「RVC(Retrieval-based-Voice-Conversion-WebUI)」を試す
GitHubレポジトリ
日本語README
Retrieval-based-Voice-Conversion-WebUI
VITSに基づく使いやすい音声変換(voice changer)framework
はじめに
本リポジトリには下記の特徴があります。
- Top1 検索を用いることで、生の特徴量を訓練用データセット特徴量に変換し、トーンリーケージを削減します。
- 比較的貧弱な GPU でも、高速かつ簡単に訓練できます。
- 少量のデータセットからでも、比較的良い結果を得ることができます。(10 分以上のノイズの少ない音声を推奨します。)
- モデルを融合することで、音声を混ぜることができます。(ckpt processing タブの、ckpt merge を使用します。)
- 使いやすい WebUI。
- UVR5 Model も含んでいるため、人の声と BGM を素早く分離できます。
最先端の人間の声のピッチ抽出アルゴリズム InterSpeech2023-RMVPEを使用して無声音問題を解決します。効果は最高(著しく)で、crepe_full よりも速く、リソース使用が少ないです。- A カードと I カードの加速サポート
とりあえずMacでやってみる。
レポジトリクローン
git clone https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
cd Retrieval-based-Voice-Conversion-WebUI
Macの場合はrun.shを実行するだけでよいみたい。run.shの中身はこんな感じ。
HomebrewでPython-3.8を持ってきて、Python仮想環境を作ってパッケージインストール、モデルダウンロード、起動、という感じなので、問題なさそう。
run.shを実行
sh ./run.sh
Create venv...
Python 3 not found. Attempting to install 3.8...
==> Downloading https://formulae.brew.sh/api/formula.jws.json
==> Downloading https://formulae.brew.sh/api/cask.jws.json
Error: python@3.8 has been disabled because it is deprecated upstream! It was disabled on 2024-10-14.
./run.sh: line 33: python3.8: command not found
./run.sh: line 34: .venv/bin/activate: No such file or directory
おっと、HomebrewのPython3.8はもう使えないのか。README読む限りはPython-3.10でもいけそうなので、書き換える。
sed -i.bak -e 's/3\.8/3\.10/g' run.sh
再度実行
sh ./run.sh
エラー。
failed. please install aria2
あとこの辺もかなぁ。
ERROR: Cannot install fairseq and fairseq==0.12.2 because these package versions have conflicting dependencies.
The conflict is caused by:
fairseq 0.12.2 depends on omegaconf<2.1
hydra-core 1.0.7 depends on omegaconf<2.1 and >=2.0.5
To fix this you could try to:
1. loosen the range of package versions you've specified
2. remove package versions to allow pip to attempt to solve the dependency conflict
WARNING: Ignoring version 2.0.5 of omegaconf since it has invalid metadata:
Requested omegaconf<2.1 from https://files.pythonhosted.org/packages/e5/f6/043b6d255dd6fbf2025110cea35b87f4c5100a181681d8eab496269f0d5b/omegaconf-2.0.5-py3-none-any.whl (from fairseq==0.12.2) has invalid metadata: .* suffix can only be used with `==` or `!=` operators
PyYAML (>=5.1.*)
~~~~~~^
Please use pip<24.1 if you need to use this version.
aria2はrequirements.txtから削除して、Homebrewでインストールすれば良さそう。
brew install aria2
あとはpipのバージョンを下げる。requirements.txtの先頭に以下を追加。
pip<24.1
仮想環境削除して再度実行
rm -rf .venv
sh ./run.sh
とりあえずこれで必要なモデルはダウンロードして起動まで行けた。
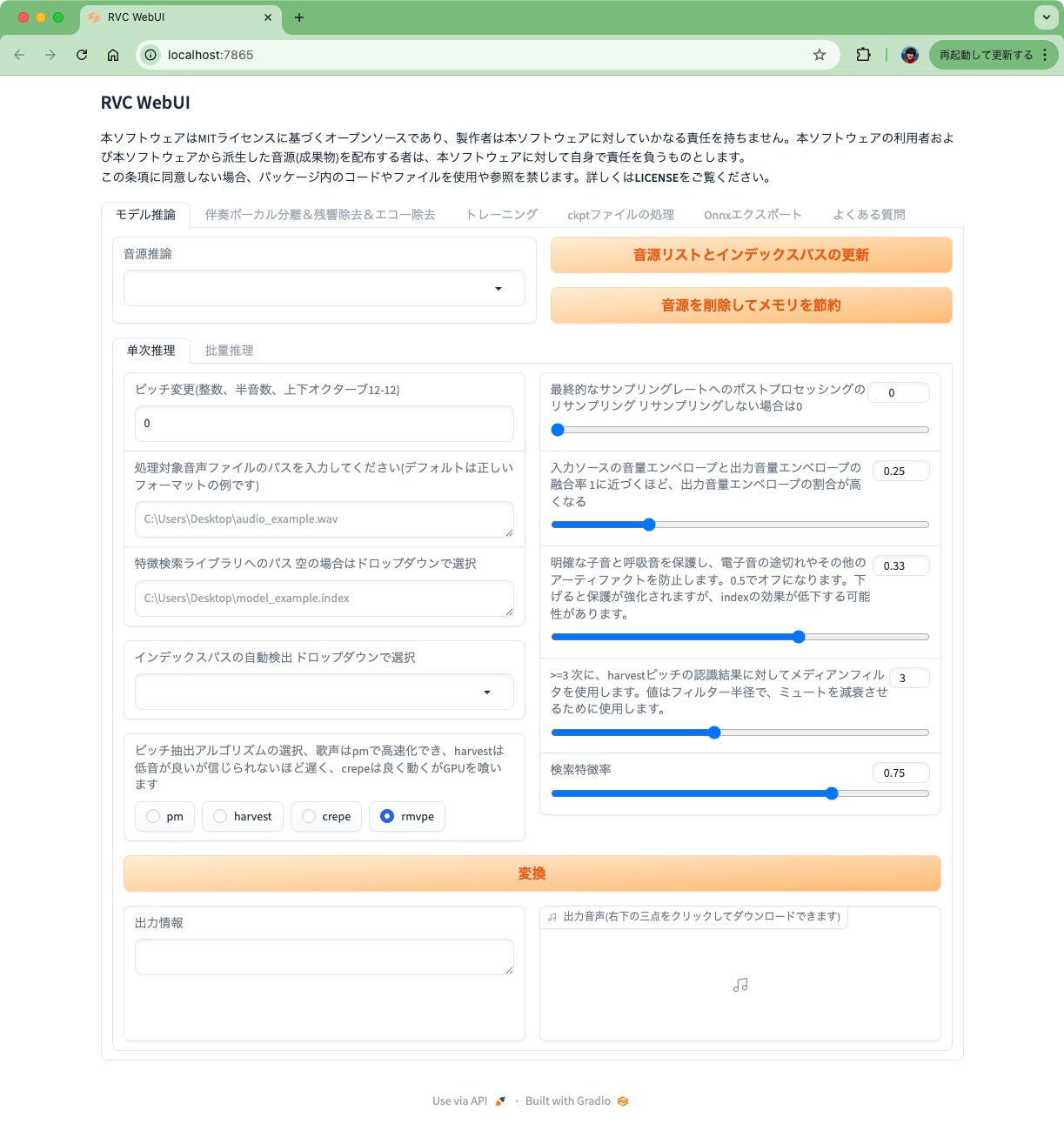
これで使えるのかな?と思ったけど、それとは別に音源モデルが必要になる。
調べてみると以下があった。どうやらRVCのモデルはBooth等で販売しているものが多い様子。以下はMITライセンスで公開されている、素晴らしい。
モデルをダウンロードして解凍、中のファイルを全て assets/weights 配下に配置する。
WebUIで「音源リストとインデックスパスの更新」をクリックして、モデルのリストが表示されればOK。
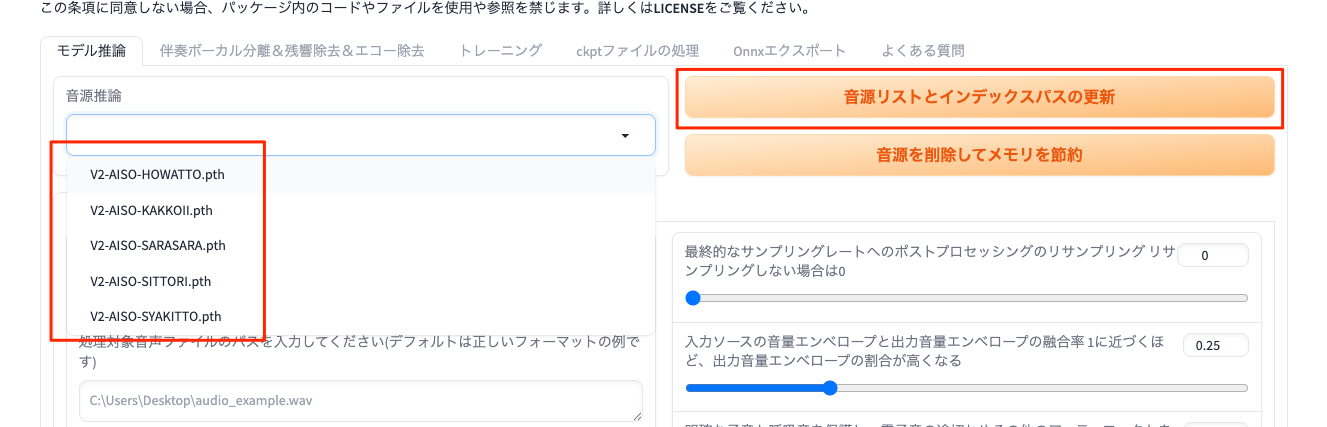
では、音声ファイルのパスを入力して、変換・・・・だけど、エラーになった・・・

ログには以下と出ている。
_pickle.UnpicklingError: Weights only load failed. This file can still be loaded, to do so you have two options, do those steps only if you trust the source of the checkpoint.
(1) In PyTorch 2.6, we changed the default value of the `weights_only` argument in `torch.load` from `False` to `True`. Re-running `torch.load` with `weights_only` set to `False` will likely succeed, but it can result in arbitrary code execution. Do it only if you got the file from a trusted source.
(2) Alternatively, to load with `weights_only=True` please check the recommended steps in the following error message.
WeightsUnpickler error: Unsupported global: GLOBAL fairseq.data.dictionary.Dictionary was not an allowed global by default. Please use `torch.serialization.add_safe_globals([Dictionary])` or the `torch.serialization.safe_globals([Dictionary])` context manager to allowlist this global if you trust this class/function.
Check the documentation of torch.load to learn more about types accepted by default with weights_only https://pytorch.org/docs/stable/generated/torch.load.html.
んー、PyTorchの仕様が変わって動かないものがあるってことかな?一旦止めて、インストールされているPyTorchのバージョンを確認してみた。
source .venv/bin/activate
pip freeze | grep -i torch
torch==2.6.0
torchaudio==2.6.0
torchcrepe==0.0.20
torchfcpe==0.0.4
とりあえずダウングレードしてみる
pip install "torch<2.6.0" "torchaudio<2.6.0"
torch==2.5.1
torchaudio==2.5.1
torchcrepe==0.0.20
torchfcpe==0.0.4
再度起動。
sh ./run.sh
先ほどとは違って多少処理が行われている感じになったけども、結果的にはエラーになってしまった。
NotImplementedError: Output channels > 65536 not supported at the MPS device. As a temporary fix, you can set the environment variable `PYTORCH_ENABLE_MPS_FALLBACK=1` to use the CPU as a fallback for this op. WARNING: this will be slower than running natively on MPS.
んー、でもこれ、run.shの中で実施されているんだけどなー。
Ubuntu-22.04サーバ(RTX4090)でやりなおした。
sudo apt install aria2 python3-dev
git clone https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
cd Retrieval-based-Voice-Conversion-WebUI
uv venv -p 3.10
uv pip install "torch<2.6.0" "torchaudio<2.6.0" torchvision
uv pip install -r requirements.txt
./tools/dlmodel.sh
pyproject.tomlが邪魔でuv runが実行できないので削除。
rm pyproject.toml
起動
uv run infer-web.py
音源モデルと音声ファイルを配置して実行。今度はOK!

できたもの。使用した音声は自分で録音したもの。以下を発話している。
おはようございます。今日はとても良いお天気ですね。こんな日は競馬場に行きたくなりますね。
参考
学習についてはこちらがわかりやすい
ただ、自分の場合だけども、
- 「ワンクリックトレーニング」をクリックしても「step1:処理中のデータ」と表示されたまま、何も進まない。CPUやGPUも使用していないように思えるので、どこかでコケてそう。ログもでないのでわからない。
- 「モデルのトレーニング」を実行すると、エラーになる。ログを見るとmatplotlibでエラー。
AttributeError: 'FigureCanvasAgg' object has no attribute 'tostring_rgb'-
matplotlibをダウングレードすれば良いみたい。
uv pip install matplotlib==3.7.0 - ダウングレード後、モデルのトレーニングはできるようになった。ただ、UI上は「エラー」になる。
- 「特徴インデックスのトレーニング」を実行すると「training」となるのだけど、そこから表示が変わらない。
- CPUをガンガンに使っているのでおそらく処理はなにか行われている。
- ログには何も出ない。
一応、上記でpthファイルは作成されていて、それを選択すれば推論はできた。
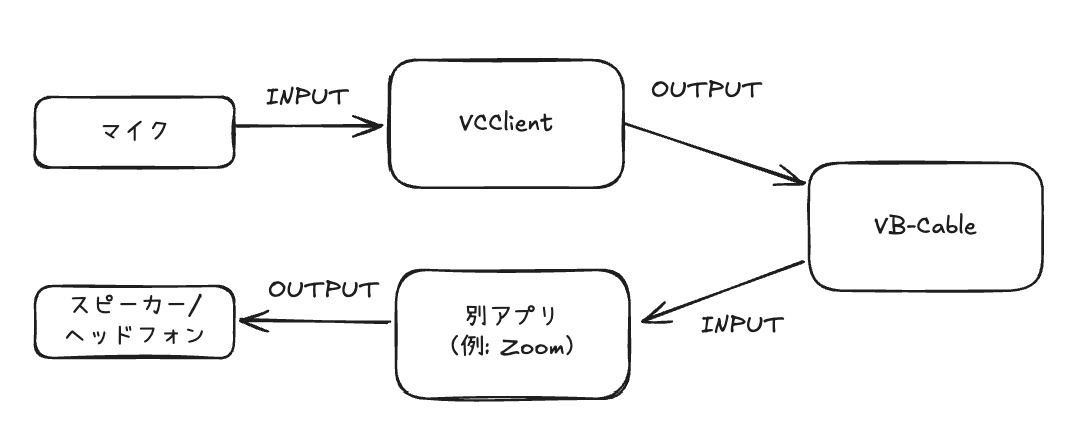
作成したpthファイルをVCClientでも使えた。確認したかったところまでできたのでOKとする。
VCClient経由で変換後音声を流すには、このあたりを使えば良いみたい。
MacだとHomebrewでインストールできる。
brew install vb-cable
仮想デバイスが作成されるので、こんな感じにすれば、配信的なことができる。