像はURLでも指定できる
(snip)
{
"role": "user",
"content": [
{
"type": "text",
"text": "三角形の面積は?"
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/e/e2/The_Algebra_of_Mohammed_Ben_Musa_-_page_82b.png"
}
}
]
}
(snip)
動画
動画を直接理解はできないので、動画のフレームをサンプリングして画像として渡す。音声については、現時点ではまだ入力をサポートしていないため、Whisperと組みあわせる。
2つのサンプルが用意されている。
- 要約
- 質問と回答
動画の処理のためのライブラリをインストールする。必要なものは以下。
- ffmpeg
- opencv-python
- movie-py
Colaboratoryには、ffmpegが既にインストールされている。
!ffmpeg -version
ffmpeg version 4.4.2-0ubuntu0.22.04.1 Copyright (c) 2000-2021 the FFmpeg developers
built with gcc 11 (Ubuntu 11.2.0-19ubuntu1)
configuration: --prefix=/usr --extra-version=0ubuntu0.22.04.1 --toolchain=hardened --libdir=/usr/lib/x86_64-linux-gnu --incdir=/usr/include/x86_64-linux-gnu --arch=amd64 --enable-gpl --disable-stripping --enable-gnutls --enable-ladspa --enable-libaom --enable-libass --enable-libbluray --enable-libbs2b --enable-libcaca --enable-libcdio --enable-libcodec2 --enable-libdav1d --enable-libflite --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libgme --enable-libgsm --enable-libjack --enable-libmp3lame --enable-libmysofa --enable-libopenjpeg --enable-libopenmpt --enable-libopus --enable-libpulse --enable-librabbitmq --enable-librubberband --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libspeex --enable-libsrt --enable-libssh --enable-libtheora --enable-libtwolame --enable-libvidstab --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx265 --enable-libxml2 --enable-libxvid --enable-libzimg --enable-libzmq --enable-libzvbi --enable-lv2 --enable-omx --enable-openal --enable-opencl --enable-opengl --enable-sdl2 --enable-pocketsphinx --enable-librsvg --enable-libmfx --enable-libdc1394 --enable-libdrm --enable-libiec61883 --enable-chromaprint --enable-frei0r --enable-libx264 --enable-shared
libavutil 56. 70.100 / 56. 70.100
libavcodec 58.134.100 / 58.134.100
libavformat 58. 76.100 / 58. 76.100
libavdevice 58. 13.100 / 58. 13.100
libavfilter 7.110.100 / 7.110.100
libswscale 5. 9.100 / 5. 9.100
libswresample 3. 9.100 / 3. 9.100
libpostproc 55. 9.100 / 55. 9.100
opencv-python、movie-pyをインストール
!pip install opencv-python --quiet
!pip install moviepy --quiet
で今回は以下の動画を使う。"sample.mp4"とする。
動画の画像フレームと音声を分離する。
import cv2
from moviepy.editor import VideoFileClip
import time
import base64
def process_video(video_path, seconds_per_frame=2):
base64Frames = []
base_video_path, _ = os.path.splitext(video_path)
video = cv2.VideoCapture(video_path)
total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps = video.get(cv2.CAP_PROP_FPS)
frames_to_skip = int(fps * seconds_per_frame)
curr_frame=0
# ビデオをループし、指定したサンプリングレートでフレームを抽出する
while curr_frame < total_frames - 1:
video.set(cv2.CAP_PROP_POS_FRAMES, curr_frame)
success, frame = video.read()
if not success:
break
_, buffer = cv2.imencode(".jpg", frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
curr_frame += frames_to_skip
video.release()
# ビデオからオーディオを抽出する
audio_path = f"{base_video_path}.mp3"
clip = VideoFileClip(video_path)
clip.audio.write_audiofile(audio_path, bitrate="32k")
clip.audio.close()
clip.close()
print(f"Extracted {len(base64Frames)} frames")
print(f"Extracted audio to {audio_path}")
return base64Frames, audio_path
VIDEO_PATH = "sample.mp4"
# 毎秒1フレームを抽出する。seconds_per_frame`パラメータを調整してサンプリングレートを変更できる。
base64Frames, audio_path = process_video(VIDEO_PATH, seconds_per_frame=1)
MoviePy - Writing audio in sample.mp3
MoviePy - Done.
Extracted 61 frames
Extracted audio to sample.mp3
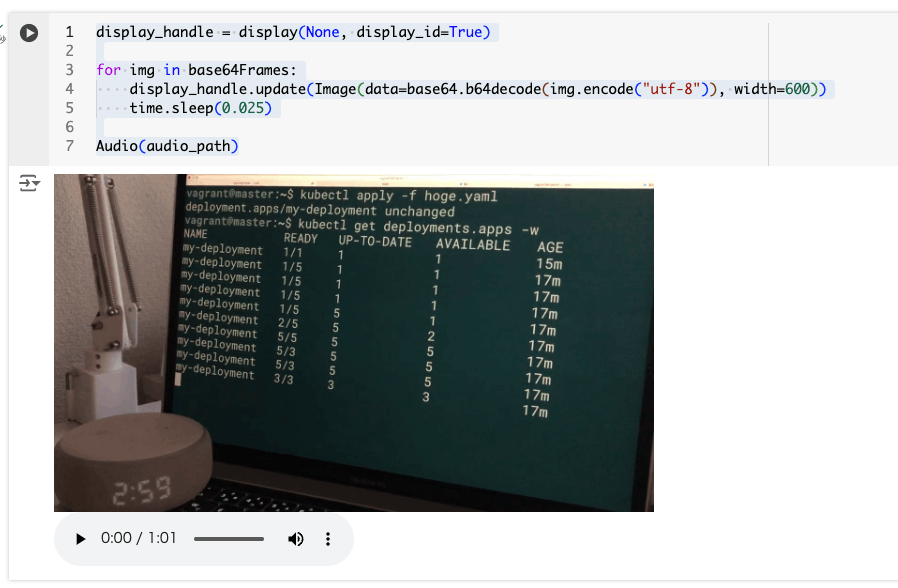
動画は61フレームの画像に、音声はsample.mp3として分割された。確認してみる。
display_handle = display(None, display_id=True)
for img in base64Frames:
display_handle.update(Image(data=base64.b64decode(img.encode("utf-8")), width=600))
time.sleep(0.1)
Audio(audio_path)
画像がGIFアニメっぽく表示されて、音声もきければOK。
要約
ではまず画像から要約。
response = client.chat.completions.create(
model="gpt-4o-2024-05-13",
messages=[
{
"role": "system",
"content": "あなたは動画の要約を作成するアシスタントです。提供された動画を元に要約を生成してください。回答はMarkdownで出力してください。"
},
{
"role": "user",
"content": [
"これらは動画のフレームです。",
*map(lambda x:
{
"type": "image_url",
"image_url": {
"url": f'data:image/jpg;base64,{x}',
"detail": "low"
}
},
base64Frames
)
],
}
],
temperature=0,
)
print(response.choices[0].message.content)
動画の要約
この動画は、Kubernetesのコマンドを使用してデプロイメントの状態を確認する様子を示しています。以下は動画のフレームごとの要約です。
- 最初のフレーム:
- コマンド
kubectl apply -f hoge.yamlが実行され、デプロイメントが適用されます。- 結果として、デプロイメントは変更されていないことが表示されます。
- 次のフレーム:
- コマンド
kubectl get deployments.apps -wが実行され、デプロイメントの状態が監視されます。- 初期状態では、1つのレプリカが稼働中で、15分経過していることが表示されます。
- その後のフレーム:
- デプロイメントのレプリカ数が増加していく様子が表示されます。
- 最初は1つのレプリカが稼働中でしたが、次第に5つのレプリカが稼働中になるまで増加します。
- 各レプリカの状態(READY、UP-TO-DATE、AVAILABLE)と経過時間(AGE)が更新されていきます。
- 最後のフレーム:
- 最終的に、5つのレプリカがすべて稼働中で、17分経過している状態が表示されます。
この動画は、Kubernetesのデプロイメント管理とその状態監視の基本的な操作を示しています。
きちんと動画内の文字列なんかも認識しているし、デプロイメントのレプリカ数の変化なんかもきちんと把握できている。
次に音声の要約。
まずWhisperで文字起こしを行う。
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=open(audio_path, "rb"),
)
print("テキスト: ", transcription.text + "\n\n")
テキスト: アレクサ、キューブコントロールを開いて。 キューブコントロールです。ポットの数を確認します。 現在、1個のポットが動いています。どうしますか? ポットを5個にセット。 ポットの数を言ってください。 5個。 成功しました。ポットの数を5個にしました。 現在、5個のポットが動いています。どうしますか? ポットを3個にセット。 成功しました。ポットの数を3個にしました。 現在、3個のポットが動いています。どうしますか? ストップ。 わかりました。また呼んでくださいね。
gpt-4oで上記の文字起こしを元に要約。
response = client.chat.completions.create(
model="gpt-4o-2024-05-13",
messages=[
{
"role": "system",
"content": "あなたは文字起こしの要約を作成するアシスタントです。提供された文字起こしのテキストを元に要約を生成してください。要約はMarkdownで出力してください。"
},
{
"role": "user",
"content": [
{
"type": "text",
"text": f"音声文字起こしの内容: {transcription.text}"
}
],
}
],
temperature=0,
)
print(response.choices[0].message.content)
### 音声文字起こしの要約 1. **キューブコントロールの起動** - ユーザーが「アレクサ、キューブコントロールを開いて」と指示。 - キューブコントロールが起動し、現在のポットの数を確認。 2. **ポットの数の変更** - 現在1個のポットが動いている状態。 - ユーザーがポットの数を5個にセットするよう指示。 - キューブコントロールが確認し、ポットの数を5個に変更。 3. **再度ポットの数の変更** - 現在5個のポットが動いている状態。 - ユーザーがポットの数を3個にセットするよう指示。 - キューブコントロールが確認し、ポットの数を3個に変更。 4. **操作の終了** - 現在3個のポットが動いている状態。 - ユーザーが「ストップ」と指示。 - キューブコントロールが操作を終了し、再度の呼び出しを促す。
では画像+音声の2つを合わせて要約する。
## Generate a summary with visual and audio
response = client.chat.completions.create(
model="gpt-4o-2024-05-13",
messages=[
{
"role": "system",
"content": "あなたは動画の要約を作成するアシスタントです。提供された動画と音声文字起こしを元に要約を生成してください。回答はMarkdownで出力してください。"
},
{
"role": "user",
"content": [
"これらは動画のフレームです。",
*map(lambda x:
{
"type": "image_url",
"image_url": {
"url": f'data:image/jpg;base64,{x}',
"detail": "low"
}
},
base64Frames
),
{
"type": "text",
"text": f"音声文字起こしの内容: {transcription.text}"
}
],
}
],
temperature=0,
)
print(response.choices[0].message.content)
動画の要約
この動画では、ユーザーが音声アシスタント(アレクサ)を使ってKubernetesのポッド数を操作する様子が示されています。以下はその詳細です:
- 初期状態:
- ユーザーはターミナルで
kubectl apply -f hoge.yamlコマンドを実行し、デプロイメントの状態を確認しています。初期状態では1個のポッドが動いています。
- 音声コマンドのやり取り:
- ユーザー: 「アレクサ、キューブコントロールを開いて。」
- アレクサ: 「キューブコントロールです。ポットの数を確認します。現在、1個のポットが動いています。どうしますか?」
- ユーザー: 「ポットを5個にセット。」
- アレクサ: 「ポットの数を言ってください。」
- ユーザー: 「5個。」
- アレクサ: 「成功しました。ポットの数を5個にしました。現在、5個のポットが動いています。どうしますか?」
- ユーザー: 「ポットを3個にセット。」
- アレクサ: 「成功しました。ポットの数を3個にしました。現在、3個のポットが動いています。どうしますか?」
- ユーザー: 「ストップ。」
- アレクサ: 「わかりました。また呼んでくださいね。」
- 結果の確認:
- ターミナルの表示が更新され、ポッドの数が5個、次に3個に変更されていることが確認できます。
この動画は、音声アシスタントを使ってKubernetesのポッド数を動的に変更するデモンストレーションを行っています。
画像フレーム、音声、それぞれ単独だと情報が足りなかったのが組み合わせることで、きちんと動画の内容を理解できている。素晴らしい。
とはいいつつも、これは今までもgpt-4-turbo(with Vision)でもできていたことなので目新しいわけではない(精度は上がっているのだろうとは思うけども)
gpt-4oは音声での入出力ができるというのが一番目新しい機能だと思うので、それがリリースされたらぜひ確認したい。
あとは精度・レスポンスというところは向上しているように感じるし、価格も下がっているので、だいぶ使いやすくなっているとは思う。
とりあえず画像認識というかOCRとしてもかなり優秀だと思える。
スクレイピングしてキャプチャした画像を読み込ませてQAやってみたけど、しっかり読み取っている。
どういうことができるか?のユースケースがここのExplorations of capabilitiesにまとまっている。
- Visual Narratives - Robot Writer’s Block
- Visual narratives - Sally the mailwoman
- Poster creation for the movie 'Detective'
- Character design - Geary the robot
- Poetic typography with iterative editing 1
- Poetic typography with iterative editing 2
- Commemorative coin design for GPT-4o
- Photo to caricature
- Text to font
- 3D object synthesis
- Brand placement - logo on coaster
- Poetic typography
- Multiline rendering - robot texting
- Meeting notes with multiple speakers
- Lecture summarization
- Variable binding - cube stacking
- Concrete poetry
トークン数も確認。
!pip install tiktoken
!pip freeze | grep tiktoken
tiktoken==0.7.0
テキストはここで使用したものを使う。
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4o")
text="""\
メロスは激怒した。必ず、かの邪知暴虐の王を除かなければならぬと決意した。メロスには政治がわからぬ。メロスは、村の牧人である。笛を吹き、羊と遊んで暮らしてきた。けれども邪悪に対しては、人一倍に敏感であった。今日未明、メロスは村を出発し、野を越え山越え、十里離れたこのシラクスの町にやって来た。メロスには父も、母もない。女房もない。十六の、内気な妹と二人暮らしだ。この妹は、村のある律儀な一牧人を、近々花婿として迎えることになっていた。結婚式も間近なのである。メロスは、それゆえ、花嫁の衣装やら祝宴のごちそうやらを買いに、はるばる町にやって来たのだ。まず、その品々を買い集め、それから都の大路をぶらぶら歩いた。メロスには竹馬の友があった。セリヌンティウスである。今はこのシラクスの町で、石工をしている。その友を、これから訪ねてみるつもりなのだ。久しく会わなかったのだから、訪ねていくのが楽しみである。
(snip)
花婿はもみ手して、照れていた。メロスは笑って村人たちにも会釈して、宴席から立ち去り、羊小屋に潜り込んで、死んだように深く眠った。\
"""
tokens = enc.encode(text)
print(len(tokens))
3489
上記の記事の価格あたりの処理可能な日本語文字数のシートを更新した。
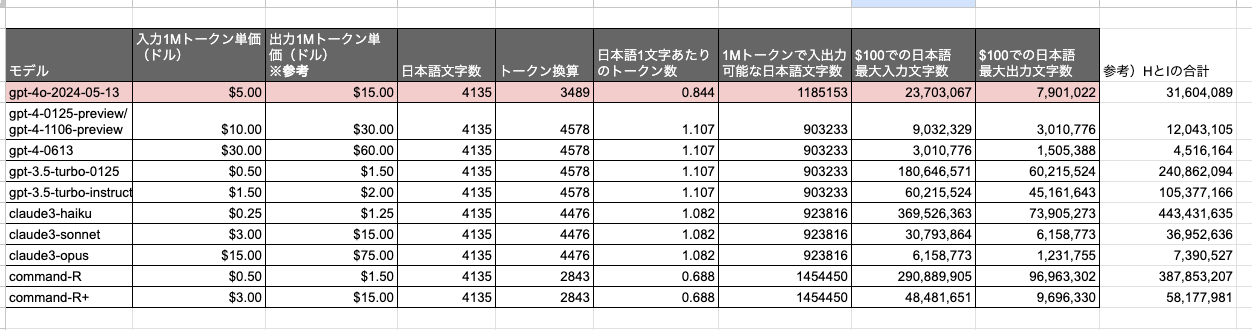
Sonnetあたりと価格帯は同じで性能はおそらく最上位クラス、で、gpt-4-turboから見ると同じコストなら2.6倍使えるって感じ
そういえば
gpt-4oは音声での入出力ができるというのが一番目新しい機能だと思うので、それがリリースされたらぜひ確認したい。
これ試してないなと思って試そうとしたけど、ちゃんと試してた
もはや過去の記憶がない