Pineconeでハイブリッド検索を試してみる
よくあるベクトルDBを使ったRAGを構築してみたのだけど、元となるデータによっては単純なベクトル検索では期待するドキュメントをうまく拾えない場合があった。
このような場合、キーワード検索とベクトル検索を組み合わせたハイブリッド検索で解決できる可能性があるらしい。
ざっと調べてみた限り、ハイブリッド検索はAzure Cognitve Servie, Pinecone, Weaviate, Elastic Searchあたりでサポートされている。
今回はPineconeを試してみる。
なお、Pineconeそのものを触ったことがないので基本的なところから順番にやっていく。環境はColaboratoryで。
まずQuickstartを写経していく。
インストールと設定
PineconeのPythonクライアントをインストール
!pip install pinecone-client
APIキーと環境を確認しておく。Pineconeにログインして「API Keys」を開くと確認できる。
上記をセット。
import pinecone
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")
warningが出るけど一旦気にしない。
/usr/local/lib/python3.10/dist-packages/pinecone/index.py:4: TqdmExperimentalWarning: Using `tqdm.autonotebook.tqdm` in notebook mode. Use `tqdm.tqdm` instead to force console mode (e.g. in jupyter console)
from tqdm.autonotebook import tqdm
インデックスのリストを取得してみるが、インデックスはまだ作ってないので何も表示されない。
pinecone.list_indexes()
[]
インデックスの作成
インデックスを作成していく。データについては、最初に紹介したQiitaの記事で紹介されている以下のデータを使う。
!wget https://d.line-scdn.net/stf/linecorp/ja/csr/dataset_.zip
!unzip dataset_.zip
Excelファイルが展開される。
['Archive: dataset_.zip', ' inflating: dataset_.xlsx ']
Pandasで読み込む。
import pandas as pd
df = pd.read_excel("dataset_.xlsx")
df
こんな感じのデータが読み込まれる。
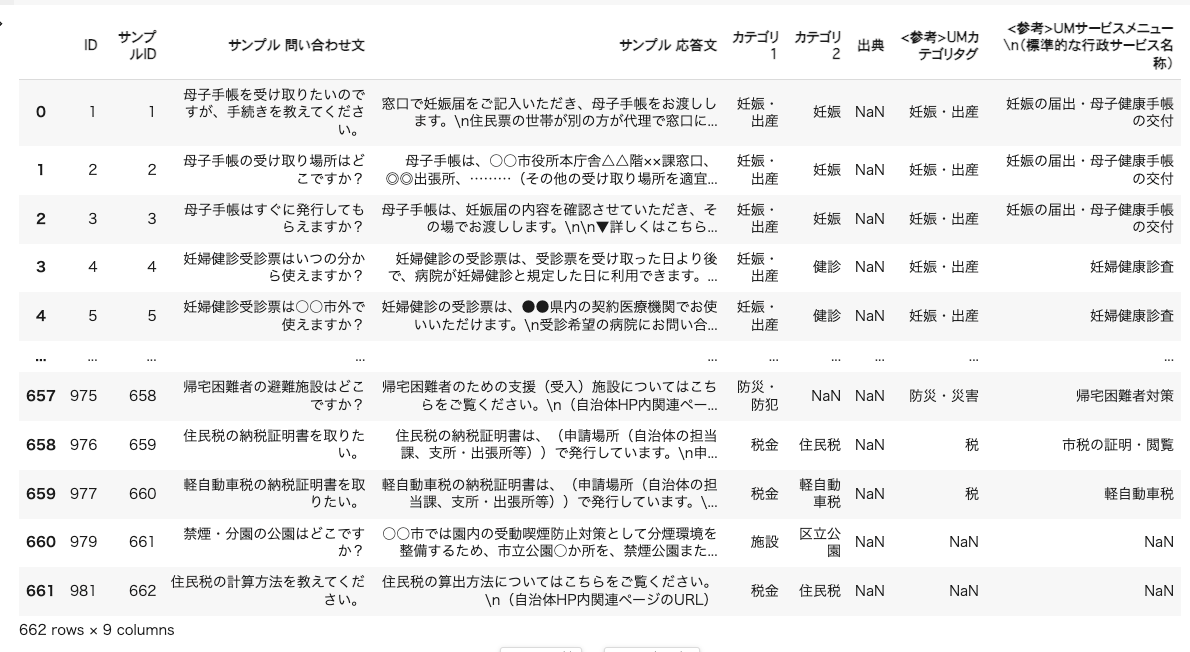
列名が扱いづらいので一旦変更する。
df.rename(columns={
'サンプルID': 'SampleID',
'サンプル 問い合わせ文': 'Q',
'サンプル 応答文': 'A',
'カテゴリ1': 'cat1',
'カテゴリ2': 'cat2',
'出典': 'ref',
'<参考>UMカテゴリタグ': 'tag',
'<参考>UMサービスメニュー\n(標準的な行政サービス名称)': 'Service'
}, inplace=True)
df

一応各列にNaNがどの程度含まれているか確認しておく。
df.isnull().sum()
ID 0
SampleID 0
Q 0
A 0
Cat1 0
Cat2 31
Ref 662
Tag 225
Service 225
dtype: int64
カテゴリ2以降のデータにはNaNが含まれていることがわかる。メタデータ等で使いたい場合には注意する必要があるということだけ理解しておいて、とりあえず今は一旦このままでおいておく。
でQAの場合はもう少しデータをいじりたいところなのだが、まずはPineconeを使ってみることを優先して、一旦このままで進める。
次にEmbeddingsを作成する。PineconeはあくまでもEmbeddingsの箱なので、Embeddingsを作成してくれるわけではない。OpenAIのEmbeddings APIを使ってEmbeddingsを作成する。
OpenAIパッケージをインストールする
!pip install openai
Embeddingsを取得する関数を用意する。
import openai
openai.api_key = "sk-XXXXXXXXX"
def get_embeddings_openai(text):
response = openai.Embedding.create(
input=text,
model="text-embedding-ada-002"
)
return response["data"][0]["embedding"]
Pandasのデータフレームの"A"列に対して、この関数を適用して、"A_embeddings"列にEmbeddingsを入れる。ちなみにtqdmのprogress_applyを使うと、Pandasのapplyに対して進捗を表示できて便利!
from tqdm.notebook import tqdm
tqdm.pandas()
df["A_embeddings"] = df["A"].progress_apply(lambda x: get_embedding(x))
df
ではこのデータを使ってPineconeにインデックスを作成する。以下の内容で。
- インデックス名は"quickstart"にした。
- 次元数は1536。これはOpenAI Embeddingsが1536次元になっているため。
- metricは、類似度の尺度というか計算方法。'euclidean', 'cosine', 'dotproduct' から選択できる。一般的には文章の場合はコサイン類似度が使用されることが多いらしい。
pinecone.create_index("quickstart", dimension=1536, metric="cosine")
pinecone_index = pinecone.Index("quickstart")
pinecone.list_indexes()
quickstartインデックスが作成された
['quickstart']
GUIでも確認できる。
ではEmbeddingsを投入する。
- idはユニークな文字列を指定する。ここではデータフレームの"ID"列を使う。
- valuesにEmbeddingsを指定
- metadataに付与するメタデータを指定する。ここでは検索の結果として得られる回答文とあとカテゴリを指定してみた。
for index, row in tqdm(df.iterrows(), total=df.shape[0]):
pinecone_index.upsert(
vectors = [
{
'id': str(row["ID"]),
'values': row["A_embeddings"],
'metadata': {"Answer": row["A"], "Category": row["Cat1"]}
}
]
)
インデックスの状態を見てみる。
pinecone_index.describe_index_stats()
662件のデータが入っていることがわかる。
{'dimension': 1536,
'index_fullness': 0.0,
'namespaces': {'': {'vector_count': 662}},
'total_vector_count': 662}
GUIでも確認できる。
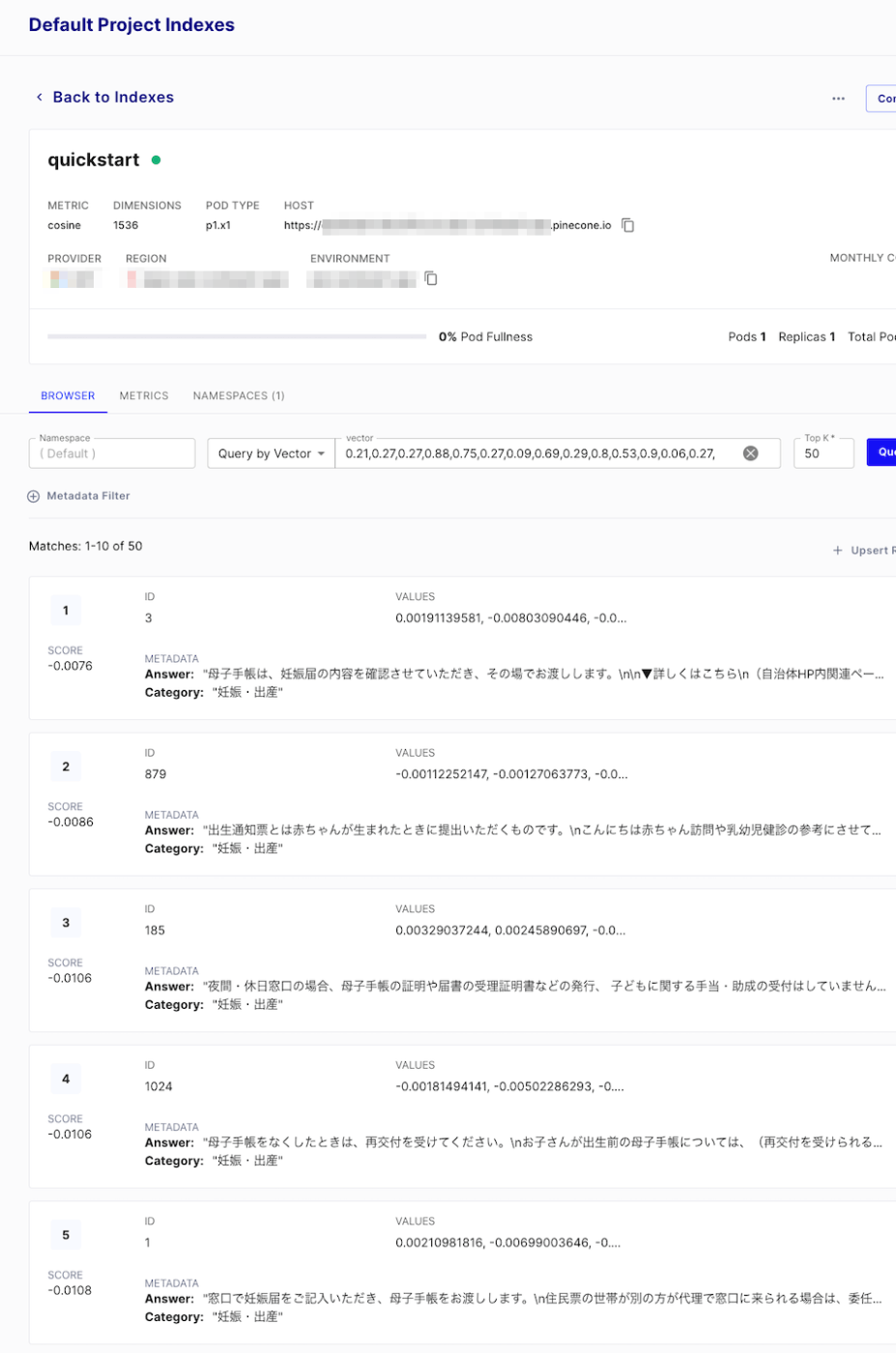
セマンティック検索
では検索してみる。
query = "母子手帳を受け取りたいのですが、手続きを教えてください。"#@param {type:"string"}
query_vector = get_embedding(query)
pinecone_index.query(
vector=query_vector,
top_k=10,
include_metadata=True
)
結果
{'matches': [{'id': '37',
'metadata': {'Answer': '母子手帳の申請には診断書はいりませんが、妊娠届に診断を受けた病院名・医師名を記入していただきます。',
'Category': '妊娠・出産'},
'score': 0.904983163,
'values': []},
{'id': '3',
'metadata': {'Answer': '母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.899657249,
'values': []},
{'id': '1024',
'metadata': {'Answer': '母子手帳をなくしたときは、再交付を受けてください。\n'
'お子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。\n'
'お子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。\n'
'申請の際はご本人確認できるものをお持ちください。\n'
'\n'
'◆お問い合わせ\n'
'(自治体の担当課等の名称)\n'
'(電話番号)/(開庁時間)',
'Category': '妊娠・出産'},
'score': 0.891071,
'values': []},
{'id': '36',
'metadata': {'Answer': '産前は母子手帳以外の手続きは特にありません。\n'
'産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。',
'Category': '妊娠・出産'},
'score': 0.888703644,
'values': []},
{'id': '2',
'metadata': {'Answer': '母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.87811625,
'values': []},
{'id': '396',
'metadata': {'Answer': '妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.875171483,
'values': []},
{'id': '185',
'metadata': {'Answer': '夜間・休日窓口の場合、母子手帳の証明や届書の受理証明書などの発行、 '
'子どもに関する手当・助成の受付はしていませんので、通常窓口で手続き・申請してください。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.872382224,
'values': []},
{'id': '280',
'metadata': {'Answer': '私立幼稚園の補助金の振込先口座は、申請書に記載されている保護者欄が一致していれば、父と母どちらでも可能です。',
'Category': '学校・教育'},
'score': 0.869726658,
'values': []},
{'id': '1082',
'metadata': {'Answer': '母子手帳は住所が変わってもそのままお使いいただけます。再発行等の手続は必要ありません。\n'
'\n'
'◆お問い合わせ\n'
'(自治体の担当課や子育てセンター等の名称)\n'
'(電話番号)/(開庁時間)',
'Category': '妊娠・出産'},
'score': 0.868921161,
'values': []},
{'id': '1',
'metadata': {'Answer': '窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n'
'住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.865602076,
'values': []}],
'namespace': ''}
それっぽい検索ができているように見える。ただし実際にはこの質門に対して期待する回答は、検索結果10番目のデータがそれなので、検索上限が5件ぐらいだとヒットしないことになる。少し微妙である。
これについてはデータのもたせ方等にもよるので、後述。
検索フィルタ
メタデータでフィルタすることもできる。
query = "母子手帳を受け取りたいのですが、手続きを教えてください。"#@param {type:"string"}
category = "\u30AB\u30C6\u30B4\u30EA\u30FC\u3092\u9078\u629E" #@param ['カテゴリーを選択', '妊娠・出産', '健診・予防接種', '子どもの手当・助成', '施設', '保育', '採用・職員情報', '住民票・戸籍・印鑑証明', '健康・医療', '子育て・子ども家庭支援', '学校・教育', '商工・労働・相談', 'ごみ・リサイクル', '暮らしに役立つ情報', '区の紹介', '地域', '保険・年金', '女性相談', '生涯学習・スポーツ', '税金', '防災・防犯', '観光・イベント', '施策・計画・取り組み', '渋谷区LINE公式アカウントについて', '環境衛生', '障害者', '広報', '高齢者・介護と福祉サービス', '暮らしに関する相談'] {allow-input: false}
query_vector = get_embedding(query)
if category != "カテゴリーを選択":
filter = {
"Category": {"$eq": category},
}
else:
filter = {}
pinecone_index.query(
vector=query_vector,
top_k=10,
include_metadata=True,
filter=filter
)
Unicodeエンコードされているのでちょっと見えにくいけど、上は「カテゴリーを選択」が選ばれている=カテゴリーが選択されていない場合。結果は先程と同じになる。

カテゴリを選択すると結果が変わる。つまりフィルタが効いている。

それっぽい検索ができているように見える。ただし実際にはこの質門に対して期待する回答は、検索結果10番目のデータがそれなので、検索上限が5件ぐらいだとヒットしないことになる。少し微妙である。
これについてはデータのもたせ方等にもよるので、後述。
上で見てもらった通り、必ずしもQとAが一致するわけではない。この辺は以下がわかりやすい。
単純なベクトル検索では、「ユーザの質問のベクトル」と「ドキュメントを分割したテキストのベクトル」を比較することで類似度を計算しますが、以下の点が問題になる可能性があります。
- 比較する文章同士の種類があっていない
類似度を計算するということは、比較するもの同士の種類が合っていることが前提になるはずです。説明文と説明文の比較はできるはずですが、ユーザの質問とドキュメント内の説明文の比較は少しズレた種類を比較していると言え、精度が下がる原因になりそうです。例えば、質問のテキストでは「〇〇についてわからないのですが、どうしたら良いか教えてください」のように書かれ、社内文章などの文章では「〇〇の方法」「〇〇の際は以下から手続きしてください」のように書かれていることが想定され、文体などが異なることが多そうです。
(→ 比較する文章を揃える方が良い)
例を挙げると、以下のような質問がある。
母子手帳を受け取りたいのですが、手続きを教えてください。
これに対し、期待している回答、つまりベクター化したデータは以下となっていて、検索結果の類似度のランキングでは10位になっていた。
窓口で妊娠届をご記入いただき、母子手帳をお渡しします。
住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。
▼詳しくはこちら
(自治体HP内関連ページのURL)
実際に上位5件に来ていた回答は以下のようなものだった。
母子手帳の申請には診断書はいりませんが、妊娠届に診断を受けた病院名・医師名を記入していただきます。
母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。
母子手帳をなくしたときは、再交付を受けてください。
お子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。
お子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。
申請の際はご本人確認できるものをお持ちください。
◆お問い合わせ
(自治体の担当課等の名称)
(電話番号)/(開庁時間)
産前は母子手帳以外の手続きは特にありません。
産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。
母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。
▼詳しくはこちら
(自治体HP内関連ページのURL)
上位5件はパッと見てもどれも間違っているわけではない。質門は「母子手帳」「受け取り」「手続き」というトピックのどれかもしくは複数に関連しているものであり、ベクター検索上はこちらのほうが上位になったということになる。
ここまでは定性的・属人的な判断だったので、定量的に見てみたいと思う。すべての質問をベクトル検索した場合、本来期待していた回答がランキングの何番目に出てくるか?をざっと算出してみる。
test_df = df.copy() # 元のデータフレームを触りたくなかったので複製した。
for index, row in tqdm(test_df.iterrows(), total=test_df.shape[0]):
query_vector = get_embedding(row["Q"])
result = pinecone_index.query(
vector=query_vector,
top_k=999,
include_metadata=True
)
match_rank = 999
for i, v in enumerate(result["matches"]):
if row["A"] == v["metadata"]["Answer"]:
match_rank = i+1
break
test_df.loc[test_df["ID"] == row["ID"], "rank01"] = match_rank
test_df
結果はこんな感じ。"rank01"列に検索ランクが追加されている。

これをPlotlyでグラフで表してみる。
!pip install plotly
import plotly.graph_objects as go
# 値の頻度を計算して、値デソート
value_counts = test_df['rank01'].value_counts()
value_counts = value_counts.sort_index()
# 11位以上の場合は「その他」でひとまとめにする
mask = value_counts.index >= 11
tail = value_counts[mask].sum()
value_counts = value_counts[~mask]
value_counts['その他'] = tail
# サイズでソートされないようにグラフ描画
fig = go.Figure(go.Pie(labels=value_counts.index, values=value_counts, hole=0.3, direction="clockwise", sort=False))
fig.show()
こんな感じになる。
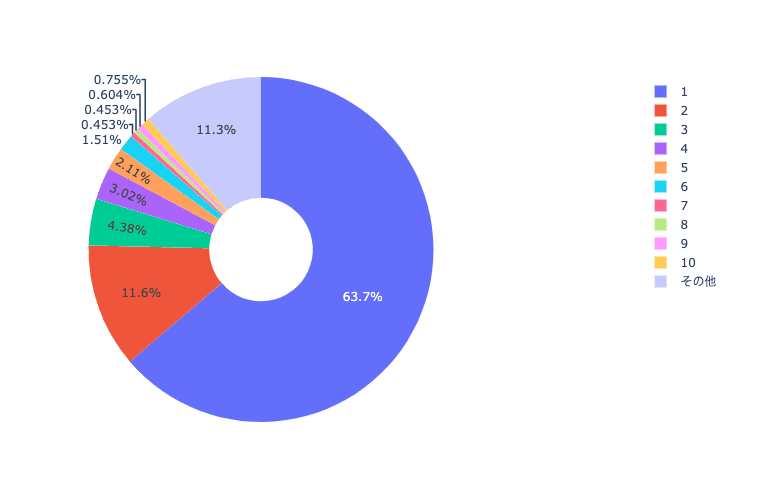
検索結果の上限が5件の場合だと85%、10件の場合だと88.7%ということになった。
精度が90%未満というのは正直物足りないし、RAGではこの部分をプロンプトに含めることになるので検索上限を増やしてトークンを消費するのも微妙。
ということでいろいろ工夫してみる。
パターン1
QとAはそもそも文章としては異なるので類似度が下がるということであれば、Qそのものをベクトル化してAはメタデータに紐づけて引っ張ってくればいいという考え方ができる。これならば質門=ベクトルデータなので類似性はかなり高いはずと考えられる。
母子手帳を受け取りたいのですが、手続きを教えてください。
に対して、これをそのままベクトル化して、以下の回答はメタデータにする。
窓口で妊娠届をご記入いただき、母子手帳をお渡しします。
住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。
▼詳しくはこちら
(自治体HP内関連ページのURL)
QからEmbeddingsを作る。
df["Q_embeddings"] = df["Q"].progress_apply(lambda x: get_embedding(x))
これをPineconeに突っ込む。
for index, row in tqdm(df.iterrows(), total=df.shape[0]):
pinecone_index.upsert(
vectors = [
{
'id': str(row["ID"]),
'values': row["Q_embeddings"],
'metadata': {"Answer": row["A"], "Category": row["Cat1"]}
}
]
)
検索してみる
query = "母子手帳を受け取りたいのですが、手続きを教えてください。"#@param {type:"string"}
query_vector = get_embedding(query)
pinecone_index.query(
vector=query_vector,
top_k=10,
include_metadata=True
)
結果。想像通り、検索結果の1位として上がってくる。当然ながら類似度もかなり高い。
{'matches': [{'id': '1',
'metadata': {'Answer': '窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n'
'住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.999996126,
'values': []},
{'id': '2',
'metadata': {'Answer': '母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.932579935,
'values': []},
{'id': '3',
'metadata': {'Answer': '母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.91920042,
'values': []},
{'id': '36',
'metadata': {'Answer': '産前は母子手帳以外の手続きは特にありません。\n'
'産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。',
'Category': '妊娠・出産'},
'score': 0.913755536,
'values': []},
{'id': '37',
'metadata': {'Answer': '母子手帳の申請には診断書はいりませんが、妊娠届に診断を受けた病院名・医師名を記入していただきます。',
'Category': '妊娠・出産'},
'score': 0.91365087,
'values': []},
{'id': '1024',
'metadata': {'Answer': '母子手帳をなくしたときは、再交付を受けてください。\n'
'お子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。\n'
'お子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。\n'
'申請の際はご本人確認できるものをお持ちください。\n'
'\n'
'◆お問い合わせ\n'
'(自治体の担当課等の名称)\n'
'(電話番号)/(開庁時間)',
'Category': '妊娠・出産'},
'score': 0.909973323,
'values': []},
{'id': '69',
'metadata': {'Answer': '児童手当を受けるには、認定請求が必要です。\n'
'まず、○○市のホームページより「児童手当・特例給付 '
'認定請求書」をダウンロードしてご記入ください。\n'
'必要書類を添付し、(自治体の担当課等の名称)へ郵送又はご持参ください。\n'
'\n'
'【提出先】\n'
'(自治体の担当課等の名称、場所、郵送する場合の宛名及び住所等)\n'
'\n'
'必要書類等は以下のとおりです。\n'
'①請求者名義の金融機関の口座番号がわかるもの\n'
'②請求者と配偶者の「住民税課税(非課税)証明書」\n'
'③印鑑(朱肉を使うもの)\n'
'④請求者が厚生年金加入者(被用者)の場合は、「厚生年金加入証明書」\n'
'\u3000'
'(「健康保険証のコピー」で代えることもできます。)\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000\u3000'
'*状況によってはその他の書類が必要になる場合があります。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)\n'
'\n'
'◆お問い合わせ\n'
'(自治体の担当課等の名称)\n'
'(電話番号)/(開庁時間)',
'Category': '子どもの手当・助成'},
'score': 0.906975746,
'values': []},
{'id': '71',
'metadata': {'Answer': '1.転出される自治体に児童手当の消滅届を提出\n'
'2.○○市に転入届を提出\n'
'3.(自治体の担当課等の名称)へ「児童手当・特例給付\u3000'
'認定請求書」を提出\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)\n'
'\n'
'◆お問い合わせ\n'
'(自治体の担当課等の名称)\n'
'(電話番号)/(開庁時間)',
'Category': '子どもの手当・助成'},
'score': 0.906440616,
'values': []},
{'id': '77',
'metadata': {'Answer': 'お子さまが海外留学する場合、「児童手当等に係る海外留学に関する申立書」と在学証明書等留学の事実を証明する書類〔書類が外国語のものは、親族以外の第三者の方が訳した翻訳書(訳者の署名・押印あり)〕が必要です。\n'
'\n'
'◆お問い合わせ\n'
'(自治体の担当課等の名称)\n'
'(電話番号)/(開庁時間)',
'Category': '子どもの手当・助成'},
'score': 0.905123651,
'values': []},
{'id': '1082',
'metadata': {'Answer': '母子手帳は住所が変わってもそのままお使いいただけます。再発行等の手続は必要ありません。\n'
'\n'
'◆お問い合わせ\n'
'(自治体の担当課や子育てセンター等の名称)\n'
'(電話番号)/(開庁時間)',
'Category': '妊娠・出産'},
'score': 0.904652357,
'values': []}],
'namespace': ''}
定量的にチェックしてみる。
test_df = df.copy()
for index, row in tqdm(test_df.iterrows(), total=test_df.shape[0]):
query_vector = get_embedding(row["Q"])
result = pinecone_index.query(
vector=query_vector,
top_k=999,
include_metadata=True
)
match_rank = 999
for i, v in enumerate(result["matches"]):
if row["A"] == v["metadata"]["Answer"]:
match_rank = i+1
break
test_df.loc[test_df["ID"] == row["ID"], "rank02"] = match_rank
import plotly.graph_objects as go
value_counts = test_df['rank02'].value_counts()
value_counts = value_counts.sort_index()
mask = value_counts.index >= 11
tail = value_counts[mask].sum()
value_counts = value_counts[~mask]
value_counts['その他'] = tail
fig = go.Figure(go.Pie(labels=value_counts.index, values=value_counts, hole=0.3, direction="clockwise", sort=False))
fig.show()
結果
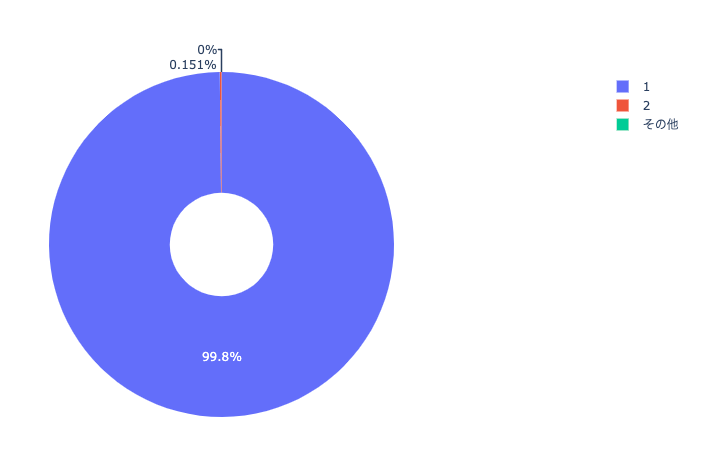
質門そのものがベクトル化されているので、当然といえば当然。(むしろ1位じゃないやつがある方がおかしいと思ってみてみたら、全く同じ質問だけど回答が微妙に違うQAがあったための様子)
ただし、質門と回答を比較した場合、回答が持つコンテキストは質門が持つコンテキストに比べてとても大きい。つまり質門をベクトル化した場合には、この回答が持つ豊富なコンテキストが使われない可能性が高く、予め用意した質門以外には弱かったりという可能性が考えられる。
例えば
幼稚園は何歳からですか?
という質門に紐づいている回答は以下で、上記の通り質問すればこれが1位になる。
○○市では、市立幼稚園に入園できるのは4歳児(2年保育)と5歳児(1年保育)です。
▼市立幼稚園について
(自治体HP内関連ページのURL)
私立幼稚園の場合、原則として3歳児から最長3年保育が可能です。詳しくは入園を希望する幼稚園へお問い合わせください。
▼私立幼稚園一覧
(自治体HP内関連ページのURL)
が、例えば、
3年保育が可能な幼稚園を教えてください。
というような、回答に含まれている他の情報を聞いた場合、
{'matches': [{'id': '317',
'metadata': {'Answer': '○○市内には市立幼稚園が×(←市立幼稚園数)園あります。詳しくはこちらをご覧ください。\n'
'(自治体HP内関連ページのURL)',
'Category': '施設'},
'score': 0.925715148,
'values': []},
{'id': '249',
'metadata': {'Answer': '(利用可能日時を記載してください。)\n'
'例「市立保育園の一時保育を利用時間は、月曜日から金曜日の9時~18時の間で8時間以内です。(土曜日・日曜日・祝日・年末年始を除く)\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)」',
'Category': '保育'},
'score': 0.91958952,
'values': []},
{'id': '180',
'metadata': {'Answer': 'お近くの幼稚園は、こちらからお探しください。\n'
'(自治体HP内関連ページのURL)',
'Category': '学校・教育'},
'score': 0.919260681,
'values': []},
{'id': '331',
'metadata': {'Answer': '(位置情報を利用して近隣の施設を検索する機能がある場合は、検索方法を記載してください。)\n'
'例「お近くの保育園は、メニューの周辺施設検索より探すことができます。周辺施設検索をタップして位置情報を送ってください。」',
'Category': '保育'},
'score': 0.918168,
'values': []},
{'id': '286',
'metadata': {'Answer': '○○市内の私立幼稚園では、○○、●●において、満3歳児クラスがあります。',
'Category': '学校・教育'},
'score': 0.917359352,
'values': []},
{'id': '905',
'metadata': {'Answer': '○○公園が(地域名)×丁目にあります。(公園の特徴等を記載してください。)\n'
'\n'
'▼○○公園\n'
'(自治体HP内関連ページのURL)',
'Category': '施設'},
'score': 0.915989757,
'values': []},
{'id': '308',
'metadata': {'Answer': '(保育園の申し込み方法を記載してください。)\n'
'例「認可保育園への入園を希望する場合は、○○課で申し込みをしてください。\n'
'なお、申し込みには希望する保育園を記入した申込書や保護者の就労証明書などが必要となります。\n'
'詳しくはこちらをご覧ください。\n'
'(自治体HP内関連ページのURL)」',
'Category': '保育'},
'score': 0.914087832,
'values': []},
{'id': '246',
'metadata': {'Answer': '市立保育園の一時保育の利用対象者は、(対象者を記載してください。例「市内在住で生後57日目から小学校就学前までの健康で集団保育が可能な児童」)が対象となります。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '保育'},
'score': 0.913414061,
'values': []},
{'id': '370',
'metadata': {'Answer': '○○市内の保育園についてはこちらをご覧ください。\n'
'(自治体HP内関連ページのURL)',
'Category': '保育'},
'score': 0.909635186,
'values': []},
{'id': '389',
'metadata': {'Answer': '認可保育園には市立保育園、私立保育園、認定こども園があります。\n'
'詳しい一覧はこちらをご覧ください。\n'
'(自治体HP内関連ページのURL)',
'Category': '保育'},
'score': 0.90948838,
'values': []}],
'namespace': ''}
という感じで、期待していた回答は得られないという次第。
今回は、試していないけど、LLMを使ってAのコンテキストに基づいた質門をランダムに生成して、それで評価してみると良いと思う。
パターン2
入力内容とQの類似度も確保しつつ、Aのコンテキストも活かすやり方として、QとAを結合する。具体的には、
以下のQと
母子手帳を受け取りたいのですが、手続きを教えてください。
以下のAを
窓口で妊娠届をご記入いただき、母子手帳をお渡しします。
住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。
▼詳しくはこちら
(自治体HP内関連ページのURL)
結合してこれをEmbeddings化する。
Q: 母子手帳を受け取りたいのですが、手続きを教えてください。
A: 窓口で妊娠届をご記入いただき、母子手帳をお渡しします。
住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。
▼詳しくはこちら
(自治体HP内関連ページのURL)
こんな感じ。
df["QA"] = "Q: " + df["Q"] + "\nA: " + df["A"]
df["QA_embeddings"] = df["QA"].progress_apply(lambda x: get_embedding(x))
あとはこれまでと同じようにPineconeに突っ込んで検索してみる。
for index, row in tqdm(df.iterrows(), total=df.shape[0]):
pinecone_index.upsert(
vectors = [
{
'id': str(row["ID"]),
'values': row["QA_embeddings"],
'metadata': {"Answer": row["A"], "Category": row["Cat1"]}
}
]
)
query = "母子手帳を受け取りたいのですが、手続きを教えてください。"#@param {type:"string"}
query_vector = get_embedding(query)
pinecone_index.query(
vector=query_vector,
top_k=10,
include_metadata=True
)
結果。1位で出てきた。
{'matches': [{'id': '1',
'metadata': {'Answer': '窓口で妊娠届をご記入いただき、母子手帳をお渡しします。\n'
'住民票の世帯が別の方が代理で窓口に来られる場合は、委任状が必要になります。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.906402826,
'values': []},
{'id': '1024',
'metadata': {'Answer': '母子手帳をなくしたときは、再交付を受けてください。\n'
'お子さんが出生前の母子手帳については、(再交付を受けられる場所)で再交付を受けられます。\n'
'お子さんが出生後の母子手帳については、(再交付を受けられる場所)で受けられます。\n'
'申請の際はご本人確認できるものをお持ちください。\n'
'\n'
'◆お問い合わせ\n'
'(自治体の担当課等の名称)\n'
'(電話番号)/(開庁時間)',
'Category': '妊娠・出産'},
'score': 0.884627819,
'values': []},
{'id': '2',
'metadata': {'Answer': '母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)………で受け取れます。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.883319199,
'values': []},
{'id': '37',
'metadata': {'Answer': '母子手帳の申請には診断書はいりませんが、妊娠届に診断を受けた病院名・医師名を記入していただきます。',
'Category': '妊娠・出産'},
'score': 0.88268131,
'values': []},
{'id': '36',
'metadata': {'Answer': '産前は母子手帳以外の手続きは特にありません。\n'
'産後に、出生の届出や出生通知書の提出、(自治体が行う出産助成等)の申請をお願いします。',
'Category': '妊娠・出産'},
'score': 0.882636547,
'values': []},
{'id': '396',
'metadata': {'Answer': '妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.882166386,
'values': []},
{'id': '3',
'metadata': {'Answer': '母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.880061,
'values': []},
{'id': '1082',
'metadata': {'Answer': '母子手帳は住所が変わってもそのままお使いいただけます。再発行等の手続は必要ありません。\n'
'\n'
'◆お問い合わせ\n'
'(自治体の担当課や子育てセンター等の名称)\n'
'(電話番号)/(開庁時間)',
'Category': '妊娠・出産'},
'score': 0.876639783,
'values': []},
{'id': '185',
'metadata': {'Answer': '夜間・休日窓口の場合、母子手帳の証明や届書の受理証明書などの発行、 '
'子どもに関する手当・助成の受付はしていませんので、通常窓口で手続き・申請してください。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '妊娠・出産'},
'score': 0.85916096,
'values': []},
{'id': '139',
'metadata': {'Answer': '(申請方法、有効期限、更新等の手続きについて記載してください。)',
'Category': '子どもの手当・助成'},
'score': 0.858512163,
'values': []}],
'namespace': ''}
さきほどのパターン1ではだめだった3年保育が可能な幼稚園を教えてください。という質門に関しても、1位ではないけれども2位で拾えている。
{'matches': [{'id': '286',
'metadata': {'Answer': '○○市内の私立幼稚園では、○○、●●において、満3歳児クラスがあります。',
'Category': '学校・教育'},
'score': 0.887740731,
'values': []},
{'id': '344',
'metadata': {'Answer': '○○市では、市立幼稚園に入園できるのは4歳児(2年保育)と5歳児(1年保育)です。\n'
'▼市立幼稚園について\n'
'(自治体HP内関連ページのURL)\n'
'\n'
'私立幼稚園の場合、原則として3歳児から最長3年保育が可能です。詳しくは入園を希望する幼稚園へお問い合わせください。\n'
'\n'
'▼私立幼稚園一覧\n'
'(自治体HP内関連ページのURL)',
'Category': '学校・教育'},
'score': 0.880313516,
'values': []},
{'id': '1076',
'metadata': {'Answer': '○○市の幼稚園についてはこちらをご確認ください。\n'
'▼市立幼稚園一覧\n'
'(自治体HP内関連ページのURL)\n'
'○○市では、市立幼稚園に入園できるのは○歳児(○年保育)と○歳児(○年保育)です。\n'
'\n'
'▼私立幼稚園一覧\n'
'(自治体HP内関連ページのURL)\n'
'私立幼稚園の場合、原則として3歳児から最長3年保育が可能です。詳しくは入園を希望する幼稚園へお問い合わせください。',
'Category': '学校・教育'},
'score': 0.875292718,
'values': []},
{'id': '1080',
'metadata': {'Answer': '3歳児健診は子どもの3歳の誕生月に通知されますので、指定の保健相談所にて受診してください。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '健診・予防接種'},
'score': 0.873763,
'values': []},
{'id': '590',
'metadata': {'Answer': '市が実施または助成する健診は、3から4か月健診、6から7か月健診、9から10か月健診、1歳6か月内科健診、1歳6か月歯科健診、3歳児健診です。\n'
'また、必要がある場合は、経過観察健診(予約制)をご案内いたします。',
'Category': '健診・予防接種'},
'score': 0.869407594,
'values': []},
{'id': '1054',
'metadata': {'Answer': '一時保育制度とは、子育てのリフレッシュを主な目的に、市内在住の小学校就学前までの子どもを預かる制度です。市内○か所の保育園で実施しています。\n'
'料金の支払方法や申込方法等については、各施設へお問い合わせください。\n'
'\n'
'▼詳しくはこちら\n'
'(自治体HP内関連ページのURL)',
'Category': '保育'},
'score': 0.868289232,
'values': []},
{'id': '620',
'metadata': {'Answer': '乳児健診は、(実施場所)で、3から4か月健診、1歳6か月歯科健診、3歳児健診を無料で行っております。\n'
'また、6から7か月健診、9から10か月健診、1歳6か月内科健診については、受診票を郵送しますので、契約医療機関にて受診してください。',
'Category': '健診・予防接種'},
'score': 0.868286252,
'values': []},
{'id': '389',
'metadata': {'Answer': '認可保育園には市立保育園、私立保育園、認定こども園があります。\n'
'詳しい一覧はこちらをご覧ください。\n'
'(自治体HP内関連ページのURL)',
'Category': '保育'},
'score': 0.867016137,
'values': []},
{'id': '188',
'metadata': {'Answer': '認定こども園とは、保育園と幼稚園の機能や特長をあわせ持つ施設です。\n'
'市内の認定こども園は、保育所型の認定こども園で、認可保育園として認可を受けています。\n'
'3~5歳児になると、保育が必要なお子さんに加え、保育の必要性にかかわらず、利用時間が短・中時間のお子さんも入園できます。\n'
'\n'
'※短・中時間の利用を希望する場合は、各園に直接お問い合わせください。',
'Category': '保育'},
'score': 0.865729451,
'values': []},
{'id': '287',
'metadata': {'Answer': '(預かり保育を実施している私立幼稚園)において、預かり保育を実施しています。\n'
'具体的な時間など詳しくは各幼稚園にお問い合わせください。',
'Category': '学校・教育'},
'score': 0.865547359,
'values': []}],
'namespace': ''}
定量的な数値も見てみる。
test_df = df.copy()
for index, row in tqdm(test_df.iterrows(), total=test_df.shape[0]):
query_vector = get_embedding(row["Q"])
result = pinecone_index.query(
vector=query_vector,
top_k=999,
include_metadata=True
)
match_rank = 999
for i, v in enumerate(result["matches"]):
if row["A"] == v["metadata"]["Answer"]:
match_rank = i+1
break
test_df.loc[test_df["ID"] == row["ID"], "rank03"] = match_rank
import plotly.graph_objects as go
value_counts = test_df['rank03'].value_counts()
value_counts = value_counts.sort_index()
mask = value_counts.index >= 11
tail = value_counts[mask].sum()
value_counts = value_counts[~mask]
value_counts['その他'] = tail
fig = go.Figure(go.Pie(labels=value_counts.index, values=value_counts, hole=0.3, direction="clockwise", sort=False))
fig.show()
結果
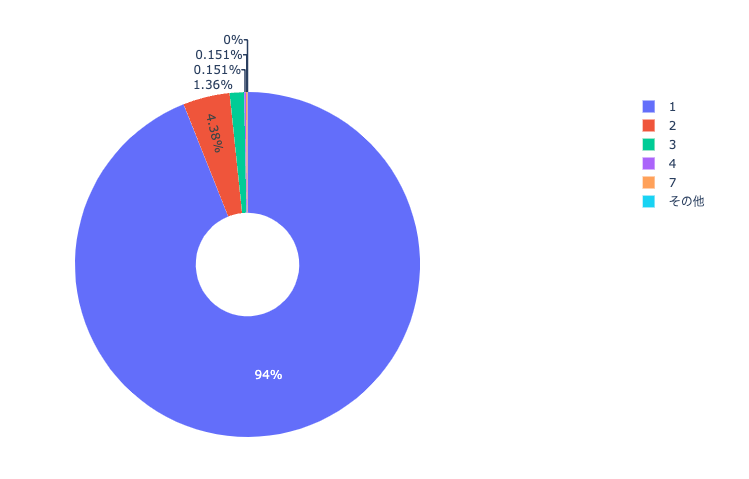
検索結果の上限が5件の場合で99.8%と非常に検索精度が上がったことがわかる。
とはいえ、5件で拾えなかったものもある(1件だけだけど)わけで、参考までに個人的な経験則として、今回使用したのとは違う別のQAデータ(非公開)で同じ手法を使用したにもかかわらず、検索上限10件でも拾えないものがあったりもした。
検索ロジックもそうだけど、元のQAデータそのものの質等によっても変わってくる部分が大きいと思う。
ハイブリッド検索(未完)
ということでやっとハイブリッド検索の話。
まあ上の検証で非常によい数字を出せたのではあるけれども、上にも書いた通り、データによってはこれでも拾えないものが出てきたりもする。データの質というところは当然あるので、データの見直しというのも一つの方法ではあるけども、もう一つの方法としてハイブリッド検索を試してみたいと思う。
まずはPineconeが公式にノートブックを公開している「Hybrid Search for E-Commerce with Pinecone」を写経していく。
と思って一通り動かしてみたけども、まとまってるものがあった。
な~んとなく雰囲気はわかったものの、
- テキストベースのQA
- 日本語
でハイブリッド検索をやるにはもう少し理解が必要な感じ。
Pineconeとは違うけど、以下でWeaviateやMeilisearchを使ってハイブリッドを試してみた。
こういうのを試してみて感じたのは、過度かつ安易にハイブリッドに対して期待値を上げていた自分がいたなということ。実際にはretrievalの手段がなんであれ、精度向上にはコストがかかるということを感じている。
でそういうのを突き詰めるとこういうことにもなる。これほんとにわかる。
なので、ハイブリッドを採用する場合にはこのあたりを踏まえてよくよく検討する必要があるかなと思う。
検索については、この本が良かった。全部読みきれてないのだけども。
で話は戻って、Pineconeでハイブリッドをやるならば、おそらく日本語のトークナイザーを自分で実装する必要があると思われる。Pineconeが公式にハイブリッド検索を実装するためのユーティリティーを出している。
のだけども、この実装ではBM25とSPLADEに対応していて、少なくともBM25は日本語非対応、SPLADEはよくわかっていない。
LlamaIndexとかの場合、PineconeVectorStoreを使うことになるのだけど、
オプションでトークナイザーを渡すことができる。
以下はBM25Retrieverを試した際の記事。自分はSudachiを使ってトークナイザー関数を実装したので、これと同じようなやりかたでできるのではないか?と思う。試していないのでしらんけど。