OpenAI ChatCompletions APIのオーディオ入出力を試す(gpt-4o-audio-preview)
ドキュメント
DeepL訳
オーディオ生成
テキストと画像を生成するだけでなく、一部のモデルでは、音声による応答を生成したり、音声入力を使用してモデルに指示を出すこともできます。音声入力にはテキストよりも豊富なデータを含めることができるため、モデルは入力内のトーン、抑揚、その他のニュアンスを検出することができます。
これらの音声機能を使用して、以下の操作を行うことができます。
- テキストの要約を音声で生成する(テキスト入力、音声出力)
- 録音に対して感情分析を行う(音声入力、テキスト出力)
- モデルとの非同期の音声対話(音声入力、音声出力)
Quick Startに従ってやってみる。Colaboratoryで。
パッケージインストール
!pip install openai
!pip freeze | grep openai
openai==1.52.0
APIキーをセット
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
オーディオの出力
入力はテキストで、テキスト+オーディオを出力する
import base64
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-audio-preview",
modalities=["text", "audio"],
audio={"voice": "alloy", "format": "wav"},
messages=[
{
"role": "user",
"content": "ゴールデンレトリバーは家庭犬として適していますか?"
}
]
)
gpt-4o-audio-preview ってのが今回のオーディオ入出力に対応したモデル。modalitiesってのとaudioのパラメータがある。
APIリファレンスを見ると、modalitiesで出力したいモダリティを設定する、デフォルトはtextで、gpt-4o-audio-previewで音声出力したい場合['text', 'audio']を両方指定しておけば良さそう。audioにはTTSで使う音声とフォーマットを指定する。
レスポンス全体はこんな感じ。
import json
print(json.dumps(json.loads(completion.json()), indent=2, ensure_ascii=False))
{
"id": "chatcmpl-AJWbFQKlre6KWX5WAgJiMrs55N3PZ",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": null,
"refusal": null,
"role": "assistant",
"audio": {
"id": "audio_XXXXXXXXXX",
"data": "UklGRoZVEABXQVZFZ(...snip...)",
"expires_at": 1729220513,
"transcript": "はい、ゴールデンレトリバー\nは家庭犬として非常に適しています。忠実で友好的、賢くトレーニングがしやすいです。また、子供や他のペットとも仲良く過ごせることが多いです。定期的な運動と十分な愛情が必要ですが、その見返りに素晴らしい家族の一員となってくれます。"
},
"function_call": null,
"tool_calls": null
},
"internal_metrics": []
}
],
"created": 1729216909,
"model": "gpt-4o-audio-preview-2024-10-01",
"object": "chat.completion",
"service_tier": null,
"system_fingerprint": "fp_6e2d124157",
"usage": {
"completion_tokens": 570,
"prompt_tokens": 23,
"total_tokens": 593,
"completion_tokens_details": {
"audio_tokens": 446,
"reasoning_tokens": 0,
"text_tokens": 124
},
"prompt_tokens_details": {
"audio_tokens": 0,
"cached_tokens": 0,
"cached_tokens_internal": 0,
"text_tokens": 23,
"image_tokens": 0
}
}
}
オーディオはレスポンス内のchoices[0].message.audio.dataにBASE64エンコードされて返される。choices[0].message.audio.transcriptにその文字起こしも入っているみたい。
ファイルにダウンロードするか
wav_bytes = base64.b64decode(completion.choices[0].message.audio.data)
with open("dog.wav", "wb") as f:
f.write(wav_bytes)
BASE64データをそのままColaboratoryで再生して確認するとよい
import io
from IPython.display import Audio, display
audio = Audio(wav_bytes)
display(audio)
オーディオの入力
サンプルではあらかじめ用意されたWAVファイルを取得して使っているようだけど、その場で音声を録音して投げれるようにしてみる。ChatGPTに書いてもらってもらったのを少し修正した。
from IPython.display import display, HTML
import base64
import io
import os
# 録音用のダイアログを表示する関数
def record_audio():
display(HTML('''
<button id="startBtn" onclick="startRecording()">録音開始</button>
<button id="stopBtn" onclick="stopRecording()" disabled>録音停止</button>
<audio id="audio" controls></audio>
<script>
let mediaRecorder;
let audioChunks = [];
let audioElement = document.getElementById('audio');
let startBtn = document.getElementById('startBtn');
let stopBtn = document.getElementById('stopBtn');
async function startRecording() {
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
mediaRecorder = new MediaRecorder(stream);
mediaRecorder.start();
mediaRecorder.ondataavailable = event => {
audioChunks.push(event.data);
};
startBtn.disabled = true;
stopBtn.disabled = false;
}
async function stopRecording() {
mediaRecorder.stop();
mediaRecorder.onstop = async () => {
const audioBlob = new Blob(audioChunks, { type: 'audio/wav' });
const reader = new FileReader();
reader.readAsDataURL(audioBlob); // Base64形式に変換
reader.onloadend = function() {
const base64data = reader.result.split(',')[1]; // Base64データ部分のみを取得
google.colab.kernel.invokeFunction('recordedAudio', [base64data], {});
audioElement.src = URL.createObjectURL(audioBlob); // 録音した音声を再生
};
audioChunks = [];
};
startBtn.disabled = false;
stopBtn.disabled = true;
}
</script>
'''))
# Python側で受け取る関数を定義
from google.colab import output
# 音声データを格納する変数
audio_data = None
def handle_recorded_audio(base64_audio):
global audio_data
audio_data = base64_audio # 録音された音声をBase64形式で格納
# Base64形式のデータをデコードしてファイルに保存
audio_bytes = base64.b64decode(base64_audio)
with open('tmp.wav', 'wb') as f:
f.write(audio_bytes)
# FFmpegで音声を変換
os.system("ffmpeg -y -i tmp.wav -acodec pcm_s16le -ar 44100 recorded_audio.wav")
output.register_callback('recordedAudio', handle_recorded_audio)
# 音声録音を開始
record_audio()
こんな感じで録音して、再生確認ができる。

録音されたオーディオは、recorded_audio.wavというWAVファイルに保存される。中でBASE64にしてるのでそのまま投げれるかな?と思ったけど、「WAVの形式が正しくない」と言われたので、WAVファイルに変換して出力している。
import base64
import requests
from openai import OpenAI
client = OpenAI()
with open("recorded_audio.wav", "rb") as f:
wav_data = f.read()
encoded_string = base64.b64encode(wav_data).decode('utf-8')
completion = client.chat.completions.create(
model="gpt-4o-audio-preview",
modalities=["text", "audio"],
audio={"voice": "alloy", "format": "wav"},
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "なんて言ってる?"
},
{
"type": "input_audio",
"input_audio": {
"data": encoded_string,
"format": "wav"
}
}
]
},
]
)
import io
from IPython.display import Audio, display
print(completion.choices[0].message.audio.transcript)
wav_bytes = base64.b64decode(completion.choices[0].message.audio.data)
audio = Audio(wav_bytes)
display(audio)

全然関係ないけど、ブラウザで音声の録音には上で使用しているようにmediaRecorder APIを使う。mediaRecorder APIはブラウザによって対応している音声データの形式が異なるらしく、デフォルトだとaudio/webm形式になるのが一般的らしい。今回のコードだとで以下の箇所でWAVで指定してるんだけど、どうやらそれでもダメみたい。
const audioBlob = new Blob(audioChunks, { type: 'audio/wav' });
で、実際にはどうやらwebmになってたみたいで、それをBASE64にして送ってもダメだったってことね。実はこのあたり全然わかってなくて、ちょっとハマってたりした。
ちゃんとオーディオファイルの形式とかを理解できていないのだけど、WAVでそのまま取り込めるようにしようとすると、ヘッダ処理したりとか少し手間がかかるような印象を持った。
以下は古い記事だけど今はどうなのかな?
自分のサンプルコードでは、ffmpegを使って変換しているけど、もうちょっときれいに書けると思う。
なお、入力可能な形式は以下
マルチターンで会話履歴の中に含めるには、生成されたオーディオレスポンスのIDが必要になるみたい。
最初の例だと
{
"id": "chatcmpl-AJWbFQKlre6KWX5WAgJiMrs55N3PZ",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": null,
"refusal": null,
"role": "assistant",
"audio": {
"id": "audio_XXXXXXXXXX", # ここ
"data": "UklGRoZVEABXQVZFZ(...snip...)",
"expires_at": 1729220513,
"transcript": "はい、ゴールデンレトリバー\nは家庭犬として非常に適しています。忠実で友好的、賢くトレーニングがしやすいです。また、子供や他のペットとも仲良く過ごせることが多いです。定期的な運動と十分な愛情が必要ですが、その見返りに素晴らしい家族の一員となってくれます。"
},
"function_call": null,
"tool_calls": null
},
"internal_metrics": []
}
],
(snip)
これをmessagesで指定する。
"messages": [
{
"role": "user",
"content": "ゴールデンレトリバーは家庭犬として適していますか?"
},
{
"role": "assistant",
"audio": {
"id": "audio_XXXXXXXXXX"
}
},
{
"role": "user",
"content": "どういう理由でそういえますか?"
}
]
なるほど、expires_atはおそらく音声レスポンスがキャッシュされてるのではないかと推測。
ユースケースがあるわけではないけど、例えば、こういうことはできないのかな?
- 入力はテキスト、例えば論文の内容とかとする
- 出力は音声とテキスト
- 音声は論文の内容をポッドキャスト風音声にする
- 出力は論文の内容の要約をMarkdownにする
音声の文字起こしはついてくるみたいだけど、別々のものを返せるといろいろ面白そうなんだけど。
まとめ
ドキュメントにも書いてあるけど、単なるTTS・STTでいいならばそっちのモデルを使ったほうが対費用効果は良いということなので、そうじゃないユースケースでの活用で使うことになるね。
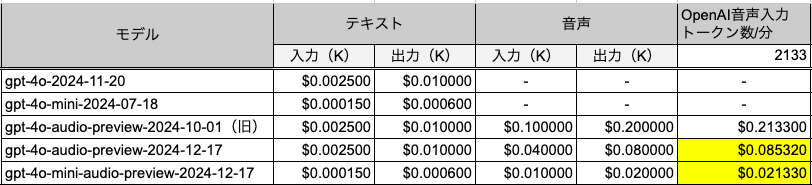
料金
gpt-4o-audio-preview-2024-10-01
- テキスト
- 入力: $2.50 / 1Mトークン
- 出力: $10.00 / 1Mトークン
- オーディオ
- 入力: $100.00 / 1Mトークン
- 出力$200.00 / 1Mトークン
料金の目安が注釈にある
音声入力は1分あたり約6セント、音声出力は1分あたり約24セントかかります。
オーディオ部分だけ見るとRealtime APIと同じだねぇ。
んー、この注釈がいつのまにやら見当たらなくなっている・・・
料金の目安が注釈にある
音声入力は1分あたり約6セント、音声出力は1分あたり約24セントかかります。
オーディオ部分だけ見るとRealtime APIと同じだねぇ。
ここのFAQには
モデルへの音声入力について、トークンで考えるとどうなるでしょうか?
この点を明らかにするためのより優れたツールの開発に取り組んでいますが、音声入力のおよそ1時間分が、このモデルで現在サポートされている最大コンテクストウィンドウである128kトークンに相当します。
とある。
モデルも新しくなっているので、最新のものだけあらためて。単位を1Kトークンにして、オーディオ入力1分あたりの料金を算出してみた。