LLMをscikit-learnのように扱える「Scikit-LLM」を試す
2024/10のTechnology RaderでAssessになってた「Dynamic few-shot prompting」のところで出てきた。
GitHubレポジトリ
Scikit-LLM: Scikit-Learnと大規模言語モデルの融合
ChatGPTのような強力な言語モデルをscikit-learnにシームレスに統合し、テキスト分析タスクを強化。
ドキュメント
実はさらっとscikit-learnのGetting Startedだけは以下で終わらせた。全然見についてはいないけど、雰囲気は多少感じれたのかな。
ということで少しやってみる。
Quick start
ColaboratoryでQuick startに従って進めてみる。以下のような題材。
Scikit-LLMを使ってGPT-4でゼロショットテキスト分類を行う方法を見てみましょう。
パッケージインストール
!pip install scikit-llm
!pip freeze | grep -i "scikit"
scikit-image==0.24.0
scikit-learn==1.5.2
scikit-llm==1.4.0
APIキーをセット。よくある環境変数の設定とは違うみたい。
from skllm.config import SKLLMConfig
from google.colab import userdata
SKLLMConfig.set_openai_key(userdata.get('OPENAI_API_KEY'))
テキストのZero-Shot分類を行う。まず分類用データセットを取得。
from skllm.datasets import get_classification_dataset
# 感情分析データセット
# ラベル: positive, negative, neutral
X, y = get_classification_dataset()
ちょっとデータセットの中身を覗いてみる。
print(len(X))
print(X[0])
30
I was absolutely blown away by the performances in 'Summer's End'. The acting was top-notch, and the plot had me gripped from start to finish. A truly captivating cinematic experience that I would highly recommend.
print(len(y))
print(y[0])
30
positive
なるほど、英文とその感情のラベルがそれぞれX, yに入っている。
日本語のデータセットについては後でやってみるとして、一旦はこれで進めてみる。
ZeroShotGPTClassifierで分類器を作成。このあたりはscikit-learnっぽさが出ている。
from skllm.models.gpt.classification.zero_shot import ZeroShotGPTClassifier
# gpt-4o-miniを用いたゼロショット分類器の作成
clf = ZeroShotGPTClassifier(model="gpt-4o-mini")
# 分類器のフィッティング(訓練データを使用)
clf.fit(X,y)
# テキストデータ X に対して予測を実行
predictions = clf.predict(X)
print()
print(predictions)
結果
100%|██████████| 30/30 [00:17<00:00, 1.76it/s]
['positive' 'positive' 'positive' 'positive' 'positive' 'positive'
'positive' 'positive' 'positive' 'positive' 'negative' 'negative'
'negative' 'negative' 'negative' 'negative' 'negative' 'negative'
'negative' 'negative' 'negative' 'neutral' 'neutral' 'neutral' 'neutral'
'neutral' 'neutral' 'neutral' 'neutral' 'neutral']
scikit-learn的な感覚で、データセットからフィッティングして、そのデータセットのまま予測してるんだから、全部同じだろ、と思ったら、微妙に違った。
import numpy as np
print(np.array_equal(y, predictions))
for i in range(0, len(y)):
print(f"Train: {y[i]} Predict: {predictions[i]}")
False
Train: positive Predict: positive
Train: positive Predict: positive
Train: positive Predict: positive
Train: positive Predict: positive
Train: positive Predict: positive
Train: positive Predict: positive
Train: positive Predict: positive
Train: positive Predict: positive
Train: positive Predict: positive
Train: positive Predict: positive
Train: negative Predict: negative
Train: negative Predict: negative
Train: negative Predict: negative
Train: negative Predict: negative
Train: negative Predict: negative
Train: negative Predict: negative
Train: negative Predict: negative
Train: negative Predict: negative
Train: negative Predict: negative
Train: negative Predict: negative
Train: neutral Predict: negative
Train: neutral Predict: neutral
Train: neutral Predict: neutral
Train: neutral Predict: neutral
Train: neutral Predict: neutral
Train: neutral Predict: neutral
Train: neutral Predict: neutral
Train: neutral Predict: neutral
Train: neutral Predict: neutral
Train: neutral Predict: neutral
fitを使っているけど、実際には訓練を行っているわけではなくて、多分プロンプト組み立ててるだけなんじゃないかなと思うのだけどどうだろう。
上記の例は言ってしまうと訓練データを使った「教師あり学習」と言えると思う(といってもどういう使い方になるのかがわからないけど)。Zero−Shotの場合は「教師なし学習」と同じように訓練データなし・ラベルだけで分類できる。
from skllm.models.gpt.classification.zero_shot import ZeroShotGPTClassifier
# ラベルだけを指定して分類器を作成
clf = ZeroShotGPTClassifier(model="gpt-4o-mini")
# フィッティング時に訓練データは渡さず、ラベル候補のみ指定
clf.fit(None, ["positive", "negative", "neutral"])
# テキストデータ X に対して予測を実行
predictions = clf.predict(X)
print()
print(predictions)
100%|██████████| 30/30 [00:16<00:00, 1.87it/s]
['positive' 'positive' 'positive' 'positive' 'positive' 'positive'
'positive' 'positive' 'positive' 'positive' 'negative' 'negative'
'negative' 'negative' 'negative' 'negative' 'negative' 'negative'
'negative' 'negative' 'negative' 'neutral' 'neutral' 'neutral' 'neutral'
'neutral' 'neutral' 'neutral' 'neutral' 'neutral']
日本語でもやってみる。
感情分類用の以下のデータセットを使った。
!pip install datasets
まずトレーニングデータを20件ピックアップする。
from datasets import load_dataset
import pandas as pd
import numpy as np
dataset = load_dataset("llm-book/wrime-sentiment")
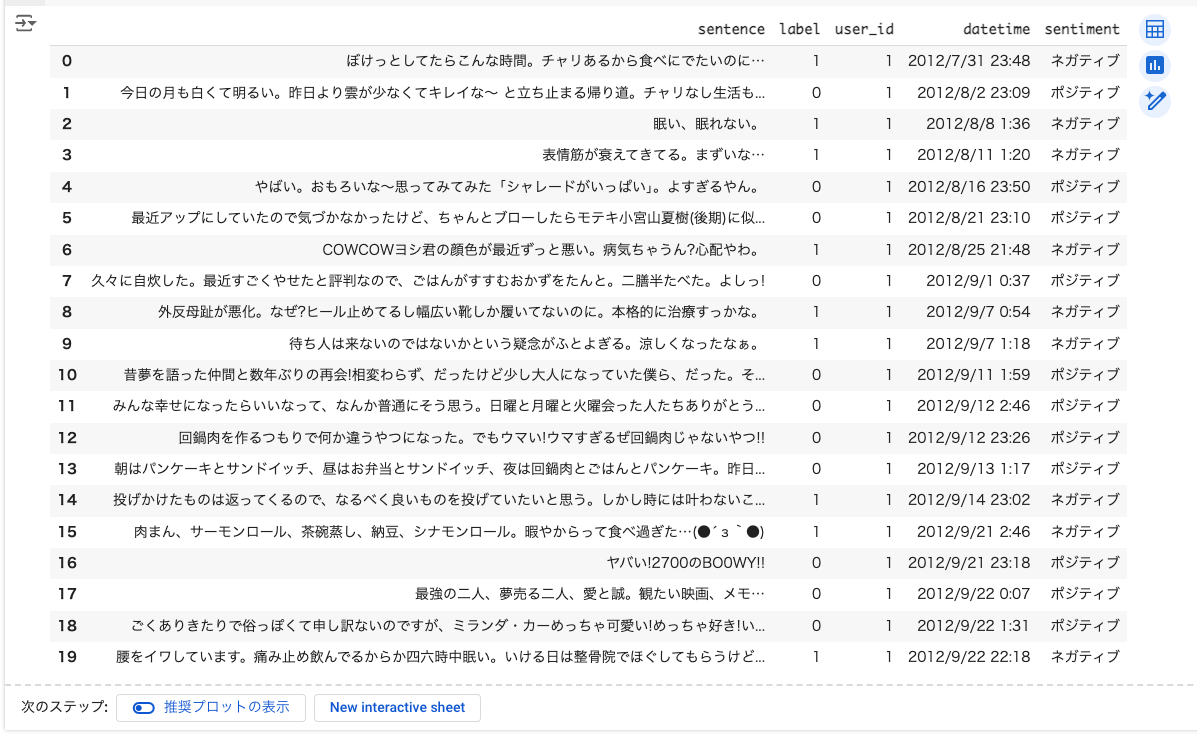
train_df = pd.DataFrame(dataset["train"][:20])
train_df['sentiment'] = np.where(train_df['label'] == 0, "ポジティブ", "ネガティブ")
train_df
同じようにテストデータも20件ピックアップ。
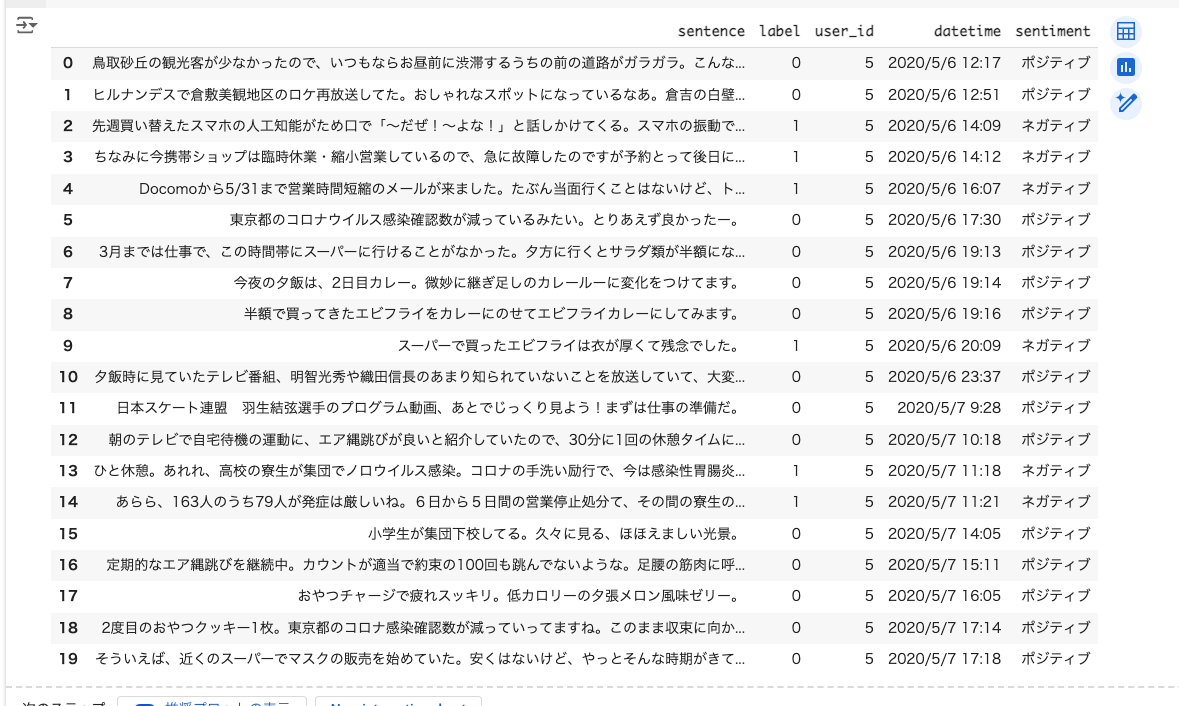
test_df = pd.DataFrame(dataset["test"][:20])
test_df['sentiment'] = np.where(test_df['label'] == 0, "ポジティブ", "ネガティブ")
test_df
ではトレーニングデータでフィッティングを行い、テストデータで予測を行う。
from skllm.models.gpt.classification.zero_shot import ZeroShotGPTClassifier
clf = ZeroShotGPTClassifier(model="gpt-4o-mini")
X = list(train_df['sentence'])
y = list(train_df['sentiment'])
clf.fit(X,y)
predictions = clf.predict(list(test_df["sentence"]))
print()
print(predictions)
100%|██████████| 20/20 [00:10<00:00, 1.83it/s]
['ネガティブ' 'ポジティブ' 'ネガティブ' 'ネガティブ' 'ネガティブ' 'ポジティブ' 'ポジティブ' 'ポジティブ' 'ポジティブ'
'ネガティブ' 'ポジティブ' 'ポジティブ' 'ポジティブ' 'ネガティブ' 'ネガティブ' 'ポジティブ' 'ポジティブ' 'ポジティブ'
'ポジティブ' 'ポジティブ']
結果を比較してみる。
import numpy as np
test_sentiments = list(test_df['sentiment'])
print(np.array_equal(test_sentiments, predictions))
for i in range(0, len(test_sentiments)):
same = False
if test_sentiments[i] == predictions[i]:
same = True
print(f"Train: {test_sentiments[i]} Predict: {predictions[i]} Same?: {same}")
False
Train: ポジティブ Predict: ネガティブ Same?: False
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
OpenAI以外にもAzure、VertexAI、GGUF(llama-cpp-python)、OpenAI互換APIに対応している模様。
モデルによって、サブモジュールに分かれている、estimatorsの名称が変わる、ので適宜置き換える。
- 例
- OpenAI
- サブモジュール:
from skllm.models.gpt.classification.zero_shot - estimator:
ZeroShotGPTClassifier
- サブモジュール:
- VertexAI
- サブモジュール:
from skllm.models.vertex.classification.zero_shot - estimator:
ZeroShotVertexClassifier
- サブモジュール:
- OpenAI
あと別パッケージになるが、Ollamaも使える。
なお、以降はOpenAIのものを使っていく。
もう少し見てみる。ドキュメントでは以下が紹介されている。
- テキスト分類
- Zero-Shot
- Few-Shot
- Dynami Few-Shot
- Chain-of-thought
- Tunable(ファインチューニングだと思う)
- テキスト→テキストのモデリング
- 要約
- 翻訳
- Tunable
- テキストのベクトル化
- タグ
- 名前付きエンティティ認識
テキスト分類: Zero-shot
ここはQuick Startでもやってるところなので、Quick Startで出てこなかったことだけピックアップ。
まずトレーニングデータの扱いなんだけど、そもそもZero-Shotはトレーニングデータが不要。
from skllm.models.gpt.classification.zero_shot import ZeroShotGPTClassifier
from skllm.datasets import get_classification_dataset
X, _ = get_classification_dataset()
clf = ZeroShotGPTClassifier()
clf.fit(None, ["positive", "negative", "neutral"])
labels = clf.predict(X)
Quick startでも、fitにトレーニングデータも与えている例がまず最初に来るので、ん?となっていたのだけど、トレーニングデータがない例が本来の使い方として考えれば良いのではないかと思う。
あともう一つ、MultiLabelZeroShotGPTClassifierでマルチラベルも使える。
マルチラベルのサンプルデータセットをまず見てみる。
from skllm.datasets import get_multilabel_classification_dataset
X, y = get_multilabel_classification_dataset()
import pprint
print(len(X))
pprint.pprint(X[:5])
10
['The product was of excellent quality, and the packaging was also very good. '
'Highly recommend!',
'The delivery was super fast, but the product did not match the information '
'provided on the website.',
'Great variety of products, but the customer support was quite unresponsive.',
'Affordable prices and an easy-to-use website. A great shopping experience '
'overall.',
'The delivery was delayed, and the packaging was damaged. Not a good '
'experience.']
print(len(y))
pprint.pprint(y[:5])
10
[['Quality', 'Packaging'],
['Delivery', 'Product Information'],
['Product Variety', 'Customer Support'],
['Price', 'User Experience'],
['Delivery', 'Packaging']]
1文に対して複数のラベルが付与されているということね。これを使って分類してみる。
candidate_labels = [
"Quality",
"Price",
"Delivery",
"Service",
"Product Variety",
"Customer Support",
"Packaging",
"User Experience",
"Return Policy",
"Product Information",
]
clf = MultiLabelZeroShotGPTClassifier(model="gpt-4o-mini", max_labels=3)
clf.fit(None, [candidate_labels])
predictions = clf.predict(X)
max_labelsで出力するラベルの数を指定できる。
結果
print(predictions)
[['Quality' 'Packaging' 'User Experience']
['Delivery' 'Product Information' 'Quality']
['Product Variety' 'Customer Support' '']
['Price' 'User Experience' 'Service']
['Delivery' 'Packaging' 'User Experience']
['Customer Support' 'Return Policy' '']
['Return Policy' 'User Experience' 'Product Information']
['Service' 'Delivery' 'Quality']
['Quality' 'Price' 'User Experience']
['Product Information' 'Delivery' '']]
テキスト分類: Few-shot
FewShotGPTClassifierやMultiLabelFewShotGPTClassifierを使う。
上の方でも少し試した感情分類用の以下のデータセットを使ってトレーニングデータを準備。
!pip install datasets
from datasets import load_dataset
import pandas as pd
import numpy as np
dataset = load_dataset("llm-book/wrime-sentiment")
train_df = pd.DataFrame(dataset["train"])
train_df['sentiment'] = np.where(train_df['label'] == 0, "ポジティブ", "ネガティブ")
# ラベルごとのサンプリングするデータ数
sample_size = 10
# ポジティブとネガティブで分ける
positive_sample_df = train_df[train_df['sentiment'] == "ポジティブ"].sample(n=sample_size, random_state=42)
negative_sample_df = train_df[train_df['sentiment'] == "ネガティブ"].sample(n=sample_size, random_state=42)
# 結合してランダムに並べ替える
train_sample_df = pd.concat([positive_sample_df, negative_sample_df]).sample(frac=1, random_state=42).reset_index(drop=True)
train_sample_df

本来のscikit-learnならば、トレーニングデータは大量に用意するのだろうけども、ドキュメントにある通り、
Scikit-LLM が提供する推定器は、学習データのサブセットを自動的に選択するのではなく、学習セット全体を使用して例を構築します。したがって、トレーニングセットが大きい場合は、トレーニングセットと検証セットに分割することを検討し、トレーニングセットは小さく保つことをお勧めします(1クラスあたり10例を超えないことをお勧めします)。さらに、再帰バイアスを避けるために、サンプルの順序を入れ替えることをお勧めします。
Scikit-LLMでは、恐らくfitで渡すトレーニングデータはプロンプト内のFew-Shotとして使用されることになると思うので、あまり大量に渡さない方が良いと思う(最近のLLMならできるかもしれないけど、コストやレスポンスの観点もあるし)。
このへんは、書き方や概念的にはscikit-learnと似て非なるところではないかな?逆にscikit-learnを知っているほうが混乱するかも。
次にテストデータ。
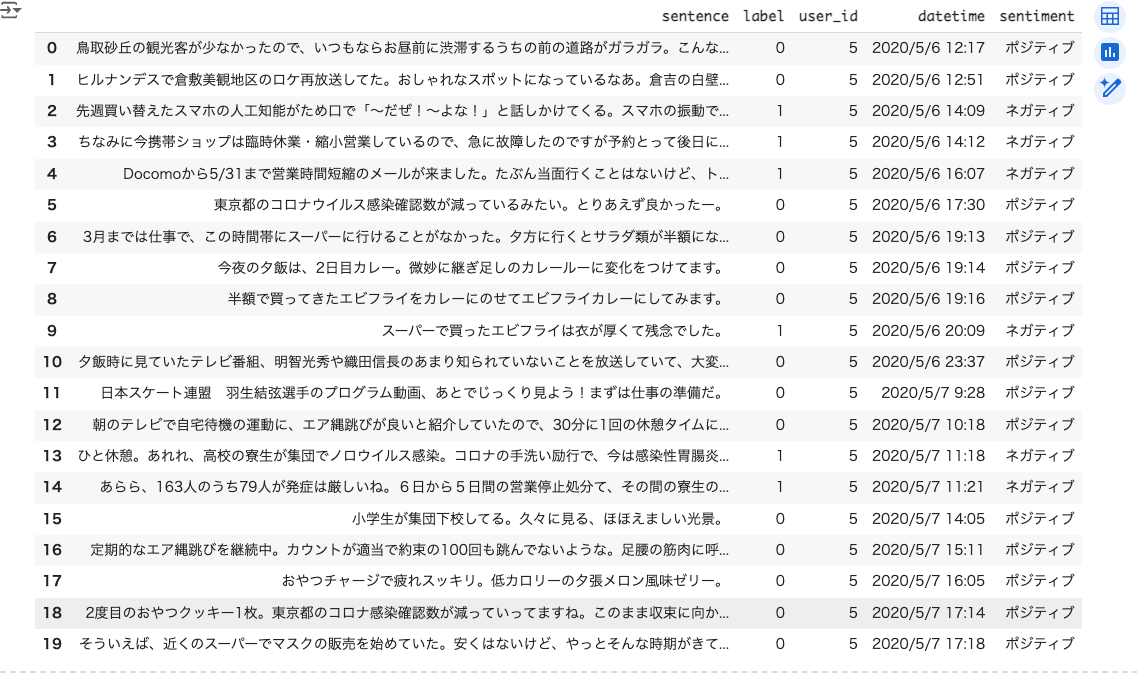
test_df = pd.DataFrame(dataset["test"][:20])
test_df['sentiment'] = np.where(test_df['label'] == 0, "ポジティブ", "ネガティブ")
test_df
ではFew−Shotで分類してみる。
from skllm.models.gpt.classification.few_shot import FewShotGPTClassifier
clf = FewShotGPTClassifier(model="gpt-4o-mini")
X = list(train_sample_df['sentence'])
y = list(train_sample_df['sentiment'])
test = list(test_df['sentence'])
clf.fit(X,y)
predictions = clf.predict(test)
結果
import numpy as np
test_sentiments = list(test_df['sentiment'])
print(np.array_equal(test_sentiments, predictions))
for i in range(0, len(test_sentiments)):
same = False
if test_sentiments[i] == predictions[i]:
same = True
print(f"Train: {test_sentiments[i]} Predict: {predictions[i]} Same?: {same}")
False
Train: ポジティブ Predict: ネガティブ Same?: False
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ネガティブ Same?: False
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ネガティブ Predict: ネガティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
Train: ポジティブ Predict: ポジティブ Same?: True
ドキュメントにはマルチラベルの例があるので、興味があればそちらを。
テキスト分類: Dynamic Few-shot
今回Scikit−LLMを触ろうと思った理由はこれ。とりあえずドキュメントを読んでみる。
Dynamic Few-Shot ClassificationはFew-Shot Text Classificationを拡張したもので、より大規模なデータセットに適しています。各クラスに対して固定のサンプルセットを使用する代わりに、各サンプルに対して動的なサブセットをその場で構築します。これにより、モデルの限られたコンテクストウィンドウを効率的に利用し、消費されるトークンの数を節約することができます。
以下でも少し調べているけども、クエリに最適なFew-shotをベクトル検索等で動的に取得してプロンプトを構築するというもの。
ドキュメントのサンプルは、レビュー文が、本に関するものか、映画に関するものか、を分類するというもの。日本語に訳してやってみる。
まずトレーニングデータを用意。
X = [
# 例1: 本 - サイエンスフィクション
"私はサイエンスフィクション小説を読むのが大好きです。それは私を別の世界に連れて行ってくれます。",
# 例2: 本 - ミステリー
"良いミステリー小説は、最後まで私を推理させます。",
# 例3: 本 - 歴史
"歴史小説は、異なる時代や場所の感覚を与えてくれます。",
# 例4: 映画 - サイエンスフィクション
"私はサイエンスフィクション映画を見るのが大好きです。それは私を他の銀河に連れて行ってくれます。",
# 例5: 映画 - ミステリー
"良いミステリー映画は、私をシートの端に座らせ続けます。",
# 例6: 映画 - 歴史
"歴史映画は過去の一瞥を提供します。"
]
y = ["本", "本", "本", "映画", "映画", "映画"]
以下のクエリを分類するものとする。
query = "私はこのSF小説が大好きになりました。科学とフィクションのユニークな融合に魅了されました。"
DynamicFewShotGPTClassifierを使って、分類器を作成。予測する前に、プロンプトがどうなるかを見てみる。
from skllm.models.gpt.classification.few_shot import DynamicFewShotGPTClassifier
import json
clf = DynamicFewShotGPTClassifier(n_examples=1).fit(X,y)
prompt = clf._get_prompt(query)
システムプロンプト
print(prompt["system_message"])
You are a text classifier.
ユーザプロンプト
print(prompt["messages"])
You will be provided with the following information:
1. An arbitrary text sample. The sample is delimited with triple backticks.
2. List of categories the text sample can be assigned to. The list is delimited with square brackets. The categories in the list are enclosed in the single quotes and comma separated.
3. Examples of text samples and their assigned categories. The examples are delimited with triple backticks. The assigned categories are enclosed in a list-like structure. These examples are to be used as training data.
Perform the following tasks:
1. Identify to which category the provided text belongs to with the highest probability.
2. Assign the provided text to that category.
3. Provide your response in a JSON format containing a single key `label` and a value corresponding to the assigned category. Do not provide any additional information except the JSON.
List of categories: ['本', '映画']
Training data:
Sample input:
```私はサイエンスフィクション小説を読むのが大好きです。それは私を別の世界に連れて行ってくれます。```
s
Sample target: 本
Sample input:
```私はサイエンスフィクション映画を見るのが大好きです。それは私を他の銀河に連れて行ってくれます。```
s
Sample target: 映画
Text sample: ```私はこのSF小説が大好きになりました。科学とフィクションのユニークな融合に魅了されました。```
Your JSON response:
別のクエリでも試してみる。
prompt = clf._get_prompt("歴史小説は面白いねぇ。")
print(prompt["messages"])
You will be provided with the following information:
1. An arbitrary text sample. The sample is delimited with triple backticks.
2. List of categories the text sample can be assigned to. The list is delimited with square brackets. The categories in the list are enclosed in the single quotes and comma separated.
3. Examples of text samples and their assigned categories. The examples are delimited with triple backticks. The assigned categories are enclosed in a list-like structure. These examples are to be used as training data.
Perform the following tasks:
1. Identify to which category the provided text belongs to with the highest probability.
2. Assign the provided text to that category.
3. Provide your response in a JSON format containing a single key `label` and a value corresponding to the assigned category. Do not provide any additional information except the JSON.
List of categories: ['本', '映画']
Training data:
Sample input:
```歴史小説は、異なる時代や場所の感覚を与えてくれます。```
s
Sample target: 本
Sample input:
```歴史映画は過去の一瞥を提供します。```
s
Sample target: 映画
Sample input:
```私はサイエンスフィクション小説を読むのが大好きです。それは私を別の世界に連れて行ってくれます。```
s
Sample target: 本
Sample input:
```良いミステリー映画は、私をシートの端に座らせ続けます。```
s
Sample target: 映画
Text sample: ```歴史小説は面白いねぇ。```
Your JSON response:
クエリによってFew-shotが変わっているのがわかる。
ここはベクトル検索が行われており、デフォルトだとtext-embedding-ada-002が使用されているっぽい。ドキュメントによるとベクトル検索はScikit-Learn KNNとAnnoyに対応しているらしいが、カスタムなものも使えるとのこと。
予測も含めたコードはこんな感じになる。
from skllm.models.gpt.classification.few_shot import DynamicFewShotGPTClassifier
X = [
# 例1: 本 - サイエンスフィクション
"私はサイエンスフィクション小説を読むのが大好きです。それは私を別の世界に連れて行ってくれます。",
# 例2: 本 - ミステリー
"良いミステリー小説は、最後まで私を推理させます。",
# 例3: 本 - 歴史
"歴史小説は、異なる時代や場所の感覚を与えてくれます。",
# 例4: 映画 - サイエンスフィクション
"私はサイエンスフィクション映画を見るのが大好きです。それは私を他の銀河に連れて行ってくれます。",
# 例5: 映画 - ミステリー
"良いミステリー映画は、私をシートの端に座らせ続けます。",
# 例6: 映画 - 歴史
"歴史映画は過去の一瞥を提供します。",
]
y = ["本", "本", "本", "映画", "映画", "映画"]
clf = DynamicFewShotGPTClassifier(model="gpt-4o-mini", n_examples=2)
clf.fit(X,y)
predictions = clf.predict(["私はこのSF小説が大好きになりました。科学とフィクションのユニークな融合に魅了されました。"])
print()
print(predictions)
Building index for class `本` ...
Batch size: 1
100%|██████████| 3/3 [00:01<00:00, 2.32it/s]
Building index for class `映画` ...
Batch size: 1
100%|██████████| 3/3 [00:01<00:00, 2.26it/s]
0%| | 0/1 [00:00<?, ?it/s]Batch size: 1
0%| | 0/1 [00:00<?, ?it/s]
100%|██████████| 1/1 [00:00<00:00, 2.12it/s]
100%|██████████| 1/1 [00:01<00:00, 1.10s/it]
['本']
ラベルごとのトレーニングデータはきちんと揃えておくこと。
バランスの取れたサンプリング 最後に説明すべきことは、クラスバランスです。もしN個の最近傍だけが数ショットのプロンプトのために選択された場合、いくつかのクラスが不足したり、完全に欠落したりする危険性が非常に高くなります。この問題を軽減するために、単一のインデックスを作成する代わりに、トレーニングデータをクラスごとに分割します。このようにして、各クラスからN個の例をサンプリングし、各クラスの均等な表現を保証します。
テキスト分類: Chain-of-thought
Chain-of-thoughtもトレーニングデータは不要なので、Zero-shotと同じ。ただし、LLMがより深い推論を行うことで、分類を行う。
上のサンプルをそのまま使ってやってみる。
from skllm.models.gpt.classification.zero_shot import CoTGPTClassifier
X = [
# 例1: 本 - サイエンスフィクション
"私はサイエンスフィクション小説を読むのが大好きです。それは私を別の世界に連れて行ってくれます。",
# 例2: 本 - ミステリー
"良いミステリー小説は、最後まで私を推理させます。",
# 例3: 本 - 歴史
"歴史小説は、異なる時代や場所の感覚を与えてくれます。",
# 例4: 映画 - サイエンスフィクション
"私はサイエンスフィクション映画を見るのが大好きです。それは私を他の銀河に連れて行ってくれます。",
# 例5: 映画 - ミステリー
"良いミステリー映画は、私をシートの端に座らせ続けます。",
# 例6: 映画 - 歴史
"歴史映画は過去の一瞥を提供します。",
]
y = ["本", "本", "本", "映画", "映画", "映画"]
clf = CoTGPTClassifier(model="gpt-4o")
clf.fit(X,y)
プロンプトを見てみる。
prompt = clf._get_prompt("歴史小説は面白いねぇ。")
print(prompt["messages"])
You are tasked with classifying a given text sample based on a list of potential categories. Please adhere to the following guidelines:
1. The text intended for classification is presented between triple backticks.
2. The possible categories are enumerated in square brackets, with each category enclosed in single quotes and separated by commas.
Tasks:
1. Examine the text and provide detailed justifications for the possibility of the text belonging or not belonging to each category listed.
2. Determine and select the most appropriate category for the text based on your comprehensive justifications.
3. Format your decision into a JSON object containing two keys: `explanation` and `label`. The `explanation` should concisely capture the rationale for each category before concluding with the chosen category.
Category List: ['本', '映画']
Text Sample: ```歴史小説は面白いねぇ。```
Provide your JSON response below, ensuring that justifications for all categories are clearly detailed:
では分類。
predictions = clf.predict(["歴史小説は面白いねぇ。"])
predictions
array([['本',
"The text sample '歴史小説は面白いねぇ。' translates to 'Historical novels are interesting, aren't they?' in English. This text explicitly mentions '歴史小説' which means 'historical novels'. This directly relates to the category '本', which means 'books', as novels are a type of book. There is no mention of films or any context that would suggest the text is discussing movies, which would relate to the category '映画'. Therefore, the text is more appropriately classified under '本'."]],
dtype='<U468')
分類した理由も出力してくれる。
テキスト分類: ファインチューニング
Tunableはファインチューニングを行うものらしい。OpenAIの場合、ファインチューニングできるモデルは以下にある。対象のモデルをbase_modelとして指定する。
なお、トレーニング用のデータセットは最低10件みたいなので、今回は20件生成させてみた。
from skllm.models.gpt.classification.tunable import GPTClassifier
X = [
# 本の例
"私はサイエンスフィクション小説を読むのが大好きです。それは私を別の世界に連れて行ってくれます。", # 例 1 - 本 - サイエンスフィクション
"良いミステリー小説は、最後まで私を推理させます。", # 例 2 - 本 - ミステリー
"歴史小説は、異なる時代や場所の感覚を与えてくれます。", # 例 3 - 本 - 歴史
"ファンタジー小説は、想像力をかき立てる不思議な世界を作り上げます。", # 例 4 - 本 - ファンタジー
"ロマンス小説は、心温まる物語で私を引き込んでくれます。", # 例 5 - 本 - ロマンス
"探偵小説は、登場人物たちの頭脳戦が魅力です。", # 例 6 - 本 - 探偵
"ノンフィクションは、現実世界についての新しい知識を得られるのが楽しいです。", # 例 7 - 本 - ノンフィクション
"ホラーノベルは、恐怖の感覚を楽しむために読みます。", # 例 8 - 本 - ホラー
"詩集は、言葉の美しさを味わう素晴らしい機会を与えてくれます。", # 例 9 - 本 - 詩集
"自己啓発書は、人生に対する新たな視点を提供してくれます。", # 例 10 - 本 - 自己啓発
# 映画の例
"私はサイエンスフィクション映画を見るのが大好きです。それは私を他の銀河に連れて行ってくれます。", # 例 11 - 映画 - サイエンスフィクション
"良いミステリー映画は、私をシートの端に座らせ続けます。", # 例 12 - 映画 - ミステリー
"歴史映画は、過去の出来事を生き生きと描いてくれます。", # 例 13 - 映画 - 歴史
"ファンタジー映画は、信じられないような世界を映像で体験できます。", # 例 14 - 映画 - ファンタジー
"ロマンス映画は、感情的な物語が心に響きます。", # 例 15 - 映画 - ロマンス
"探偵映画は、複雑な謎解きと驚くべき展開が魅力です。", # 例 16 - 映画 - 探偵
"ドキュメンタリー映画は、現実の世界を映し出し、新たな知見を与えてくれます。", # 例 17 - 映画 - ドキュメンタリー
"ホラー映画は、恐怖の要素が視覚的に強烈です。", # 例 18 - 映画 - ホラー
"コメディ映画は、笑いを提供し、日々のストレスを和らげます。", # 例 19 - 映画 - コメディ
"アニメ映画は、色鮮やかで独特な世界観が素晴らしいです。" # 例 20 - 映画 - アニメ
]
y = ["本", "本", "本", "本", "本", "本", "本", "本", "本", "本",
"映画", "映画", "映画", "映画", "映画", "映画", "映画", "映画", "映画", "映画"]
clf = GPTClassifier(base_model="gpt-4o-mini-2024-07-18", n_epochs=1)
clf.fit(X,y)
以下のような感じで、ファインチューニングが行われている様子。
Created new file. FILE_ID = file-XXXXXXXXX
Waiting for file to be processed ...
Created new tuning job. JOB_ID = ftjob-XXXXXXXXXX
[2024-10-27 08:12:30.108565] Waiting for tuning job to complete. Current status: validating_files
OpenAIのダッシュボードでもファインチューニングが動いているのがわかる。ちなみにひとつ下でFailedになってるのはトレーニングデータが少なすぎて失敗した。
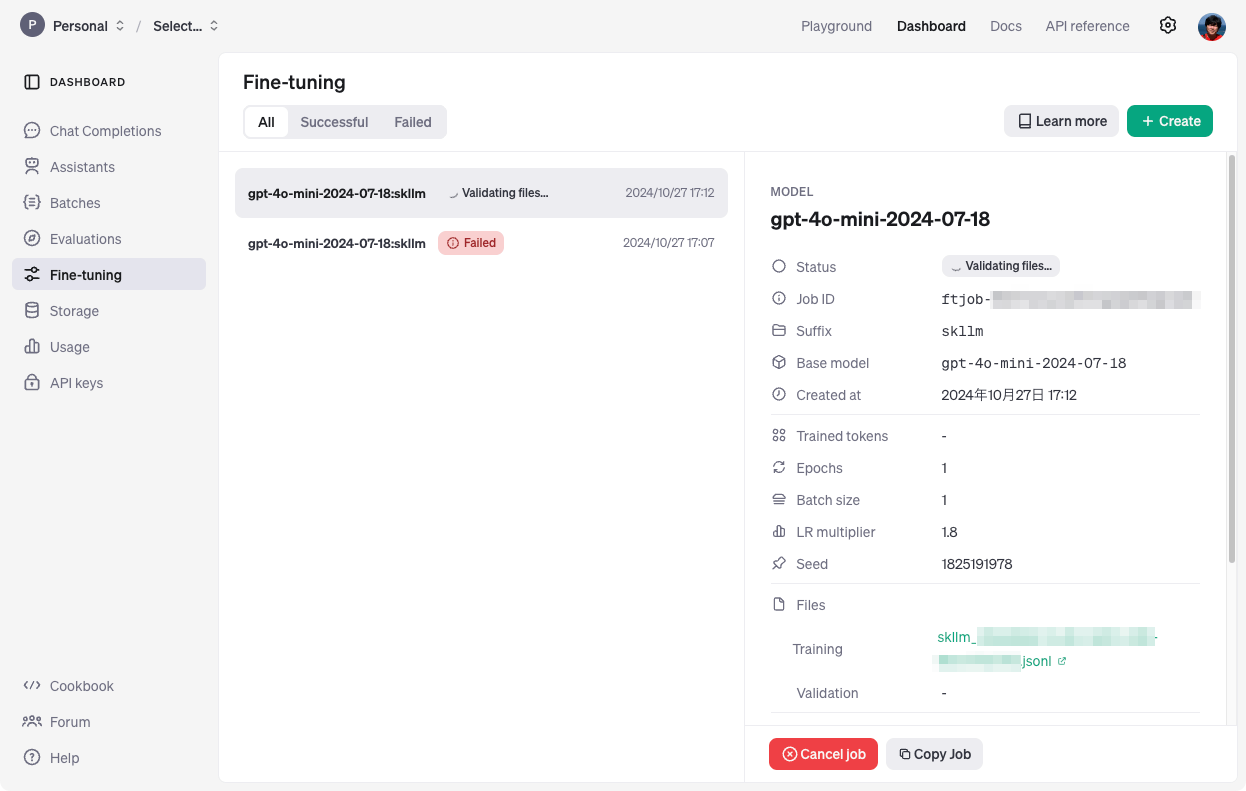
以下のように表示されれば完了。今回は20件でだいたい4分ぐらいだった。
[2024-10-27 08:14:31.130588] Waiting for tuning job to complete. Current status: running
Finished training.
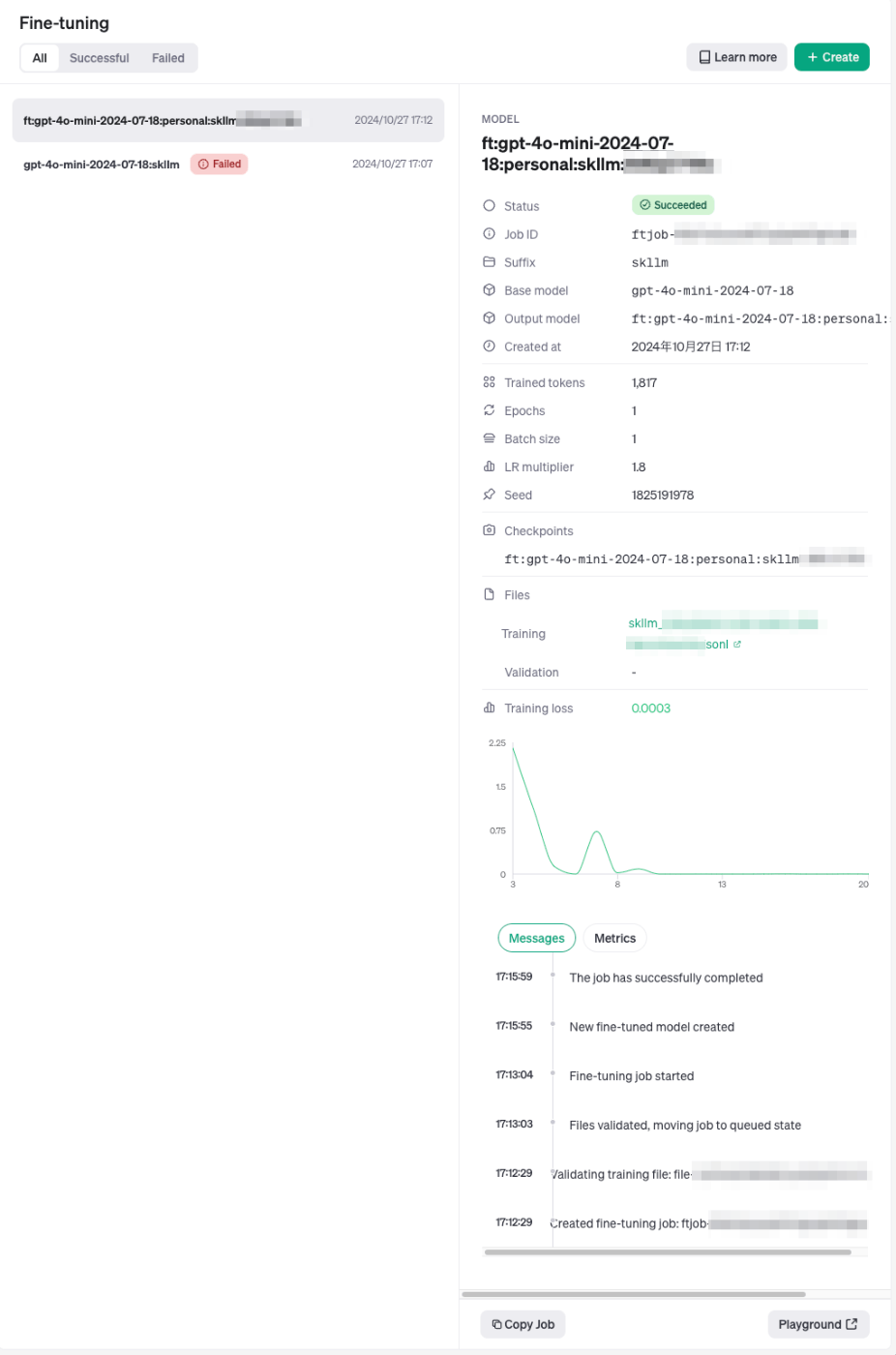
このモデルで分類してみる。
predictions = clf.predict(["歴史小説は面白いねぇ。"])
predictions
array(['映画'], dtype='<U2')
全然あかんw。まあ十分なトレーニングデータが恐らく必要だと思う。
ファインチューニングしたモデルが不要になれば以下のように削除できる。
from openai import OpenAI
from google.colab import userdata
client = OpenAI(api_key=userdata.get('OPENAI_API_KEY'))
# ファインチューニングモデルのモデル名を指定
client.models.delete("ft:gpt-4o-mini-2024-07-18:personal:skllm:XXXXXXXXX")
ModelDeleted(id='ft:gpt-4o-mini-2024-07-18:personal:skllm:XXXXXXXXX', deleted=True, object='model')
テキスト→テキストのモデリング: 要約
Scikit-LLMで提供される要約モジュールは、estimator・プリプロセッサのどちらでも使用可能。プリプロセッサとして使う場合、要約は「次元削減の前処理」と似たような感じになる。次元削減というのは、データのサイズや複雑さを減らす処理、つまりPCA・SVD・LDA等と同じようなイメージらしい。まあ要約も、長い文章を短くするという意味では似たような役割といえる。
以下の記事の冒頭部分をサンプルとして使う。
from skllm.models.gpt.text2text.summarization import GPTSummarizer
summarizer = GPTSummarizer(model="gpt-4o-mini", max_words=15, focus="タイトル")
X = [
(
"オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。"
"1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。8連勝、重賞5勝を含む12戦10勝を記録した後、"
"1988年1月に中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。1988年度のJRA賞最優秀4歳牡馬、"
"1989年度のJRA賞特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬。1991年、JRA顕彰馬に"
"選出。愛称は「オグリ」「芦毛の怪物」「スーパーホース」など多数。"
"中央競馬時代はスーパークリーク、イナリワンの二頭とともに「平成三強」と総称され、自身と騎手である"
"武豊の活躍を中心として起こった第二次競馬ブーム期において、第一次競馬ブームの立役者とされるハイセイコー"
"に比肩するとも評される高い人気を得た。 日本競馬史上屈指のアイドルホースである。"
),
(
"ナリタブライアン(欧字名:Narita Brian、1991年5月3日 - 1998年9月27日)は、日本の競走馬、種牡馬。"
"中央競馬史上5頭目のクラシック三冠馬であり、そのトレードマークから「シャドーロールの怪物」という愛称で"
"親しまれた。1993年8月にデビューし、同年11月から1995年3月にかけてクラシック三冠を含むGI5連勝、10連続"
"連対を達成し、1993年JRA賞最優秀3歳牡馬、1994年JRA賞年度代表馬および最優秀4歳牡馬に選出された。1995"
"年春に故障(股関節炎)を発症したあとは低迷し、6戦して重賞を1勝するにとどまったが(GIは5戦して未勝利)、"
"第44回阪神大賞典におけるマヤノトップガンとのマッチレースや短距離戦である第26回高松宮杯への出走によって"
"ファンの話題を集めた。第26回高松宮杯出走後に発症した屈腱炎が原因となって1996年10月に競走馬を引退した。"
"引退後は種牡馬となったが、1998年9月に胃破裂を発症し、安楽死の措置がとられた。日本競馬史上最強と言われる"
"競走馬の一頭である。"
"半兄に1993年のJRA賞年度代表馬ビワハヤヒデがいる。1997年日本中央競馬会 (JRA) の顕彰馬に選出された。"
)
]
X_summarized = summarizer.fit_transform(X)
max_wordsは要約の目安、focusは要約時に特に注目すべきコンセプトを指定できるみたい。
X_summarized
array(['オグリキャップは日本の競走馬で、多くの重賞を勝利した。', 'ナリタブライアンは日本の競走馬で、クラシック三冠を達成した。'],
テキスト→テキストのモデリング: 翻訳
上のデータを使って英語に翻訳してみる。
from skllm.models.gpt.text2text.translation import GPTTranslator
translater = GPTTranslator(model="gpt-4o-mini", output_language="English")
X = [
(
"オグリキャップ(欧字名:Oguri Cap、1985年3月27日 - 2010年7月3日)は、日本の競走馬、種牡馬。"
"1987年5月に岐阜県の地方競馬・笠松競馬場でデビュー。8連勝、重賞5勝を含む12戦10勝を記録した後、"
"1988年1月に中央競馬へ移籍し、重賞12勝(うちGI4勝)を記録した。1988年度のJRA賞最優秀4歳牡馬、"
"1989年度のJRA賞特別賞、1990年度のJRA賞最優秀5歳以上牡馬および年度代表馬。1991年、JRA顕彰馬に"
"選出。愛称は「オグリ」「芦毛の怪物」「スーパーホース」など多数。"
"中央競馬時代はスーパークリーク、イナリワンの二頭とともに「平成三強」と総称され、自身と騎手である"
"武豊の活躍を中心として起こった第二次競馬ブーム期において、第一次競馬ブームの立役者とされるハイセイコー"
"に比肩するとも評される高い人気を得た。 日本競馬史上屈指のアイドルホースである。"
),
(
"ナリタブライアン(欧字名:Narita Brian、1991年5月3日 - 1998年9月27日)は、日本の競走馬、種牡馬。"
"中央競馬史上5頭目のクラシック三冠馬であり、そのトレードマークから「シャドーロールの怪物」という愛称で"
"親しまれた。1993年8月にデビューし、同年11月から1995年3月にかけてクラシック三冠を含むGI5連勝、10連続"
"連対を達成し、1993年JRA賞最優秀3歳牡馬、1994年JRA賞年度代表馬および最優秀4歳牡馬に選出された。1995"
"年春に故障(股関節炎)を発症したあとは低迷し、6戦して重賞を1勝するにとどまったが(GIは5戦して未勝利)、"
"第44回阪神大賞典におけるマヤノトップガンとのマッチレースや短距離戦である第26回高松宮杯への出走によって"
"ファンの話題を集めた。第26回高松宮杯出走後に発症した屈腱炎が原因となって1996年10月に競走馬を引退した。"
"引退後は種牡馬となったが、1998年9月に胃破裂を発症し、安楽死の措置がとられた。日本競馬史上最強と言われる"
"競走馬の一頭である。"
"半兄に1993年のJRA賞年度代表馬ビワハヤヒデがいる。1997年日本中央競馬会 (JRA) の顕彰馬に選出された。"
)
]
X_translated = translater.fit_transform(X)
X_translated
array(['Oguri Cap (Romanized: Oguri Cap, March 27, 1985 - July 3, 2010) was a Japanese racehorse and stallion. He debuted in May 1987 at the Kasamatsu Racecourse in Gifu Prefecture. After recording 10 wins out of 12 races, including 8 consecutive wins and 5 major victories, he transferred to central horse racing in January 1988, where he recorded 12 major wins (including 4 GI wins). He was awarded the JRA Award for Best 4-Year-Old Colt in 1988, the JRA Special Award in 1989, and the JRA Award for Best Older Male Horse and Horse of the Year in 1990. In 1991, he was selected as a JRA Hall of Fame horse. He had many nicknames, including "Oguri," "The Gray Monster," and "Super Horse." During his time in central horse racing, he was collectively referred to as one of the "Heisei Three Strong" along with Super Creek and Inari One, and he gained immense popularity, being compared to High Seiko, who was a key figure in the first horse racing boom, during the second horse racing boom period centered around his and jockey Yutaka Take\'s performances. He is considered one of the top idol horses in the history of Japanese horse racing.',
'Narita Brian (Romanized: Narita Brian, May 3, 1991 - September 27, 1998) was a Japanese racehorse and stallion. He was the fifth horse in the history of Japanese horse racing to win the Classic Triple Crown and was affectionately known as the "Monster with the Shadow Roll" due to his trademark. He debuted in August 1993 and achieved five consecutive Grade I victories, including the Classic Triple Crown, from November of that year to March 1995, along with ten consecutive placings. He was awarded the JRA Award for Best 3-Year-Old Colt in 1993, the JRA Award for Horse of the Year and Best 4-Year-Old Colt in 1994. After suffering an injury (hip arthritis) in the spring of 1995, he struggled, winning only one graded race in six starts (with no wins in five Grade I races), but he drew fans\' attention with a match race against Mayano Top Gun in the 44th Hanshin Daishoten and his participation in the short-distance 26th Takamatsunomiya Kinen. He retired from racing in October 1996 due to a tendon injury that developed after the 26th Takamatsunomiya Kinen. After retirement, he became a stallion but suffered a ruptured stomach in September 1998, leading to euthanasia. He is considered one of the strongest racehorses in the history of Japanese racing. He has a half-brother, Biwa Hayahide, who was the JRA Award Horse of the Year in 1993. He was inducted as a JRA Hall of Fame horse in 1997.'],
dtype=object)
テキスト→テキストのモデリング: ファインチューニング
テキスト→テキストのモデリングでもファインチューニングができるのだが、
これらの推定器は、追加の前処理やプロンプトを作成することなく、提供されたデータをそのまま使用します。このアプローチではより柔軟な対応が可能ですが、データが正しくフォーマットされていることを確認するのはユーザーの責任です。
んー、ここがちょっとよくわからない。とりあえず見様見真似で進めてみる。
以下のデータセットを使用させていただいて、ずんだもん口調になるように変えてみる。
!wget https://huggingface.co/datasets/alfredplpl/simple-zundamon/resolve/main/zmn.jsonl
import json
X = []
y = []
with open("zmn.jsonl", "r", encoding='utf-8') as f:
for l in f:
data = json.loads(l)
X.append(data["messages"][1]["content"])
y.append(data["messages"][2]["content"])
X[:5]
['あなたの名前を教えてください。',
'あなたの好きなものを教えてください。',
'今の姿はいつ手に入れたのですか?',
'あなたのスリーサイズを教えてください。',
'あなたは誰ですか。']
y[:5]
['ボクの名前はずんだもんなのだ。',
'ずんだ餅に関係することはだいたい好きなのだ。',
'令和3年6月17日にこの姿を手に入れたのだ。',
'オマエは失礼な人なのだ。',
'ずんだもんなのだ。ずんだの妖精なのだ。']
ではファインチューニングする。ドキュメントではsystem_msgというパラメータがあるが、これは存在しなかった。
from skllm.models.gpt.text2text.tunable import TunableGPTText2Text
model = TunableGPTText2Text(
base_model = "gpt-4o-mini-2024-07-18",
n_epochs = 1, # int または Noneを指定。None の場合、OpenAI が自動的に決定する。
)
model.fit(X, y) # Xが入力で、yが出力になる模様
Created new file. FILE_ID = file-XXXXXXXXXX
Waiting for file to be processed ...
Created new tuning job. JOB_ID = ftjob-XXXXXXXXXX
[2024-10-27 09:15:32.442720] Waiting for tuning job to complete. Current status: validating_files
[2024-10-27 09:17:32.824056] Waiting for tuning job to complete. Current status: running
Finished training.
ではモデルにテキストを与えてみる。
import json
response = model.transform(["おはよう"])
print(json.dumps(json.loads(response[0]), indent=2, ensure_ascii=False))
{
"label": "ずんだもんはおはようなのだ。ずんだもんはおはようなのだ。"
}
んー、それっぽく機能はしているようだけども、fitに渡すデータの形式が間違ってるのかもしれない・・・
またそのうち調べることにする。
テキストのベクトル化
まずはシンプルにテキストをベクトル化する例
from skllm.models.gpt.vectorization import GPTVectorizer
vectorizer = GPTVectorizer(model="text-embedding-3-small", batch_size=1)
X = vectorizer.fit_transform([
"日本の伝統的な和食は、「一汁三菜」を基本とし、主食、汁物、主菜、副菜で構成されています。",
"気象観測には、気温、湿度、気圧、風向風速、雨や雪の分布、雲の動き、大気の状態など様々なデータを使用して行われます。"
])
X
array([[-0.02593018, -0.03431672, 0.00667518, ..., 0.0072755 ,
-0.0413951 , -0.02315259],
[ 0.01344733, 0.01277973, 0.00049146, ..., -0.0350775 ,
0.00124698, 0.0215348 ]])
もう一つの例。ベクトル化モジュールをXGBoost分類器と組み合わせたパイプライン。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import LabelEncoder
from xgboost import XGBClassifier
X_train = [
# 本の例
"私はサイエンスフィクション小説を読むのが大好きです。それは私を別の世界に連れて行ってくれます。", # 例 1 - 本 - サイエンスフィクション
"良いミステリー小説は、最後まで私を推理させます。", # 例 2 - 本 - ミステリー
"歴史小説は、異なる時代や場所の感覚を与えてくれます。", # 例 3 - 本 - 歴史
"ファンタジー小説は、想像力をかき立てる不思議な世界を作り上げます。", # 例 4 - 本 - ファンタジー
"ロマンス小説は、心温まる物語で私を引き込んでくれます。", # 例 5 - 本 - ロマンス
"探偵小説は、登場人物たちの頭脳戦が魅力です。", # 例 6 - 本 - 探偵
"ノンフィクションは、現実世界についての新しい知識を得られるのが楽しいです。", # 例 7 - 本 - ノンフィクション
"ホラーノベルは、恐怖の感覚を楽しむために読みます。", # 例 8 - 本 - ホラー
"詩集は、言葉の美しさを味わう素晴らしい機会を与えてくれます。", # 例 9 - 本 - 詩集
"自己啓発書は、人生に対する新たな視点を提供してくれます。", # 例 10 - 本 - 自己啓発
# 映画の例
"私はサイエンスフィクション映画を見るのが大好きです。それは私を他の銀河に連れて行ってくれます。", # 例 11 - 映画 - サイエンスフィクション
"良いミステリー映画は、私をシートの端に座らせ続けます。", # 例 12 - 映画 - ミステリー
"歴史映画は、過去の出来事を生き生きと描いてくれます。", # 例 13 - 映画 - 歴史
"ファンタジー映画は、信じられないような世界を映像で体験できます。", # 例 14 - 映画 - ファンタジー
"ロマンス映画は、感情的な物語が心に響きます。", # 例 15 - 映画 - ロマンス
"探偵映画は、複雑な謎解きと驚くべき展開が魅力です。", # 例 16 - 映画 - 探偵
"ドキュメンタリー映画は、現実の世界を映し出し、新たな知見を与えてくれます。", # 例 17 - 映画 - ドキュメンタリー
"ホラー映画は、恐怖の要素が視覚的に強烈です。", # 例 18 - 映画 - ホラー
"コメディ映画は、笑いを提供し、日々のストレスを和らげます。", # 例 19 - 映画 - コメディ
"アニメ映画は、色鮮やかで独特な世界観が素晴らしいです。" # 例 20 - 映画 - アニメ
]
y_train = ["本", "本", "本", "本", "本", "本", "本", "本", "本", "本",
"映画", "映画", "映画", "映画", "映画", "映画", "映画", "映画", "映画", "映画"]
X_test = [
# 本の例
"SF小説は、現実では体験できない異世界の冒険に連れて行ってくれるから大好きです。", # 例 1 - 本 - サイエンスフィクション
"ミステリー小説は、真相がわかるまでの緊張感がたまりません。", # 例 2 - 本 - ミステリー
# 映画の例
"SF映画は、未来の技術や宇宙の謎に触れられるところが面白いです。", # 例 3 - 映画 - サイエンスフィクション
"ミステリー映画は、次の展開を予想しながら見るのが楽しいです。" # 例 4 - 映画 - ミステリー
]
y_test = ["本", "本", "映画", "映画"]
le = LabelEncoder()
y_train_encoded = le.fit_transform(y_train)
y_test_encoded = le.transform(y_test)
steps = [("GPT", GPTVectorizer()), ("Clf", XGBClassifier())]
clf = Pipeline(steps)
clf.fit(X_train, y_train_encoded)
yh = clf.predict(X_test)
array([1, 1, 0, 0])
ラベルは以下のように確認できる。
for i, label in enumerate(le.classes_):
print(f"{i}: {label}")
0: 映画
1: 本
タグ: 名前付きエンティティ認識
まず、タグ付けは、生のテキスト文字列からエンティティを抽出してXML的なタグを付与するものらしい。
例えば以下の文章にネガポジ分類のタグをつけるならば
新しい携帯電話はとても気に入っていますが、バッテリーの持ちにはがっかりしています。
以下のようになるイメージ。
<positive>新しい携帯電話はとても気に入っていますが、</positive><negative>バッテリーの持ちにはがっかりしています。</negative>
これを使って、名前付きエンティティを抽出するサンプルが以下。
from skllm.models.gpt.tagging.ner import GPTExplainableNER as NER
entities = {
"PERSON": "個人の名前。",
"ORGANIZATION": "会社や組織の名前。",
"DATE": "特定の時間的な参照。"
}
data = [
"2022年6月3日、ティム・クックがサンフランシスコでアップルの新製品を発表",
"2021年1月10日、イーロン・マスクがオースティンのテスラ工場を訪問",
"2023年5月5日、マーク・ザッカーバーグがシリコンバレーでフェイスブックのメタバースを発表",
]
ner = NER(entities=entities, display_predictions=True)
tagged = ner.fit_transform(data)
display_predictionsを有効にすると以下のようにわかりやすく出力表示してくれる。

結果の方も見てみる。
import pprint
pprint.pprint(tagged)
こちらはタグ付けされた出力や、それについての説明なども出力されている。
["<not_entity></not_entity><entity><reasoning>The date '2022年6月3日' is a "
'specific temporal reference, indicating a particular '
"day.</reasoning><tag>DATE</tag><value>2022年6月3日</value></entity><not_entity>、</not_entity><entity><reasoning>'ティム・クック' "
'is a personal name, referring to an individual known as Tim '
"Cook.</reasoning><tag>PERSON</tag><value>ティム・クック</value></entity><not_entity>がサンフランシスコで</not_entity><entity><reasoning>'アップル' "
'is the name of a well-known company, which is an '
'organization.</reasoning><tag>ORGANIZATION</tag><value>アップル</value></entity><not_entity>の新製品を発表</not_entity>',
"<not_entity></not_entity><entity><reasoning>The text '2021年1月10日' refers to "
'a specific date, which is a temporal '
'reference.</reasoning><tag>DATE</tag><value>2021年1月10日</value></entity><not_entity>、</not_entity><entity><reasoning>The '
"text 'イーロン・マスク' is a well-known individual's name, identifying a "
'person.</reasoning><tag>PERSON</tag><value>イーロン・マスク</value></entity><not_entity>がオースティンの</not_entity><entity><reasoning>The '
"text 'テスラ' refers to a well-known company, identifying an "
'organization.</reasoning><tag>ORGANIZATION</tag><value>テスラ</value></entity><not_entity>工場を訪問</not_entity>',
"<not_entity></not_entity><entity><reasoning>The date '2023年5月5日' is a "
'specific temporal reference, indicating a particular '
"day.</reasoning><tag>DATE</tag><value>2023年5月5日</value></entity><not_entity>、</not_entity><entity><reasoning>'マーク・ザッカーバーグ' "
'is the name of an individual, known as the CEO of '
"Facebook.</reasoning><tag>PERSON</tag><value>マーク・ザッカーバーグ</value></entity><not_entity>がシリコンバレーで</not_entity><entity><reasoning>'フェイスブック' "
'is the name of a well-known company, which is a social media '
'platform.</reasoning><tag>ORGANIZATION</tag><value>フェイスブック</value></entity><not_entity>のメタバースを発表</not_entity>']
名前付きエンティティ認識は、DenseとSparseがあり、以下のような違いがあるらしい。
- Dense
- すぐに完全な(タグ付けされた)出力を生成
- より大きなモデルが使用されている場合(gpt-4 など)に最適
- テキストに、語彙的に曖昧な単語が複数(別個)含まれることが予想される場合。
- 例: 「アップルはアップルCEOの大好物」→最初の「アップル」と次の「アップル」は別の意味になる。
- Sparse
- エンティティのリストのみが生成され、それが正規表現によってテキストにマッピングされる
- 出力トークンの数が少ない(使用料が安い)
- 厳密な検証 -> 出力が反転可能で、指定されたエンティティだけを含むことが保証される
- 精度が高い(特に小さいモデルの場合)
基本的にはSparseが推奨とあり、恐らくsparse_outputというパラメータでどちらかを選択する様子(デフォルトはTrue)
まとめ
scikit-learn自体を知らなかったので、少し事前に調べてから試したのだけど、たしかに雰囲気は似ているかな。でも上の方で書いたけども、自分は、scikit-learnにおけるfit=モデルの学習、という風に考えて始めたので(実際は多分プロンプトを構成しているだけなので違うと思う)、少し混乱した。Issueにも上がっている。
ただ、慣れてしまえばとてもシンプルだし、あと自分が今回試した目的として、
- 最近、分類タスクに興味があった
- Dynamic Few-shot Promptingに興味があった
があって、これらについては簡潔に実現できるので、実際に活用できそうという風に感じた。
scikit-learnももう少し触って色々慣れていきたい。