LlamaIndexモジュールガイドを試してみる: Evaluating
Evaluation
Understanding: Evaluation
Modules Guide: Evaluating
前提として、RAGの場合の評価基準は2つある。
- レスポンスの評価
- レスポンスは検索されたコンテキストと一致するか?
- クエリとも一致するか?
- 基準となる回答やガイドラインにマッチしているか?
- 検索の評価
- 検索されたソースはクエリに関連しているか?
RAGでは結果は常に一定ではない=既存のテストツールなどで定量的には測れない。そこで評価もLLMに判断させる、かつ、複数の観点で評価するというのが最近の主流だと思う。
レスポンスの評価
上で書いた通り、LLMが生成する内容を定量的に評価するのは難しい。そこで複数の観点で評価を行う。挙げられているのは以下のようなもの。
- 正しさ(Correctness)
- 生成された答えが、クエリで指定された参照答えと一致するかどうか(ラベルが必要)。
- 意味的類似性(Semantic Similarity)
- 予測された答えが参照された答えと意味的に類似しているかどうか (ラベルが必要)。
- 忠実さ(Faithfulness)
- 答えが検索された文脈に忠実かどうか(言い換えれば、幻覚があるかどうか)を評価する。
- コンテキストの関連性(Context Relevancy)
- 検索されたコンテキストがクエリに関連しているかどうか。
- 回答の関連性(Answer Relevancy)
- 生成された回答がクエリに関連しているかどうか。
- ガイドラインの遵守(Guideline Adherence)
- 予測された回答が特定のガイドラインに準拠しているかどうか。
AzureのPrompt Flowで利用可能な評価指標も概ね似たような内容になっている様子。

referred from 「Azure Machine Learning Prompt flow 評価メトリクス解説」 by Nobusuke Hanagasaki on SpeakerDeck
なので、評価用の「質問」を用意して、実際に回答を生成させて、上記の指標で評価することになる。
検索の評価
検索の場合は、既存の検索技術でいろいろな評価指標がすでに確立されている模様。例えば以下。
- mean-reciprocal rank (MRR): 平均順位
- hit-rate: ヒット率
- precision: 精度
質問と正解となる検索結果のデータがあれば、実際に検索してみて、その検索結果のランキングを上記の指標で評価することになる。
参考として、以前こういうものを試したことがある。
LlamaIndexにおける評価
評価のためのモジュールとして以下が用意されている。
- ResponseEvaluator
- RetrieverEvaluator
また評価フレームワークとのインテグレーションも用意されている。ドキュメントにあるのは以下。
- DeepEval
- Ragas
また評価用データの作成や利用には以下のようなモジュールがある。
- DatasetGenerator
- LabelledRagDataset/LlamaHub
あまり細かくは見ないけど少し触ってみる。個人的にはRagasとの連携を確認したいところ。
参考:
ざっとドキュメントを見た感じの印象
- 評価用データセットを作るモジュールが複数あるのだが・・・
- モジュールの名前空間が微妙に違う・・・
- DatasetGeneratorという如何にもデータセット作成のものもあれば、、、
- evaluationという如何にも概念的なモジュールのメソッドもある・・・
- Deprecatedなものがちらほらある模様・・・・
- DatasetGeneratorはRagDatasetGeneratorに変わるっぽい
- しかもモジュール空間が違う・・・
- モジュールの名前空間が微妙に違う・・・
という感じで、最初にきれいに整理した上で理解したいなと思ったのだけど、そこは諦める。ドキュメントに従って粛々と見ていくことにする。
検索の評価
Usage Pattern (Retrieval)
Retrieval Evaluation
検索評価はRetrieverEvaluatorを使う。
from pathlib import Path
import requests
wiki_titles = ["ドウデュース", "イクイノックス"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = page["extract"]
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
ドキュメントからインデックスを作る。評価データセットの作成にはノードが必要になるのと、後でわかりやすいようにノードIDを少しいじっている。
import os
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.readers.file.flat_reader import FlatReader
from llama_index.text_splitter import SentenceSplitter
from llama_index.embeddings import OpenAIEmbedding
from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-4")
embed_model = OpenAIEmbedding()
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
)
reader = FlatReader()
docs_d = reader.load_data(Path("data/ドウデュース.txt"))
docs_e = reader.load_data(Path("data/イクイノックス.txt"))
node_parser = SentenceSplitter(chunk_size=512, chunk_overlap=50)
nodes = []
for d in [docs_d, docs_e]:
doc_title = os.path.splitext(os.path.basename(d[0].metadata["filename"]))[0]
nds = node_parser.get_nodes_from_documents(d, show_progress=True)
for idx, n in enumerate(nds):
n.id_ = f"{doc_title}_{idx}"
nodes.extend(nds)
index = VectorStoreIndex(nodes, service_context=service_context)
retriever = index.as_retriever(similarity_top_k=2)
軽く検索してみる。
from llama_index.response.notebook_utils import display_source_node
retrieved_nodes = retriever.retrieve("イクイノックスの主な勝ち鞍は?")
for node in retrieved_nodes:
display_source_node(node, source_length=1000)
Node ID: イクイノックス_16
Similarity: 0.8767508121700972
Text: 木村哲也調教師は本競走初制覇。また、クリストフ・ルメールは武豊と並ぶジャパンカップ最多4勝目。そのほかにも、3着に5番人気のスターズオンアースが入ったため、3連単のオッズが11.3倍となったのは、第40回を制したアーモンドアイと2着馬コントレイル、3着馬デアリングタクトの13.4倍を更新し、歴代JRA・GIにおける最低額配当となった他、イクイノックス、リバティアイランドのワイドのオッズが1.3倍となり、2000年の天皇賞(春)を制したテイエムオペラオーと2着馬ラスカルスズカ、3着馬ナリタトップロードなどと並び、ワイドの低額配当タイの記録となった。 鞍上のルメールはレース後のインタビューで「この馬の走りは信じられません。ペースが速かったけど、直線はすぐに反応して、自分でもびっくりした。アクセレーション(加速)がすごかったです。1番枠にリバティアイランドがいての2番枠。タイトルホルダーとパンサラッサの後ろにつけたかったけど、イクイノックスはいいスタートを切りました。後ろにつけて、そこから勝つ自信がありました。イメージ通りです。スーパーホースですね。
Node ID: イクイノックス_11
Similarity: 0.8749314044156363
Text: GI5連勝、史上3頭目となる天皇賞(秋)連覇を達成した。ジャックドールによる前半1000m通過57秒7という数字は、前年(2022年)のパンサラッサの大逃げによる同57秒4とコンマ3秒しか違わず、前年度と同じように全体的にタフな流れであった。前年と同じようなレース展開に対して、イクイノックスは、昨年は中団馬群の後方から追い込み勝利したのに対し、今年はジャックドール、ガイアフォースの後ろの3番手でレースを進めた。イクイノックスが直線半ばで先頭に立ったのと対照的に、直後にいたドウデュース(7着)やヒシイグアス(9着)らは失速し後方へ下がった。2着のジャスティンパレス、3着のプログノーシスは最後方にいた2頭であり、本来は典型的な追い込み決着となるはずであったレースにおいて、イクイノックスだけが先行して勝利したことから、よりイクイノックスの強さが際立つレースとなった。このレースの進め方に関して、鞍上のルメールは「イクイノックスの(背中の)上だと普通のペース。彼は跳びが大きくて、スムーズな走り方をする。
ではgenerate_question_context_pairsを使って評価用データセットを作成する。各ノードのコンテキストごとに質問を生成することで、検索評価用のクエリとコンテキストのペアができる模様。
num_questions_per_chunk でノードごとに生成する質問数を指定できる。
あとデフォルトのプロンプトだと英語になってしまうので、プロンプトをカスタマイズしている。
from llama_index.evaluation import generate_question_context_pairs
custom_qa_generate_prompt_template = """\
コンテキスト情報は以下です。
---------------------
{context_str}
---------------------
事前知識を使わずに、与えられたコンテキスト情報から、以下のクエリに基づいた問題のみを作成してください。
あなたは教師/教授です。
あなたの仕事は次の小テスト/試験のために{num_questions_per_chunk}個の問題を作成することです。
問題はドキュメント全体にわたって多様でなければなりません。
問題は提供されたコンテキスト情報に限定してください。
年号を質問する問題は避けなければなりません。
1つの問題から複数の回答を求める質問は避けなければなりません。1つの問題は1つの回答を求めるものに限定してください。
"""
qa_dataset = generate_question_context_pairs(
nodes,
llm=llm,
num_questions_per_chunk=2,
qa_generate_prompt_tmpl=custom_qa_generate_prompt_template
)
中身を見てみる。
print(qa_dataset)
こんな感じで、生成された質問と生成元のコンテキストであるノートIDとの紐づけをもつEmbeddingQAFinetuneDatasetオブジェクトが出来上がる。
EmbeddingQAFinetuneDataset(
queries={
'd3cf03bc-c9e7-4ba6-8f54-32e36f9f7c6c': 'ドウデュースの馬名の意味は何ですか?',
'd0b353fd-5d81-4fa0-ae12-d3cbc4d4160b': 'ドウデュースが育成された牧場の名前は何ですか?',
'a650e6fa-e7d1-4d53-ab6d-2671f048f2a3': 'この馬が初めて出走したレースは何でしょうか?',
'60862713-2cef-4862-9cdd-c73f39c93b42': '鞍上の武豊が朝日杯フューチュリティステークスで初制覇した後、彼が完全制覇までに残した唯一のレースは何でしょうか?',
(snip)
},
relevant_docs={
'd3cf03bc-c9e7-4ba6-8f54-32e36f9f7c6c': ['ドウデュース_0'],
'd0b353fd-5d81-4fa0-ae12-d3cbc4d4160b': ['ドウデュース_0'],
'a650e6fa-e7d1-4d53-ab6d-2671f048f2a3': ['ドウデュース_1'],
'60862713-2cef-4862-9cdd-c73f39c93b42': ['ドウデュース_1'],
(snip)
これをファイルに保存。
qa_dataset.save_json("pg_eval_dataset.json")
逆に読み出す場合。
from llama_index.evaluation import EmbeddingQAFinetuneDataset
qa_dataset = EmbeddingQAFinetuneDataset.from_json("pg_eval_dataset.json")
ではRetrieverEvaluatorを使って評価する。まずevaluatorオブジェクトを作成する。メトリクスはhit_rate、mrrとあとcohere_cohere_rerank_relevancyというのがある模様。
from llama_index.evaluation import RetrieverEvaluator
metrics = ["mrr", "hit_rate"]
retriever_evaluator = RetrieverEvaluator.from_metric_names(
metrics,
retriever=retriever
)
評価用データセットから1つ拾って試してみる。
sample_id, sample_query = list(qa_dataset.queries.items())[0]
sample_expected = qa_dataset.relevant_docs[sample_id]
print([sample_id, sample_query, sample_expected])
['c877603d-93e2-44a7-8ef8-1e0905fb8cbf', 'ドウデュースの主な勝ち鞍にはどのようなレースが含まれていますか?', ['ドウデュース_0']]
import nest_asyncio
nest_asyncio.apply()
eval_result = retriever_evaluator.evaluate(sample_query, sample_expected)
print(eval_result)
どうやらヒットしなかった模様。
Query: ドウデュースの主な勝ち鞍にはどのようなレースが含まれていますか?
Metrics: {'mrr': 0.0, 'hit_rate': 0.0}
せっかくなのでcohere_cohere_rerank_relevancyも有効にしてみる。cohereのパッケージをインストール。APIキーを環境変数にセットしておくこと。
!pip install cohere
from google.colab import userdata
import os
os.environ["COHERE_API_KEY"] = userdata.get('COHERE_API_KEY')
from llama_index.evaluation import RetrieverEvaluator
import nest_asyncio
nest_asyncio.apply()
metrics = ["mrr", "hit_rate", "cohere_rerank_relevancy"]
retriever_evaluator = RetrieverEvaluator.from_metric_names(
metrics,
retriever=retriever
)
sample_id, sample_query = list(qa_dataset.queries.items())[0]
sample_expected = qa_dataset.relevant_docs[sample_id]
eval_result = retriever_evaluator.evaluate(sample_query, sample_expected)
print(eval_result)
Query: ドウデュースの主な勝ち鞍にはどのようなレースが含まれていますか?
Metrics: {'mrr': 0.0, 'hit_rate': 0.0, 'cohere_rerank_relevancy': 0.99287856}
うーむ、結果は変わったのだけど、そもそもsimilarity_top_k=2だからcohereのリランキングがあったとしても役に立たない気がするな、ちょっとcohere_rerank_relevancyがどういう意味なのかわからない。
ちょっと見てみると確かに期待するノードは参照されていないね。
from llama_index.response.notebook_utils import display_source_node
retrieved_nodes = retriever.retrieve("ドウデュースの主な勝ち鞍にはどのようなレースが含まれていますか?'")
for node in retrieved_nodes:
display_source_node(node, source_length=1000)
Node ID: ドウデュース_3
Similarity: 0.8780128252423496
Text: 単勝4.2倍の3番人気でレースを迎えた。レースではスタートから後方に控え、前半1000メートルを58秒9という早いペースの中落ち着いてレースを進め、直線に入ってスパート。鞍上武豊の右ムチに応え加速し先団を捉え、大外から伸びてくるイクイノックスをクビ差抑え込み優勝。朝日杯以来のGI制覇となり、勝ちタイムは2分21秒9のダービーレコード(コースレコードは2018年ジャパンカップでアーモンドアイが記録した2分20秒6)。鞍上の武は、歴代最多を更新する2013年のキズナ以来となるダービー6勝目、かつ歴代最年長、史上初の50代でのダービージョッキーの名誉となった。また朝日杯フューチュリティステークスの勝ち馬が日本ダービーを制したのは、1994年のナリタブライアン(前身である朝日杯3歳ステークスを勝利)以来28年ぶりとなった。 6月10日に国際競馬統括機関連盟が発表した「ロンジンワールドベストレースホースランキング」において、ドウデュースは日本ダービーを勝利した功績を評価され、シャフリヤールやエンブレムロードと並ぶレーティング120で第15位タイに位置づけられた。
Node ID: ドウデュース_7
Similarity: 0.8676904303336961
Text: 武豊は2017年のキタサンブラック以来、6年ぶりの制覇となった。また、54歳9カ月10日での有馬記念勝利は最年長勝利記録であり、同時に自身が持つJRA・GI最年長勝利記録(54歳19日)を更新。ドリームジャーニーやオルフェーヴル、ブラストワンピースに騎乗し歴代最多の有馬記念4勝を挙げている池添謙一に並ぶ勝利数となった。馬番5番での優勝は、1970年のスピードシンボリ、1972年のイシノヒカルに次いで、51年ぶり3度目となった。さらに、ダービー馬による有馬記念制覇はオルフェーヴル以来10年ぶり9頭目で、三冠馬以外ではハクチカラ、ダイナガリバー、トウカイテイオーに次いで30年ぶり4頭目となったほか、父ハーツクライとの本競走親子制覇を達成した。本競走での親子制覇は史上6回目となった。 優勝後、陣営は翌年のドバイと凱旋門賞に再挑戦する旨を表明した。
検索件数を増やすか、インデックスで何かしら工夫するか、みたいな判断になるね。
では全部の評価データセットでテストする、といいたいところだけど、自分のCohereのAPIキーは評価用でrate limitがきついのでメトリクスから外しておいた。
from llama_index.evaluation import RetrieverEvaluator
import nest_asyncio
nest_asyncio.apply()
metrics = ["mrr", "hit_rate"]
retriever_evaluator = RetrieverEvaluator.from_metric_names(
metrics,
retriever=retriever
)
eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)
結果をpandasで表示
import pandas as pd
def display_results(name, eval_results):
"""Display results from evaluate."""
metric_dicts = []
for eval_result in eval_results:
metric_dict = eval_result.metric_vals_dict
metric_dicts.append(metric_dict)
full_df = pd.DataFrame(metric_dicts)
hit_rate = full_df["hit_rate"].mean()
mrr = full_df["mrr"].mean()
columns = {"retrievers": [name], "hit_rate": [hit_rate], "mrr": [mrr]}
metric_df = pd.DataFrame(columns)
return metric_df
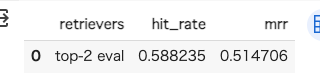
display_results("top-2 eval", eval_results)
なかなか残念な結果。
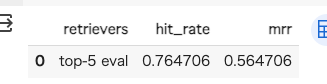
top-5でやり直してみた。多少改善はしたけど個人的に物足りないかな。インデックスの作り方とかはいろいろ試す余地がありそう。後今回はプロンプトを全然カスタマイズもしてないので、その辺りも改良の余地はあるかも。
レスポンスの評価
レスポンスの評価に使えるEvaluatorはモジュール一覧
を見る限りはこの辺っぽい
- Faithfulness Evaluator
- Relevancy Evaluator
- Guideline Evaluator
- Correctness Evaluator
- Embedding Similarity Evaluator
で、これらは全てBaseEvaluatorクラスから継承されて、evaluateとevaluate_responseの2つのメソッドを持つ。
evaluateメソッドはクエリ、コンテキスト、レスポンス(と追加の引数)を受ける。
def evaluate(
self,
query: Optional[str] = None,
contexts: Optional[Sequence[str]] = None,
response: Optional[str] = None,
**kwargs: Any,
) -> EvaluationResult:
evaluate_responseメソッドは、クエリとLlamaIndexのResponseオブジェクト(と追加の引数)を受ける。Responseオブジェクトにはレスポンスと根拠となるコンテキストノードが含まれる。こちらの方がオブジェクトをそのまま使えるというだけっぽい。
def evaluate_response(
self,
query: Optional[str] = None,
response: Optional[Response] = None,
**kwargs: Any,
) -> EvaluationResult:
どちらもやることは同じでevaluate、つまり評価を行う。
そして全てのEvaluatorは以下の結果を返す。
eval_result = evaluator.evaluate(query=..., contexts=..., response=...)
eval_result.passing # 成功・失敗のどちらか
eval_result.score # 数値的なスコア
eval_result.feedback # フィードバック文字列?
ということで実際に試してみる。
Faithfulness Evaluatorを使った評価
いくつかのEvaluatorがあるがここでは、FaithfulnessEvaluatorを使って一通りの流れを確認していく。
FaithfulnessEvaluatorは、取得したコンテキストに対して回答が信頼できるものであるか、つまり逆に言うと**ハルシネーションがないか?**を評価する。
上で作成したインデックスをそのまま使ってクエリエンジンを作成して、クエリを送ってみる。
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("ドウデュースの主な勝ち鞍は?")
print(response)
ドウデュースの主な勝ち鞍には、日本ダービー、有馬記念、朝日杯などが含まれます。
FaithfulnessEvaluatorを使ってレスポンスを評価する。
from llama_index.evaluation import FaithfulnessEvaluator
import nest_asyncio
nest_asyncio.apply()
evaluator = FaithfulnessEvaluator(service_context=service_context)
eval_result = evaluator.evaluate_response(response=response)
print(repr(eval_result))
EvaluationResult(
query=None,
contexts=[
'(snip)また、54歳9カ月10日での有馬記念勝利は最年長勝利記録であり、同時に自身が持つJRA・GI最年長勝利記録(54歳19日)を更新。(snip)',
'(snip)鞍上武豊の右ムチに応え加速し先団を捉え、大外から伸びてくるイクイノックスをクビ差抑え込み優勝。朝日杯以来のGI制覇となり、勝ちタイムは2分21秒9のダービーレコード(コースレコードは2018年ジャパンカップでアーモンドアイが記録した2分20秒6)。(snip)',
(snip)
],
response='ドウデュースの主な勝ち鞍には、日本ダービー、有馬記念、朝日杯などが含まれます。',
passing=True,
feedback='YES',
score=1.0,
pairwise_source=None,
invalid_result=False,
invalid_reason=None
)
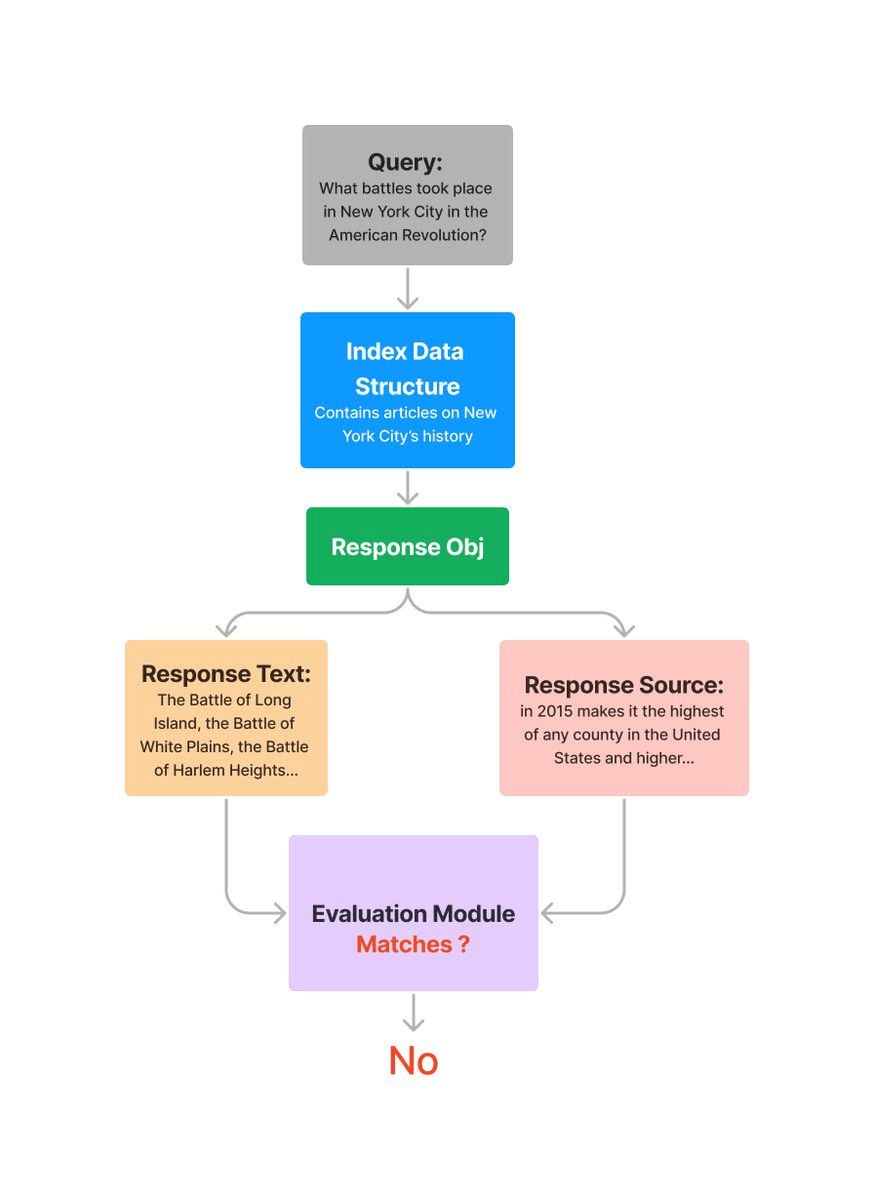
評価の流れはこう。
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
FaithfulnessEvaluatorは、生成されたレスポンスとコンテキストとなったノードを見比べて評価する。Evaluatorによってはここにクエリが含まれたりするみたい。
で結果の方は、passing: True、score=1.0ということで、正しい回答と評価されている。回答としても全く間違ってはいないし。ところでフィードバックって何?と思ってコードを見てみたら「回答に対するフィードバックまたは理由」とある。ただプロンプトを見る限りは、単純にYES/NOを返すだけのプロンプトが設定されていると思われる。passing: Trueを文字列で置き換えたら"YES"ってだけのような気がするな。深くまでは見てないけども。
根拠として検索されたノードごとに評価を行うこともできる。
response_str = response.response
for source_node in response.source_nodes:
eval_result = evaluator.evaluate(
response=response_str,
contexts=[source_node.get_content()]
)
print(str(eval_result.passing), str(eval_result.score), eval_result.feedback, eval_result.contexts[0].replace("\n","\\n")[:30])
False 0.0 NO 武豊は2017年のキタサンブラック以来、6年ぶりの制覇となっ
True 1.0 YES 単勝4.2倍の3番人気でレースを迎えた。レースではスタートか
False 0.0 NO まずまずのスタートを決めると、道中は馬群を見て最後方グループ
False 0.0 NO 当日の第5競走で武豊が騎乗馬に右膝を蹴られ負傷したため、急遽
False 0.0 NO === 3歳(2022年) ===\n3歳初戦として、弥生賞
クエリ+レスポンスの関連性の評価
RelevancyEvaluatorを使うと、検索されたコンテキストと生成された回答が元のクエリに対して関連性があるか、十分であるか、を評価する。上のFaithfulnessEvaluatorでは、レスポンスとコンテキストだけで評価されていたが、こちらの場合はこれにクエリも追加される。
from llama_index.evaluation import RelevancyEvaluator
import nest_asyncio
nest_asyncio.apply()
evaluator = RelevancyEvaluator(service_context=service_context)
query = "ドウデュースの主な勝ち鞍は?"
response = query_engine.query(query)
eval_result = evaluator.evaluate_response(query=query, response=response)
print(str(eval_result))
query='ドウデュースの主な勝ち鞍は?' contexts=None response='ドウデュースの主な勝ち鞍は、日本ダービー、有馬記念、そして京都記念です。' passing=True feedback='YES' score=1.0 pairwise_source=None invalid_result=False invalid_reason=None
図にするとこう。クエリも追加されているのがわかる。
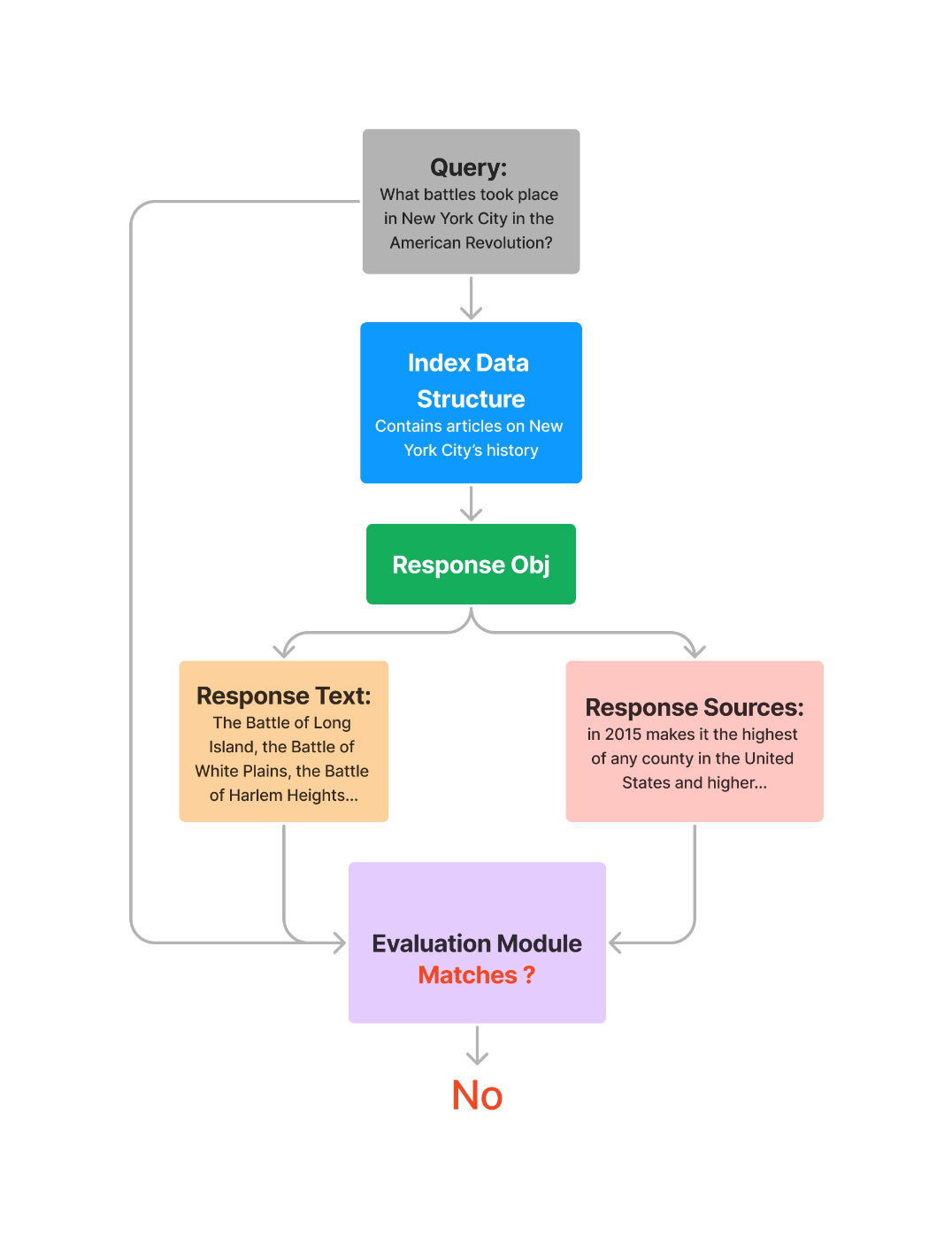
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
こちらの場合も同様に、根拠として検索されたノードごとに評価を行うことができる。
response_str = response.response
for source_node in response.source_nodes:
eval_result = evaluator.evaluate(
query=query,
response=response_str,
contexts=[source_node.get_content()],
)
print(str(eval_result.passing), str(eval_result.score), eval_result.feedback, source_node.get_content().replace("\n","")[:30])
False 0.0 No 武豊は2017年のキタサンブラック以来、6年ぶりの制覇となっ
False 0.0 NO 単勝4.2倍の3番人気でレースを迎えた。レースではスタートか
False 0.0 NO まずまずのスタートを決めると、道中は馬群を見て最後方グループ
False 0.0 NO 当日の第5競走で武豊が騎乗馬に右膝を蹴られ負傷したため、急遽
False 0.0 NO === 3歳(2022年) ===3歳初戦として、弥生賞ディ
バグなのかはわからないけど、RelevancyEvaluatorは戻り値にcontextsが含まれてないのよね。。。なのでresponseの中身から直接拾っている。まあ引数では渡してるので評価がおかしいとかではなくて、出力結果では見えないというだけ。
おもしろいのは結果が全部Noになっていること。今回の回答は複数のノードにまたがって生成されているので、それぞれのノード単体で見るとRelavantじゃないってことなのかもしれないな。
説明のための図としてはこうなってるけど、色々足りないよね。説明不足な図とかめちゃ気になる。
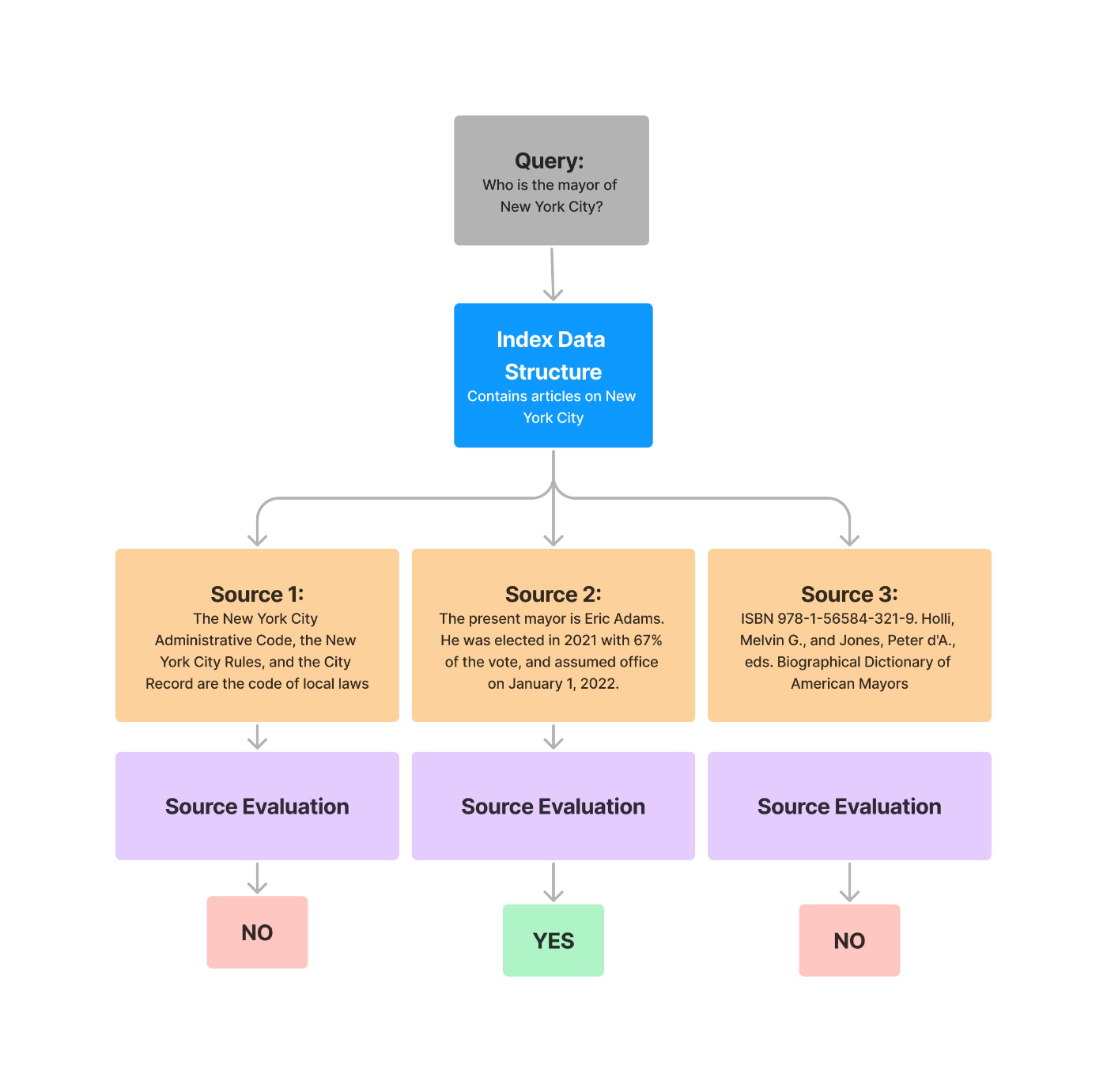
© 2023 Jerry Liu. LlamaIndex is released under the MIT license
評価用データの生成
検索の評価ではgenerate_question_context_pairsを使って評価用データ(コンテキストから質問)を作成したが、DatasetGeneratorというのもある。
DatasetGeneratorはドキュメントまたはノードから作成ができる。
ここまでの続きですでにドキュメントのロードおよびノード分割は終わってるものとする。
ドキュメントから作成する場合。generate_questions_from_nodesで質問が作成できる。
from llama_index.evaluation import DatasetGenerator
documents = docs_d + docs_e
data_generator = DatasetGenerator.from_documents(documents)
eval_questions_from_doc = data_generator.generate_questions_from_nodes(num=10)
eval_questions_from_doc
なんかいろいろDeprecatedなWarningが出るけどもこんな感じで。
WARNING:llama_index.service_context:chunk_size_limit is deprecated, please specify chunk_size instead
/usr/local/lib/python3.10/dist-packages/llama_index/evaluation/dataset_generation.py:184: DeprecationWarning: Call to deprecated class DatasetGenerator. (Deprecated in favor of `RagDatasetGenerator` which should be used instead.)
return cls(
/usr/local/lib/python3.10/dist-packages/llama_index/evaluation/dataset_generation.py:279: DeprecationWarning: Call to deprecated class QueryResponseDataset. (Deprecated in favor of `LabelledRagDataset` which should be used instead.)
return QueryResponseDataset(queries=queries, responses=responses_dict)
['When was Dou Deuce born?',
'Who is the owner of Dou Deuce?',
'Which race did Dou Deuce win in 2021 to achieve his first Group 1 victory?',
'How many consecutive wins did Dou Deuce have before his first loss?',
'Who was the jockey for Dou Deuce in the Asahi Hai Futurity Stakes?',
'What was the winning time for Dou Deuce in the Tokyo Yushun (Japanese Derby)?',
'How many times has jockey Yutaka Take won the Japanese Derby?',
"Which race did Dou Deuce win to become the JRA's best 2-year-old colt in 2021?",
'What was the finishing position of Dou Deuce in the 2022 Satsuki Sho (Japanese 2000 Guineas)?',
"Which international race did Dou Deuce's performance in the Japanese Derby earn him recognition in?"]
ノードから作成する場合
from llama_index.evaluation import DatasetGenerator
data_generator = DatasetGenerator(nodes)
eval_questions_from_nds = data_generator.generate_questions_from_nodes(num=10)
eval_questions_from_nds
<ipython-input-71-7aff93d86790>:3: DeprecationWarning: Call to deprecated class DatasetGenerator. (Deprecated in favor of `RagDatasetGenerator` which should be used instead.)
data_generator = DatasetGenerator(nodes)
WARNING:llama_index.service_context:chunk_size_limit is deprecated, please specify chunk_size instead
/usr/local/lib/python3.10/dist-packages/llama_index/evaluation/dataset_generation.py:279: DeprecationWarning: Call to deprecated class QueryResponseDataset. (Deprecated in favor of `LabelledRagDataset` which should be used instead.)
return QueryResponseDataset(queries=queries, responses=responses_dict)
['When was Dou Deuce born?',
'What are the major victories of Dou Deuce?',
"What is the meaning of the horse's name, Dou Deuce?",
'Who is the owner of Dou Deuce?',
'Where was Dou Deuce born and raised?',
"Which trainer is responsible for Dou Deuce's training?",
'What is the significance of the JRA Award received by Dou Deuce?',
'Which farm did Dou Deuce come from?',
'Which race did Dou Deuce win in 2022?',
'In which year did Dou Deuce win the Asahi Hai Futurity Stakes?']
英語になっているのでプロンプトを書き換えてみる。
from llama_index.evaluation import DatasetGenerator
from llama_index.prompts import PromptTemplate
custom_question_generate_prompt = """\
コンテキスト情報は以下です。
---------------------
{context_str}
---------------------
事前知識は使わずに、与えられたコンテキスト情報のみを使って、以下のクエリに基づいて質問だけを生成してください。
{query_str}
"""
custom_question_generate_prompt_template = PromptTemplate(custom_question_generate_prompt)
custom_question_gen_query = """\
あなたは教師/教授です。
あなたの仕事は次の小テスト/試験のために10個の問題を設定することです。
問題は文書全体にわたって多様であるべきです。
問題は提供されたコンテキスト情報に限定してください。
"""
data_generator = DatasetGenerator(
nodes,
question_gen_query=custom_question_gen_query,
text_question_template=custom_question_generate_prompt_template,
)
eval_questions_from_nds = data_generator.generate_questions_from_nodes(num=10)
eval_questions_from_nds
/usr/local/lib/python3.10/dist-packages/llama_index/evaluation/dataset_generation.py:279: DeprecationWarning: Call to deprecated class QueryResponseDataset. (Deprecated in favor of `LabelledRagDataset` which should be used instead.)
return QueryResponseDataset(queries=queries, responses=responses_dict)
['ドウデュースの主な勝ち鞍は何ですか?',
'ドウデュースの馬名の意味は何ですか?',
'ドウデュースは2019年に誕生した競走馬ですか?',
'ドウデュースはどこの牧場で育成されましたか?',
'ドウデュースはどの厩舎に入厩しましたか?',
'ドウデュースは2021年のJRA賞で何を受賞しましたか?',
'ドウデュースは2022年のどのレースで優勝しましたか?',
'ドウデュースは2023年のどのレースに出走する予定ですか?',
'ドウデュースはどのオーナーの所有馬ですか?',
'ドウデュースはどのトレーニングセンターに所属していますか?']
question_gen_queryとか文字列で渡すんだけど、{num_questions_per_chunk} とかが展開されなくて結構雑な感じの実装になってるのがな・・・
あとDatasetGeneratorにはgenerate_dataset_from_nodesというメソッドもあってどうやらこちらは質問と回答のペアを作ってくれる模様。
from llama_index.evaluation import DatasetGenerator
from llama_index.prompts import PromptTemplate
custom_question_generate_prompt = """\
コンテキスト情報は以下です。
---------------------
{context_str}
---------------------
事前知識は使わずに、与えられたコンテキスト情報のみを使って、以下のクエリに基づいて質問だけを生成してください。
{query_str}
"""
custom_question_generate_prompt_template = PromptTemplate(custom_question_generate_prompt)
custom_text_qa_prompt = '''\
コンテキスト情報は以下です。
---------------------
{context_str}
---------------------
事前知識は使わずに、与えられたコンテキスト情報のみを使って、以下のクエリに回答してください。
Query: {query_str}
Answer: """
'''
custom_text_qa_prompt_template = PromptTemplate(custom_text_qa_prompt)
custom_question_gen_query = """\
あなたは教師/教授です。
あなたの仕事は次の小テスト/試験のために10個の問題を設定することです。
問題は文書全体にわたって多様であるべきです。
問題は提供されたコンテキスト情報に限定してください。
"""
data_generator = DatasetGenerator(
nodes,
question_gen_query=custom_question_gen_query,
text_qa_template=custom_text_qa_prompt_template,
text_question_template=custom_question_generate_prompt_template,
)
eval_dataset = data_generator.generate_dataset_from_nodes(num=10)
eval_dataset.qr_pairs
[
(
'ドウデュースの主な勝ち鞍は何ですか?',
'ドウデュースの主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念です。'
),
(
'ドウデュースの馬名の意味は何ですか?',
'ドウデュースの馬名の意味は「する+テニス用語(勝利目前の意味)」です。'
),
(snip)
]
今気づいたけど、num=10って表示する数だけっぽく見えるな。入出力を表示させると、なんか各ノードに対して質問して回答生成しているように見える?ちょっと動きがイマイチわからないけど、numとnum_questions_per_chunkの設定が正しく理解できないのかも。
複数の評価をバッチで行う
複数のEvaluatorを使って多面的に評価する。BatchEvalRunnerを使う。上で生成した質問データ(eval_questions_from_nds)を使ってやってみる。
ここは繰り返しになるけど、まず評価用のデータセットを作る
from llama_index.evaluation import DatasetGenerator
from llama_index.prompts import PromptTemplate
custom_question_generate_prompt = """\
コンテキスト情報は以下です。
---------------------
{context_str}
---------------------
事前知識は使わずに、与えられたコンテキスト情報のみを使って、以下のクエリに基づいて質問だけを生成してください。
{query_str}
"""
custom_question_generate_prompt_template = PromptTemplate(custom_question_generate_prompt)
custom_text_qa_prompt = '''\
コンテキスト情報は以下です。
---------------------
{context_str}
---------------------
事前知識は使わずに、与えられたコンテキスト情報のみを使って、以下のクエリに回答してください。
Query: {query_str}
Answer: """
'''
custom_text_qa_prompt_template = PromptTemplate(custom_text_qa_prompt)
custom_question_gen_query = """\
あなたは教師/教授です。
あなたの仕事は次の小テスト/試験のために2個の問題を設定することです。
問題は文書全体にわたって多様であるべきです。
問題は提供されたコンテキスト情報に限定してください。
"""
data_generator = DatasetGenerator(
nodes,
question_gen_query=custom_question_gen_query,
text_qa_template=custom_text_qa_prompt_template,
text_question_template=custom_question_generate_prompt_template,
)
eval_dataset = data_generator.generate_dataset_from_nodes()
eval_dataset
['ドウデュースの主な勝ち鞍は何ですか?',
'ドウデュースはどの厩舎に入厩しましたか?',
'ドウデュースは何歳の時にデビューしましたか?',
'ドウデュースの初の重賞勝利はどの競走でしたか?',
'問題1: ドウデュースは、弥生賞ディープインパクト記念でどのような結果を残しましたか?',
'問題2: ドウデュースは、東京優駿(日本ダービー)でどのようなオッズで出走しましたか?',
'ドウデュースが日本ダービーで優勝した際の勝ちタイムは何秒でしたか?',
'ドウデュースは「ロンジンワールドベストレースホースランキング」で何位に位置づけられましたか?',
'ドウデュースはなぜ凱旋門賞への出走を表明したのですか?',
'ドウデュースは凱旋門賞に出走する前にどのようなレースに参加しましたか?',
'ドウデュースはどのようなレースで勝利しましたか?',
'ドウデュースはなぜドバイターフへの出走を取り消したのですか?',
'武豊が騎乗予定だったジャパンカップでの急な乗り替わりについて、どのような影響があったと考えられますか?',
'有馬記念での武豊の復帰によるレース結果について、どのような要素が勝利につながったと考えられますか?',
'武豊が有馬記念で達成した記録は何ですか?',
'武豊の有馬記念優勝後、陣営はどのような挑戦を表明しましたか?',
'ドウデュースの母親はどのような実績を持っていますか?',
'ドウデュースはどの競走に再挑戦する予定ですか?',
'イクイノックスが2022年に勝利した競走は何ですか?',
'イクイノックスの馬名の意味は何ですか?',
'イクイノックスの父は誰ですか?',
'イクイノックスはどの厩舎に入厩しましたか?',
'イクイノックスがデビューした競馬場とレース距離は何でしたか?',
'イクイノックスは東京スポーツ杯2歳ステークスで何着になりましたか?',
'ダノンベルーガはどのレースで共同通信杯を制しましたか?',
'ルメールはイクイノックスの競馬についてどのようにコメントしましたか?',
'イクイノックスが天皇賞(秋)での勝利を飾るまでの経緯を説明してください。',
'イクイノックスの天皇賞(秋)での勝利によって達成された記録について詳しく説明してください。',
'イクイノックスの父は誰ですか?',
'イクイノックスは何歳の時に有馬記念を制覇しましたか?',
'イクイノックスが有馬記念で史上最短のキャリア6戦で制覇したことについて、どのような特徴がありますか?',
'イクイノックスが2023年のドバイシーマクラシックでどのような成績を収めましたか?また、その成績が評価された理由は何ですか?',
'ドバイシーマクラシックでのイクイノックスの勝利タイムは何でしたか?',
'イクイノックスはドバイシーマクラシックで何着差で優勝しましたか?',
'イクイノックスがロンジンワールドベストレースホースランキングで何位になりましたか?',
'イクイノックスは次にどのレースに出走する予定ですか?',
'イクイノックスが宝塚記念で優勝した際に、どのような末脚で追い込んできたのですか?',
'イクイノックスが宝塚記念で優勝したことにより、どのような記録を達成しましたか?',
'イクイノックスが天皇賞(秋)で連覇を達成する前に、どのような成績を収めていましたか?',
'イクイノックスが天皇賞(秋)で勝利した際のタイムは何秒でしたか?また、このタイムはどのような意味を持ちますか?',
'イクイノックスが前年と比べてどのようなレース展開で勝利しましたか?',
'イクイノックスが勝利したレースで他の競走馬と比べてどのような特徴がありましたか?',
'イクイノックスの走破タイムが1999年のクリスタルハウスの記録を上回ったことを説明してください。',
'イクイノックスの鞍上であるクリストフ・ルメールがレース後に述べたイクイノックスの特徴について説明してください。',
'イクイノックスの総獲得賞金はいくらですか?',
'イクイノックスの父であるキタサンブラックは何勝しましたか?',
'イクイノックスがジャパンカップでの勝利を決めた時の勝ちタイムは何秒でしたか?',
'イクイノックスのGI6連勝を阻止しようとした三冠牝馬は誰でしたか?',
'イクイノックスが史上初となる総賞金額20億円を超えたのはいつですか?',
'イクイノックスの父とのジャパンカップ親子制覇は何度目ですか?',
'ジャパンカップでの木村哲也調教師の成績について説明してください。',
'イクイノックスがレース中にどのような特徴を見せたのか説明してください。',
'イクイノックスの特徴は何ですか?',
'イクイノックスの今後の競馬予定について、シルクレーシングの米本昌史代表はどのようにコメントしましたか?',
'イクイノックスがなぜ引退を決めたのか、その理由を説明してください。',
'引退式にはどのような人々が出席しましたか?',
'イクイノックスの種牡馬入りについて、オファー金額は明言されていないものの、どのような評価がされていると報道されていますか?',
'イクイノックスの引退について、キタサンブラックのオーナーである北島三郎はどのようなコメントをしていますか?',
'イクイノックスが種牡馬となった後、どのようなイベントが行われましたか?',
'イクイノックスの種付料はどのように決定されましたか?また、その金額はどのような意味を持っていますか?',
'イクイノックスの競走成績に基づいて、どのような特徴があると言えますか?',
'イクイノックスについて評価した人々は誰ですか?それぞれの評価はどのような内容でしたか?',
'イクイノックスの走りの特徴は何ですか?',
'イクイノックスはどのような評価を受けていますか?',
'イクイノックスがなぜ賞賛されているのですか?',
'イクイノックスの血統にはどのような馬が関係していますか?']
バッチ評価
from llama_index.evaluation import FaithfulnessEvaluator, RelevancyEvaluator
from llama_index.evaluation import BatchEvalRunner
faithfulness_evaluator = FaithfulnessEvaluator(service_context=service_context)
relevancy_evaluator = RelevancyEvaluator(service_context=service_context)
runner = BatchEvalRunner(
{"faithfulness": faithfulness_evaluator, "relevancy": relevancy_evaluator},
workers=8,
)
eval_results = await runner.aevaluate_queries(
index.as_query_engine(),
queries=eval_dataset.questions
)
でこのeval_resultsなんだけどちょっと扱いにくいフォーマットになっている。。。
- 評価指標(faithfulnessとrelevancy)がオブジェクトの最上位のキーで、そこから評価結果が配列で入っている
- faithfulnessとrelevancyで評価結果のオブジェクトの中身が微妙に違う
- 上でも書いたけど、Relevancyはコンテキストを返してくれない(Noneになる)ので、そこを考慮する必要がある。
- プロンプトをカスタマイズする場合は各Evaluatorごとに設定する必要がある。
でサンプルコードもあるんだけど・・・
def get_eval_results(key, eval_results):
results = eval_results[key]
correct = 0
for result in results:
if result.passing:
correct += 1
score = correct / len(results)
print(f"{key} Score: {score}")
return score
faithfulness_score = get_eval_results("faithfulness", eval_results)
relevancy_score = get_eval_results("relevancy", eval_results)
faithfulness Score: 0.5909090909090909
relevancy Score: 0.4696969696969697
うーん、データセットがあるんだから、それの内容と照らし合わせたいよねえ・・・ただ、BatchEvalRunnerに与えるデータセットは質問だけなので、せっかくデータセット作っても使いにくいんだよね。。。
Ragasに期待したほうが良さそうな気がしてる。
Ragasを使った評価
引き続きインデックス等はここまで使ったものをそのまま使う。
あとRagasでは質問・回答のセットが必要になるが、データセットも前回作ったものがそのまま使える。
questions = [i[0] for i in eval_dataset.qr_pairs]
answers = [i[1] for i in eval_dataset.qr_pairs]
print(questions[0])
print(answers[0])
ドウデュースの主な勝ち鞍は何ですか?
朝日杯フューチュリティステークス、東京優駿、有馬記念
回答は配列の配列にしておく必要がある模様。
eval_answers = [[a] for a in answers]
ではRagasをインストール
!pip install ragas
Ragasのメトリクスを設定
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_precision,
context_recall,
)
from ragas.metrics.critique import harmfulness
metrics = [
faithfulness,
answer_relevancy,
context_precision,
context_recall,
harmfulness,
]
LlamaIndexのクエリエンジン、メトリクス、質問、回答を渡して、Ragasで評価実施。ちなみにサラッと試したらgpt-4のrate limitに引っかかったのでgpt-3.5-turboに変えている。
from ragas.llama_index import evaluate
llm = OpenAI(model="gpt-3.5-turbo")
embed_model = OpenAIEmbedding()
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
)
query_engine = index.as_query_engine(service_context=service_context)
result = evaluate(query_engine, metrics, questions, eval_answers)
結果
{'faithfulness': 0.6621, 'answer_relevancy': 0.8607, 'context_precision': 0.1210, 'context_recall': 0.8106, 'harmfulness': 0.0000}
pandasのデータフレームで表示
result.to_pandas()
良きですねー

メトリクスの意味については以下も参考になる。
Evaluatorは他にも色々あるし、LabelledRagDatasetとかLlamaHubのデータセットとかもあるのだけど、とりあえず自分的にはragasをもう少し使い込んでみようというところ。ちょっとLlamaIndex標準の評価は過渡期なのかなーという気もするので。
retrieval単体評価のデータセットどう作ればいいんだろう?という疑問が湧いた。
そんなこんなしてるうちにこういうのを見つけた。
目的に合うのかどうかは置いといて、ちょっと気になったので使ってみる
考え方はこれで、最初にベースライン作って、そこからパラメータ調整していくイメージなんだけど、検索精度というよりは検索結果+レスポンス見てる感じなので、retriever単体の評価がしたいという自分のニーズとはちょっと違う感がある。
なんかこういうのを見てると、retrieval / synthesisを疎な感じでやること自体がそもそも間違ってるのかなぁという気がしてしまう。なんというかこうRAGは密になってしまうというか。。。
データセット周りでちょっと悩んでたので色々調べてみたところ、以下を見つけた。
これによると、最適なチャンクサイズを探るには以下が重要とある。
- 関連性と粒度
chunk_sizeを128のように小さくすると、より粒度の細かいチャンクが得られます。逆に、チャンクサイズが512の場合、上位のチャンクに必要な情報がすべて含まれることになり、クエリに対する回答がすぐに得られるようになります。これをナビゲートするために、「忠実性」と「関連性」メトリクスを採用しています。これらはそれぞれ、クエリと検索されたコンテキストに基づいて、「幻覚」がないことと、回答の「関連性」を測定します。- レスポンス生成時間
chunk_sizeが大きくなるにつれて、LLMが答えを生成するための情報量も大きくなる。これにより、より包括的なコンテキストを確保できる反面、システムの処理速度が低下する可能性があります。追加された深さがシステムの応答性を損なわないようにすることが重要です。
ふむ、ただこれって観点も含めて結局のところは、LLMも含めたe2eの評価だよねぇ。チャンクサイズごとに、ってのは気になるところなのだけども、retrieverの単体評価、というのとはちょっと違う。