🎙️
AIボイチェン RVCの設定方法
はじめに
環境構築から学習データ作成・利用までを記載
RVCのgithubを参照しつつ補足しています
環境構築
-
仮想環境構築(不要な場合はスキップ)
- rvc用の仮想環境をanacondaで構築する場合(rvcという名称でpython3.10入れる)
conda create -n rvc python=3.10 - 仮想環境の起動
conda activate rvc
- rvc用の仮想環境をanacondaで構築する場合(rvcという名称でpython3.10入れる)
-
RVCの導入
- 2.1. win + Nvidia(RTX30xx)を利用する場合
- cmdで下記を実行し、cudaのバージョンが11.7か11.8か確認する
nvcc -V- 11.7か11.8でない場合、cuda11.8をインストールする
- cudaのバージョンに合うpytorchを入れる(下記は11.8の場合)。各バージョンのpipは公式サイト参照。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
- cmdで下記を実行し、cudaのバージョンが11.7か11.8か確認する
- 2.2. CPU利用の場合(win + Nvidia(RTX30xx)でない場合)
- cmdで下記を実行
pip install torch torchvision torchaudio
- cmdで下記を実行
- 2.3. githubからRVCのファイルをcloneする
- 2.4. cmdのカレントディレクトリを移動する
cd cloneしたRVCのディレクトリ - 2.5. cmdで関連ライブラリをinstall
pip install -r requirements.txt - 2.5 重みファイルのダウンロード
-
Hugging Faceから、下記RVCのフォルダ・ファイルに対応するものを全てダウンロードして格納する
- ./assets/hubert/hubert_base.pt
- ./assets/pretrained
- ./assets/uvr5_weights
- ./assets/pretrained_v2
-
Hugging Faceから、下記RVCのフォルダ・ファイルに対応するものを全てダウンロードして格納する
- 2.6 RVCの起動
- cmdで下記を実行する
python infer-web.py
学習方法
- UI起動後、トレーニングタブを選択
- 学習時設定の登録
- ①モデル名:任意の名称
- ②トレーニング用のフォルダのパス:wavもしくはmp3のデータのあるフォルダのパス
- ③ピッチ抽出アルゴリズムの選択:harvest

- データ処理をクリックし、処理終了を待つ(1~2分程度)
- 特徴抽出をクリックし、処理終了を待つ(1~2分程度)
- ワンクリックトレーニングをクリックし、処理終了を待つ(約30分~)
- 補足:1時間のwavでGTX3060tiで30分程度
- /assets/weightsに学習重みが保存される
学習データ利用(音声ファイルの変換)
- UIのモデル推論タブに移動する
- ①「音源推論」に学習モデルが表示されない場合は、「音源リストとインデックスパスの更新」をクリックしたのち、自身の学習データを選択する
- ②変換元とするwav・mp3ファイルのパスをコピペする
- ③harvestを選択
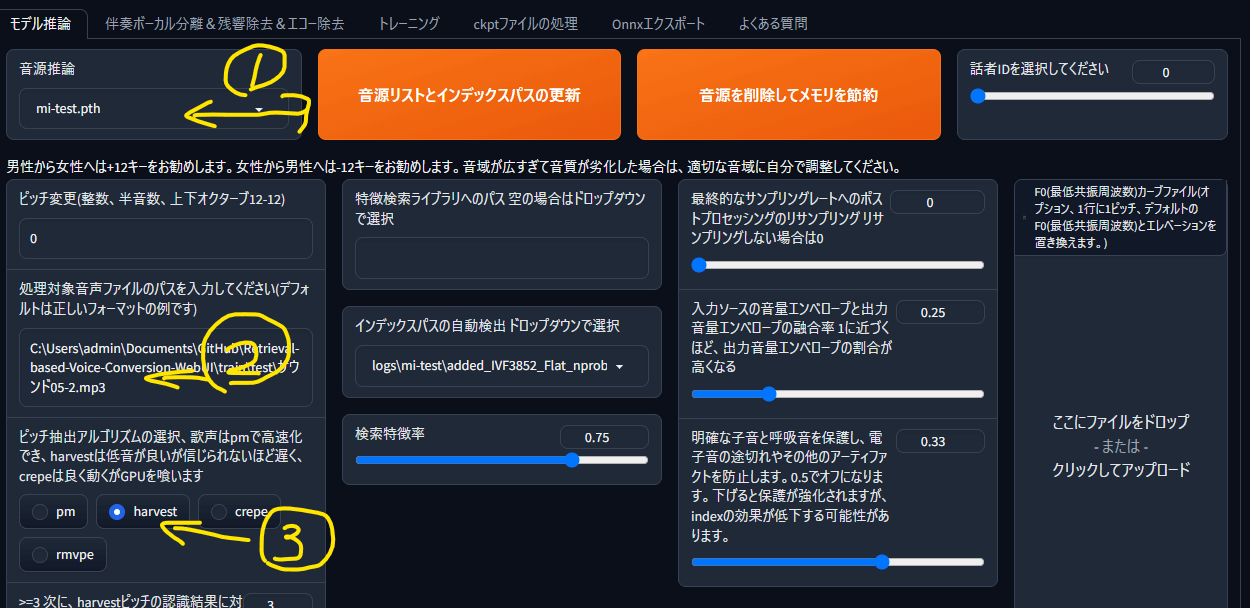
- ④変換をクリックする
- ⑤出力音声を選択して確認・保存ができる
リアルタイム変換
- cmdでリアルタイム変換用GUI起動する
python gui_v1.py- おそらく初回にmodule不足エラー数回出ます。不足したmoduleは下記を都度実行しインストールし、その後、上記cmdを再度実行
pip install モジュール名 - GUIの設定
- .pthファイルを選択:/assets/weights/ にある自身のモデルを選択
- .indexファイルを選択:logs/モデル名/ にあるadded~から始まるindexファイル選択
- ピッチアルゴリズム:harvestを選択
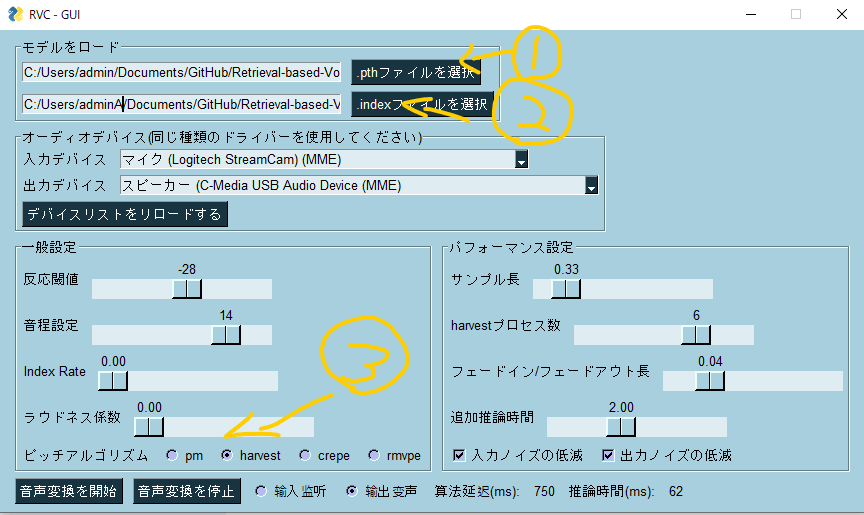
- 「音声変換を開始」でリアルタイム変換が始まります
- 音程が合わない場合、音程設定をいじることでより自然になります
所感
- wavの変換はわりと自然な変換ができている
- リアルタイム変換はwavに比べ、音割れによる機械音声ぽさが目立つためやや不自然
- 学習時の設定などはある程度品質が良くなるものを設定しているが、設定次第ではもう少しだけ品質が良くなる余地がある
Discussion