LlamaIndexでRAG Fusionを試す
日本語の解説記事。LangChain LCELでの実装例も(参考になる)
LlamaIndexでRAG Fusionを行う方法はざっと見た感じ3つあるように思える。
LlamaPackのRAGFusionPipelinePackを使う
Reciprocal Rerank Fusion Retrieverを使う
フルスクラッチでFusion Retrieverを作る
LCELっぽくやるならばQueryPipelineを使いたいところだけど、Reciprocal Rerank Fusion Retrieverを使うのが一番シンプルに見えるのでこれでやってみる。
今回は、Vector RetrieverとBM25 RetrieverをFusion RetrieverでラップしてHybrid Fusionとして使うことにする。
LlamaIndexでBM25 Retrieverを使うのは以下を参考。
パッケージインストール。BM25用にSudachiもインストール。トレーシング用にArize Phoenixも。
!pip install -U llama-index llama-index-retrievers-bm25 llama-index-callbacks-arize-phoenix sudachipy sudachidict-core sudachidict-core sudachidict-small sudachidict-full
Arize Phonixのトレーシングを有効化。
import phoenix as px
import llama_index.core
px.launch_app()
llama_index.core.set_global_handler("arize_phoenix")
APIキー読み込み
import os
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
データを用意する。以下を使う。
!wget https://d.line-scdn.net/stf/linecorp/ja/csr/dataset_.zip
!unzip dataset_.zip
import pandas as pd
df = pd.read_excel("dataset_.xlsx")
df.rename(columns={
'サンプル 問い合わせ文': 'Question',
'サンプル 応答文': 'Answer',
'カテゴリ1': 'Category',
}, inplace=True)
df.drop(columns=["ID", "カテゴリ2","出典","<参考>UMカテゴリタグ","<参考>UMサービスメニュー\n(標準的な行政サービス名称)"], inplace=True)
df.rename(columns={"サンプルID":"ID"}, inplace=True)
df

上記よりLlamaIndexのテキストノードを作成。
from llama_index.core.schema import TextNode, NodeRelationship, RelatedNodeInfo
nodes = []
for idx, row in df.iterrows():
id = row["ID"]
text = row["Answer"].replace("\n\n","\n")
node = TextNode(text=text, id_=id)
nodes.append(node)
日本語トークナイザーを設定。
from typing import List
from sudachipy import Dictionary, SplitMode
import requests
# stopwordsの設定。SlothLibのものを使用して、いくつか追加した
url = "http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt"
stopwords = []
for line in requests.get(url).text.split("\r\n"):
if len(line) > 1:
stopwords.append(line)
stopwords.extend(
[
"ください",
" ",
" ",
]
)
# キーワードだけ抽出したいので雑に品詞でフィルタした
pos_list = ["名詞","動詞","形容詞"]
sudachi_tokenizer = Dictionary(dict="full").create()
mode = SplitMode.C
# トークナイザーの定義
def ja_tokenizer(text: str) -> List[str]:
tokens = sudachi_tokenizer.tokenize(text, mode)
token_list = []
for token in tokens:
if token.surface() in stopwords:
continue
if token.part_of_speech()[0] not in pos_list:
continue
token_list.append(token.surface())
return token_list
ベクトルインデックスとRetrieverを作成。
from llama_index.core import VectorStoreIndex
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(model="text-embedding-3-small")
index = VectorStoreIndex(nodes, embed_model=embed_model, show_progress=True)
vector_retriever = index.as_retriever(similarity_top_k=4)
BM25Retrieverを作成。BM25Retrieverはベクトルインデックスからdocstore(おそらくテキストノードだけを持っている)を取得して作成できる様子。
from llama_index.retrievers.bm25 import BM25Retriever
bm25_retriever = BM25Retriever.from_defaults(
docstore=index.docstore,
similarity_top_k=4,
tokenizer=ja_tokenizer,
)
それぞれのRetrieverの動作確認。
Vector Retriever
results = vector_retriever.retrieve("母子手帳を受け取りたいのですが、手続きを教えてください。")
for r in results:
print("Score:",r.get_score())
print("ID:", r.id_)
print("Contents:", r.get_content()[:50])
print("******")
Score: 0.6957241831137635
ID: 108
Contents: 母子手帳をなくしたときは、再交付を受けてください。
お子さんが出生前の母子手帳については、(再交付を
Score: 0.6666531900418796
ID: 2
Contents: 母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)…
Score: 0.6609320925237477
ID: 3
Contents: 母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。
▼詳しくはこちら
(自治体HP
Score: 0.6298975509156324
ID: 36
Contents: 産前は母子手帳以外の手続きは特にありません。
産後に、出生の届出や出生通知書の提出、(自治体が行う出
BM25 Retriever
results = bm25_retriever.retrieve("母子手帳を受け取りたいのですが、手続きを教えてください。")
for r in results:
print("Score:",r.get_score())
print("ID:", r.id_)
print("Contents:", r.get_content()[:50])
print("******")
Score: 10.138956255349715
ID: 2
Contents: 母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)…
Score: 8.174780299250818
ID: 231
Contents: 住民票の写しについては、(請求・受け取りができる場所)で請求・受け取りができます。
▼詳しくはこち
Score: 7.8101200469768415
ID: 36
Contents: 産前は母子手帳以外の手続きは特にありません。
産後に、出生の届出や出生通知書の提出、(自治体が行う出
Score: 6.734619010857896
ID: 528
Contents: ごみの分別について、よく質問される品目の一覧はこちらをご覧ください。
(自治体HP内関連ページのUR
Fusion Retrieverを作成。
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core.retrievers.fusion_retriever import FUSION_MODES
from llama_index.llms.openai import OpenAI
import nest_asyncio
nest_asyncio.apply()
llm = OpenAI(model="gpt-3.5-turbo-0125", temperature=0.1)
multiple_query_gen_prompt_str = """\
あなたは1つの入力クエリに基づいて、複数のクエリを生成する親切なアシスタントです。
次の入力クエリに関連する{num_queries}個のクエリを各行に1つずつ生成してください。
クエリを生成する際は、元のクエリの意味を大きく変えない範囲で、関連性の高いと思われる文脈情報を絞り込んだり、元のクエリとは異なる表現で書き換えてください。
入力クエリ: {query}
生成したクエリ:
"""
fusion_retriever = QueryFusionRetriever(
# Fusionしたいretrieverのリスト
retrievers=[vector_retriever, bm25_retriever],
# クエリ生成に使用するLLM
llm=llm,
# 最終的に取得されるチャンクの数
similarity_top_k=5,
# 元のクエリを含んだトータルのクエリの数を指定する
# ex: 4個生成させたい場合は5を指定
# ex: 1だと生成されない(元のクエリだけになる)
num_queries=5,
# Fusionモードの指定、以下より選択
# - RECIPROCAL_RANK = "reciprocal_rerank" # Reciprocal Rank Fusion
# - RELATIVE_SCORE = "relative_score" # Relative Score Fusion
# - DIST_BASED_SCORE = "dist_based_score" # Distance-based Score Fusion
# - SIMPLE = "simple" # シンプルに元のスコアにもとづいてリランク
mode=FUSION_MODES.RECIPROCAL_RANK,
use_async=True,
verbose=True,
# クエリ生成時のプロンプトを指定
query_gen_prompt=multiple_query_gen_prompt_str,
)
QueryFusionRetrieverではクエリを生成するのでそのためのプロンプトが必要になる。ここでは元のクエリから類似のクエリを4個生成するように指示している(指定する数は元のクエリも含むのでトータルで5になる)
FusionモードはChatGPTに聞いてみた。
Rank Fusion(ランクフュージョン)は、異なる検索結果や評価基準から統合されたランキングを作成する方法です。それぞれの手法について、以下に簡潔に説明します:
- RECIPROCAL_RANK ("reciprocal_rerank") - 逆順位フュージョンを適用します。この方法では、各アイテムの順位の逆数を用いてスコアを算出し、これらを統合して最終的なランキングを決定します。例えば、あるアイテムが一つのリストで1位、別のリストで3位だった場合、それぞれの逆数(1と1/3)が計算され、その合計値に基づいてランク付けされます。
- RELATIVE_SCORE ("relative_score") - 相対スコアフュージョンを適用します。各リストにおけるアイテムのスコアを、そのリスト内での最高スコアや平均スコアなどに対する相対的な値(比率)として計算し、これを基にランキングを統合します。この方法では、各リストのスケールの違いを調整できるため、異なる評価基準を持つリスト間でも公平な比較が可能になります。
- DIST_BASED_SCORE ("dist_based_score") - 距離ベースのスコアフュージョンを適用します。このアプローチでは、各アイテムについて異なるリスト間の位置(距離)を考慮してスコアを計算します。たとえば、アイテムが各リストでどれだけ一貫して高い(または低い)位置にあるかに基づいて、その重要性を評価します。
- SIMPLE ("simple") - 単純な再順序付けを行います。この方法では、既存のスコアをそのまま使用して結果を再整理します。最も単純で直感的なアプローチであり、特定の結果セットに既に与えられているスコアに基づいて、新たなランキングを生成します。
あとはここにも少し書いてある。
トータルで実行されるクエリや取得されるチャンクの数はトレーシングで確認することとして、このFusion Retrieverにクエリを投げてみる。
nodes_with_scores = fusion_retriever.retrieve("母子手帳を受け取りたいのですが、手続きを教えてください。")
print("\n******")
for node in nodes_with_scores:
print("Score:",node.get_score())
print("ID:", node.id_)
print("Contents:", node.get_content()[:50])
print("******")
Generated queries:
- 母子手帳の受け取り手続きはどのようにすればいいですか?
- 母子手帳を取得するために必要な手続きを教えてください。
- 母子手帳を受け取るためにはどこに行けばいいですか?
- 母子手帳の手続きに必要な書類や条件は何ですか?
Score: 0.09865990111891751
ID: 2
Contents: 母子手帳は、○○市役所本庁舎△△階××課窓口、◎◎出張所、………(その他の受け取り場所を適宜記載)…
Score: 0.09865150713907986
ID: 108
Contents: 母子手帳をなくしたときは、再交付を受けてください。
お子さんが出生前の母子手帳については、(再交付を
Score: 0.09758463230171321
ID: 36
Contents: 産前は母子手帳以外の手続きは特にありません。
産後に、出生の届出や出生通知書の提出、(自治体が行う出
Score: 0.08119118967876239
ID: 3
Contents: 母子手帳は、妊娠届の内容を確認させていただき、その場でお渡しします。
▼詳しくはこちら
(自治体HP
Score: 0.048131080389144903
ID: 450
Contents: 妊娠したら妊娠届を○○課窓口(または支所・出張所窓口)に提出し、母子手帳を受け取ってください。
▼詳
最初に生成されたクエリが出力されている。その後出力されているチャンクは、これらのクエリをそれぞれのRetrieverに投げて、得られた全チャンクをランキング順位を元に上位5件ひろった結果の様子。
では、トレーシングを見てみる。

一番上のretrieveはFusion Retrieverによる最終的なretrievalの結果なので、実際のRetrievalはその下位で行なわれているRetrievalになる。
順に見ていく。
まず最初にLLMでクエリを生成している。

合計5個のクエリを生成した。これらをそれぞれのRetrieverになげてretrievalする。
1つ目のクエリをまずVector Retrieverに投げて結果を取得。

同じクエリをBM25 Retrieverに投げて結果を取得。
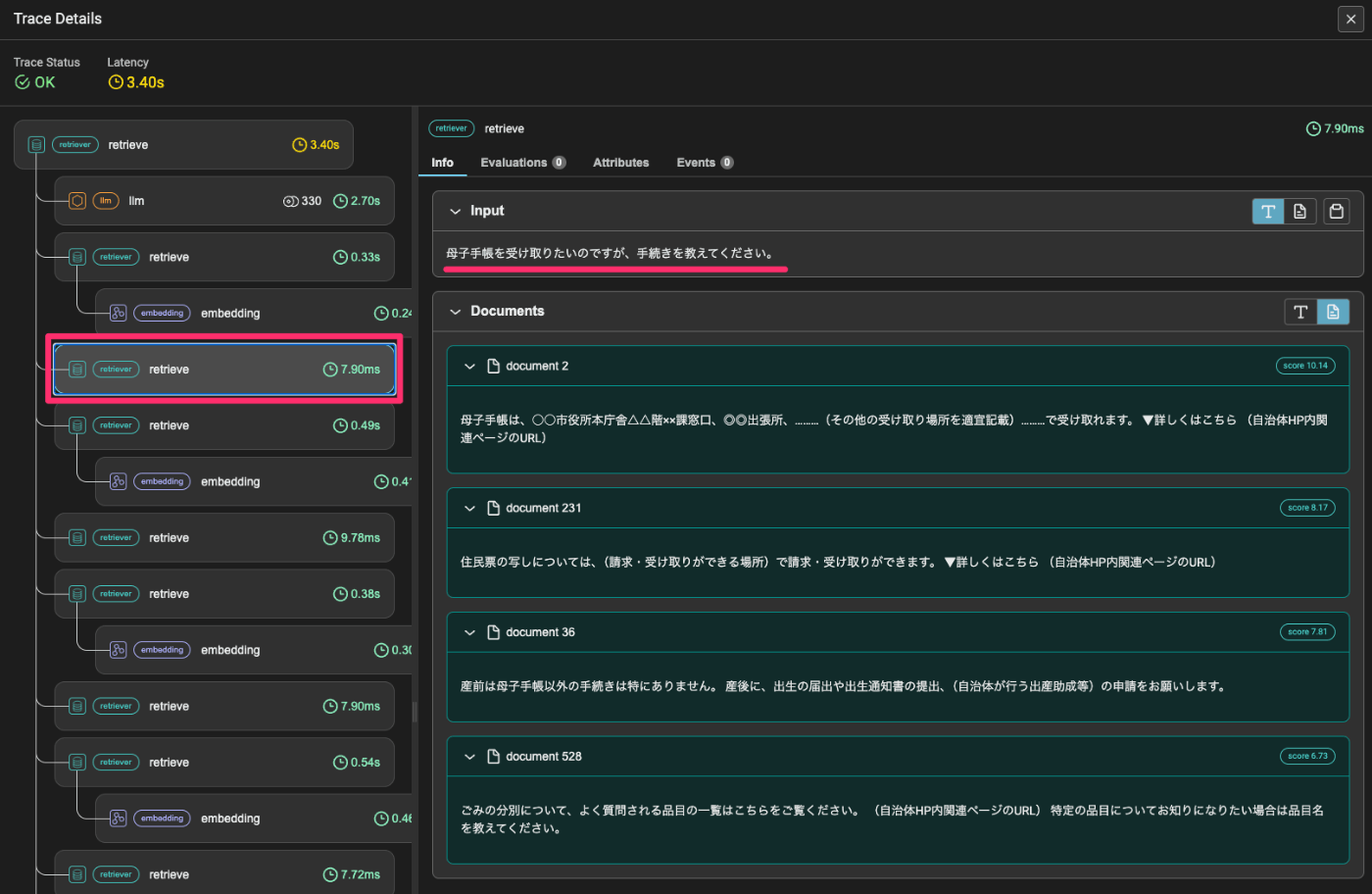
で次に2番目のクエリをVector Retrieverに投げて結果を取得。
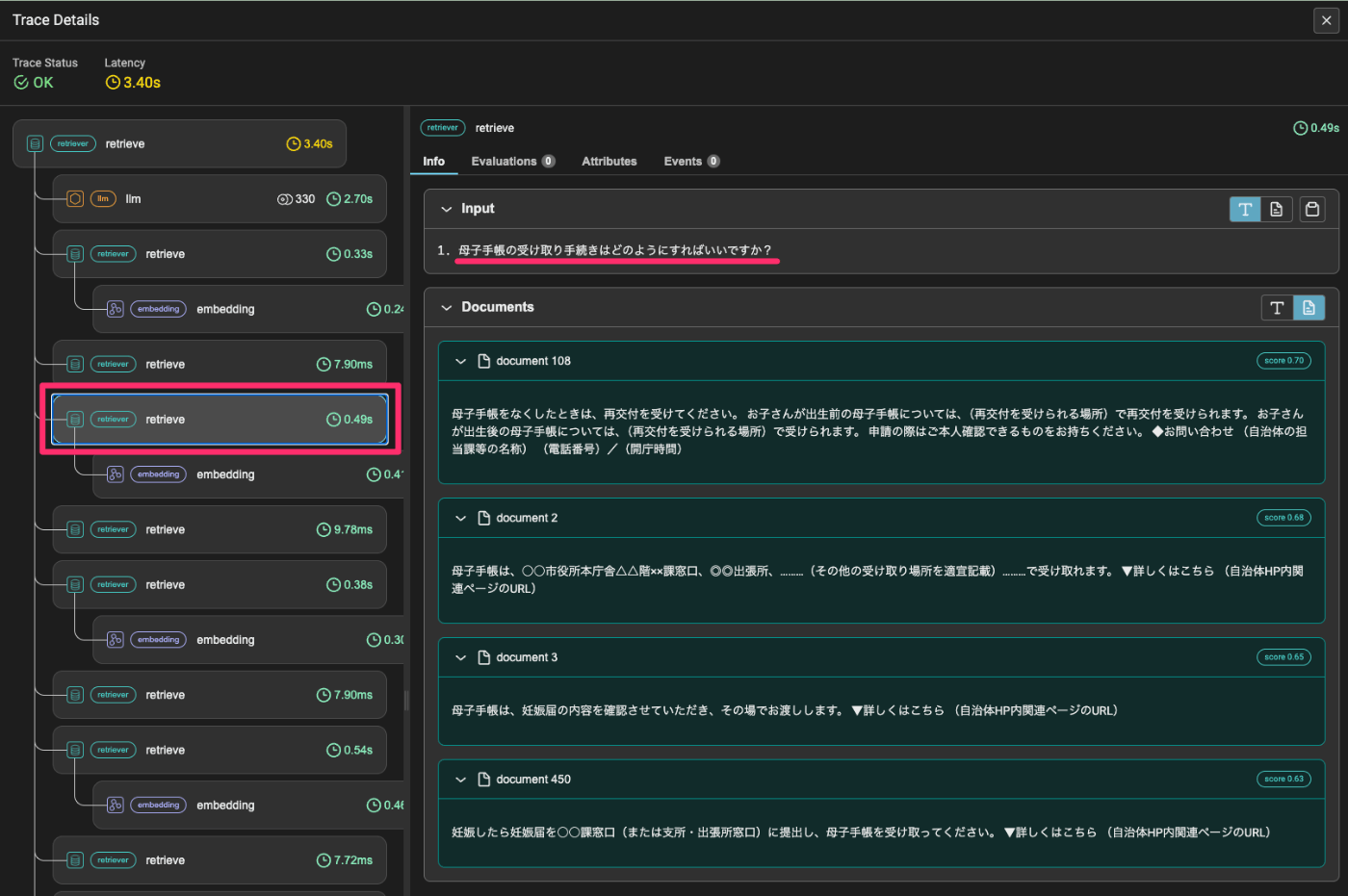
このようにして全クエリを各Retrieverごとに投げる。
よって、
- Retriever x 2
- Vector Retriever・BM25 Retriever共にsimilarity_top_kは4
- クエリ: 5(入力クエリ1+生成したクエリ4)
となるので、2 x 4 x 5 = 40チャンク が得られる。当然重複しているものもあるだろうけども、これらをReciprocal Rank Fusionアルゴリズムでリランキングして、Fusion Retrieverのsimilarity_top_kで指定した上位5件を拾ったのが最後の結果ということになる。
で精度はどうなの?っていう話だけど、今回の例だと本来ほしいドキュメントのIDは1のものなので実は取れていない。

ただ、チューニング的なところは何も考慮せずにやってるだけなので、精度を上げる余地は多分にあるとは思う。
- 今回はQAデータを使用して、Aをベクトル化している。したがって、Qとは文章のボリュームや使用されているキーワードなどで乖離がある。
- ベクトルインデックスだと、意味的に近しいということである程度近いものを拾えそう
- 逆にBM25だとクエリのキーワード次第で他のものが上位に来るとかありそう
- 例えば今回の例だとクエリのキーワードは
['母子手帳', '受け取り', '手続き', '教え']になる - 該当のID:1のAには「母子手帳」しか含まれていない
- 例えば今回の例だとクエリのキーワードは
- 個人的な主観だとBM25はそのままだとなかなか欲しいコンテキストを得にくい印象がある。
- チューニングを行う必要はある。
- 固有名詞とかは強そう。
- Fusion Retrieverは、各Retrieverの検索結果をもとにリランキングする。つまり、各Retrieverの検索結果数が少なくて、その時点で拾えていないとなると、そもそもFusion Retrieverのリランクの土俵に上がってこない。
- 元の各Retrieverのtop-kは多めに取ったほうがいいような気がしている。これはリランカー使うときも同じで、多めにとってリランクさせて上位を拾うってのが良さそう。
- これにより関連するコンテンツを集めてRAGの最終的な生成内容をよりリッチにするっていう意味合いがあると思う。
- まあそのためにクエリを生成させて入るのだけども、どんなクエリが生成されるか次第で変わるのでなんとも。
- 元の各Retrieverのtop-kは多めに取ったほうがいいような気がしている。これはリランカー使うときも同じで、多めにとってリランクさせて上位を拾うってのが良さそう。
- ベクトルインデックスとBM25はデフォルトだと50:50で重み付けがされている。この割合を変えることで順位などが変わる。
-
retriever_weights=[7,3]みたいな感じで指定できる
-
この辺をチューニングすればある程度の精度改善はできるのではないかな?しらんけど。
WeaviateやMeilisearchでやったときも思ったけど、ハイブリッド、いい感じのバランス取るのが難しい割に精度めちゃ上がるって感じもしなくて難しい。チューニングが足りないのかもしれないけど、うーん、という感じ。
今回はVectorRetriever/BM25RetrieverでHybrid Fusionにしたけど、単にVectorRetrieverだけで複数クエリのバリエーションだけに対応するっていうほうがまずは試しやすいかなと思った。
fusion_retriever = QueryFusionRetriever(
retrievers=[vector_retriever], # ここ
llm=llm,
similarity_top_k=5,
num_queries=5,
mode=FUSION_MODES.RECIPROCAL_RANK,
use_async=True,
verbose=True,
query_gen_prompt=multiple_query_gen_prompt_str,
)
この場合だと異なる言い方でベクトル検索する感じなので、概ね似たような検索結果にはなるけど、多少クエリのばらつきにも対応できるし、最終的な回答のリッチさも少しはあがるかなというところ。
そのへんはともかくとして、LlamaIndexのFusion Retriever、めちゃめちゃ簡単に書けてしまう。最初に紹介したフルスクラッチのやつと見比べるとかなりコンパクトになっているのがわかる。