「Dynamic Few-shot prompting」を試す
ここで知った。
GitHubレポジトリ
LlamaIndexのworkflowsで実装されているみたい。
動画での紹介
2024/10のTechnology RaderでAssessにもなってた。
こういうのがあるみたい。
これを使って生成精度を高めているSQLジェネレータらしい
YouTube動画をNotebookLMに読み込ませてみた。
概要
このソースは、"Dynamic Few-shot Prompting"という手法を用いて、LLMモデルの応答構造を動的に調整する方法について解説しています。この手法では、ユーザーのクエリに基づいて、適切な応答構造を示す例をデータベースから取得し、それをプロンプトに組み込みます。具体的には、ユーザーのクエリとデータベース内の事例をベクトル化して類似度を計算し、最も類似した事例をプロンプトに追加することで、応答構造を調整します。この手法は、複数の種類のクエリに対してそれぞれ異なる応答構造を生成したい場合に有効です。また、新しい事例をデータベースに追加することで、LLMモデルの応答構造を容易に更新できます。このソースでは、LlamaIndexを用いてDynamic Few-shot Promptingを実装する手順が詳しく解説されており、具体的なコード例も紹介されています。
Dynamic Few-Shot Promptingの誕生前の課題
- 従来のFew-Shotプロンプティング
- メリット
- プロンプトに良質な応答例を含めることでモデルの性能向上が見込める
- 課題
- アプリケーションの成長やクエリ内容の多様化に伴い、最適な応答構造も複雑化し、膨大な数の応例が必要になる
- 大量の応答例をプロンプトに含めると、モデルが混乱し、パフォーマンスが低下する可能性があった
- モデルのFine-Tuningでは、新たな応答例を即座に反映することが難しい
- メリット
- Dynamic Few-Shot Promptingがこれらの課題を解決する
Dynamic Few-Shot Promptingの仕組み
Dynamic Few-Shot Promptingは、ユーザーのクエリに対して適切な応答を動的に生成することを目的としている。仕組みは、以下の手順になる。
- 良質な応答例のデータベース化: まず、様々なクエリに対する良質な応答例を収集し、データベースとして蓄積する。
- ベクトルストアインデックスの作成: 収集した応答例を基に、ベクトルストアインデックスを構築。各応答例をベクトル表現に変換し、類似度に基づいて検索できるようにする。
- ユーザーのクエリ解析: ユーザーからクエリが入力されると、そのクエリの内容を解析。
- ベクトル検索による応答例抽出: 解析されたクエリを用いて、ベクトルストアインデックスを検索し、クエリに最も類似した応答例を2〜3件抽出。
- 動的プロンプト生成: 抽出された応答例をFew-Shotプロンプトとして使用し、LLMへの入力プロンプトを動的に生成
- LLMによる応答生成: 生成されたプロンプトをLLMに入力し、最終的な応答を生成。
Dynamic Few-Shot Promptingのポイントは、ステップ4と5にある。
従来のFew-Shotプロンプティングでは、プロンプトに含める応答例は固定だったが、Dynamic Few-Shot Promptingでは、ユーザーのクエリに最適な応答例を動的にプロンプトに含めることができ、これにより適切な応答を生成することができる。
Dynamic Few-Shot Promptingのメリットは、応答例のデータベースとベクトルストアインデックスを更新するだけで、新たな応答例を即座に反映できるという点。フィードバックシステムなどを介して収集した新しい応答例を迅速にモデルに組み込み、モデルの性能を継続的に向上させることが可能になる。
Scikit-LLMでの例。結構簡単にできる。
元のレポジトリを修正してdocker composeで動かせるようにした。
使い方などはREADMEを参照してもらうとして、こんな感じで動く。
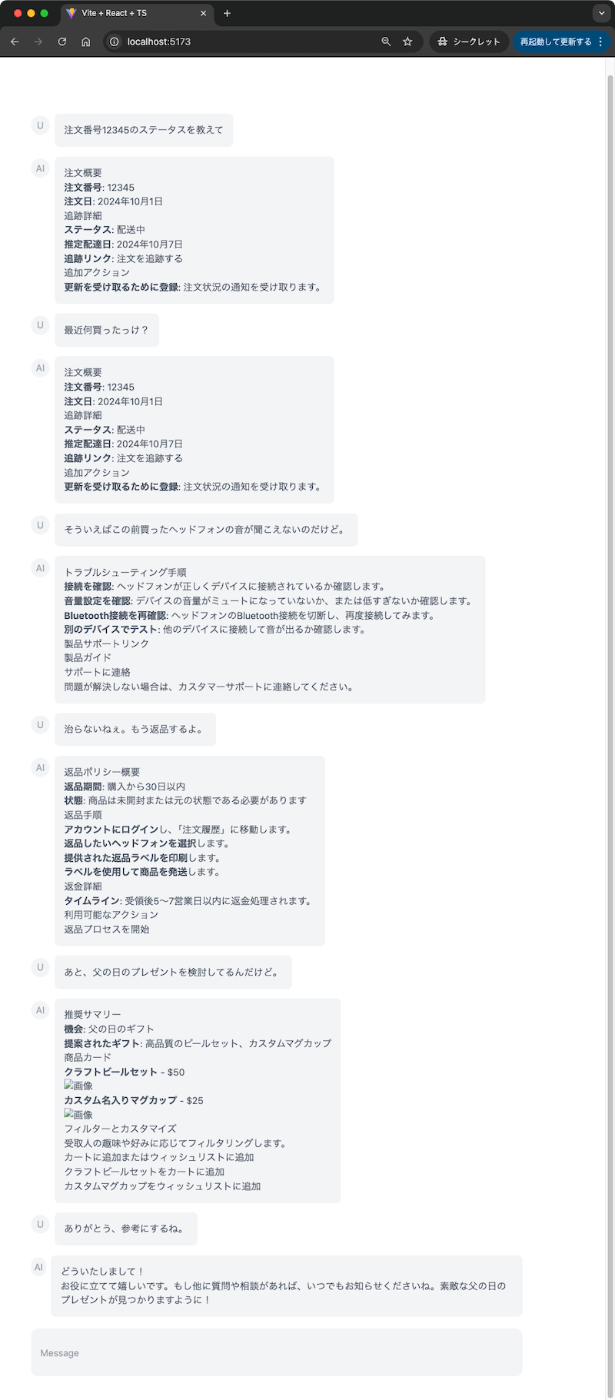
注文履歴に関連するクエリを投げると、以下のデータベースから検索を行い、
以下の内容でFew Shot Promptingが登録されたベクトルDBから検索を行い、クエリと関連性のある出力フォーマットをFew ShotとしてLLM二階等を生成させるという感じになっている。
一番最後以外はFew Shotの内容をもとに回答が生成されているのがわかる。
ホントならWorkflowsの処理内容を追いかけるべきなんだけど、それはまたおいおい。