haystackのAnnotation Toolを試す
経緯
ユーザーガイドはPDFだった・・・
以下のdocker-compose.ymlを拝借
ローカルで動かそうと思うので雑に設定。
version: "3"
services:
backend:
image: deepset/haystack-annotation:latest
environment:
NODE_ENV: "production"
DB_HOSTNAME: "db"
DB_NAME: "haystack" # 適当に設定、ただしPOSTGRES_DBと揃える
DB_USERNAME: "haystack" # 適当に設定、ただしPOSTGRES_USERと揃える
DB_PASSWORD: "haystack" # 適当に設定、ただしPOSTGRES_PASSWORDと揃える
DEFAULT_ADMIN_EMAIL: "example@example.com" # コメントアウト外して適当に設定、後述
DEFAULT_ADMIN_PASSWORD: "example" # コメントアウト外して適当に設定、後述
COOKIE_KEYS: "haystack" # コメントアウト外して適当に設定、
JWT_SECRET: "haystack" # コメントアウト外して適当に設定、
DOMAIN_WHITELIST: "*"
ports:
- "7001:7001"
links:
- "db:database"
depends_on:
- db
networks:
- app-network
restart: unless-stopped
db:
image: "postgres:12"
environment:
POSTGRES_USER: "haystack"
POSTGRES_PASSWORD: "haystack"
POSTGRES_DB: "haystack"
ports:
- "5432:5432"
volumes:
- ./postgres-data:/var/lib/postgresql/data
networks:
- app-network
healthcheck:
# ↓POSTGRES_USER/POSTGRES_DBに合わせて、usernameとdbnameを設定
test: "pg_isready --username=haystack --dbname=haystack && psql --username=haystack --list"
timeout: 3s
retries: 5
restart: unless-stopped
networks:
app-network:
driver: bridge
少しだけ設定について触れておく。
DEFAULT_ADMIN_EMAILとDEFAULT_ADMIN_PASSWDは管理者用アカウント用なのだけど、触ってみた感じだとこのアカウントでは、プロジェクトの作成、データの登録、アノテーション等、このツールを使ってやりたいことが一切できない模様。これらを使うにはログイン画面でアカウントを作成する必要がある。
なので、正直、この管理者用アカウントを何に使うのかがよくわからないのだけど、ここに自分のよく使うメアドなんかを使ってしまうと、結局別にアカウントを作成しないといけなくなり、別のメアドが必要になる。特にメアドでアカウント作成してもメールが飛んできたりはしないようなので、(ローカルで使う場合には)ADMINは適当に設定しておけばいいんじゃないかと思っている。
ということで、設定が終わったら起動
$ docker compose up
起動したら、http://XXX.XXX.XXX.XXX:7001/ にアクセス。
ログイン画面が表示されたら、"sign up here"からアカウント作成。
必要事項を入力して"Registration"をクリック。
アカウントが作成され、再度ログイン画面が表示されるので、作成したアカウントでログイン。
ログインできた。
メニューをざっと見ると、
- プロジェクト
- ドキュメント
- 質問
- インポート
- アノテーションのエクスポート
- ユーザー管理
という感じっぽい。とりあえず"Create project"でプロジェクトを作る。

プロジェクト名とアノテーションモードを設定して"Create project"をクリック。アノテーションモードは"Default"と"Answer Category"の2つがあるのだけど、まだどういう違いがあるのかわからない。とりあえず"Default"で作ってみる。
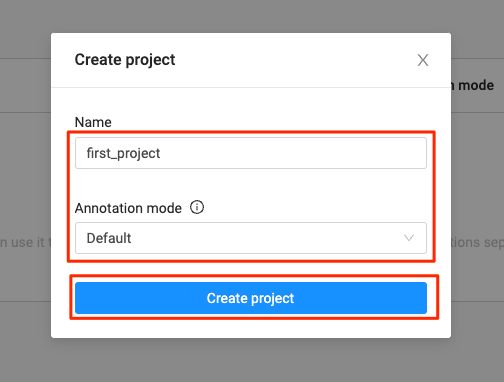
プロジェクトが作成された。では作成されたプロジェクトを選択する。左上のドロップダウンから選択するか、もしくはプロジェクト一覧の右にある「→」をクリック。
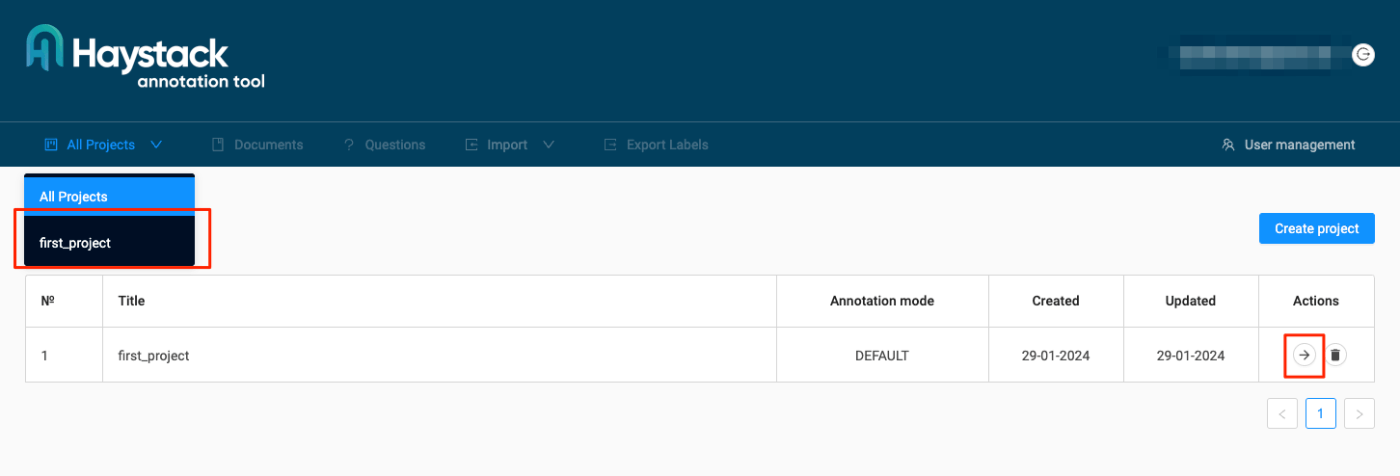
選択したプロジェクトに入った。まだドキュメントが1つもない状態なので、まずドキュメントを用意する。"Import" -> "Document"をクリック。
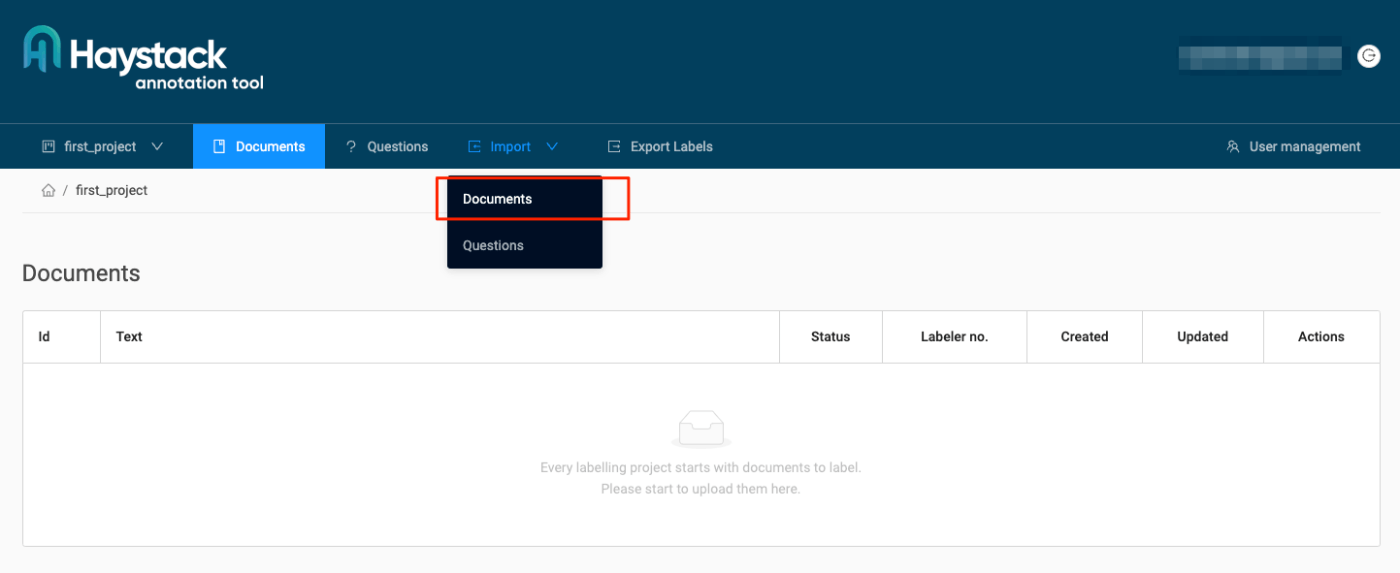
ファイルをアップロード。単体のテキストとCSVでのバッチアップロードができるっぽい。とりあえずwikipediaから取得したmarkdownを拡張子.txtに変更してアップロードして、アップロードが終わったらドキュメントメニューに戻る。
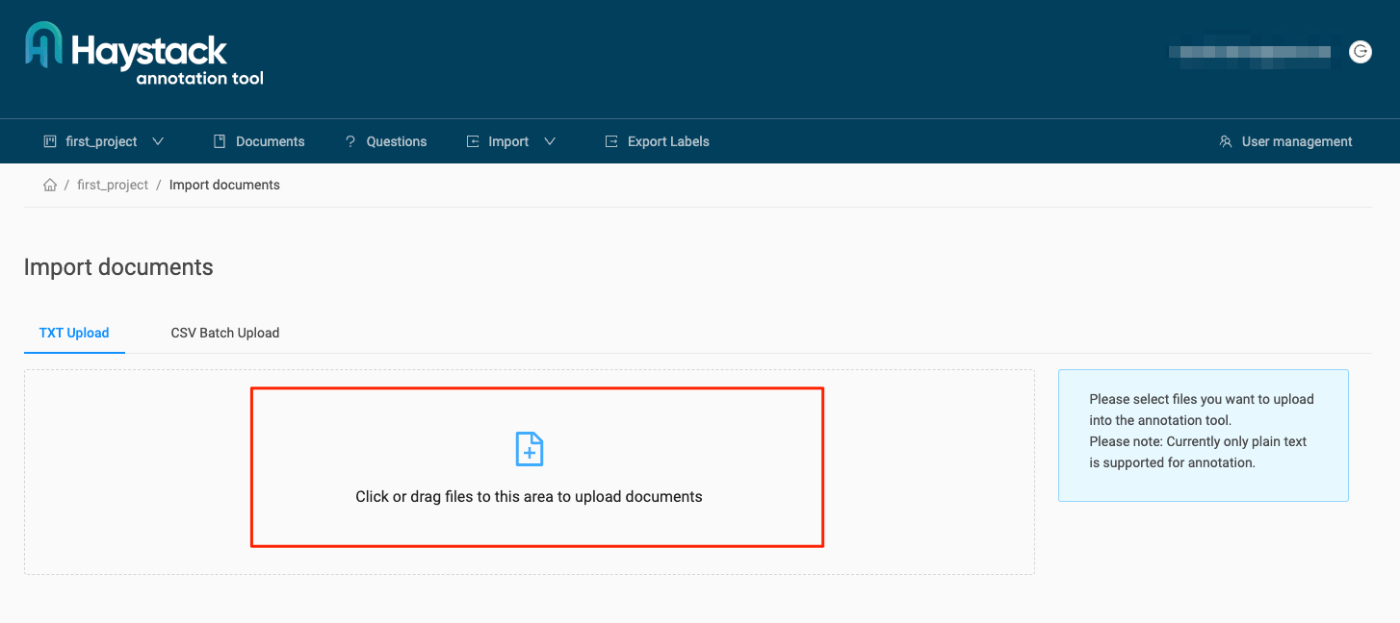
ドキュメントがアップロードされた。右の「→」をクリック。
ドキュメントが読み込まれている。左の"ADD CUSTOM QUESTION"をクリック。
回答となる箇所を部分選択する。
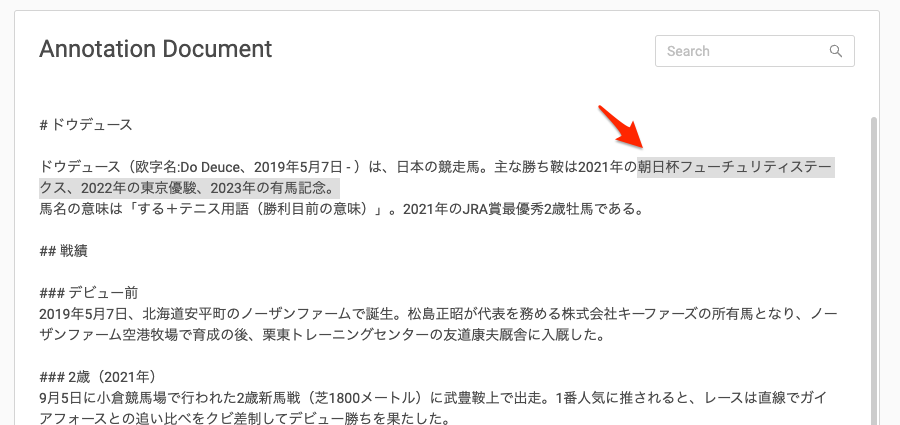
質問を入力する画面が出てくるので、選択した箇所が回答となるような質問を入力して"Submit"。Question Categoryはグレーアウトしているので、どう使うかはまだわからない。
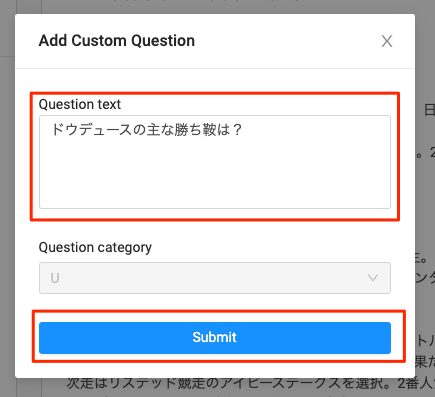
質問とドキュメントの該当箇所が紐付けられる。これを繰り返して、アノテーションしていく。注意としては、離れた複数の箇所を選択して1つの質問に紐付けることはできない。例えばこの例だと「ドウデュースの血統は?」に対して、「父」「母」の箇所が離れているので、両方を設定することはできない。
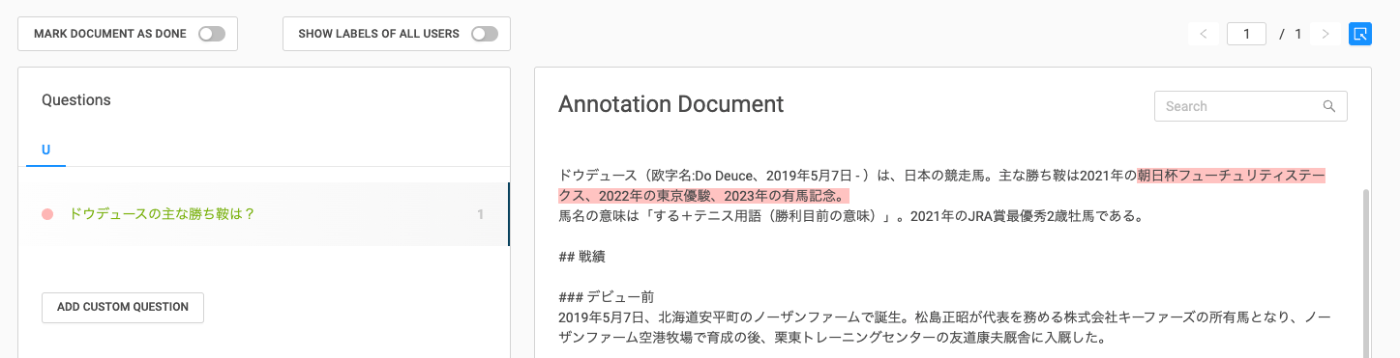
一通りアノテーションを作成したら、"Export Labels"をクリック。
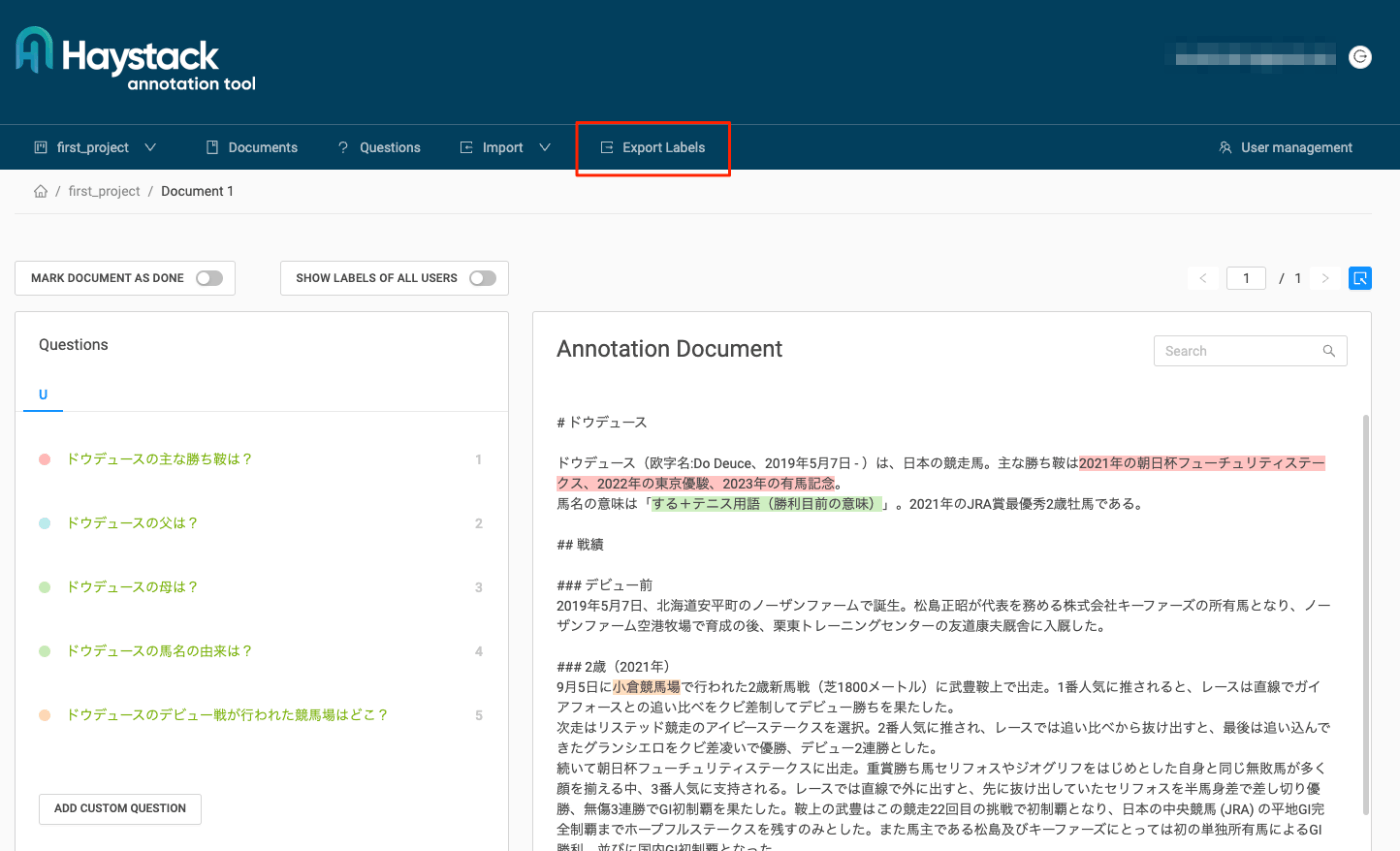
"Export answers"をクリックすると、Excel/CSV/SQuAD形式で出力ができる。今回はSQuAD形式で。
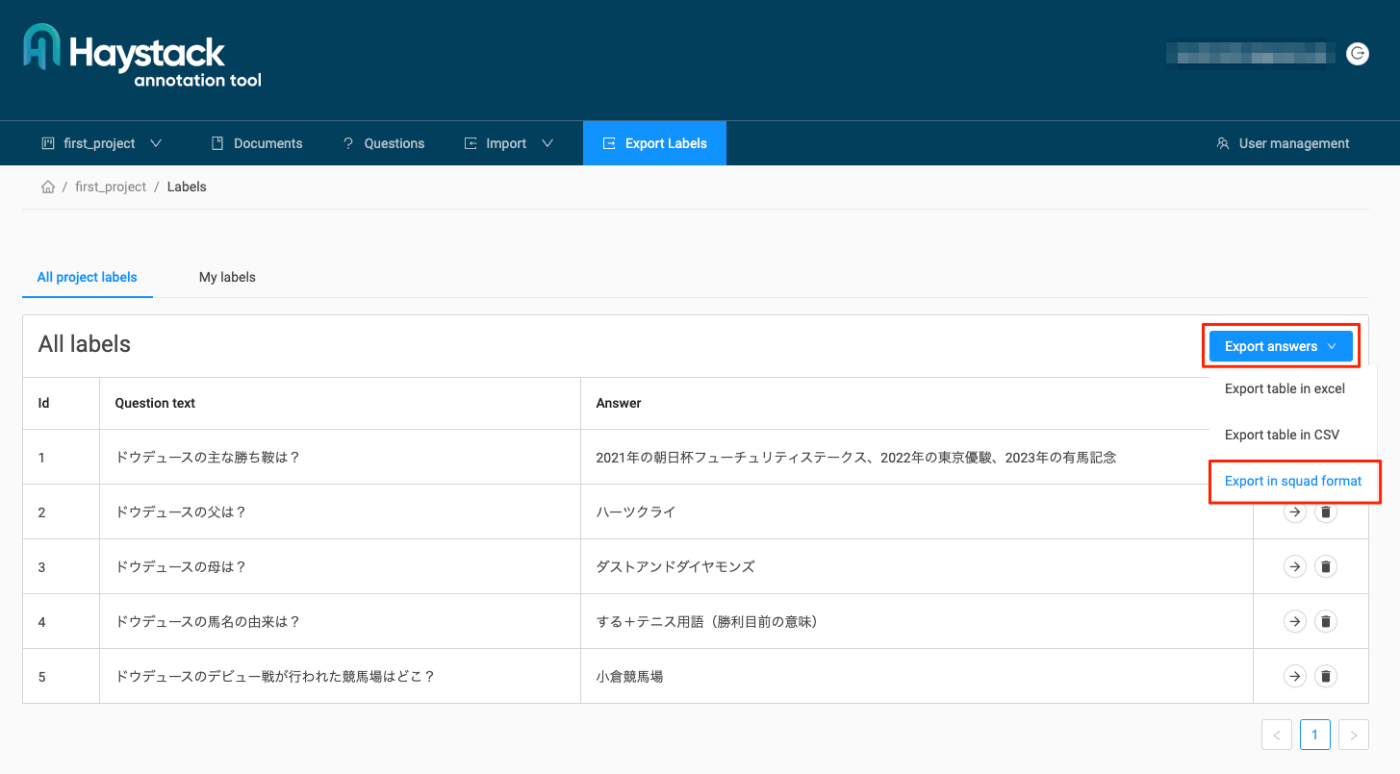
こんな感じのファイルが出力される。
{
"data": [
{
"paragraphs": [
{
"qas": [
{
"question": "ドウデュースの主な勝ち鞍は?",
"id": 1,
"answers": [
{
"answer_id": 1,
"document_id": 1,
"question_id": 1,
"text": "2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念",
"answer_start": 58,
"answer_end": 102,
"answer_category": null
}
],
"is_impossible": false
},
{
"question": "ドウデュースの父は?",
"id": 2,
"answers": [
{
"answer_id": 2,
"document_id": 1,
"question_id": 2,
"text": "ハーツクライ",
"answer_start": 3000,
"answer_end": 3006,
"answer_category": null
}
],
"is_impossible": false
},
(snip)
],
"context": "# ドウデュース\n\nドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。\n馬名の意味は(snip)## 脚注\n\n### 注釈\n\n### 出典\n\n## 外部リンク\n\n競走馬成績と情報 netkeiba、スポーツナビ、JBISサーチ、Racing Post",
"document_id": 1
}
]
}
]
}
その他の機能については、ドキュメント見るなり、実際に触ってみればわかるのではないかと思う。
今回の自分の目的にはあわなそうだけども、reader-retrieverモデルのデータセットを作るなら、まあ悪くないのではないだろうか。全部手動というわけではなくて、質問を予めファイルでインポートして、質問とドキュメントの該当箇所をアノテーションするだけ、みたいなこともできるので、質問はLLMに事前に生成させておいて、みたいな使い方もできそう。
あと、質問と回答のカテゴライズができたり、ネガティブなアノテーションとして「回答が含まれていない」「質問の意味がわからない」みたいなことも設定できるみたい。