LLMアプリの評価・分析ツール「Context.ai」を試す
よい表題が思いつかないけども、以下の記事で紹介したサービスの1つ。
ロギングとかトレースとかというよりは、ユーザの入力内容やAIのレスポンスのテキストを解釈して、ユーザの意図をカテゴライズしてどういう内容が多いのか、AIが適切な回答をしているのか、ユーザがそれに対して不満を感じていないか、などを評価するサービスのように思える。どっちかというとフィードバック的な意味合いが強い感がある。
なるほど、"context"というのはそういうことね。テキストの解釈にもLLMが使用されている様子。これちょっとおもしろい。
動画がわかりやすい。
マルチターンのインタラクションログを追いかけつつ、ユーザの満足度とか不満みたいなものを集計するのって結構難しいと思う。その点でこのサービスに興味を持ったので少し試してみる。
概要
上の動画が一番イメージしやすいと思うけど、ドキュメントだとこのあたり。
ドキュメント
Context.aiとは?
Context.aiは、LLMを利用した製品の評価・分析ツールである。
Context.aiを使えば、ユーザーが自然言語インターフェイスとどのようにやりとりしているかを理解することができる。これは、どこであなたの顧客が素晴らしい体験をしているかを知るのに役立つだけでなく、潜在的な改善領域をプロアクティブに検出することもできる。本番環境へ移行する前に、変更によるパフォーマンスへの影響を評価でテストし、不適切な会話が行われている場所を特定することができる。
Context.aiはこんな人に向いている:
- LLM応答の品質を測定し、改善したいソフトウェアおよび機械学習エンジニア
- LLMベースの機能のパフォーマンスを最適化したいプロダクトマネージャー
- 顧客の行動を理解したい創業者
アナリティクスのスタートガイドをご覧になれば、すぐにContext.aiを使い始めることができる。
概要
Context.aiの製品アナリティクスは、LLMアプリケーションの構築者がユーザーの行動と製品のパフォーマンスをよりよく理解することを可能にする。これにより、次のことが可能になる:
- 人々がなぜ、どのように製品を使用しているかを理解する。 ユーザーは何を求めているのか?
- 実際のユーザーからのフィードバック信号を使用して、製品のパフォーマンスを監視する。 ユーザーのニーズはどの程度満たされているか?
- 改善余地がある低パフォーマンスの領域を特定する。 どうすれば製品をより良くできるのか?
これらの質問に答えるために、Context.aiはトランスクリプトに、会話の意味と目的を捉えるトピックラベルで注釈を付ける。そしてContext.aiは、様々な成功指標を使ってすべての会話を採点する。この2つを組み合わせることで、プロダクトビルダーは、プロダクトがうまく機能しているトランスクリプトのグループと、改善が必要な領域を知ることができる。
私たちのアナリティクス製品との統合は30分もかからない。私たちのPythonまたはJavascript SDKを使用するか、APIを直接呼び出すことで開始できる。
料金
制限はあるが無料プランがある。
- 1ヶ月あたりのアナリティクスイベント: 1000回
- 1ヶ月あたりの評価: 100回
- 1アカウントのみ
- データ保持は30日間
有料プランは基本的に"contact sales"っぽいので金額感は不明。
Getting Started
Colaboratoryでやる。
事前準備として以下を用意しておくこと。
- https://with.context.ai でアカウントを作成。
- ログイン後の画面でAPIキーを取得しておく

なお、今回はPython SDKを使って進める。なお、上の方にも少し書いている通り、API / JavaScript SDKでも利用できるし、LangchainとHaystack向けのインテグレーションもある様子。
パッケージインストール
!pip install --upgrade context-python
Context.aiのAPIキーをColaboratoryのシークレットに登録しておいて、環境変数に読み込み。
from google.colab import userdata
import os
os.environ["GETCONTEXT_TOKEN"] = userdata.get('GETCONTEXT_TOKEN')
まずはLLMアプリなしで、会話ログを直接登録するのをやってみる。
import getcontext
from getcontext.generated.models import Conversation, Message, MessageRole, Rating
from getcontext.token import Credential
import os
token = os.environ.get("GETCONTEXT_TOKEN")
c = getcontext.ContextAPI(credential=Credential(token))
c.log.conversation(
body={
"conversation": Conversation(
messages=[
Message(
message="あなたは親切な日本語のアシスタントです。",
role=MessageRole.SYSTEM,
),
Message(
message="こんにちは!",
role=MessageRole.USER,
),
Message(
message="こんにちは!今日はどんなお手伝いをしましょうか?",
role=MessageRole.ASSISTANT,
rating=Rating.POSITIVE,
),
],
metadata={
"model": "gpt-3.5-turbo",
"user_id": "1234",
"environment": "test",
}
)
}
)
ざっと見た感じ、会話履歴をまるっと投げ込めばよいみたい。あとそれに付随するメタデータの指定ができたり、個々の発話のレイティングみたいなものも設定できるように見える。
Context.aiの管理画面を見てみる。
左のメニューから"Overview"で、会話がグラフで可視化される。会話数、ユーザー感情の平均、会話の平均ターン数、言語別の割合、など。あと表示はされていないけども、よく会話に出てくるトピックや、ユーザーフィードバックのトレンドなどが表示される様子。
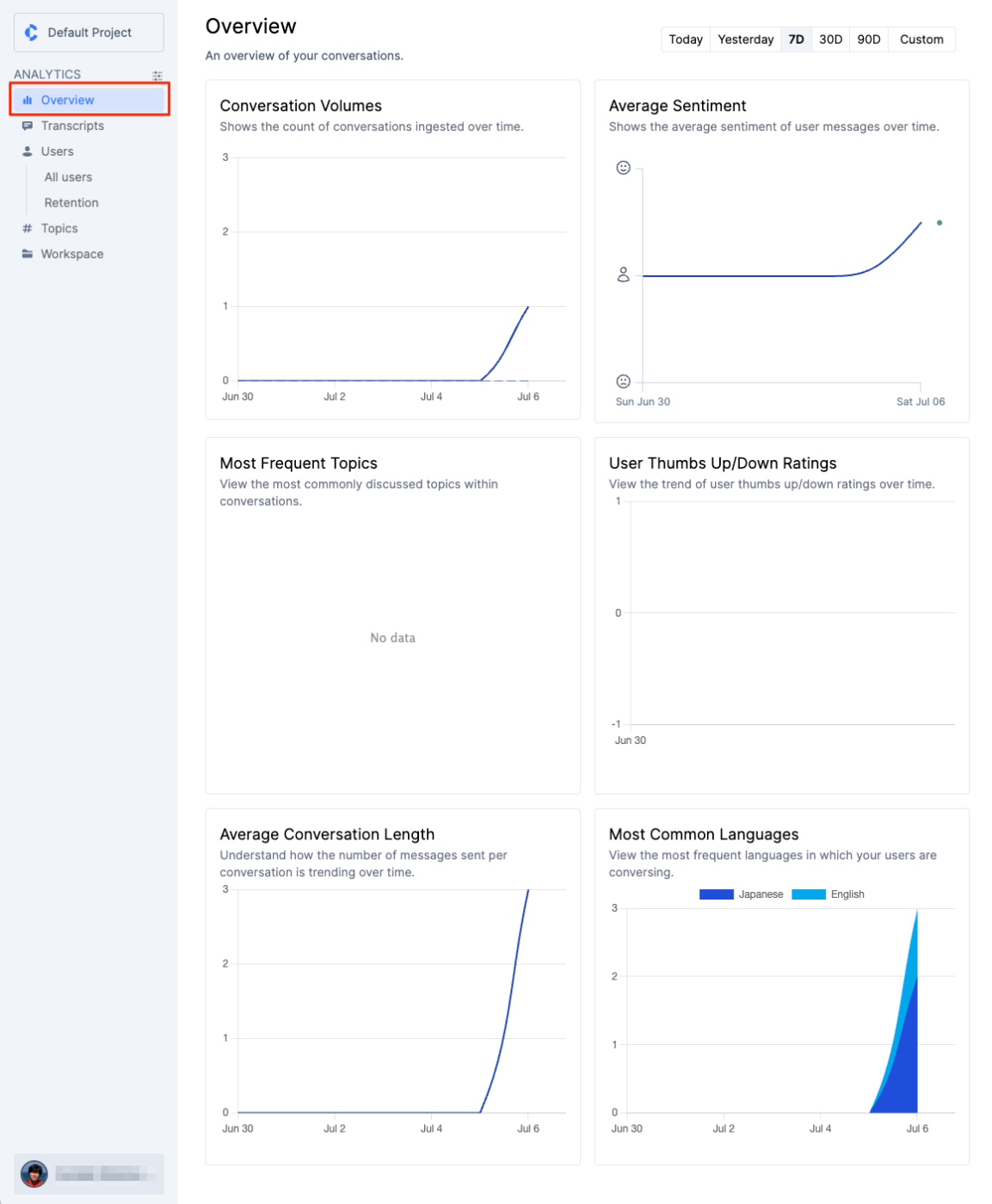
左メニューから"Transcript"を選択すると、個々の会話セッションが確認できる様子。先ほど登録した会話が見えているのでこれをクリック。

該当の会話セッションのやりとりが表示される。ここでユーザの発話に自動で"High Sentiment"がついていたり、登録時に付与したレイティングなどが、ラベリングされている。そして、これらを元に会話セッション自体にもラベルが付与されているのだろうと思う。これらは上のフィルターで絞り込んだりできるっぽい。
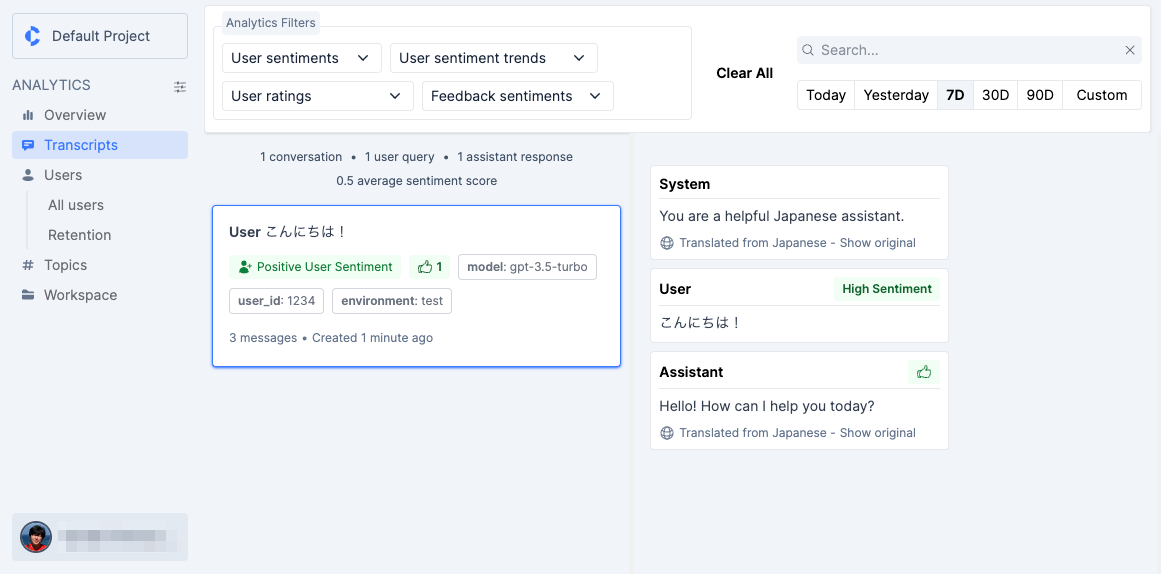
よく見ると、ユーザの入力以外は英語になっていて、自動的に翻訳されている様子。"Show original"で元々のクエリやレスポンスがそのまま表示される。今のところは英語圏がメインターゲットなのかも。
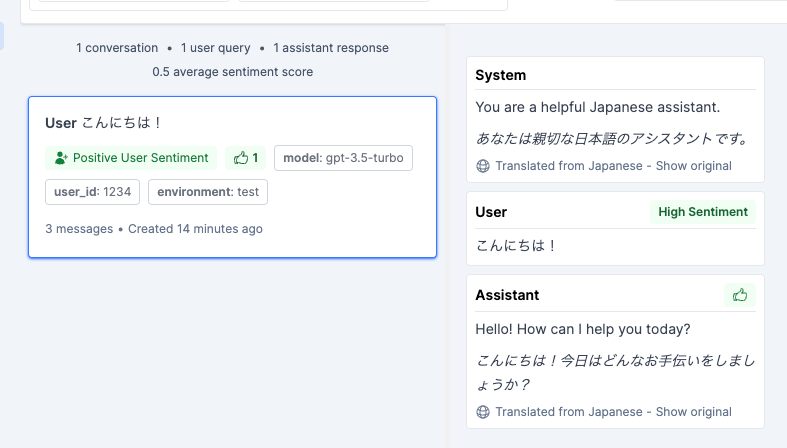
では会話の続きを登録してみる。上の会話に1つメッセージを追加しただけ。
c.log.conversation_upsert(
body={
"conversation": Conversation(
messages=[
Message(
message="あなたは親切な日本語のアシスタントです。",
role=MessageRole.SYSTEM,
),
Message(
message="こんにちは!",
role=MessageRole.USER,
),
Message(
message="こんにちは!今日はどんなお手伝いをしましょうか?",
role=MessageRole.ASSISTANT,
rating=Rating.POSITIVE,
),
Message(
message="今日は最高の1日だったんだよね!聞いてくれる?",
role=MessageRole.USER,
rating=Rating.POSITIVE,
),
],
metadata={
"model": "gpt-3.5-turbo",
"user_id": "1234",
"environment": "test",
}
)
}
)
GUIを見ると、先ほどのセッションに会話が追加されて、こちらにも"Sentiment"が付与されているのがわかるし、新しいメッセージのレイティングが加算されているのがわかる。

またラベルは自分で付与することもできる。スターもつけれる。
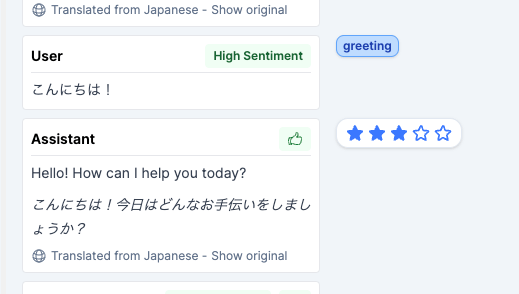
自分でつけたラベルでもフィルタできる。

メタデータを少し変えて会話を登録してみる。
c.log.conversation(
body={
"conversation": Conversation(
messages=[
Message(
message="あなたは親切な日本語のアシスタントです。",
role=MessageRole.SYSTEM,
),
Message(
message="ちょっと今困ってることがあって、相談に乗ってくれる・・・?",
role=MessageRole.USER,
),
Message(
message="それは大変ですね・・・お力になれるように努力しますので何でも聞いて下さい。どんなことでこまっているのですか?",
role=MessageRole.ASSISTANT,
rating=Rating.POSITIVE,
),
],
metadata={
"model": "gpt-4o",
"user_id": "5678",
"environment": "test",
}
)
}
)
別の会話セッションとして登録される。

左メニューの"User"をクリックすると、"Overview"と似た感じのグラフが表示されるが、ユニークユーザ、新規ユーザ、戻ってきたユーザ、利用頻度の高いユーザ、などに分類されて、よりユーザエンゲージメント的な要素で可視化される。

"User"->"All Users"とすすめば、個別のユーザIDごとにトレンドを見たり会話履歴を見たりすることができる。
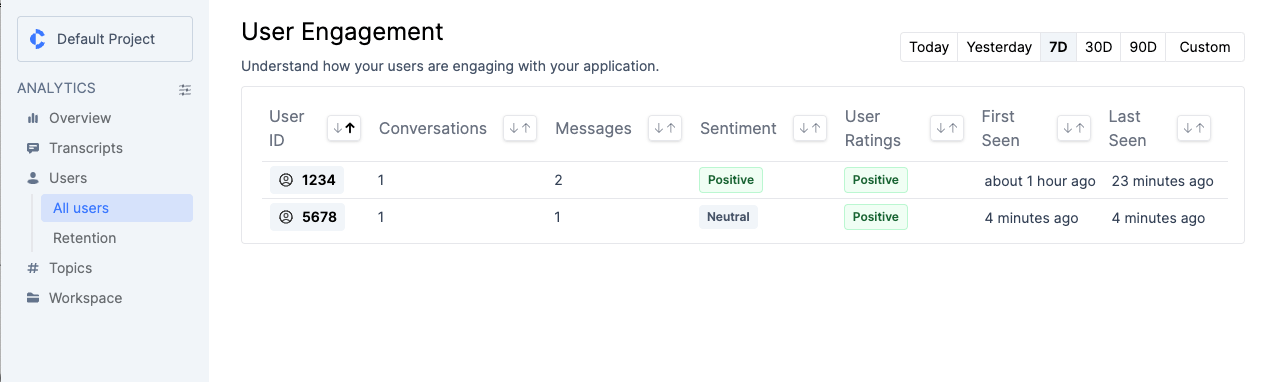

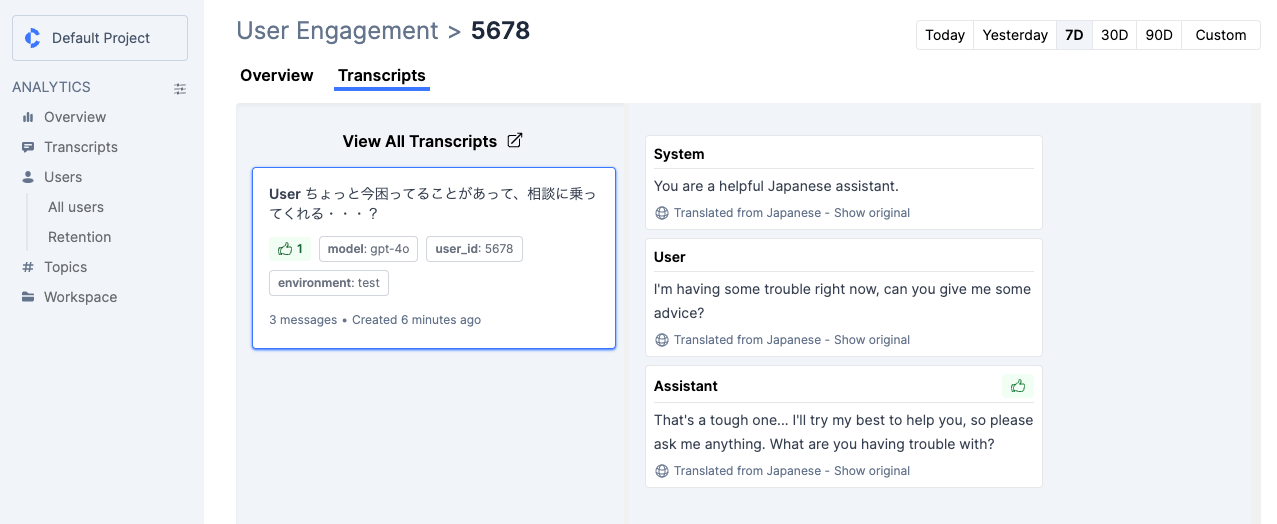
今回のテストだとデータが少ない・期間が短いせいか何も表示されなかったけども、リテンションの観点で見たりもできるみたい。

他にもGUIで見れることは色々あるし、SDKも非同期に対応していたり評価モジュールがあったりするようが、実際のチャットアプリ的なもので組み込んでみたくなった。
とりあえずLangChainとのインテグレーションなら簡単だろうと想定してドキュメントを見てみた。
が、LangChainのドキュメントが更新されたのでリンクが切れている様子。あたらしいドキュメントは以下。
ContextCallbackHandlerというコールバックを使えば良さそう。ただし、
- 上記はLLMChainで書かれていてちょっと古い感がある。できればLCELで書きたい。
- ContextCallbackHandlerのコードを見てみると、"user_id"を考慮していないし、これをクラスの外から受け渡すことも出来ない。
- 実際に古い書き方だとトレースはされるものの"user_id"が付与されない。
なので、user_idをちゃんと付与してやるには、まずこのクラスを継承したカスタムなクラスを書くなりする必要がありそう。
あと、Context.aiのPython SDKのコードはGitHub等でどうも公開されていないようで見つからない。PyPIにもURL等の記載がなかった。で、インストールされたパスのコードを見てみると、どうやら以下で自動生成されている様子。
で、なんでコードを見ようと思ったかというと、
The Upsert conversation method is deprecated in favor of the Threads Ingestion Method. Please do not use Upsert for new integrations, using Threads is much simpler and less prone to user error!
Context.aiのAPIリファレンスを見てみると、このUpsertというエンドポイントはdeprecatedらしい。で、Python SDKのGetting Startedで紹介されていたコード(log.conversation_upsert)もどうやらdeprecatedなAPIのままになっている模様。後継のAPIは以下のthread conversationなんだけども
ThreadとUpsertの違いは、
- Upcertは会話履歴を常にまるっと全部送って上書きする。ThreadはスレッドIDを元に追加分だけを送る。
- Threadは初期作成時にスレッドIDがレスポンスに付与されてくるので、それを次のリクエストに含めて送る。
あたりっぽくて、まあそらそのほうがいいよな、という感はあるのだけど、ただSDKのコード見てても、このThead APIを使って更新する方法がよくわからず、色々試してもうまくいかなかったので、一旦Upsertをそのまま使うことにする。
パッケージインストール
!pip install --upgrade --quiet langchain-core langchain-openai langchain_community context-python
!pip freeze | egrep -i "langchain|context-python"
context-python==0.18.0
langchain==0.2.6
langchain-community==0.2.6
langchain-core==0.2.11
langchain-openai==0.1.14
langchain-text-splitters==0.2.2
APIキーの読み込み
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
os.environ['GETCONTEXT_TOKEN'] = userdata.get('GETCONTEXT_TOKEN')
LCELでRunnableWithMessageHistoryを使った会話履歴を保持するチャットのコード。
# ContextCallbackHandlerを継承したContextCallbackHandlerを定義
class CustomContextCallbackHandler(ContextCallbackHandler):
# コンストラクタをオーバーライド
def __init__(self, token: str = "", verbose: bool = False, **kwargs: Any) -> None:
# kwargsでuser_idを含むmetadataを渡せるようにする
metadata = kwargs.get('metadata')
super().__init__(token=token, verbose=verbose, **kwargs)
if metadata and isinstance(metadata, dict):
self.metadata.update(metadata)
# 会話履歴をContext.aiに送信する関数をオーバーライド
def _log_conversation(self) -> None:
"""Log the conversation to the context API."""
if len(self.messages) == 0:
return
self.client.log.conversation_upsert(
body={
"conversation": self.conversation_model(
messages=self.messages,
metadata=self.metadata,
)
}
)
# Upsertだと全部の会話履歴を上書きするはず、と思っていたけど、
# どうも重複して追加されてしまうので、ここで初期化(元のコードのまま)
self.messages = []
# ここでmetadataを消すことでuser_idが消えてしまうのでコメントアウト
#self.metadata = {}
# 会話履歴を取り出す関数
def get_session_history(user_id: str) -> BaseChatMessageHistory:
if user_id not in store:
store[user_id] = ChatMessageHistory()
return store[user_id]
# 会話メモリを初期化
store = {}
# ユーザIDを定義
user_id = "abc1234"
# CustomContextCallbackHandlerを初期化、ここでContext.aiに送るmetadata(ユーザID)を渡す
token = os.environ.get("GETCONTEXT_TOKEN")
context_callback = CustomContextCallbackHandler(token, metadata={"user_id": user_id})
# モデルの定義、ここでcallbackも定義する
model = ChatOpenAI(model="gpt-3.5-turbo-0125", callbacks=[context_callback])
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは大阪のおばちゃんです。20字以内で簡潔、かつ大阪弁で元気に明るく回答します。",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
runnable = prompt | model | StrOutputParser()
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input",
history_messages_key="history",
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="User ID",
description="Unique identifier for the user.",
default="",
is_shared=True,
),
],
)
ではクエリを送ってみる。
with_message_history.invoke(
{"input": "おばちゃん、元気?"},
config={"configurable": {"user_id": user_id}},
)
もちろんやで!元気モリモリやで!ありがとな!
with_message_history.invoke(
{"input": "そうなんや、こっちは競馬に負けて最低やわ・・・"},
config={"configurable": {"user_id": user_id}},
)
そら残念やなぁ。次は絶対勝てるで!気持ち切り替えて、また頑張ってみてや!
with_message_history.invoke(
{"input": "そやなー、競馬は明日もあるし、頑張って取り戻すわ!おばちゃん、いつもありがとうな!"},
config={"configurable": {"user_id": user_id}},
)
ええやん!明日こそは大勝利やで!おばちゃんも応援してるで!頑張ってな!ありがとな!
ちょっとuser_idをいろんなところで渡してて冗長感があるんだけども。
ではContext.aiのGUIを確認してみる。

出来たっぽい。「競馬に負けた」ところで"very low sentiment"になっていて、そのあと気を取り直したところで"high sentiment"になっている。
LangChainのcallbacksを正しく理解できていないので、この修正の仕方が正しいのかどうかはちょっとわからない。
まとめ
トレーシング的なプロジェクトやプラットフォームはいくつかあるが、おそらく多くのものはデバッグとかロギングとかが目的になっているのに対して、ユーザエンゲージメントという観点で色々ラベリングしてくれるってのが、Context.aiのポイントだと思う。なるほど「コンテキスト」という名前は納得感がある。
マルチターンの会話を追いかけるのは結構面倒だし、さらにログ量が増えると大変になると思うので、その点でも良いサービスだと自分は感じた。
ただ、
- 価格がよくわからない
- SDKの使い方がよくわからない、ドキュメントが足りない
- オープンソース的なアプローチがほとんど見られないので、細かいところを追いかけにくい
- デバッグ的なトレーシングはできない
- コミュニティサポート的なものもない
あたりを考えると、エンジニア目線だとちょっと足りないかなという気もした。
着眼点は良さそうに思えるので、今後の展開に期待。
上に書いたことをフィードバックしてみたら、ドキュメントが更新された
Python SDKでThread APIを使うコードに更新された様子。
まず初回の会話ログを登録する。
import getcontext
from getcontext.generated.models import Conversation, Message, MessageRole, Rating, Thread
from getcontext.token import Credential
import os
from google.colab import userdata
os.environ["GETCONTEXT_TOKEN"] = userdata.get('GETCONTEXT_TOKEN')
token = os.environ.get("GETCONTEXT_TOKEN")
c = getcontext.ContextAPI(credential=Credential(token))
res = c.log.conversation_thread(
body={
"conversation": Conversation(
messages=[
Message(
message="あなたは親切な日本語のアシスタントです。",
role=MessageRole.SYSTEM,
),
Message(
message="こんにちは!",
role=MessageRole.USER,
),
Message(
message="こんにちは!今日はどんなお手伝いをしましょうか?",
role=MessageRole.ASSISTANT,
),
],
metadata={
"model": "gpt-3.5-turbo",
"user_id": "abcd1234",
"environment": "test",
}
)
}
)
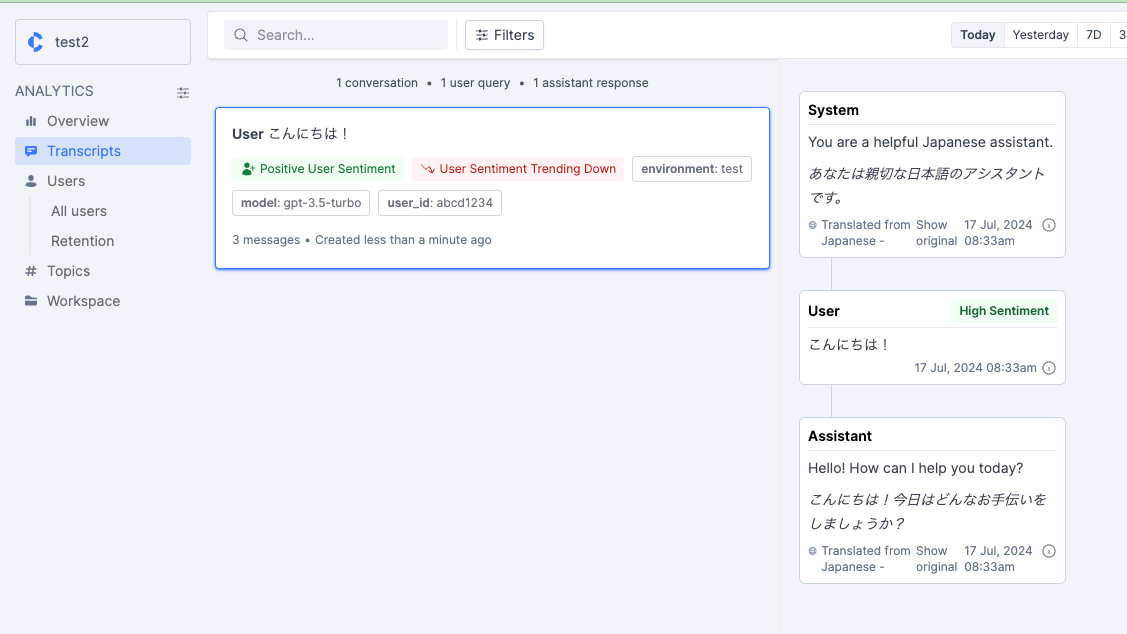
ここは前回とほぼ同じなのだけども、前回と違ってconversation_threadメソッドを使っている。スレッドのIDを指定せずにconversation_threadメソッドを実行すると、新規にスレッドIDが発行される。
thread_id = res.data.id
thread_id
c_6lenhmg68l1y19p
以降はこのThread IDを指定してconversation_threadメソッドを実行して、後続の会話だけを追加していけば良い。
c.log.conversation_thread(
body={
"conversation": Thread(
id=res.data.id,
messages=[
Message(
message="明日の天気を教えて。",
role=MessageRole.USER,
),
Message(
message="明日の東京都の天気は晴れ、1日中雨の心配はいりません。お出かけ日和ですね!",
role=MessageRole.ASSISTANT,
rating=Rating.POSITIVE,
),
],
metadata={
"model": "gpt-3.5-turbo",
"user_id": "abcd1234",
"environment": "test",
}
)
}
)
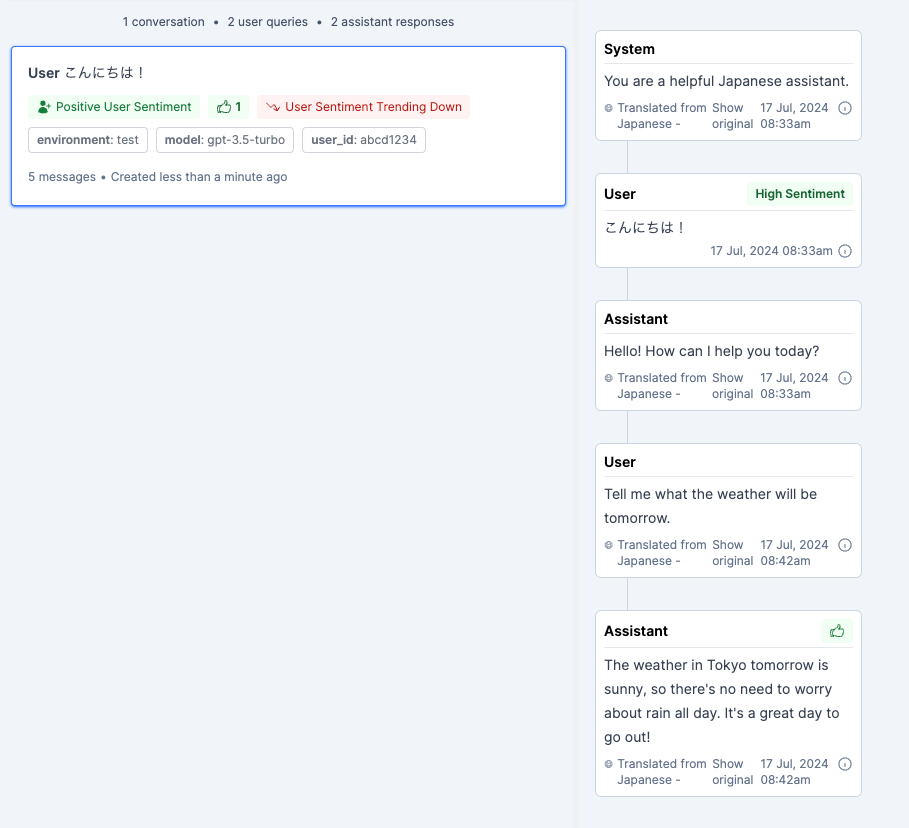
毎回全部の会話履歴を送信するconversation_upsertと違って、conversation_threadであれば追加分だけ送ればいいので、IDさえ引き継げばよいということになる。
ざっとOpenAI Python SDKを使ったシンプルなContext.ai連携のチャットアプリを書いてみた。
from google.colab import userdata
import getcontext
from getcontext.generated.models import Conversation, Thread
from getcontext.token import Credential
from openai import OpenAI
openai_client = OpenAI(api_key=userdata.get('OPENAI_API_KEY'))
context_client = getcontext.ContextAPI(credential=Credential(userdata.get('GETCONTEXT_TOKEN')))
metadata={
"model": "gpt-3.5-turbo",
"user_id": "hogehoge",
"environment": "test",
}
def get_response(messages):
try:
response = openai_client.chat.completions.create(
model=metadata["model"],
messages=messages
)
return response.choices[0].message.content
except Exception as e:
return f"エラーが発生しました: {str(e)}"
def convert_messages_for_context(messages: list[dict]) -> list[dict]:
"""OpenAIのメッセージフォーマットをContextのメッセージフォーマットに変換する"""
return [
{"message" if k == "content" else k: v for k, v in message.items()}
for message in messages
]
def chat():
print("チャットアプリへようこそ!")
print("終了するには 'quit' と入力してください。")
messages = [
{"role": "system", "content": "あなたは親切なアシスタントです。"}
]
# スレッドIDを初期化
thread_id = None
while True:
user_input = input("User: ")
if user_input.lower() == 'quit':
print("Assistant: チャットを終了します。さようなら!")
break
messages.append({"role": "user", "content": user_input})
gpt_response = get_response(messages)
print(f"Assistant: {gpt_response}")
messages.append({"role": "assistant", "content": gpt_response})
# スレッドIDがなければスレッドIDを取得、あればそのスレッドIDを使う
if thread_id == None:
res = context_client.log.conversation_thread(
body={
"conversation": Conversation(
messages=convert_messages_for_context(messages),
metadata=metadata,
)
}
)
thread_id = res.data.id
else:
res = context_client.log.conversation_thread(
body={
"conversation": Thread(
id=thread_id,
messages=convert_messages_for_context(messages[-2:]),
metadata=metadata,
)
}
)
if __name__ == "__main__":
chat()

こんな感じで記録される。
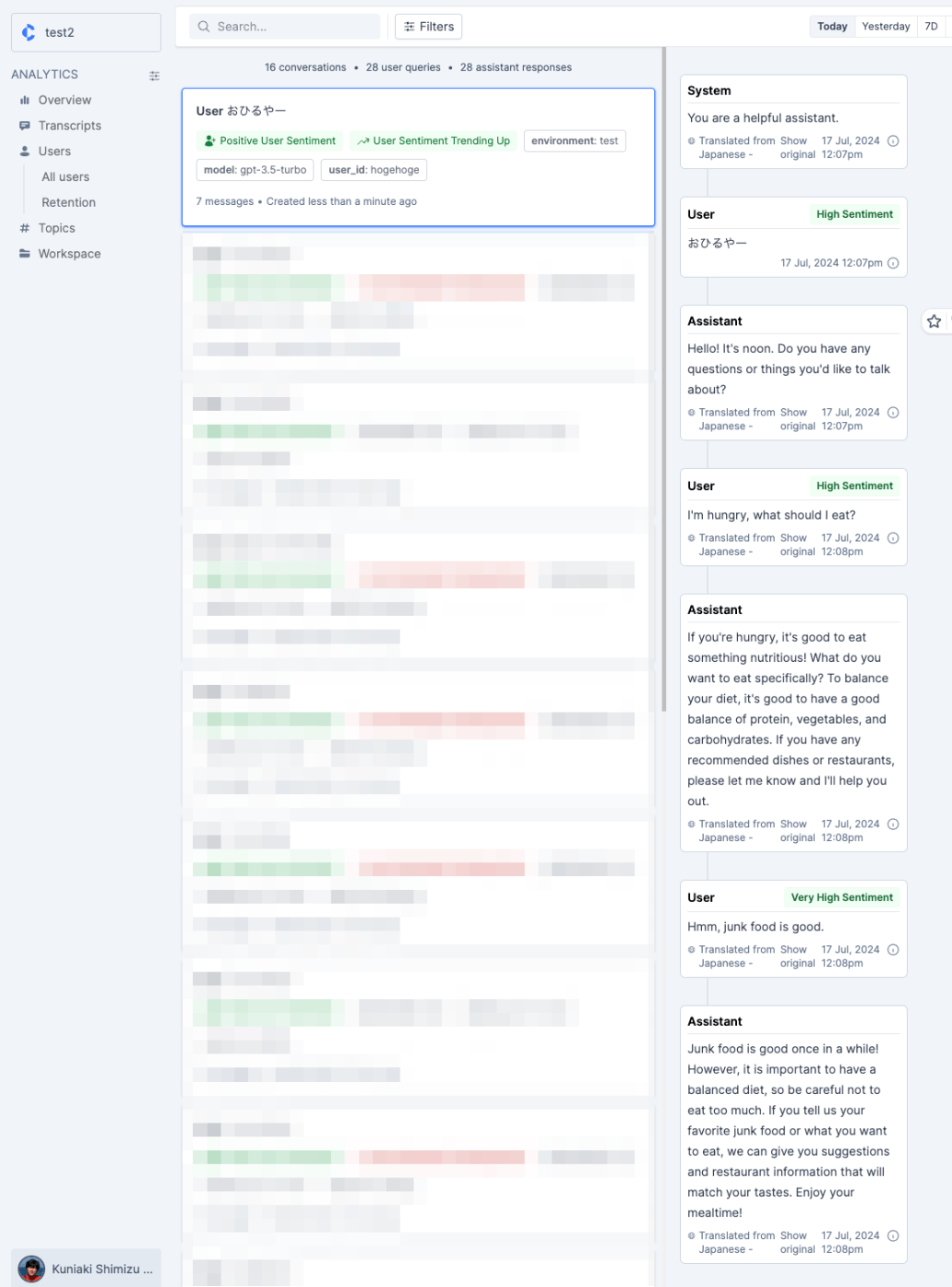
試しながら思ったけど、Sentimentの判定は日本語と英語だと少し違いがありそう(英語で判定してる気がするので、日本語的にHighかLowかという感覚とは少しずれがあるような気がする)